Teorie složitosti. I když je problém rozhodnutelný (řešitelný algoritmicky), může mít příliš velké nároky na čas výpočtu nebo paměť, a může se tedy stát, že bude prakticky nerealizovatelný - PowerPoint PPT Presentation
38
Teorie složitosti I když je problém rozhodnutelný (řešitelný algoritmicky), může mít příliš velké nároky na čas výpočtu nebo paměť, a může se tedy stát, že bude prakticky nerealizovatelný Přestože často mluvíme o tom, že určitý algoritmus je „rychlý “ a jiný naopak „pomalý “, bylo by vhodné mít k dispozici určitou charakteristiku, která nám umožní různé algoritmy porovnávat Touto charakteristikou je časová (paměťová ) složitost Samozřejmě lze příslušné algoritmy naprogramovat, testovat jejich chování na různých instancích problému, měřit čas výpočtu (či využití paměti) a potom usuzovat na příslušné charakteristiky, ale to není příliš efektivní ani „praktické“
Transcript
Teorie složitosti
I když je problém rozhodnutelný (řešitelný algoritmicky), může mít příliš velké nároky na čas výpočtu nebo paměť, a může se tedy stát, že bude prakticky nerealizovatelný
Přestože často mluvíme o tom, že určitý algoritmus je „rychlý“ a jiný naopak „pomalý“, bylo by vhodné mít k dispozici určitou charakteristiku, která nám umožní různé algoritmy porovnávat
Touto charakteristikou je časová (paměťová) složitostSamozřejmě lze příslušné algoritmy naprogramovat, testovat
jejich chování na různých instancích problému, měřit čas výpočtu (či využití paměti) a potom usuzovat na příslušné charakteristiky, ale to není příliš efektivní ani „praktické“
Časová složitost
Odhlédneme-li od konkrétního hardwaru i softwarového prostředí, v němž je příslušný algoritmus implementován, můžeme časovou složitost charakterizovat počtem operací stroje, které je nutné během výpočtu provést
Nejde nám o přesný počet operací, ale o obecné vyjádření trendu růstu počtu operací stroje v závislosti na velikosti vstupních dat
Nechceme počítat přesný čas výpočtu pro data určité délky, ale spíše znát odpověď na otázku, kolikrát déle bude trvat výpočet jestliže vstupní data budou například desetkát větší než obvykle (eventuálně při testování programu).
Časová složitost
Délka výpočtu samozřejmě závisí i na některých dalších parametrech a konkrétním charakteru úlohy
Pro třídící algoritmus může být velký rozdíl, zda je posloupnost již téměř setříděná, nebo naopak setříděná zcela opačně; u grafu může být u některých úloh důležitý například maximální stupeň vrcholu; matice o stejném rozměru může být řídká nebo naopak hustá atd.
Stejný algoritmus může proto „běžet“ mnohem déle na nejnepříjemnějších datech a naopak být poměrně rychlý na datech jiných (a přesto budou vždy délky n)
Časová složitost
Většinou mluvíme o složitosti v nejhorším případě (pesimistická složitost), kdy dosažený výsledek platí univerzálně, ale někdy se užívá i průměrná složitost, kdy se na základě pravděpodobnosti výskytu určitých dat zjišťuje střední hodnota složitosti výpočtu (bývá těžší odhadnout)
DEF: Nechť T je deterministický Turingův stroj, který se zastavuje na všechny vstupy. Časová složitost T je funkce f:NN, kde f(n) je maximální počet kroků, které stroj T udělá na libovolný vstup délky n.
Časová složitost
Příklad: Časová složitost algoritmu pro přijímání jazyka L={0k1k| k 0}
Řešení:
Délka vstupních dat: k+k=2k=n
1. Příslušný TS nejprve zkontroluje, zda jde o posloupnost 0i1j k čemuž potřebuje n kroků, potom n kroků zpět na začátek pásky … 2n kroků
2. Dokud jsou na pásce nuly i jedničky:
postupně vždy smaže první 0, udělá i kroků, smaže 1 a udělá i kroků zpět …1+i+1+i=2i+2 kroků pro i nul => celkem(2i+2)*n/2<(2n+2)*n/2
3. Pokud už není na pásce žádná nula, zkontroluje se, že už tam není ani žádná jednička a skončí … j+1n kroků
Časová složitost
Celkem: 2n + (2n+2)*n/2 + n = 3n + n2+n = n2+4n
Už v předchozím počítání kroků jsme se dopouštěli jistých odhadů a zjednodušení ( např. (2i+2)*n/2<(2n+2)*n/2 )
Zajímá nás asymptotická složitost, tj. uvažujeme velký rozsah vstupních dat (tedy velká n) a potom je zřejmé, že druhou část výrazu n2+4n můžeme zanedbat.
n2+4n n2
Vzhledem ke kvadratické závislosti z tohoto výsledku usuzujeme, že například pro 10x rozsáhlejší vstupní data bude výpočet trvat 100x déle atd.
