1 STATISTICKÁ ŠETŘENÍ Základem každého statistického zkoumání jsou údaje (data). Lze je získat v zásadě dvěma způsoby. Buď je převzít z nějakého zdroje nebo je sami zjistit. Sekundární data • údaje, které převezmeme z různých zdrojů; • převzetí je nejčastějším způsobem získání dat; • vždy je nutné prověřit důvěryhodnost zdroje dat. Primární data • data, která nejsou převzatá; • jsou originální, sami je zjišťujeme. Zdrojem statistických údajů je statistické šetření (zjišťování). Je to získávání neznámých dat o hodnotách určených statistických znaků jednotlivých jednotek zkoumaného statistického souboru. Náplní statistického šetření není pouze vlastní získávání dat, ale jsou to také teoretické a praktické postupy tohoto zjišťování. V případě statistických šetření v oblasti sociálně-ekonomických informací se často setkáváme s velmi rozsáhlými základními soubory. Proto je v prvé řadě nutno rozhodnout, zda statistické šetření realizovat jako úplné (vyčerpávající) či výběrové. V případě, že zjišťování bude prováděno jako výběrové, je třeba zvolit vhodný druh šetření, který nám umožní získat o zkoumané problematice co nejkvalitnější informace. Základní soubor (populace) • statistický soubor, jehož vlastnosti zkoumáme; • rozsah tohoto souboru N je většinou velký. Výběrový soubor (výběr, vzorek) • je tvořen pouze některými statistickými jednotkami, vybranými ze základního souboru; • rozsah tohoto souboru n < N. 1.1 Druhy výběrových statistických šetření Existuje celá řada druhů výběrových šetření, která rozdělujeme podle toho, do jaké míry lze výsledky výběrového šetření zobecnit na základní soubor. Nereprezentativní výběrová šetření • výběrový soubor je nereprezentativní; • zobecnění výsledků na základní soubor není možné nebo je přinejmenším velmi problematické. Reprezentativní výběrová šetření • výběrový soubor je reprezentativní (svými vlastnostmi představuje velmi věrnou zmenšeninu vlastností souboru základního); • v takovém případě je možno zobecnit poznatky, získané při zkoumání výběrového souboru, na soubor základní.
Transcript
1 STATISTICKÁ ŠET ŘENÍ Základem každého statistického zkoumání jsou údaje (data). Lze je získat v zásadě dvěma způsoby. Buď je převzít z nějakého zdroje nebo je sami zjistit. Sekundární data
• údaje, které převezmeme z různých zdrojů; • převzetí je nejčastějším způsobem získání dat; • vždy je nutné prověřit důvěryhodnost zdroje dat.
Primární data
• data, která nejsou převzatá; • jsou originální, sami je zjišťujeme.
Zdrojem statistických údajů je statistické šetření (zjišťování). Je to získávání neznámých dat o hodnotách určených statistických znaků jednotlivých jednotek zkoumaného statistického souboru. Náplní statistického šetření není pouze vlastní získávání dat, ale jsou to také teoretické a praktické postupy tohoto zjišťování. V případě statistických šetření v oblasti sociálně-ekonomických informací se často setkáváme s velmi rozsáhlými základními soubory. Proto je v prvé řadě nutno rozhodnout, zda statistické šetření realizovat jako úplné (vyčerpávající) či výběrové. V případě, že zjišťování bude prováděno jako výběrové, je třeba zvolit vhodný druh šetření, který nám umožní získat o zkoumané problematice co nejkvalitnější informace. Základní soubor (populace)
• statistický soubor, jehož vlastnosti zkoumáme; • rozsah tohoto souboru N je většinou velký.
Výběrový soubor (výběr, vzorek) • je tvořen pouze některými statistickými jednotkami, vybranými ze základního
souboru; • rozsah tohoto souboru n < N.
1.1 Druhy výběrových statistických šetření Existuje celá řada druhů výběrových šetření, která rozdělujeme podle toho, do jaké míry lze výsledky výběrového šetření zobecnit na základní soubor. Nereprezentativní výběrová šetření
• výběrový soubor je nereprezentativní; • zobecnění výsledků na základní soubor není možné nebo je přinejmenším velmi
problematické.
Reprezentativní výběrová šetření • výběrový soubor je reprezentativní (svými vlastnostmi představuje velmi věrnou
zmenšeninu vlastností souboru základního); • v takovém případě je možno zobecnit poznatky, získané při zkoumání výběrového
souboru, na soubor základní.
1.1.1 Nereprezentativní výběrová šetření
Anketa • způsob šetření, kdy je oslovena jen určitá část statistických jednotek (určitý okruh
osob, podniků, institucí atd.); • nejběžnější formou jsou dotazníky; • princip dobrovolnosti, návratnost je velmi malá.
Metoda základního masivu • vhodná tehdy, obsahuje-li soubor několik velmi velkých jednotek a velký počet
jednotek malých; • probíhá-li zkoumaný jev převážně ve velkých jednotkách, prošetří se pouze tyto,
zatímco malé jednotky se vynechají. Existují různé další druhy nereprezentativních šetření, např. samovolný výběr, namátkový výběr atd. 1.1.2 Reprezentativní výběrová šetření Podle toho, jakým způsobem je reprezentativnost výběrového souboru zabezpečena, lze reprezentativní výběrová šetření rozdělit v zásadě na dva druhy, a to záměrný výběr a náhodný výběr. V případě, že výběrová data jsou pořízena náhodným výběrem, mluvíme o tzv. pravděpodobnostních výběrových šetřeních. Záměrný (úsudkový) výběr
• zkušený odborník vybírá podle vlastního úsudku ze základního souboru určité statistické jednotky záměrně tak, aby výběrový soubor byl co nejvíce reprezentativní;
• nebezpečí silného prvku subjektivity; • zabezpečení reprezentativnosti může být poměrně obtížné; • tento výběr lze provádět v zásadě dvěma způsoby – jako výběr typický nebo výběr
kvótní; • typický výběr spočívá ve výběru jednotek s hodnotami zkoumaného znaku blízkými
modu event. průměru; v případě kvótního výběru sestavujeme výběrový soubor tak, aby kopíroval strukturu základního souboru podle zvoleného kvótního (pomocného) znaku.
Náhodný výběr
• výběrová data jsou pořízena náhodným způsobem; • takováto výběrová šetření označujeme jako pravděpodobnostní; • tato šetření jsou vždy reprezentativní; • reprezentativnost výběrového souboru je zabezpečena prostřednictvím náhody,
přesněji řečeno prostřednictvím zabezpečení působení zákonitostí náhody; • charakteristiky získané z výběrového souboru lze zobecnit na základní soubor za
pomoci metod matematické statistiky; • existují různé druhy náhodného výběru, záleží přitom na hledisku, podle kterého se
třídění provádí.
1.2 Náhodný výběr Z hlediska pravděpodobnosti vybírání lze náhodný výběr realizovat dvěma způsoby, a to jako výběr se stejnými nebo různými pravděpodobnostmi. Náhodný výběr se stejnými pravděpodobnostmi
• každá jednotka základního souboru má stejnou pravděpodobnost vybrání, tedy stejnou možnost dostat se do výběrového souboru;
• výhodou je, že není třeba mít k dispozici jakékoli další informace, stačí znát pouze rozsah základního souboru.
Náhodný výběr s různými pravděpodobnostmi
• jednotky základního souboru mají různou pravděpodobnost vybrání; • je třeba mít doplňkové informace, na jejichž základě přiřadíme jednotlivým jednotkám
pravděpodobnosti vybrání.
1.2.1 Prostý náhodný výběr
• nejjednodušší druh náhodného výběru; • přímý (neomezený) výběr jednotek z netříděného základního souboru; • při každém tahu má každá jednotka, která je při tomto tahu v základním souboru,
stejnou pravděpodobnost vybrání; • lze ho realizovat jako výběr s vracením nebo bez vracení .
Výběr s vracením
• jednotlivé tahy jsou nezávislými náhodnými pokusy; • pravděpodobnost, že jednotka bude vybrána je pro všechny tahy stejná (1/N); • rozsah základního souboru se nemění.
Výběr bez vracení
• jednotlivé tahy jsou závislými pokusy; • pravděpodobnost, že bude jednotka vybrána, se s každým dalším tahem zvětšuje; • rozsah základního souboru se s každým dalším tahem zmenšuje.
1.2.2 Složitější uspořádání náhodného výběru Oblastní (stratifikovaný) výběr
• základní soubor se nejdříve rozdělí na oblasti (tzv. straty); • oblasti by měly být uvnitř co nejvíce homogenní, tzn. obsahovat jednotky, které jsou
si z určitého hlediska podobné; • v dalším kroku provedeme v každé oblasti náhodný výběr daného počtu prvků,
nejčastěji se provádí výběr proporcionální – výběrové rozsahy v oblastech jsou úměrné velikostem oblastí;
• vyžaduje určité předběžné informace pro třídění jednotek do oblastí; • vede ke značné prostorové rozptýlenosti jednotek výběrového souboru.
Dvoustupňový (vícestupňový) výběr • základní soubor se nejdříve rozdělí do skupin; • v prvním stupni se ze základního souboru vyberou skupiny jednotek – tzv. primární
jednotky; • ve druhém stupni se ve vybraných primárních jednotkách náhodně vybírají statistické
jednotky - tzv. sekundární jednotky; • tento druh výběru lze zobecnit pro více stupňů; • prostorová rozptýlenost vybraných jednotek je oproti oblastnímu výběru menší,
snižují se tak náklady na získání dat. Výběr skupin
• je zvláštním případem dvoustupňového výběru; • v prvním stupni se ze základního souboru vyberou skupiny jednotek; • ve druhém stupni se ve vybraných skupinách prošetří všechny jednotky; • oproti klasickému dvoustupňovému výběru se ještě více zvýší prostorová koncentrace
vybraných jednotek. 1.2.3 Techniky náhodného výběru Náhodný výběr je možno provádět různými způsoby, vždy je však nutno zabezpečit, aby nebyla narušena náhodnost vybírání, jinak řečeno je nutno použít správnou techniku výběru. V některých případech lze provést náhodný výběr přímo, většinou však je třeba mít k dispozici tzv. oporu výběru. Je to soubor značek nebo čísel, kterými jsou statistické jednotky zastoupeny. U opory výběru je důležité, aby byla úplná a co nejvíce aktuální. Jako oporu výběru je možno použít např. registr firem, registr osob, mapu atd. Losování
• nejjednodušší technika náhodného výběru; • je třeba mít k dispozici oporu výběru; • všechny jednotky základního souboru nebo jejich zástupce (např. lístky s názvy nebo
pořadovými čísly jednotek) řádně promícháme a následně odebereme požadovaný počet jednotek;
• lze realizovat jako výběr s vracením i bez vracení; • lze použít jak pro výběr se stejnými, tak i s různými pravděpodobnostmi; • není to univerzální metoda, v případě rozsáhlých souborů je její použití obtížné, někdy
prakticky neproveditelné. Výběr pomocí náhodných čísel
• je třeba mít k dispozici oporu výběru; • každé jednotce základního souboru přiřadíme pořadové číslo; • k získání potřebného počtu náhodných čísel lze použít tabulky náhodných čísel nebo
software, který obsahuje generátor náhodných čísel; • jednotky s těmito pořadovými čísly pak zahrneme do výběru; • u rozsáhlých základních souborů je tato metoda oproti losování jednodušší, ale přesto
stále značně pracná; • v takovém případě je většinou lepší přejít např. k výběru systematickému.
Systematický výběr • není k němu třeba opora výběru; • podmínkou provedení je, aby jednotky základního souboru byly seřazeny nezávisle na
zkoumaném znaku, tedy zcela objektivně; • stanovíme výběrový krok k = N/n;
• náhodně zvolíme první jednotku (např. losováním); • vybíráme každou k-tou jednotku počínaje od náhodně zvolené.
Výběr pomocí nekorelovaného znaku • do výběru se zahrnou jednotky se společnou hodnotou zvoleného znaku, nezávislého
na znaku zjišťovaném.
2 METODY POŘIZOVÁNÍ DAT Pořizování dat je první a velmi významnou etapou statistického průzkumu, neboť na kvalitě údajové základny do značné míry záleží úspěch celého šetření. K pořizování dat lze použít různé techniky, z nichž nesporně nejfrekventovanější je dotazování. Existují i další techniky, např. pozorování a experiment, které jsou zejména v oblasti sociálně-ekonomické využívány méně.
2.1 Dotazování Dotazování je nejrozšířenější způsob získávání údajů při průzkumech v sociálně-ekonomické oblasti. Nástrojem jeho uskutečnění je dotazník. Forma komunikace s respondentem může být buď přímá (např. písemné dotazování) nebo zprostředkovaná (osobní dotazování pomocí tazatele). Písemné dotazování
• kontakt výzkumníka s respondentem je přímý, bezprostřední; • probíhá za pomoci dotazníku; • respondent má k dispozici psané otázky, na ně přímo písemně odpovídá; • velmi důležitá je přitom kvalita dotazníku; • problém je nejen s návratností dotazníků, ale také se správností a úplností odpovědí; • v současnosti ustupuje papírová forma dotazníku čím dál více formě elektronické.
Osobní dotazování
• komunikace s respondentem je zprostředkovaná, má podobu rozhovoru respondenta s tazatelem;
• při tomto způsobu má respondent menší pocit anonymity, což je někdy na překážku; • tazatel čte otázky (případně varianty odpovědí) a zaznamenává reakce respondenta; • jde o proces finančně, organizačně i časově náročnější než písemné dotazování; • významná je úloha tazatele, který respondenta do značné míry ovlivňuje; • tazatel by měl mít určitou úroveň vzdělání, být náležitě vyškolen a instruován; • důležitá je průběžná kontrola práce tazatelů.
Telefonické dotazování
• modifikovaná forma osobního dotazování; • je operativnější, výhodou je rychlost a nižší cena; • respondent se cítí více v anonymitě, je otevřenější; • tento způsob dotazování však musí být stručnější, navíc při něm nelze použít vizuální
pomůcky.
2.2 Dotazník Kvalita dotazníku je faktorem, který významně ovlivňuje každý průzkum. Špatně sestavený dotazník má negativní dopad na získávání informací a tím na výsledky prováděného šetření. Při vytváření dotazníku je třeba dodržovat určitá pravidla a naplnit celou řadu požadavků.
2.2.1 Celkový dojem dotazníku Dotazník by měl na respondenta zapůsobit na první pohled příznivým dojmem, určitým způsobem ho upoutat, aby měl chuť a zájem se jeho vyplňování věnovat.
