43
Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 1 z 43 Kontejnery a datovody

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 1 z 43
Kontejnery a datovody

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 2 z 43
Obsah 1. Standardní knihovna kolekcí
2. Datovody
3. KONEC

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 3 z 43
1. Standardní knihovna kolekcí
Obsah 1.1 Co jsou to kontejnery
1.2 Pole 1.2.1 Deklarace a inicializace 1.2.2 Použití 1.2.3 Pole jako konstanta, vícerozměrná pole 1.2.4 Pole jako objekt 1.2.5 Proměnný počet parametrů
1.3 Kolekce 1.3.1 Přidání a odebrání prvků 1.3.2 Zjišťování obsahu a velikosti, iterace 1.3.3 Převody na pole a datovody
1.4 Množiny
1.5 Seznamy 1.5.1 Práce s prvky na dané pozici 1.5.2 Práce s celým seznamem
1.6 Fronty a dvojité fronty
1.7 Mapy (slovníky) 1.7.1 Práce s jednotlivými prvky 1/2 1.7.2 Práce s jednotlivými prvky 2/2 1.7.3 Práce s celou mapou
1.8 Diagram tříd klíčové podmnožiny kolekcí Javy

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 4 z 43
1.1 Co jsou to kontejnery ► Kontejner = objekt sloužící k uložení jiných objektů
● Na rozdíl od běžného života může být objekt uložen v několika kontejnerech
► Kontejnery dělíme na: ● Statické – „narodí se“ s kapacitou, která jim zůstane až do smrti
● Přepravka ● Pole
● Dynamické – mohou svůj objem přizpůsobovat okamžitým potřebám ● Množina ● Seznam ● Fronta ● Strom ● Mapa (slovník)
► I dynamické kontejnery lze definovat jako neměnné, které pak již počet ani hodnoty uchovávaných prvků nemění

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 5 z 43
1.2 Pole ► Pole jsou statické kontejnery, které mají přímou podporu
v instrukčním souboru současných mikroprocesorů
► Jejich výhodou je maximální možná efektivita, jejich nevýhodou je, že nevyhovují některým zásadám moderního programování
► V současnosti se proto od jejich používání ve vyšších hladinách architektury postupně upouští a používají se spíše v implementačním suterénu ● S nadsázkou bychom mohli říci, že se dává přednost objektům,
které vystupují jako dekorátor vybavující obalené pole potřebnými dodatečnými vlastnostmi a schopnostmi

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 6 z 43
1.2.1 Deklarace a inicializace ► Při vytváření pole definujeme, kolik prvků se do něj vejde,
a během jeho života již tato hodnota nejde změnit
► Typ pole se deklaruje tak, že se za typ prvků napíší hranaté závorky ● V definici se v těchto závorkách uvádí počet prvků ● Pole inicializované jen svým rozměrem má všechny prvky vynulované
int[] polePětiCelýchČísel = new int[5]; String[] poleTříSetStringů = new String[300];
► Při inicializaci hodnot pole uvádíme hodnoty ve složených závorkách ● Při inicializaci hodnotami se neuvádí počet prvků, překladač si jej odvodí
int[] maláPrvočísla = {1, 3, 5, 7}; String[] ročníObdobí = {"Jaro", "Léto", "Podzim", "Zima"}; IShape[] trio = {new Rectangle(), new Ellipse(), new Triangle()};

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 7 z 43
1.2.2 Použití ► Pole mají veřejný statický atribut length, v němž je uložena jejich délka
int malýchPrvočísel = maláPrvočísla.length; //Uloží se hodnota 4
► Nepotřebujeme-li vytvářet proměnnou, ale chceme pole hned použít, lze sloučit způsoby deklarace z minulé stránky public static void main(String[] args) { /* Tělo metody */ } @Test public void testMain() { main(new String[] {"První", "Druhý", "Třetí"}); }
► K hodnotám polí přistupujeme tak, že napíšeme název proměnné s odkazem na dané pole a za něj uvedeme v hranatých závorkách index prvku, přičemž prvky v poli jsou indexovány od nuly String léto = ročníObdobí[1]; int posledníMaléPrvočíslo = maláPrvočísla[maláPrvočísla.length – 1];