Časová složitost
Hovoříme o takzvané asymptotické složitosti.
Přesný výpočet počtu kroků TS je zbytečně komplikovaný už i u celkem jednoduchých algoritmů. U větších programů by to bylo nemožné a my ani nepotřebujeme znát přesné číslo.
Můžeme tedy zanedbávat „drobné“ členy, které se významněji projevují při malých hodnotách n (n2+4n n2), i konstanty, kterými je funkce f násobena a které ovlivňují konkrétní číselnou hodnotu výsledku, ale nikoliv rychlost růstu (kn2 n2 – pořád jde o kvadratický růst a od určitého dostatečně velkého n můžeme konstantu k zanedbat)
Funkce f(n)=0.001n3 roste mnohem rychleji než g(n)=1000n2
(Pro všechna n > 1 000 000 platí než f(n) > g(n) )
Časová složitost
Čas pro vykonání jednotlivých instrukcí na konkrétním hardwaru není stejný, ale jelikož jde vždy o několik taktů, můžeme i tuto skutečnost zanedbat. Stačí, pokud platí předpoklad, že existuje konstanta k, která omezuje maximální počet taktů pro vykonání jedné instrukce.
Někdy zase můžeme výpočet složitosti zjednodušit tím, že zcela zanedbáváme některé instrukce. U třídících algoritmů například počítáme obvykle jen instrukce porovnávání klíčů a nikoliv už instrukce případné výměny prvků, jelikož je jich nejvýše stejně jako instrukcí porovnání (n+n=2n n)
Obecně lze říci, že pokud existuje konstanta k, která omezuje počet „pomocných“ instrukcí vzhledem k počtu instrukcí, které bereme v úvahu, můžeme ty „pomocné“ zanedbat.
Značení O, ,
Díky soustředění se na „rozhodující“ člen výrazu a zanedbávání podrobností můžeme zavést a využívat následující pojmy.
DEF: Pro libovolné dvě funkce f, g: NN řekneme, že fO(g) (čteme „f je ve velkém O g“ či zjednodušeně „f je velké O g“), právě když kN n0N n>n0 : f(n) kg(n)
Pokud fO(g), říkáme také, že funkce f roste řádově nejvýše jako funkce g (funkce g je horní odhad funkce f)
Značení O, ,
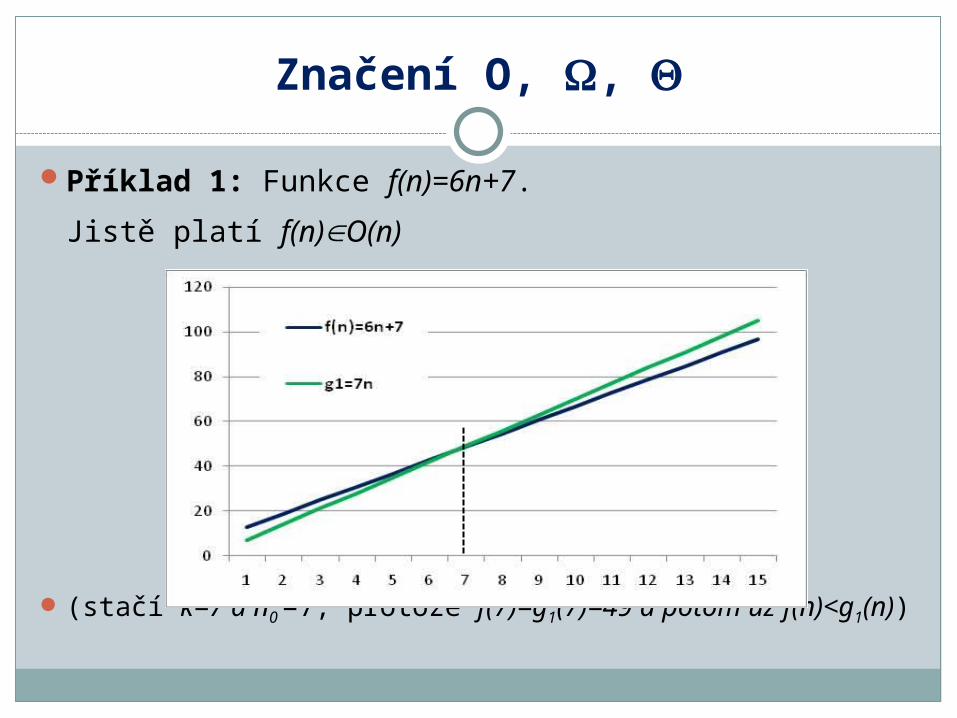
Příklad 1: Funkce f(n)=6n+7.
