115
POČÍTAČE A PROGRAMOVÁNÍ 2 Přednášky Zbyněk Raida, Irena Hlavičková, Michal Pokorný a další ÚSTAV RADIOELEKTRONIKY

POČÍTAČE A PROGRAMOVÁNÍ 2
Přednášky
Zbyněk Raida, Irena Hlavičková, Michal Pokorný a další
ÚSTAV RADIOELEKTRONIKY


POČÍTAČE A PROGRAMOVÁNÍ 2
Přednášky
Zbyněk Raida, Irena Hlavičková, Michal Pokorný a další
ÚSTAV RADIOELEKTRONIKY

© Zbyněk Raida, Irena Hlavičková, Michal Pokorný, 2007
ISBN 978-80-214-3536-0


Název POČÍTAČE A PROGRAMOVÁNÍ 2 Přednášky
Autoři Prof. Dr. Ing. Zbyněk Raida Mgr. Irena Hlavičková Ing. Michal Pokorný
Vydavatel Vysoké učení technické v Brně Fakulta elektrotechniky a komunikačních technologií Ústav radioelektroniky Purkyňova 118, 612 00 Brno
Vydání druhé, přepracované
Rok vydání 2007
Náklad 400 ks
Tisk MJ Servis s.r.o., Kouty 16, 621 00 Brno
ISBN 978-80-214-3536-0
Tato publikace neprošla redakční ani jazykovou úpravou

obsah
- 5 -
Obsah
1 Úvod ........................................................................................................................................ 7
1.1 Programování ................................................................................................................... 7 1.2 Borland C++ Builder – první pohled.............................................................................. 10
2 Jazyk C .................................................................................................................................. 13
3 Identifikátory, typy dat, proměnné........................................................................................ 14
3.1 Lokální a globální proměnné.......................................................................................... 14 3.2 Pravidla deklarování proměnných.................................................................................. 15 3.3 Základní typy proměnných............................................................................................. 16 3.4 Ukazatele ........................................................................................................................ 17 3.5 Pole................................................................................................................................. 18
4 Výrazy, operátory, konverze ................................................................................................. 22
4.1 Aritmetické konverze ..................................................................................................... 22 4.2 Priorita operací ............................................................................................................... 23 4.3 Aritmetické operátory .................................................................................................... 24 4.4 Relační operátory ........................................................................................................... 25 4.5 Logické operátory........................................................................................................... 27 4.6 Bitové operátory ............................................................................................................. 28 4.7 Operátory inkrementování a dekrementování ................................................................ 29 4.8 Přiřazovací operátory ..................................................................................................... 30
5 Řetězce, ukazatele ................................................................................................................. 31
6 Příkazy................................................................................................................................... 38
6.1 Příkazy pro větvení programu ........................................................................................ 39 6.2 Příkazy pro cykly ........................................................................................................... 41 6.3 Příkazy pro přenos řízení................................................................................................ 43 6.4 Příklad ............................................................................................................................ 44 6.5 Abecední seznam příkazů............................................................................................... 47
7 Funkce ................................................................................................................................... 48
7.1 Programové jednotky, hlavičkové soubory.............................................................. 54 7.2 Rekurze funkcí ............................................................................................................... 57
8 Pokročilé datové typy............................................................................................................ 59
8.1 Struktury......................................................................................................................... 59 8.2 Unie ................................................................................................................................ 60 8.3 Výčtové typy .................................................................................................................. 61 8.4 Dynamické proměnné..................................................................................................... 62

obsah
- 6 -
8.5 Příklad Auta.................................................................................................................... 63 8.6 Příklad Žáci .................................................................................................................... 65
9 Struktury ve Windows........................................................................................................... 68
9.1 Borland C++ Builder – druhý pohled............................................................................. 68 9.2 Vývoj aplikace pro Windows......................................................................................... 71 9.3 Seznam počítačů............................................................................................................. 76 9.4 Struktury v C++.............................................................................................................. 82
10 Matice ve Windows............................................................................................................. 83
10.1 Sčítání a inverze ........................................................................................................... 83 10.2 Uživatelské rozhraní..................................................................................................... 85
11 Grafika ve Windows............................................................................................................ 88
11.1 Kreslení grafů ............................................................................................................... 93 11.2 Tvary ............................................................................................................................ 95
12 MDI aplikace....................................................................................................................... 97
13 Práce se soubory................................................................................................................ 100
14 Příklady ............................................................................................................................. 103
14.1 Stavový automat ......................................................................................................... 103 14.2 Interaktivní vykreslování přenosové charakteristiky filtru ........................................ 106
15 Literatura ........................................................................................................................... 113

úvod
- 7 -
1 Úvod Předmět Počítače a programování 2 (ve zkratce BPC2) je vyučován v letním semestru
prvního ročníku bakalářského studia. Předmět je společný všem oborům studijního programu Elektrotechnika, elektronika, komunikační a řídicí technika.
Základním cílem předmětu je naučit se programovat v jazyku C. Tento jazyk je v sou-časnosti používán pro programování mikroprocesorů řídících vše od vysavače přes měřicí přístroj po jednotlivé subsystémy moderního auta. Jazyk C se používá pro vývoj všemožných aplikací pro Windows i LINUX. Jazyk C je zkrátka všude.
S jazykem C se budeme seznamovat prostřednictvím vývojového nástroje Borland C++ Builder. Dvouměsíční licenci programu lze získat zdarma na www.borland.com. Každý se tak může s programováním v jazyce C seznamovat sám doma s využitím legálního software.
Programovací jazyk je jazykem stejným jako každý jiný. Naučit se anglicky je dřina a s jazykem C je to stejné. Bez toho, že by člověk hodiny programoval, o programech přemýšlel a zkoušel stejnou věc naprogramovat lépe a lépe, to zkrátka nejde. Přejeme tedy otevřenou mysl a spoustu trpělivosti.
Předkládané skriptum vzniklo po ně-kolikaleté zkušenosti s výukou jazyka C na FEKT VUT v Brně. S jeho psaním pomohli Ilona Lázničková, Lukáš Oliva, Miloš Rich-ter a mnoho dalších. Všichni se snažíme učit jazyk C co možná nejlépe a nejzajímavěji. Snad se to alespoň trochu daří.
1.1 Programování Pod pojmem programování rozumíme
psaní textu, který procesoru počítače jedno-značně říká, co má dělat a jak. Psaní progra-mu můžeme rozdělit do následujících kroků:
1. Sestavení algoritmu. Na základě za-daného úkolu navrhneme postup (sesta-víme algoritmus), jakým lze danou úlohu vyřešit. Algoritmus obvykle vy-jadřujeme blokovým schématem.
Na pevném disku počítače máme v sou-boru teplo.dat uloženy teploty, které byly během předchozího dne naměřeny v každou celou hodinu. Našim úkolem je určit tu hodinu, kdy byla teplota nejnižší. Soubor tedy otevřeme a data z něj uložíme do sady proměnných souhrnně označených jako temp (temperature, teplota). Dále si vytvoříme pomocnou proměnnou min_temp (minimum temperature) a uložíme
start
min_temp←m ←
min_temp
ANO
NE
min_temp←min_time←
m m + 1←
m<25NE
ANO
konec
temp ← teplo.dat9001
>temp(m)
teplo(m)m
Obr. 1.1 Algoritmus hledání nejnižší teploty

úvod
- 8 -
do ní nerealisticky vysokou teplotu 900°C. Obsah proměnné min_temp budeme postupně porovnávat s jednotlivými zaznamenanými teplotami (na právě porovnávaný obsah proměnné ze sady temp ukazuje index m). Pokud je některá zaznamenaná teplota nižší nežli obsah min_temp (větev ANO) uložíme tuto hodnotu do min_temp, a současně do proměnné min_time uložíme pořadí daného čísla (dané teploty) v souboru teplot; pořadí čísla v souboru totiž odpovídá hodině, kdy byla teplota naměřena. V opačném případě (testovaná teplota ze souboru je vyšší nežli obsah min_temp) se nic neděje.
Jakmile projdeme všechna čísla v souboru (index m je větší než počet hodin dne), budeme mít v proměnné min_temp údaj o nejnižší naměřené teplotě a v proměnné min_time údaj o hodině, kdy byla tato teplota naměřena.
Popsaný algoritmus lze vyjádřit blokovým schématem z obr. 1.11.
2. Zapsání algoritmu v programovacím jazyku. Na základě přesně daných pravidel ja-zyka (tzv. syntaxe) napíšeme text (tzv. zdrojový kód), který překladač programovacího jazyka umí přeložit do kódu strojového – do kódu, kterému „rozumí“ procesor počítače.
Pokud se rozhodneme algoritmus pro vyhledávání nejnižší teploty (obr. 1.1) vyjádřit v ja-zyku C, může zdrojový kód algoritmu vypadat následovně2: #include <conio.h>
void main( void) { // pole teplot; první údaj naměřen v 1:00, poslední údaj // naměřen ve 24:00 float temp[24] = {-8.1, -8.3, -8.6, -9.2, -9.4, -9.2, -9.0, -8.5, -7.9, -6.7, -5.0, -2.3, +1.1, +2.3, +1.2, -0.8, -2.6, -4.1, -5.2, -6.3, -7.7, -8.5, -9.1, -9.3}; float min_temp; // nejnižší teplota int min_time; // hodina, kdy naměřena min.teplota int m; // index pro vyhledávání min_temp = 900; // počáteční nastavení for( m=1; m<25; m++) // cyklus přes 24 hodiny if( temp[m-1]<min_temp) // pokud v m-té hodině teplota nižší { // nežli min_temp min_temp = temp[m-1]; // změň obsah min_temp min_time = m; // ulož údaj o hodině s min.teplotou } cprintf("Min. teplota %4.1f ", min_temp); // zobraz min.teplotu cprintf("byla v %d hodin", min_time); // zobraz hodinu getch(); }
1 Obr. 1.1 je tzv. vývojový diagram. Jeho účelem je popsání algoritmu. Oválné rámečky značí začátek nebo
konec programu či podprogramu, obdélníkové proceduru, funkci nebo příkaz. Kosodélníky značí místo větvení, ve kterém se rozhoduje o pokračovací větvi.
2 V textu budeme pro psaní programů využívat následující konvence: klíčová slova (float, int, if, for …) budou tučně, poznámky budou psány kurzívou, ostatní zdrojový kód je psán proporcionálním písmem.

úvod
- 9 -
První řádek nám říká, že do programu zahrnujeme knihovnu naprogramovaných funkcí conio3 (console input output – funkce pro načítání a vypisování do příkazového řádku). Do této knihovny patří např. cprintf (tisk do příkazového řádku) nebo getch (načtení znaku).
Druhý řádek programu je tzv. hlavička funkce. Uprostřed hlavičky se nachází jméno funkce (v našem případě main4). Nalevo od jména je uveden typ hodnoty, kterou funkce vrací (v našem případě void5). Napravo od jména se v závorce uveden seznam vstupních parametrů (v našem případě opět void). Slovo void značí prázdný parametr, tedy nic. Každý program v jazyku C je chápán jako funkce.
Složené závorky označují kód, který společně tvoří jeden blok – tělo funkce. Za dvojité lomítko můžeme psát svůj komentář (znaky komentáře jsou překladačem ignorovány). Slovo float uvozuje reálnou proměnnou, slovo int celočíselnou proměnnou. Proměnná temp sestává z 24 reálných čísel, první číslo má v hranatých závorkách index 0. Znamén-kem = vložíme do proměnné konkrétní číselnou hodnotu.
Řádkem for říkáme, že následný kód budeme vykonávat od m=1 do m=24 (poté přestane platit m<25), přičemž po každém vykonání následného kódu bude hodnota indexu m zvý-šena o jedničku (m++). Pokud je splněna nerovnost v kulaté závorce za if, vykoná se následný blok ve složené závorce; v opačném případě nebude vykonáno nic.
Poslední dva řádky vypíší nejnižší teplotu a odpovídající hodinu do příkazového řádku (viz obr. 1.2). Za %4.1f je dosazen obsah proměnné min_temp typu float; vypsané číslo sestává celkem ze čtyř znaků, z nichž jeden je za desetinnou tečkou. Za %d je do-sazen obsah proměnné min_time typu int.
Obr. 1.2 Textový výstup programu do příkazového řádku.
3. Ladění programu. Člověk je omylný, a proto se při psaní zdrojového kódu dopouští omylů. Naše možné chyby přitom můžeme rozdělit na omyly syntaktické a omyly logické.
3 Knihovna conio je speciální knihovna prostředí Borland C++ Builder. Jak si asi všimli ti, kteří používají
jinou literaturu nebo už s jazykem C měli co do činění, její funkce cprintf, resp. cscanf se podobají funkcím standardní knihovny C pro vstup a výstup (stdio.h) – scanf, printf, a stejně se i používají. Funkce knihovny stdio na rozdíl od conio zkompilujeme kdekoli (Linux/Windows, gcc/MSVisual Studio/...), a výsledkem jejich používání je přenositelný kód.
4 Funkce main() je nejdůležitější funkcí programu. V každém programu smí být jen jedna. Funkce main() obsahuje, co program dělá. Ostatní funkce jsou pouze pomocné a jsou spouštěny v main() nebo v ostatních funkcích.
5 Pokud by měl být zdrojový kód zcela obecný (tzn. přeložitelný libovolným kompilátorem jazyka C), musela by funkce vracet celočíselnou hodnotu. Jelikož překladač Borlandu nemá s návratovou hodnotou void po-tíže, nebudeme se jí vyhýbat.

úvod
- 10 -
Syntaktickým omylem rozumíme omyl v zápisu (záměna malého a velkého písmene, od-kaz na neexistující proměnnou, atd.). Na syntaktický omyl nás upozorní překladač, který v důsledku našeho omylu není schopen převést náš zdrojový kód na kód strojový.
Pokud bychom cyklus v našem příkladu zahájili slovem For, dopustili bychom se syn-taktického omylu. Syntaxe jazyka C totiž vyžaduje začít slovo for malým písmenem.
Logickým omylem je omyl, který překladač neodhalí. Po spuštění programu se však naše aplikace chová jinak, než jsme očekávali6. Napíšeme-li v našem příkladu místo přiřazení min_time=m nesprávně min_time=m+1, bude údaj o času nejnižší teploty posunut o jednu hodinu. Běh programu bude bezproblémový, avšak produkovaný výsledek bude chybný.
Proces odstraňování chyb je nazýván laděním (debugging). Ladění je posledním krokem při vývoji programu.
1.2 Borland C++ Builder – první pohled Borland C++ Builder je komplexní nástroj pro vytváření rozsáhlých aplikací určených
pro operační systémy Microsoft Windows. Zahrnuje podporu programování databázových, internetových, grafických a dalších aplikací. Tyto aplikace jsou programovány v jazyce C++.
Jazyk C++ vznikl jako tzv. objektové rozšíření základního jazyka C7. Stručné vysvětlení pojmu objektově orientované programování si ponecháme na druhou polovinu semestru. Hlouběji se lze s objektovým jazykem C++ seznámit v navazujících předmětech v dalších semestrech studia. Náš předmět se soustřeďuje na základní neobjektovou verzi jazyka C.
Abychom se zbytečně nerozptylovali všemi možnostmi, které nám Windows přinášejí, budou naše první programy určeny pouze pro příkazovou řádku. Mluvit budeme o tzv. konzo-lových aplikacích (console applications). Uživatelský pohled na konzolovou aplikaci vidíme na obr. 1.2.
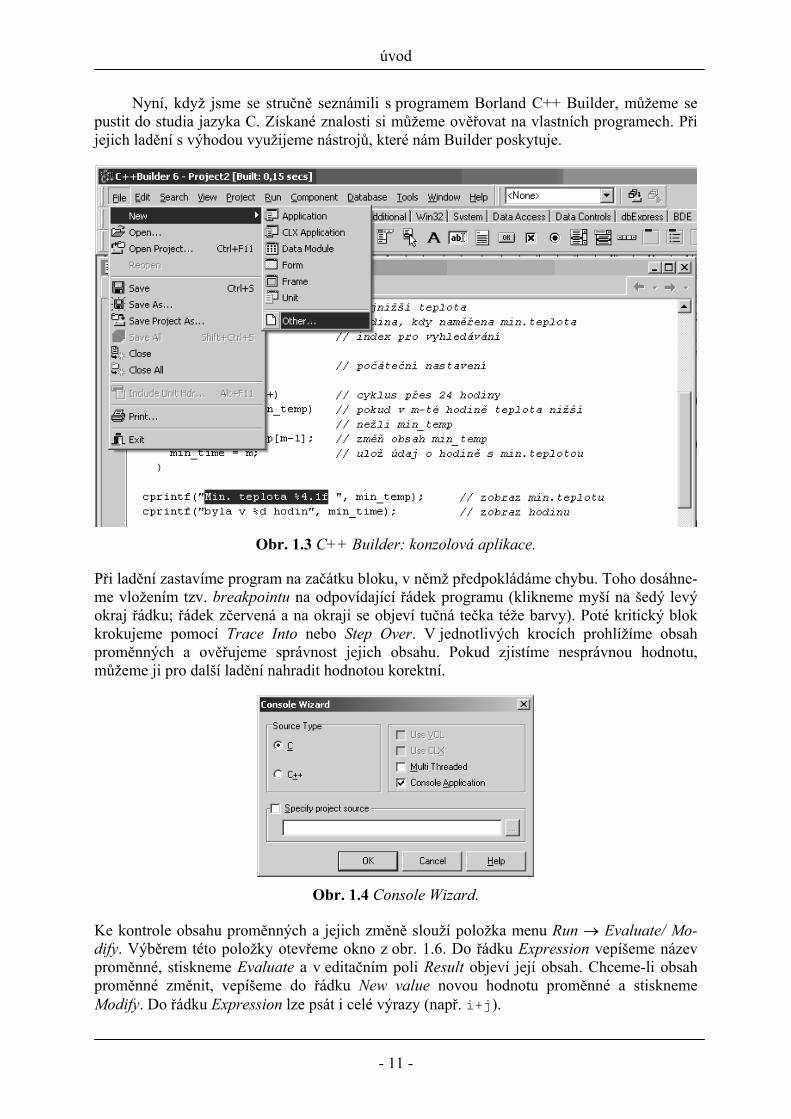
Obr. 1.3 ukazuje základní pohled na Borland C++ Builder. Novou konzolovou aplikaci vytvoříme postupným výběrem položek menu New → Other. V okénku, které se následně otevře, vybereme ikonu Console Wizard.
Výběrem ikony Console Wizard otevřeme dialog pro základní nastavení konzolové aplikace (viz obr. 1.4). Jelikož budeme psát neobjektový program, v levé části dialogu vybere-me možnost C. Jelikož nebudeme psát program, který řeší úlohu rozdělenou do několika paralelních vláken (threads), možnost Multi Threaded zůstane v pravé části okna nevybrána.
Potvrdíme-li nastavení aplikace tlačítkem OK, otevře se editor pro psaní zdrojového kódu. Kód můžeme uložit do souboru, spustit, krokovat řádek po řádku. Všechny tyto úkony lze spustit stiskem ikony na tzv. speedbaru Builderu (viz obr. 1.5).
6 Toto je lepší varianta. Horší chyby se projeví až v okamžiku, když program považujeme za funkční. Předejít
oběma druhům chyb se dá pomocí správných programátorských návyků (inicializace proměnných, kontrola přetečení polí, apod.), jak se dozvíme v dalším textu.
7 Jazyk C++ se na rozdíl od C poměrně rychle vyvíjí. Důvodem jeho vzniku bylo zjednodušení vývoje aplikací a vytvoření jazyka se stručnějším zápisem. V současné době C++ přináší možnosti, které v C přímo nejsou (např. šablony nebo přetížení operátorů). Využití těchto vlastností ale vyžaduje naučit se něco navíc. Tyto možnosti slouží k usnadnění programování. Na druhou stranu není pravda, že by algoritmus, který lze napro-gramovat v C++ nešlo naprogramovat v C.
úvod
- 11 -
Nyní, když jsme se stručně seznámili s programem Borland C++ Builder, můžeme se pustit do studia jazyka C. Získané znalosti si můžeme ověřovat na vlastních programech. Při jejich ladění s výhodou využijeme nástrojů, které nám Builder poskytuje.
Obr. 1.3 C++ Builder: konzolová aplikace.
Při ladění zastavíme program na začátku bloku, v němž předpokládáme chybu. Toho dosáhne-me vložením tzv. breakpointu na odpovídající řádek programu (klikneme myší na šedý levý okraj řádku; řádek zčervená a na okraji se objeví tučná tečka téže barvy). Poté kritický blok krokujeme pomocí Trace Into nebo Step Over. V jednotlivých krocích prohlížíme obsah proměnných a ověřujeme správnost jejich obsahu. Pokud zjistíme nesprávnou hodnotu, můžeme ji pro další ladění nahradit hodnotou korektní.
Obr. 1.4 Console Wizard.
Ke kontrole obsahu proměnných a jejich změně slouží položka menu Run → Evaluate/ Mo-dify. Výběrem této položky otevřeme okno z obr. 1.6. Do řádku Expression vepíšeme název proměnné, stiskneme Evaluate a v editačním poli Result objeví její obsah. Chceme-li obsah proměnné změnit, vepíšeme do řádku New value novou hodnotu proměnné a stiskneme Modify. Do řádku Expression lze psát i celé výrazy (např. i+j).
úvod
- 12 -
novýprojekt
otevři ulož
spusťaplikaci
zastav běhaplikace
krokuj dovnitřfunkce
funkcev jednomkroku
Obr. 1.5 Tzv. speedbar Builderu.
Ladicí nástroje Builderu jsou efektivní a pohodlné. Přesto je lepší dobře si promyslet a na-kreslit algoritmus sestavovaného programu, abychom se nedopouštěli zbytečných logických omylů. Nutné je dobře se naučit syntaxi programovacího jazyka, abychom se nedopouštěli zbytečných omylů syntaktických.
Obr. 1.6 Dialog pro sledování obsahu proměnných.

jazyk c
- 13 -
2 Jazyk C Programovací jazyk C vyvinul na přelomu šedesátých a sedmdesátých let D.M. Ritchie
u firmy AT&T. Jazyk se stal postupem doby natolik oblíbený, že byl kodifikován Americkým národním úřadem pro normalizaci (ANSI8). Na základě této normy vznikla řada implementací jazyka C pro různé typy počítačů a pro různé druhy operačních systémů.
Počátkem osmdesátých let byla navržena objektová verze9 jazyka, pro níž se vžilo označení C++. Jazyk C++ se postupem doby stal základem moderních vývojových nástrojů, jakými jsou Borland C++ Builder nebo Microsoft Visual C++.
S nástrojem Borland C++ Builder jsme se již seznámili a zůstaneme mu dále věrni. Nicméně, naši pozornost soustředíme na původní, neobjektovou verzi jazyka, na ANSI C. Důležité pro nás bude, abychom si zvykli na syntaxi jazyka C a abychom se naučili v jazyce C myslet. Přechod k moderní, objektové verzi C++ by pak už měl být pro nás relativně snadný.
8 Současná používaná norma jazyka C je ISO99. 9 Program obvykle sestává z nezávislého kódu (posloupnost instrukcí v tělech funkcí) a z nezávislých dat
(proměnné, v nichž jsou uloženy programem zpracovávané údaje). Objektové programování skládá funkce (kód) a proměnné (data) do jediné struktury, kterou nazýváme objekt.

identifikátory, typy dat, proměnné
- 14 -
3 Identifikátory, typy dat, proměnné Identifikátorem rozumíme libovolnou posloupnost písmen anglické abecedy a číslic10.
Identifikátor hraje roli jména naší vlastní proměnné nebo naší vlastní funkce.
Identifikátor musí začínat písmenem (nesmí mít na první pozici číslo). V jazyce C je třeba rozlišovat malá a velká písmena.
Termínem proměnná rozumíme místo v paměti, do něhož ukládáme data určitého typu. Jméno proměnné (sestavujeme jej podle výše uvedených pravidel pro identifikátory) zastupuje adresu paměťového místa. Typ proměnné jednoznačně určuje, jak velký paměťový prostor má být na dané platformě vyhrazen pro uložení obsahu proměnné a jak má být inter-pretován.
Proměnné musíme před jejich použitím deklarovat. Deklarace počítači oznamuje, jak velké paměťové místo má být pro naši proměnnou rezervováno a jakým jménem se budeme na toto paměťové místo odkazovat.
3.1 Lokální a globální proměnné Podle umístění deklarace můžeme proměnné rozdělit na lokální a globální.
Lokální proměnná je deklarována v těle funkce11. Tato proměnná je pak dostupná jen v rámci této funkce a existuje jen po dobu jejího provádění. Jakmile tělo funkce opustíme (je vykonána poslední instrukce funkce či bloku), je paměťové místo, v němž byla proměnná uložena, uvolněno (vymaže se jeho adresa, a tím je ztracen i jeho obsah).
Globální proměnná je většinou deklarována mimo těla funkce. Tato proměnná existuje po celou dobu provádění programu a mohou k ní přistupovat všechny funkce, které jsou definovány za deklarací této proměnné. Základním programátorským pravidlem je používat globální proměnné pouze v nejnutnějších případech.
Deklarace sestává z typu proměnné (kolik bajtů je třeba v paměti rezervovat pro uložení obsahu proměnné) a z identifikátoru proměnné (jméno reprezentující adresu paměťového pro-storu pro uložení hodnoty).
Práci s lokálními a globálními proměnnými si vysvětlíme na jednoduchém příkladu. Později, až budeme probírat funkce, se k tomuto tématu ještě podrobněji vrátíme.
10 Existuje ještě několik dalších znaků, které jsou povoleny, ale s výjimkou podtržítka _ se nedoporučuje je
užívat. 11 Přesněji platí, že proměnné lze v C deklarovat na začátku bloku. Blok je ohraničen složenými závorkami –
vyskytuje se jako těla cyklů for či podmínky if. Je možné ho i vložit kamkoli v programu. Začátek bloku je kromě globální deklarace (před funkcí main) jediným místem programu, kde mohou být deklarovány pro-měnné.

identifikátory, typy dat, proměnné
- 15 -
#include <conio.h> int a = 10; // global variable void main( void) { int b = 20; // local variable cprintf( "Global: %d\r\n", a); getch(); cprintf( "Local : %d\r\n", b); getch(); }
Proměnná a je globální a je přístupná ze všech funkcí deklarovaných v programu níže. Proto můžeme její obsah vytisknout i uvnitř funkce main. Proměnná b je lokální. Existuje pouze v rámci funkce main, v níž je deklarovaná. Mimo funkci main není proměnná b přístupná.
Ve výše uvedeném výpisu si můžeme všimnout, že se v deklaraci globální proměnné a objevuje za jménem proměnné rovnítko následované celočíselnou hodnotou. Pomocí této konstrukce můžeme přímo v deklarační části programu nově vytvořenou proměnnou inicia-lizovat (na paměťové místo označené identifikátorem a ukládáme hodnotu 10).
Dále připomeňme:
• #include <conio.h> spojí náš program s knihovnou funkcí určených pro vytváření konzolových aplikací.
• void main( void) je hlavička funkce hlavní program. Náš hlavní program nemá žádný vstupní parametr (void v závorce) a žádný parametr výstupní (void vlevo).
• K tisku slouží funkce cprintf. Řetězec, který chceme zobrazit v příkazovém řádku, je vepsán do uvozovek. Za %d je do řetězce vložen obsah celočíselné proměnné a (první volání funkce) nebo b (druhé volání funkce). Řídicí znak \r přenese kurzor na začátek příkazového řádku, řídicí znak \n přenese kurzor na nový řádek.
• Funkce getch() slouží k načtení znaku z konzoly. Zde funkci používáme jako čekání na stisk klávesy.
3.2 Pravidla deklarování proměnných Jak je zřejmé z uvedeného výpisu, deklarování proměnné se řídí následujícími pravidly:
1. Na volném řádku uvedeme typ proměnné (v našem případě int).
2. Typ proměnné oddělíme mezerou od jména proměnné daného typu.
3. Pokud potřebujeme deklarovat více proměnných daného typu, jejich jména oddělujeme čárkami (např. int first, second, third;).
4. Řádek s deklarací je ukončen středníkem.
Dosud jsme se v našich příkladech setkali pouze s celočíselným typem proměnné int a ra-cionálním typem proměnné float. O dalších základních typech se dozvíme v následujícím odstavci.

identifikátory, typy dat, proměnné
- 16 -
3.3 Základní typy proměnných Vybrané základní typy proměnných jsou uvedeny v tab. 2.1. Proměnné z tabulky může-
me rozdělit do tří skupin:
Znakové char (znak ANSI znakové sady12), unsigned char (unsigned omezuje proměnnou pouze na kladné hodnoty).
Celočíselné int (32-bitové celé číslo se znaménkem), short int (short sníží možnou velikost celého čísla; ušetříme 16 bitů), unsigned int (unsigned omezuje proměnnou pouze na kladné hodnoty).
Racionální float (32-bitové číslo s plovoucí desetinnou čárkou a znaménkem), double (64-bitové číslo s plovoucí desetinnou čárkou a znaménkem), long double (long zvýší přesnost reprezentace racionálního čísla double).
Neštěstím jazyka C je skutečnost, že velikosti typů jsou závislé na použitém procesoru či pro-středí. Datové typy int a double by měly být nejpřirozenějšími typy z hlediska výpočtů pro danou platformu. Nejsou dány velikosti datových typů, ale pouze jejich relace (obsah menšího datového typu se vždy vejde do typu většího). Typy s pevnou velikostí jsou definovány v rámci normy v stdint.h. U PC Windows to je:
typ bitů rozsah unsigned char 8 X ∈ <0, +255> char 8 X ∈ <-128, +127> short int 16 X ∈ <-32.768; +32.767> unsigned int 32 X ∈ <0; +4.294.967.295> int 32 X ∈ <-2.147.483.648; +2.147.483.647> float 32 1,18 ⋅ 10-38 < |X| < 3,40 ⋅ 10+38 double 64 2,23 ⋅ 10-308 < |X| < 1,79 ⋅ 10+308 long double 80 3,37 ⋅ 10-4932 < |X| < 1,18 ⋅ 10+4932
Tab. 2.1 Vybrané základní typy proměnných Borland C++ Builderu13
Při výběru vhodného typu proměnné se rozhodujeme nejdříve mezi základními skupinami. Pro uložení znaku volíme skupinu char, pro uložení celočíselného indexu skupinu int, pro uložení racionálního čísla skupinu float-double. Podrobnější specifikaci typu uvnitř zvolené skupiny pak formulujeme pomocí tzv. modifikátorů (modifiers) unsigned, short, long … s ohledem na požadovaný číselný rozsah proměnné na jedné straně a na dostupnou velikost paměti na straně druhé.
Jakmile procesor vykoná úkony spojené s deklarací, je v paměti vytvořeno místo pro uložení hodnoty daného typu. Adresa tohoto paměťového místa je reprezentovaná proměn-nou. Např. pro float z je rezervováno v paměti 32 bitů a adresa tohoto prostoru je repre- 12 Každý znak je reprezentován odpovídajícím celočíselným ASCII kódem. Se znakovými proměnnými tedy
můžeme pracovat rovněž jako s celými čísly. 13 Aby to nebylo tak jednoduché, velikost typů se může mezi procesory měnit. Pro získání velikosti typu lze
použít operátor sizeof().