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 8 z 43
1.2.3 Pole jako konstanta, vícerozměrná pole ► Je-li pole deklarováno jako konstanta, nesmíme vyměnit pole,
avšak prvky pole se měnit mohou ● U polí nelze zakázat změnu jejich prvků →
proto se také nyní doporučuje používat místo polí seznamy final int[] meze = {1, 9}; meze[0] = 0; //Nultý prvek pole má nyní hodnotu 0 meze = new int[] {1, 10}; //Syntaktická chyba, hodnotu "meze" nelze měnit
► Prvkem pole může být hodnota libovolného typu včetně jiného pole – v deklaraci typu pole se pak objeví několik párů závorek ● Počet závorek označuje tzv. rozměr pole ● Pro jednorozměrná pole se občas používá termín vektor
int [][] dvojrozměrné; String[][][] trojrozměrné;

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 9 z 43
1.2.4 Pole jako objekt ► Pole jsou standardní objekty Javy, přímí potomci třídy Object
► Pole nedefinují žádné vlastní metody; ve svém portfoliu mají pouze metody zděděné od třídy Object
► Metody pro práci s poli jsou proto definovány v jiných, většinou knihovních třídách – především ve třídě java.util.Arrays
► Třída java.util.Arrays obsahuje metody pro: ● Vyhledávání prvků pole, jejich seřazení, inicializace prvků zadanou hodnotou ● Porovnání celých polí a vytvoření jejich kopie (celých či jejich části) ● Vytvoření textového podpisu ● Vytvoření datovodu čerpajícího prvky z daného pole

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 10 z 43
1.2.5 Proměnný počet parametrů ► Má-li nějaká metoda definován proměnný počet parametrů,
předá se jí pole, jehož délka odpovídá počtu předaných parametrů ● Byla-li metoda volána bez parametrů, má pole délku 0,
nicméně i s takovým polem se v programu občas setkáte
► Definice metody public static void main(String[] args) je a současně není stejná jako definice public static void main(String... args) ● Uvnitř těla metody na zvolené signatuře nezáleží,
v obou případech pracujeme stejně ● Je li v programu definována metoda jedním z těchto způsobů,
není již možno definovat její přetíženou verzi druhým způsobem – překladač to považuje za syntaktickou chybu
● Na druhou stranu zvolím-li v rodiči jeden ze způsobů, je nutné jej dodržet i v potomku

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 11 z 43
1.3 Kolekce ► Kontejnery, které mohou obecně měnit počet svých prvků,
další požadavky se na ně nakladou
► Všechny kolekce instancemi tříd implementujících interfejs java.util.Collection<E>, kde E je typ prvků ukládaných do kolekce
► Místo obecných kolekcí se většinou používají instance některého z jejích potomků tohoto interfejsu, protože díky upřesňujícím znalostem o daném potomku můžeme optimalizovat práci s jeho instancemi
► Interface Collection<E> je však přesto třeba znát, protože všichni jeho potomci používají metody, které od něj zdědili
► Kontrakt některých z deklarovaných metod připouští implementaci vyhazující UnsupportedOperationException

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 12 z 43
1.3.1 Přidání a odebrání prvků ● boolean add(E e)
Přidá do kolekce zadaný prvek ● boolean addAll(Collection<? extends E> c)
Přidá do kolekce všechny prvky zadané kolekce ● void clear()
Vyprázdni kolekci ● boolean remove(Object o)
Odstraní zadaný objekt z kolekce a vrátí informaci, zda se kolekce změnila ● boolean removeAll(Collection<?> c)
Odstraní z kolekce všechny prvky ze zadané kolekce; vrátí informaci, zda se tím změnila
● boolean retainAll(Collection<?> c) Ponechá v kolekci pouze prvky ze zadané kolekce; vrátí, zda se tím změnila
● default boolean removeIf(Predicate<? super E> filter) Vyjme z kolekce prvky, které odpovídají zadanému predikátu