Jistě platí f(n)O(n)
(stačí k=7 a n0 =7, protože f(7)=g1(7)=49 a potom už f(n)<g1(n))
Značení O, ,
DEF: Pro libovolné dvě funkce f, g: NN řekneme, že f(g) (čteme „f je ve velkém g“ či zjednodušeně „f je velké g“), právě když kN n0N n>n0 : f(n) kg(n)
Pokud f (g), říkáme také, že funkce f roste řádově nejméně jako funkce g (funkce g je dolní odhad funkce f)
DEF: Pro libovolné dvě funkce f, g: NN řekneme, že f(g) (čteme „f je ve velkém g“ či zjednodušeně „f je velké g“), právě když fO(g) a současně f(g).
Pokud f (g), říkáme také, že funkce f roste asymptoticky řádově stejně rychle jako funkce g.
Značení O, ,
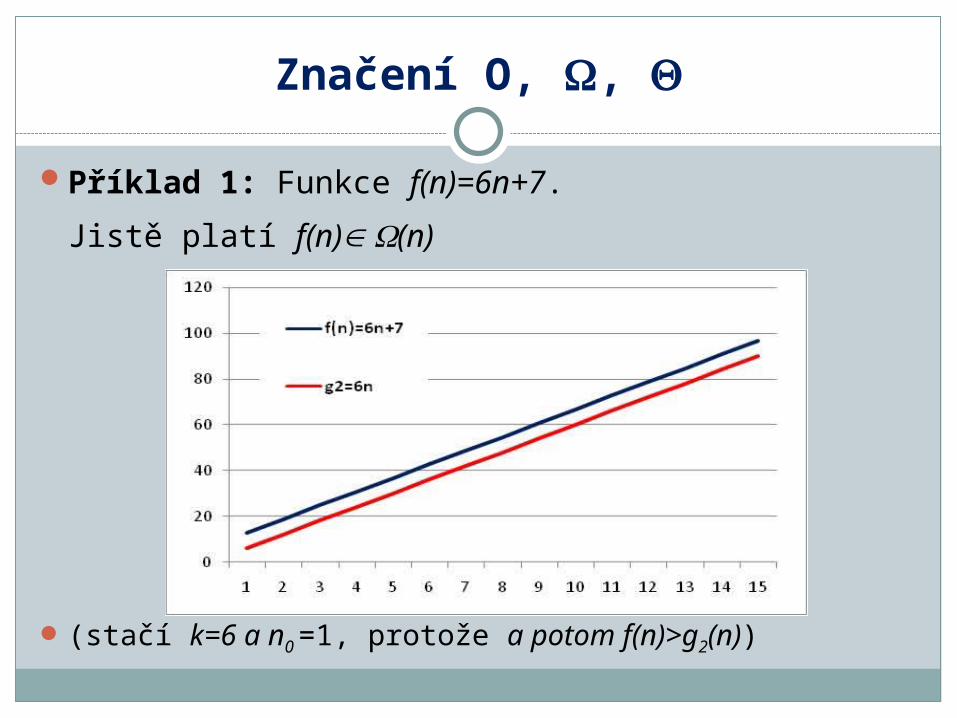
Příklad 1: Funkce f(n)=6n+7.