identifikátory, typy dat, proměnné
- 17 -
zentována identifikátorem z. Pokud deklaraci doplníme nepovinným přiřazením float z=3.14, je do vytvořeného paměťového místa přímo uložena hodnota 3.14. Přiřazení počá-tečních hodnot deklarovaným proměnným nazýváme inicializací.
V inicializační části deklarace se mohou vyskytovat i výrazy. Například při deklaraci int a = 3, b = 4; double c = 0.2*a + b;
je nejdříve vyčíslen výraz 0.2*a+b, a poté je vypočítaný výsledek uložen do proměnné c. Deklarace a inicializace proměnných a a b musí samozřejmě předcházet výše uvedenou de-klaraci a inicializaci proměnné c.
Vyčíslování výrazů při inicializaci proměnné c se liší v případě, kdy je c deklarováno jako globální proměnná (na začátku jednotky, mimo funkce) a kdy jako proměnná lokální (uvnitř některé z funkcí). V prvém případě je výraz v inicializační části vyčíslován jen jednou, a to na začátku programu. V druhém případě je výraz počítán při každém volání funkce znovu. Pokud je obsah proměnných a a b neměnný během vykonávání celého programu, je lepší inicializovat c jako globální proměnnou. Pokud se však obsah a a b během programu mění, nezbývá než c inicializovat lokálně.
3.4 Ukazatele Termínem ukazatel (pointer) rozumíme proměnnou, která je určena pro uložení adresy
určitého paměťového místa. Každý ukazatel musí být přitom spjatý s datovým typem, který je na dané adrese uložen.
Při čtení popisu ukazatelů v dalších odstavcích můžeme mít pocit, že z praktického po-hledu nejsou užitečné. O jejich užitečnosti se přesvědčíme později při probírání dynamických proměnných.
Deklarujeme-li v programu ukazatel, stačí nám do standardní deklarace přidat před jeho jméno symbol *. Tzn., int *b je ukazatel na celočíselnou proměnnou. Pokud chceme do ukazatele uložit adresu proměnné int a, použijeme zápisu b=&a. Pokud si chceme prohléd-nout obsah paměťového místa, jehož adresa je uložena v b, použijeme konstrukce c=*b (c je deklarováno jako celé číslo, obsah adresy uložené v b – tzn. hodnotu proměnné a – kopíru-jeme do proměnné c).
Práci s ukazateli si opět vysvětlíme na příkladu: #include <conio.h> void main( void) { float x = 3.14, y = 2.27; // 1 float* p; // 2 p = &x; // 3 address of x to p *p = y; // 4 cont. of y on address in p cprintf("In x, we have: %4.2f. \r\n",x); // 5 printing result getch(); }
V našem programu máme deklarovány dvě lokální racionální proměnné x a y. Obě proměnné jsou přímo v deklarační části naplněny konkrétními hodnotami. Po vykonání řádku 1 máme tedy v paměti uloženo na adrese &x číslo 3.14 a na adrese &y číslo 2.27.

identifikátory, typy dat, proměnné
- 18 -
Na řádku 2 deklarujeme ukazatel na racionální číslo p. Do proměnné p tedy můžeme uložit adresu již existujícího racionálního čísla (v našem případě buď &x nebo &y). Identifiká-tor p tedy reprezentuje adresu místa v paměti, které je určeno pro uložení adresy. Chceme-li se podívat na obsah proměnné, jejíž adresa je uložena v p, napíšeme *p. Přiřadíme-li p = &x, bude *p vracet hodnotu 3.14. Přiřadíme-li p = &y, bude *p vracet hodnotu 2.27. Situace je graficky znázorněna na obr. 3.1.
adresa
selektor : offset
proměnná
místo v paměti
&x x
&y y
p
3.14
2.27
&p
Obr. 3.1 Ukazatele.
V našem případě na řádku 3 do proměnné p vkládáme adresu proměnné x, na řádku 4 mění-me obsah místa v paměti s adresou uloženou v p – přiřazujeme do něj obsah proměnné y. Provedením příkazu na řádku 4 se tedy změní hodnota proměnné x, neboť v p byla uložena právě její adresa. Výsledkem příkazu na 5. řádku tím pádem bude výpis: In x, we have: 2.27
Pokud bychom napsali *x, kompilátor nás upozorní, že se jedná o nesmysl. Proměnná x není ukazatel, proměnná x reprezentuje datovou oblast pro racionální číslo, a proto nemůžeme prostřednictvím hvězdičky říci podívej se do datového prostoru, jehož adresa je uložena v x.
Naopak zápis &p je v pořádku. Ptáme se totiž na adresu, na níž je uložena adresa (uka-zatel) reprezentovaná proměnnou p, jak je znázorněno na obr. 3.1.
Následující program ukazuje poměrně častou chybu: void main( void) { int x=1; // 1 int *p; // 2 *p = x; // 3 – no address saved in p }
Na řádku 3 se snažíme změnit obsah místa paměti, jehož adresa je uložena v p. Jenže v p zatím není uložena žádná „rozumná“ adresa, obsah proměnné p nebyl inicializován, takže p může ukazovat na nějaké náhodné místo. Může to být místo zcela neškodné, takže zápisem na ně nic nepokazíme a program bude vypadat, že funguje normálně. Může se však také stát, že se budeme v paměti snažit přepsat nějakou důležitou informaci, což povede k chybě.
3.5 Pole Pole (array) je datová struktura tvořená několika složkami stejného typu. Počet složek
pole udáváme v jeho deklaraci v lomené závorce za jménem pole. Počet složek musí být klad-né celé číslo. Např. deklarace int d[3] zavádí pole d tvořené třemi složkami typu int.

identifikátory, typy dat, proměnné
- 19 -
Jelikož složky pole jsou indexovány od nuly, sestává naše pole ze tří celých čísel d[0], d[1] a d[2].
Má-li pole více indexů, objeví se v deklaraci za jménem pole více lomených závorek. Např. pole double d[2][2] sestává ze čtyř racionálních čísel d[0][0], d[0][1], d[1][0] a d[1][1].
Pole můžeme stejně jako prosté proměnné inicializovat přímo v deklarační části pro-gramu. U pole je deklarace doplněna složenou závorkou, která obsahuje počáteční hodnoty jeho složek double angle[5] = {0.0, 0.1, 0.2, 0.3, 0.4}.
A
0
1
2
3
4 A[4]
A[3]
A[2]
A[1]
A[0]
B
0 1
2 3
4 5
B[0][y]
B[1][y]
B[2][y]
B[x][0] B[x][1]
Obr. 3.2 Pole.
Práci s poli si vysvětlíme na jednoduchém příkladu. Budeme mít jednorozměrné pole tří celých čísel x, do něhož budeme ukládat velikosti úhlů ve stupních. Ke každé složce pole x chceme vypočítat hodnotu funkce sinus a výsledek uložit do odpovídající složky pole y. Abychom mohli pracovat s funkcí sinus, musíme propojit náš program s matematickou knihovnou math.h. V této knihovně je též definována konstanta π jako M_PI. Ludolfovo číslo π potřebujeme pro přepočítávání velikosti úhlů ze stupňů na radiány. Celý program může vypadat následovně: # include <conio.h> // library of console functions # include <math.h> // library of mathematical functions void main( void) { int x[3] = {30, 60, 90}, n; // array of angles, variable for cycles float y[3]; // array of functional values cprintf( "Functional values of sine:\r\n" ); cprintf("x sin(x)\r\n"); // printing headline for( n=0; n<3; n++) { y[n]=sin( x[n]*M_PI/180.0); // computing functional values cprintf("%d %f\r\n",x[n],y[n]); // printing results } getch(); }
Abychom nemuseli výpočtu každé funkční hodnoty a jejímu tisku do konzolového okna vě-novat zvláštní řádek zdrojového kódu, který by se lišil pouze hodnotou indexu pole, použili jsme cyklus for. Fungování cyklu for nyní vysvětlíme jen zhruba, ale později se k němu ještě vrátíme.

identifikátory, typy dat, proměnné
- 20 -
Cyklus for se používá tehdy, chceme-li nějaké příkazy provádět opakovaně s tím, že hodnota jisté proměnné (říká se jí řídicí proměnná cyklu) se postupně mění od určité počáteč-ní po určitou hodnotu koncovou. Např. v Pascalu cyklus for i:=1 to 10 do xxx provádí příkaz xxx postupně pro hodnoty řídicí proměnné i=1, i=2, ..., i=10. V jazyce C má cyklus for syntaxi14 for( init; cond; incr) tělo cyklu
Výrazem init nastavíme počáteční hodnotu řídicí proměnné, výrazem cond zadáme pod-mínku trvání cyklu a výrazem incr realizujeme zvýšení (nebo nějakou jinou změnu) řídicí proměnné po vykonání všech příkazů z těla cyklu. Dále tělo cyklu je příkaz nebo více příkazů, které se mají cyklicky opakovat. Je-li příkazů více, musí být ohraničeny složenými závorkami.
Zvláštní pozornost si zaslouží příkaz i++. Pomocí tohoto příkazu zvyšujeme hodnotu proměnné i o jedničku. Stejného výsledku bychom dosáhli příkazem i=i+1.
Je nutné zdůraznit, že kompilátor jazyka C žádným způsobem nekontroluje překročení hranice polí. Při logické chybě se tedy může stát, že náš program pracuje se složkami pole mimo rozsah, daný v deklaraci. Tento případ často nastává při chybné indexaci pole od jed-ničky namísto od nuly. Potom je poslední složka pole uložena do nedeklarované složky (tj. do paměťového místa mimo prostor vyhrazený deklarací), což může způsobit předčasné ukončení běhu programu.
Vše si můžeme ověřit na výše uvedeném příkladě – stačí nám změnit parametry cyklu for na ( n=1; n<4; n++). Program se bez problému zkompiluje a spustí, protože neobsa-huje žádnou chybu syntaxe, problémy mohou nastat až při jeho vykonávání. Proto musíme práci s indexy polí věnovat zvýšenou pozornost [3].
V dalším příkladu si vyzkoušíme práci s polem dvojrozměrným. Původní (original) dvojrozměrné pole znaků orig odpovídá dvěma slovům psaným nad sebou. Každé slovo sestává z pěti písmen. Našim úkolem je znaky zkopírovat do přepsaného (rewritten) pole rev tak, aby řádky byly přehozeny a slova plynula od konce. Jedno z možných řešení následuje: # include <conio.h> void main( void) { char orig[2][5] = {'t','a','m','t','o', // first word 's','a','l','e','k'}; // second word char rev[2][5]; // rearranged words int i; for(i=0;i<5;i++) // rearranging words { rev[0][i] = orig[1][4-i]; // first <- second rev[1][i] = orig[0][4-i]; // second <- first }
14 Je dobré si všimnout, za příkazem for není středník. Příkaz for zakončený středníkem by proběhl tolikrát,
kolikrát říká jeho hlavička, ale ve výsledku by nic neprovedl (vykonal by několikrát prázdný příkaz repre-zentovaný středníkem).

identifikátory, typy dat, proměnné
- 21 -
for(i=0;i<4;i++) // printing first word cprintf( "%c ", rev[0][i]); cprintf( "%c\r\n", rev[0][4]); // last character for(i=0;i<4;i++) // printing second word cprintf( "%c ", rev[1][i]); cprintf( "%c\r\n", rev[1][4]); // last character getch(); // waiting }
Význam jednotlivých řádků programu by měl být zřejmý z komentářů. Pokud tomu tak není, zkopírujme si zdrojový kód do Builderu a program krokujme – pak by mělo být vše jasné. Jen si prosím povšimněme, že při zadávání hodnoty znakové proměnné je daný znak uveden v jednoduchých uvozovkách. To je rozdíl oproti celému řetězci, který se vepisuje do uvozo-vek dvojitých. Chceme-li tisknout znak do příkazového řádku, jako parametr v řetězci po-užíváme %c.
Závěrečnou poznámku věnujme ještě dvojrozměrným polím. Na dvojrozměrné pole se můžeme dívat jako na matici. První index dvojrozměrného pole udává číslo řádku (číslováno od hodnoty 0), druhý index odpovídá číslu sloupce (opět číslováno od hodnoty 0). Při inicia-lizaci dvojrozměrného pole jsou číselné hodnoty ze složené závorky postupně ukládány po řádcích od levého horního rohu (indexy [0][0]) po pravý dolní roh.

výrazy, operátory, konverze
- 22 -
4 Výrazy, operátory, konverze Výrazem rozumíme konstrukci, která slouží k výpočtu hodnot. Výraz sestavujeme
z operandů a operátorů. Roli operandu přitom může hrát proměnná, konstanta nebo volání funkce, která vrací hodnotu. Operátorů obsahuje jazyk C velké množství, takže se seznámíme jen s těmi nejdůležitějšími.
Z hlediska počtu operandů můžeme operátory rozdělit na unární (jeden operand) a binární (dva operandy). Mezi unární operátory patří např. změna znaménka –a; – je unární operátor a a je operand. Mezi binární operátory patří např. součet a+b; + je binární operátor a a, b jsou operandy.
Operátory můžeme dělit podle účelu použití na aritmetické, logické, relační, přiřazovací a další. V našem textu se přidržíme tohoto druhého členění
4.1 Aritmetické konverze Aritmetické binární operátory mohou mít operandy různých typů. Dříve, než je prove-
dena operace přikazovaná operátorem, musí dojít ke sjednocení typu operandů (abychom např. při sčítání sčítali čísla reprezentovaná stejným počtem bitů). Výsledek operace je pak stejného typu jako operandy po konverzi.
Konverze typu operandů se řídí následujícími pravidly:
1. Všechny operandy typu char a všechny celočíselné operátory doplněné modifikátorem short jsou převedeny na typ int bez modifikátorů (celé číslo či znak jsou reprezento-vány 32 bity). U proměnné char tedy pracujeme s celočíselným ASCII kódem znaku.
2. Všechny operandy typu float (32 bitů) jsou převedeny na typ double (64 bitů).
3. Je-li jeden z operandů …
3.1 typu double, je i druhý operand převeden na typ double;
3.2 doplněn modifikátorem long, je rovněž druhý operand doplněn modifikátorem long;
3.3 doplněn modifikátorem unsigned, je rovněž druhý operand doplněn modifikátorem unsigned.
4. Nenastane-li žádný z výše uvedených případů, oba operandy musejí být typu int.
Aritmetické konverze si prakticky vyzkoušíme na jednoduchém programu: void main( void) { int a, b; double c, d;
a = 4/5; // - 1 - b = 4/5.0; // - 2 -
c = 4/5; // - 3 - d = 4/5.0; // - 4 - }

výrazy, operátory, konverze
- 23 -
• Na pravé straně řádku –1– jsou oba operandy typu int. Jelikož výsledek musí být stej-ného typu jako oba operandy, je celá pravá strana typu int (celé číslo). Protože celá část podílu 0.8 je nulová, bude celá pravá strana rovna nule. Nulovou hodnotu pravé strany uložíme do proměnné vlevo, takže a=0. Pokud bychom pravou stranu změnili např. na 8/5, byla by celá část podílu 1.6 jednotková a a=1.
V jazyce C se nejprve vypočte pravá strana a potom se teprve provede přiřazení. Proto není možné přizpůsobit typ výsledku na pravé straně typu na levé straně přiřazovacího operátoru (=).
• Na pravé straně řádku –2– je první operand typu int a druhý typu double. Podle pra-vidla (3.1) jsou tedy oba operandy převedeny na typ double a výsledek je téhož typu. Nicméně výsledek typu double přiřazujeme proměnné typu int. Do b je tedy zkopí-rována pouze celá část výsledku (b=0) a desetinná část je ignorována.
• Pravá strana řádku –3– je celočíselná (oba operandy jsou typu int). I když je tedy pro-měnná c deklarována jako racionální, bude c=0.
• Pravá strana řádku –4– je racionální (jelikož jeden operand je typu double, je i druhý operand konvertován na tento typ). A jelikož proměnná d je rovněž deklarována jako typ double, bude platit d=0.8.
I když tedy z matematického hlediska jsou všechny čtyři řádky našeho programu identické, z pohledu jazyka C se liší. Na automatické konverze datových typů, které za nás dělá překla-dač jazyka C, proto musíme dávat velký pozor15.
Dále si ještě vyzkoušejme, k jakým konverzím dochází u znakových proměnných: void main( void) { int a; char c = ′d′; a = c + 1; // - 1 - }
V jediném příkazu programu (řádek 1) je znak d uložený do znakové proměnné c nahrazen kódem znaku v ASCII tabulce (hodnota 100). K tomuto celočíselnému kódu je následně při-dána jednička, takže ve výsledku máme v proměnné a hodnotu 101. Této hodnotě odpovídá znak e.
4.2 Priorita operací Sestává-li výraz z více operátorů, jsou odpovídající operace prováděny v pořadí, daném
prioritou těchto operátorů. Např. ve výrazu a+b*c bude nejdříve vyčíslen součin b*c (náso-bení má vyšší prioritu než sčítání), a až poté bude výsledek přičten k operandu a. Pokud se jedná o operace stejné priority (např. a+b+c), u naprosté většiny operací dochází k vyhodno-cování výrazu zleva doprava (napřed je vyčíslen součet a+b, a poté je k výsledku přičten obsah proměnné c). U operací, kde je tomu naopak (vyhodnocování se děje zprava doleva) na to jmenovitě upozorníme.
15 Konverze, kterou jsme zmínili, se nazývá explicitní. Provádí ji kompilátor sám bez našeho zásahu. Občas ale
může být užitečné určit si přetypování ručně. V tom případě nastupuje tzv. implicitní konverze zapsaná jako (typ) výraz – např. (int) c/d; tím je výsledek dělení převeden na celé číslo.
výrazy, operátory, konverze
- 24 -
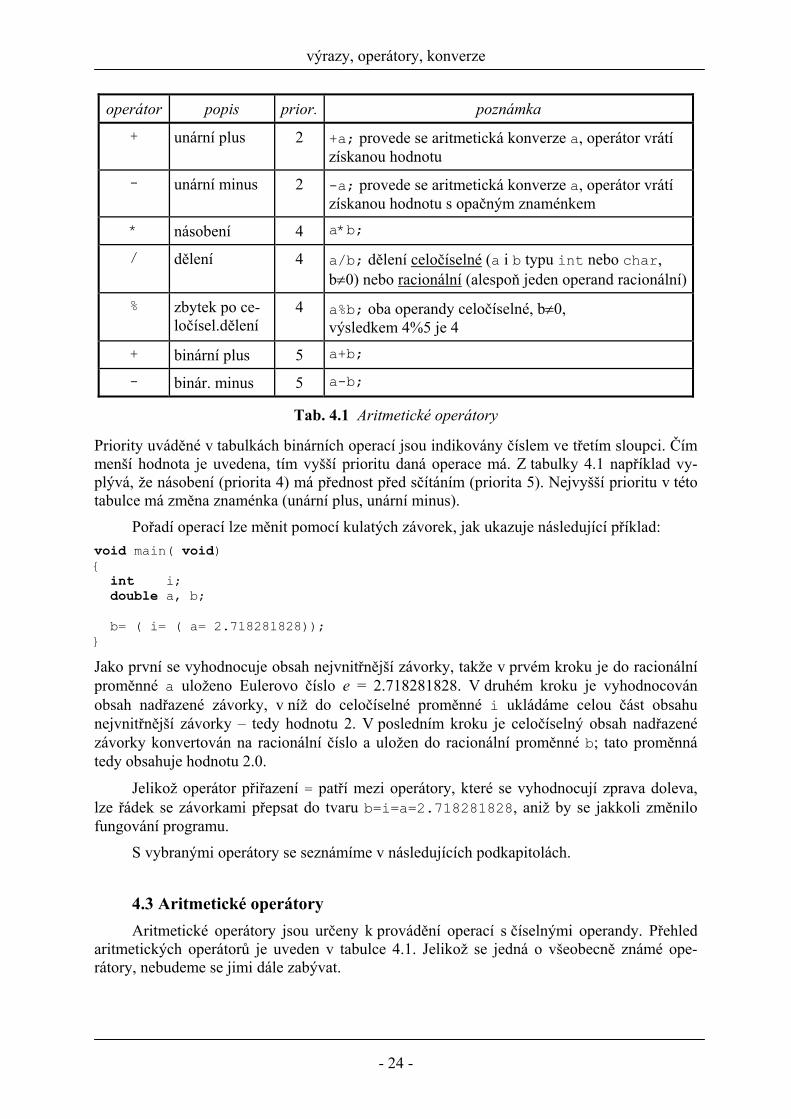
operátor popis prior. poznámka + unární plus 2 +a; provede se aritmetická konverze a, operátor vrátí
získanou hodnotu - unární minus 2 -a; provede se aritmetická konverze a, operátor vrátí
získanou hodnotu s opačným znaménkem * násobení 4 a*b;
/ dělení 4 a/b; dělení celočíselné (a i b typu int nebo char, b≠0) nebo racionální (alespoň jeden operand racionální)
% zbytek po ce-ločísel.dělení
4 a%b; oba operandy celočíselné, b≠0, výsledkem 4%5 je 4
+ binární plus 5 a+b;
- binár. minus 5 a-b;
Tab. 4.1 Aritmetické operátory
Priority uváděné v tabulkách binárních operací jsou indikovány číslem ve třetím sloupci. Čím menší hodnota je uvedena, tím vyšší prioritu daná operace má. Z tabulky 4.1 například vy-plývá, že násobení (priorita 4) má přednost před sčítáním (priorita 5). Nejvyšší prioritu v této tabulce má změna znaménka (unární plus, unární minus).
Pořadí operací lze měnit pomocí kulatých závorek, jak ukazuje následující příklad: void main( void) { int i; double a, b; b= ( i= ( a= 2.718281828)); }
Jako první se vyhodnocuje obsah nejvnitřnější závorky, takže v prvém kroku je do racionální proměnné a uloženo Eulerovo číslo e = 2.718281828. V druhém kroku je vyhodnocován obsah nadřazené závorky, v níž do celočíselné proměnné i ukládáme celou část obsahu nejvnitřnější závorky – tedy hodnotu 2. V posledním kroku je celočíselný obsah nadřazené závorky konvertován na racionální číslo a uložen do racionální proměnné b; tato proměnná tedy obsahuje hodnotu 2.0.
Jelikož operátor přiřazení = patří mezi operátory, které se vyhodnocují zprava doleva, lze řádek se závorkami přepsat do tvaru b=i=a=2.718281828, aniž by se jakkoli změnilo fungování programu.
S vybranými operátory se seznámíme v následujících podkapitolách.
4.3 Aritmetické operátory Aritmetické operátory jsou určeny k provádění operací s číselnými operandy. Přehled
aritmetických operátorů je uveden v tabulce 4.1. Jelikož se jedná o všeobecně známé ope-rátory, nebudeme se jimi dále zabývat.

výrazy, operátory, konverze
- 25 -
4.4 Relační operátory Relační operátory nám umožňují porovnávat obsah číselných proměnných, obsah pro-
měnných znakových (char) nebo ukazatele na stejný datový typ. Dále nám relační operátory umožňují vzájemné porovnání znakové hodnoty char s číselnými hodnotami. Přehled relač-ních operátorů je uveden v tabulce 4.2.
operátor popis prior.== rovná se 8 != nerovná se 8 < menší než 7 > větší než 7 <= menší než nebo rovno 7 >= větší než nebo rovno 7
Tab. 4.2 Relační operátory
Mají-li porovnávané proměnné číselný charakter, provede se nejdříve aritmetická konverze. Pak operátor vrátí hodnotu 1, pokud je relace splněna, a hodnotu 0, pokud splněna není. V pří-padě ukazatelů je považována za vyšší hodnotu ta, která ukazuje na vyšší adresu.
V následujícím příkladě si ukážeme porovnání dvou ukazatelů: void main( void) { int i = 10, j = 10; // - 1 - int *a, *b; // - 2 - int c; // - 3 - a = &i; // in a, the address of i is stored b = &j; // in b, the address of j is stored c = a==b; // are the addresses in a and b the same? getch(); }
Na prvním řádku deklarace alokujeme v paměti místo pro celočíselnou hodnotu, její adresu reprezentujeme symbolem i a do alokovaného místa paměti uložíme hodnotu 10. Totéž provedeme pro proměnnou j. Obě proměnné obsahují totéž číslo 10, ale adresy jsou různé (máme dvě nezávislá paměťová místa). V těle programu zmíněné adresy ukládáme do uka-zatelů a a b. Jelikož adresy v ukazatelích a a b se liší (v našem programu a = :0012FF88 a b = :0012FF84), operátor rovnosti == vrací hodnotu nepravda. V proměnné c je tedy uloženo číslo 0.
Další příklad na porovnávání je věnován znakům.

výrazy, operátory, konverze
- 26 -
void main( void) { int A[3] = {96, 98, 100}; // integer numbers char B[3] = {'a', 'b', 'c'}; // characters int n; for( n=0; n<3; n++) cprintf(" Is the number %d equal to character %c? %d\r\n", A[n], B[n], A[n]==B[n]); getch(); }
ASCII hodnoty znaků a, b a c jsou 97, 98 a 99. Při jejich porovnávání dává tedy operátor == hodnotu pravda jen v prostředním případě.
Velmi často se vyskytuje situace, kdy určité příkazy chceme provádět pouze v případě, že je splněna nějaká podmínka. Toho docílíme použitím konstrukce if (cond) make;
Příkaz make (případně více příkazů ohraničených složenými závorkami) se provede jedině v případě, že je výraz cond nenulový. Výraz cond velmi často (i když ne vždy) obsahuje právě některý z relačních operátorů.
Použití podmínky si ukážeme na jednoduchém příkladu. Máme dvě celočíselné pro-měnné, a a b, a chtěli bychom je uspořádat sestupně, tj. tak, aby proměnná a obsahovala větší a proměnná b menší z původních hodnot. Uspořádané hodnoty pak vypíšeme. void main( void) { int a = 3, b = 5; int temp; cprintf("Originally, a = %d and b = %d.\r\n",a,b); if ( a<b ) { temp = a; a = b; b = temp; } cprintf("Reordered, a = %d and b = %d.",a,b); getch(); }
V případě, že a bylo menší než b, hodnoty proměnných se prohodily. V opačném případě se nestalo nic. Výpis už nepatří do bloku příkazů za podmínkou, a provede se proto vždy.
Nyní upozorníme na častou a velmi zrádnou chybu. Jak již bylo řečeno, rovnost se zjišťuje pomocí operátoru ==. Z nepozornosti však programátor občas napíše rovnítko jen jedno. Co se pak stane, vysvětlíme na příkladu. V celočíselné proměnné marks jsou body, které získal student z programování. Jestliže získal plný počet bodů, chceme mu pogratulovat. if ( marks = 100 ) // this is NOT correct! cprintf("Congratulations! You are the best!");
V tomto případě namísto zjištění, zda se hodnota proměnné marks rovná 100, do proměnné marks hodnotu 100 uložíme. Protože výsledkem příkazu přiřazení je přiřazená hodnota, v tomto případě 100, podmínka bude splněna (hodnota výrazu v závorce za if není nulová) a výpis Congratulations… se objeví vždy, nezávisle na tom, kolik měl student původně

výrazy, operátory, konverze
- 27 -
bodů. Program se tedy bude chovat úplně jinak, než bychom chtěli. Abychom se chybě tohoto druhu vyhnuli, je vhodné sledovat hlášení kompilátoru. Příslušné varování je Possibly incor-rect assignment.
4.5 Logické operátory Logické operátory realizují základní logické operace – negaci, konjunkci (logický sou-
čin, někdy označujeme jako and) a disjunkci (logický součet, někdy označujeme jako or). Operandy musejí být buď číselné nebo se musí jednat o ukazatele. Přehled logických ope-rátorů je uveden v tab. 4.3.
Výsledek logické operace je vždy celočíselný (int). Výsledek pravda je stejně jako v případě operátorů relačních reprezentován hodnotou 1, výsledek nepravda hodnotou 0.
Operátor negace vrací hodnotu 1, je-li operand nulový, a vrací hodnotu 0, je-li operand nenulový. Operátor konjunkce vrací hodnotu 1, jsou-li oba operandy nenulové. V ostatních případech vrací operátor nulu. Operátor disjunkce vrací hodnotu 1, je-li alespoň jeden z ope-randů nenulový.
operátor popis prior.! negace 2 && konjunkce 12 || disjunkce 13
Tab. 4.3 Logické operátory
Rovněž pro logické operátory máme připraven příklad. V poli sales jsou uvedeny měsíční tržby krámku s lahvovým pivem. Našim úkolem je najít první měsíc, v němž byla tržba vyšší než 300 000 korun, a současně nižší než 400 000 korun. void main( void) { float sales[6] = { 228.3, 551.4, 289.0, 355.1, 380.0, 600.0}; int n; for( n=0; (sales[n]<300.0) || (sales[n]>400.0); n++); cprintf( "In the %dth month, the sales were %6.3f", n+1, sales[n]); getch(); }
Zadaný problém jsme se rozhodli řešit pomocí známého cyklu for. Cyklus běží tak dlouho, dokud je splněno, že tržby jsou menší než 300 tisíc nebo větší než 400 tisíc. Ve čtvrtém mě-síci dává jak prvé tak druhé porovnání nepravdu, takže i logický součet dává nepravdu a cyk-lus for končí. V proměnné n zůstane n=3 (čtvrtý měsíc). Za zmínku stojí skutečnost, že za cyklem for je uveden středník; v rámci cyklu se tedy nevykonává žádný příkaz a cyklus se používá jen k tomu, aby do doby nesplnění podmínky byl inkrementován obsah proměnné n.
Z výše uvedeného popisu by mělo být zřejmé, že program nepočítá s možností, že zadané podmínce neodpovídá žádný testovaný měsíc. V tomto případě by smyčka for pokračovala dále na porovnávání obsahu nedeklarovaných složek pole sales, což by mohlo způsobit havárii programu. Vyřešení popsaného problému necháváme na čtenáři.

výrazy, operátory, konverze
- 28 -
V následujícím příkladu předvedeme složitější kombinaci logických operátorů. Chceme zjistit, zda znaková proměnná c obsahuje písmeno anglické abecedy, přičemž nezáleží na tom, zda se jedná o písmeno malé či velké. if ( ( (c>='a') && (c<='z') ) || ( (c>='A') && (c<='Z') ) ) cprintf( "In c, there is a letter."); else cprintf( "In c, there is not a letter.");
Tentokrát jsme použili konstrukci if–else. Příkaz (případně skupina příkazů ve složených závorkách) uvedený za else se provede pouze v případě, že není splněna podmínka za if.
Nyní rozebereme podmínku: v proměnné c je malé písmeno, jestliže je mezi znaky a až z (včetně). Podmínku však nemůžeme napsat ve tvaru 'a'<=c<='z'16. Musíme ji rozepsat jako logický součin podmínek 'a'<=c a c<='z'. Podobně je to s velkými písmeny. Dohro-mady pak děláme logický součet podmínek „c je malé písmeno“ a „c je velké písmeno“.
Poznamenejme ještě, že závorky kolem jednotlivých výrazů v podmínce nebyly nutné, neboť relační operátory mají vyšší prioritu než logické a operátor && má vyšší prioritu než ||. Se závorkami je ale výraz čitelnější. Navíc, nejsme-li si jisti prioritou jednotlivých operátorů, závorkou navíc nic nezkazíme, zatímco závorka zapomenutá by nadělala spoustu škody.
4.6 Bitové operátory Bitové operátory pracují s jednotlivými bity operandů. Operand je operátorem chápán
jako pole bitů; operátor bere složku po složce (bit po bitu) a s každou postupně provede po-žadovanou operaci. Přehled bitových operátorů je uveden v tab. 4.4.
operátor popis prior.<< bitový posuv vlevo 6 >> bitový posuv vpravo 6 & konjunkce po bitech 9 | disjunkce po bitech 11 ^ nerovnost po bitech 10 ~ bitový komplement 2
Tab. 4.4 Bitové operátory
Bitové operátory můžeme rozdělit do dvou skupin, a to na operátory posuvu a na bitové lo-gické operátory.
Mezi operátory posuvu patří posuv vlevo o1<<o2 a posuv vpravo o1>>o2. Operandy o1 a o2 musejí být buď celočíselné nebo znakové. Při posuvu vlevo posouváme jednotlivé bity o1 o o2 pozic doleva. o2 uvolněných míst vpravo je zaplněno nulami. o2 prvních bitů operandu o1, které jsme jakoby vysunuli mimo, je ztraceno. Při posuvu vpravo je situace podobná. Mělo by být zřejmé, že o2 (o kolik pozic posouváme jednotlivé bity) musí obsa-
16 Syntakticky by nám taková podmínka prošla, ale nevyhodnocovala by se zrovna tak, jak bychom si předsta-
vovali.