• důležitá je vhodná grafická úprava, která ovlivňuje první dojem respondenta (barva a kvalita papíru, úprava první stránky atd.);
• formát dotazníku – neměl by být ani příliš malý ani příliš velký, za nejvhodnější je běžně považován formát A4;
• pokud je součástí dotazníku úvodní text, měl by vzbudit v respondentovi zájem, zdůraznit smysl poskytovaných informací, apelovat na důležitost respondentovi spolupráce;
• dotazník by měl mít optimální délku (maximálně 40 až 50 otázek), doba potřebná k vyplnění by neměla přesahovat 20 minut; příliš rozsáhlý dotazník respondenta odrazuje, protože jeho vyplnění zabere mnoho času;
• důležité je ujistit respondenta o zachování anonymity. 2.2.2 Formulace otázek Formulace jednotlivých otázek má pro úspěch šetření velký význam. Důležité je i vhodné pořadí otázek, které může respondenta do značné míry ovlivnit.
• otázky je třeba formulovat jednoznačně a srozumitelně; • sled otázek by měl být pokud možno co nejvíce logický, není vhodné přeskakovat
z jednoho problému na druhý; • velký význam má validita otázek, jinak řečeno, je třeba se ptát skutečně na to, co
potřebujeme zjistit; validita většinou souvisí s časovými, sociálními a kulturními podmínkami výzkumu;
• důležitá je také reliabilita neboli spolehlivost odpovědí, která má vyjádřit míru stálosti opakovaně zjišťovaných výsledků, jinak řečeno výsledkem opakovaného zjišťování by měly vždy být shodné údaje;
• je vhodné vyvarovat se všeho, co na respondenta působí negativně (dlouhá a složitá formulace otázek atd.);
• doporučuje se používání eufemismů, tedy opisných vyjádření, která zeslabují některá nepříjemná či negativní hodnocení;
• není vhodné používat sugestivní otázky, které svou formulací zavádějí respondenty k určité odpovědi.
2.3 Druhy otázek Otázky lze rozdělit podle typu do několika skupin. Záleží přitom na hledisku, podle kterého jsou otázky tříděny. 2.3.1 Druhy otázek podle formy Uzavřené
• jinak řečeno řízené, standardizované; • tento typ otázek je typický pro kvantitativní výzkum;
• nabízejí respondentovi několik variant odpovědí, z nichž je nucen si vybrat; • výhody – rychlé a snadné vyplnění dotazníku; respondenta je možno nasměrovat na to,
co nás nejvíce zajímá; • nevýhody – respondent si musí vybrat z nabízených variant odpovědí, a to i v případě,
že je nepovažuje za výstižné; předkládané varianty mohou působit na respondenta sugestivně.
Uzavřené otázky lze dále rozdělit na: Dichotomické (binární, alternativní, dvojné)
• mají pouze dvě varianty odpovědí (např. ano – ne, žena – muž); • výhodou je to, že jsou snadno zpracovatelné; • častou nevýhodou je skutečnost, že respondenti jsou nuceni vyjádřit krajní stanovisko.
Výběrové (polytomické, s možností vybrat pouze jednu variantu)
• pro zpracování jsou výhodné; • nevýhodou je to, že vylučují možnost vybrat v případě potřeby více variant.
Výčtové (polytomické, s možností vybrat více variant)
• umožňují volnější výběr, mohou lépe odrážet realitu; • odpověď respondenta se v tomto případě nazývá vícehodnotová (multiple response); • nevýhodou je obtížnost statistického zpracování, je třeba použít speciální analytické
postupy; • např. je možno postupovat tak, že jednotlivé varianty jsou brány jako dichotomický
znak, který se buď vyskytl nebo nevyskytl. Polytomické, s uvedením pořadí variant
• na respondenta působí příznivě, umožňují mu určovat pořadí variant; • z hlediska statistického zpracování jsou ještě náročnější než otázky výčtové.
Otevřené
• jinak řečeno volné, nestandardizované; • tento typ otázek je typický pro kvalitativní výzkum (např. marketingový); • respondentovi nejsou předkládány žádné varianty odpovědí, může se vyjádřit zcela
svobodně, vlastními slovy; • výhody – respondent není omezen nabízenými variantami odpovědí; není tak tlačen do
odpovědí, které mu nevyhovují; • nevýhody – volnost odpovědí způsobuje problémy při následném zpracování; nejdříve
je třeba provést kategorizaci (např. kódování); • při kategorizaci dat je možno použít i složitější metody, např. shlukovou analýzu
(cluster analysis). Polootevřené
• jinak řečeno polouzavřené; • jsou kombinací otevřených a uzavřených otázek; • je to v podstatě kompromisní forma otázek, která umožňuje respondentovi, aby si
zvolil sám, zda chce odpovídat volně či si vybírat z nabízených variant odpovědí.
2.3.2 Druhy otázek podle účelu Meritorní
• pro průzkum jsou nejvýznamnější, zabývají se přímo předmětem průzkumu; • týkají se samotné podstaty zkoumaného problému.
Pomocné
• napomáhají vedení rozhovoru požadovaným směrem; • kontaktní – slouží k navázání kontaktu s respondentem, pomáhají mu vniknout
dozkoumané problematiky; někdy se ani dále nezpracovávají; • filtrační (větvící) – při dotazování slouží k roztřídění respondentů do určitých skupin
(podsouborů), které následně odpovídají na odlišné otázky. Identifikační
• bývají označovány také jako analytické; • slouží k popisu nejdůležitějších vlastností zkoumaných jednotek (pohlaví, věk,
zaměstnání atd.); • při následném zpracování umožňují respondenty třídit do skupin podle požadovaných
kritérií. Kontrolní
• ověřují správnost odpovědí na některé položené otázky; • jsou důležité zejména tam, kde z nějakých důvodů předem pochybujeme o kvalitě
odpovědí, resp. předpokládáme možnost jejich zkreslování; • v dotazníku by měly být umístěny tak, aby nebyla odhalena jejich funkce.
2.3.3 Druhy otázek podle obsahu Přímé
• účel dotazu je zřejmý, takže respondent vědomě odpovídá na to, na co je dotazován; • tento typ otázek s sebou nese různá rizika – na respondenta může působit nepříjemně,
někdy vyvolává pocit napětí či ohrožení; • respondent v takovém případě neodpoví pravdivě, ale tak, aby to podle něj bylo
společensky přijatelné; • dochází tak k více či méně systematickému zkreslování odpovědí; • často vede ke snížení ochoty k další spolupráci.
Nepřímé
• z dotazu není na zcela patrné, co je otázkou zjišťováno; • respondent se necítí osobně ohrožen, k dané problematice se pak vyjadřuje ochotněji; • jejich cílem je co nejvíce snížit možnost zkreslení odpovědí.
3 ŠKÁLOVÁNÍ Škálování je technika, používaná k vyhodnocování dat v marketingových průzkumech, ve výzkumech veřejného mínění a v dalších oblastech, kde jsou zkoumány jevy, které nejsou objektivně pozorovatelné a měřitelné (kvantifikovatelné). Jedná se většinou o postoje, názory, pocity, motivace, znalosti apod., tedy o jevy, které existují pouze ve vědomí dotazovaných osob a nejsou kvantitativního charakteru. Škála
• je to určitá stupnice, na kterou promítneme (převedeme) zkoumaný jev, jinak řečeno zjišťujeme stupeň hodnocení respondentova vnímání sledovaného jevu;
• škála může být vyjádřena různým způsobem – slovně, číselně či graficky; • při škálování dochází ke zjednodušení zkoumaných jevů, které jsou souhrnem celé
řady různých znaků; • výhodou je, že toto zjednodušení umožňuje aplikaci statistických metod, zkoumané
jevy je možno měřit a hodnotit; • nevýhodou je, že dané fenomény jsou touto metodou zachyceny pouze zhruba, právě
vzhledem k jejich zjednodušení. Pravidla pro tvorbu škál
• pro tvorbu škál existuje celá řada rámcových pravidel, kterými je vhodné se řídit; • škála by neměla mít příliš málo ani příliš mnoho stupňů, detailnost stupnice vždy
závisí na konkrétní situaci; • čím více stupňů škála má, tím větší klade nároky na rozlišovací schopnosti
respondenta (v praxi je nejběžnější škála pětistupňová); • v případě ordinální škály je třeba jednoznačně stanovit směr škály; • za vhodnější bývá považován lichý počet stupňů, který většinou umožňuje
respondentovi zaujmout neutrální postoj („nevím“, „nedokážu odpovědět“ atd.); • nedoporučuje se používat záporné hodnoty, neboť mohou v respondentovi evokovat
negativní asociace.
3.1 Typy škál Existují různé typy škál, které úzce souvisejí s typologií statistických proměnných. Třídícím kritériem je přitom způsob srovnávání hodnot (kategorií) škály. Nominální škály
• jsou slovní (jmenné); • slouží ke kvalitativnímu třídění dat; • jedná se v podstatě o výčet různých kategorií odpovědí, přičemž tyto kategorie nelze
hierarchicky uspořádat; • mezi jednotlivými kategoriemi nelze stanovit vzdálenosti, je možno pouze posoudit,
zda jsou kategorie stejné či různé; • pokud jsou v takovýchto škálách používána čísla, mají význam pouhých symbolů a
nelze je zpracovávat kvantitativními metodami; • zpracování je možné za pomoci statistických metod, vhodných pro nominální
proměnné.
Ordinální (pořadové) škály • jsou slovní nebo numerické; • zařazují kategorie odpovědí do určitého pořadí; • pořadí kategorií může vyjadřovat hodnocení, důležitost, přitažlivost atd.; • jednotlivé kategorie lze hierarchicky uspořádat podle objektivně stanoveného kritéria; • kategoriím lze přiřadit pořadová čísla (např. 1, 2, 3); • vzdálenosti (diference) mezi kategoriemi nemají žádný význam neboť chybí obsah
vzdálenosti mezi čísly; • je přípustná libovolná monotónní transformace, zachovávající pořadí kategorií; • kategorie lze mezi sebou porovnávat nerovností,je tedy možno posoudit, zda je jedna
kategorie větší či menší než druhá; nelze však změřit o kolik; • kategorie nelze porovnávat podílem, jinak řečeno nelze stanovit, kolikrát je jedna
kategorie větší či menší než druhá; • problémem je velká subjektivita při takovémto hodnocení, stejná pořadí různých
respondentů nemusejí znamenat totéž; • zpracování provádíme za pomoci statistických metod, vhodných pro ordinální
proměnné.
Metrické škály • jsou vždy numerické; • používají se při zkoumání metrických proměnných, které jsou udávány v měrných
jednotkách; • ke zpracování lze používat statistické metody, vhodné pro metrické resp. kardinální
proměnné; • existují v zásadě dva druhy metrických škál, a to intervalové a poměrové.
Intervalové škály
• hodnoty škály lze srovnávat pouze rozdílem (diferencí), nelze je porovnávat podílem (poměrem);
• stejná vzdálenost mezi dvěma hodnotami má stejný význam, ať jsou na škále umístěny kdekoli;
• takovéto škály lze lineárně transformovat; • tyto škály nemají přirozený počátek, tedy objektivně stanovenou nulu (absolutní
nulový bod); • např. teplotní stupnice (Celsiova a Fahrenheitova).
Poměrové škály
• hodnoty škály lze srovnávat nejen rozdílem, ale také podílem (poměrem); • tyto škály mají přirozený počátek, tedy absolutní nulu; • takovéto škály lze lineárně transformovat, ale pouze bez absolutního členu.
3.2 Škálovací postupy Existuje celá řada škálovacích postupů, které lze rozdělit v zásadě do dvou skupin. Buď jsou to postupy založené na vzájemném srovnávání jednotek vzhledem ke sledovanému znaku nebo postupy založené na samostatném hodnocení, nezávislém na ostatních. Respondent přitom může hodnotit sledovaný jev přímo (bezprostředně) nebo nepřímo (zprostředkovaně).
Metoda párových srovnání • postup srovnávací, hodnocení přímé; • respondent porovnává různé subjekty, jejich vlastnosti apod. (obecně stimuly); • ve výběrovém souboru n respondentů srovnáváme všechny možné dvojice k stimulů
podle stanoveného kritéria; • spočteme, kolikrát byla dána přednost stimulu A před stimulem B, zjištěné četnosti
jsou uspořádány do dvourozměrné tabulky; • v tabulce jsou tedy četnosti případů, kdy např. stimul ve sloupci zvítězil nad stimulem
v řádku; • sloupcové součty pak představují celkový počet případů, kdy stimul ve sloupci
zvítězil nad všemi ostatními stimuly; • je tedy možno stanovit pořadí stimulů, nelze však určit diference v hodnocení
respondentů; • výsledkem postupu je ordinální škála.
Zlomkové škály
• postup srovnávací, hodnocení přímé; • postup je založen na vzájemném srovnávání stimulů; • jednomu ze stimulů je přiřazeno určité ohodnocení (např. 100 bodů); • toto hodnocení je základem pro všechna další prováděná srovnávání, jinak řečeno
v závislosti na tomto základu přiřazují respondenti určité počty bodů ostatním stimulům;
• hodnocení dalších stimulů je tedy zlomkem ohodnocení základu; • nedostatkem této metody je velká subjektivita, která často vede k výskytu extrémních
hodnot, neboť není stanovena horní mez hodnocení; • výsledkem postupu je ordinální škála.
Škály konstantního součtu
• postup srovnávací, hodnocení přímé; • je modifikací zlomkové škály; • respondent rozdělí mezi srovnávané stimuly stanovený počet bodů (např. 100); • součet ohodnocení je tedy předem omezen, čímž se eliminuje nebezpečí vzniku
výrazných extrémů; • výsledkem postupu je ordinální škála.
Grafická škála
• hodnocení samostatné, přímé; • grafickou škálu lze vyjádřit různými způsoby; • může ji představovat např. úsečka, jejímuž počátečnímu a koncovému bodu jsou
přiřazeny opačné extrémní hodnoty (např. jeden kraj představuje zcela pozitivní postoj, druhý kraj zcela negativní postoj);
• respondent vyjadřuje svoji odpověď tím, že umístí na úsečku v příslušném místě bod; • lze přejít na fyzicky změřené vzdálenosti, takže je možno vyjádřit odpovědi číselně; • jiným způsobem vyjádření je např. posloupnost obrázků, které srozumitelně a názorně
vyjadřují požadované odstupňování; • obrázkům lze přiřadit pořadová čísla, čímž získáme ordinální škálu.
Bodovací (známkovací) škála • hodnocení samostatné, přímé; • podle charakteru zkoumaného znaku je třeba zvolit vhodný počet škálových hodnot; • jednotlivá bodová hodnocení lze doplnit slovním popisem; • takováto škála je ordinální.