Jistě platí f(n) (n)
(stačí k=6 a n0 =1, protože a potom f(n)>g2(n))
Značení O, ,
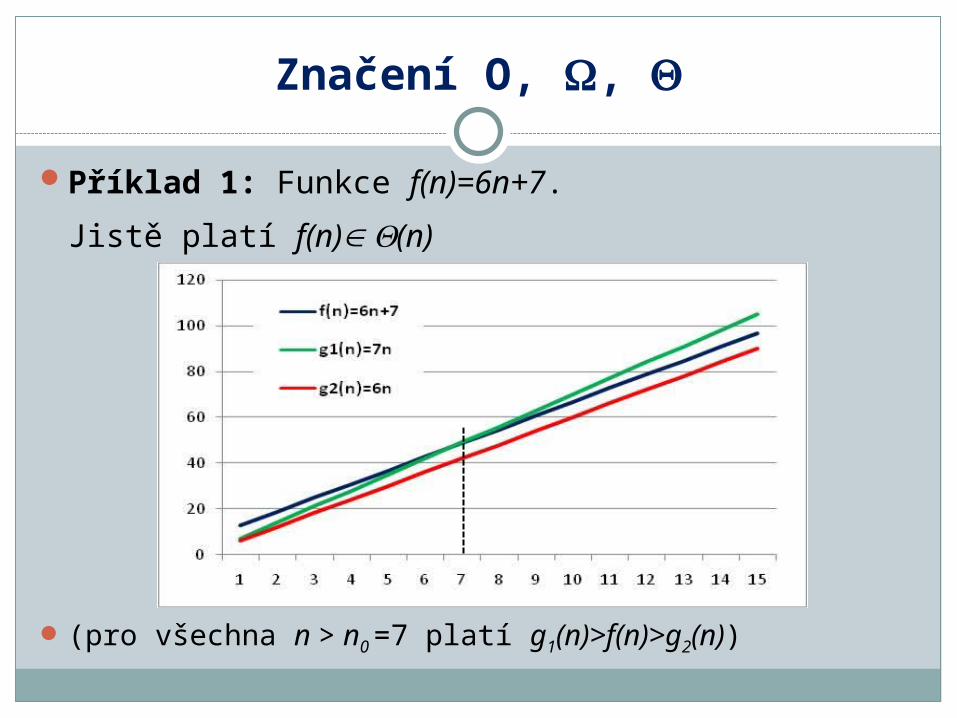
Příklad 1: Funkce f(n)=6n+7.
Jistě platí f(n) (n)
(pro všechna n > n0 =7 platí g1(n)>f(n)>g2(n))
Různá složitost
DEF: Funkci f říkámelineární, pokud platí f (n), kvadratická, pokud platí f (n2), logaritmická, pokud platí f (log n),polynomiální, pokud platí f (nc) pro nějaké c>0,exponenciální, pokud platí f (cn) pro nějaké c>1.
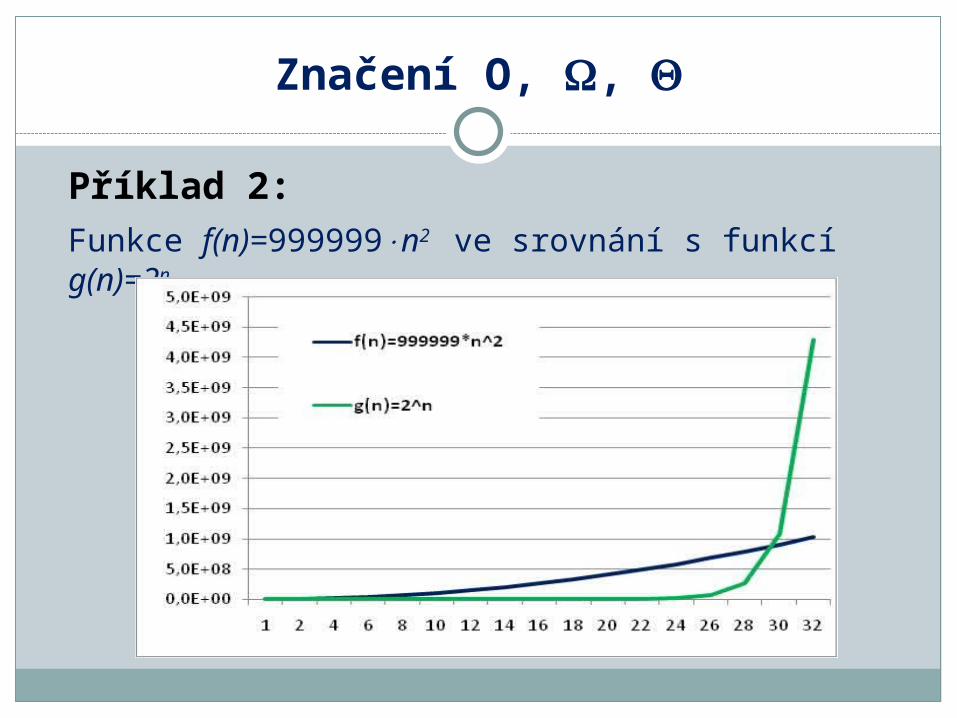
Příklad 2: Funkce f(n)=999999n2 se ve srovnání s funkcí g(n)=2n
zdá být dosti velká, ale stačí zvolit například n=30 a g(30)>f(30)
Příklad 2: Funkce f(n)=999999n2 ve srovnání s funkcí g(n)=2n
Značení O, ,
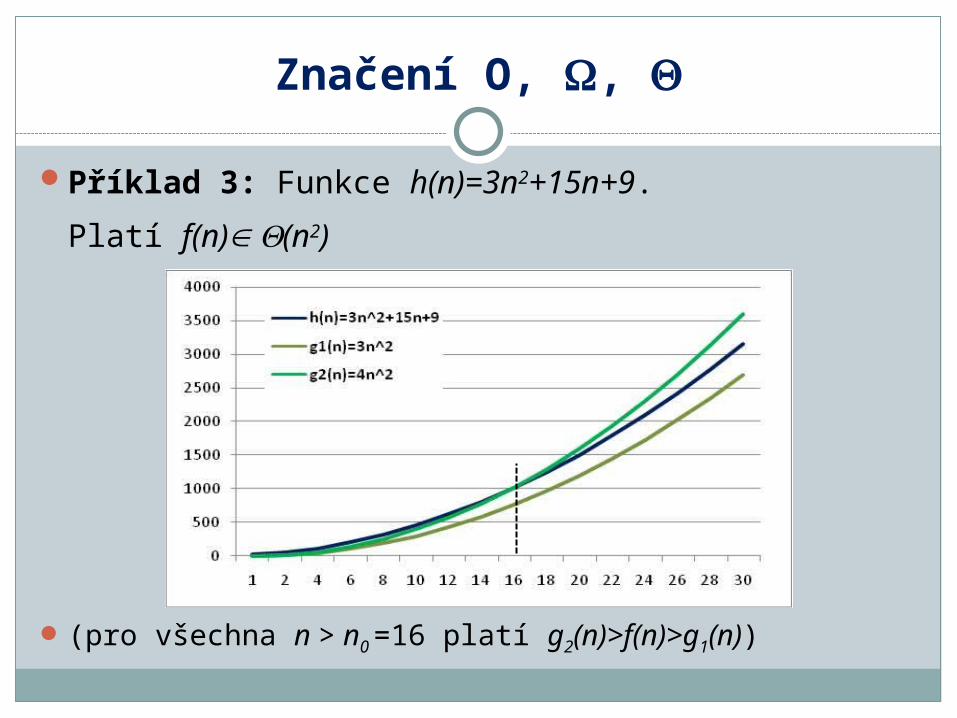
Příklad 3: Funkce h(n)=3n2+15n+9.
Platí f(n) (n2)
(pro všechna n > n0 =16 platí g2(n)>f(n)>g1(n))
Složitost algoritmu
Příklad 4: Jakou složitost má algoritmus pro výpočet aritmetického průměru n čísel?Řešení:
prumer(X,n)pom:=0for i:=1 to n do pom:=pom+X[i]return pom/n