výrazy, operátory, konverze
- 29 -
hovat nezáporné číslo, které je menší než počet bitů operandu o1; v opačném případě není výsledek definován.
bit A0
bit A1
bit A0&A1
bit A0|A1
bit A0^A1
bit ~A0
0 0 0 0 0 1
0 1 0 1 1 1
1 0 0 1 1 0
1 1 1 1 0 0
Tab. 4.5 Příklady bitových operací
Dále je dobré uvědomit si, že bitový posuv o jednu pozici doprava odpovídá dělení dvojkou a bitový posuv o jednu pozici doleva odpovídá násobení dvojkou.
Bitové logické operátory jsou obdobou výše vysvětlených operátorů logických (nebito-vých) s tím rozdílem, že jsou na hodnoty celočíselných nebo znakových proměnných apliko-vány bit po bitu. Výsledky bitové operace pro všechny možné kombinace hodnot bitů A0 a A1 jsou uvedeny v tab. 4.5. Několik konkrétních příkladů uvádíme níže: void main( void) { int a = 6, b = 13; // in binary form, 6 = (0110)2 and 13 = (1101)2 int c,d,e,f; c = a | b; // c <- (01111)2 = 15 d = a & b; // d <- (00100)2 = 4 e = a ^ b; // e <- (01011)2 = 11 f = a << 2; // f <- (11000)2 = 24 }
4.7 Operátory inkrementování a dekrementování Operátor inkrementování (++) zvýší obsah proměnné o jedničku, operátor dekremen-
tování (--) obsah proměnné o jedničku sníží. Je-li operátor ++ (--) umístěn za proměnnou, je nejprve vyčíslen výraz, v němž se proměnná vyskytuje, a až poté je zvýšen (snížen) obsah této proměnné. Pokud operátor ++ (--) umístíme před proměnnou, nejprve je zvýšen (snížen) obsah této proměnné, a až poté dochází k vyčíslení výrazu, v němž se tato proměnná nachází. To dokumentuje následující příklad: void main( void) { double r1, r2, a1=5.1, a2=5.1, b=4.2; r1 = a1++ + b; r2 = ++a2 + b; }
Jak proměnná a1 tak proměnná a2 obsahují po vykonání programu hodnotu 6,1 = 5,1 + 1 (výsledek inkrementování). Zatímco však v proměnné r1 je uloženo číslo 9,3 (nejprve byl vyčíslen součet 5,1 + 4,2, a až poté byla zvýšena hodnota a1 na 6,1), proměnná r2 obsahuje hodnotu 10,3 (nejprve bylo a2 inkrementováno na 6,1, a až poté byl vypočten celkový součet.
Operátory ++ a -- mají prioritu 2.

výrazy, operátory, konverze
- 30 -
4.8 Přiřazovací operátory Základní přiřazovací operátor je symbolizován znakem =. Máme-li výraz A1 = A2, je
nejprve vyčíslena pravá strana operátoru. Máme-li pravou stranu vyčíslenou, konvertujeme ji na týž typ, jakého je A1, a výsledek poté ukládáme do A1. Proměnné A1 a A2 musejí být buď aritmetické typy nebo ukazatele na stejné typy.
Přiřazovacímu operátoru může být předřazen symbol aritmetické operace (součet +, rozdíl -, násobení *, dělení /, celočíselné dělení %), logické operace (logický součin &, logic-ký součet |, logická nerovnost ^) nebo symbol bitového posuvu (posuv vlevo <<, posuv vpravo >>). Potom např. zápis a<<=b+c je ekvivalentní zápisu a = a<<(b+c).
Přiřazovací operátory mají prioritu 15.
Následující příklad ukazuje použití přiřazovacího operátoru s předřazenou operací ná-sobení; počítáme faktoriál čísla, které je uloženo v proměnné n. void main( void) { int n = 5, i, fact=1; for( i=1; i<=n; i++) fact *= i; // the same as fact = fact*i cprintf( "The factorial of the number %d is %d.", n, fact); getch(); }

řetězce, ukazatele
- 31 -
5 Řetězce, ukazatele Slovem řetězec (string) označujeme v jazyce C pole znaků, které je ukončeno speciál-
ním ukončovacím znakem null. Do pole šesti znaků tedy můžeme ukládat slova sestávající nejvýše z pěti znaků; šestá pozice musí být rezervována právě pro ukončovací znak. Vše by mělo být zřejmé z následujícího příkladu: void main( void) { char string_1[6] = {'a','b','c','\0'}; // - 1 - char string_2[6] = "ABCDE"; // - 2 - char *string_3 = "12345"; // - 3 - char string_4[ 6]; // - 4 - cprintf("1. retezec: %s\r\n", string_1); cprintf("2. retezec: %s\r\n", string_2); cprintf("3. retezec: %s\r\n", string_3); strcpy( string_4, string_1); cprintf("4. retezec: %s\r\n", string_3); getch(); }
První deklarace se na řetězec striktně dívá jako na pole znaků. Do string_1 lze uložit nej-výše 5 znaků; šestá pozice je rezervou pro null. V naší deklaraci vkládáme do řetězce tři znaky a na čtvrtou pozici dáváme null, abychom indikovali konec řetězce.
Druhá deklarace se liší pouze v inicializační části. Do dvojitých uvozovek vložíme znaky, z nichž řetězec sestává; ukončovací znak null je pak za poslední znak řetězce vložen automaticky. V předchozím jsme se s tímto zápisem řetězce setkali u funkce cprintf při specifikaci, jaký řetězec má být vytištěn do konzolového okna.
Řetězec můžeme rovněž chápat jako ukazatel na první znak. První znak potom ukazuje na znak druhý a vše pokračuje tak dlouho, dokud nenarazíme na ukončovací znak null. Velikost pole (a tedy i velikost paměťového místa pro uložení řetězce) je dimenzována podle počtu znaků v řetězci (v našem případě se opět jedná o pole 6 znaků – včetně ukončovacího null, který je opět do pole vložen automaticky.
Právě popsaný, třetí způsob deklarace řetězce není doporučeno používat. Je vždy lépe deklarovat řetězec druhým způsobem a pevně zadat dimenzi pole.
Čtvrtý řetězec je prázdným řetězcem (místo v paměti, reprezentované jménem string_4), není naplněno žádnými daty – nebo přesněji daty náhodnými. Tento řetězec je připraven k tomu, abychom do něj mohli při běhu programu uložit řetězec o nevýše pěti znacích.
Na dalších třech řádcích tiskneme obsah inicializovaných řetězců. Jak je vidět, para-metr, za nějž je při běhu programu řetězec dosazen, je indikován znaky %s.
Pokud chceme kopírovat obsah jedné řetězcové proměnné do druhé řetězcové proměn-né, nelze použít jednoduchý přiřazovací příkaz string_4 = string_1. Tento příkaz by vedl k pouhému zkopírování adresy prvého znaku. Aby byl řetězec zkopírován korektně, je

řetězce, ukazatele
- 32 -
k tomu nutno použít funkci strcpy (string copy) z knihovny string.h. Prvním parametrem funkce je řetězcová proměnná, do níž řetězec kopírujeme, druhým parametrem je pak řetězco-vá proměnná, z níž řetězec kopírujeme. Připomeňme, že na začátku programu nesmíme zapo-menout uvést #include <string.h>, aby byla funkce strcpy v našem programu dostupná.
Na dalším příkladu si ukážeme, jak lze s řetězci pracovat: void main( void) { char R[7] = "ABCDEF"; char S[7], T[7]; int n; for( n=0; n<6; n++) S[5-n] = *(R+n); S[6]='\0'; cprintf( "%s\r\n", S); getch(); // last -> first for( n=0; n<6; n++) T[n] = R[n]+32; T[6]='\0'; cprintf( "%s\r\n", T); getch(); // capital -> small }
V poli R máme uložen řetězec, který budeme zpracovávat. V prvém případě jej máme pře-skládat od posledního písmene k prvnímu a výsledek uložit do řetězcové proměnné S. V pří-padě druhém máme velká písmena převést na malá a výsledek uložit do proměnné T.
Jelikož dopředu víme, že náš řetězec sestává z šesti znaků (bez znaku null), můžeme pro zpracování řetězce použít cyklus for. U řetězce R, z něhož znaky bereme, postupujeme od nultého do pátého znaku. U řetězce S, do něhož znaky vkládáme, postupujeme od znaku pátého do znaku nultého. S řetězcem S pracujeme standardně jako s polem. Na jednotlivé znaky řetězce R se však díváme jako na ukazatele, jež adresují místo v paměti, v němž je uložen kopírovaný znak. Adresa nultého znaku je uložena v R, obsah paměťového místa, na které adresa ukazuje, získáme pomocí nám dobře známého zápisu *R. Napíšeme-li R+1, nezvyšujeme hodnotu adresy o jedničku, ale posouváme se na další složku pole. Zapsáním *(R+1) tedy dostáváme druhý znak řetězce.
Při převodu velkého písmene na malé využijeme skutečnosti, že kód malého písmene je v ASCII tabulce vyšší o hodnotu 32 ve srovnání s kódem písmene velkého. S řetězci nyní pracujeme jako s poli celočíselných kódů znaků. Kód uložený v n-té složce pole R zvýšíme o hodnotu 32 a uložíme do odpovídající složky pole T.
Nyní si ukážeme, jak lze výše uvedený program zobecnit tak, aby řetězce popsaným způsobem zpracovával bez ohledu na jejich délku. Využijeme k tomu funkci strlen (string length) z knihovny string, která vrací počet znaků řetězce před ukončovacím znakem null.

řetězce, ukazatele
- 33 -
void main( void) { char R[7] = "AB"; // only two characters are in the string char S[7], T[7]; int n, d=strlen(R); // strlen saves 2 to the variable d for( n=0; n<d; n++) S[d-1-n] = *(R+n); S[d]='\0'; cprintf( "%s\r\n", S); getch(); // last -> first for( n=0; n<d; n++) T[n] = R[n]+32; T[d]='\0'; cprintf( "%s\r\n", T); getch(); // capital -> small }
Konečně program můžeme ještě více zjednodušit voláním funkce strrev(R), která znaky v R přepíše v opačném pořadí, a voláním funkce strlwr(R), která velké znaky v R nahradí znaky malými. void main( void) { char R[7] = "AB"; strrev( R); cprintf( "%s\r\n", R); getch(); strlwr( R); cprintf( "%s\r\n", R); getch(); }
V následujícím příkladě si ukážeme spojení tří řetězců (tří slov) first, second a third do jediné věty final. Vzhledem k tomu, že spojování dvou řetězců je vytvářením jednoho pole znaků ze dvou polí znaků, nelze použít jednoduše operátor +, ale je třeba zavolat funkci strcat z knihovny string. Voláním strcat(R,T) dosáhneme toho, že řetězec T se připojí na konec řetězce R. void main( void) { char first[9] ="wine "; // word one char second[9]="women "; // word two char third[9] ="songs"; // word three char final[30]; // the sentence strcpy( final, first); // final <- first strcat( final, second); // final <- final + second strcat( final, third); // final <- final + third cprintf( "%s\r\n", final); getch(); }
V našem příkladě nejprve zkopírujeme do věty final první slovo first voláním kopírovací funkce strcpy. V druhém kroku voláním strcat připojíme za first slovo druhé, a dalším voláním strcat připojíme za second slovo třetí.

řetězce, ukazatele
- 34 -
V následujícím příkladu na práci s řetězci si ukážeme, jak lze v řetězci nalézt konkrétní znak a tento znak nahradit znakem jiným. Prohledávaným řetězcem je number, hledaný znak je uložen v proměnné digit a namísto hledaného znaku chceme do řetězce umístit písmeno x. void main( void) { char number[11]; // the processed number char digit = '8'; // the searched character char *ptr; strcpy( number, "1487265098"); // initializing number cprintf("An orig.string: %s\r\n", number); // unchanged string ptr = strchr( number, digit); // pointer to the first digit to ptr while( ptr) { *ptr = 'x'; // rewrite the digit by x ptr = strchr( number, digit); // search for a new digit } cprintf("A modif.string : %s", number); // print changed string getch(); }
K vyhledání znaku v řetězci využijeme funkci P=strchr(A,B), která v řetězci A najde znak B a ukazatel na tento znak uloží do P. Pokud v řetězci zadaný znak není nalezen, vrací funkce hodnotu null.
Abychom v našem čísle number odhalili a nahradili všechny číslice digit, použijeme příkaz cyklu pro neznámý počet iterací (nevíme totiž dopředu, kolikrát se číslice digit ve slově number nachází). Tím cyklem je while( cond) do, který opakuje příkaz do tak dlouho, dokud je podmínka cond nenulová. Budeme-li mít všechny znaky digit v našem čísle number zaměněny za x, vrátí strchr nulový ukazatel. Proto nám stačí do ukončovací podmínky příkazu while vložit proměnnou ptr.
Pokud se znak digit v řetězci number vůbec nenalézá, bude ptr obsahovat null a cyklus while neproběhne ani jednou. V opačném případě nahradíme obsah adresy odpovída-jící nalezenému znaku znakem x a novým voláním strchr se pokusíme vyhledat další znak digit v řetězci. Na závěr změněný řetězec pro kontrolu vytiskneme v konzolovém okně.
Výše uvedený program nyní modifikujme tak, aby v čísle number jednak nalezl pozici prvního výskytu číslice digit, a jednak aby spočítal výskyt všech číslic, aniž bychom je mu-seli nahrazovat znakem x:

řetězce, ukazatele
- 35 -
void main( void) { char number[11]; // the processed number char digit = '8'; // the searched character int cnt = 0; // the number of digits in the number int firstpos; // first position if the digit in number char *ptr; strcpy( number, "1487268898"); // initializing number ptr = strchr( number, digit); // pointer to the first digit to ptr if( ptr) // the number of char elements between ptrs firstpos = ptr - number; // i.e., the index of the first digit cprintf( "The first %c is at the %d position of %s\r\n", digit, firstpos+1, number); while( ptr) { cnt++; ptr = strchr( ptr+1, digit); // search for a next digit } cprintf( "There are %d digits %c in the number %s\r\n", cnt, digit, number); getch(); }
Nalezení pozice prvního výskytu číslice digit je realizováno jako rozdíl ukazatelů. V pro-měnné ptr je uložen ukazatel na první nalezenou číslici digit, v proměnné number je ukazatel na první znak řetězce. Odečteme-li oba ukazatele od sebe, získáme informaci o počtu znaků mezi prvním výskytem digit a počátkem řetězce.
Počítání znaků digit bez jejich náhrady znakem x je založeno na drobné modifikaci výše uvedeného cyklu while. Při prohledávání řetězce se posuneme o jednu pozici za nale-zený znak (ptr+1) a ten znovu prohledáváme. Nalezneme-li znak digit, do ptr uložíme ukazatel na tento znak (a znaky následující).
V dalším příkladu ukážeme rozdělení řetězce, který se skládá ze dvou slov oddělených dvojicí znaků čárka – mezera, na jednotlivá slova. Vše bude nejprve provedeno bez pomoci funkcí z knihovny string (projdeme řetězec po jednotlivých znacích), ve druhé verzi jsou pak funkce pro práci s řetězci z knihovny string hojně využity. Poznamenejme, že program bude správně fungovat pouze v případě, že původní řetězec má očekávaný tvar.

řetězce, ukazatele
- 36 -
void main( void) { char s[10] ="Adam, Eve"; // two words separated by a comma char first[5]; // first word char second[5]; // second word int i, pos; for( i=0; s[i]!=','; i++) first[i]=s[i]; // copying the part before the comma pos = i; // pos <- the position of comma first[i]= '\0'; // including the end character for ( i=0; s[i+pos+2]!= '\0'; i++) second[i]=s[i+pos+2]; // copying the part after comma second[i]= '\0'; // including the end character cprintf("The first word: %s\r\n", first); cprintf("The second word: %s\r\n", second); getch(); }
V první části programu kopírujeme jednotlivé znaky řetězce s do řetězce first tak dlouho, dokud nenarazíme na čárku. Po skončení cyklu bude pozice čárky uložena v proměnné i. Cyklus totiž ukončila podmínka, že v řetězci s na pozici i je právě čárka. Hodnotu i si zapa-matujeme – uložíme ji do proměnné pos – a pokračujeme v kopírování, tentokrát do řetězce second. Protože musíme vynechat i mezeru za čárkou, posouváme se o pos+2. Znaky přepi-sujeme do té doby, dokud v řetězci s nenajdeme ukončovací znak.
Nyní stejný problém vyřešíme pomocí funkcí pro práci s řetězci: #include <string.h>
void main( void) { char s[10] ="Adam, Eve"; char first[5],second[5]; char *p; int pos; p = strchr(s, ','); // finding comma in s pos = p-s; // pos <- the position of comma strncpy(first,s,pos); // copying the first pos characters first[pos]= '\0'; // including the end character strcpy(second,p+2); // copying the part after comma cprintf("The first word: %s\r\n", first); cprintf("The second word: %s\r\n", second); getch(); }
Funkci strchr již známe – pomocí ní najdeme ukazatel na místo, kde je v řetězci s čárka. Pozici čárky pak zjistíme tak, že od tohoto ukazatele odečteme ukazatel na začátek řetězce s. Dále překopírujeme prvních pos znaků (má-li čárka pozici pos, díky indexování od nuly je před ní v řetězci právě pos znaků) z řetězce s do řetězce first. Toho dosáhneme pomocí funkce strncpy(kam,odkud,n), která zkopíruje do řetězce kam prvních n znaků řetězce odkud (pokud řetězec odkud tolik znaků obsahuje; pokud je kratší, na zbývající místa vloží znaky null). Nevkládá však na konec automaticky ukončovací znak null (leda právě v pří-padě, že kopírujeme náhodou řetězec až do konce), o to se musíme postarat sami. Nakonec

řetězce, ukazatele
- 37 -
zkopírujeme zbytek řetězce s do řetězce second. K tomu použijeme už dobře známou funkci strcpy. Tentokrát ale chceme kopírovat až od určitého znaku, ne od začátku řetězce. Proto funkci strcpy jako druhý parametr zadáme adresu místa, odkud chceme kopírování začít, což je v našem případě o dva znaky za mezerou (abychom přeskočili i čárku), takže příslušný ukazatel je p+2.
Stejného výsledku bychom dosáhli i zápisem strcpy(second,&s[pos+2]).
Příkladů na práci s řetězci lze vymyslet celou řadu. Proto další procvičování necháváme na fantazii každého z nás…

příkazy
- 38 -
6 Příkazy Program je v podstatě posloupnost příkazů, které procesor postupně provádí. Pokud
speciální příkaz nezpůsobí přenesení řízení do jiné části programu nebo pokud speciální pří-kaz nezpůsobí přerušení programu, jsou příkazy plněny sekvenčně.
Nejjednodušším příkazem v jazyce C je prázdný příkaz. Řádek s prázdným příkazem obsahuje pouze středník, který tento příkaz ukončuje. Prázdný příkaz využijeme s výhodou tehdy, když potřebujeme přenést řízení do jiné části programu: if( err) goto end; // pokud došlo k chybě (err!=0), skoč na end c++; // jinak inkrementuj end: ; // prázdný příkaz, označený návěštím
Konstrukce goto end přenáší řízení programu na řádek, který začíná konstrukcí end: (tzv. návěštím). Pokud se objeví chyba (obsah proměnné err je nenulový), neinkrementujeme ob-sah proměnné c, protože skočíme na prázdný příkaz, umístěný na posledním řádku.
Stejný význam jako prázdný příkaz má rovněž prázdný blok {}.
O něco málo složitějším příkazem je příkaz výrazový. Mezi výrazové příkazy řadíme přiřazení, volání funkcí a podobné konstrukce. Jako příklad si uveďme: C++; A = cos( b) + c;
S výrazovými příkazy se setkáváme od našeho prvního programu.
Třetím elementárním příkazem je blok (složený příkaz). Složený příkaz použijeme v případě, kdy je jazykem C striktně vyžadováno volání jediného příkazu, avšak pro požado-vané fungování programu je nutno použít příkazů více. Složený příkaz vytvoříme z posloup-nosti příkazů tak, že tuto posloupnost uzavřeme do složených závorek.
Složený příkaz může obsahovat další složený příkaz (další blok). Potom mluvíme o blo-ku vnořeném a bloku nadřazeném.
Kromě posloupnosti příkazů může složený příkaz obsahovat rovněž deklarace nových proměnných. Proměnné, které deklarujeme uvnitř bloku, existují pouze po dobu, kdy jsme v tomto bloku (neopustíme jeho složené závorky). Pokud uvnitř vnořeného bloku deklarujeme proměnnou stejného jména, jaké nese proměnná v bloku nadřazeném, lokální proměnná za-stíní proměnnou globální. Tento jev demonstrujeme na krátkém, nepříliš praktickém příkladu: void main( void) { int a = 1; { int a = 2, b = 3; cprintf("Inside the block:"); cprintf("In a, we have %d", a); cprintf(" and in b, we have %d.", b); } cprintf("\r\nOutside the block:"); cprintf("In a, we have %d.", a); getch(); }

příkazy
- 39 -
Výsledný výpis bude: Inside the block: In a, we have 2 and in b, we have 3. Outside the block: In a, we have 1.
Kdybychom se vně bloku pokusili o výpis b, kompilátor by ohlásil chybu, protože proměnná b v ten moment už není definována.
6.1 Příkazy pro větvení programu Příkazy pro větvení programu bývají označovány jako příkazy podmíněné nebo výbě-
rové. Podle toho, zda je či není splněna určitá podmínka, je totiž vybrána určitá alternativa dalšího pokračování programu.
Mezi příkazy pro větvení patří náš dobrý známý if. Doposud jsme ho používali ve for-mě if( cond) make; (je-li splněna podmínka cond, vykonej příkaz make). Příkaz však lze rozšířit přidáním alternativy: if( cond) make_this; else make_that; (při splnění podmínky cond vykonej příkaz make_this, při nesplnění podmínky cond vykonej příkaz make_that).
Použití příkazu if si vysvětlíme na následujícím příkladu. Ve dvojrozměrném poli people je v prvém sloupci uložena nula, pokud se jedná o muže, a jednička, pokud se jedná o ženu. Ve druhém sloupci pole je uložena informace o hmotnosti osoby. Naším úkolem je vypočíst průměrnou hmotnost mužů a průměrnou hmotnost žen. void main( void) { int people[10][2] = {{0,101},{0,67},{0,83},{1,46}, {1,67},{0,121},{1,78},{1,54},{1,77},{0,56}}; float men=0, women=0; int num=0, n; for(n=0;n<10;n++) { // printing the gender and the weight cprintf("%d %d\r\n", people[n][0], people[n][1]); if( people[n][0]==0) // if the person is man { men += people[n][1]; num++; // the number of men } else // otherwise the person is woman women += people[n][1]; } men /= num; // the average weight of men women /= (10-num); // the average weight of women cprintf("average weight of men : %6.2f\r\n", men); cprintf("average weight of women: %6.2f\r\n", women); getch(); }
Předpokládáme, že máme informace o celkem 10 osobách. Proto příkazem for vytvoříme cyklus, který v 10 bězích postupně zpracuje každou osobu. V rámci cyklu for nejprve volá-ním funkce cprintf vytiskneme do konzolového okna informaci o pohlaví a hmotnosti kaž-dé osoby. Příkazem if testujeme, zda se jedná o muže nebo o ženu. V proměnné men akumu-lujeme hmotnost mužů, v proměnné num počet mužů v množině osob a v proměnné women akumulujeme hmotnost žen. Podělením akumulované hmotnosti mužů počtem mužů dostává-

příkazy
- 40 -
me jejich průměrnou hmotnost. Totéž provedeme pro ženy a výsledky vytiskneme do konzo-lového okna.
Dalším příkazem pro větvení je switch (přepínač). Přepínač používáme v případech, kdy chceme nabídnout více potenciálních možností pokračování programu nežli dvě. Toho lze samozřejmě dosáhnout kombinací několika příkazů if, avšak takové konstrukce bývají vět-šinou dosti nepřehledné.
Použití přepínače si předvedeme na předchozím programu, týkajícím se hmotnosti. Mo-difikovaný program má kromě průměrné hmotnosti mužů a žen počítat i hmotnosti mládeže (tu označuje dvojka v prvním sloupci). V případě, že se v prvním sloupci nachází jiná hodnota než povolené 0, 1 a 2, zvýšíme o jedničku počítadlo chybně zadaných údajů: void main( void) { int people[10][2] = {{0,101},{2,67},{0,83},{4,46}, {1,67},{0,121},{1,78},{1,54},{1,77},{2,56}}; float men=0, women=0, kids=0; int im=0, iw=0, ie=0, n; for(n=0;n<10;n++) { cprintf("%d %d\r\n", people[n][0], people[n][1]); switch( people[n][0]) { case 0: men +=people[n][1]; im++; break; case 1: women+=people[n][1]; iw++; break; case 2: kids +=people[n][1]; break; default: ie++; } } cprintf("average weight of men : %6.2f\r\n", men/im); cprintf("average weight of women: %6.2f\r\n", women/iw); cprintf("average weight of women: %6.2f\r\n", kids/(10-im-iw-ie)); cprintf("the number of errors : %d\r\n", ie); getch(); }
Přepínač je označen klíčovým slovem switch. V závorce za ním je uveden celočíselný nebo znakový parametr. Potenciální hodnoty parametru udáváme za klíčová slova case. Za hodno-tou parametru následuje dvojtečka a sekvence příkazů, které se mají vykonat v případě, kdy parametr nabude odpovídající hodnoty. Sekvence příkazů je ukončena klíčovým slovem break, které zamezí prohledávání dalších možností case. Sekce default se vykoná v pří-padě, kdy hodnota parametru není nalezena u žádného case.
Nyní si na příkladu ukážeme, co se stane, když v přepínači zapomeneme řádek s case ukončit příkazem break. Program se pak chová možná trochu překvapivě. V našem příkladu je parametrem přepínače znaková proměnná c. switch( c) { case 'a': cprintf("Alpha"); break; case 'b': cprintf("Bravo"); case 'c': cprintf("Charlie"); default : cprintf("Something else"); }

příkazy
- 41 -
Protože příkaz pro case 'b' není ukončen příkazem break, program bude pokračovat dál, jenže už se nebude kontrolovat, je-li parametr c roven hodnotě uvedené za case. Budou se vykonávat všechny další příkazy ve všech následujících větvích, dokud se nenarazí na break nebo dokud se nedojde na konec bloku přepínače. Výsledné výpisy proto budou vypadat takto:
• pro c == 'a': Alpha • pro c == 'b': BravoCharlieSomething else • pro c == 'c': CharlieSomething else • pro c něco jiného: Something else
Toto chování se na první pohled může zdát podivné, ve skutečnosti však má svůj význam. Využijeme je v případě, když chceme provádět totožné příkazy pro několik různých hodnot parametru. To ukazuje následující příklad.
V proměnné pp je počet piv, která vypil Pepa (a aspoň jedno vypil určitě). Cílem je napsat, kolik piv Pepa vypil, a to gramaticky správně. cprintf("Pepa vypil %d ",pp); switch (pp) { case 1: cprintf("pivo."); break; case 2: case 3: case 4: cprintf("piva."); break; default: cprintf("piv."); break; } getch();
Krokováním programu v Builderu si můžeme ověřit, zda program pracuje správně či nikoli.
6.2 Příkazy pro cykly Příkazy pro cykly slouží k násobnému opakování určité sekvence příkazů. Počet opako-
vání sekvence může být buď známý (zpracováváme data všech žáků ve třídě) nebo neznámý (počítáme funkční hodnotu funkce tak dlouho, dokud nenalezneme hodnotu minimální).
V našich příkladech jsme se již setkali s jedním zástupcem skupiny příkazů pro cykly, a to s příkazem for. Obecně můžeme tento příkaz zapsat jako for(init,cond,update) make. Výrazem init provedeme počáteční nastavení pro spuštění cyklu. Výraz cond před-stavuje podmínku, která musí být splněna (výraz musí mít nenulovou hodnotu); v opačném případě je cyklus ukončen. Výrazem update aktualizujeme obsah proměnných po ukončení každého cyklu. Slovo make reprezentuje příkaz, který vykonáváme tak dlouho, dokud platí podmínka cond.
Pomocí cyklu for můžeme napsat jednoduchý program, který najde největší číslo ze zadané pětice racionálních čísel: float number[5] = {1.27E-2, 7.93E+1, 3.27E+0, 9.91E+1, 6.61E+1}; float max = 1e-5; // extremely low value of maximum int n; // for the control of the cycle for( n=0; n<5; n++) // for n=0 to n<5, at the end inkcrement n if( number[n]>max) max=number[n]; // if the number is higher than max, save it to max

příkazy
- 42 -
V našem případě vykonáváme příkaz if pětkrát. Od počáteční hodnoty n=0 pokračujeme sekvencí n=1,2,3,4; pak přestává platit podmínka n<5. Inkrementaci n po vykonání každé-ho cyklu nám předepisuje aktualizace n++.
Upozorněme, že ani jeden výraz v kulaté závorce za for není povinný. To znamená, že i zápis for(;;) je v pořádku. Tento zápis představuje nekonečnou smyčku. Rovněž je zají-mavé, že obsah proměnných vystupujících v kulaté závorce za for můžeme měnit z těla cyklu (v žádném případě to však nedoporučujeme).
Dalším příkazem cyklu, který nám jazyk C dává k dispozici, je while(cond) make. Je-li podmínka cond vyhodnocena jako pravdivá, je vykonán příkaz make. Poté je zahájen druhý cyklus novým vyhodnocením podmínky cond, novým podmíněným vykonáním příka-zu make. Cyklus končí v okamžiku, kdy je cond vyhodnocena jako nepravdivá.
Použití cyklu while si můžeme ukázat na jednoduchém vyhledávání kořene rovnice y = x2 – 1. Na začátku uložíme do proměnné x hodnotu 0.05. Postupně budeme tuto hodnotu zvyšovat o přírůstek 0.1 tak dlouho, dokud nedosáhneme nejmenší funkční hodnoty (v abso-lutní hodnotě): double x = 0.05, // starting value of the variable y, // actual functional value min = 100.0; // high former functional value while( (y=fabs( x*x-1.0))<min) // if actual functional value < former { min = y; // save actual functional value x += 0.1; // do the next step } x -= 0.1; // return one step back
Nutnost posunutí x o krok zpátky je dána tím, že cyklus končí v situaci, kdy aktuální funkční hodnota je větší než funkční hodnota předchozí. Musíme se tedy vrátit k předchozí hodnotě, která byla blíže nule.
V uvedeném programu jsme poprvé použili funkci fabs. Funkce fabs je definována ve standardní matematické knihovně math, takže na začátek jednotky musíme umístit direktivu # include <math.h>. Funkce fabs počítá absolutní hodnotu z racionálního čísla.
Dále si všimněme obsahu kulaté závorky za klíčovým slovem while. V této závorce nejdříve (díky závorkám) vypočteme aktuální funkční hodnotu fabs( x*x-1.0), tuto hod-notu uložíme do proměnné y, a konečně porovnáme předchozí a aktuální funkční hodnotu pro podmínečné vykonání cyklu. Možnostmi efektivního zápisu zdrojového kódu je jazyk C pro-slulý.
Posledním příkazem pro cykly je konstrukce do-while. Základní odlišnost příkazu do-while od samotného příkazu while spočívá v tom, že tělo cyklu nejdříve vykonáme a až poté testujeme splnění podmínky. Zatímco u příkazu while se může stát, že tělo cyklu není vykonáno ani jednou (protože ani napoprvé není splněna podmínka), u příkazu do-while je tělo nejméně jednou vykonáno vždy (nejdřív vykonávám, potom testuji).
Stejný program pro jednoduché vyhledání minima naší funkce bychom mohli s použi-tím do-while vytvořit například takto:

příkazy
- 43 -
double x = 0.05, // starting value of the variable y, // actual functional value min = 100.0; // high former functional value y=fabs( x*x-1.0); // compute actual functional value do // UNCONDITIONALY do: { min = y; // save actual functional value x += 0.1; // do the next step } while( (y=fabs( x*x-1.0))<min); // until the condition is not met x -= 0.1; // return one step back
Funkce programu by měla být zřejmá z komentářů.
6.3 Příkazy pro přenos řízení Jednotlivé příkazy, z nichž program v jazyce C sestává, jsou vykonávány postupně
jeden za druhým. Pokud potřebujeme tuto přirozenou posloupnost příkazů přerušit a řízení programu přenést do jiného místa (tj. na jinou instrukci než tu, která následuje za instrukcí aktuální), využijeme k tomu příkazy pro přenos řízení.
První dva příkazy pro přenos řízení – break a continue – můžeme použít pouze v tělech cyklů (for, while, do) nebo v těle přepínače (switch). Použití zmíněných příkazů kdekoli jinde znamená chybu.
Použití příkazu break způsobí přerušení cyklu, z jehož těla je příkaz volán. Narazíme-li tedy uprostřed 5. iterace cyklu od nuly do devíti na break, druhá polovina 5. iterace a šestý až devátý cyklus nebudou vykonány. Příkaz continue ukončí právě probíhající iteraci cyklu a přejde k prvnímu příkazu další iterace. Narazíme-li tedy uprostřed 5. iterace cyklu od nuly do devíti na continue, druhá polovina 5. iterace nebude vykonána a cyklus bude pokračovat od počátku šesté iterace dále.
Příkaz continue použijeme ke korekci špatně zadaného čísla při výpisu do konzolo-vého okna. Pokud se v řetězci, v němž má být uloženo znakové vyjádření čísla, objeví jiné znaky než číslice a desetinná tečka, je před voláním funkce cprintf aktuální iterační krok přerušen a je zahájen další iterační cyklus: void main( void) { char dist[10] = "59a0.c2"; // an invalid number int test, n; for( n=0; dist[n]!='\0'; n++) // through the whole string { test = (dist[n]>='0') && (dist[n]<='9'); // truth for zero to nine test = test || (dist[n]=='.'); // truth for dot if( !test) continue; // if not truth ... cprintf("%c", dist[n]); // printing is skipped } getch(); }
Nyní program modifikujme tak, aby při odhalení nekorektního znaku došlo k přerušení výpisu čísla do konzolového okna a namísto toho byla zobrazena informace o tom, na které pozici se nachází nekorektní znak:

příkazy
- 44 -
void main( void) { char dist[10] = "59a0.c2"; // an invalid number int test, n; for( n=0; dist[n]!='\0'; n++) // through the whole string { test = (dist[n]>='0') && (dist[n]<='9'); // truth for zero to nine test = test || (dist[n]=='.'); // truth for dot if( !test) // if not truth ... { // printing the error message cprintf("\r\n\n...%dth position\r\n", n+1); getch(); break; // leaving the cycle for } cprintf( "%c", dist[n]); } getch(); }
Tím jsme si probrali základní příkazy jazyka C. Jejich abecední seznam uvádíme v podkapito-le 6.5.
6.4 Příklad Na závěr se pokusme vyřešit komplikovanější příklad. Uživatel může do konzolového
okna napsat jednoduchou větu sestávající z podmětu, přísudku v minulém čase a předmětu. Našim úkolem je určit, zda se jedná o větu oznamovací nebo tázací, a zda je věta formulována v záporu či nikoli. V podstatě se jedná o rozhodnutí, do které z níže uvedených čtyř skupin věta náleží:
• Oznamovací bez záporu (táta volal mámu). • Oznamovací se záporem (máma nevolala tátu). • Tázací bez záporu (volal táta mámu). • Tázací se záporem (nevolala máma tátu).
Dříve, než se pustíme do vymýšlení algoritmu pro realizaci programu, vyřešíme problém načtení věty z konzolového okna, do kterého ji vepíše uživatel programu. Naše oblíbená knihovna konzolových funkcí conio.h nám k tomu nabízí funkce cscanf a cgets.
Začněme funkcí cscanf( char *form, addr).
Prvním parametrem je řetězec form, který nám určuje formát načítaného údaje. V pří-padě řetězce za form dosadíme ”%s”, v případě načítání racionálního čísla (float) bychom psali ”%f”.
Druhým parametrem je adresa proměnné, do níž budeme načítané údaje ukládat. V pří-padě řetězce dosadíme za addr přímo jméno proměnné (jak již bylo řečeno, reprezentuje ukazatel na první znak), v případě racionální proměnné float dosadíme za addr výraz &a (jak již víme, &a nás informuje o adrese, na níž je obsah proměnné a uložen).
Načtení věty určené pro další zpracování si vyzkoušejme na jednoduchém programu, který má za úkol načtenou větu vytisknout na nový řádek konzolového okna:

příkazy
- 45 -
void main( void) { char sent[ 60]; // the sentence to be proceed float a; cscanf( "%s", sent); // reading string from the console cprintf( "\r\n%s", sent); // reprinting string to the console getch(); getch(); // waiting ... }
Spustíme-li uvedený program, získáme pouze první slovo věty, protože funkce cscanf skončí načítání řetězce po prvním bílém znaku17, tzn., že mezerník načítání z konzoly ukončí, přičemž ukončovací mezera je již zpracována funkcí getch. Proto getch voláme dvakrát, abychom měli čas přečíst si, co se v konzolovém okně vlastně odehrálo.
Pro načtení řetězce včetně bílých znaků slouží funkce char *cgets(char *str). Načítání řetězce se ukončí po načtení ukončujícího znaku (klávesa Enter) nebo po dosažení maximálního počtu načítaných znaků; informaci o maximálním počtu znaků musíme vložit do nulté složky pole str před voláním funkce cgets.
Funkce cgets vrací ukazatel na první znak načítaného řetězce. Parametrem funkce cgets je pomocný řetězec str, jehož délka je o dvě složky větší, nežli je délka načítaného řetězce. Do první složky pole str funkce cgets vepíše počet skutečně načtených znaků a od druhé složky se objevují znaky zadané uživatelem programu.
Načítání věty a její kontrolní tisk by v případě použití funkce cgets vypadal takto: void main( void) { char *sent, buff[ 62]; // the sentence and the buffer buff[0] = 60; sent = cgets( buff); // reading string from the console cprintf( "\r\n%s", sent); // reprinting string to the console getch(); // waiting ... }
V porovnání s předchozím programem došlo ve zdrojovém textu ke čtyřem změnám:
1. Vytvořili jsme pomocný řetězce buff, který je o dvě složky větší ve srovnání s před-pokládanou délkou načítaného řetězce (na tři slova věty včetně mezer si rezervujeme 60 znaků).
2. Řetězec sent, do kterého budeme ukládat načtenou větu, deklarujeme jako ukazatel na znak (dimenzi pole určí funkce cgets).
3. Do nulté složky pole buff jsme uložili hodnotu 60 (předpokládaný počet znaků ve větě).
4. Mohli jsme odebrat jedno volání funkce getch. Ukončí-li uživatel zadávání řetězce stiskem klávesy Enter, funkce cgets vloží do odpovídající složky pole ukončovací znak null a předá řízení programu následné instrukci.
Spustíme-li druhou verzi programu, vše již funguje podle našich představ.
Nyní se můžeme věnovat samotnému algoritmu. Postupovat budeme v následujících krocích: 17 Bílé znaky (white spaces) jsou důležité znaky, které se nezobrazují na monitoru. Jedná se např. o mezeru,
tabulátor, skok na nový řádek, návrat na začátek řádku, atd.

příkazy
- 46 -
1. Rozhodneme, zda se jedná o oznamovací nebo tázací větu. Uvažujeme, že sloveso v minulém čase má na poslední pozici (volal) nebo pozici předposlední (volala, volalo) znak l. Sloveso může být prvním slovem (tázací věta) nebo slovem druhým (věta ozna-movací). Testujeme tedy přítomnost znaku l o jednu nebo dvě pozice před mezerou. Po-kud je znak l odhalen u prvního slova, bere se první slovo za sloveso.
2. Rozhodneme, zda je ve větě zápor či nikoli. Z bodu 1 známe pozici slovesa. Větu bu-deme považovat za zápornou, pokud prvními dvěma písmeny slovesa budou ne.
3. Vypíšeme výsledky.
Celý program (včetně načítání řetězce z konzoly) by tedy mohl vypadat následovně: #include <string.h> #include <conio.h> void main( void) { char *sent, buff[ 62]; // the sentence and the buffer char copy[ 60]; // a copy of the read string char *ptr; // for searching characters int word=0, gap=0; // what word is verb, what character is space buff[0] = 60; // the sentence can consist of 60 characters sent = cgets( buff); // reading a string from the console strlwr( sent); // all the letters converted to the small ones strcpy( copy, sent); // copying the read string ptr = strchr( copy, 'l'); // is l in the sentence? if( ptr) // yes, l is there { do // searching for l before the space { ptr = strchr( copy, ' '); // serching for the space *ptr = 'x'; // replacing space by x word++; // what word is the verb gap = strlen( copy) - strlen( ptr); // which one character is the gap } while( !(sent[gap-1]=='l' || sent[gap-2]=='l')); if( word==1) // the verb is the first word if( sent[0]=='n' && sent[1]=='e') cprintf("\r\nAn interrogative (tazaci) negative sentence\r\n"); else cprintf("\r\nAn interrogative (tazaci) positive sentence\r\n"); else // the verb is the second word { ptr = strchr( sent, ' '); if( *(ptr+1)=='n' && *(ptr+2)=='e') cprintf("\r\nAn indicative (oznamovaci) negative sentence\r\n"); else cprintf("\r\nAn indicative (oznamovaci) positive sentence\r\n"); } } else // no, l is not there cprintf("\r\nNo verb in past in the sentence\r\n"); getch(); // waiting ... }

příkazy
- 47 -
V deklarační části nám k řetězcům buff a sent, které používáme k načtení věty z konzoly, přibyl řetězec copy pro zálohování načtené věty a řetězec ptr pro vyhledávání zadaných znaků. Do celočíselné proměnné word budeme ukládat informaci o tom, kterým slovem ve větě je sloveso (zda prvým či druhým). V celočíselné proměnné gap je uložen index mezery ve větě.
V prvním bloku programu načteme větu a uložíme ji do řetězce sent. Všechna písmena ve větě sent převedeme voláním funkce strlwr na malá (usnadňujeme si tím následné testování) a kopii věty uložíme do řetězce copy. Následně voláním funkce strchr otestu-jeme, zda se ve větě nachází alespoň jedno písmeno l. Pokud tomu tak není (funkce strchr uloží do ptr nulový ukazatel), příkaz if nás přenese na tisk varování, že zadaná věta ne-obsahuje sloveso v minulém čase.
Pokud se ve větě alespoň jedno písmeno l nachází, cyklem do–while opakujeme hle-dání mezery mezi slovy tak dlouho, dokud jedno nebo dvě pozice před mezerou není znak l18. Při každém odhalení mezery tuto mezeru nahradíme v kopii věty znakem x (abychom při dal-ším vyhledávání nevyhledali tutéž mezeru) a zvedneme počítadlo slov word o jedničku. Pozi-ci mezery určíme jako rozdíl počtu znaků v celé větě a počtu znaků v úseku věty za mezerou.
Pokud je sloveso na první pozici (proměnná word obsahuje hodnotu 1), jedná se o tá-zací větu; pro určení záporu nás stačí testovat první dva znaky celého řetězce. Pokud je slo-veso na druhé pozici (obsah proměnné word je různý od jedničky), nalezneme první mezeru ve větě a testujeme následující dva znaky.
Tím je program zhruba hotov. V dalším kroku doporučujeme ověření jeho činnosti kro-kováním.
6.5 Abecední seznam příkazů break Přeruš vykonávání celého cyklu.
continue Přeruš vykonávání aktuální iterace v rámci cyklu.
do make while(cn) Vykonávej příkaz make tak dlouho, dokud je splněna pod-mínka cn.
for(init;cn;up) make Vykonávej příkaz make tak dlouho, dokud je splněna pod-mínka cn. Inicializace cyklu je dána parametrem init. Pří-kaz up se vykoná na konci každého iteračního cyklu.
goto lab Program přejde na řádek označený návěštím lab; návěštím je první identifikátor na řádku, ukončený dvojtečkou.
if(cn) d1; else d2 Pokud je splněna podmínka cn, je vykonán příkaz d1; v opač-ném případě je vykonán příkaz d2.
switch(vl) case 1: do break; default do; Přepínač dle hodnoty vl vybírá po-mocí case odpovídající příkaz. Pokud hodnota vl není u žád-ného case nalezena, vykoná se příkaz ze sekce default.
while(cn) make Vykonávej příkaz make tak dlouho, dokud podmínka cn je splněna.
18 V našem programu není ošetřen stav, kdy se znak l nachází jinde než na posledních dvou pozicích prvních
dvou slov. Ošetření tohoto stavu můžeme vytvořit v rámci vlastního procvičování práce s příkazy.

funkce
- 48 -
7 Funkce Při pohledu na zdrojový kód mnoha programů si můžeme všimnout, že se některé jeho
části ve výpisu vícekrát opakují. Kvůli tomu je pak zdrojový kód zbytečně dlouhý a málo pře-hledný. Uvedený problém můžeme vyřešit pomocí funkcí.
Pokud procesor při vykonávání programu narazí na volání funkce, je adresa instrukce následující za voláním funkce uložena do tzv. zásobníku19 a řízení programu je přeneseno na první instrukci v těle funkce. Následně je vykonávána posloupnost instrukcí, které tvoří tělo funkce. Jakmile procesor vykoná poslední instrukci těla funkce, je ze zásobníku vybrána návratová adresa a řízení programu se vrátí instrukci, která následuje po řádku s voláním funkce.
Opakuje-li se ve zdrojovém kódu programu vícekrát stejná sekvence instrukcí, je vhod-né vytvořit z této sekvence tělo funkce a namísto opakování stejné sekvence příkazů volat funkci. Z hlediska vykonávání programu se nic nemění. Zdrojový kód programu je však kratší a přehlednější.
Dosud jsme se setkali pouze s funkcí main reprezentující hlavní blok programu. Jelikož náš program neměl žádný vstupní parametr, uváděli jsme do závorky za jméno funkce klíčové slovo void (prázdný parametr). Jelikož náš program žádnou hodnotu nevracel, uváděli jsme klíčové slovo void rovněž nalevo od jména funkce.
Jako příklad funkce s jedním vstupním parametrem a jedním parametrem výstupním si naprogramujme pow3, která bude vracet třetí mocninu racionálního čísla a bude ji tisknout do konzolového okna. Funkci pak budeme volat v programu, který má vypočíst třetí mocniny čísel uložených v poli inp a uložit do pole out. Celý program by mohl vypadat následovně: #include <conio.h> float pow3( float A) // the third power of A { float y = A*A*A; cprintf("The third power of %5.2f is: %5.2f\r\n", A, y); return y; } void main( void) { float out[3], inp[3] = {1.1, 2.2, 3.3}; int n; for( n=0; n<3; n++) out[n] = pow3( inp[n]); // calling pow3 getch(); }
19 Zásobník (stack) je speciální typ paměti, z níž vybíráme jako první tu hodnotu, kterou jsme do paměti uložili
jako poslední. Do zásobníku se samočinně ukládají návratové adresy při volání funkcí. Pokud tedy rekurziv-ně voláme nějakou funkci, při každém novém volání se návratová adresa uloží do zásobníku. Pokud funkci v rekurzi voláme mnohokrát, ukládáme návratovou adresu do zásobníku mnohokrát, a zásobník může přetéci (vyčerpáme jeho kapacitu).

funkce
- 49 -
Při deklarování funkce se vstupním parametrem musíme do závorky za jméno funkce uvést typ a jméno parametru. Na toto jméno se pak odvoláváme v těle funkce vždy, když chceme hodnotou z parametru pracovat.
Jakmile máme hodnotu, kterou má funkce vrátit, vypočtenu, uvedeme ji (jméno pro-měnné, v níž je hodnota uložena) za klíčové slovo return. Toto klíčové slovo se postará o předání této hodnoty (v našem případě předáváme složce pole out) a o návrat z těla funkce zpět do hlavního programu. Z toho vyplývá, že za příkazem return již nesmí žádné další instrukce následovat (pokud následují, jsou ignorovány).
Právě popsaný program se nyní pokusme modifikovat tak, aby byl schopen počítat obecně n-tou mocninu čísla, kde n je číslo celé: #include <conio.h> #include <math.h> float pow_n( float A, int n) { // 2 inputs, 1 output float y = 1; int k; for( k=1; k<=fabs(n); k++) y *= A; if( n<0) y=1/y; cprintf("%dth power of %5.2f is %5.2f\r\n",n,A,y); return y; } void main( void) { float out[3], inp[3] = {1.1, 2.2, 3.3}; int n; for( n=0; n<3; n++) out[n] = pow_n( inp[n], n+1); // calling pow_n getch(); }
Při deklaraci funkce pow_n je celočíselný mocnitel uveden jako její druhý parametr. Vzájem-né součiny mocněnce počítáme v cyklu for, jehož horní limit je dán právě hodnotou moc-nitele.
V předchozích příkladech popsané volání funkce nazýváme voláním hodnotou. Z pro-měnné uvedené při volání funkce v závorce za jménem funkce se vezme pouze hodnota, ta se zkopíruje do lokální proměnné A vytvořené voláním funkce, a dále se zpracovává. Jakmile je běh funkce ukončen, daná lokální proměnná a s ní i její obsah zanikají. Obsah proměnné, z níž jsme hodnotu převzali, nám funkce nijak nezmění. Toto chování si předvedeme na pří-kladu. Pokusíme se napsat funkci, která navzájem vymění hodnoty dvou proměnných. Tato funkce nebude vracet žádnou hodnotu, uvedeme ji proto slovem void.

funkce
- 50 -
void swap( int a, int b) // this will NOT work! { int temp; temp = a; a = b; b = temp; } void main( void) { int m = 3, n = 2; cprintf("Originally, m = %d and n = %d.\r\n",m,n); swap( m,n); cprintf("After swapping, m = %d and n = %d.\r\n",m,n); getch(); }
Výsledkem tohoto pokusu bude výpis Originally, m = 3 and n = 2. After swapping, m = 3 and n = 2.
Obsahy proměnných se nevyměnily, protože funkci swap byly předány pouze kopie hodnot proměnných m a n. Výměna se provedla s těmito kopiemi, samotných proměnných m a n se akce vůbec nedotkla.
Pokud chceme, aby se vše, co s předanými hodnotami v rámci funkce provádíme, pro-mítlo do proměnných, v nichž jsou uloženy, namísto hodnoty předáváme odkaz (ukazatel) na tuto proměnnou. Popsané volání funkce nazýváme voláním odkazem.
Správná verze funkce pro prohození hodnot a následné použití této funkce vypadá takto: void swap( int *a, int *b) { int temp; temp = *a; *a = *b; *b = temp; } void main( void) { int m = 3, n = 2; cprintf("Originally, m = %d and n = %d.\r\n",m,n); swap( &m,&n); cprintf("After swapping, m = %d and n = %d.\r\n",m,n); getch(); }
V tomto případě jsou vstupní parametry ukazatele na typ int. Při volání funkce pak předá-váme adresy proměnných m a n. Tyto adresy jsou sice opět zkopírovány do dočasných proměnných, jenže uvnitř funkce pak pracujeme s obsahy těchto adres, tedy se skutečnými hodnotami proměnných m a n.
Častým případem, kdy též používáme volání parametru odkazem, je situace, kdy máme funkci, která má vracet nějakou hodnotu, ale pro jisté hodnoty vstupních parametrů tato hod-nota není definovaná. Můžeme zařídit, aby i v tomto případě funkce určitou hodnotu vracela, např. nulu, ale jak pak rozlišíme, zda došlo k chybě či zda je nula náhodou opravdu správný výsledek? Funkci proto předáme ještě jeden parametr, do kterého bude uložena jednička nebo nula, podle toho, zda k chybě došlo nebo nedošlo. Takovéto ošetření možného chybového stavu ukážeme opět na funkci pro výpočet n-té mocniny. V příkladu uvedeném před chvílí

funkce
- 51 -
jsme zanedbali možnost, že bychom počítali zápornou mocninu nuly, což nelze. Teď to na-pravíme: float pow_n( float A, int n, int *err) { float y = 1; int k; *err = ( A==0 && n<=0 ); // -- 1 -- if (*err) return 0; // -- 2 -- for( k=1; k<=fabs(n); k++) y *= A; if (n<0) y = 1/y; return y; } void main( void) { float x,y; int n,e; cprintf("Computation of the n-th power of x: "); cprintf("\r\nx = ");cscanf("%f",&x);getch(); cprintf("\r\nn = ");cscanf("%d",&n);getch(); y = pow_n(x,n,&e); if (e) cprintf("\r\nError!"); else cprintf("%dth power of %5.2f is %5.2f\r\n",n,x,y); getch(); }
Všimněme si, že ve funkci pow_n se dvakrát vyskytuje return. Jestliže vstupní parametry byly nepřípustné, tj. základ mocniny byl nulový a exponent záporný nebo nulový, funkce díky příkazu return 0 vrátila jako výsledek nulu a skončila, tj. další příkazy v ní uvedené už se neprováděly. Jestliže chyba nenastala, funkce pokračovala dál výpočtem n-té mocniny, a na závěr byla jako výsledek vrácena hodnota proměnné y.
Poznamenejme ještě, že místo příkazů na řádcích označených 1 a 2 bylo možno napsat jediný příkaz, a to if (*err = ( A==0 && n<=0 )) return 0;
Takovýto program by byl o trochu efektivnější, zvláště pro začátečníka však hůře čitelný.
Chceme-li, aby funkce vypočítala třetí mocninu čísla a uložila ji do původní proměnné, můžeme psát:

funkce
- 52 -
void pow_3( float *A) { *A = (*A)*(*A)*(*A); cprintf("3rd power is %5.2f\r\n",*A); } void main( void) { float y = 2.2; pow_3( &y); getch(); }
Pokud jsou vstupními parametry funkcí pole, předává se funkci ukazatel na první složku pole. Automaticky tedy dochází k předávání parametrů odkazem. Chceme-li, aby funkce fungovala univerzálně pro pole jakékoli délky, předáme jí jako druhý parametr délku pole. V následující ukázce budeme mít funkci, která najde maximální hodnotu v celočíselném poli libovolné délky. int maximum( int *a, int N) { int k, max=a[0]; for( k=1; k<N; k++) if (a[k]>max) max = a[k]; return max; } void main( void) { int A[10],B[5],maxA,maxB; ... // getting the values of A and B somehow maxA = maximum(A,10); maxB = maximum(B,5); cprintf("The maximum value of array A is %d.\r\n",maxA); cprintf("The maximum value of array B is %d.\r\n",maxB); getch();
}
Při volání funkce maximum jsme jako parametr předali přímo A, což reprezentuje adresu začátku pole A. Stejně dobře jsme mohli napsat maximum(&A[0],10).
Jiná možnost, jak předávat pole coby parametr funkce, je vytvořit si vlastní typ a mít pak ve funkci parametr tohoto typu. Tento způsob je vhodný, hodláme-li funkci používat pro pole nebo matici pevných rozměrů.
Vytvořme funkci add_mtx, která sečte matice A a B a výsledek loží zpět do A. Dále vytvořme funkci print_mtx, která matici vytiskne do konzolového okna. Celý program by pak mohl vypadat například takto:

funkce
- 53 -
#include <conio.h> typedef int t_mtx[3][3] ; void add_mtx( t_mtx A, t_mtx B) { int m, n; for( m=0; m<3; m++) for( n=0; n<3; n++) A[m][n] = A[m][n] + B[m][n]; } void print_mtx( t_mtx X) { int m, n; for( m=0; m<3; m++) { for( n=0; n<3; n++) cprintf( " %d", X[m][n]); cprintf("\r\n"); } cprintf("\n\n"); getch(); } void main( void) { t_mtx A = { 1, 2, 3, 4, 5, 6, 7, 8, 9}; t_mtx B = {10,20,30,40,50,60,70,80,90}; print_mtx( A); print_mtx( B); add_mtx( A, B); print_mtx( A); }
Jedinou novinkou, která se ve výše uvedeném výpisu vyskytuje, je definování našeho vlast-ního datového typu (direktiva typedef). Za touto direktivou následuje deklarace tak, jak jsme na ni zvyklí. Rozdíl je v tom, že jméno t_mtx není jménem proměnné, ale jménem datového typu. Ke standardním datovým typům jako float či char tedy přidáváme vlastní typ t_mtx.
Nyní si ukážeme, že funkce mohou být nejprve deklarovány, zatímco jejich definice (celé tělo funkce) může následovat až později. Tohoto faktu budeme využívat především při sestavování vlastních knihoven.
Zatím jsme vždy své vlastní funkce definovali na začátku souboru, a teprve potom následovala funkce main. Dá se to však udělat i tak, že nejprve napíšeme tzv. deklarace funkcí (pouze jejich hlavičky ukončené středníkem), pak funkci main, a pak teprve budou následovat celé funkce (jejich tzv. definice). Ukážeme si to na příkladu, ve kterém najdeme minimum funkce f na intervalu [a, b]; ve skutečnosti hledáme jen minimum funkčních hodnot v bodech a, a+h, a+2h,..., b, kde h je zadaný krok.

funkce
- 54 -
#include <conio.h> double f(double x); // declaration of function f double min(double a, double b, double h);// declaration of function min void main( void) { double a,b,h,xmin,ymin; ... // reading a,b and h xmin = min(a,b,h); ymin = f(xmin); cprintf("\r\nThe minimum value is achieved at x = %lf.",xmin); cprintf("\r\nThe function value is y = %lf.",ymin); getch(); } double min( double a, double b, double h) // definition of function min { double x=a, xm=a, ym=f(a); while ( x<=b) { if ( f(x)<ym) { xm = x; ym = f(x); } x += h; } return xm; } double f( double x) // definition of function f { return (x*x-1); }
Když nyní při překladu kompilátor narazí ve funkci main na volání funkce min, je „spoko-jen“, i když definována tato funkce zatím nebyla. Z deklarace „ví“, že funkce min opravdu má mít tři parametry typu double a má vracet hodnotu téhož typu. Propojení se „skutečnou“ funkcí min pak obstará tzv. linker, který v přeloženém souboru (s příponou obj) najde funkci tohoto jména a na patřičné místo zapíše její adresu.
7.1 Programové jednotky, hlavičkové soubory
Pokud bychom si vytvořili více funkcí např. pro práci s maticemi a pokud bychom chtěli tyto funkce využívat ve více programech, je výhodné vytvořit si z nich vlastní knihovnu – obdobu nám známých knihoven conio, stdlib či math.
Každá knihovna sestává ze dvou soubo-rů – souboru hlavičkového (header, přípona h) Obr. 7.1 Hlavičkový a zdrojový soubor.

funkce
- 55 -
a souboru zdrojového (přípona c). V hlavičkovém souboru uvádíme hlavičky funkcí a dekla-race proměnných, které musejí být vidět zvenčí.
Hlavičkový soubor pak pomocí direktivy #include vložíme do hlavního zdrojového souboru. Touto direktivou dáváme pokyn tzv. preprocesoru20, aby na místo, kde je tento pří-kaz uveden, vložil (čistě textově) obsah souboru zadaného jména. Tzn. efekt je úplně stejný, jako kdybychom na uvedené místo potřebné deklarace napsali „ručně“. Zdrojový soubor (přípona c) musí být připojen k našemu projektu, protože linker hledá funkce pouze v soubo-rech s příponou obj, které k projektu patří. Pokud tento soubor dále popsaným způsobem nově vytváříme v Borland C++ Builderu, bude k projektu připojen automaticky. Pokud hodláme použít knihovnu již hotovou, k projektu ji připojíme tak, že v menu zvolíme Project → Add to Project..., a pak pomocí dialogu vybereme příslušný soubor.
Vytváříme-li svou vlastní knihovnu v programu Borland C++ Builder, vybíráme odpo-vídající položky ze stejného dialogu, v němž nastavujeme základní parametry konzolové aplikace při jejím vytváření. Hlavičkový a zdrojový soubor musejí mít stejné jméno a musejí být uloženy ve stejném adresáři jako naše aplikace. V našem příkladě jsme zvolili pojmeno-vání matrix.c a matrix.h.
Hlavičkový soubor bude v našem případě obsahovat definici našeho datového typu t_mtx a hlavičky funkcí add_mtx a print_mtx: typedef int t_mtx[3][3]; void add_mtx( t_mtx A, t_mtx B); void print_mtx( t_mtx X);
Zdrojový soubor bude v našem případě obsahovat implementaci funkcí add_mtx a print_mtx a bude do něj též vložen obsah hlavičkového souboru. Tím budou na začátku uvedeny deklarace funkcí (což by v tomto případě ani nebylo nutné) a definice našeho dato-vého typu t_mtx (což nutné je, protože ve funkcích se s ním pracuje):
20 Preprocesor upravuje soubor před samotnou kompilací. Vynechává komentáře, vkládá hlavičkové soubory
apod. Veškeré úpravy jsou pouze textové, s jazykem C vlastně nemají nic společného. Příkazy pro prepro-cesor začínají symbolem #.

funkce
- 56 -
#include <conio.h> #include "matrix.h" void add_mtx( t_mtx A, t_mtx B) { int m, n; for( m=0; m<3; m++) for( n=0; n<3; n++) A[m][n] = A[m][n] + B[m][n]; } void print_mtx( t_mtx X) { int m, n; for( m=0; m<3; m++) { for( n=0; n<3; n++) cprintf( " %d", X[m][n]); cprintf("\r\n"); } cprintf("\n\n"); getch(); }
Konečně soubor s hlavním blokem programu vypadá následovně: #include <conio.h> #include "matrix.h" void main( void) { t_mtx A = { 1, 2, 3, 4, 5, 6, 7, 8, 9}; t_mtx B = {10,20,30,40,50,60,70,80,90}; print_mtx( A); print_mtx( B); add_mtx( A, B); print_mtx( A); getch(); }
Zatímco standardní knihovny jsou při zahrnování do programu uváděny v ostrých závorkách, naše vlastní knihovny uvádíme v uvozovkách. Jestliže je naše knihovna uložena v tomtéž adresáři jako celý projekt, stačí napsat za #include do uvozovek pouze jméno hlavičkového souboru, jako jsme to udělali zde. Kdyby naše knihovna byla v jiném adresáři (což je u slo-žitějších knihoven nebo u knihoven, které hodláme používat ve více aplikacích, možná vhod-nější), museli bychom napsat i absolutní nebo relativní cestu k souboru, např.: #include "C:\MyPrograms\MatrixLibrary\matrix.h" // absolutní cesta #include "..\MatrixLibrary\matrix.h" // relativní cesta
Pokud vše proběhne správně, dostaneme v konzolovém okně výsledky, jak jsou uvedeny v obr. 7.2.