Sémantický diferenciál
• hodnocení samostatné, přímé; • spočívá ve vytvoření soustavy shodně orientovaných škál, jejichž krajní body jsou
• tento systém hodnocení je vícekriteriální, hodnocení je prováděno z různých hledisek; • většinou jsou používány sedmibodové event. pětibodové škály, které mohou být
vyjádřeny graficky, číselně, pomocí piktogramů apod.; • respondent na každé škále vyznačí své hodnocení; • pokud vyznačené body spojíme křivkou, získáme tzv. polaritní profil, který zobrazuje
jak celkové hodnocení objektu, tak i hodnocení jeho jednotlivých vlastností; • získaná hodnocení je možno dle potřeby shrnovat, lze stanovit průměrné (resp.
prostřední) hodnocení objektu jako celku i průměrné hodnocení jednotlivých vlastností.
Likertova metoda
• hodnocení samostatné, nepřímé; • postoj respondentů je vyjádřen výroky; • respondent ohodnotí stupeň svého souhlasu či nesouhlasu s daným výrokem určitým
počtem bodů v souladu s nabídnutou škálou (většinou pětibodovou či sedmibodovou); • sumarizací výsledků pro jednotlivé respondenty získáme u každého z nich celkové
skóre; • sumarizací výsledků pro jednotlivé otázky získáme celkové skóre pro každou otázku; • skóre je dále možno podrobněji analyzovat – stanovit jejich průměr, modus, medián a
změřit jejich variabilitu. Skalogramová analýza
• základem je posloupnost kumulativních otázek, to znamená otázek uspořádaných tak, že respondentova kladná odpověď na některou z nich s velkou pravděpodobností znamená také kladnou odpověď na všechny otázky předchozí;
• pokud je tato pravděpodobnost rovna 1, jde o tzv. perfektní skalogram; • tato metoda je značně pracná, při větším počtu otázek vyžaduje použití počítače.
4 CHYBĚJÍCÍ ÚDAJE Při statistickém zpracování hrají zásadní roli kvalitní, validní a věrohodná primární data, protože pouze na základě takovýchto dat je možno činit správné závěry a kvalifikovaná rozhodnutí. V této souvislosti vystupuje do popředí faktor, který může významně ovlivnit výsledky jakéhokoli průzkumu, a tím je existence chybějících údajů. Zejména u rozsáhlejších výběrových souborů se chybějícím údajům v podstatě nelze vyhnout. Jejich podíl je do značné míry závislý na kvalitě zjišťování, zejména pak v případě dotazníkových šetření, která jsou nejfrekventovanější formou provádění průzkumů.
4.1 Druhy chybějících údajů 1. Uživatelem definované chybějící údaje
• uživatel sám určuje, co bude za chybějící údaj považováno; • může to být nezodpovězená otázka (ať již respondent neodpověděl z jakýchkoli
důvodů, tzv. non-response), nečitelná nebo špatně označená odpověď (takže není jasné, co respondent zamýšlel sdělit) či odpověď „nevím“ (pokud není jednou z možností předkládané škály);
• jako chybějící údaje je rovněž v případě potřeby možno definovat málo zastoupené kategorie či kategorie pro sledování určitého problému nepodstatné;
• za chybějící údaje také lze považovat odlehlá pozorování, která mohou výrazně zkreslit hodnoty některých statistických charakteristik.
Non-response
• v případě, že je odpověď nevyplněná, jde ze strany respondenta nejčastěji o odmítnutí odpovědi, kdy respondent požadovaný údaj nechce sdělit; v poslední době je velmi častým argumentem odmítnutí zákon o ochraně osobních údajů;
• další možností je, že respondent neporozuměl otázce nebo si z nabízených odpovědí není schopen vybrat, protože žádná dobře nevystihuje jeho názory či pocity;
• někdy nemá respondent dost času, aby vyplnil dotazník celý, nebo ztratí v průběhu jeho vyplňování zájem;
• je také možné, že v době zjišťování není respondent k dispozici; • existují rovněž respondenti, kteří sice údaje poskytnou, ale úmyslně nebo neúmyslně
zkreslují stav zkoumaného problému. 2. Systémové chybějící údaje Mohou vzniknout v zásadě dvěma způsoby:
• při samotném vstupu dat, a to v případě, kdy nebyla zadána žádná hodnota nebo byla vložena hodnota nepřípustná;
• jako výsledky výpočtů, které jsou z matematického hlediska neproveditelné (např. dělení nulou).
4.2 Druhy chyb při statistickém zpracování Při statistickém zpracování je nutno rozlišovat tzv. výběrovou chybu, která je předmětem zájmu matematické statistiky, a nevýběrovou chybu, která vzniká v souvislosti s chybějícími údaji.
Výběrová chyba (sampling error) • vzniká vlivem variability zkoumaných proměnných v populaci v důsledku skutečnosti,
že vždy prošetřujeme pouze jeden ze všech možných existujících výběrových souborů; • při zvětšování rozsahu výběru se tato chyba zmenšuje; • vzniká pouze v případě výběrových šetření; • minimalizace výběrové chyby je jedním ze základních momentů matematicko-
statistické teorie výběrových šetření. Nevýběrová chyba (non-sampling error)
• je důsledkem existence chybějících údajů; • při zvětšování rozsahu výběru má tato chyba tendenci k růstu; • vede k více či méně významnému zkreslení, které je do značné míry nezávislé na
výběrovém postupu; • vzniká jak v případě výběrových, tak i úplných šetření; • mezi odborníky existují názory, že při průzkumech způsobují nevýběrové chyby větší
zkreslení celkových výsledků než chyby výběrové.
4.3 Postupy při práci s chybějícími údaji Při práci s chybějícími údaji je vždy třeba zvolit optimální postup, který bude nevýběrové chyby v rámci možností minimalizovat, abychom co nejvíce eliminovali ztrátu informace. Nejdříve je třeba rozhodnout, zda chybějící údaje v souboru ponecháme či nikoli. 1. Ponechání chybějících údajů ve výběrovém souboru
• tento přístup vyžaduje speciální postupy při použití statistických metod; • rozsah souboru se zmenšuje, což může vést k oslabení statistické síly prováděných
analýz; • nejvážnějším problémem je skutečnost, že zbylá data mohou být značně zkreslená.
2. Nahrazení chybějících údajů konkrétními hodnotami
• v podstatě se jedná o odhad chybějících údajů, opírající se o zbývající data; • v tomto případě lze volit z řady metod, a to podle konkrétní situace, charakteru dat
apod. Nahrazení chybějících údajů aritmetickým průměrem, vypočteným ze zjištěných hodnot
• velmi jednoduchý způsob; • tato metoda má však celou řadu omezení; • nelze ji například doporučit v situaci, kdy je chybějících údajů příliš mnoho, pokud je
variabilita údajů velmi vysoká resp. existují extrémní pozorování, takže aritmetický průměr nemá dobrou vypovídací schopnost.
Nahrazení mediánem, modem, minimální či maximální hodnotou
• obdobný způsob, jako nahrazení aritmetickým průměrem; • tento postup lze však využít i pro nominální proměnné, např. místo minimální hodnoty
se dosazuje hodnota s nejnižší četností apod.
Nahrazení chybějících údajů tzv. skupinovým průměrem • poněkud složitější metoda; • nejprve je nutno hodnoty proměnné, u které se chybějící údaje vyskytují, rozdělit do
skupin podle hodnot jiné proměnné; • v těchto skupinách je následně vypočten aritmetický průměr (event. modus jde-li o
proměnnou nominální); • chybějící údaj je pak nahrazen aritmetickým průměrem (event. modem) z příslušné
skupiny, případně také hodnotou z této skupiny náhodně vybranou; • klíčovým momentem tohoto postupu je rozdělení údajů do skupin, resp. nalezení
vhodné proměnné, na jejímž základě bude toto rozdělení provedeno; • velmi přitom záleží na konkrétní situaci, avšak zásadním požadavkem je, aby
vytvořené skupiny byly uvnitř co nejvíce homogenní, protože pouze v takovém případě má použití výše uvedené metody reálné opodstatnění.
Nahrazení chybějících údajů podle vzoru
• hodnoty určitých proměnných u respondenta, u něhož chybí údaj, jsou porovnávány s hodnotami těchto proměnných u jiných respondentů;
• přichází v úvahu několik možností: pokud se podaří nalézt respondenta se stejnými hodnotami, nahradí se chybějící údaj podle něj; pokud takový respondent není k dispozici, je možno postup opakovat pro jiné proměnné nebo vybrat respondenta náhodně;
• při provádění opakovaných šetřeních lze použít metodu nahrazení chybějícího údaje poslední, tedy nejnovější zjištěnou hodnotou.
Nahrazení chybějícího údaje odhadem, stanoveným na základě metod regresní analýzy
• z existujících hodnot jsou odhadnuty parametry modelu, vysvětlujícího hodnoty určité proměnné na základě hodnot jiných proměnných;
• tento postup přichází v úvahu pouze v případě numerických proměnných.
4.4 Řešení problematiky chybějících údajů v programových systémech Na problematiku chybějících údajů je v různé míře pamatováno ve většině programových systémů, existují různé způsoby jejich zpracování a speciální postupy pro operace s nimi. Velmi důležité je například vědět, jak mohou být chybějící údaje označovány. V tomto směru jsou mezi jednotlivými programy (např. STATGRAPHICS, SYSTAT, STATISTICA) značné rozdíly. Používány jsou rovněž různé metody vypouštění údajů, v zásadě lze rozlišit dva druhy. Metody vypouštění údajů 1. Listwise
• jde o velmi ztrátovou metodu; • chybí-li hodnota libovolné proměnné, pak je automaticky vyloučen z analýzy celý řádek datové matice s alespoň jednou chybějící hodnotou;
• použití má smysl pouze v případě, kdy počet chybějících údajů je malý v poměru k rozsahu souboru (u větších souborů např. menší než 5 %).
2. Pairwise • tato metoda je méně ztrátovou alternativou; • při hodnocení dvojic proměnných jsou vyloučeny pouze ty řádky, které se přímo týkají
alespoň jedné z proměnných, bez ohledu na to, že v jiných sloupcích těchto řádků nějaké údaje chybí;
• vynechávány jsou tedy pouze případy, kdy chybí hodnoty proměnné používané v právě probíhajících výpočtech;
• uvedený postup v důsledku vede k tomu, že různé výpočty (např. různé korelační koeficienty) používají různé soubory dat s různými rozsahy;
• tento způsob vynechání údajů se používá pro soubory s malým rozsahem nebo tehdy, když je počet chybějících údajů příliš vysoký.
Existují rovněž speciální softwarové produkty pro analýzu chybějících údajů, např. Missing Value Analysis, který je jedním z modulů systému SPSS. Pomocí něj je možno například zjistit, jsou-li chybějící údaje rozmístěny náhodně, zda existují páry proměnných, v nichž se chybějící údaje vyskytují společně, testovat existenci statisticky významných rozdílů mezi odpověďmi těch, kteří na určitou otázku neodpověděli a těch, kteří odpověděli atd. Těmito problémy se běžné programy většinou nezabývají.
5 ZPRACOVÁNÍ DAT Data, která jsme získali statistickým šetřením, je třeba adekvátním způsobem zpracovat a vyhodnotit. Prvním krokem je setřídění a zpřehlednění údajů formou tabulek a grafů. Cílem přitom je, aby vynikly charakteristické rysy a zákonitosti analyzovaného souboru. Při zpracování jednotlivých proměnných nezávisle na sobě používáme metody jednorozměrné popisné statistiky, které zahrnují rovněž výpočet statistických charakteristik.
5.1 Tabulka jednorozměrného rozdělení četností 5.1.1 Tabulka prostého rozdělení četností
• tato tabulka je výsledkem zpracování diskrétní proměnné s několika málo obměnami; • je možno ji použít pro slovní i číselné proměnné, a to jak ordinální, tak metrické resp.
kardinální; • v případě zpracování nominální proměnné nebude tato tabulka obsahovat kumulativní
četnosti, vzhledem k tomu, že obměny nominálních proměnných nelze uspořádat jednoznačným způsobem (hierarchicky).
Tabulka rozdělení četností
Četnost Kumulativní četnost Obměna proměnné
ix absolutní
in relativní
ip absolutní relativní
1x 1n 1p 1n 1p
2x 2n 2p 21 nn + 21 pp +
. . . . .
. . . . .
. . . . .
kx kn kp n 1
Celkem n 1 × ×
n
n
n
np i
k
ii
ii ==∑
=1
; nnk
ii =∑
=1
; ∑=
=k
iip
1
1
5.1.2 Tabulka intervalového rozdělení četností
• tato tabulka je výsledkem zpracování spojité proměnné nebo diskrétní proměnné s větším počtem obměn;
• variační rozpětí (R) rozdělíme na určitý počet intervalů (k); • optimální počet intervalů stanovíme podle některého ze známých pravidel (např.
Sturgesovo pravidlo: nk 10log3,31+≈ );
• při výpočtech lze každý interval zastoupit jeho středem, výsledky takovýchto výpočtů samozřejmě budou pouze přibližné.
5.2 Grafické znázornění Existuje velmi mnoho různých druhů grafů, je však třeba vždy vybrat takový, který co nelépe odpovídá charakteru zobrazovaných dat. Ke grafům, nejběžněji používaným v jednorozměrné popisné statistice, patří např. následující: Polygon četností
• spojnicový graf; • je vhodný pro znázornění prostého rozdělení četností.
Histogram četností • sloupkový graf; • vhodný pro znázornění intervalového rozdělení četností.
Výsečový graf (piechart)
• plošný graf; • vhodný pro znázornění rozdělení četností nominální proměnné.
Sloupkový graf (barchart)
• sloupkový graf; • vhodný pro znázornění rozdělení četností nominální proměnné.
5.3 Statistické charakteristiky Kromě výše uvedených metod třídění a vizualizace dat je třeba charakterizovat základní rysy zkoumaného souboru pomocí statistických charakteristik. Jejich prostřednictvím lze vyjádřit v koncentrované formě informace, které jsou v datech obsaženy. Existují čtyři skupiny popisných charakteristik; každou z charakteristik přitom lze konstruovat dvěma způsoby. Druhy statistických charakteristik:
Způsoby konstrukce statistických charakteristik: 1. Charakteristiky, které jsou funkcí všech hodnot dané proměnné:
• výpočet se provádí podle určitého funkčního předpisu; • nevýhodou je, že jsou ovlivněny případnými extrémy; • výhodou je skutečnost, že zahrnují každou jednotlivou hodnotu proměnné.