Máme n čísel v poli X a cyklus for se vykoná n-krát, takže n-krát se bude přičítat číslo, n-krát se bude inkrementovat i a kdybychom chtěli být opravdu korektní, n+1-krát se bude porovnávat i<n; potom ještě závěrečné dělení je 1 instrukce.Celkem tedy f(n)= 3n+2 a platí f (n) => lineární složitost
Složitost algoritmu
Příklad 5: Jakou složitost má algoritmus:prg2(n)for i:=1 to n*n do for j:=1 to i do print „ahoj“
Řešení:Vnější cyklus for vykoná n2-krát, počet iterací vnitřního cyklu závisí na proměnné i vnějšího cyklu. Vnitřních iterací (a tisků) proběhne tedy1+2+3+….+n2= n2(n2+1)/2Celkem tedy f(n)= (n4+ n2)/2 Platí f (n4) => polynomiální složitost
Složitost algoritmu
Příklad 6: Jakou složitost má algoritmus přímého zatřiďování n čísel?
Řešení:Nalezení největšího prvku v poli proběhne v jednom průchodu polem … n kroků (uvažuji jen porovnávání, ostatní instrukce zanedbávám). Pro druhý největší prvek už to bude jen n-1 kroků, …Celkově tedy n+ n-1 +….+3+2+1= n(n+1)/2 krokůPotom f(n)= (n2+ n)/2 Platí f (n2) => kvadratická složitost
Složitost algoritmu
Příklad 7: Jakou složitost má algoritmus bublinkového třídění n čísel?