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 13 z 43
1.3.2 Zjišťování obsahu a velikosti, iterace ● boolean contains(Object o)
Zjistí, zda kolekce obsahuje zadaný prvek ● boolean containsAll(Collection<?> c)
Zjistí, zda kolekce obsahuje všechny prvky ze zadané kolekce ● boolean isEmpty()
Zjistí, zda je kolekce prázdná ● int size()
Vrátí počet prvků v kolekci ● default void forEach(Consumer<? super T> action)
S každým prvkem kolekce provede zadanou akci ● Iterator<E> iterator()
Vrátí externí iterátor, který postupně zpřístupní prvky uložené v kolekci a umožní tak externímu programu s nimi něco provést. Znalost iterátorů je potřebná především pro analýzu starších programů současné programování dává před iterátory přednost datovodům, ale objevují se stále situace, kdy je iterátor výhodnější

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 14 z 43
1.3.3 Převody na pole a datovody ● Object[] toArray()
Vrátí pole s prvky kolekce ● Object[] toArray(Object[] a)
Vrátí pole prvků zadaného typu s prvky kolekce; vejdou-li se do pole v parametru, vrátí toto pole, nevejdou-li se, vytvoří nové
● default Stream<E> stream() Vrátí datovod, který použije danou kolekci jako svůj zdroj dat
● default Stream<E> parallelStream() Vrátí paralelní datovod, který použije danou kolekci jako svůj zdroj dat

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 15 z 43
1.4 Množiny ► Množina je kolekce, která připustí pouze jeden výskyt prvku v kolekci
► Při pokusu o druhé přidání téhož prvku se nestane nic, jenom přidávací metoda oznámí, že se množina nezměnila
► Množiny jsou definovány jako instance interfejsu java.util.Set<E>, který je potomkem interfejsu Collection<E>
► Implementace množin v Javě vyžaduje: ● Ukládají-li se hodnotové objekty, musí být neměnné ● Ukládané objekty musí mít metody equals(Object) a hashCode()
definovány tak, aby dodržovaly vzájemný kontrakt
► Množina obecně neřeší pořadí prvků, ale existují i takové, kterým vysvětlíte, jak se pozná, který prvek je větší, a ony je při procházení dodávají seřazené dle velikosti

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 16 z 43
1.5 Seznamy ► Seznam je kolekce prvků, u nichž je známé jejich pořadí
► Na rozdíl od množin není pořadí obecně závislé na nějakém pravidle, ale objekt, který žádá seznam o přidání prvku, může ovlivnit, kam se tento prvek v seznamu zařadí
► Oproti kolekci přidává metody, které pracují s pozicemi uložených prvků

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 17 z 43
1.5.1 Práce s prvky na dané pozici ● E get(int index)
Vrátí prvek umístěný na zadané pozici (indexuje se od nuly) ● int indexOf(Object o)
Vrátí index prvního výskytu zadaného prvku nebo -1 ● int lastIndexOf(Object o)
Vrátí index posledního výskytu zadaného prvku nebo -1 ● void add(int index, E element)
Přidá zadaný prvek na zadanou pozici ● void addAll(int index, Collection<? extends E> c)
Na zadanou pozici a za ní přidá všechny prvky za zadané kolekce ● E remove(int index)
Odebere prvek na zadané pozici, indexy jeho následovníků se sníží o 1 ● default void replaceAll(UnaryOperator<E> operator)
Nahradí všechny prvky hodnotou získanou aplikací zadaného operátoru na daný prvek

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 18 z 43
1.5.2 Práce s celým seznamem ● ListIterator<E> listIterator()
Vrátí iterátor, který rozšiřuje možnosti standardního iterátoru o funkce využívající znalosti pozice a sousedů aktuálního prvku
● List<E> subList(int fromIndex, int toIndex) Vrátí seznam obsahující prvky v zadaném rozsahu indexů. Tento podseznam je pouze pohledem na původní seznam, takže všechny změny v původním seznamu se projeví i v onom pohledu
● default void sort(Comparator<? super E> c) Seřadí prvky v seznamu podle pravidel zadaných v zadaném komparátoru