2. Charakteristiky, které nejsou funkcí všech hodnot dané proměnné:
• jsou to konkrétní hodnoty (event. průměry dvou sousedních hodnot) proměnné, stanovené podle určitého kritéria;
• výhodou je, že nejsou ovlivněny případnými extrémy; • nevýhodou je, že nemusejí vždy zachytit vlastnosti typické pro daný soubor, neboť
k jejich výpočtu používáme pouze určité vybrané hodnoty. 5.3.1 Charakteristiky polohy (úrovn ě)
• charakterizují úroveň (velikost, hladinu) proměnné; • používá se pro ně rovněž pojem střední hodnoty, neboť v podstatě charakterizují
střed, kolem něhož jednotlivé hodnoty kolísají. 5.3.1.1 Charakteristiky polohy, které jsou funkcí všech hodnot - průměry
Aritmetický průměr
• používá se tam, kde má informační smysl součet hodnot proměnné; • např. k výpočtu průměrného věku v souboru osob, průměrné mzdy v souboru
pracovníků atd.
prostý: n
xx
n
ii∑
== 1 vážený:
∑
∑
=
==k
ii
k
iii
n
nxx
1
1
Harmonický průměr
• používá se tam, kde má smysl součet převrácených hodnot proměnné; • např. k výpočtu průměrné doby potřebné ke splnění úkolu, kdy jednotky plní úkoly
současně.
prostý:
∑=
=n
i i
H
x
nx
1
1 vážený:
∑
∑
=
==k
i i
i
k
ii
H
x
n
nx
1
1
Geometrický průměr
• používá se tam, kde má smysl součin hodnot proměnné; • např. k výpočtu průměrného koeficientu růstu v časových řadách.
prostý: n
n
ii
nnG xxxxx ∏
=
=⋅⋅⋅=1
21 ..... vážený: n
k
i
ni
n nk
nnG
ik xxxxx ∏=
=⋅⋅⋅=1
21 ...21
Kvadratický průměr
• používá se tam, kde má smysl součet čtverců hodnot proměnné; • např. jestliže jednotlivé hodnoty jsou již samy odchylkami původních hodnot od
aritmetického průměru, odchylkami od normy apod.
prostý: n
xx
n
ii
K
∑== 1
2
vážený:
∑
∑
=
==k
ii
k
iii
K
n
nxx
1
1
2
5.3.1.2 Charakteristiky, které nejsou funkcí všech hodnot Modus
• označení symbolem x)
; • varianta s největší četností neboli typická hodnota; • při grafickém znázornění je to vrchol rozdělení četností.
Kvantily
• hodnoty, které rozdělují uspořádaný statistický soubor (hodnoty proměnné jsou seřazeny do neklesající řady) na určitý počet stejně obsazených částí;
• hodnoty menší event. stejné tvoří určitou stanovenou část rozsahu souboru (určitý podíl, určité procento).
Obecné označení kvantilů:
px , kde p je relativní četnost;
px100~ , kde 100 · p je relativní četnost vyjádřená v %.
Vybrané druhy kvantil ů:
• medián: označení 5,050,~,~ xxx – prostřední hodnota uspořádaného statistického
souboru, která ho dělí na dvě stejně četné části; existuje tedy 50 % hodnot menších (nebo stejných) a 50 % hodnot větších (nebo stejných).
Výpočet mediánu: a) rozsah souboru n je liché číslo – mediánem je konkrétní prvek.
+=2
1~
nxx , kde výraz 2
1+n udává pořadí mediánu v dané neklesající řadě hodnot.
b) rozsah souboru n je sudé číslo – mediánem je aritmetický průměr prostředních
dvou hodnot.
2
~ 2
2
2
+
+
=nn xx
x .
• tercily: ( ) ( )
6,06,663,03,33~,~ xxxx – jsou to dva kvantily, které rozdělují uspořádaný
statistický soubor na tři stejně četné části; • kvartily: ( ) ( ) ( )75,0755,025,025
~,~,~ xxxxxx – jsou to tři kvantily, které rozdělují
uspořádaný statistický soubor na čtyři stejně četné části;
• kvintily: ( ) ( ) ( ) ( )8,0806,0604,0402,020~,~,~,~ xxxxxxxx – jsou to čtyři kvantily, které
rozdělují uspořádaný statistický soubor na pět stejně četných částí; • sextily: 5 kvantilů, 6 částí; • septily: 6 kvantilů, 7 částí; • oktávily: 7 kvantilů, 8 částí; • nonily: 8 kvantilů, 9 částí; • decily: 9 kvantilů, 10 částí; • percentily: 99 kvantilů, 100 částí atd
Obecně se kvantily menší než x~ nazývají dolní kvantily, kvantily větší než x~ horní kvantily.
Výpočet kvantilů z intervalového rozdělení četností:
• používáme v případě, že neznáme jednotlivé hodnoty proměnné a k dispozici máme pouze intervalové rozdělení četností;
• přibližnou hodnotu jakéhokoli kvantilu je možno stanovit lineární interpolací podle vztahu
dh
d
dh
dp
ii
ip
xx
xx
−−
=−−~
,
kde dx je dolní a hx je horní mez intervalu, ve kterém leží hledaný kvantil;
di je kumulativní relativní četnost v %, odpovídající dx ;
hi je kumulativní relativní četnost v % , odpovídající hx .
5.3.2 Charakteristiky variability
• variabilita = různost = odlišnost; • udávají rozptýlení (kolísání) hodnot kolem zvoleného středu, obvykle kolem některé
ze středních hodnot. 5.3.2.1 Charakteristiky absolutní variability Tyto míry lze použít pro numerické proměnné, a to jak ordinální, tak metrické. V případě ordinálních proměnných je možno pomocí těchto charakteristik porovnávat variabilitu ve dvou či více souborech, protože odlišnosti obměn ordinálních proměnných jsou plně charakterizovány jejich absolutními rozdíly. Jiná je však situace u proměnných metrických resp. kardinálních, kde stejná absolutní variabilita v různých souborech nemusí znamenat stejnou variabilitu celkovou. Pro porovnávání je pak vhodnější použít charakteristiky relativní variability. Variační rozpětí
minmax xxR −=
Kvantilová rozpětí kvartilové rozpětí: 2575
~~ xxRq −= decilové rozpětí: 1090~~ xxRd −= atd.
Kvantilové odchylky
kvartilová odchylka: 2
~~2575 xx
Q−
= decilová odchylka: 8
~~1090 xx
D−
= atd.
Průměrná absolutní odchylka
prostá: n
xxd
n
ii∑
=
−= 1 vážená:
∑
∑
=
=
−=
k
ii
k
iii
n
nxxd
1
1
Rozptyl
• tato charakteristika je funkcí všech pozorování, což znamená, že bere v úvahu velikost všech hodnot numerické proměnné;
• u metrických proměnných je udána ve čtvercích příslušných měrných jednotek, není proto příliš vhodná pro interpretaci;
• nabývá hodnot z intervalu )∞,0 .
prostý (klasický): ( )
n
xxs
n
ii
x
∑=
−= 1
2
2 vážený (klasický): ( )
∑
∑
=
=
−=
k
ii
k
iii
x
n
nxxs
1
1
2
2
Výpočtový tvar rozptylu
prostý: 22
2
11
2
2 xxn
x
n
x
s
n
ii
n
ii
x −=
−=∑∑
==
vážený: 22
2
1
1
1
1
2
2 xxn
nx
n
nx
sk
ii
k
iii
k
ii
k
iii
x −=
−=∑
∑
∑
∑
=
=
=
=
Směrodatná odchylka
• je definována jako kladná druhá odmocnina z rozptylu, tj. 2xx ss += ;
• udává, jak se v průměru liší jednotlivé hodnoty znaku od aritmetického průměru v obou směrech (±);
• je vhodná pro interpretaci, neboť je udána v příslušných měrných jednotkách; • nabývá hodnot z intervalu )∞,0 .
V případě, že pracujeme s výběrovým souborem, používáme výběrový rozptyl a výběrovou směrodatnou odchylku:
prostý: ( )
11
2
2
−
−=′∑
=
n
xxs
n
ii
x vážený: ( )
11
2
2
−
−=′∑
=
n
nxxs
k
iii
x
Rozklad rozptylu Skládá-li se statistický soubor z několika dílčích podsouborů, v nichž známe jednotlivé dílčí rozptyly 2
is , dílčí průměry ix a četnosti in , pak rozptyl celého souboru 2xs můžeme rozložit
na součet 2 rozptylů, z nichž jeden charakterizuje variabilitu mezi skupinami ( 2
ixs ) a druhý
variabilitu uvnitř skupin ( 2is ): 222
ixx sssi
+= .
Rozptyl skupinových průměrů: ( )
2
1
1
1
1
2
1
1
2
2
−=−
=∑
∑
∑
∑
∑
∑
=
=
=
=
=
=k
ii
k
iii
k
ii
k
iii
k
ii
k
iii
x
n
nx
n
nx
n
nxx
si
Průměr skupinových rozptylů:
∑
∑
=
==k
ii
k
iii
i
n
nss
1
1
2
2
5.3.2.2 Charakteristiky relativní variability Tyto charakteristiky jsou většinou konstruovány jako míry absolutní variability dělené nějakou střední hodnotou, nejčastěji aritmetickým průměrem nebo mediánem. Vzhledem ke své konstrukci jsou to míry bezrozměrné, pro interpretaci je lze vyjádřit v %. Variační koeficient
• je bezrozměrné číslo; • umožňuje porovnávat variabilitu souborů s různou úrovní či různými měrnými
jednotkami; • obecně nabývá hodnot z intervalu ( )∞∞− , , pro kardinální proměnné nabývá hodnot
z intervalu )∞,0 .
x
sV x
x =
5.3.2.3 Variabilita ordinální prom ěnné Pro ordinální proměnné lze použít výše uvedené míry absolutní a relativní variability, avšak vzhledem k charakteru proměnných je vypovídací schopnost těchto měr problematická a do značné míry omezená. Pro měření variability ordinálních proměnných existují speciální charakteristiky, které lépe odpovídají tomuto typu proměnných. Ordinální rozptyl (variance)
• nabývá hodnot z intervalu 1,0 ;
• hodnoty 0 nabývá v případě, kdy je zastoupena pouze jediná kategorie; • hodnoty 1 nabývá tehdy, kdy je každé z obou krajních kategorií přiřazena relativní četnost 0,5.
• udává podíl dvojic jednotek se vzájemně odlišnou variantou proměnné z celkového počtu všech možných dvojic jednotek;
• je možno ji vyjádřit v %; • nabývá hodnot z intervalu1,0 .
( )11
22
−
−=
∑=
nn
nnM
k
ii
Nominální variance
• používá se v případě, že známe pouze relativní četnosti a neznáme rozsah souboru; • skutečný stupeň variability podhodnocuje; • nabývá hodnot z intervalu )1,0 .
∑=
−=k
iip
1
21nomvar
5.3.3 Charakteristiky šikmosti
• šikmost = asymetrie; • v symetrickém rozdělení platí, že xx ~= ; počet podprůměrných hodnot je stejný jako
počet hodnot nadprůměrných; polovina malých hodnot je nahuštěna v první polovině
variačního rozpětí stejně, jako je polovina velkých hodnot nahuštěna ve druhé polovině variačního rozpětí;
• v kladně zešikmeném rozdělení obvykle platí, že xx ~> ; počet podprůměrných hodnot je větší než počet hodnot nadprůměrných; polovina malých hodnot je nahuštěnější (rozkládá se na menší části variačního rozpětí) než polovina velkých hodnot (rozkládá se na větší části variačního rozpětí);
• v záporně zešikmeném rozdělení obvykle platí, že xx ~< ; počet podprůměrných hodnot je menší než počet hodnot nadprůměrných; polovina malých hodnot se rozkládá na větší části variačního rozpětí než polovina velkých hodnot.
Míra šikmosti α
prostá: ( )
31
3
x
n
ii
ns
xx∑=
−=α vážená:
( )3
1
3
x
i
k
ii
ns
nxx∑=
−=α
Míra šikmosti α'
α ′ = n
nn ′′−′,
kde n′ je počet podprůměrných hodnot,
n ′′ je počet nadprůměrných hodnot. Interpretace charakteristik šikmosti:
• v symetrickém rozdělení jsou rovny 0; • v kladně zešikmeném rozdělení jsou větší než 0; • v záporně zešikmeném rozdělení jsou menší než 0.
5.3.4 Charakteristiky špi čatosti
• špičatost = exces; • špičatost spočívá ve větší nahuštěnosti hodnot prostřední velikosti ve srovnání se
stupněm nahuštěnosti ostatních hodnot resp. všech hodnot proměnné; • polovina prostředních hodnot je nahuštěna na značně menší části variačního rozpětí
než zbývající polovina hodnot, jinak řečeno velká špičatost znamená vysokou koncentraci hodnot v blízkosti středních hodnot;
• špičatější rozdělení má výraznější vrchol, který více vystupuje.
Míra špičatosti β
prostá: ( )
34
1
4
−−
=∑
=
x
n
ii
ns
xx
β vážená: ( )
34
1
4
−−
=∑
=
x
i
k
ii
ns
nxx
β
Interpretace charakteristik špičatosti:
• vyšší hodnota znamená větší špičatost, tzn. špičatější je to rozdělení, které máβ vyšší;
• základem pro srovnání je normované normální rozdělení, kde 0=β ;
• pokud je 0>β , rozdělení je špičatější než normované normální rozdělení;
• pokud je 0<β , rozdělení je plošší než normované normální rozdělení.
6 ZOBECNĚNÍ VÝSTUPŮ Z VÝBĚRU NA POPULACI – TEORIE ODHADU
Máme-li k dispozici výběrová data, pořízená náhodným výběrem, můžeme na jejich základě činit úsudky na obecnější skutečnosti, týkající se základního souboru. Provádíme tedy zevšeobecňující neboli induktivní úsudek. Nástrojem, který je za tímto účelem používán, jsou objektivní matematicko-statistické metody, označované rovněž jako statistická indukce. Induktivní usuzování s sebou vždy nese určité riziko nesprávného úsudku, jinak řečeno riziko omylu. V případě, že byl výběr pořízen náhodným způsobem, lze riziko omylu kvantifikovat, resp. předem volit. To umožňuje hodnotit přesnost a spolehlivost získaných výsledků. Statistická indukce zahrnuje teorii odhadu a testování statistických hypotéz. Teorie odhadu se zabývá metodami, kterými lze z napozorovaných hodnot náhodné veličiny získat co nejlepší odhady neznámých parametrů jejího rozdělení. Tyto odhady mohou být dvojího typu, a to bodové nebo intervalové.
6.1 Bodový odhad Spočívá v nahrazení neznámé hodnoty parametru základního souboru hodnotou vhodné výběrové charakteristiky, která bude sloužit jako dobrá náhrada neznámého parametru. Vhodnost odhadů přitom posuzujeme podle jejich vlastností. Vlastnosti bodového odhadu
• parametry v ZS značíme obecně Θ (konkrétně např. K,, σµ );
• výběrové charakteristiky značíme obecně t (např. K,, xsx );
• symbolický zápis bodového odhadu: test =Θ nebo t ~ Θ ;
• nahrazením skutečné hodnoty odhadem vznikne výběrová chyba Θ−t .