Řešení:Pokud je posloupnost setříděná, projde se pole jednou, není co „probublávat“ a třídění končí … O(n) V případě, že posloupnost je setříděná opačně (největší prvek je první) při prvním průchodu se dostane (propadne) první prvek na své (poslední) místo … n kroků Při k-tém průchodu se „usadí“ k-tý prvek … n kroků Při n-tém průchodu se již jen ověří, že je „uspořádáno“… n Celkově tedy n+ n +….+n+n= nn krokůPotom f(n)= n2, platí f (n2) => kvadratická složitost
Složitost algoritmu
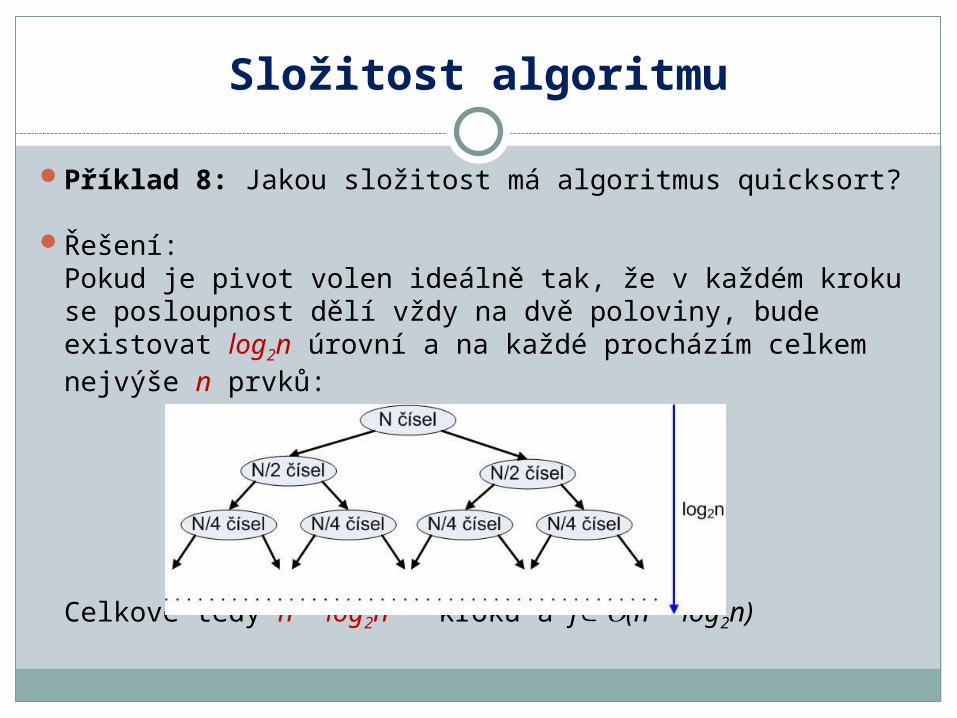
Příklad 8: Jakou složitost má algoritmus quicksort?
Řešení:Pokud je pivot volen ideálně tak, že v každém kroku se posloupnost dělí vždy na dvě poloviny, bude existovat log2n úrovní a na každé procházím celkem nejvýše n prvků:
Celkově tedy n log2n kroků a f (n log2n)
Složitost algoritmu
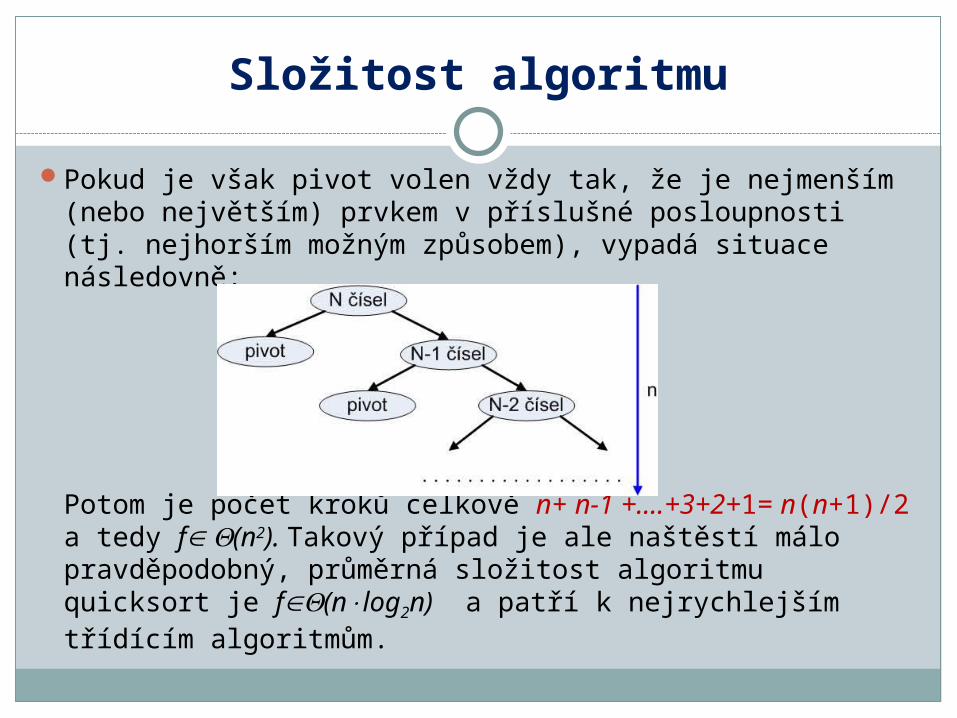
Pokud je však pivot volen vždy tak, že je nejmenším (nebo největším) prvkem v příslušné posloupnosti (tj. nejhorším možným způsobem), vypadá situace následovně:
Potom je počet kroků celkově n+ n-1 +….+3+2+1= n(n+1)/2a tedy f (n2). Takový případ je ale naštěstí málo pravděpodobný, průměrná složitost algoritmu quicksort je f(nlog2n) a patří k nejrychlejším třídícím algoritmům.