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 19 z 43
1.6 Fronty a dvojité fronty ► Fronty byly dodatečně dodány do knihovny hlavně kvůli možnosti
definovat fronty procesů čekajících na nějaký prostředek
► Fronta je sice ve skutečnosti seznam, ale předpokládá se, že se bude pracovat pouze s prvky na některém jejím konci ● na jednom konci budou přicházet čekající ● na druhém konci se budou odebírat obsluhovaní
► Dvojitá fronta (Dequeue) umožňuje, aby objekty mohly přicházet k oběma koncům a aby je také bylo možno obsluhovat na obou koncích fronty
► Dvojitá fronta se uplatní např. při realizaci zásobníku, u nějž se přidává i odebírá na stejném konci

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 20 z 43
1.7 Mapy (slovníky) ► Mapy (slovníky) jsou kolekce (přesněji množiny) uspořádaných dvojic
[klíč; hodnota] – říkáme, že mapují klíč na hodnotu
► Mapy jsou definovány jako instance interfejsu java.util.Map<K,V>, kde K označuje typ klíče (Key) a V typ jemu přiřazené hodnoty (Value)
► Každý klíč se smí v mapě vyskytnout pouze jednou, nicméně několika klíčům může být přiřazena shodná hodnota
► Dvojice uložené v mapě jsou instancemi interního interfejsu java.util.Map.Entry<K,V>
► Mapy jsem sice označil jako množiny uspořádaných dvojic, ale neřadíme je mezi kolekce, jsou to samostatné datové typy

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 21 z 43
1.7.1 Práce s jednotlivými prvky 1/2 ● boolean containsKey(Object key)
Zjistí, zda mapa obsahuje hodnotu sdruženou se zadaným klíčem ● boolean containsValue(Object value)
Zjistí, jestli existuje nějaký klíč, s nímž je sdružena zadaná hodnota ● V get(Object key)
Vrátí hodnotu sdruženou se zadaným klíčem ● default V getOrDefault(Object key, V defaultValue)
Vrátí hodnotu sdruženou se zadaným klíčem, a pokud takový klíč v mapě není, vrátí zadanou implicitní hodnotu
● V put(K key, V value) Vloží do mapy zadanou dvojici [klíč; hodnota]. Pokud zadaný klíč již nějakou hodnotu přiřazenu měl, nahradí ji zadanou hodnotou a původní hodnotu vrátí.
● void putAll(Map<? extends K,? extends V> m) Vloží do mapy všechny dvojice z mapy zadané jako parametr

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 22 z 43
1.7.2 Práce s jednotlivými prvky 2/2 ● default V putIfAbsent(K key, V value)
Neměl-li zadaný klíč ještě přiřazenu nenullovou hodnotu, přiřadí mu zadanou ● V remove(Object key)
Odebere dvojici se zadaným klíčem z mapy ● default boolean remove(Object key, Object value)
Je-li zadaný klíč mapován na zadanou hodnotu, odebere dvojici z mapy ● default V replace(K key, V value)
Je-li již zadaný klíč mapován na nenullovou hodnotu, přiřadí mu hodnotu zadanou v parametru
● default boolean replace(K key, V oldValue, V newValue) Je-li již zadaný klíč mapován na hodnotu zadanou v parametru oldValue, sdruží s ním hodnotu zadanou v parametru newValue

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 23 z 43
1.7.3 Práce s celou mapou ● void clear()
Vyčistí mapu = odebere z ní všechny uložené dvojice ● boolean isEmpty()
Zjistí, jestli je mapa prázdná ● int size()
Vrátí počet dvojic uložených v mapě ● Set<Map.Entry<K,V>> entrySet()
Vrátí množinu všech dvojic uložených v mapě ● Set<K> keySet()
Vrátí množinu klíčů v mapě (klíče jsou jedinečné ⇒ mohou být v množině) ● Collection<V> values()
Vrátí kolekci všech hodnot v mapě (hodnoty nemusí být jedinečné ⇒ kolekce)
● default void forEach(BiConsumer<? super K,? super V> action) Aplikuje zadanou akci na všechny dvojice v mapě