6.2 Intervalový odhad Spočívá v konstrukci náhodného intervalu, od něhož se zvolenou pravděpodobností
α−= 1P očekáváme, že bude obsahovat skutečnou hodnotu neznámého parametru Θ . Spolehlivost odhadu α−1
• je to pravděpodobnost, nabývá hodnot od 0 do 1; • volíme vždy číslo blízké 1, nejčastěji 0,95 (event. 0,99 nebo 0,9); • čím vyšší spolehlivost odhadu požadujeme, tím bude za jinak stejných podmínek
interval spolehlivosti (dále jen IS) širší. Riziko odhadu α
• udává, v kolika případech ze 100, tedy v jakém % případů, nebude IS pokrývat odhadovaný parametr Θ .
Intervaly spolehlivosti mohou být konstruovány dvěma způsoby: 1. oboustranné intervaly spolehlivosti
6.2.1 Odhad parametru µ (střední hodnoty) normálního rozdělení
Bodový odhad
Bodovým odhadem střední hodnoty ∑=
=N
iix
N 1
1µ je výběrový průměr ∑=
=n
iix
nx
1
1. Je to
nevychýlený odhad střední hodnoty.
Intervalový odhad Při konstrukci IS pro parametr µ rozlišujeme 3 případy: 1. Velký výběr z normálního rozdělení se známým rozptylem σ2: Oboustranný IS:
ασµσαα −=
⋅+<<⋅−
−−1
21
21 n
uxn
uxP
Pravostranný IS:
ασµ α −=
⋅+< − 11n
uxP
Levostranný IS:
αµσα −=
<⋅− − 11n
uxP
nu
σα ⋅=∆
−2
1 je přípustná chyba odhadu.
2. Velký výběr z normálního rozdělení s neznámým rozptylem σ2: Při řešení praktických úloh obvykle neznáme rozptyl ZS 2σ . Odhadujeme jej proto pomocí výběrového rozptylu 2
xs :
( )1
1
2
2
−
−=∑
=
n
xxs
n
ii
x .
Oboustranný IS:
αµ αα −=
⋅+<<⋅−
−−1
21
21 n
sux
n
suxP xx
Pravostranný IS:
αµ α −=
⋅+< − 11n
suxP x
Levostranný IS:
αµα −=
<⋅− − 11n
suxP x
3. Malý výběr z normálního rozdělení s neznámým rozptylem σ2: V případě, že rozsah výběru je malý, nahradíme kvantily normálního rozdělení ( )2;σµN
kvantily Studentova rozdělení ( )1−nt .
Oboustranný IS:
( ) ( ) αµ αα −=
⋅−+<<⋅−−
−−111
21
21 n
sntx
n
sntxP xx
Pravostranný IS:
( ) αµ α −=
⋅−+< − 111n
sntxP x
Levostranný IS:
( ) αµα −=
<⋅−− − 111n
sntxP x
6.2.2 Odhad parametru π (relativní četnosti) alternativního rozdělení Je třeba mít k dispozici výběr dostatečně velkého rozsahu; to je zajištěno splněním podmínky
( )ππ −1n >9 .
Bodový odhad
Bodovým odhadem relativní četnosti N
M=π je výběrová relativní četnost (výběrový podíl)
n
mp = .
Intervalový odhad
Oboustranný IS:
( ) ( ) απ αα −=
−⋅+<<−⋅−−−
111
21
21 n
ppup
n
ppupP
Pravostranný IS:
( ) απ α −=
−⋅+< − 11
1 n
ppupP
Levostranný IS:
( ) απα −=
<−⋅− − 1
11 n
ppupP
( )n
ppu
−⋅=∆−
1
21
α je přípustná chyba odhadu.
6.2.3 Odhad parametru σ2 (rozptylu) normálního rozdělení
Bodový odhad
Bodovým odhadem rozptylu ( )
N
xN
ii∑
=
−= 1
2
2
µσ je výběrový rozptyl
( )1
1
2
2
−
−=∑
=
n
xxs
n
ii
x . Je to
nezkreslený a konzistentní odhad.
Intervalový odhad Při konstrukci IS pro parametr 2σ rozlišujeme 2 případy - buď známe parametr µ nebo ho neznáme. V praxi je častější případ, kdy parametr µ neznáme, proto se na něj zaměříme. Oboustranný IS:
( )( )
( )( ) α
χσ
χ αα
−=
−−
<<−
−
−
11
1
1
12
2
22
2
21
2
n
sn
n
snP xx
Pravostranný IS: ( )
( ) αχ
σα
−=
−−
< 11
12
22
n
snP x
Levostranný IS: ( )
( ) ασχ α
−=
<
−−
−
11
1 221
2
n
snP x
6.2.4 Stanovení minimálního rozsahu výběru Pokud při stanovení minimálního rozsahu výběru vycházíme ze vzorce přípustné chyby odhadu parametruµ , jeho jednoduchou úpravou dostaneme :
2
22
21
∆
⋅≥
−σαu
n .
Pokud neznáme2σ , použijeme místo něj jeho bodový odhad 2xs .
Pokud neznáme π , použijeme místo něj jeho bodový odhadp .
7 ZOBECNĚNÍ VÝSTUPŮ Z VÝBĚRU NA POPULACI – TESTOVÁNÍ STATISTICKÝCH HYPOTÉZ
Testování hypotéz je postup, sloužící k ověření určitých předpokladů o základním souboru, které lze formulovat jako tzv. statistické hypotézy. Úkolem matematické statistiky je na základě výběrových dat rozhodnout, zda určitou hypotézu přijmeme nebo zamítneme. Pokud se hypotézy týkají neznámého parametru ZS a při testování vycházíme ze známého pravděpodobnostního rozdělení náhodné veličiny v ZS, jedná se o tzv. parametrické testy. Jestliže se hypotézy týkají různých vlastností ZS a test nevyžaduje znalost konkrétního rozdělení v ZS, hovoříme o testech neparametrických. Symbolika
• nulová neboli testovaná hypotéza se obecně značí 0H ;
• alternativní hypotéza se obecně značí 1H . Testové kriterium (t): vhodná statistika, která má při platnosti 0H známé pravděpodobnostní
rozdělení. Prostor hodnot testového kriteria (dále jen TK) rozdělíme na dva disjunktní obory (W a V). Kritický obor (W): je tvořen množinou hodnot TK, které jsou při platnosti 0H tak extrémní,
že pravděpodobnost jejich výskytu je velmi malá. Obor přijetí (V): je tvořen množinou všech hodnot TK, které neleží v kritickém oboru. Kritické hodnoty: oddělují obor přijetí a kritický obor; jsou to určité kvantily rozdělení testového kriteria při platnosti 0H . Pravděpodobnost chyby 1. druhu (α): je to pravděpodobnost, že zamítneme 0H , ačkoli platí.
Nazývá se hladina významnosti; Pravděpodobnost chyby 2. druhu (β): je to pravděpodobnost, že nezamítneme0H , ačkoli
neplatí. Síla testu (1- β): je pravděpodobnost správného zamítnutí0H , jinak řečeno je to schopnost
testu zamítnout neplatnou 0H .
Testovacích postupů je celá řada a různí se podle konkrétní situace, přesto je však možno shrnout obecné principy testování statistických hypotéz do několika kroků, které se provádějí vždy, bez ohledu na individuální typ testu. 1. Formulace hypotéz H0 a H1.
2. Volba testového kritéria: zvolíme vhodnou charakteristiku, jejíž rozdělení při platnosti
0H je známé.
3. Vymezení kritického oboru: je omezen kritickými hodnotami.
4. Výpočet hodnoty TK z výběrových dat.
5. Formulace závěru o výsledku testu: velmi důležité, existují dvě možnosti. • TK leží v kritickém oboru (TK Є W): pak zamítáme 0H , tzn. prokázali jsme H1.
• TK leží v oboru přijetí (TK Є V): pak nezamítáme 0H , tzn. neprokázali jsme H1.
7.1 Testy parametrů některých rozdělení náhodné veličiny 7.1.1 Test parametru µ normálního rozdělení 1. Formulace hypotéz
00 : µµ =H
01 :) µµ ≠Ha oboustranná alternativní hypotéza
01 :) µµ >Hb pravostranná alternativní hypotéza
01 :) µµ <Hc levostranná alternativní hypotéza
2. Volba testového kritéria Rozlišujeme tři případy: a) známe rozptyl ZS σ2
n
xU σ
µ0−= ( )1;0N≈
b) neznáme rozptyl ZS σ2 a výběr má malý rozsah
n
sx
t 0µ−= ( )1−≈ nt
c) neznáme rozptyl ZS σ2 a výběr má velký rozsah
n
sx
U 0µ−= ( )1;0N≈
3. Stanovení kritického oboru Pro případy a) a c) a různé typy alternativních hypotéz:
≥≤≡−
21
2
;) αα uuauuuWa
{ }α−≥≡ 1;) uuuWb
{ }αuuuWc ≤≡ ;)
Pro případ b) a různé typy alternativních hypotéz:
( ) ( )
−≥−≤≡−
11;)2
12
nttantttWa αα
( ){ }1;) 1 −≥≡ − ntttWb α
( ){ }1;) −≤≡ ntttWc α
7.1.2 Test parametru σ2 normálního rozdělení 1. Formulace hypotéz
20
20 : σσ =H
20
21 :) σσ ≠Ha
20
21 :) σσ >Hb
20
21 :) σσ <Hc
2. Volba testového kritéria Rozlišujeme dva případy: buď parametr µ známe nebo ne. V praxi převažuje případ, kdy parametr µ neznáme, proto se na něj omezíme.
( )20
22 1
σχ sn −= ≈ ( )12 −nχ
3. Stanovení kritického oboru
( ) ( )
−≥−≤≡−
11;) 2
21
22
2
22 nanWa αα χχχχχ
( ){ }1;) 21
22 −≥≡ − nWb αχχχ
( ){ }1;) 222 −≤≡ nWc αχχχ
7.1.3 Test parametru π alternativního rozdělení v případě velkých výběrů Při tomto testu je třeba mít k dispozici výběr dostatečně velkého rozsahu, což je zajištěno splněním podmínky ( )ππ −1n >9 . 1. Formulace hypotéz
00 : ππ =H
01 :) ππ ≠Ha
01 :) ππ >Hb
01 :) ππ <Hc
2. Volba testového kritéria
( )n
pU
00
0
1 πππ−
−= ( )1;0N≈
3. Stanovení kritického oboru
≥≤≡−
21
2
;) αα uuauuuWa
{ }α−≥≡ 1;) uuuWb
{ }αuuuWc ≤≡ ;)
7.1.4 Test střední hodnoty E(x) v případě velkých výběrů Tento test se používá tehdy, když náhodný výběr pochází z libovolného pravděpodobnostního rozdělení se střední hodnotou E(x) a konečným rozptylem D(x), a přitom se jedná o výběr velkého rozsahu. 1. Formulace hypotéz
( ) ( )xExEH 00 : =
( ) ( )xExEHa 01 :) ≠
( ) ( )xExEHb 01 :) >
( ) ( )xExEHc 01 :) <
2. Volba testového kritéria
( )( )n
xD
xExU 0−
= ( )1;0N≈
V praxi většinou rozptyl D(x) neznáme, a proto ho musíme nahradit vhodným konzistentním odhadem. Tím může být výběrový rozptyl 2s . 3. Stanovení kritického oboru
≥≤≡−
21
2
;) αα uuauuuWa
{ }α−≥≡ 1;) uuuWb
{ }αuuuWc ≤≡ ;)
7.2 Testy shody parametrů v několika souborech Při testování shody parametrů ve více souborech je třeba rozlišit, zda provádíme úsudky na základě závislých či nezávislých výběrů. V případě nezávislých výběrů předpokládáme, že vybírání jednotek z jednoho základního souboru nezávisí na vybírání jednotek ze souboru druhého. U výběrů závislých však výsledek z prvního výběru tvoří logický pár s výsledkem z výběru druhého, proto v této situaci někdy hovoříme o párových testech. V dalším textu se zaměříme na výběry nezávislé. 7.2.1 Test shody rozptylů dvou normálních rozdělení 1. Formulace hypotéz
22
210 : σσ =H
22
211 :) σσ ≠Ha
22
211 :) σσ >Hb
22
211 :) σσ <Hc
2. Volba testového kritéria
22
21
s
sF = ( )1;1 21 −−≈ nnF
3. Stanovení kritického oboru
( ) ( )
−−≥−−≤≡−
1;11;1;) 21
21
21
2
nnFFannFFFWa αα
( ){ }1;1;) 211 −−≥≡ − nnFFFWb α
( ){ }1;1;) 21 −−≤≡ nnFFFWc α
7.2.2 Test shody středních hodnot dvou normálních rozdělení 1. Formulace hypotéz
210 : µµ =H
211 :) µµ ≠Ha
211 :) µµ >Hb
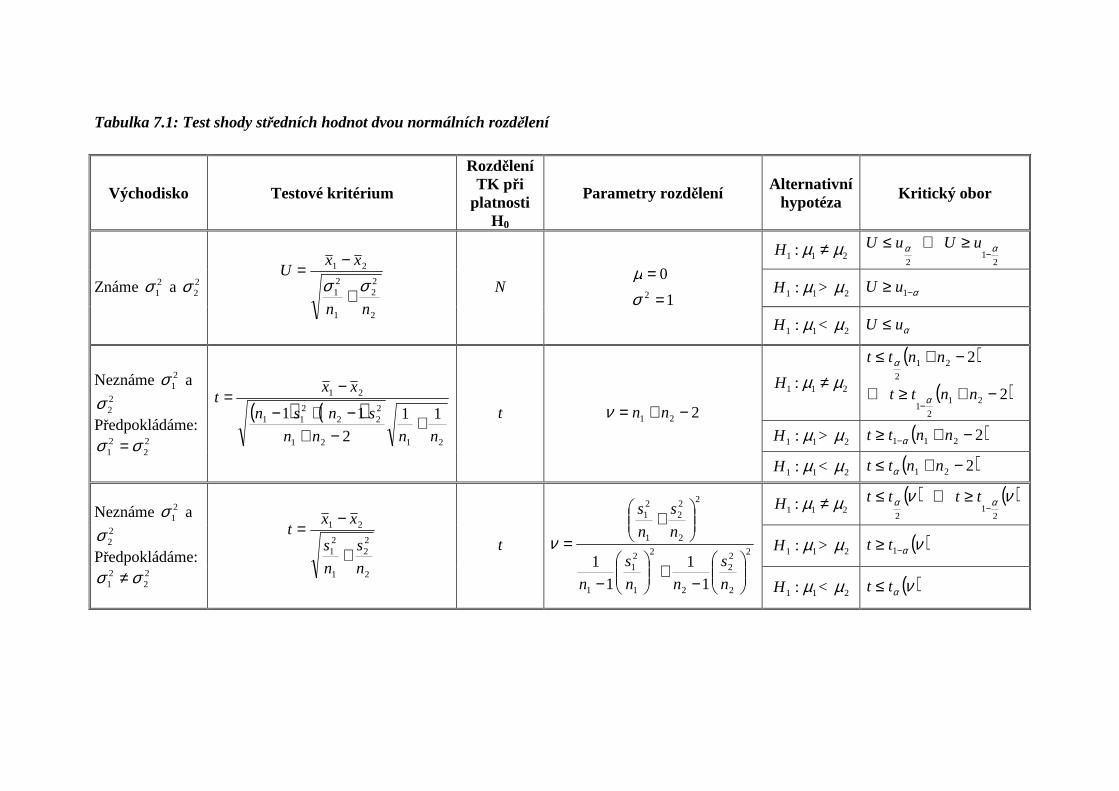
211 :) µµ <Hc Další postup, tedy volba testového kritéria a stanovení kritického oboru, závisí na rozptylech základního souboru, z něhož vybíráme. Existují tři možnosti, které jsou z důvodu přehlednosti uspořádány do tabulky 7.1.