Složitost algoritmu
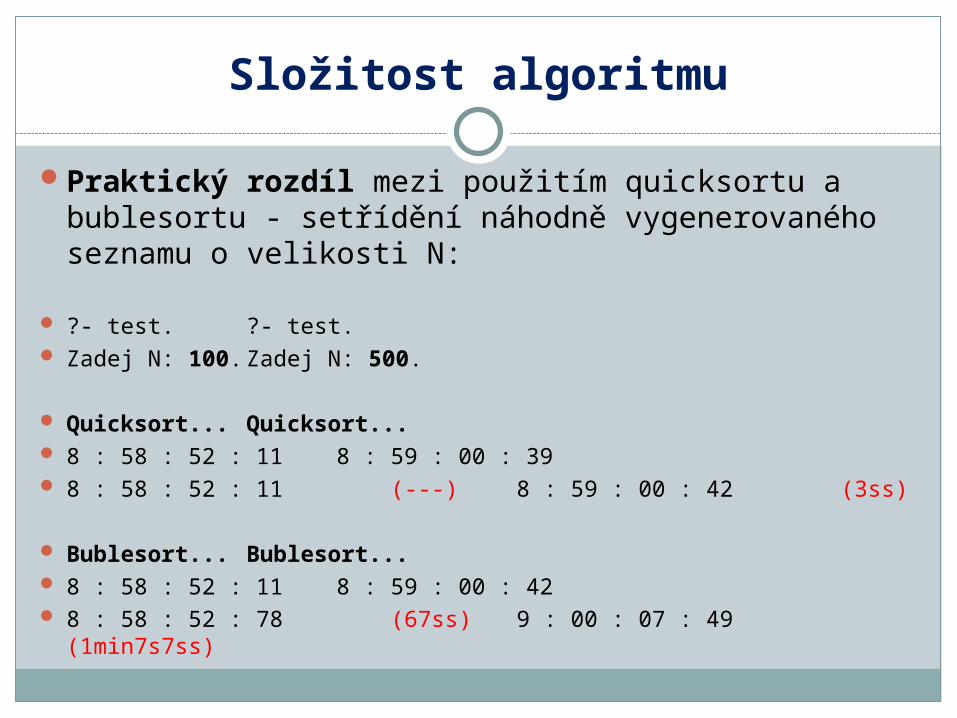
Praktický rozdíl mezi použitím quicksortu a bublesortu - setřídění náhodně vygenerovaného seznamu o velikosti N:
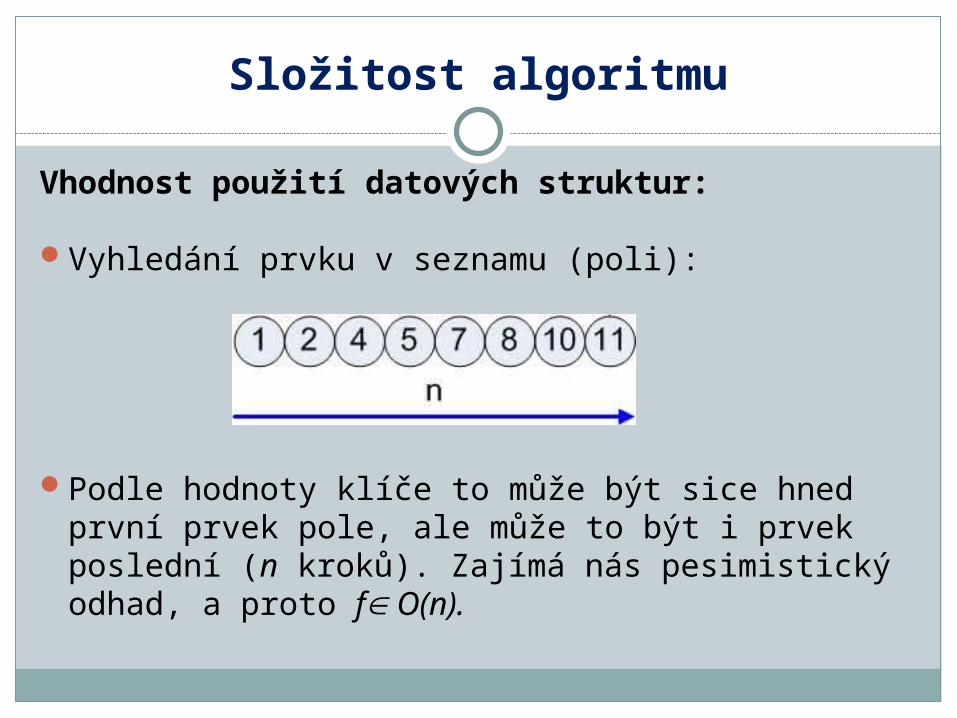
Podle hodnoty klíče to může být sice hned první prvek pole, ale může to být i prvek poslední (n kroků). Zajímá nás pesimistický odhad, a proto f O(n).