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 24 z 43
1.8 Diagram tříd klíčové podmnožiny kolekcí Javy
§

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 25 z 43
2. Datovody
Obsah 2.1 Seznámení
2.1.1 Motivace 2.1.2 Obecná charakteristika 2.1.3 Odchylky od kontejnerů 2.1.4 Změna používaných iterátorů 2.1.5 Analogie s výrobní linkou 2.1.6 Typy operací s daty v datovodu: 2.1.7 Vztah operací k datovodům
2.2 Operace s daty v datovodu 2.2.1 Ukázka 2.2.2 Filtrování obsahu datovodu 2.2.3 Řazení objektů v datovodu 2.2.4 Konverze prvků v datovodu
2.3 Možnosti získání datovodu 2.3.1 Tovární metody pro generování datovodů

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 26 z 43
2.1 Seznámení ► V OOP jsou pod termínem stream (proud) chápány objekty
zprostředkovávající přenos dat od zdroje k cíli ● Zdrojem či cílem může být soubor, datovod (pipe), oblast paměti, objekt, … ● Ve standardní knihovně Javy jsou takto pojímané proudy definovány
jako potomci abstraktních tříd InputStream, OutputStream, Reader a Writer
► Funkcionální programování tento termín používá pro potenciálně nekonečné seznamy, které data neuchovávají, ale pouze „o nich ví“.
● Program definuje, jaká data se do proudu zařadí, resp. jak datovod ona data získá
● Nezávisle na tom se definuje, co se těmito daty bude dělat ● Proudy jsou ve své přirozenosti funkcionální, takže nemění data umístěná
v proudu – každé „dato“ je za života proudu „navštíveno“ jen jednou ● Většina operací je implementována jako odložené (lazy)
► Pro odlišení budeme funkcionální proudy označovat jako datovody

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 27 z 43
2.1.1 Motivace ► Klasický postup:
Opakovaně prováděj: požádej kontejner o další uloženou instance, zjisti, jestli patří mezi ty, které je třeba zpracovat, pokud ano tak instanci požadovaným způsobem zpracuj
► Nevýhody: ● Zbytečně se opakuje podobný kód ● V programu zpracovává jedna položka po druhé
► Trend: posilovat deklarativní přístup k programování ● Snaha moci vysvětlit co se má dělat a nechat na knihovně jak to udělá ● Umožníme tím specialistům navrhujícím knihovny
optimalizovat řešení – např. pro intenzivní využití paralelismu

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 28 z 43
2.1.2 Obecná charakteristika ► Knihovny kolekcí a polí jsou staré, široce používané,
a proto je nelze zásadně modifikovat ● Snaha použít přístup funkcionálního programování, kde jsou datovody
chápány jako univerzální posloupnosti postupně zpřístupňovaných dat
► Datovod je klíčová abstrakce pro zpracování skupin dat umožňující specifikovat, co se má s daty dělat, a abstrahovat od toho, jak se to bude dělat
► Většina metod datovodů čte data z datovodu, zpracuje je a předává dalšímu datovodu, který pro ten účel vytvořila
► Ukázka – sečti váhy červených udělátek v kolekci widgets int sum = widgets.stream() .filter(b -> b.getColor() == RED) .mapToInt(b -> b.getWeight()) .sum();

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 29 z 43
2.1.3 Odchylky od kontejnerů ► Datovody předem neblokují žádnou paměť pro zpracovávaná data
● Data „přitékají“ datovodem k požadované operaci, která předá výsledek dalšímu datovodu, jenž data dopraví k další operaci
► Datovody se nezajímají o to, zda je vstup dat konečný či nekonečný, prostě převezmou zdrojová data a dopraví je k požadované operaci
► Operace se většinou hned neprovádí, ale pouze naplánují ● Odložené operace – lazy operations
► Naplánované operace počkají si, až k nim datovod zpracovávaný objekt dopraví, a pak se o tento objekt postarají
► Datovod může rozdělit práci mezi několik pracovišť ● Je-li následující pracoviště zahlcené, může rozdělit přepravované objekty
mezi několik paralelně fungujících pracovišť (procesorů), čímž se celková doba zpracování všech objektů (vstupních dat) výrazně zkrátí