Tabulka 7.1: Test shody středních hodnot dvou normálních rozdělení
Východisko Testové kritérium
Rozdělení TK p ři
platnosti H0
Parametry rozdělení Alternativní
hypotéza Kritický obor
211 : µµ ≠H 2
12
αα−
≥∪≤ uUuU
11 : µH > 2µ α−≥ 1uU Známe 21σ a 2
2σ
2
22
1
21
21
nn
xxU
σσ +
−= N
1
02 =
=
σµ
11 : µH < 2µ αuU ≤
211 : µµ ≠H
( )221
2
−+≤ nntt α
( )221
21
−+≥∪−
nntt α
11 : µH > 2µ ( )2211 −+≥ − nntt α
Neznáme 21σ a
22σ
Předpokládáme: 22
21 σσ =
( ) ( )2121
222
211
21
11
2
11
nnnn
snsn
xxt
+−+
−+−
−=
t 221 −+= nnν
11 : µH < 2µ ( )221 −+≤ nntt α
211 : µµ ≠H ( ) ( )νν αα2
12
−≥∪≤ tttt
11 : µH > 2µ ( )να−≥ 1tt
Neznáme 21σ a
22σ
Předpokládáme: 22
21 σσ ≠ 2
22
1
21
21
n
s
n
s
xxt
+
−=
t 2
2
22
2
2
1
21
1
2
2
22
1
21
1
1
1
1
−+
−
+
=
n
s
nn
s
n
n
s
n
s
ν
11 : µH < 2µ ( )ναtt ≤
7.3 Některé neparametrické testy
7.3.1 χ2-test dobré shody Tento test slouží k ověření shody mezi teoretickým a empirickým rozdělením a je použitelný pouze v případě velkých výběrů. Předpokladem testu je možnost roztřídit výsledky náhodného výběru jednoznačným a vyčerpávajícím způsobem do určitého počtu (k) disjunktních tříd. Požadovaný rozsah výběru: Je nutné, aby rozsah výběru zajistil dostatečné obsazení ve všech skupinách, do nichž je soubor roztříděn, tj. 5,0 >inπ pro i = 1, 2, ... , k. Někdy bývá tato
podmínka volněji formulována tak, že všech třídách musí platit 1,0 >inπ a alespoň v 80 %
tříd musí platit 5,0 >inπ . Nejsou-li výše uvedené podmínky splněny, je třeba některé třídy
sloučit (např. sousední či věcně příbuzné). Tento test se používá ve dvou situacích :
I. H0 udává proporce četností v jednotlivých skupinách (může být formulováno intuitivně).
II. H0 přepokládá, že ZS má rozdělení určitého typu: • jestliže H0 udává typ rozdělení i jeho parametry, jedná se o úplně specifikovaný model; • jestliže H0 udává pouze typ rozdělení bez specifikace parametrů, jde o neúplně
specifikovaný model. Ad I. 1. Formulace hypotéz
iiH ,00 : ππ = , pro i = 1, 2, ... , k
01 : HnonH
2. Volba testového kritéria
( )
∑=
−=
k
i i
ii
n
nnG
1 ,0
2,0
ππ
≈ ( )12 −kχ
3. Stanovení kritického oboru
( ){ }1; 21 −≥≡ − kGGW αχ
Ad II. Úplně specifikovaný model
1. Formulace hypotéz
( )2.:0 PonapřH
01 : HnonH
Další postup viz. případ I.
Neúplně specifikovaný model
1. Formulace hypotéz
( )λPonapřH .:0
01 : HnonH
2. Volba testového kritéria
( )
∑=
−=
k
i i
ii
n
nnG
1 ,0
2,0
ππ
≈ ( )12 −− pkχ
3. Stanovení kritického oboru
( ){ }1; 21 −−≥≡ − pkGGW αχ
4. Formulace závěru o výsledku testu
Pokud TK Є W, zamítáme H0, jinak řečeno přijímáme H1. V tom případě není rozdělení, specifikované nulovou hypotézou, vhodným modelem pro empirická data. Shoda teoretického a empirického rozdělení se na hladině významnosti α nepotvrdila. 7.3.2 Kolmogorovův-Smirnovův test pro jeden výběr Tento test o tvaru rozdělení lze použít i v případě, kdy máme k dispozici výběr malého či dokonce velmi malého rozsahu, takže nepřipadá v úvahu aplikace χ2-testu dobré shody. Podmínkou však je, že náhodný výběr pochází z některého spojitého rozdělení, které musí být hypotézou H0 úplně specifikované. Údaje nemusí být setříděny do skupin, test vychází z jednotlivých napozorovaných hodnot. 1. Formulace hypotéz
:0H náhodný výběr pochází z určitého rozdělení se spojitou distribuční funkcí F(x), která
je úplně specifikována 01 : HnonH
2. Volba testového kritéria
( ) ( )xFxFd nx
n −= sup
3. Stanovení kritického oboru
{ }α−≥≡ 1;; nnn dddW
4. Formulace závěru o výsledku testu
Pokud TK Є W, zamítáme H0. V tom případě není rozdělení, specifikované nulovou hypotézou, vhodným modelem pro empirická data. Shoda teoretického a empirického rozdělení se na hladině významnosti α nepotvrdila.
8 ANALÝZA ZÁVISLOSTÍ
Cílem analýzy závislostí dvou či více proměnných je hlubší proniknutí do podstaty sledovaných jevů a procesů a přiblížení k tzv. příčinným souvislostem. Tato analýza zahrnuje zkoumání charakteru závislosti proměnných, měření intenzity této závislosti atd. Používaných metod je velmi mnoho a jejich volba se odvíjí od celé řady faktorů, z nichž nejvýznamnějším je charakter zkoumaných proměnných.
8.1 Tabulka dvourozměrného rozdělení četností
• tato tabulka je elementární metodou popisu závislosti dvou proměnných; • je vhodná jak pro numerické, tak slovní proměnné; • podle charakteru proměnných rozlišujeme různé druhy tabulek, jejich obecný formát
je však jednotný. Tabulka dvourozměrného rozdělení četností
jy
ix 1y 2y . . . sy Součty četností
•in
1x 11n 12n . . . sn1 •1n
2x 21n 22n . . . sn2 •2n
. . . . . .
. . . . . .
. . . . . .
rx 1rn 2rn . . . rsn •rn
Součty četností
jn• 1•n 2•n . . . sn• n
∑=
• =s
jiji nn
1
; ∑=
• =r
iijj nn
1
nnnnr
i
s
jij
s
jj
r
ii === ∑∑∑∑
= ==•
=•
1 111
n
np i
i•
• = ; n
np j
j•
• = ; n
np ij
ij =
Druhy tabulek dvourozměrného rozdělení četností Korelační tabulka: obě proměnné jsou numerické.
Kontingenční tabulka: alespoň jedna z proměnných je slovní.
Asociační tabulka: obě proměnné jsou alternativní.
Čtyřpolní tabulka: obě proměnné nabývají pouze dvou obměn.
Podmíněné rozdělení četností • je to rozdělení četností jedné proměnné, odpovídající určité obměně druhé proměnné; • jinak řečeno, jde o rozdělení četností jedné z proměnných za podmínky, že druhá
proměnná nabyla určité obměny; • v takovémto rozdělení stanovujeme podmíněné charakteristiky proměnných; • lze přitom stanovit, jak podmíněné charakteristiky proměnné y vzhledem k proměnné
x, tak podmíněné charakteristiky proměnné x vzhledem k proměnné y.
Podmíněné relativní četnosti: •
=i
ijij n
np / ;
j
ijji n
np
•
=/
Podmíněný průměr: •
=
•
=∑∑
==i
s
jij
i
s
jijj
i n
y
n
ny
y 11
Podmíněný rozptyl:
( ) ( )•
=
•
=∑∑ −
=−
=i
s
jiij
i
s
jijij
yi n
yy
n
nyy
s 1
2
1
2
2
8.2 Grafické znázornění dvourozměrného rozdělení četností Grafy jsou další formou popisu závislosti dvou proměnných. Existuje celá řada různých druhů grafů, je však třeba vždy vybrat takový, který co nelépe odpovídá charakteru zobrazovaných dat. Ke grafům, často používaným v analýze závislostí, patří např. následující: Čára podmíněných průměrů
• spojnicový graf; • znázorňuje průběh podmíněných průměrů.
Čára podmíněných rozptylů
• spojnicový graf; • znázorňuje průběh podmíněných rozptylů.
Bodový graf (diagram)
• je grafickým vyjádřením dvourozměrného rozdělení četností; • jako grafické prostředky používá body, umisťované v souřadnicové soustavě; • slouží ke znázornění závislosti mezi dvěma kvantitativními znaky.
8.3 Analýza rozptylu Jednou z metod zkoumání závislosti dvou proměnných je statistický test, zvaný analýza rozptylu. Pomocí tohoto testu zjišťujeme, zda změny hodnot proměnné y lze vysvětlit změnami proměnné x, která bývá také označována jako faktor x. V případě, že zkoumáme závislost y pouze na jednom faktoru x, jedná se o tzv. jednofaktorovou analýzu rozptylu. Základním předpokladem aplikace této metody je, že závislá proměnná y je vždy numerická,
zatímco faktor x může být jak numerický, tak slovní. Při testu je využíván postup, označovaný jako rozklad rozptylu. 8.3.1 Rozklad rozptylu
Tato metoda spočívá v rozkladu celkového rozptylu (2ys ) závisle proměnné y na dvě části, a to
rozptyl podmíněných průměrů ( 2.mys ) a průměr podmíněných rozptylů ( 2
.vys ).
2.
2.
2vymyy sss +=
Celkový rozptyl ( 2ys )
( )n
S
n
yy
s y
k
i
n
jij
y
i
=−
=∑∑
= =1 1
2
2 ; kde n
y
y
k
i
n
jij
i
∑∑= == 1 1
Rozptyl podmíněných průměrů ( 2.mys )
• označuje se jako meziskupinový rozptyl; • odráží variabilitu mezi jednotlivými skupinami; • kolísání podmíněných průměrů je důsledkem závislosti proměnné y na faktoru x; • meziskupinová variabilita je část celkové variability, která je vysvětlitelná faktorem x.
( )n
S
n
nyys my
k
iii
my.1
2
2. =
−=∑
=
Průměr podmíněných rozptylů ( 2.vys )
• označuje se jako vnitroskupinový rozptyl ; • odráží variabilitu uvnitř skupin; • kolísání je důsledkem závislosti proměnné y na jiných faktorech než na x.
n
S
n
nss vy
k
iii
vy.1
2
2. ==∑
=
Vzhledem k tomu, že platí vztah 2.
2.
2vymyy sss += , platí také, že vymyy SSS .. += . Za účelem
zjednodušení lze tedy používat pouze čitatele vzorců, které označujeme jako součty čtverců. 8.3.2 Předpoklady testu
• máme základní soubor s normálním rozdělením ( )2;σµN ;
• ze základního souboru je pořízeno k nezávislých náhodných výběrů; • každý z výběrů má normální rozdělení s neznámou střední hodnotou kµµµ ,,, 21 K a
s neznámým rozptylem 222
21 ,,, kσσσ K ;
• rozptyly všech skupin jsou stejné, tj. 222
21 kσσσ === K (tzv. homoskedasticita);
• počet pozorování musí být vždy větší než počet skupin, tj. n > k.
8.3.3 Postup testu 4. Formulace hypotéz
kH µµµ === K210 :
01 : HnonH
5. Volba testového kritéria
kn
Sk
S
Fvy
my
−
−=.
.
1 ( )knkF −−≈ ;1
6. Stanovení kritického oboru
( ){ }knkFFFW −−≥≡ − ;1; 1 α
4. Formulace závěru o výsledku testu
Pokud TK Є W, zamítáme H0 a přijímáme H1. Znamená to, že na zvolené hladině významnosti se podařilo prokázat, že existuje závislost proměnné y na faktoru x.
8.3.4 Měření intenzity závislosti proměnné y na faktoru x
Poměr determinace: y
my
S
SP .2 = ; 1;02 ∈P
Poměr korelace: 2PP = ; 1;0∈P
8.4 χ2 – test o nezávislosti v kontingenční tabulce Pro aplikaci této metody je třeba, aby data byla uspořádána do kontingenční tabulky. Podstatou testu je porovnání empirických četností ( ijn ) s teoretickými četnostmi ( ijn′ ), tedy
takovými, které jsou očekávány v případě nezávislosti obou proměnných. Výpočet teoretických četností
n
nnn ji
ij•• ⋅
=′
8.4.1 Předpoklady testu
• všechna políčka kontingenční tabulky musí být dostatečně obsazena ( 5≥′ijn );
• pokud podmínka obsazenosti políček není splněna, musíme některé třídy sloučit nebo zvětšit rozsah výběru.
8.4.2 Postup testu 1. Formulace hypotéz
:0H proměnné a a b jsou nezávislé
01 : HnonH
2. Volba testového kritéria
( )
∑∑= = ′
′−=
r
i
s
j ij
ijij
n
nnG
1 1
2
( )( )[ ]11 −−≈ srG
3. Stanovení kritického oboru
( )( )[ ]{ }11; 21 −−>≡ − srGGW αχ
4. Formulace závěru o výsledku testu
Pokud TK Є W, zamítáme H0 a přijímáme H1. Znamená to, že na zvolené hladině významnosti se podařilo prokázat existenci závislosti proměnných a a b. 8.4.3 Měření intenzity závislosti proměnných v kontingenční tabulce
Cramérův koeficient kontingence: hn
GCCr ⋅
= ; 1,0∈CrC , h = min (r-1; s-1)
Pearsonův koeficient kontingence: nG
GCP +
= ; )1,0∈PC
8.5 Regresní a korelační analýza
Do regresní a korelační analýzy patří celá řada metod a postupů, vhodných ke zkoumání závislosti numerických proměnných. Tyto metody se jak z výpočetních, tak interpretačních hledisek často prolínají, a proto je někdy obtížné mezi nimi stanovit přesnou hranici. Regresní analýza
• zabývá se především zkoumáním jednostranné závislosti proměnné y (závislá, vysvětlovaná proměnná) na proměnné x, resp. proměnných mxxx ,,, 21 K (nezávislé,
vysvětlující proměnné); • nezávislá proměnná vystupuje ve vztahu obou proměnných jako příčina, závislá
proměnná jako důsledek; • při zkoumání metodami regresní analýzy je důležitý zejména směr závislosti, tedy
která proměnná je závislá, a která nezávislá; • závislost většinou modelujeme nějakou matematickou funkcí, která bývá označována
jako regresní funkce.