funkce
- 57 -
Obr. 7.2 Výsledky programu na výpočet matic v konzolovém okně.
Na závěr našeho povídání o programových jednotkách si ještě popišme různé možnosti kom-pilace našeho programu. Ty jsou uvedeny v submenu programu Borland C++ Builder Project:
• Compile Unit slouží k přeložení aktuální programové jednotky z jazyka c (soubor s pří-ponou c) do strojového kódu (soubor s příponou obj). Kód v jazyku c, který je psán na relativně vysoké (abstraktní) úrovni je tak převeden na sekvenci instrukcí na nízké (kon-krétní) úrovni. Instrukce strojového kódu jsou instrukce, kterým rozumí procesor. Jedná se o instrukce přesunu dat mezi registry, o přičtení čísla z registru k obsahu akumulátoru, atd.
• Make Project pracuje stejně jako příkaz Compile Unit s tím rozdílem, že z jazyka C do strojového kódu překládáme všechny programové jednotky, z nichž náš program (pro-jekt) sestává. Přeložené jednotky však zůstávají nepropojeny.
• Built Project pracuje stejně jako příkaz Make Project s tím rozdílem, že přeložené modu-ly ve strojovém kódu jsou navzájem propojeny do jediného výsledného binárního soubo-ru (přípona exe). O propojení jednotlivých modulů do výsledného binárního kódu se stará tzv. linker.
Při kompilování složitějších projektů je dobré nejprve přeložit a odladit jednotlivé knihovny. Pokud proběhne překlad knihoven bez potíží, přejdeme k propojení knihoven linkerem a k testování programu jako celku.
7.2 Rekurze funkcí Rekurzním voláním funkce označujeme situaci, kdy ve svém těle funkce volá sebe
samu. To znamená, že k novému volání funkce dochází ještě před dokončením jejího běhu.
V jazyku C je rekurzní volání funkcí povoleno. Hloubka rekurze (počet současně plat-ných volání) není přitom teoreticky omezena. Praktické omezení je dáno velikostí zásob-níku21.
Rekurzi funkcí si ukážeme na programu pro výpočet faktoriálu. Jak dobře víme, fakto-riál čísla N spočítáme jako součin f(N) = N ⋅ (N–1) ⋅ (N–2) ⋅ … ⋅ 3 ⋅ 2 ⋅ 1. S využitím rekurze můžeme tento součin přepsat do tvaru f(N) = N ⋅ f(N–1), takže odpovídající funkce bude v ja-zyku C vypadat následovně:
21 Při každém novém volání funkce je do zásobníku uložena návratová adresa. Adresa je ze zásobníku vyzved-
nuta při ukončení vykonávání funkce a při návratu na instrukci, která následuje po volání funkce. Pokud proběhne vysoký počet rekurzí, je do zásobníku ukládán vysoký počet návratových adres a žádné adresy nejsou vyzvedávány. Tak může dojít k překročení kapacity zásobníku.

funkce
- 58 -
// factorial unsigned long faktorial( unsigned int n) { if( n) // for non-zero value of n return n*faktorial( n-1); // recursion else return 1; // for zero value of n }

pokročilé datové typy
- 59 -
8 Pokročilé datové typy Doposud jsme pracovali jen se základními typy. Jednalo se o číselné datové typy int
(celé číslo), float a double (racionální čísla) a znakový typ char. Dále jsme si uvedli, že k těmto datovým typům můžeme přiřadit tzv. modifikátory (přívlastky) short, long, signed a unsigned.
Dále jsme se při našem seznamování s jazykem C setkali s prázdným datovým typem void. Proměnnou prázdného typu je přitom zakázáno deklarovat. Typu void jsme využívali k deklaraci funkcí, které nevracely hodnotu, a umísťovali jsme ji do seznamu formálních parametrů (do kulatých závorek za identifikátor funkce), když daná funkce žádné formální parametry neměla.
Rovněž jsme se již seznámili s ukazatelem na proměnnou daného typu a s polem (slož-ky pole jsou tvořeny proměnnými jednoho konkrétního typu). V následujících odstavcích se seznámíme se složitějšími datovými konstrukcemi.
8.1 Struktury Strukturu (structure) si můžeme představit jako pole, které sestává z položek různých
typů (což u pole bylo nemyslitelné). Struktura může sdružovat proměnné různých typů, které společně popisují jediný objekt (např. osobu, zařízení, poštovní adresu) a které proto k sobě logicky patří.
Představme si, že chceme naprogramovat jednoduchý telefonní seznam svých přátel. Každého ze svých známých popíšeme jménem (řetězec), věkem (celé číslo) a telefonním čís-lem (opět řetězec). Odpovídající struktura tedy může vypadat následovně: typedef struct t_friend // my friend { char name[20]; // name int age; // age char phone[20]; // phone number } my_friend;
Klíčové slovo typedef říká, že deklarujeme svůj vlastní datový typ. Na vlastní datový typ se potom můžeme v programu odkazovat stejným způsobem, jako se odkazujeme na datové typy základní (int, float, double, char).
Našim vlastním datovým typem je v uvedeném příkladě struktura (klíčové slovo struct). Na tento náš vlastní datový typ se můžeme odvolávat prostřednictvím identifikátoru t_friend (písmenem t na počátku slova říkáme, že se jedná o identifikátor typu). Ve slože-né závorce za identifikátorem typu pak následují deklarace jednotlivých složek struktury (ře-tězce jméno a telefonní číslo, kladné celé číslo věk). Identifikátorem my_friend za složenou závorkou deklarujeme proměnnou našeho vlastního typu.
Pokud v programu ukládáme do jednotlivých složek struktury data nebo je čteme, musíme udat jméno proměnné typu struktura i jméno složky, s níž pracujeme. Mezi jménem struktury a jménem její složky je tečka.
Vše by mělo být zřejmé z následujícího příkladu:

pokročilé datové typy
- 60 -
void main( void) { t_friend anna; strcpy( anna.name, "novakova\0"); anna.age = 16; strcpy( anna.phone, "+420776151443\0"); cprintf(" %s - %d let - tel.: %s", anna.name, anna.age, anna.phone); getch(); }
8.2 Unie Unie (union) představuje možnost, jak lze do jedné proměnné ukládat hodnoty různých
typů. Jako příklad si uveďme: union u1 {int i; double d; char c;} U = {'u'};
Deklarace začíná klíčovým slovem union. Identifikátor za klíčovým slovem (v našem přípa-dě u1) nazýváme jmenovkou unie. Ve složených závorkách za jmenovkou následuje seznam složek unie.
Výše uvedená deklarace zavádí unii typu u1 a proměnnou U typu u1. Do proměnné U můžeme přitom ukládat celočíselné hodnoty (int), racionální hodnoty (double) a hodnoty znakové (char).
Jednotlivé složky unie se překrývají (v naší unii může být uloženo buď i nebo d nebo c). To znamená, že počáteční adresa všech tří našich složek je stejná (adresa unie je adresou všech jejích složek). Co se týká rozsahu unie, ten je dán rozsahem její největší složky.
Práci s uniemi si vysvětleme na příkladu. Vytvořme unii t_dog, která bude sloužit k ukládání údaje o psovi. Tímto údajem může být věk psa (celé číslo), hmotnost psa (racio-nální číslo) nebo znakový kód jeho rasy. O tom, kterým parametrem bude pes popsán, rozho-duje uživatel stiskem klávesy W (weight), A (age) nebo T (type). Stiskne-li uživatel jinou klávesu, vypíšeme do konzolového okna nějakou urážku … #include <conio.h> #include <stdlib.h> typedef union t_dog // my dog { int age; // its age double weight; // its weight char type; // its race } my_dog; void main( void) { my_dog bobik; char choice, *S, buff[22], *endptr; buff[0] = 20; cprintf("Parameter of my dog ..."); choice = getch();

pokročilé datové typy
- 61 -
switch( choice) { case 'W': { cprintf( "Weigth of my dog:\r\n"); S = cgets( buff); bobik.weight = strtod( S, &endptr); break; } case 'A': { cprintf( "Age of my dog:\r\n"); S = cgets( buff); bobik.age = strtod( S, &endptr); break; } case 'T': { cprintf( "Race of my dog:\r\n"); bobik.type = getch(); break; } default: cprintf( "Stupid ..."); } getch(); }
8.3 Výčtové typy Výčtové typy (enumerative types) připomínají svou deklarací struktury a unie. Např.:
enum cards {seven, eight, nine, face_card, ace} set_1, set_2;
zavádí výčtový typ cards a dvě proměnné set_1, set_2 tohoto typu. Výčtový typ cards sestává z osmi konstant seven, eight, …, ace. Konstantě seven přitom odpovídá celočí-selná hodnota nula, konstantě eight hodnota jedna a konstantě ace hodnota sedm.
Složkám výčtového typu ovšem můžeme přiřadit i jiné celočíselné hodnoty: enum cards {seven=7, eight, nine, face_card=20, ace=30} set_1, set_2;
Složka seven je rovna sedmi, složka eight je rovna osmi (neuvedeme-li vedle identifikátoru přiřazovací příkaz, je hodnota konstanty vypočtena inkrementováním hodnoty konstanty před-chozí), kluk je roven dvaceti, eso třiceti, atd.
Výčtové proměnné lze s výhodou využít zejména pro přepínač (switch). Sestavíme si množinu možných variant a podle nich pak program větvíme. V případě dnů týdne můžeme postupovat následovně: enum days {mo,tu,we,th,fr,sa,su} a_day; switch( a_day) { case mo: ...; break; case tu: ...; break; case we: ...; break; case th: ...; break; case fr: ...; break; case sa: ...; break; case su: ...; }

pokročilé datové typy
- 62 -
8.4 Dynamické proměnné Dosud jsme při své práci využívali tzv. statických proměnných (static variables). Pokud
byly tyto proměnné deklarovány jako globální (mimo těla funkcí), byla jim při spuštění pro-gramu vyhrazena odpovídající část paměti, a tento paměťový prostor nebylo po celý běh programu možno využít k jiným účelům. Pokud se jednalo o lokální proměnnou, rezervace paměťového místa se vztahovala k období, kdy byly vykonávány instrukce z těla dané funkce.
Pokud program pracuje s velkými objemy dat, které se využívají jen po určitou krátkou dobu, je využití statických proměnných neefektivní (velký paměťový prostor je pro proměnné rezervován i v době, kdy s proměnnou nepracujeme). Popsaný problém můžeme vyřešit využitím tzv. dynamických proměnných (dynamic variables). V okamžiku, kdy potřebujeme s proměnnou pracovat, vyhradíme pro ni v paměti počítače odpovídající paměťový prostor (voláním funkce malloc), přidělený prostor naplníme daty a ty zpracováváme. Jakmile jsou data zpracována, uvolníme paměťový prostor voláním funkce free.
Konkrétní postup vytváření a ničení dynamické proměnné je uveden v následujícím příkladu: #include <conio.h> #include <stdlib.h> void main( void) { double *x, y; x = (double*) malloc( sizeof( double)); *x = 3.14; y = *x; free( x); cprintf("Ludolf's number: %f", y); getch(); }
V deklarační části programu deklarujeme ukazatel na racionální číslo x; tím si v paměti po-čítače vyhradíme místo pro uložení adresy. Na pátém řádku programu dynamicky alokujeme voláním funkce malloc v paměti místo pro uložení racionální hodnoty a adresu tohoto dyna-micky alokovaného paměťového místa uložíme do x.
Pokud bychom funkci malloc vyhledali v nápovědě, byli bychom informováni o násle-dujících vstupních a výstupních parametrech: void *malloc(size_t size)
Vstupním parametrem funkce malloc je údaj o velikosti paměťového místa, které si přejeme v paměti dynamicky vyhradit. Velikost místa v bajtech zjistíme voláním funkce sizeof, je-jímž parametrem je identifikátor typu proměnné, pro kterou chceme paměťové místo vyčlenit (v našem případě racionální hodnota double).
Funkce malloc vrací ukazatele (hvězdička před jejím identifikátorem) na prázdný typ void. Jelikož my však pracujeme s ukazatelem na proměnnou typu double, musíme provést tzv. přetypování. Pokud před identifikátor funkce malloc předřadíme (double *), dáváme tím najevo, že adresa, kterou funkce malloc vrací, neukazuje na prázdný typ ale na proměn-nou typu double.
Od okamžiku, kdy je dynamická proměnná vytvořena, pracujeme s ní stejným způso-bem, jakým jsme pracovali s ukazateli. Na šestém řádku programu do vytvořeného místa

pokročilé datové typy
- 63 -
paměti uložíme hodnotu 3.14, na sedmém řádku obsah tohoto paměťového místa kopírujeme do proměnné y.
Jakmile dynamicky alokovaný paměťový prostor nepotřebujeme, uvolníme jej voláním funkce free. Zde je třeba si uvědomit, že v proměnné x nadále zůstává adresa, kterou jsme do ní uložili při alokaci. Obsah této adresy však byl funkcí free uvolněn pro další použití.
Velmi časté je použití dynamických proměnných v případě, kdy chceme pracovat s po-lem, ale předem nevíme, jak má být rozsáhlé. Ukážeme to na následujícím příkladu.
Dynamicky vytvoříme pole délky n, která bude zadána až za běhu programu. Pak pole naplníme čísly 1, 2, …, n a vypíšeme je, aby se ukázalo, že dál se s takovýmto polem pracuje obvyklým způsobem. Na závěr paměť pro toto pole vyhrazenou opět uvolníme. Kdyby se při alokaci ukázalo, že není k dispozici dostatek paměti, funkce malloc vrátí jako výsledek nulu. To v našem příkladu také testujeme. #include <conio.h> #include <stdlib.h> void main( void) { double *A; int n, i; cprintf("Input the desired length of the array: "); cscanf("%d", &n);getch(); A = (double*) malloc( n*sizeof( double)); if( A==0) cprintf("\r\nNot enough memory!"); else { for( i=0; i<n; i++) { A[i] = i+1; cprintf("\r\nA[%d] = %lf",i,A[i]); } free( A); } getch(); }
8.5 Příklad Auta Jako příklad práce s probíranými datovými typy si vytvoříme jednoduchou databázi
automobilů. Každý vůz bude popsán jménem výrobce a rokem výroby. Tyto údaje o autu uložíme do dynamické proměnné a adresu proměnné uložíme do pole.
Zadávání nového auta do databáze indikuje uživatel stiskem klávesy A, mazání auta z databáze indikuje stiskem klávesy D a ukončení práce s programem stiskem klávesy Q. Pro jednoduchost uvažujme, že v databázi musí být vždy uloženo nejméně jedno auto.
Ve vyvíjeném programu budeme využívat funkce z knihovny conio (vstupy a výstupy do konzolového okna), string (práce s řetězci) a stdlib (dynamické alokování a uvolňo-vání paměti). Proto program zahájíme následujícími třemi řádky:

pokročilé datové typy
- 64 -
#include <conio.h> #include <stdlib.h> #include <string.h>
Jelikož jméno výrobce type a rok výroby year současně popisují jeden automobil, sdružíme tyto údaje do jediné struktury t_car. Následně vytvoříme pole ukazatelů na automobil my_cars a zavedeme celočíselnou proměnnou count, která bude obsahovat informaci o poč-tu automobilů v databázi: typedef struct t_car // car record { char type[10]; // producer of a car int year; // the year of the production } a_car; // the end of the car record t_car *my_cars[ 20]; // array of pointers to cars int count=0; // the number of recorded cars
V následujícím kroku vytvoříme funkci add, která dynamicky vytvoří dynamickou strukturu a_car a uloží do ní data ze vstupních parametrů funkce _type (řetězec obsahující jméno výrobce) a _year (celočíselná proměnná nesoucí rok výroby auta). Následně je ukazatel na tuto strukturu uložen do pole my_cars: void add( char *_type, int _year) { t_car *car; // pointer to a car car = (a_car *) malloc( sizeof( a_car)); strcpy( car->type, _type); // notation 1 (*car).year = _year; // notation 2 my_cars[ count++] = car; }
Ve výše uvedeném zdrojovém kódu si pozornost zaslouží dvě skutečnosti:
1. Ukazatel na dynamický vytvořené auto *car je lokální proměnnou. To znamená, že voláním malloc vytvoříme v paměti prostor pro auto, adresu tohoto paměťového místa uložíme do proměnné car a následně vytvořené paměťové místo zaplníme daty. Jakmile však funkci add opustíme, lokální proměnná car, a současně v ní uložená adresa, zani-kají; nezaniká však vytvořené paměťové místo a do něj uložené údaje o autu. Abychom neztratili přístup k uloženým údajům o autu, musíme před opuštěním funkce add uložit ukazatel na auto do globálního pole ukazatelů my_cars.
2. Odkazujeme-li se na složku dynamické struktury, píšeme (*car).year. Tento relativně komplikovaný zápis lze nahradit ekvivalentním car->year.
V dalším kroku naprogramujeme funkci, která bude do konzolového okna tisknout údaje o automobilech: void show( void) { cprintf("type: %s", my_cars[ count]->type); cprintf("year: %d", my_cars[ count]->year); }
Jelikož proměnné my_cars a count jsou deklarovány jako globální, nemusí mít funkce show žádné vstupní parametry.

pokročilé datové typy
- 65 -
Funkce pro vymazání posledního auta z databáze nejprve otestuje, zda mám v databázi více než jedno auto (alespoň jedno auto musí v databázi zůstat). Pokud tomu tak je, snížíme údaj o počtu aut v databázi o jedničku, voláním funkce show vytiskneme údaje o mazaném autě do konzolového okna a voláním funkce free uvolníme auto z paměti: void erase( void) { if( count>1) // if at least two cars are in the database ... { count--; // one car will be removed show(); // print data of the removed car free( my_cars[ count]); // delete the last car } else cprintf("All cars can’t be deleted"); }
Tělo programu by pak vypadalo následovně: void main( void) { char cmd; // a command chosen by the user (A, D, Q) char *my_type; // type of the car int my_year; // year the car was produced char *y, type_buff[12]; // for reading data from the console char year_buff[12], *endptr; cprintf("A: Add, D: Delete, Q: Quit\r\n"); // printing menu cmd = getch(); // reading command while( !(cmd=='Q' || cmd=='q')) // in case of different command than Q { if( cmd=='A' || cmd=='a') // in case of the command A { cprintf("\r\ntype : "); // read the type of the car type_buff[0]=10; my_type = cgets( type_buff); cprintf("\r\nyear : "); // read the year of production year_buff[0]=10; y = cgets( year_buff); my_year = strtod( y, &endptr); add( my_type, my_year);} // add the car to the batabase if( cmd=='D' || cmd=='d') // in case of the command D erase();} // delete the car from the batabase cprintf("A: Add, D: Delete, Q: Quit"); // printing menu cmd = getch(); // reading command } }
Význam jednotlivých řádků kódu by měl být zřejmý z komentářů.
8.6 Příklad Žáci Druhým příkladem má být seznam žáků základní školy. Každý žák je popsán příjmením
a studijním průměrem. Program má umožnit výpočet průměrné známky hochů (příjmení končí znakem různým od a) a průměrné známky dívek. Aby vedení školy motivovalo žáky ke studiu, náhodně losuje každý den žáka s průměrem lepším než 1,5 a věší jej na nástěnku.

pokročilé datové typy
- 66 -
Začněme deklarací struktury, pole ukazatelů na žáky (pro začátek jej plníme nulovými ukazateli) a celočíselnou proměnnou pro počet žáků v seznamu: typedef struct TZak { char name[21]; // jméno žáka float aver; // studijní průměr } AZak; AZak *zaci[5] = { NULL, NULL, NULL, NULL, NULL}; int cnt = 0; // počet žáků v seznamu
Aby se nám seznam žáků pohodlně plnil, vytvoříme si funkci pro přidávání: void add( char *_name, float _aver) { AZak *zak; // pomocný žák zak = (AZak*) malloc( sizeof( AZak)); // dynamické vytvoření žáka strcpy( zak->name, _name); // naplnění žáka daty zak->aver = _aver; zaci[ cnt++] = zak; // ukazatel na žáka do seznamu }
Ve funkci pro počítání průměrných známek hochů a dívek rozlišujeme pohlaví podle toho, zda je posledním písmenem v řetězci písmeno a (dívky) či nikoli22: void wo_men( void) { float av_men=0, av_wo=0; // počet a průměr hochů int num_men=0, num_wo=0, n; // počet a průměr dívek for( n=0; n<cnt; n++) // přes všechny žáky v seznamu if( zaci[n]->name[ strlen(zaci[n]->name)-1] == 'a') { // jedná se o dívku av_wo += zaci[n]->aver; num_wo++; } else { // jedná se o hocha av_men += zaci[n]->aver; num_men++; } cprintf( "Prumer hosi: %2.2f, divky: %2.2f\r\n", av_men/num_men, av_wo/num_wo); } // není ošetřeno dělení nulou
Ve funkci pro náhodný výběr žáka se studijním průměrem lepším než 1,5 tak dlouho generu-jeme náhodný index, dokud nemá odpovídající žák požadovanou průměrnou známku23:
22 Je pravda, že naše kritérium třídění mužů a žen je velmi nedokonalé. Autoři tohoto skripta – Oliva a Raida by
podle něj skončili mezi dámami. 23 Opět jsme si zjednodušili život. Tajně totiž doufáme v to, že ve třídě máme alespoň jednoho výborného žáka,
který danou podmínku splňuje.

pokročilé datové typy
- 67 -
void find_best( void) { int num=0, ind, n; randomize(); do ind = random( cnt); while( zaci[ind]->aver>1.5); cprintf("Cenu sprt dne vyhrava %s s prumerem %4.2f\r\n", zaci[ind]->name, zaci[ind]->aver); }
Na závěr všechny vytvořené funkce voláme v těle programu: void main( void) { add( "Kalna", 1.42); // přidání žáků add( "Lukes", 3.89); add( "Sobek", 1.11); add( "Sipova", 1.38); wo_men(); I// výpis průměrných známek find_best(); // losování nejlepšího getch(); }
Tím je jednoduchý program pro ředitele školy hotov.

struktury ve windows
- 68 -
9 Struktury ve Windows Touto kapitolou opouštíme svět konzolového okna a přesouváme se do světa Windows.
Abychom se mohli na tento přechod plně soustředit, vytvoříme si program založený na dyna-mických strukturách, jako tomu bylo v předchozí kapitole. Nyní však programu vytvoříme uživatelské rozhraní Windows.
9.1 Borland C++ Builder – druhý pohled Spustíme-li Borland C++ Builder, je okamžitě připraven k vytváření aplikací pro Win-
dows. Při vytváření uživatelského rozhraní Builder využívá principů tzv. vizuálního progra-mování (drag &drop design): programátor sestavuje myší uživatelské rozhraní svého programu, a Builder mu generuje odpovídající zdrojový kód, napsaný v jazyce C++. Pokud programátor zasáhne do zdrojového kódu, změna se samočinně promítne do vizuálně sestave-ného prvku a naopak (tzv. two-way tools).
Integrované prostředí Builderu pro vývoj aplikací pro Windows sestává z pěti základ-ních částí (obr. 9.1) – z editoru zdrojového kódu (béžový rámeček), z palety komponentů (modrý rámeček), z formuláře pro vizuální sestavování uživatelského rozhraní programu (fialový rámeček), z inspektora objektů (zelený rámeček) a z tzv. rychlého panelu (červený rámeček).
Editor zdrojového kódu (code editor) slouží k vytváření zdrojového kódu, napsaného v jazyce C++. Část kódu je generována samočinně jako reakce na vizuální sestavování uživa-telského rozhraní, zbytek musí programátor dopsat sám.
Paleta komponentů (component palette) je tvořena sadou záložek, na kterých jsou umís-těny komponenty, z nichž lze vizuálně sestavovat okno programu (formulář, form). Volná místa na záložkách jsou připravena pro umístění originálních komponentů, vytvořených pro-gramátorem.
Formulář (form) je základní okno operačního systému Windows s tečkovaným rastrem, do něhož myší umisťujeme jednotlivé komponenty. Jednotlivé parametry (proměnné) formu-láře a vkládaných komponentů můžeme zadávat jednak myší (umístění, rozměr), a jednak je můžeme určovat prostřednictvím inspektoru objektů (viz dále). Všechny zadané hodnoty pro-měnných se samočinně promítnou do zdrojového kódu vyvíjené aplikace.
Inspektor objektů (object inspector) sestává ze dvou záložek – ze záložky s názvem Proměnné (properties) a ze záložky s názvem Události (events).
Záložka Proměnné obsahuje seznam všech parametrů toho komponentu, který je za-ostřen (focused, programátor na něj kliknul myší). Nastavíme-li např. šířku a výšku kompo-nentu myší, numerické vyjádření nastavených rozměrů komponentu se automaticky objeví v inspektoru objektů vedle proměnných Height a Width. Postupovat lze samozřejmě i obrá-ceně.
Záložka Události obsahuje seznam událostí objektu, který je právě zaostřen ve formu-láři. Událostí rozumíme vše, co může nastat při zaostření daného komponentu. Např. při klik-nutí na tlačítko je generována událost OnClick. Má-li kliknutí na tlačítko spustit vykonávání určitého kódu (má být volána určitá funkce), vepíšeme do editačního řádku vedle události

struktury ve windows
- 69 -
jméno funkce a stiskneme klávesu Enter. Builder automaticky vygeneruje hlavičku funkce, a nám stačí její tělo (prostor mezi složenými závorkami) vyplnit zdrojovým kódem.
Obr. 9.1 Základní části uživatelského rozhraní programu Borland C++ Builder: editor zdrojového kódu (béžový rámeček), paleta komponentů (modrý rámeček), formu-lář pro vizuální sestavování uživatelského rozhraní programu (fialový rámeček), inspektor objektů (zelený rámeček) a rychlý panel (červený rámeček).
Rychlý panel (speedbar) je sestaven z tlačítek, soužících k vyvolání nejčastějších akcí. Detail rychlého panelu a popis funkce jednotlivých tlačítek je nakreslen na obr. 9.2. Anglický popis tlačítka je zobrazován v „bublinové“ nápovědě.
nový objekt
otevření souboruuložení souboru
uložení všech souborů
nápověda
vyjmutí jednotky z projektupřidání jednotky do projektu
otevření projektu
seznam jednotek
seznam formulářůjednotka <-> formulář
nový formulář spuštění programupřerušení běhu programu
"step over"
"trace into"
Obr. 9.2 Význam tlačítek na rychlém panelu.

struktury ve windows
- 70 -
Tlačítka Trace Into a Step Over slouží ke krokování programu (programátor manuálně vyko-nává instrukci za instrukcí). Při Trace Into se vnoříme se do funkce a řádek po řádku vykoná-váme jednotlivé její příkazy. Při Step Over se do funkce nevnoříme a vykonáme ji jako jeden jediný příkaz.
Celá aplikace pro Windows sestává z několika souborů, které dohromady tvoří jeden projekt. Projekt programu s jedním oknem sestává z následujících souborů (ponechány názvy, které automaticky generuje Builder):
• Project1.bpr obsahuje základní informace o našem projektu. Obsah tohoto souboru gene-ruje automaticky Builder. Do textu projektu nedoporučujeme zasahovat. Pro ilustraci uvádíme část textu projektu: <?xml version='1.0' encoding='utf-8' ?> <!-- C++Builder XML Project --> <PROJECT> <MACROS> <VERSION value="BCB.06.00"/> <PROJECT value="Project1.exe"/> <OBJFILES value="Project1.obj Unit1.obj"/> <RESFILES value="Project1.res"/> ...
• Project1.cpp je zdrojovým kódem napsaným v jazyce C++. Tento zdrojový kód je obdo-bou funkce main, kterou jsme v programech pro konzolu vytvářeli sami. Windowsovská verze této funkce, která je nazvána WinMain, má za úkol připravit aplikaci k běhu (Application->Initialize), má za úkol sestavit formuláře programu (Applica-tion->CreateForm) a má za úkol naši aplikaci spustit (Application->Run): #include <vcl.h> #pragma hdrstop USEFORM("Unit1.cpp", Form1); WINAPI WinMain(HINSTANCE, HINSTANCE, LPSTR, int) { try { Application->Initialize(); Application->CreateForm(__classid(TForm1), &Form1); Application->Run(); } catch (Exception &exception) { Application->ShowException(&exception); } catch (...) { try { throw Exception(""); } catch (Exception &exception) { Application->ShowException(&exception); } } return 0; }

struktury ve windows
- 71 -
Konstrukce try – catch slouží k ošetření chybových stavů (tzv. výjimky, exceptions). Jelikož se jedná o problematiku zasahující do jazyka C++, nebudeme se jí v rámci tohoto předmětu zabývat.
Rovněž obsah tohoto souboru generuje samočinně Builder a programátor by do něj neměl zasahovat.
• Project1.res je binárním souborem, který obsahuje informace o windowsovských prvcích (tlačítka, editační řádky, …) používaných v našem programu.
• Unit1.cpp slouží k psaní zdrojového kódu našeho programu. Zdrojový kód svázaný s růz-nými formuláři je ukládán do různých souborů. Důležité je odlišit jméno jednotky od jména projektu (Unit1.cpp versus Project1.cpp); v opačném případě se soubory s přípo-nou cpp vzájemně přepíší a s programováním musíme začít zcela nanovo.
• Unit1.h je hlavičkový soubor vztažený ke zdrojovému souboru Uni1.cpp svázanému s formulářem. Jeho obsah je opět generován samočinně a v naprosté většině případů není třeba do něj zasahovat.
• Unit1.dfm obsahuje informace o formuláři. Jeho obsah (opět je generován Builderem) vypadá např. takto: object Form1: TForm1 Left = 271 Top = 301 Width = 330 Height = 208 Caption = 'Form1' Color = clBtnFace Font.Charset = DEFAULT_CHARSET Font.Color = clWindowText Font.Height = -11 Font.Name = 'MS Sans Serif' Font.Style = [] OldCreateOrder = False PixelsPerInch = 96 TextHeight = 13 end
Nyní známe to nejdůležitější o prvcích uživatelského rozhraní programu Borland C++ Buil-der, které se používají při vývoji aplikací pro Windows. V následujícím odstavci si tedy můžeme popsat základní kroky tohoto vývoje.
9.2 Vývoj aplikace pro Windows Vývoj aplikace pro Windows v Borland C++ Builderu lze rozdělit do několika základ-
ních kroků. Nyní si tyto kroky podrobně probereme, abychom mohli vytvořit svůj vlastní program.
Základní kroky budeme vysvětlovat na programu, který po stisku tlačítka Počítej načte sčítance, jež uživatel vepíše do editačních řádků formuláře, zadané sčítance sečte a výsledek zobrazí. Formulář programu je nakreslen na obr. 9.3.
1. Spuštění Builderu Po spuštění obsahuje Builder prázdný formulář a prázdné editační okno, které odpovídá
programové jednotce tohoto formuláře.