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 30 z 43
2.1.4 Změna používaných iterátorů ► Při práci s klasickými poli a kolekcemi se používají především
externí (sekvenční) iterátory ● Program požádá kontejner o iterátor, který pak v cyklu žádá o další instanci,
s níž provede požadovanou operaci
► Při práci s datovody využíváme interní (dávkové) iterátory provádějící s iterovanými objekty operace definované lambda-výrazy
► Výhody: ● Z programu zmizí pomocný kód, který měl na starosti řízení iterací,
(tj. popis jak to dělat) a zpřehlední se tak popis akcí, které budou popisovat, co se zpracovávanými objekty udělat
● Objeví-li se v budoucnu nějaké propracovanější techniky paralelizace prováděných činností, není třeba upravovat část programu řešící aplikační logiku, ale stačí pouze vylepšit knihovnu datovodů a tím se automaticky zefektivní zpracování programů, které tyto datovody využívají

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 31 z 43
2.1.5 Analogie s výrobní linkou ► Na počátku je vstup
● V případě výrobního pásu je to sklad dílů, nebo nějak zabezpečený přísun vstupních surovin od dodavatele
● V případě datovodu to bude zdroj dat – většinou nějaký zdrojový kontejner, zdrojem ale může být i generátor, který vytváří data na požádání
► Pracoviště ● Podél výrobního pásu jsou připravená pracoviště,
na nichž zaškolení dělníci provádějí jednotlivé operace ● V případě datovodu nahradíme dělníky metodami (přesněji lambda výrazy),
které s přišedším objektem provedou požadovanou operaci a … ● … vypustí jej do dalšího datovodu, kde pokračuje k dalšímu pracovišti
► Výsledky ● Na konci výrobního pásu „vypadne“ hotový výrobek ● Na konci série operací s daty posílanými datovody obdržíme (doufejme )
požadovaný výsledek

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 32 z 43
2.1.6 Typy operací s daty v datovodu: ► Filtrace
● Např. při procházení souborů na disku mne zajímají jen ty s danou příponou
► Mapování (konverze) ● Z přišedšího objektu mne zajímá jen hodnota jednoho atributu –
do výstupního datovodu odchází ona
► Řazení ● Pro další zpracování potřebuji mít data definovaným způsobem seřazena
► Souhrny (reduction, folding) ● Na přitékajících datech mne zajímá pouze nějaká souhrnná informace
průměr, součet, …
► Sdružování (mutable reduction) ● Zpracovaná data vkládám do nějakého kontejneru (kolekce, pole, …)

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 33 z 43
2.1.7 Vztah operací k datovodům ► Vrácený datovod nemusí být shodný se vstupním
● Když má operace např. zjistit počet znaků v řetězci, je vstupním datovodem datovod textových řetězců (stringů) a výstupním datovodem datovod celých čísel
● V případě potřeby může mít výstupní datovod jinak uspořádaná data než datovod vstupní
► Operace nejsou nijak ovlivněny tím, zda je vstup dat konečný (klasický kontejner), nebo nekonečný
● Data prostě přitékají a co přiteče, to se zpracuje, a čeká se na další
► Operace nejsou svázány s konkrétním datovodem; program může postupně vytvářet různé datovody, na jejichž data pošle danou sadu operací
● Jednou může být zdrojem dat kolekce, jindy generátor apod. ● Operace pouze vědí, že data přijdou, ony je mají zpracovat a někam poslat