Korelační analýza
• zabývá se zejména intenzitou vzájemného vztahu proměnných, na kterou je kladen větší důraz než na směr závislosti;
• jedná se o základní metodu posuzování lineární závislosti proměnných; • výraz „correlatió“ pochází z latiny, znamená vzájemnou souvislost.
8.5.1 Regresní modely Jsou to matematické modely, které vyjadřují představu o průběhu závislosti numerických proměnných. Na jejich základě je možno stanovit odhady neznámých hodnot závisle proměnné y ze známých hodnot nezávisle proměnné x, resp. proměnných mxxx ,,, 21 K .
• aditivní (součtový) – jeho složky se skládají sčítáním, je nejčastější; • multiplikativní (součinový) – jeho složky se skládají násobením.
Tyto dva typy modelů lze rovněž různě kombinovat, vzniklé modely však bývají poměrně komplikované, což negativně ovlivňuje zejména interpretaci výsledků analýzy. Teoretická (hypotetická) regresní funkce: ( )xηη =
• existují různé typy regresních funkcí, nejčastější jsou lineární regresní funkce; • linearita se může hodnotit jak z hlediska proměnných, tak z hlediska parametrů.
Parametry regresní funkce
• neznámé konstanty, symbolicky je značíme řeckými písmeny( )mβββ ,,, 10 K ;
• jejich hodnoty lze odhadnout z výběrových dat; • je třeba zvolit takovou metodu, aby odhady měly co nejlepší vlastnosti.
1. Funkce lineární z hlediska parametrů
přímka x10 ββη +=
rovina 22110 xx βββη ++=
nadrovina mmxxx ββββη ++++= K22110
parabola 2210 xx βββη ++=
hyperbola 110
−+= xββη
logaritmická funkce xln10 ββη +=
polynom mmxxx ββββη ++++= K
2210
2. Funkce nelineární z hlediska parametrů
exponenciální funkce x10ββη =
mocninná funkce 10
ββη x=
Tőrnquistova funkce 1
0
ββη+
=x
x
8.5.2 Jednoduchá lineární regrese O jednoduché lineární regresi hovoříme v případě, kdy je regresní funkce lineární z hlediska parametrů a má pouze jednu vysvětlující proměnnou x, označovanou též jako regresor. Teoretická (hypotetická) regresní funkce: x10 ββη +=
• parametry této funkce je třeba odhadnout pomocí vhodné metody; • nejčastěji provádíme odhad metodou nejmenších čtverců; • odhadneme-li parametry teoretické regresní funkce, získáme tzv. výběrovou regresní
1. 0== xyyx bb ⇒ x a y jsou korelačně nezávislé; sdružené regresní přímky svírají pravý úhel.
2. xy
yx bb
1= ⇒ x a y jsou perfektně závislé; sdružené regresní přímky svírají nulový úhel.
8.5.3 Míry intenzity lineární závislosti Tyto charakteristiky měří intenzitu lineární závislosti neboli korelovanosti, nikoli sílu závislosti obecně. Jedná se o symetrické míry.
Koeficient determinace: 22
2
2222
yx
xy
y
xy
x
xyxyyxxyyx
ss
s
s
s
s
sbbrr
⋅=⋅=⋅== ; 1;02 ∈xyr
Koeficient korelace: ( ) ( )2222
2
yyxx
yxxy
ss
srrr
yx
xyyxxyyx
−⋅−
⋅−=⋅
=== ; 1;1−∈xyr
Pro měření korelace pořadí je vhodné použít Spearmanův koeficient, který je variantou korelačního koeficientu a měří intenzitu lineární závislosti dvou pořadí. Interpretace i test jsou zcela stejné, jako u korelačního koeficientu.
Spearmanův koeficient pořadové korelace: ( )
( )1
61
21
2
−
−−=∑
=
nn
bar
n
iii
s ; 1;1−∈sr
Interpretace 1. znaménko +/– udává směr závislosti:
xyr >0 ⇒ přímá závislost
xyr < 0 ⇒ nepřímá závislost
2. xyr udává sílu závislosti:
0=xyr ⇒ lineární nezávislost
1=xyr ⇒ funkční (perfektní) závislost
0→xyr ⇒ slabá lineární závislost
1→xyr ⇒ silná lineární závislost
Test hypotézy o nulové hodnotě korelačního koeficientu 1. Formulace hypotéz
0:0 =yxH ρ
01 : HnonH
2. Volba testového kritéria
21
2
yx
yx
r
nrt
−
−⋅= ( )2−≈ nt
3. Stanovení kritického oboru
( ) ( )
−≥∪−≤≡−
22;2
12
nttntttW αα
4. Formulace závěru o výsledku testu
Pokud TK Є W, zamítáme H0 a přijímáme H1. Znamená to, že na zvolené hladině významnosti se podařilo prokázat, že existuje lineární závislost proměnných x a y.
8.5.4 Další míry intenzity závislosti Tyto charakteristiky měří sílu závislosti obecně, nezávisle na typu regresní funkce. Proto je lze použít i pro měření nelineární závislosti. Na rozdíl od měr lineární závislosti nejsou symetrické.
Index determinace: y
T
S
SI =2 ; 1;02 ∈I
Pokud porovnáváme funkce s různým počtem parametrů, je třeba hodnotu 2I vhodným způsobem upravit (penalizovat), protože u funkcí s větším počtem parametrů vychází 2I automaticky vyšší. Existují různé formy penalizace, např.:
( ) ( )( ) y
Radj Spn
Sn
pn
nII
−−
−=−−⋅−−=
11
111 22 .
Index korelace: 2II ±= ; 1;1−∈I
Rozklad celkového součtu čtverců: RTy SSS +=
KyS celkový součet čtverců;
KTS teoretický součet čtverců; část variability, kterou lze vysvětlit zvolenou regresní funkcí
KRS reziduální součet čtverců; část variability, kterou nelze zvolenou regresní funkcí vysvětlit.
( )∑=
−=n
iiy yyS
1
2
( )∑=
−=n
iiT yYS
1
2 ; ( )∑=
−=n
iiiR YyS
1
2 .
CCeellkkoovvýý FF –– tteesstt
• pomocí tohoto testu ověřujeme vhodnost zvoleného modelu jako celku; • je založený na analýze rozptylu.
1. Formulace hypotéz
0......,,,,: 2100 == mcH ββββ (tj. regresní funkce není vhodná k vystižení závislosti y
na x) 01 : HnonH
2. Volba testového kritéria
pnS
pSF
R
T
−−
=1
( )pnpF −−≈ ;1
3. Stanovení kritického oboru
( ){ }pnpFFFW −−>≡ − ;1; 1 α
4. Formulace závěru o výsledku testu
Pokud TK Є W, zamítáme H0 a přijímáme H1. Znamená to, že na zvolené hladině významnosti se podařilo prokázat, že zvolená regresní funkce je vhodným modelem.
DDííllččíí tt –– tteessttyy
• pomocí těchto testů ověřujeme vhodnost jednotlivých parametrů modelu; • jsou to dílčí testy o nulových hodnotách parametrů.
1. Formulace hypotéz
mhH h ,,2,1,0:0 K==β (tj. parametr není ve funkci přínosný)
01 : HnonH
2. Volba testového kritéria
( )h
hh bs
bt = , mh ,,2,1 K= ; ht ( )pnt −≈
3. Stanovení kritického oboru
( ) ( )
−≥∪−≤≡−
pnttpntttW hhh
21
2
; αα
4. Formulace závěru o výsledku testu
Pokud TK Є W, zamítáme H0 a přijímáme H1. Znamená to, že na zvolené hladině významnosti se podařilo prokázat, že testovaný parametr je v regresní funkci přínosný. 8.5.5 Nelineární regrese Pokud není regresní funkce lineární v parametrech, hovoříme o nelineární regresi. V takovém případě nelze parametry funkce odhadnout metodou nejmenších čtverců a je třeba použít jiných postupů, např. metodu linearizující transformace, metodu částečných součtů atd.
Následně se pak většinou aplikují další metody pro zlepšení vlastností odhadů. Tyto procesy mohou být výpočetně značně náročné a využívá se k nim proto statistický software. 8.5.6 Vícenásobná lineární regrese Vícenásobná regrese se zabývá analýzou závislosti proměnné y na dvou či více vysvětlujících proměnných (regresorech) mxxx ,,, 21 K . Volba vhodného typu regresní funkce je většinou
obtížná, doporučuje se použití statistických programů. Přednost dáváme co nejjednodušším regresním modelům, nejčastěji proto volíme lineární vícenásobnou regresní funkci. Teoretická vícenásobná lineární regresní funkce: mmxxx ββββη +++= K22110
8.5.7 Volba vhodného typu regresní funkce Při volbě vhodného regresního modelu je možno uplatnit celou řadu různých kriterií, která lze vzájemně kombinovat.
• v prvé řadě by se volba měla opírat o určitou teorii, jinak řečeno by měla vyplývat z věcného rozboru vztahů mezi zkoumanými proměnnými;
• velmi důležitá je snaha o co největší jednoduchost modelu, a to především kvůli možnostem interpretace získaných výsledků;
• nedílnou součástí volby modelu jsou statistické testy, a to jak test celkové vhodnosti modelu, tak i testy jednotlivých parametrů;
• v případě, že testy hovoří proti použití daného modelu, není vhodné ho dále uvažovat; • ke změření přilnavosti zvolené regresní funkce k empirickým údajům je třeba použít
vhodné kritérium. Některá kritéria posouzení kvality regresní funkce: 1. Index determinace
( ) ( )( ) y
Radj Spn
Sn
pn
nII
−−
−=−−⋅−−=
11
111 22
Pozn.: adjusted = upravený.
• za vhodnější je považována ta regresní funkce, která má hodnota I2 vyšší; • při srovnávání funkcí s rozdílným počtem parametrů musíme hodnotu I2 upravit
(penalizovat), neboť u funkce s vyšším počtem parametrů vychází hodnota I2 automaticky vyšší. Existují různé formy penalizace, např.:
2. Reziduální součet čtverců a reziduální rozptyl
( )∑=
−=n
iiiR YyS
1
2
• za vhodnější považujeme funkci, která má reziduální součet čtverců nižší; • reziduální součet čtverců lze použít pouze tehdy, když srovnáváme funkce se stejným
počtem parametrů.
pn
SS R
R −=2
• za vhodnější považujeme funkci, která má reziduální rozptyl nižší; • reziduální rozptyl můžeme použít i v případě, že srovnávané regresní funkce mají
různý počet parametrů. 3. Testové kritérium F
pnS
pSF
R
T
−−
=1
• za vhodnější je považována ta funkce, u níž je hodnota F vyšší; • lze ho použít i pro srovnání regresních funkcí s různým počtem parametrů.
9 FAKTOROVÁ ANALÝZA Tato vícerozměrná statistická metoda vznikla v psychologii, je však využívána rovněž v sociologii, marketingu a mnoha dalších oblastech. Hlavním cílem faktorové analýzy (dále jen FA) je rozbor struktury vzájemných vztahů mezi zkoumanými proměnnými. Vychází se přitom z předpokladu, že závislosti mezi sledovanými proměnnými jsou důsledkem působení jistého menšího počtu latentních nezměřitelných veličin, které jsou označovány jako společné faktory. Jedná se v podstatě o skryté příčiny vzájemně korelovaných proměnných. Povaha faktorové analýzy je spíše heuristická a průzkumná než ověřovací, takže předpokladem jejího úspěšného použití jsou nejen značné předmětné znalosti zkoumané oblasti, ale rovněž respektování předpokladů metody. Hlavní cíle faktorové analýzy
• smyslem této metody je celkové zjednodušení statistických analýz prostřednictvím redukce dat, a to při co nejmenší ztrátě informace;
• cílem FA je vytvořit nové proměnné, označované jako společné faktory, které jsou hypotetické, v praxi přímo neměřitelné a umožňují lépe pochopit analyzovaná data;
• FA popisuje každou pozorovanou proměnnou jako kombinaci vlivů jednotlivých faktorů, které jsou definovány jako lineární kombinace původních proměnných;
• FA se snaží odvodit, vytvořit a pochopit společné faktory tak, aby co nejlépe a nejjednodušeji vysvětlovaly pozorované závislosti;
• pomocí faktorů je vysvětlen celkový rozptyl pozorovaných proměnných; • v konečném řešení by každá ze zkoumaných proměnných měla korelovat s co
nejmenším možným počtem faktorů; • počet použitých faktorů může být různý, čím více faktorů se vypočítá, tím větší
procento rozptylu proměnných je vysvětleno; • na druhou stranu je však třeba nalézt co nejmenší přijatelný počet faktorů, tak aby
došlo k co největšímu zjednodušení složité reality; • vytvořené faktory je případně možno využít v dalších analýzách.
Uplatnění faktorové analýzy
• metoda má široké uplatnění v mnoha různých oborech; • v psychologii se využívá pro přípravu a vyhodnocování testů inteligence, schopností či
znalostí; • při analýze dat z velkých databází (např. databáze bank či mobilních operátorů) ji lze
využít k redukci informace a snížení dimenze zkoumaného problému; • v marketingovém průzkumu se používá při analýze nákupních košíků, či pro tvorbu
percepčních map výrobků nebo značek. Nedostatky faktorové analýzy
• nebezpečí klamných výsledků při rutinním použití FA; • nejednoznačnost řešení, přesněji řečeno odhadu faktorových parametrů; • přílišná subjektivita při některých krocích; • často nejasná interpretace a přibližnost výsledků.
9.1 Matematický model faktorové analýzy Model faktorové analýzy vyjadřuje vztah vektoru měřených (tzv. manifestních) proměnných Y = ( )MYY ,,1 K a jedné či více neměřitelných (latentních) proměnných F = ( )KFF ,,1 K . Modelové rovnice vyjadřující vztah mezi faktory a zjišťovanými proměnnými:
kF K neměřené (neznámé, latentní) příčiny, tzv. faktory;
mka K převodní koeficienty kF na mY , tzv. faktorové zátěže (faktorové koeficienty);
mε K chyba rovnice (reziduum modelu);
M je počet proměnných, K je počet faktorů, MK ≤ . Rovnice modelu platí pro každé jednotlivé pozorování a vysvětlují zjištěné hodnoty Y u každé jednotky (respondenta) pomocí faktorů F.