struktury ve windows
- 72 -
Před zahájením práce je vhodné si prázdnou aplikaci uložit. Stisknutím čtvrtého tlačítka nahoře vlevo (Save All) otevřeme standardní dialog pro ukládání do souboru. Builder nám v řádku File name nabídne standardní jméno jednotky formuláře (unit1.cpp). My toto jméno změníme na add_form.cpp (formulář pro sčítání čísel), aby se nám v souborech lépe orientovalo. Po tisku tlačítka Save nám Builder nabídne standardní jméno projektu (pro-ject1.bpr), přičemž my toto jméno změníme na addition.bpr.
Podívejme se na obsah jednotky add_form.cpp, který automaticky vygeneroval Builder: #include <vcl.h> // knihovna windowsovských prvků #pragma hdrstop // konec seznamu předkompilovaných // hlavičkových souborů #include "add_form.h" // hlavičkový soubor naší jednotky #pragma package(smart_init) // řádná inicializace balíčků #pragma resource "*.dfm" // svázání souboru *.dfm s našim formulářem TForm1 *Form1; // ukazatel na náš formulář __fastcall TForm1::TForm1(TComponent* Owner) : TForm(Owner) { }
První direktiva #include <vcl.h> propojuje náš program s Visual Component Library. Jedná se o knihovnu, v níž jsou soustře-děny komponenty.
Direktiva pragma se předřa-zuje těm direktivám, které mohou být pro jiné kompilátory (nežli Bor-land C++ Builder) neznámé. V pří-padě neznámé direktivy je tato direktiva ignorována. Stručný popis direktiv je pro ilustraci uveden přímo ve výpisu.
Direktiva #include "add_form.h" spojuje naši jednotku s jejím hlavičkovým sou-borem. Jelikož se jedná o nestandardní knihovnu, je jméno hlavičkového souboru uvedeno v uvozovkách. V editoru kódu se k hlavičkovému souboru dostaneme prostřednictvím zá-ložky na spodní hraně okna (viz modrý rámeček v obr. 9.4).
Za poslední direktivou je deklarován ukazatel na náš formulář TForm1 *Form1. Formulář je tzv. komponentem (component). Na komponent se přitom můžeme dívat jako na velice komplikovanou strukturu, která:
• v sobě obsahuje nejen datové složky, ale také funkce;
• může být umístěna na paletě komponentů a může být vizuálně programována (lze ji z palety přenést myší do formuláře);
• má své parametry zveřejněny v inspektoru objektů.
Pokud tedy chceme pracovat s popisem v záhlaví formuláře (složka Caption), odvoláváme se na něj jako na Form1->Caption (viz obr. 2.4). V příkladu z obrázku v rámci inicializační
Obr. 9.3 Okno programu pro sčítání

struktury ve windows
- 73 -
funkce (její hlavičku pro nás samočinně vygeneroval Builder) kopírujeme do záhlaví okna text MyForm24. Tento text se v záhlaví objeví po spuštění aplikace.
Obr. 9.4 Nastavování textu v záhlaví formuláře prostřednictvím inspektora objektů (čer-vený rámeček) a inicializační funkce (zelený rámeček). Přístup k hlavičkovému souboru jednotky (modrý rámeček).
Stejného efektu dosáhneme vepsáním textu MyForm do řádku Caption v inspektoru objektů.
2. Nastavení parametrů aplikace a hlavního formuláře Každému programu bývá většinou přiřazena vlastní ikona. Ikonu vytvoříme v editoru,
který v Builderu spustíme prostřednictvím položky menu Tools → Image editor (editor obráz-ků). Vyberme z menu editoru obrázků položku File → New… → Icon file (a potvrďme stan-dardní parametry ikony 32×32 bodů, 16 barev). Tím spustíme jednoduchý grafický editor, v němž můžeme bod po bodu ikonu sestavit. Výběrem položky menu File → Save uložíme ikonu do adresáře k ostatním souborům našeho programu (soubor add_icon.ico).
Vytvořenou ikonu přiřadíme naší aplikaci prostřednictvím položky menu Builderu Project → Options. Otevřeme tím dialog s třemi řadami záložek. Vybereme záložku Applica-tion a stiskem tlačítka Load Icon načteme námi vytvořenou ikonu. Do řádku Title vepíšeme řetězec Sčítání. Stiskem tlačítka OK dialog uzavřeme. Spustíme-li naši aplikaci znovu, jak okno tak tlačítko ve stavové liště Windows budou mít naši ikonu, a navíc, tlačítko v liště bude obsahovat český název Sčítání.
Po základním nastavení aplikace se zaměříme na nastavení parametrů formuláře:
24 Textové řetězce, které jsou složkami komponentů Builderu (popis v záhlaví formuláře, popis tlačítka, text
v editačním řádku, …), jsou typu AnsiString. Tento typ umožňuje pohodlnou práci s řetězci – obyčejné přiřazení (místo strcpy), slučování řetězců pomocí + (místo strcat) a mnoho dalších věcí. Je to však typ, se kterým se dá pracovat pouze v Builderu. Proto je vhodné jej používat především při práci s komponentami Builderu. Ve vlastních knihovnách bychom se měli použití řetězců typu AnsiString vyvarovat, protože tím zhoršíme přenositelnost kódu. Podobné vlastnosti jako AnsiString má string, což je typ C++, a tudíž je použitelný univerzálně.

struktury ve windows
- 74 -
a) Pevné rozměry okna. Myší nastavíme rozměr formuláře (v inspektoru se automaticky mění obsah proměnných Height a Width). V inspektoru nastavíme BorderStyle na bsSingle (okno nepůjde roztáhnout myší taháním za okraje) a v BorderIcons nasta-víme biMaximize na false (zablokujeme ikonu pro roztažení okna přes celou obra-zovku).
b) Popis okna. V inspektorovi naplníme parametr Caption = Sčítání (dosud parametr obsahoval řetězec Form1).
Tím jsou základní nastavení dokončena.
3. Vizuální sestavení okna V dalším kroku postupně umístíme dovnitř formuláře komponenty z palety. Jak je vidět
z obr. 9.3, pracujeme se třemi komponenty (všechny tři se v paletě nacházejí na záložce Stan-dard).
Návěští (Label). Jedná se o text, kterým ve formuláři popisujeme další objekty (v našem případě editační řádky). Návěští můžeme rovněž použít jako textový výstup (v na-šem případě pro vypsání součtu). V inspektoru objektů vyplňujeme u návěští proměnné Cap-tion (řetězec, který se objeví ve formuláři), Font (otevře se standardní dialog pro výběr pa-rametrů písma) a Name (jméno návěští). Pro snadnější orientaci ve zdrojovém kódu je vhodné přepisovat standardní jména generovaná Builderem jmény vlastními.
Editační řádek (Edit). Jedná se o jednoduchý jednořádkový editor, který můžeme využít jako textový vstup programu (v našem případě pro načítání sčítanců). V inspektoru vyplňujeme u editačního řádku Text (obsah editačního řádku; v našem případě prázdný ře-tězec – tedy nic), Font a v případě potřeby jméno řádku Name.
Pokud chceme editační řádek doplnit „bublinkovou“ nápovědou, nastavíme v inspektoru ShowHint = true a do proměnné Hint vepíšeme obsah „bublinky“ (v našem případě vepí-šeme upozornění, že lze vepsat pouze celé číslo). Obdobný mechanismus funguje i u ostatních komponentů.
Pokud chceme editační řádek svázat s návěštím (aby se při výběru návěští automaticky zaostřil s ním svázaný řádek), musíme do položky FocusControl návěští zadat jméno svá-zaného editačního řádku.
Tlačítko (Button). Základním úkolem tlačítka je dát pokyn k provedení nějaké akce. Pokud uživatel na tlačítko klikne nebo pokud ho stiskne prostřednictvím klávesnice, vždy je generována událost tlačítka OnClick. Tuto událost nalezneme v inspektoru na záložce Events. Vepíšeme-li do editačního řádku vedle události jméno funkce, Builder tuto funkci deklaruje v editoru kódu (jako prázdnou) a její volání pevně sváže s danou událostí. V našem případě nazveme obslužnou funkci addition a její tělo si popíšeme v další podka-pitole.
Na záložce Properties inspektora zadáme text uvnitř tlačítka Caption = &Počítej (znak & způsobí podtržení následujícího písmene; při stisku klávesové kombinace Alt+P dojde ke stlačení tlačítka). Opět můžeme změnit jméno objektu (Name) a parametry písma uvnitř objektu (Font).

struktury ve windows
- 75 -
Na závěr uveďme ještě jednu poznámku. Je zvykem, že při postupném mačkání tabe-lační klávesy postupně zaostřujeme jednotlivé komponenty v okně. Pořadí zaostřování kom-ponentů přitom odpovídá pořadí, v němž byly komponenty do okna vkládány. Pokud chceme pořadí zaostřování změnit, učiníme tak v inspektoru prostřednictvím parametru TabOrder. Pokud nechceme, aby se tabelátor na určitém komponentu zastavil, nastavíme pro něj v in-spektoru TabStop = false.
4. Ošetření událostí V našem programu pro sčítání dvou čísel budeme pracovat s jedinou událostí, a to se
stiskem tlačítka Počítej. Jakmile uživatel programu toto tlačítko stiskne (objeví se událost tlačítka OnClick), zavoláme funkci addition. Abychom funkci svázali s uvedenou událostí tlačítka, tlačítko zaostříme (klikneme na něj myší) a v inspektoru vepíšeme na záložce Events řetězec addition vedle události OnClick. Potvrdíme-li svou volbu stiskem klávesy Enter, Builder vygeneruje deklaraci této funkce: void __fastcall TForm1::addition( TObject *Sender) { }
Funkce je samozřejmě prázdná (neobsahuje žádnou instrukci, nic nedělá). Reakci na stisk tlačítka musíme mezi složené závorky napsat sami jako posloupnost vhodných instrukcí.
Než začneme sestavovat program, vysvětleme si stručně význam jednotlivých slov v hlavičce funkce:
• __fastcall udává způsob, jakým má být funkce volána. Všechny funkce pro ošetření událostí musejí být volány s tímto slovem;
• TForm1::addition říká, že funkce addition je pevně svázána s hlavním formulářem našeho programu (na ploše tohoto formuláře naše tlačítko leží). Hlavnímu formuláři jsme ponechali standardní název Form1 (položka Name na záložce inspektora Properties), a proto má naše funkce tzv. předponu TForm1;
• Sender je proměnná typu TObject. Jedná se o společný základ všech komponentů z Visual Component Library.
Nyní již hlavičce vygenerované prázdné funkce rozumíme, a proto se můžeme začít věnovat psaní jejího těla: void __fastcall TForm1::addition( TObject *Sender) { int first, second; // -1- první a druhý sčítanec first = StrToInt( Add1Edit->Text); // -2- první edit.řádek na číslo second = StrToInt( Add2Edit->Text); // -3- druhý edit.řádek na číslo Result->Caption = IntToStr( first + second); // -4- sečtení a zobrazení }
Na řádku č.1 zavádíme dvě pomocné proměnné, které existují jen uvnitř naší funkce. Proměn-né first a second jsou typu int.
Druhý a třetí řádek musíme začít číst zprava. Konstrukce Add1Edit->Text říká, že budeme pracovat s textem, který uživatel vepíše do prvého editačního řádku (v inspektoru jsme ho pojmenovali – prostřednictvím položky Name – Add1Edit). Vepsaný text je uložen

struktury ve windows
- 76 -
ve formě řetězce (posloupnost znaků) v proměnné editačního řádku Text (viz inspektor, záložka Properties).
Abychom mohli provést operaci sčítání, musíme převést řetězec na číslo. O tuto kon-verzi se stará standardní funkce StrToInt (String To Integer, převod řetězce na celé číslo). Vstupním parametrem je řetězec Add1Edit->Text, výstupním parametrem je celé číslo. Získané celé číslo uložíme do celočíselné pomocné proměnné first.
S obsahem druhého editačního řádku a s jeho převodem na druhý sčítanec je to obdob-né. Výsledkem je druhý řetězec převedený na celé číslo second.
Na posledním řádku obě čísla sečteme (first+second) a součet převedeme z celočí-selné formy na řetězec (IntToStr, Integer To String). K zobrazení získaného řetězce vy-užijeme modrého návěští vedle tlačítka Počítej (pojmenovali jsme ho Result – inspektor, položka Name). Text návěští je uložen v jeho proměnné Caption. Konstrukce Result->Caption = s tedy říká, že řetězec s ukládáme do proměnné Caption, která patří návěští Result.
Naši jedinou událost tedy máme ošetřenu. Nyní je třeba zkontrolovat, zda program fun-guje a zda pracuje správně.
9.3 Seznam počítačů Nyní, když jsme se seznámili se základními kroky vytváření uživatelského rozhraní
programu pro Windows, se pokusíme vytvořit jednoduchý seznam počítačů v laboratoři a jednoduché funkce pro práci s tímto seznamem. Vše uložíme do samostatné jednotky, kterou prostřednictvím hlavičkového souboru spojíme s jednotkou formuláře. V jednotce formuláře budeme pouze volat funkce z naší jednotky.
Umisťování vlastního kódu do samostatných jednotek by mělo být základním pravidlem naší práce. Díky tomuto přístupu pak můžeme náš kód bez zbytečné práce používat jak pro konzolu tak pro Windows.
Obr. 9.5 Dialog pro vytvoření nové programové jednotky a jejího hlavičkového souboru.

struktury ve windows
- 77 -
Po spuštění Builderu vybereme z menu File → New → Other, čímž otevřeme dialog z obr. 9.525. Pro vytvoření naší jednotky vybereme ikonu Cpp File. Náš kód bude sice napsán v ry-zím jazyce C, nicméně všechny soubory pro Windows, které generuje Builder, jsou psány v C++. Proto pro udržení jednotného přístupu dáme přednost právě popsané volbě. Co se týká hlavičkového souboru, zde nezbývá než zvolit Header File. Jak jednotka tak hlavičkový soubor musejí mít přirozeně stejné jméno, odlišnost je jen v příponě.
Uživatelské požadavky na vyvíjený program lze shrnout do několika bodů:
1. Každý počítač v laboratoři je popsán jménem výrobce, cenou a velikostí paměti RAM.
2. Program musí umět přidat do seznamu nový počítač, vyhledat nejlevnější počítač a listo-vat seznamem.
Na základě těchto požadavků můžeme sestavit strukturu popisující počítač a můžeme vytvořit hlavičky funkcí, které budou realizovat požadované úkoly. Obsah hlavičkového souboru (po-jmenovali jsme jej pocitac.h) bude tedy vypadat následovně: typedef struct t_pc { char prod[ 20]; // name of the producer int price; // price of the computer float mem; // RAM capacity in GB } a_pc; // adding new computer void add( char* _prod, int _price, float _mem); void sort( void); // sorting according to the price t_pc* get_fwd( void); // point out to the next computer t_pc* get_bwd( void); // point out to the previous computer int show_price( void); // get price of an added pc int show_cheap( void); // get price of the cheapest pc
Nyní se podrobněji podívejme na obsah jednotky pocitac.cpp, v níž jsou uložena těla výše uvedených funkcí. V úvodní části vložíme do jednotky všechny potřebné hlavičkové soubory a deklarujeme tři globální proměnné katalog (pole ukazatelů na dynamicky vytvářené počí-tače), index (ukazovátko na pozici pole za posledním vloženým počítačem) a ptr (ukazo-vátko na počítač, jehož údaje jsou zobrazeny v editačních řádcích): #include <stdlib.h> // allocating memory for dynamic variables #include <string.h> // handling null-terminated strings #include "pocitac.h" // definition of the structure t_pc t_pc *katalog[20]; // array of pointers to computers int index=0; // first free position in the katalog int ptr=index-1; // pointer to a pc displayed in edits
Jelikož žádná z uvedených globálních proměnných není obsažena v hlavičkovém souboru, nelze k nim přistupovat z ostatních programových jednotek jinak než voláním funkcí z jed-notky pocitac.cpp.
Pokračujme funkcí pro přidání počítače do seznamu. V jejím těle máme deklarován ukazatel na strukturu *my_pc. Voláním malloc pro strukturu alokujeme v paměti prostor a adresu tohoto prostoru uložíme do *my_pc. Následně bereme hodnoty z hlavičky (řetězec 25 Spoluautorka skripta namítá: Nestačilo by zvolit File → New → Unit? Tím se udělá Header File i Cpp File.
Má samozřejmě pravdu.

struktury ve windows
- 78 -
s názvem výrobce _prod, celé číslo s cenou _price, racionální číslo s kapacitou paměti v GB _mem) a plníme jimi složky vytvořené struktury. Na závěr uložíme adresu takto naplně-ného paměťového prostoru do pole ukazatelů na počítače katalog. void add( char* _prod, int _price, float _mem) { t_pc *my_pc; my_pc = (t_pc*) malloc( sizeof( t_pc)); strcpy( my_pc->prod, _prod); my_pc->price = _price; my_pc->mem = _mem; katalog[ ptr=index++] = my_pc; }
Lomené závorky na posledním řádku těla funkce add obsahují výraz ptr=index++. To znamená, že ukazatel na právě vytvořený počítač *my_pc uložíme do nejnižší volné složky pole katalog (odpovídající index nejnižší volné složky je uložen v proměnné index), poté index uložíme do proměnné ptr (ukazovátko na počítač zobrazený v editačních řádcích) a nakonec hodnotu indexu o jedničku zvětšíme (operátor ++ je uveden napravo, a proto inkre-mentujeme se zpožděním).
Nyní se soustřeďme na hledání nejlevnějšího počítače: void sort( void) { int m,n; t_pc *x; for( m=0; m<index; m++) for( n=m+1; n<index; n++) if( katalog[m]->price>katalog[n]->price) { x = katalog[m]; katalog[m] = katalog[n]; katalog[n] = x; } }
Funkce sort seřadí počítače od nejlevnějšího po nejdražší. Chceme-li pak vypsat údaje o nejlevnějším počítači, stačí nám vzít nultý ukazatel z pole katalog. Jelikož pole katalog, jehož složky třídíme podle ceny, je globální proměnnou, nemusí mít funkce sort deklaro-vány žádné vstupní a žádné výstupní parametry.
Doposud jsme pracovali uvnitř programové jednotky. Pokud však chceme data z této jednotky posílat do jednotek jiných (v našem případě do formuláře pro Windows), je třeba vytvořit funkce, které pošlou požadovaná vnitřní data jednotky ven. V našem případě se bude jednat o funkci pro listování seznamem od právě zobrazeného počítače dopředu, t_pc* get_fwd( void) { // if ptr does not point the last pc if( ptr<index-1) ptr++; // increase it (we move forward) return katalog[ ptr]; // return address of a pc pointed by ptr }
o funkci pro listování seznamem od právě zobrazeného počítače dozadu,

struktury ve windows
- 79 -
t_pc* get_bwd( void) { // if ptr does not point the zero pc if( ptr>0) ptr--; // decrease it (we move backward) return katalog[ ptr]; // return address of a pc pointed by ptr }
o funkci pro vrácení ceny právě přidaného počítače int show_price( void) { return katalog[index-1]->price; }
a o funkci pro vrácení ceny počítače nejlevnějšího: int show_cheap( void) { return katalog[ 0]->price; // computers sorted from the cheapest one }
Tím je naše programová jednotka dokončena, takže pro ni můžeme vytvořit windowsovské uživatelské rozhraní (viz obr. 9.6). To sestává z editačních řádků (komponenty TEdit), jež odpovídají zadávaným parametrům počítače, z návěští (komponenty TLabel) pro každý editační řádek, z tlačítek (komponenty TButton) pro přidávání počítače do seznamu, pro hledání nejlevnějšího počítače, pro posuv dopředu a posuv zpět. Tlačítka jsou vizuálně orá-mována komponentem TBevel ze záložky palety komponentů Additional. Pod tlačítky je umístěno ještě jedno návěští, v němž kontrolně zobrazujeme cenu počítače, který jsme právě přidali do seznamu (tlačítko Přidej), a cenu nejlevnějšího počítače v seznamu (tlačítko Hledej).
ProdLbl
ProdEdit
PriceLbl
PriceEdit
MemLbl
MemEdit
AddBtn
FindBtn
FwdBtn
BwdBtn
ShowLbl
Bevel1
Obr. 9.6 Hlavní formulář programu pro seznam počítačů s uvedenými jmény použitých komponentů.
Nyní nahlédněme do hlavičkového souboru takto sestaveného formuláře:

struktury ve windows
- 80 -
class TForm1 : public TForm { __published: // IDE-managed Components TEdit *ProdEdit; // editační řádek pro zadání výrobce TLabel *ProdLbl; // návěští k řádku výrobce TEdit *PriceEdit; // editační řádek pro zadání ceny TLabel *PriceLbl; // návěští k řádku ceny TEdit *MemEdit; // editační řádek pro zadání paměti TLabel *MemLbl; // návěští k řádku paměti TButton *AddBtn; // tlačítko přidej TButton *FindBtn; // tlačítko hledej TButton *FwdBtn; // tlačítko vřed TButton *BwdBtn; // tlačítko zpět TLabel *ShowLbl; // návěští pro zobrazení ceny TBevel *Bevel1; // zvýrazňovací rámeček void __fastcall add_pc(TObject *Sender); // přidání počítače void __fastcall seach_pc(TObject *Sender); // hledání nejnižší ceny void __fastcall fwd_pc(TObject *Sender); // posun dopředu void __fastcall bwd_pc(TObject *Sender); // posun zpět private: // User declarations public: // User declarations __fastcall TForm1(TComponent* Owner); };
Vidíme, že jednotlivé složky komponentu formulář za nás Builder samočinně deklaroval. Do deklarace byly přidány rovněž hlavičky funkcí, které jsme v inspektoru objektů zadali jako odezvu na stisk jednotlivých tlačítek.
Nyní máme sestaveno uživatelské rozhraní a vytvořeno jádro našeho programu. Obojí tedy můžeme propojit: #include <vcl.h> #pragma hdrstop #include "Unit1.h" #include "pocitac.h" // header file of our unit #pragma package(smart_init) #pragma resource "*.dfm" TForm1 *Form1; // pointer to the main form of the program
Jelikož budeme často potřebovat vypisovat údaje o počítači do editačních řádků (listování seznamem dopředu a zpět), vytvoříme funkci show_pc, která vytiskne údaje o počítači do jednotlivých editačních řádků. Počítač, jehož údaje se mají do řádku tisknout, je zadán uka-zatelem v hlavičce funkce. void show_pc( t_pc *my_pc) { Form1->ProdEdit->Text = my_pc->prod; Form1->PriceEdit->Text = IntToStr( my_pc->price); Form1->MemEdit->Text = FloatToStrF( my_pc->mem, ffGeneral, 6, 2); }
Funkce show_pc nepatří k našemu formuláři (jméno funkce není uvedeno ve tvaru TForm1::show_pc). Proto je třeba u každého editačního řádku uvést, že je součástí formu-láře (že je složkou komponentu Form1).
Dále ještě upozorněme na funkci FloatToStrF na posledním řádku těla funkce show_pc. Tato funkce převádí racionální číslo na řetězec, přičemž programátor může určit

struktury ve windows
- 81 -
formát čísla v řetězci. V našem případě bude mít číslo obecný tvar s desetinnou tečkou (konstanta ffGeneral), přesnost převodu bude na 6 desetinných míst a zobrazeny budou dvě číslice za desetinnou tečkou.
Nyní postupně naprogramujeme odezvy na stisk jednotlivých tlačítek ve formuláři. Pro každé tlačítko vypíšeme k události OnClick na záložce Events inspektora objektů jméno obslužné funkce:
• Pro tlačítko Přidej: void __fastcall TForm1::add_pc(TObject *Sender) { add( ProdEdit->Text.c_str(), StrToInt(PriceEdit->Text), StrToFloat(MemEdit->Text)); ShowLbl->Caption = IntToStr( show_price()); }
• Pro tlačítko Hledej: void __fastcall TForm1::seach_pc(TObject *Sender) { sort(); // sort computers according to the price ShowLbl->Caption = IntToStr( show_cheap()); }
• Pro tlačítko Vpřed: void __fastcall TForm1::fwd_pc(TObject *Sender) { t_pc *my_pc; my_pc = get_fwd(); show_pc( my_pc); }
• Pro tlačítko Zpět: void __fastcall TForm1::bwd_pc(TObject *Sender) { t_pc *my_pc; my_pc = get_bwd(); show_pc( my_pc); }
Jádrem všech čtyř výše uvedených funkcí – odezev na stisk některého z tlačítek – je volání odpovídající funkce z naší jednotky pocitac.cpp. Vyjma funkce pro přidávání počítačů do seznamu voláme funkce bez vstupních parametrů (funkce exportují do Uni1.cpp informace z jednotky pocitac.cpp).
V případě funkce pro přidávání počítačů do seznamu musíme vzít řetězce z položky Text editačních řádků a musíme je převést na data typu, který odpovídá jednotlivým složkám struktury t_pc:
• Jméno výrobce prod máme deklarováno jako řetězec ukončený znakem null. Řetězec TEdit->Text je však velmi komplikovanou strukturou, u níž je samotný řetězec ukon-čený znakem null skrytý hluboko pod povrchem; dostat se k němu můžeme voláním funkce c_str().
• Cena počítače price je celé číslo. Řetězec z editačního řádku převedeme na celé číslo voláním funkce StrToInt (String To Integer).

struktury ve windows
- 82 -
• Kapacita paměti počítače v GB mem je racionální číslo. Řetězec z editačního řádku převe-deme na racionální číslo voláním funkce StrToFloat (String To Float).
Tím máme celý program hotov.
9.4 Struktury v C++ Všechny své zdrojové kódy stále vytváříme v základní, neobjektové verzi jazyka C.
Pokud však v programu Borland C++ Builder kvůli kompatibilitě s ostatními soubory své zdrojové kódy ukládáme do souborů s příponou cpp, dívá se kompilátor na program, jako by byl napsán v objektové verzi jazyka C++. Vše, co platí pro jazyk C, lze využít rovněž v ja-zyku C++ (opačně to ovšem neplatí). Nicméně existuje jeden problém.
Když jsme v konzolových aplikacích vytvářeli databázi aut, sestavili jsme následující zdrojový kód. typedef struct t_car { char type[10]; // producer of a car int year; // the year of the production } a_car;
void add( char *_type, int _year) { t_car *car; // pointer to a car car = (a_car *) malloc( sizeof( a_car)); strcpy( car->type, _type); // ↑ INSTANCE of a car USED car->year = _year; my_cars[ count++] = car; }
V případě databáze počítačů pro Windows vypadal odpovídající zdrojový kód následovně: typedef struct t_pc { char prod[ 20]; // name of the producer int price; // price of the computer float mem; // RAM capacity in GB } a_pc;
void add( char* _prod, int _price, float _mem) { t_pc *my_pc; // pointer to a pc my_pc = (t_pc*) malloc( sizeof( t_pc)); strcpy( my_pc->prod, _prod); // ↑ TYPE of a pc USED my_pc->price = _price; my_pc->mem = _mem; katalog[ ptr=index++] = my_pc; }
Je tedy vidět, že zatímco v ryzím C jsem se při vytváření dynamických proměnných odvolá-vali na instanci struktury, v objektovém C++ se musíme odvolávat na typ. To je mimochodem logičtější…

matice ve windows
- 83 -
10 Matice ve Windows V rámci této kapitoly si vyzkoušíme napsat část knihovny pro operace s maticemi (sčí-
tání matic, výpočet inverzní matice). Následně této knihovně vytvoříme uživatelské rozhraní pro Windows.
10.1 Sčítání a inverze V prvém kroku vytvoříme hlavičkový soubor matrix.h, jehož prostřednictvím násled-
ně propojíme naši knihovnu matrix.cpp s jednotkou uživatelského rozhraní: typedef float TMatrix[4][4]; void adding( TMatrix A, TMatrix B, TMatrix E, int N); void invert( TMatrix A, TMatrix E, int N);
Na prvém řádku je deklarován typ TMatrix pro realizaci matic racionálních čísel do rozměru až 4×4. Jelikož při práci s poli se odvoláváme na adresu první složky tohoto pole, nemusejí naše funkce vracet žádné hodnoty (nalevo od jména funkce uvádíme prázdný typ void).
Funkce pro sčítání sečte matici A s maticí B a výsledek uloží do matice E. Při výpočtu inverzní matice dosadíme za A matici, kterou chceme invertovat, a za E matici jednotkovou. Jakmile je inverze dokončena, bude matice A jednotková a v E budeme mít matici inverzní. Vstupní parametr N obsahuje informaci o rozměru matice.
Funkce pro sčítání matic je velmi jednoduchá – každý prvek výsledné matice je součtem odpovídajícího prvku prvé matice A s odpovídajícím prvkem matice druhé B: #include "matrix.h" void adding( TMatrix A, TMatrix B, TMatrix E, int N) { int i, j; for( i=0; i<N; i++) for( j=0; j<N; j++) E[i][j] = A[i][j] + B[i][j]; }
Co se týká inverze matice, zde je postup trošku složi-tější. Pro matici o dvou řádcích a o dvou sloupcích je postup znázorněn na obr. 10.1.
Na levé straně dělítka je uvedena matice, kterou chceme invertovat, na pravé straně dělítka je pak uvedena matice jednotková. Na obě matice současně aplikujeme operace, které nezmění vlastnosti matice (dělení řádku číslem, sečtení dvou řádků), s cílem získat nalevo matici jednotkovou; napravo nám pak vznikne matice inverzní.
Algoritmus lze popsat několika body:
2 13 4
1 00 1
x 1/2
1 0,50 2,5
0,5 0-1,5 1 -3 x 1st row
1 0,50 1
0,5 0-0,6 0,4 / 2,5
1 00 1
0,8 -0,2-0,6 0,4
-0,5 x 2nd
Obr. 10.1 Princip invertování matice.

matice ve windows
- 84 -
• První řádek levé matice podělíme prvním diagonálním prvkem. Tím získáme v diagonále prvního řádku jedničku. Ošetření případu, kdy je na diagonále nula, ponecháme na čtenáři.
• První řádek postupně násobíme záporně vzatým koeficientem v prvém sloupci a postupně jej přičítáme k odpovídajícím řádkům matice. Tím získáme v prvém sloupci pod diago-nálním prvkem samé nuly.
• Posuneme se na diagonální prvek druhého řádku, vynulujeme prvky druhého sloupce pod diagonálou, atd. Opakujeme-li uvedený postup pro další řádky matice, bude výsledkem matice s jedničkami na diagonále a s nulami pod ní.
• Poslední řádek postupně násobíme záporně vzatými koeficienty v posledním sloupci ma-tice a přičítáme jej k odpovídajícím řádkům matice. Tím získáme v posledním sloupci matice nad diagonálou samé nuly.
• Posuneme se na diagonální prvek předposledního řád-ku, vynulujeme prvky předposledního sloupce nad diagonálou, atd. Opakujeme-li uvedený postup pro další řádky matice, bude výsledkem jednotková matice.
Celý postup je vyjádřen vývojovým diagramem z obr. 10.2. Přepsání diagramu do formy zdrojového kódu v jazyce C by pro nás pak mělo být již rutinní záležitostí: void invert( TMatrix A, TMatrix E, int N) { int i, j, k; float cf; for( i=0; i<N; i++) { cf = A[i][i]; for( j=0; j<N; j++) { A[i][j] /= cf; E[i][j] /= cf; } for( k=i+1; k<N; k++) { cf = A[k][i]; for( j=0; j<N; j++) { A[k][j] -= cf*A[i][j]; E[k][j] -= cf*E[i][j]; } } } for( i=N-1; i>0; i--) for( k=i-1; k>=0; k--) { cf = A[k][i]; for( j=N-1; j>=0; j--) { A[k][j] -= cf*A[i][j]; E[k][j] -= cf*E[i][j]; } } }
i 0, .., N-1
declare A, E
←
cf A[ i ][ i ]←
j 0, .., N-1←
A[i][j] A[i][j] / cf←E[i][j] E[i][j] / cf←
k i+1,..,N-1←
j 0, .., N-1←
A[k][j] A[k][j] - cf*A[i][j]←E[k][j] E[k][j] - cf*E[i][j]←
cf A[ k ][ i ]←
i N-1, .., 1←
k i-1,..,0←
j N-1, .., 0←
A[k][j] A[k][j] - cf*A[i][j]←E[k][j] E[k][j] - cf*E[i][j]←
cf A[ k ][ i ]←
Obr. 10.2 Vývojový diagramvýpočtu inverzní matice.

matice ve windows
- 85 -
Tím máme svou knihovnu pro práci s maticemi dokončenu a můžeme se začít věnovat uži-vatelskému rozhraní.
10.2 Uživatelské rozhraní K zadávání matic uživatelem a ke zobrazování výsledků využijeme komponent
TStringGrid ze záložky Additional. Umístíme-li komponent do formuláře, standardně jsou první řádek a první sloupec zvýrazněny šedým pozadím (legenda tabulky). Pokud o takové zvýraznění nemáme zájem, musíme v inspektoru objektů uložit do složek FixedCols a FixedRows nuly. Počet řádků textové mřížky udává RowCount, počet sloupců ColCount. Řetězce v buňkách mřížky jsou uloženy v dvoj-rozměrném poli Cells[m][n], kde m je číslo sloupce a n značí číslo řádku (obrácené pořadí ve srovnání s dvojrozměrným polem vytvoře-ným v C).
První dvě mřížky (v programu jsou ozna-čeny jako SG1 a SG2) slouží k zadávání matic uživatelem, třetí mřížku (v programu je označe-na jako SG3) používáme pro výpis výsledků.
Mřížky jsou implicitně uzamčeny proti vepisování údajů. Odemčení SG1 a SG2 dosáh-neme nastavením Options/goEditing v in-spektoru objektů na hodnotu true.
Mřížky pro zadávání matic jsou od mřížky pro zobrazení výsledků odděleny rámečkem Bevel1, jež obsahuje tlačítko pro sečtení matic v horních mřížkách (v programu nazváno AddBtn), tlačítko pro inverzi horní matice (v programu nazváno InvBtn) a editační řádek pro načtení rozměru matice Label1.
Nyní se již můžeme soustředit na začátek jednotky Unit1.cpp, v níž budeme vytvářet program pro Windows: #include <vcl.h> #pragma hdrstop #include "Unit1.h" #include "matrix.h" #pragma package(smart_init) #pragma resource "*.dfm" TForm1 *Form1; TMatrix A, B, E; int N; __fastcall TForm1::TForm1(TComponent* Owner) : TForm(Owner) { }
Obr. 10.3 Uživatelské rozhraní programupro práci s maticemi.