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 34 z 43
2.2 Operace s daty v datovodu ► Průběžné (intermediate)
● Vytvoří si vlastní (výstupní) datovod ● Ze vstupního datovodu převezmou objekt, zpracují jej,
a předají do svého výstupního datovodu ● Vracejí datovod, takže je lze jednoduše zřetězit ● Nevracejí datovod, jehož jsou instancí, ale svůj výstupní datovod =>
nelze obecně zavolat průběžnou metodu, aniž bychom si zapamatovali datovod, který nám vrátí a jehož metodu pak musíme v dalším kroku oslovit
► Koncové (terminal) ● Zakončují činnost datovodu a předávají výsledek okolnímu programu ● Výstupní hodnotou může být kolekce, objekt, ale také nic

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 35 z 43
2.2.1 Ukázka /*************************************************************************** * Zabezpečí, aby každé světlo na zhaslo, bliklo a opět se rozsvítilo. * To, jestli budou světla pracovat postupně nebo všechna najednou, * záleží na typu datovodu. */ private void streamBlink(Stream<Light> stream, String text) { //Akci, kterou budu chtít zadat vícekrát, si připravím a uložím Consumer<Light> pause = (o)->IO.pause(500); //Zapamatuje si datovod vrácený poslední průběžnou operací stream = stream //Diktuji operace, které se budou v datovodu postupně provádět .peek(Light::switchOff) .peek(pause) .peek(Light::blink) .peek(pause) .peek(Light::switchOn); //Zatím se nic nedělo, dít se začne až při provádění terminální akce long count = stream.count(); IO.inform(text + "\n\nBlikalo: " + count); } //Testy výše uvedené metody

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 36 z 43
@Before public void setUp() { lightXYS = new Light( 0, 0, 100); lightXY = new Light(100, 50); lightXYC = new Light( 50, 100, NamedColor.RED); lightXYSC = new Light(100, 100, 100, NamedColor.GREEN); lightsArr = new Light[] {lightXY, lightXYC, lightXYS, lightXYSC}; lightsCol = Arrays.asList(lightsArr); } @Test public void testGroupBlink() { Stream<Light> stream = Arrays.stream(lightsArr); //lightsCol.stream(); streamBlink(stream, "testGroupBlink"); } @Test public void testGroupBlinkParallel(){ Stream<Light> stream = lightsCol.parallelStream(); //Arrays.stream(lightsArr).parallel(); streamBlink(stream, "testGroupBlinkParallel"); }

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 37 z 43
► Pokud bychom nechtěli ukázat, že akce se spouští až při zavolání koncové metody, mohli bychom použít test ve tvaru private void streamBlinkFE(Stream<Light> stream) { //Akci, kterou budu chtít zadat vícekrát, si připravím a uložím Runnable pause = ()->IO.pause(500); //Zapamatuje si datovod vrácený poslední průběžnou operací stream.forEach((Light x) -> { x.switchOff(); pause.run(); x.blink(); pause.run(); x.blink(); pause.run(); x.blink(); pause.run(); x.switchOn(); }); } @Test public void testGroupBlinkFE() { Stream<Light> stream = lights.stream(); streamBlinkFE(stream); }
Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 38 z 43
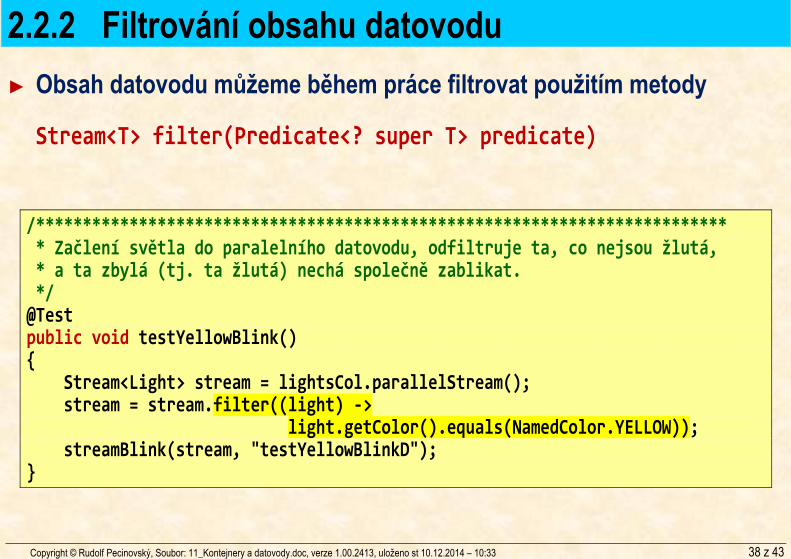
2.2.2 Filtrování obsahu datovodu ► Obsah datovodu můžeme během práce filtrovat použitím metody
Stream<T> filter(Predicate<? super T> predicate)
/************************************************************************** * Začlení světla do paralelního datovodu, odfiltruje ta, co nejsou žlutá, * a ta zbylá (tj. ta žlutá) nechá společně zablikat. */ @Test public void testYellowBlink() { Stream<Light> stream = lightsCol.parallelStream(); stream = stream.filter((light) -> light.getColor().equals(NamedColor.YELLOW)); streamBlink(stream, "testYellowBlinkD"); }