• faktory jsou proměnné, jejichž existenci předpokládáme a chceme je matematicky určit, identifikovat jejich význam a případně také odhadnout jejich hodnotu pro každou jednotku;
• koeficienty mka jsou neznámé parametry modelu, které je třeba vhodným způsobem
odhadnout; jsou to vlastně korelační koeficienty mezi faktorem a proměnnou a slouží jako základ pro interpretaci získaných faktorů;
• chyba mε je ta část empirických dat Y, kterou nelze vysvětli pomocí faktorů F,
předpokládáme však o ní, že je na faktorech nezávislá a její průměr je nula; • celková variabilita položky mY se rozkládá na dvě části, a to část vysvětlenou pomocí
faktorů F a část odpovídající mε ;
• podíl části vysvětlené pomocí faktorů F na rozptylu mY se nazývá komunalita.
Předpoklady o datech (vstupních proměnných)
• data musí být vždy číselná, aby mělo smysl pro ně počítat koeficient korelace; • pozorování by měla být vzájemně nezávislá; • počet pozorování by měl být dostatečně velký (alespoň pětkrát větší než je počet
proměnných); • v případě existence chybějících dat lze použít buď vynechání (metodou listwise či
pairwise) nebo některou z metod jejich nahrazení.
9.2 Základní úkoly a otázky faktorové analýzy Zásadním úkolem FA je správně identifikovat společné faktory, odhadnout jejich vlivy na manifestní proměnné, charakterizovat roli jednotlivých faktorů a odhadnout jejich hodnoty. Předpoklady pro určení faktorů
• všechny faktory kF musí být standardizované (normované), což znamená, že jejich
průměr je nula a rozptyl jedna; • faktory kF by měly být vzájemně nekorelované, což je výhodné i pro další metody
(např. shlukovou analýzu). Stanovení počtu faktor ů
• stanovení optimálního počtu faktorů je jednou z významných otázek FA, do značné míry jde o subjektivní záležitost;
• odhad počtu faktorů se většinou provádí pomocí standardně používaných pravidel, např. podle Kaiserova pravidla (je nejběžnější), podle procenta vysvětlené variability, podle interpretační smysluplnosti a využitelnosti atd.;
• počet faktorů lze rovněž pevně stanovit a priori. Metody a postup extrakce faktorů
• existuje řada různých metod, např. metoda hlavních komponent, metoda minimalizace korelačních reziduí, metoda maximální věrohodnosti atd.;
• nejčastěji je používána metoda hlavních komponent, která je založena na maximalizaci komunalit faktoru u všech proměnných;
• nejprve je extrahován první hlavní faktor 1F , a to tak, aby vysvětloval maximum celkové variability proměnné Y, jinak řečeno aby byl co nejsilnější;
• druhý faktor 2F je na prvním faktoru nezávislý a je stanoven tak, aby vysvětloval maximum variability nevysvětlené prvním faktorem;
• postup lze opakovat až do vyčerpání variability Y. Interpretace faktorů
• význam jednotlivých faktorů a jejich interpretaci odvozujeme podle faktorových zátěží, tedy koeficientů mka ;
• existují různá zvyková pravidla pro interpretaci, nemají však dogmatický charakter; • příklad zvykového pravidla: minimální hodnota koeficientu je 0,3; koeficienty 0,3 až
0,4 jsou slabě důležité; koeficienty nad 0,5 jsou prakticky důležité; • lze rovněž stanovit pásma: 0,3 až 0,5; 0,5 až 0,7; 0,7 až 0,9; více než 0,9 (odpovídá
10 %, 25 %, 50 % a 80 % determinace); • v analytickém kontextu nebývá interpretace faktorů jednoznačná, jde především o
nalezení vhodného pojmenování nové proměnné, které nejlépe reprezentuje nový pojem.
Rotace faktorů
• získané faktory lze z geometrického hlediska chápat jako souřadnou soustavu určitého prostoru, do kterého jsou pozorování promítnuta;
• z hlediska interpretace a využití modelu však nemusí být tato volba souřadnic tou nejvhodnější, proto jsou hledána další řešení, která by byla lepší;
• k tomuto účelu slouží postup označovaný jako rotace, založený na takové ortogonální transformaci, která vede k co nejjednodušší a nejvíce smysluplné interpretaci;
• existuje celá řada metod rotace faktorů k jednoduché struktuře; • velmi často je používána metoda VARIMAX, která zachovává nekorelovanost
rotovaných faktorů; z dalších metod lze jmenovat např. QUATRIMAX či EQUAMAX.
Grafické zobrazení
• faktory je možno interpretovat jako osy ortogonálního prostoru, do kterého se původně n-rozměrné proměnné projektují;
• proměnné Y lze tudíž vyjádřit jako body v prostoru faktorů (např. pro dva faktory je to rovina).
Výpočet faktorů
• provádíme tzv. skórování latentních vlastností, které spočívá v odhadech faktorů z hodnot jednotlivých proměnných;
• umožňuje umístění každého jednotlivého respondenta vzhledem k ostatním; • odhadové rovnice jsou inverzní k původním modelovým rovnicím.
Odhadové rovnice:
MM YbYbYbF 12121111 +++= K
MM YbYbYbF 22221212 +++= K
M
MKMKKK YbYbYbF +++= K2211
9.3 Praktická aplikace faktorové analýzy Vzhledem k poměrně značné výpočetní náročnosti FA je nezbytné použít vhodný statistický software, který provede potřebné výpočty (např. SPSS, STATGRAPHICS, STATISTICA apod.). Jednotlivé statistické pakety se pochopitelně mohou lišit v použití některých dílčích postupů a metod, v zásadě je však obecný postup velmi podobný. Procedury poskytují velké množství výstupních tabulek a grafů, které však bez znalosti teoretického základu FA není možno správně interpretovat. Shrnutí obecného postupu faktorové analýzy
• výchozím krokem je vždy analýza čtvercové korelační matice vstupních proměnných, která zahrnuje mimo jiné výpočet koeficientů korelační matice, testy jejich nulové hodnoty a další kritéria a testy (např. Kaiser-Meyer-Olkinovo kritérium, Bartlettův test apod.);
• následujícím krokem je extrakce faktorů, a proto je nutno specifikovat metodu jejich výpočtu a kritérium pro určení počtu faktorů;
• proces pokračuje rotací faktorů, jejíž metodu je rovněž třeba vhodně zvolit; • následuje odhad faktorových skórů a jejich analýza; • vhodným doplněním metody je grafické zobrazení.
Výstupy faktorové analýzy
• FA poskytuje celou řadu různých výstupů, a to jak ve formě tabulek, tak grafů; • proto je vždy nutno specifikovat, jaké konkrétní výstupy požadujeme, což
předpokládá dobrou orientaci v používaných metodách a postupech; • interpretace výsledků zahrnuje určitý prvek subjektivity, vyplývající ze samotné
podstaty této metody; • není možno přistupovat k provádění FA rutinním způsobem, základem pro správné
používání této metody je dobrá předmětná znalost zkoumané problematiky.
10 SHLUKOVÁ ANALÝZA Tato vícerozměrná statistická metoda zahrnuje řadu různých postupů, jejichž hlavním cílem je roztřídit množinu zkoumaných objektů do určitého množství co nejvíce stejnorodých skupin, označovaných jako shluky. Uplatnění shlukové analýzy je vhodné především tehdy, kdy objekty mají přirozenou tendenci k seskupování, jinak řečeno tam, kde se množina objektů reálně rozpadá do určitých tříd. Vzniklé třídy je pak třeba správně charakterizovat, tedy nalézt vhodnou interpretaci provedeného rozkladu. Hlavní cíle shlukové analýzy
• základním cílem shlukové analýzy je vytvořit kompaktní, dobře separované shluky; • počet shluků k obvykle není známý, většinou je třeba jeho optimální hodnotu stanovit; • shlukovat lze nejenom objekty, ale také proměnné; • v takovém případě hledáme skupiny proměnných, jejichž hodnoty jsou si určitým
způsobem podobné; tyto skupiny je pak možno zastoupit jedinou proměnnou, což vede ke snížení rozměru řešené úlohy;
• důležité je přitom správně specifikovat pojem podobnost, který se v konkrétních případech vztahuje pouze k p proměnným zahrnutým do zkoumání;
• shluková analýza se snaží za použití vhodných algoritmů odhalit strukturu datového souboru a klasifikovat jednotlivé proměnné;
• další možností využití shlukové analýzy je zjišťování podobností kategorií nominální proměnné na základě dvourozměrné tabulky rozdělení četností, jehož lze využít pro slučování kategorií v kontingenční tabulce;
• shluková analýza také slouží jako pomocný postup pro výběr objektů při analýze velkých datových souborů; pokud je vytvořen potřebný počet shluků objektů, lze analyzovat jenom data zjištěná u zástupců těchto shluků.
Principy shlukové analýzy
• při provádění shlukové analýzy uvažujeme různé rozklady množiny n objektů do k shluků;
• hledáme přitom takový rozklad, který je z určitého hlediska nejvýhodnější; • dále budeme připouštět pouze rozklady s disjunktním shluky, z obecného hlediska je
však možno uvažovat i překrývající se shluky; • hlavním úkolem je dosažení takového stavu, kdy objekty uvnitř shluku jsou si
podobné co nejvíce, zatímco objekty z různých shluků co nejméně; • každý ze shluků následně zastoupíme jedinou proměnnou, čímž se sníží rozměr úlohy; • výběr množiny proměnných je velmi významný a pro úspěch celé analýzy je zcela
zásadní.
Klasifikace postupů shlukové analýzy
• postupy shlukové analýzy lze klasifikovat z mnoha hledisek; • především se jedná o úlohy se zadaným počtem shluků a úlohy, v nichž je určení
vhodného počtu shluků součástí celého procesu; • v případě, kdy není třeba omezovat objem výpočtů, lze vyhodnotit všechny reálné
možnosti volby počtu shluků;
• dále lze aplikovat algoritmy hierarchického shlukování, tedy sestavit hierarchickou posloupnost rozkladů tak, že každý následující rozklad je zjemněním rozkladu předchozího;
• dalším možným hlediskem je způsob posuzování podobnosti, a to za pomoci různých speciálních měr.
10.1 Kritéria pro posouzení kvality rozkladu Velmi závažným problémem je posouzení toho, jak bylo v dané situaci použití konkrétního algoritmu úspěšné, jinak řečeno do jaké míry se podařilo dosáhnout cíle shlukové analýzy.
• k posouzení kvality provedeného rozkladu existuje několik kritérií, tzv. funkcionálů kvality rozkladu;
• v nejčastěji používaných kritériích vystupují matice vnitroshlukové a mezishlukové variability, které dávají v součtu matici celkové variability;
• velmi známé je Wardovo kritérium, které je založeno na minimalizaci celkového součtu čtverců odchylek všech hodnot od příslušných shlukových průměrů;
• v případě, že chceme dosáhnout nezávislosti na použitých měřicích jednotkách, lze použít např. minimalizaci determinantu matice vnitroshlukové variability;
• výše uvedená i další existující kritéria jsou používána nejen k vyhodnocení kvality provedeného rozkladu, ale změny jejich hodnot mohou být rovněž použity jako vodítku pro tvorbu shluků.
10.2 Míry vzdálenosti a podobnosti Jakmile provedeme výběr proměnných, které budou charakterizovat vlastnosti shlukovaných objektů, a zjistíme jejich hodnoty, je třeba se rozhodnout ohledně způsobu hodnocení podobnosti objektů, resp. jejich vzdálenosti.
• pro měření vzdálenosti objektů, které jsou charakterizovány hodnotami kvantitativních proměnných, lze použít např. Hemmingovu vzdálenost (tzv. Manhattan či city-block), euklidovskou vzdálenost nebo Čebyševovu vzdálenost;
• všechny jmenované míry mají stejné nevýhody; jednak je to závislost na použitých měřicích jednotkách, jednak nepřiměřeně velký vliv na výsledek v případě silně korelovaných proměnných;
• uvedené nedostatky je možno odstranit transformací proměnných, jinak řečeno jejich normováním; je však třeba vzít na vědomí, že normování potlačuje vliv rozdílů ve variabilitě proměnných na výsledky;
• problémem při řešení reálných situací jsou často chybějící údaje, s nimiž lze pracovat buď pomocí standardních postupů (např. vynechání řádku či odhad chybějící hodnoty) nebo za použití speciálního postupu pro výpočet vzdálenosti mezi objekty;
• při shlukování proměnných se podobnost nejčastěji měří pomocí výběrového korelačního koeficientu, v některých situacích se také používá tzv. kosinová míra, což je speciální případ výběrového korelačního koeficientu, kdy výběrové průměry obou sledovaných proměnných jsou rovny nule.
10.3 Optimalizační algoritmy Podstatou shlukové analýzy je vytvoření dobře separovaných kompaktních shluků. Cílem optimalizačních algoritmů je tedy najít takový rozklad, který bychom považovali za optimální. Za tímto účelem používáme některý z funkcionálů kvality rozkladu, nejčastěji Wardovo kritérium.
• nejspolehlivější cestou by bylo projít všechny možné rozklady, avšak v reálných úlohách jich je příliš mnoho;
• v praxi se proto využívají algoritmy, které zaručují nalezení alespoň lokálního extrému zvoleného funkcionálu kvality rozkladu;
• k těmto algoritmům patří metody, které jsou určeny k řešení úloh se zadaným počtem shluků, například metoda k-průměrů nebo fuzzy shluková analýza;
• další cestou jsou metody určování optimálního počtu shluků. Určení optimálního počtu shluků Ke stanovení optimálního počtu shluků bývají nejčastěji používány dva základní přístupy, a to heuristické procedury a formální testy.
• heuristické procedury patří ke všeobecně používaným postupům, zejména v oblasti společenských věd;
• nejjednodušším příkladem je navržení počtu shluků na základě tzv. dendrogramu, ve kterém mohou být v některých případech znázorněny výrazné shluky;
• pro stanovení optimálního počtu shluků existuje více pravidel, z nichž některá jsou globální a některá lokální.
Vzhledem ke značné výpočetní náročnosti používaných postupů je při praktickém provádění shlukové analýzy vhodné použít statistický software (např. SPSS, STATGRAPHICS, STATISTICA apod.). Jednotlivé programy se mohou do určité míry lišit, v zásadě však je jejich princip velmi podobný. Procedury poskytují množství výstupních tabulek a grafů, pro jejichž správnou interpretaci je nezbytná orientace v teoretickém základu shlukové analýzy.