matice ve windows
- 86 -
Je zřejmé, že do zdrojového kódu vygenerovaného Builderem jsme přidali vložení hlavičko-vého souboru jednotky pro práci s maticemi matrix.h, přidali jsme globální deklaraci vstupních matic A, B a matice pro výsledek E, a doplnili jsme deklaraci celého čísla N pro uložení rozměru zpracovávaných matic.
V následujícím kroku vytvoříme funkci show, jež vepíše obsah všech tří matic do příslušných textových mřížek. Jelikož funkce show není svázána s hlavním formulářem aplikace, musíme každému prvku uživatelského rozhraní předřadit Form1->. void show( void) { int m, n; Form1->Edit1->Text = IntToStr( N); // show the matrix size if( N<2) N=2; // correcting the matrix size if( N>4) n=4; for( m=0; m<N; m++) for( n=0; n<N; n++) { Form1->SG1->Cells[n][m] = FloatToStrF( A[m][n], ffGeneral, 4, 6); Form1->SG2->Cells[n][m] = FloatToStrF( B[m][n], ffGeneral, 4, 6); Form1->SG3->Cells[n][m] = FloatToStrF( E[m][n], ffGeneral, 4, 6); } }
Aby se program rozeběhl s neprázdnými maticemi A, B a E, vytvoříme inicializační funkci, která matice A a B naplní náhodnými daty a matici E sestaví jako jednotkovou: void __fastcall TForm1::init(TObject *Sender) { int m, n; randomize(); // initializing the random number generator N = 4; // matrices 4x4 generated for(m=0; m<N; m++) for(n=0; n<N; n++) { A[m][n] = random( 100); // random matrix A B[m][n] = random( 100); // random matrix B if(m==n) // unitary matrix E E[m][n] = 1; else E[m][n] = 0; // matrices shown in grids } show(); }
Hlavičku funkce init vygeneroval Builder jako odezvu na událost OnCreate formuláře; funkce je automaticky volána při procesu vytváření formuláře – tedy na začátku běhu pro-gramu.
Funkci pro sčítání matic vytváříme jako odezvu na událost OnClick tlačítka AddBtn. Význam jednotlivých řádků zdrojového kódu by měl být zřejmý z komentářů:

matice ve windows
- 87 -
void __fastcall TForm1::do_add(TObject *Sender) { int m, n; // control variables for cycles N = StrToInt( Edit1->Text); // read the matrix size if( N<2) N=2; // correcting the matrix size if( N>4) n=4; for( m=0; m<N; m++) // reading the matrices to be inverted for( n=0; n<N; n++) { A[m][n] = StrToFloat( SG1->Cells[n][m]); B[m][n] = StrToFloat( SG2->Cells[n][m]); } adding( A, B, E, N); // invert the matrix show(); // print results }
Funkci pro inverzi matice vytváříme jako odezvu na událost OnClick tlačítka InvBtn. Vý-znam jednotlivých řádků zdrojového kódu by měl být zřejmý z komentářů: void __fastcall TForm1::do_invert(TObject *Sender)
{ int m, n; // control variables for cycles N = StrToInt( Edit1->Text); // read the matrix size if( N<2) N=2; // correcting the matrix size if( N>4) n=4; for( m=0; m<N; m++) // reading the matrix to be inverted for( n=0; n<N; n++) A[m][n] = StrToFloat( SG1->Cells[n][m]); invert( A, E, N); // invert the matrix show(); // print results }
Tím máme celý program hotov.

grafika ve windows
- 88 -
11 Grafika ve Windows Windows jsou operačním systémem, jehož uživatelské rozhraní je grafické. Grafické
rozhraní (GDI, Graphics Device Interface) je jakýmsi transformátorem mezi aplikací a vý-stupním zařízením (obrazovka, tiskárna, bitová mapa, meta-soubor). Díky GDI není pro programátora rozdíl mezi kreslením na obrazovku a na tiskárnu – kreslicí metoda je stejná, pouze se změní výstupní zařízení.
Grafické rozhraní je knihovna grafických funkcí, jejichž prostřednictvím můžeme vy-kreslit vše od menu a ikon na obrazovce monitoru až po složité grafické obrazce na souřad-nicovém zapisovači.
Vedle fyzických zařízení můžeme prostřednictvím GDI pracovat i s tzv. pseudo-zaří-zeními. Pseudo-zařízení slouží k ukládání obrázků do paměti nebo na disk a patří mezi ně bitové mapy (obrázek je zde uložen bod po bodu stejně jako v paměti grafického adaptéru) a meta-soubory (obrázek je uložen ve formě posloupnosti grafických funkcí, jejichž voláním kresba vznikne).
Obrovskou výhodou GDI je jeho hardwarová nezávislost (pomocí jediné funkce mohu kreslit na obrazovku, na tiskárnu či do bitové mapy). Této vlastnosti GDI je dosaženo pro-střednictvím logických kreslicích nástrojů a prostřednictvím kontextu zařízení (DC, Device Context).
Co se týká kontextu zařízení, můžeme se na něj dívat jako na brašnu s nástroji, urče-nými vždy pro jedno konkrétní zařízení. Máme tak brašnu pro monitor, brašnu pro tiskárnu, brašnu pro bitovou mapu atd. Jména a způsob ovládání nástrojů, uložených v jednotlivých brašnách, jsou vždy stejné, ale jejich funkce je odlišná (pero z jedné brašny umí kreslit na obrazovku, pero z druhé brašny na tiskárnu). Chci-li tedy kreslit, musím si podle druhu výstupního zařízení zvolit brašnu s nástroji (DC), poté mohu provést grafickou operaci a nakonec musím DC uvolnit.
Logické kreslicí nástroje máme ve Windows celkem čtyři – pero (pen) pro kreslení čar, štětec (brush) pro vyplňování ploch, písmo (font) pro psaní textů a barevná paleta (palette) pro volbu barev. Paletami se zabývat nebudeme.
Práce s logickými kreslicími nástroji přímo na úrovni samotných Windows je dosti slo-žitá. Proto byly v programu Borland C++ Builder vytvořeny objekty, které nám práci s kres-licími nástroji usnadňují. Objekt si můžeme představit jako složitou dynamickou strukturu, jejímiž složkami mohou být vedle proměnných (vlastnosti, properties) také funkce (metody, methods).
Seznam všech vlastností a metod objektu je uveden v nápovědě. Podívejme se např. na objekt TCanvas (písmeno T říká, že se jedná o název datového typu, slovo Canvas lze přeložit jako malířské plátno). Obsah nápovědy vztažený k plátnu je znázorněn na obr. 11.1.
Klikneme-li na odkaz Properties, otevře se okno se seznamem všech datových složek objektu. Mezi těmito složkami jsou právě výše zmíněné logické kreslicí nástroje – ukazatele na pero (TPen *Pen), štětec (TBrush *Brush) a písmo (TFont *Font). Pokud bychom dále klikli na pero, opět objevujeme dynamickou strukturu s položkami barva (Color), styl (Style), šířka (Width) a dalšími.

grafika ve windows
- 89 -
Malířské plátno je nataženo např. přes celou plochu formuláře. Pokud tedy chceme nastavit barvu pera malířského plátna formuláře, píšeme Form1->Canvas->Pen->Color = clBlue;
Zde clBlue je konstanta odpovídající modré barvě. Všimněme si, že výraz čteme pozpátku – nastav barvu pera, jež bude kreslit na plátno našeho formuláře.
Obr. 11.1 Nápověda objektu TCanvas: okno s vlastnostmi (vlevo), okno s metodami (vpravo), vlastnosti pera (uprostřed).
Pokud chceme grafiku omezit pouze na určitou část formuláře, je výhodné k tomu využít komponent kreslicí plocha – PaintBox (záložka System, druhá ikona zleva).
Práci s logickými kreslicími nástroji nyní vyzkoušejme na jednoduché aplikaci, jejíž formulář (jméno změněno na F1) je nakreslen na obr. 11.2. V horní části formuláře máme umístěn rámeček Bevel (záložka Additional), jehož styl je nastaven na bsRaised a jméno změněno na B. Na plochu rámečku je s malým odsazením od okrajů umístěna kreslicí plocha PaintBox pojmenovaná PB, do níž budeme směrovat grafické výstupy. Vlevo dole je tlačítko pro spuštění grafické rutiny.

grafika ve windows
- 90 -
Celou aplikaci budeme koncipovat tak, aby se obsah formuláře, a tedy i vykreslovaný obrázek, dynamicky přizpůsoboval změně rozměrů formuláře uživatelem. Vytvoříme tedy funkci resize, která bude velikost rámečku B a kreslicí plochy PB odvozovat od rozměrů formuláře. Umístění tlačítka bude dynamicky měněno podle aktuální výšky formuláře: void resize( void) // Bevel dimensions related to form dimensions F1->B->Width = F1->Width - 60; F1->B->Height= F1->Height -100; // PaintBox dimensions related to form dimensions F1->PB->Width = F1->Width - 120; F1->PB->Height= F1->Height- 200; // Button top related to form height F1->Btn->Top = F1->Height - 60; }
Jelikož v hlavičce funkce resize není formulář F1 nijak reprezentován, musíme před každý komponent předřadit informaci o jeho příslušnosti k formuláři F1.
Obr. 11.2 Formulář grafické aplikace (PaintBox je uvnitř rámečku; bez grafického výstupu není vidět.
Informace o počátečních rozměrech a počátečním umístění komponentů lze nastavit buď pří-mo v inspektoru objektů, nebo v rámci inicializační funkce, jejíž hlavičku pro každý program samočinně generuje Builder: __fastcall TF1::TF1(TComponent* Owner) : TForm(Owner) { Width = 700; // initial height and width of the form Height = 400; B->Top = 20; // top left corner of the Bevel (related to form) B->Left = 20; PB->Top = 40; // top left corner of the PaintBox (related to form) PB->Left = 40; Btn->Left= 20; // left edge of the button (related to form) resize(); // resizing }

grafika ve windows
- 91 -
Jelikož příslušnost funkce k formuláři je ve jménu funkce indikována znaky TF1::, nemu-síme před jména komponentů předřazovat F1->. V těle funkce nastavujeme šířku a výšku formuláře, souřadnice levého horního rohu rámečku Bevel a kreslicí plochy PaintBox vzhledem k levému horníku rohu formuláře a souřadnici levé hrany tlačítka vzhledem k levé hraně formuláře. Na závěr zavoláme funkci resize, která nastaví rozměry komponentů podle hodnot výše zadaných parametrů.
Pokud uživatel za běhu programu mění rozměry formuláře, je automaticky volána funkce spojená s událostí formuláře OnResize. Nám stačí s touto událostí svázat volání funkce resize. void __fastcall TF1::resizing(TObject *Sender) { resize(); }
Nyní tedy máme připraveno vše k tomu, abychom mohli v rámci kreslicí plochy začít vytvářet svou vlastní grafiku. Vytváření grafiky je třeba implementovat v rámci funkce, která je auto-maticky volána jako odezva na událost OnPaint formuláře. Tato událost vzniká vždy, když je obsah okna poškozen (překrytí jiným oknem, změna rozměrů, atd.) a je třeba jej obnovit. V našem případě svážeme událost OnPaint s voláním funkce painting.
Nyní zpět k logickým kreslicím nástrojům.
Pero (pen) slouží ke kreslení čar. Čára je určena následujícími třemi parametry:
• Styl čáry; do proměnné Style můžeme zadávat předdefinované konstanty psSolid (plná čára), psDash (přerušovaná čára), psDot (tečkovaná čára), psDashDot (čercho-vaná čára), atd.
• Barva čáry; do proměnné Color můžeme zadávat předdefinované konstanty clGreen (zelená), clBlue (modrá), clRed (červená), clYellow (žlutá) a další.
• Šířka čáry; do proměnné Width zadáváme celá čísla určující šířku plné čáry v bodech (u jiných typů čar nelze šířku zadat).
Pro vykreslení čáry voláme funkce plátna MoveTo (nastaví pero na souřadnice počátečního bodu kreslení) a LineTo (kreslí čáru z počátečního do koncového bodu). Chceme-li na naší kreslicí ploše vykreslit diagonální přerušovanou zelenou čáru, učiníme tak kódem: PB->Canvas->Pen->Color = clLime; // green color of the line PB->Canvas->Pen->Style = psDash; // a dashed line PB->Canvas->MoveTo( PB->Left+10, PB->Top+10); PB->Canvas->LineTo( PB->Width-20, PB->Height-20);
Štětec (brush) slouží k natírání ploch. Nátěr plochy je určen následujícími dvěma parametry:
• Barva výplně; do proměnné Color můžeme zadávat stejné předdefinované konstanty, jaké se zadávají v případě pera.
• Styl výplně; do proměnné Style lze zadat bsSolid (plná výplň), bsBDiagonal , bsCross , bsDiagCross , bsFDiagonal , bsHorizontal , bsVertical a další.
Před natřením plochy štětcem musíme určit, kde se bude plocha nacházet, jaký bude mít tvar a jak bude veliká. V případě eliptické plochy voláme funkci Ellipse, v případě obdélníkové

grafika ve windows
- 92 -
plochy funkci Rectangle. Následující kód vykreslí na naší kreslicí plochu vlevo dole elipsu s plnou žlutou výplní a vpravo nahoře obdélník se šrafovanou červenou výplní: PB->Canvas->Brush->Color = clYellow; PB->Canvas->Brush->Style = bsSolid; PB->Canvas->Rectangle( PB->Left+10, PB->Height-120, PB->Left+110, PB->Height+160); PB->Canvas->Brush->Color = clRed; PB->Canvas->Brush->Style = bsDiagCross; PB->Canvas->Rectangle( PB->Width-210, PB->Top+20, PB->Width-110, PB->Top+260);
Jelikož nebyly změněny parametry pera, jsou elipsa a obdélník orámovány zelenou přerušo-vanou čarou.
Písmo (font) slouží k vypisování textů. Mezi nejdůležitější parametry patří:
• Barva písma; do proměnné Color můžeme zadávat stejné předdefinované konstanty, jaké se zadávají v případě pera a štětce.
• Výška písma; do proměnné Height zadáváme výšku znaků v bodech.
• Styl písma; do proměnné Style můžeme uložit některou z předdefinovaných konstant fsBold (tučné), fsItalic (kurzíva), fsUnderline (podtržené) a fsStrikeOut (přeškrtnuté).
Pokud bychom chtěli do našeho okna vložit tučný fialový text AHOJ, můžeme tak učinit po-mocí funkce TextOut, která na zadané obřadnice vypíše zadaný text: PB->Canvas->Font->Color = clFuchsia; PB->Canvas->Font->Height= 48; PB->Canvas->Font->Style = TFontStyles() << fsItalic; PB->Canvas->TextOut( PB->Left+10, PB->Top+100, "A H O J");
Konečný výsledek našeho snažení je vidět na obr. 11.3. Využití tlačítka Draw ponecháváme na fantazii čtenáře.
Obr. 11.3 Formulář grafické aplikace s vytvořeným obrázkem.

grafika ve windows
- 93 -
11.1 Kreslení grafů Dalším grafickým příkladem bude program pro počítání a zobrazování průběhu gonio-
metrických funkcí pro hodnoty argumentu od 0 do 2π radiánu.
Program bude reprezentován formulářem, který je znázorněn na obr. 11.4.
Do editačního řádku Edit1 uživatel může zadat s (počítá se sinus), c (počítá se kosi-nus) nebo t (počítá se tangens). Při vepsání jiného znaku je na kreslicí plochu PB vypsán text: Chybně zadaná funkce. Nastavením parametru MaxLength=1 editačního řádku v inspektoru zajistíme, že lze do řádku zapsat jediný znak. Editační řádek, návěští a tlačítko jsou opticky odděleny od zbytku formuláře rámečkem.
Stištění tlačítka Funkce (Button1) vyvolá událost OnClick, na níž reaguje funkce do_picture. Úkolem do_picture je přečíst znak z řádku Edit1, vypočítat průběh zvo-lené funkce a průběh vykreslit.
TPaintBox
Obr. 11.4 Grafy funkcí.
Jakmile máme formulář sestavený, můžeme začít programovat:
1. Jednotku s naším programem spojíme s knihovou standardních matematických funkcí, abychom mohli vyčíslovat funkční hodnoty funkcí sinus, kosinus a tangens: #include <math.h> // jednotka matematických operací
2. Goniometrické funkce budeme vykreslovat s krokem 10°; proto si vytvoříme typ vektor o 36 racionálních číslech: typedef double TVector[36];
3. Deklarujeme globální proměnné. Mezi globální proměnné zařadíme Ludolfovo číslo pi a pole funkčních hodnot vykreslovaných funkcí value:

grafika ve windows
- 94 -
double pi = 3.14; // Ludolfovo číslo TVector value; // pole funkčních hodnot
4. Vytvoříme funkci paint, která vynese hodnoty vektoru value na kreslicí plochu: void paint( TVector _value) { int n; // mazání kreslicí plochy Form1->PB->Canvas->Brush->Style = bsSolid; Form1->PB->Canvas->Brush->Color = clBtnFace; Form1->PB->Canvas->Pen->Color = clBtnFace; Form1->PB->Canvas->Rectangle( 0, 0, Form1->PB->Width, Form1->PB->Height); // nastavení barvy pera Form1->PB->Canvas->Pen->Color = clWhite; // nastavení výchozí pozice pera Form1->PB->Canvas->MoveTo( 5, 150-_value[0]); for (n=1;n<36;n++) // kreslení průběhu Form1->PB->Canvas->LineTo( 5+10*n, 150-_value[n]); }
Před samotným kreslením vymažeme obsah kreslicí plochy – přes celou plochu vykreslíme obdélník, jehož barva odpovídá šedé barvě pozadí okna.
5. Definujeme funkci do_picture jako odezvu na událost tlačítka OnClick: void __fastcall TForm1::do_picture(TObject *Sender) { char funct; // znak s (sinus), c (cosinus), t (tangens) int n; // index pro cykly a pole funct = Edit1->Text[1]; // znak funkce z editačního řádku switch( funct) // přepínání podle zadaného znaku { case 's': // znak s = sinus { for( n=0;n<36;n++) value[n] = 100*sin( n*pi/18); paint( value); break; } case 'c': // znak c = kosinus { for (n=0;n<36;n++) value[n] = 100*cos( n*pi/18); paint( value); break; } case 't': // znak t = tangens { for (n=0;n<36;n++) value[n] = 30*tan( n*pi/18); paint( value); break; } // hlášení pro ostatní znaky default: PB->Canvas->TextOutA( 10, 10, "Chybně zadaná funkce"); } }
Mezi lokálními proměnnými funkce je znak určující typ goniometrické funkce funct a pomocný index n. Obě dvě proměnné plníme aktuálními daty po každém stisknutí tlačítka Funkce, a proto jsou deklarovány lokálně.

grafika ve windows
- 95 -
Text v editačním řádku Edit1 lze chápat jako pole znaků. Text[0] obsahuje řídicí znak, v Text[1] je potom první znak zapsaný do editačního řádku. Tento znak kopírujeme do pomocné proměnné funct typu char.
6. Aby docházelo k automatické obnově vykresleného průběhu funkce, musíme událost for-muláře OnPaint svázat s kreslicí funkcí paint: void __fastcall TForm1::painting(TObject *Sender) { paint( value); }
Tím je program dokončen.
11.2 Tvary Třetí grafický příklad popisuje práci s tvary, tedy s kompo-
nentem Shape programu Borland C++ Builder (záložka Additi-onal panelu komponentů).
Formulář programu je nakreslen na obr. 11.5. Formulář sestává z jednoduchého geometrického tvaru (komponent Shape, ze zarážek Tvar a Barva (komponent CheckBox, záložka Standard), z tlačítka Změň (komponent Button, záložka Standard) a z návěští (Label, záložka Standard). Návěští zob-razuje počet stisknutí tlačítka Změň.
Pokud uživatel stiskne tlačítko Změň, vygeneruje se pro zatrženou zarážku (její proměnná Checked má nenulový obsah) náhodné celé číslo od nuly do dvou.
V případě zarážky Tvar změníme podle hodnoty tohoto čísla tvar objektu na kruh (n==0), elipsu (n==1) nebo zakulacený obdélník (n==2); tvar komponentu Shape určuje obsah jeho stejnojmenné proměnné Shape.
Obrys objektu kreslíme perem. Barva obrysové čáry Color je proměnnou pera Pen a pero je proměnnou komponentu Shape. Je-li zatržena zarážka Barva, změníme barvu podle hodnoty náhodného čísla na modrou (n==0), zelenou (n==1) nebo červenou (n==2).
Celý program sestává z globální celočíselné proměnné n, která slouží jako počítadlo stisknutí tlačítka Změň, a ze dvou funkcí.
První funkcí je automaticky vygenerovaná inicializační funkce. Do jejího těla doplníme inicializaci generátoru náhodných čísel a počáteční nastavení pera pro vykreslení obrysu tvaru: __fastcall TForm1::TForm1(TComponent* Owner) : TForm(Owner) { randomize(); // inicializace generátoru náhod.čísel // parametry obrysu tvaru Shape->Pen->Width = 3; // tloušťka čáry 3 body Shape->Pen->Color = clYellow; // barva čáry žlutá }
Druhá funkce change je volána jako odezva na stisknutí tlačítka Změň. V jejím těle nejprve testujeme, zda je zatržena zarážka povolující změnu tvaru ShapeBox. Je-li obsah její proměn-né Checked nenulový, umožní příkaz if přepínačem vybrat podle náhodně vygenerované
Obr. 11.5 Tvary

grafika ve windows
- 96 -
hodnoty tvar objektu. Obdobně je postavena část kódu pro náhodnou změnu barvy objektu. Celá funkce vypadá následovně: void __fastcall TForm1::change(TObject *Sender) { if( ShapeBox->Checked) // povolena změna tvaru switch( random( 4)) // náhodné číslo tvaru { case 0: Shape->Shape = stCircle; break; case 1: Shape->Shape = stEllipse; break; case 2: Shape->Shape = stRoundRect; break; default: Shape->Shape = stSquare; } if( ColorBox->Checked) // povolena změna barvy switch( random( 4)) // náhodné číslo barvy { case 0: Shape->Pen->Color = clBlue; break; case 1: Shape->Pen->Color = clGreen; break; case 2: Shape->Pen->Color = clRed; break; default: Shape->Pen->Color = clYellow; } Label->Caption = IntToStr( ++n); // inkrementace počítadla }
Tím je program dokončen.

mdi aplikace
- 97 -
12 MDI aplikace Zkratka MDI (pochází z anglických slov Multi Document Interface) označuje aplikaci,
která v rámci jednoho hlavního okna umožňuje uživateli pracovat v několika podřízených oknech. Typickým případem takové aplikace je textový editor Microsoft Word – v rámci editoru mohu mít současně otevřeno několik dokumentů, a současně mohu se všemi těmito
dokumenty pracovat.
Vytváření MDI aplikací si vysvětlíme na pří-kladu prohlížeče obsahu grafických souborů. Vzhled aplikace je zobrazen na obr. 12.1.
Hlavní formulář aplikace má ve své horní části umístěno základní menu, sestávající ze dvou sub-menu Soubor a Okno, a dále z položky O aplikaci. Submenu Soubor obsahuje položky Otevři (otevření pracovního formuláře s grafikou) a Konec (ukončení běhu aplikace). Submenu Okno obsahuje položky Kaskáda (uspořádání pracovních formulářů do kas-kády) a Dlaždice (dlaždicové uspořádání formulářů). Položka O aplikaci otevře dialog s informací o na-šem programu.
V prvém kroku si připravíme hlavní formulář aplikace. V inspektoru objektů nastavíme položku FormStyle na fsMDIForm, Caption na Obrázky, Name na MDIForm a do Icon nahrajeme svou vlastní ikonu. Kamkoli na plochu formuláře umístíme komponent MainMenu (druhá ikona zleva na záložce palety komponentů Standard); při spuštění programu ikona totiž zmizí.
V druhém kroku sestavíme menu. Dvakrát klikneme na ikonu MainMenu, čímž otevřeme vzorové menu, které postupně sestavujeme. Do položky Caption vepíšeme v inspektoru objektů řetězec, který se má objevit na dané pozici menu. Pokud chceme vytvořit tzv. horkou klávesu (písmeno v řetězci je podtrženo, položka menu je vybrána při stisku Alt + dané písmeno), vypíšeme před daný znak &26. Pokud chceme dvě položky menu oddělit oddělovací čárou, vepíšeme do Caption znak -. Pokud máme menu sestaveno, okno se vzorovým menu uzavřeme. Spustíme-li program, menu se rozevírá, nicméně jeho položky zatím nefungují.
Ve třetím kroku vytvoříme pracovní formulář. Z menu Builderu vybereme položku File → New → Form, čímž vytvoříme nový formulář a jemu odpovídající soubor se zdrojovým kódem. V inspektoru objektů pro nový formulář nastavíme FormStyle na fsMDIChild, Name na MDIChild a do Icon nahrajeme svou vlastní ikonu. Přes plochu pracovního formu-láře roztáhneme komponent Image (pátá ikona zleva na záložce Additional palety kompo-
26 Aby vše fungovalo správně, nesmíme mít v rámci jednoho submenu dvě stejné horké klávesy.
Obr. 12.1 MDI prohlížeč obsahu grafickýchsouborů.

mdi aplikace
- 98 -
nentů). Jméno komponentu Name nastavíme v inspektoru na Image, parametr AutoSize nastavíme na true (komponent bude měnit své rozměry podle rozměrů načítaného obrázku).
Ve čtvrtém kroku vytvoříme okno AboutForm s informací o našem programu. Okno je stylu fsNormal, v hlavičce má zobrazen řetězec About … a na ploše se vyskytuje pouze tlačítko O.K. Jakmile uživatel tlačítko stiskne, volá se funkce Close(), která okno uzavře.
Borland C++ Builder v základním nastavení automaticky vytváří všechny formuláře, které uživatel sestaví. Za běhu programu se pak pouze přepíná mezi viditelným a neviditel-ným stavem formuláře. To u pracovních oken ovšem není možné – pracovní okno se musí vytvořit až v okamžiku, kdy uživatel výběrem položky menu Otevři otevře grafický soubor. Vyloučení formuláře z procesu automatického vytváření lze dosáhnout prostřednictvím polož-ky menu Project → Options. V dialogu voleb pak na záložce Forms přesuneme MDIChild ze sloupce Auto-create forms do sloupce Available forms.
V pátém kroku začneme svůj program oživovat:
• V hlavním formuláři vybereme z menu položku Konec. Tím vytvoříme hlavičku funkce, která bude automaticky volána při výběru této položky. V těle této funkce stačí volat standardní funkci Builderu Close(), která se postará o ukončení naší aplikace.
• Pro výběr grafického souboru, který má být zobrazen v pracovním okně, použijeme standardní dialog pro práci s obrázky TOpenPicture Dialog (třetí ikona zleva na záložce Dialogs palety komponentů). Komponent umístíme libovolně na plochu hlavního formuláře – po spuštění programu se komponent skryje. Aby se nám s komponentem lépe pracovalo, zkrátíme jeho jméno na OpenDlg. Následně vybereme položku menu Otevři a do těla předdefinované funkce vepíšeme: void __fastcall TMDIForm::Otevi1Click(TObject *Sender) { if( OpenDlg->Execute()) // dialog uzavřen tlačítkem "Otevři" { MDIChild = new TChildForm( this); // vytvoření pracovního formuláře // načtení obrázku ze souboru MDIChild->Image->Picture->LoadFromFile( OpenDlg->FileName); // do hlavičky formuláře jméno souboru MDIChild->Caption = ExtractFileName( OpenDlg->FileName); } }
Abychom ze souboru hlavního okna viděli na deklarace v souboru okna pracovního, mu-síme do deklarační části souboru hlavního okna přidat: #include "ChildForm.h"
Funkce Execute dialog zobrazí a kompletně se postará o jeho fungování. Pokud uživatel uzavře dialog stiskem tlačítka Storno, vrací funkce hodnotu 0. Pokud uživatel uzavře dialog stiskem tlačítka Otevřít, vrací dialog hodnotu nenulovou. V tomto případě vytvo-říme dynamický komponent MDIChild (při tvorbě komplikovaných komponentů je zapotřebí použít namísto nám dobře známého malloc speciální funkci new). Voláním funkce LoadFromFile načteme do komponentu Image ve vytvořeném pracovním okně grafiku ze souboru FileName dialogu (soubor vybraný uživatelem). Jelikož FileName obsahuje jméno souboru včetně cesty, voláním funkce ExtractFileName z řetězce vybereme samotné jméno souboru a zkopírujeme jej do hlavičky pracovního okna.
• Implementujeme funkci položek menu Dlaždice a Kaskáda voláním standardních funkcí Tile() a Cascade():

mdi aplikace
- 99 -
void __fastcall TMDIForm::Dladice1Click(TObject *Sender) { Tile(); } void __fastcall TMDIForm::Kaskda1Click(TObject *Sender) { Cascade(); }
• Pokud bychom chtěli otevřená pracovní okna MDI aplikace uzavřít (ikona křížek v levém horním rohu okna), namísto uzavření dojde k jejich minimalizaci. Tuto potíž odstraníme ošetřením události OnClose pracovního formuláře. Do těla funkce vygenerované jako odezva na danou událost vepíšeme jediný řádek: Action = caFree;
• Poslední položkou menu, kterou musíme ošetřit, je O aplikaci. Opět ošetřujeme ze sou-boru hlavního okna. Abychom tedy viděli na deklarace v souboru okna pracovního, musíme do deklarační části souboru hlavního okna přidat: #include "AboutForm.h"
Do těla funkce vygenerované jako odezva na výběr položky menu pak vepíšeme řádek: AboutForm->ShowModal();
Tím je formulář o aplikaci zobrazen jako modální (je-li otevřen, jsou všechny ostatní součásti programu nepřístupné).
Tím máme jednoduchou MDI aplikaci dokončenou.