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 39 z 43
2.2.3 Řazení objektů v datovodu ► K zadání akce přeuspořádavající daný datovod slouží metody
Stream<T> sorted() Stream<T> sorted(Comparator<? super T> comparator)
/************************************************************************** * Začlení světla do sériového datovodu, seřadí je v něm podle vodorovné * souřadnice a nechá je v tomto pořadí postupně zablikat. */ @Test public void testXSortedBlink() { Stream<Light> stream = lights.stream(); stream = stream.sorted((first, second) -> first.getPosition().x - second.getPosition().x); streamBlink(stream); }

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 40 z 43
2.2.4 Konverze prvků v datovodu ► Prvek, který do datovodu „nastoupil“, doposud procházel
jednotlivými zastávkami, dokud činnost datovodu neskončila ► Datovody však umožňují vyměnit cestou druh prvků, s nimiž pracují
prostřednictvím některé z metod: ● <R> Stream<R> map(Function<? super T,? extends R> mapper) ● DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper) ● IntStream mapToInt (ToIntFunction <? super T> mapper) ● LongStream mapToLong (ToLongFunction <? super T> mapper)
public static void createAndDrive(IVehicleFactory vehicleFactory, String directions, Position... positions) { Arrays.stream(positions).parallel() .map(vehicleFactory::newVehicle) //Převede pozice na vozidla .peek((vehicle) -> {CM.add(vehicle);}) .forEach(goInDirections(directions)); }

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 41 z 43
2.3 Možnosti získání datovodu ► Z kolekcí prostřednictvím metod stream() a parallelStream()
► Z polí prostřednictvím metody Arrays.stream(Object[])
► Řádky souboru lze získat metodou BufferedReader.lines()
► Datovod souborů na zadané cestě (java.nio.file.Path) lze získat metodami třídy java.nio.file.Files
► Datovod náhodných čísel lze získat metodou Random.ints()
► Datovod položek v ZIP-souboru lze získat metodou JarFile.stream()
► Datovod částí sekvence znaků lze získat voláním statické metody Pattern.splitAsStream(java.lang.CharSequence)
► Datovod indexů nastavených položek lze získat voláním BitSet.stream()

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 42 z 43
2.3.1 Tovární metody pro generování datovodů ► Třída Stream nabízí navíc metody, s jejichž pomocí lze definovat
generátory datovodů zadaným způsobem vytvořených objektů
► static <T> Stream<T> of(T... values) Vytvoří datovod zadaných hodnot
► static <T> Stream<T> iterate(T seed, UnaryOperator<T> f) Vytvoří nekonečný seřazený datovod, jehož počáteční prvek je tvořen semenem seed a následující prvky jsou vytvářeny aplikací operátoru f na předchozí prvek
► static <T> Stream<T> generate(Supplier<T> s) Vytvoří nekonečný datovod, jehož prvky jsou výsledkem volání s
► IntStream range(int, int) Třída IntStream umí vytvořit datovod celých čísel ze zadaného intervalu

Copyright © Rudolf Pecinovský, Soubor: 11_Kontejnery a datovody.doc, verze 1.00.2413, uloženo st 10.12.2014 – 10:33 43 z 43
3. KONEC Zdroje:

