práce se soubory
- 100 -
13 Práce se soubory Téměř každý program, který je určen ke zpracování většího objemu dat, by měl být
schopen načíst data pro zpracování z jednoho diskového souboru a data zpracovaná by měl umět do dalšího (nebo stejného) diskového souboru uložit.
Začněme soubory v konzolových aplikacích. Diskové soubory jsou zde deklarovány jako ukazatele na typ FILE.
K otevření diskového souboru pak slouží funkce fopen. Prvním parametrem této funk-ce je řetězec se jménem diskového souboru, druhým parametrem pak je řetězec s atributem přístupu. Je-li atributem přístupu "w", je soubor otevřen pouze k zápisu, je-li atributem "r", je soubor otevřen pouze ke čtení. Funkce fopen vrací ukazatel na otevřený soubor.
K zápisu do souboru používáme funkci fprintf. Prvním parametrem funkce je ukaza-tel na soubor, do nějž zapisujeme, druhým parametrem je formátovaný řetězec, následují hodnoty dosazované za parametry formátovaného řetězce. Parametrem racionálním je %lf, parametrem celočíselným %d.
Ke čtení ze souboru používáme funkci fscanf. Prvním parametrem funkce ukazatel na soubor, do kterého ukládáme, druhým parametrem formátovaný řetězec a parametrem třetím ukazatel na paměťové místo, do kterého budeme načtená data ukládat.
Jakmile práci se souborem ukončíme, doporučuje se bezprostředně soubor uzavřít. K uzavření souboru voláme funkci fclose. Jediným parametrem této funkce je ukazatel na uzavíraný soubor.
V níže uvedeném příkladu ukládáme do diskového souboru my_file.txt čísla 0.00, 1.11, 2.22 až 9.99. Po uložení poslední hodnoty soubor uzavřeme (první blok). V druhém bloku je soubor my_file.txt otevřen a jednotlivá racionální čísla jsou ukládána do pole test. Po načtení posledního čísla je soubor uzavřen. V třetím bloku obsah pole test tiskneme do konzoly. void main( void) { FILE *fw, *fr; int i; double test[ 10], buff; fw = fopen( "my_file.txt", "w"); // the first block for( i=0; i<10; i++) fprintf( fw, "%lf \n", 1.11*i); fclose( fw); fr = fopen( "my_file.txt", "r"); // the second block for( i=0; i<10; i++) { fscanf( fr, "%lf", &buff); test[i] = buff; } fclose( fr); for( i=0; i<10; i++) // the third block cprintf( "%6.3f \n\r", test[i]); getch();}

práce se soubory
- 101 -
V druhém příkladu pracujeme se znakovými soubory.
V prvém bloku voláním funkce cscanf načítáme text ze tří řádků (psáno uživatelem) konzolového okna; tři řádky odpovídají třem opakováním cyklu for. U každého načteného řádku bereme znak po znaku a ukládáme voláním funkce putc do souboru tak dlouho, dokud nenarazíme na ukončovací znak NULL. Na konec každého řádku ukládáme do souboru znak \n. Po uložení třetího řádku soubor uzavřeme.
V druhém bloku soubor otevřeme pouze pro čtení. Voláním funkce getc načítáme ze souboru jednotlivé znaky, dokud nenarazíme na \n. Pak přecházíme na další řádek. Jednotlivé řádky pro kontrolu tiskneme do konzolového okna. void main( void) { FILE *fw, *fr; int i, n; char test[ 30], buff; fw = fopen( "my_file.txt", "w"); // the first block for( i=0; i<3; i++) { n = 0; cscanf( "%s", test); cprintf("\r\n"); while( test[n] != '\0') putc( test[n++], fw); putc( '\n', fw); } fclose( fw); fr = fopen( "my_file.txt", "r"); // the second block for( i=0; i<3; i++) { n = 0; while( (buff=getc(fr)) != '\n') test[n++] = buff; test[n] = '\0'; cprintf( "\r\n%s", test); } fclose( fr); getch(); getch(); }
Jak již bylo řečeno, výše uvedený popis byl věnován práci se soubory v ryzím jazyku C. Nyní se ještě stručně podívejme na stejné aktivity v podání Borland C++ Builderu. Vytvoříme jednoduchou aplikaci sestávající ze dvou vstupních řádků a dvou tlačítek. Stiskneme-li tla-čítko Ulož, přečte se obsah prvního editačního řádku a uloží se do souboru, jehož jméno uživatel zadal do standardního dialogu pro práci se soubory (záložka palety komponentů Dialogs, komponent SaveDialog). Stiskneme-li tlačítko Načti, otevře se standardní dialog pro práci se soubory (záložka palety komponentů Dialogs, komponent OpenDialog), přečte se obsah souboru zadaného uživatelem a načtený obsah se vypíše do druhého editačního řádku.
Vše lze realizovat následujícím zdrojovým kódem:

práce se soubory
- 102 -
FileStream* soubor; void __fastcall TForm1::to_file(TObject *Sender) { ShortString Buffer = WriteEdit->Text; if( SaveDlg->Execute( )) { soubor = new TFileStream( SaveDlg->FileName, fmCreate); soubor->Write( &Buffer, WriteEdit->Text.Length()+1); delete soubor; } } void __fastcall TForm1::from_file(TObject *Sender) { ShortString Buffer; if( OpenDlg->Execute( )) { soubor = new TFileStream( OpenDlg->FileName, fmOpenRead); soubor->Read( &Buffer, sizeof Buffer); ReadEdit->Text = Buffer; delete soubor; } }
K práci se soubory zde používáme datovou třídu typu FileStream. Tuto třídu si můžeme představit jako potrubí, jímž data proudí ze souboru do aplikace nebo naopak. Potrubí vždy musíme vytvořit (nový dynamický objekt vytvořený funkcí new), pak data přeneseme (volání funkcí Write nebo Read) a nakonec po sobě uklidíme (odstranění dynamického objektu voláním funkce delete).
Obr. 13.1 Formulář pro práci se soubory v Borland C++ Builderu.
Při vytváření potrubí je nutno zadat dva parametry – jméno souboru (to bereme z proměnné FileName dialogu) a mód činnosti (fmCreate pro vytvoření nového souboru, fmOpenRead pro čtení ze souboru, fmOpenWrite pro zapisování do již existujícího souboru).
Jak při zápisu do souboru tak při čtení ze souboru je třeba zadat adresu paměťového místa, jehož obsah se má do souboru přenést (nebo do něhož obsah souboru ukládáme), a počet přenášených bajtů.
Vše ostatní by mělo být z uvedeného výpisu zřejmé.

příklady
- 103 -
14 Příklady Naše skriptum uzavřeme dvěma komplexnějšími příklady programů. První příklad je
věnován stavovému automatu, příklad druhý potom interaktivnímu vykreslování přenosové charakteristiky, tj. vykreslování modulu a fáze přenosové charakteristiky filtru druhého řádu v semilogaritmickém grafu.
14.1 Stavový automat Stavový automat (state machine) může být s výhodou použit jako efektivní programo-
vací technika. V následujícím příkladě jej využijeme jako detektor sekvence znaků pro určení začátku a konce přenášené zprávy podle zvoleného komunikačního protokolu (pravidel komunikace) mezi klávesnicí a konzolou. Po programu budeme požadovat, aby nevypisoval znaky z klávesnice na obrazovku, dokud nezadáme posloupnost tří znaků s t a přestavující začátek zprávy a ukončil program po detekci posloupnosti znaků s t o, přičemž každý výskyt posloupnosti znaků s t a zadaných z klávesnice představuje začátek nové zprávy, která se začne vypisovat na nový řádek.
Popsaný systém je elementární analogií komunikačních protokolů datových sběrnic a počítačových sítí. Celý program můžeme vyjádřit diagramem o šesti stavech S1 až S6 s defi-novanými podmínkami přechodu (výraz nad čarou) a příkazem (výraz pod čarou); viz obr. 14.1.
Diagram z obr. 14.1. můžeme číst takto:
Začínáme od START přechodem na S1, kdy načítáme do proměnné ch znak z kláves-nice voláním funkce getch(). Pokud je načtený znak roven znaku s , realizuje se přechod na S2 a načte se další znak. Pokud tomu tak není, zachová se stav S1 a načte se další znak.
Tímto způsobem se dostaneme až do stavu S4, pokud jsme klávesnicí postupně zadali posloupnost s t a, nebo se program ukončí, pokud jsme zadali posloupnost s t o.
Dále bychom již měli být schopni pochopit funkci celého stavového automatu přímo z diagramu.
Pro vyjádření stavu použijeme přepínač switch, a jednotlivé přechody realizujeme modifikací parametru přepínače. Program poběží v nekonečné smyčce while(1) a jeho ukončení provedeme příkazem exit().
příklady
- 104 -
S1
S2
START Podmínka přechoduPříkaz
-ch=getch()
ch!=’s’ch=getch()
ch==’s’ch=getch()
ch!=’t’ch=getch()
S3(ch!=’a’)&&(ch!=’o’)
ch=getch()
ch==’t’ch=getch()
S4
ch==’a’ch=getch()
S5 S6
ch!=’s’putchar(ch)
ch==’s’ch=getch()
ch==’t’ch=getch()
ch==’o’exit()
STOP
ch!=’t’ putchar(’s’) putchar(ch)ch=getch()
(ch!=’o’)&&(ch!=’a’) putchar(’s’) putchar(’t’) putchar(ch)ch=getch()
(ch==’a’)putchar('\n')
putchar('\r')ch=getch()
ch==’o’exit()
Obr. 14.1 Stavový diagram přijímače zpráv.

příklady
- 105 -
void main(void) { char ch; //promenna pro nacitany znak int state=1; //parametr prepinace stavu, vychozi //hodnota = 1 ~ S1
while(1){ //nekonecna smycka ch=getch(); //nacteni jednoho znaku z klavesnice switch (state){ case 1 : //S1 if (ch=='s') state=2; //pokud je nacteny znak 's'-> //zmena prepinace na S2 break;
case 2: //S2 if (ch=='t') state=3; //pokud je nacteny znak 't'-> //zmena prepinace na S3 else state=1; //jinak změna propinace na S1 break;
case 3: //S3 if (ch=='a') state=4; //pokud je nacteny znak 'a'-> //zmena prepinace na S4 else{ if (ch=='o') exit(); //pokud je nacteny znak 'o'-> //konec programu else state=1; //pokud je znak různý od 'a' 'o' -> //zpet na stav S1 } break;
case 4: //S4 if (ch=='s') state=5; //pokud je nacteny znak 's'-> //zmena prepinace na S5 else putchar(ch); //pokud je nacteny znak různý od 's'-> //tisk znaku na monitor break;
case 5: //S5 if (ch=='t') state=6; //pokud je nacteny znak 't'-> //zmena prepinace na S6 else{ //pokud je nacteny znak ruzný od 't'-> putchar('s'); //tisk znaku 's' ze S4 na monitor putchar(ch); //tisk znaku aktualniho znaku v ch state=4; //zmena prepinace na S4 } break;
case 6: //S6 if (ch=='o') exit(); //pokud je nacteny znak 'o'-> //konec programu else{ if (ch=='a'){ //pokud je nacteny znak 'a'-> putchar('\n'); //skok na novy radek putchar('\r'); //skok na zacatek radku (oddeleni zprav) state=4; //zmena prepinace na S4 } else{ //pokud je znak různý od 'o' 'a' -> putchar('s'); //tisk znaku 's' ze S4 na monitor putchar('t'); //tisk znaku 't' ze S5 na monitor putchar(ch); //tisk znaku aktualniho znaku v ch state=4; //zmena prepinace na S4 } } break; } } }

příklady
- 106 -
14.2 Interaktivní vykreslování přenosové charakteristiky filtru V příkladu budeme interaktivně vykreslovat modul a fázi přenosové charakteristiky fil-
tru druhého řádu v semilogaritmickém grafu. Vyjdeme tedy z rovnice přenosové charakteris-tiky druhého řádu:
( )22
22
Ω+Ω
+
Ω+Ω
±=
pQ
p
pQ
ppK
ABC . (1)
Zde p = jω = j2πf značí komplexní úhlový kmitočet, Ω = 2πF úhlový mezní (rezonanční) kmitočet, Q jakost a A, B, C jsou váhovací koeficienty.
Rovnice (1) je základem pro konstrukci analogových (v některých přístupech i digitál-ních) kmitočtových filtrů.
Jedním ze způsobů vizualizace přenosových funkcí jsou modulová a fázová charakte-ristika (kmitočtový průběh modulu a argumentu přenosové funkce). Pro jejich získání musíme přenosovou funkci rozdělit na reálnou a imaginární část, jak je ukázáno v následujícím odvo-zení. V něm pro přehlednost definujeme substituční proměnné a, b, c, d:
( )( ) ( )
( ) ( )
.ImRe
)(
)(
2222
22
22
22
22
22
22
22
22
jdc
dacbjdc
dbca
jdcjba
Qd
cQ
b
a
Qj
Qj
Qj
Qj
jQ
j
jQ
jK
+=⎟⎠⎞
⎜⎝⎛
+−
+⎟⎠⎞
⎜⎝⎛
++
=
=++
=
Ω=
−Ω=
Ω±=
−Ω=
=
⎟⎟⎠
⎞⎜⎜⎝
⎛ Ω+−Ω
⎟⎟⎠
⎞⎜⎜⎝
⎛ Ω±−Ω
=
=Ω+
Ω+−
Ω+Ω
±−=
Ω+Ω
+
Ω+Ω
±=
ωω
ω
ω
ωω
ωω
ωω
ωω
ωω
ωωω
B
CABCA
ABCABC
(2)
Potom můžeme psát vztahy pro kmitočtové charakteristiky modulu a fáze:
( ) ,ImRe2
22
2
2222 ⎟
⎠⎞
⎜⎝⎛
+−
+⎟⎠⎞
⎜⎝⎛
++
=+=dc
dacbdc
dbcaK ω (3)
( )( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛+−
=⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
+++−
=⎟⎠⎞
⎜⎝⎛=
dbcadacbarctg
dcdbca
dcdacb
arctgarctgKArg22
22
ReImω . (4)
Nyní můžeme přistoupit k tvorbě programu. Nejprve si sestavíme formulář Form1, který se skládá z komponentů PaintBox PB1 a PB2, TrackBar TB1 až TB5 a ComboBox CB1 (viz obr. 14.2). Rozměry PB1 a PB2 v inspektoru objektů jsou Width = 961 a Height = 251. Rozsahy jezdců TB1 až TB4 jsou Max = 100 a Min = 0, u TB5 jsou Max = 100 a Min = l. Stav kom-ponentu CB1 bude určovat znaménko koeficientu B, jeho položka Items bude tedyobsahovat
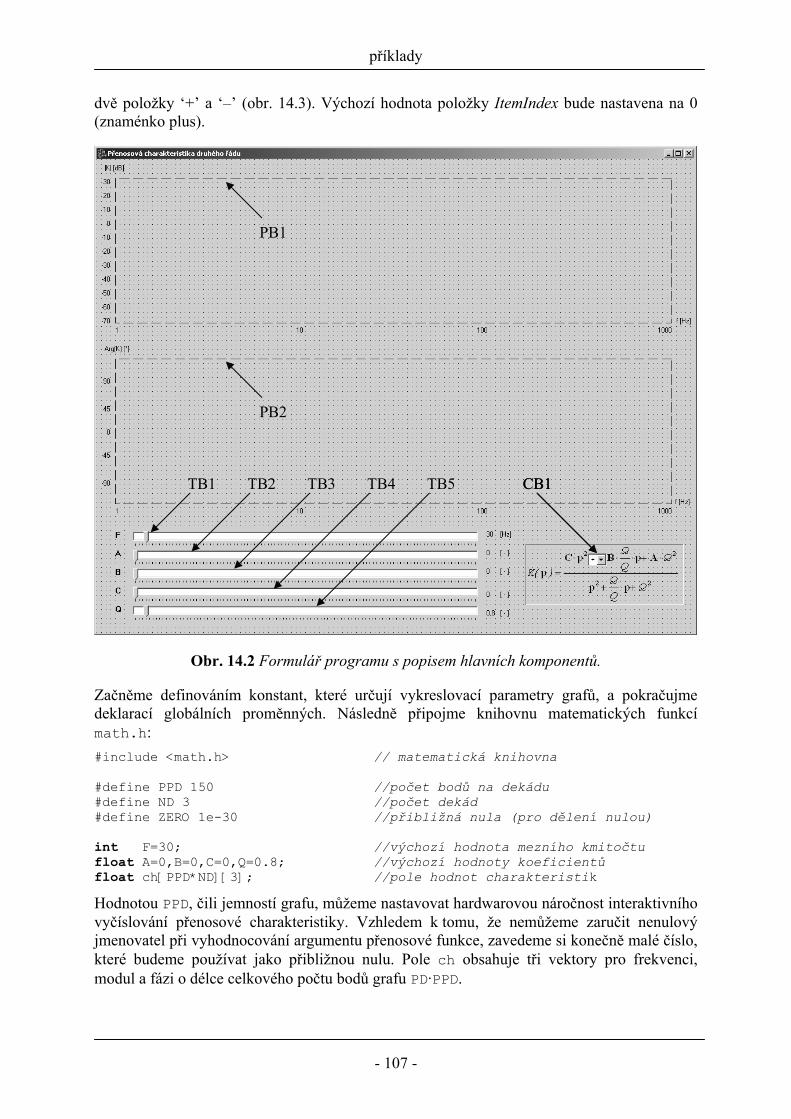
příklady
- 107 -
dvě položky ‘+’ a ‘–’ (obr. 14.3). Výchozí hodnota položky ItemIndex bude nastavena na 0 (znaménko plus).
Obr. 14.2 Formulář programu s popisem hlavních komponentů.
Začněme definováním konstant, které určují vykreslovací parametry grafů, a pokračujme deklarací globálních proměnných. Následně připojme knihovnu matematických funkcí math.h: #include <math.h> // matematická knihovna #define PPD 150 //počet bodů na dekádu #define ND 3 //počet dekád #define ZERO 1e-30 //přibližná nula (pro dělení nulou) int F=30; //výchozí hodnota mezního kmitočtu float A=0,B=0,C=0,Q=0.8; //výchozí hodnoty koeficientů float ch[PPD*ND][3]; //pole hodnot charakteristik
Hodnotou PPD, čili jemností grafu, můžeme nastavovat hardwarovou náročnost interaktivního vyčíslování přenosové charakteristiky. Vzhledem k tomu, že nemůžeme zaručit nenulový jmenovatel při vyhodnocování argumentu přenosové funkce, zavedeme si konečně malé číslo, které budeme používat jako přibližnou nulu. Pole ch obsahuje tři vektory pro frekvenci, modul a fázi o délce celkového počtu bodů grafu PD·PPD.
PB1
PB2
TB1 TB2 TB3 TB4 TB5 CB1 CB1

příklady
- 108 -
Dále vytvořme funkci eval(), která nám bude počítat požadované charakteristiky v kmitočtovém rozsahu definovaném konstantami PD a PPD. Funkce eval() nebude mít žádné vstupní parametry, bude pracovat jen s globálními proměnnými A, B, C, D, Q, F a vypočtené hodnoty bude ukládat do pole ch.
Obr. 14.3 Nastavení položky Items komponenty CB1.
Nejdříve deklarujme indexovací proměnné i, j, k, mezní úhlový kmitočet OMEGA, pomocné proměnné definované v (2), kmitočet f a úhlový kmitočet omega: void eval() //funkce vyčíslení přenosové f. { int i,j,k=0; float OMEGA=2*M_PI*F; //úhlový mezní kmitočet float omega,a,b,c,d,f; //pomocné proměnné
Dále zkontrolujme stav CB1 k určení znaménka koeficientu B: if (Form1->CB1->ItemIndex) B=-B;
Jak bylo zmíněno, chceme vykreslovat semilogaritmický graf, tedy graf s logaritmickou osou pro kmitočet. Proto není vhodné přenosovou funkci vyčíslovat v ekvidistantních krocích kmitočtu, protože bychom obdrželi nerovnoměrné rozložení hodnot v logaritmickém měřítku. Proto budeme volit kmitočet podle následujícího vztahu, který v logaritmické míře dává ekvidistantní rozdělení hodnot:
,1010 iPDDj
f ⋅= (5)
kde j = 1..PDD, i = 0..ND-1. V syntaxi jazyka C: for (i=0;i<ND;i++) { for (j=1;j<PPD+1;j++) { f = pow(10,j/float(PPD))*pow(10,i); //kmitočet
Jelikož jsme definovali konstantu PDD celým číslem, je prezentováno datovým typem int. Abychom dostali správný výsledek při dělení touto konstantou, je nutné ji přetypovat na datový typ float (viz kapitola 4.1).
Dále již jen vyčíslíme pomocné proměnné podle (2) a vztahy podle (3) a (4), které uložíme do pole ch na příslušné indexy. Aby nedocházelo k logaritmování nuly při převodu do decibelové míry, přičítáme k vypočtenému modulu přenosu konstantu ZERO. Také pokud bude jmenovatel při vyčíslování argumentu přenosu nulový, tedy relace((a*c+b*d)==0)

příklady
- 109 -
bude nabývat hodnoty 1, přičteme konstantu ZERO, aby nedošlo k dělení nulou, tj. +ZERO*((a*c+b*d)==0). omega=2*M_PI*f; //úhlový kmitočet a=A*pow(OMEGA,2)-C*pow(omega,2); //vyčíslení pomocných proměnných b=B*OMEGA*omega/Q; c=pow(OMEGA,2)-pow(omega,2); d=OMEGA*omega/Q; ch[k][0]=f; //vektor hodnot kmitočtu //vektor hodnot přenosu v dB ch[k][1]=20*log10(sqrt(pow((a*c+b*d),2) +pow((b*c-a*d),2))/(pow(c,2)+pow(d,2))+ZERO); //vektor hodnot fáze v deg. ch[k++][2]=atan((b*c-a*d)/(a*c+b*d+ZERO*((a*c+b*d)==0))) /(2*M_PI)*360;
Funkci pro vykreslení charakteristiky paint() sestavíme ze známých příkazů MoveTo(x,y) a LineTo(x,y) komponenty PaintBox. Konstanty pro umístění a škálování charakteristik budeme získávat obecnějšími konstrukcemi Form1->PB1->Height a Form1->PB1->Width na místo pevně zadaných číselných hodnot. void paint() // vykreslení průběhu { int n; Form1->PB1->Canvas->Pen->Width = 2; //nastavení tloušťky pera Form1->PB1->Canvas->Pen->Color = clRed; //nastavené barvy pera Form1->PB1->Canvas->MoveTo( 0,-ch[0][1]*3+75);//nastavení pozice pera for (n=0;n<PPD*ND;n++) // kreslení průběhu přenosu Form1->PB1->Canvas-> LineTo(log10(ch[n][0])*(Form1->PB2->Width-1)/3, -ch[n][1]*3+75); Form1->PB2->Canvas->Pen->Width = 2; //nastavení tloušťky pera Form1->PB2->Canvas->Pen->Color = clRed; //nastavené barvy pera Form1->PB2->Canvas-> MoveTo( 0,-ch[0][2]+(Form1->PB2->Height-1)/2);//nastavení pozice pera for (n=1;n<(PPD*ND);n++) // kreslení průběhu fáze Form1->PB2->Canvas-> LineTo(log10(ch[n][0])*(Form1->PB2->Width-1)/3, -ch[n][2]*(Form1->PB2->Height-1)/270+(Form1->PB2->Height-1)/2); }
Funkci vykreslení mřížky grafu grid() realizujeme podobně jako v předchozím. Logarit-mické rozmístění svislých čar získáme následujícím předpisem:
( )ijx 10log10 ⋅= , (6)
kde j = 1..9 a i = 0..ND-1. V syntaxi jazyka C:

příklady
- 110 -
void grid() //fce vykreslení mřížek { int i,j; //PB1, mřížka grafu přenosu Form1->PB1->Canvas->Pen->Color = clGray; Form1->PB1->Canvas->Pen->Width = 1; //svislé čáry, logaritmická stupnice for (i=0;i<(ND);i++) { for( j=1; j<10; j++) { Form1->PB1->Canvas-> MoveTo(log10(j*pow(10,i))*(Form1->PB1->Width-1)/3,0); Form1->PB1->Canvas-> LineTo(log10(j*pow(10,i))*(Form1->PB1->Width-1)/3, Form1->PB1->Height); } } Form1->PB1->Canvas-> MoveTo(log10(1*pow(10,ND))*(Form1->PB1->Width-1)/3,0); Form1->PB1->Canvas-> LineTo(log10(1*pow(10,ND))*(Form1->PB1->Width-1)/3,Form1->PB1->Height); //vodorovné čáry, lineární stupnice for (i=0;i<11;i++) { Form1->PB1->Canvas->MoveTo(0,i*(Form1->PB1->Height-1)/10); Form1->PB1->Canvas-> LineTo(Form1->PB1->Width-1,i*(Form1->PB1->Height-1)/10); } //orámování grafu Form1->PB1->Canvas->Pen->Color = clBlack; Form1->PB1->Canvas->Pen->Width = 3; Form1->PB1->Canvas->MoveTo(0,0); Form1->PB1->Canvas->LineTo(0,(Form1->PB1->Height-1)); Form1->PB1->Canvas->LineTo(Form1->PB1->Width-1,(Form1->PB1->Height-1)); //PB2, mřížka grafu fáze Form1->PB2->Canvas->Pen->Color = clGray; Form1->PB2->Canvas->Pen->Width = 1; //svislé čáry, logaritmická stupnice for (i=0;i<(ND);i++) { for( j=1; j<10; j++) { Form1->PB2->Canvas-> MoveTo(log10(j*pow(10,i))*(Form1->PB2->Width-1)/3,0); Form1->PB2->Canvas-> LineTo(log10(j*pow(10,i))*(Form1->PB2->Width-1)/3, Form1->PB2->Height); } } Form1->PB2->Canvas-> MoveTo(log10(1*pow(10,ND))*(Form1->PB2->Width-1)/3,0); Form1->PB2->Canvas-> LineTo(log10(1*pow(10,ND))*(Form1->PB2->Width-1)/3,Form1->PB2->Height);

příklady
- 111 -
//vodorovné čáry, lineární stupnice for (i=0;i<6;i++) { Form1->PB2->Canvas->MoveTo(0,i*(Form1->PB2->Height-1)/6); Form1->PB2->Canvas-> LineTo(Form1->PB2->Width-1,i*(Form1->PB2->Height-1)/6); } //orámování grafu Form1->PB2->Canvas->Pen->Color = clBlack; Form1->PB2->Canvas->Pen->Width = 3; Form1->PB2->Canvas->MoveTo(0,0); Form1->PB2->Canvas->LineTo(0,(Form1->PB2->Height-1)); Form1->PB2->Canvas->LineTo(Form1->PB2->Width-1,(Form1->PB2->Height-1)); }
Nyní máme vytvořené všechny potřebné funkce. Zbývá jen program sestavit a ošetřit pří-slušné události.
Při spuštění programu, tj. použitím události OnCreate hlavního formuláře Form1, vy-počteme charakteristiky z výchozích hodnot koeficientů, aby nebyly vykreslovány nesmyslná data: void __fastcall TForm1::FormCreate(TObject *Sender) { eval(); //vyčíslení funkce při spuštění }
Pro interaktivní vykreslování charakteristik ošetříme událost OnChange pro TB1 až TB5. Nejdříve sejmeme aktuální pozici jezdců TB1->Position, provedeme vhodné škálování a výsledek uložíme jako příslušný koeficient. Pozice jezdce je proměnná typu int, tudíž pro správný výsledek jej musíme přetypovat na datový typ float, tj. float(TB1->Position). Dále zobrazíme získané hodnoty koeficientů s zaokrouhlením na dvě desetinna místa Label1->Caption=floor(A*100)/100. Nakonec vyčíslíme přenosové charakteristiky funkcí eval() a vykreslíme mřížku a grafy funkcemi grid() a paint(): void __fastcall TForm1::TBChange(TObject *Sender) { F=float(TB1->Position)*10; //sejmutí pozic jezdců TB A=float(TB2->Position)/100; B=float(TB3->Position)/100; C=float(TB4->Position)/100; Q=float(TB5->Position)/5; Label1->Caption=F; //zobrazení hodnot koeficientů Label2->Caption=floor(A*100)/100; Label3->Caption=floor(B*100)/100; Label4->Caption=floor(C*100)/100; Label5->Caption=floor(Q*10)/10; eval(); //vyčíslení funkce Form1->PB1->Refresh(); //aktualizace PB, vyčistění plátna Form1->PB2->Refresh(); grid(); //vykreslení mřížky paint(); //vykreslení grafů }
Nakonec ošetříme správné překreslování okna programu použitím události OnPaint hlavního formuláře Form1:
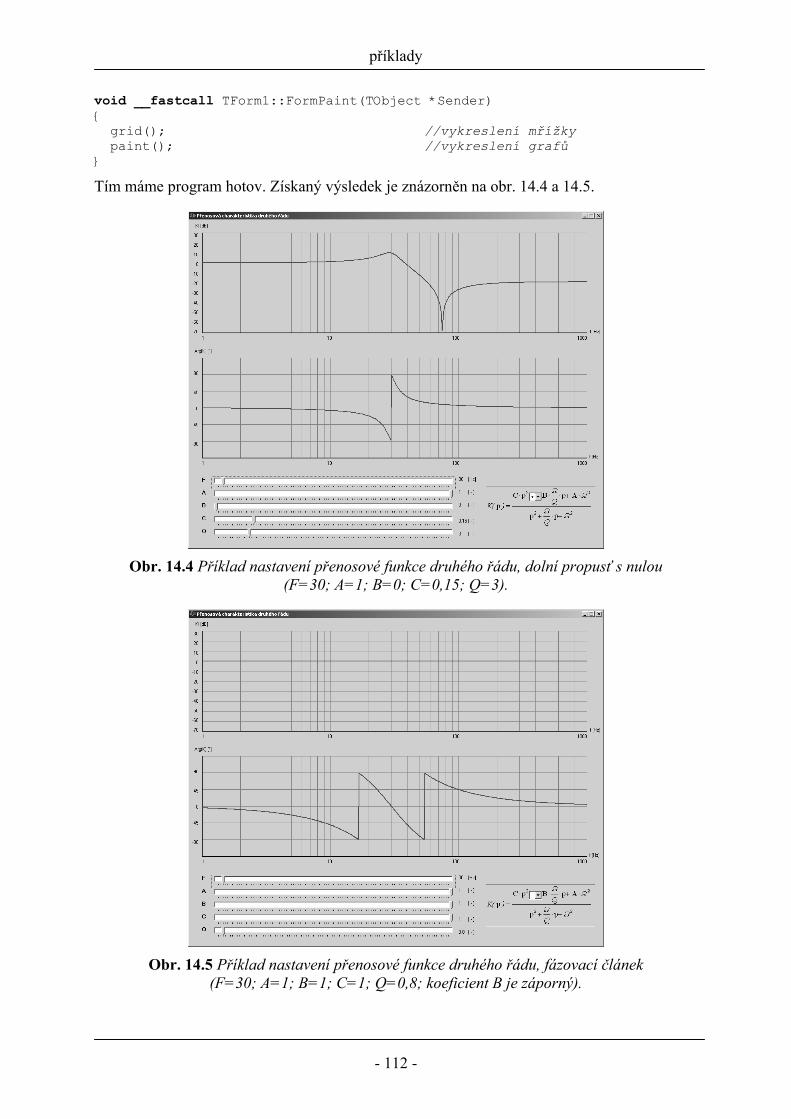
příklady
- 112 -
void __fastcall TForm1::FormPaint(TObject *Sender) { grid(); //vykreslení mřížky paint(); //vykreslení grafů }
Tím máme program hotov. Získaný výsledek je znázorněn na obr. 14.4 a 14.5.
Obr. 14.4 Příklad nastavení přenosové funkce druhého řádu, dolní propusť s nulou
(F=30; A=1; B=0; C=0,15; Q=3).
Obr. 14.5 Příklad nastavení přenosové funkce druhého řádu, fázovací článek
(F=30; A=1; B=1; C=1; Q=0,8; koeficient B je záporný).

literatura
- 113 -
15 Literatura [1] HEROUT, P. Učebnice jazyka C, 1. díl. 3. upravené vydání. České Budějovice: Kopp,
2001.
[2] HEROUT, P. Učebnice jazyka C, 2. díl. České Budějovice: Kopp, 1995.
[3] KADLEC, V. Učíme se programovat v C++ Builder a jazyce C++. Brno: Computer Press, 2002.
[4] VRÁNA, J. Práce s ukazateli v jazyce C [online]. Elektrorevue – internetový časopis. 2006, článek č. 29. Dostupné na: http://www.elektrorevue.cz/clanky/06029/index.html
[5] VIRIUS, M. Programovací jazyky C / C++. Praha: GComp, 1992.
[6] MATOUŠEK, D. C++Builder: vývojové prostředí. 1. díl. 3. rozšířené vydání. Praha: BEN – technická literatura, 2002.

