Složitost algoritmu
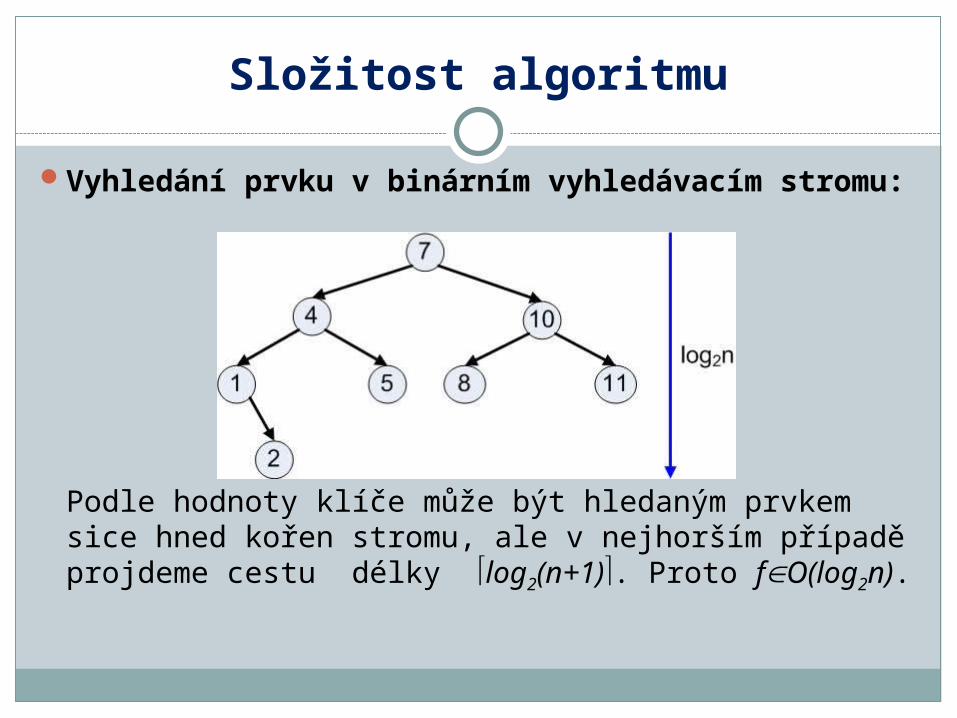
Vyhledání prvku v binárním vyhledávacím stromu:
Podle hodnoty klíče může být hledaným prvkem sice hned kořen stromu, ale v nejhorším případě projdeme cestu délky log2(n+1). Proto fO(log2n).
Složitost algoritmu
Příklad 9: Jakou složitost má algoritmus pro zjištění, že graf G=(V,E) s n vrcholy a m hranami je souvislý?
Algoritmus:1. Vezmi libovolný vrchol vi a nechť S={vi} a Pom=Ø2. Najdi všechny vj, pro které existuje hrana (vi,vj) a přidej každé vjS a vjPom do Pom 3. Jestliže Pom=Ø konec a jestliže |S|=n „graf je souvislý“, jinak „nesouvislý graf“4. Vyjmi libovolné viPom, přidej jej do množiny S a pokračuj krokem číslo 2.
Složitost: fO(nm)
Složitost algoritmu
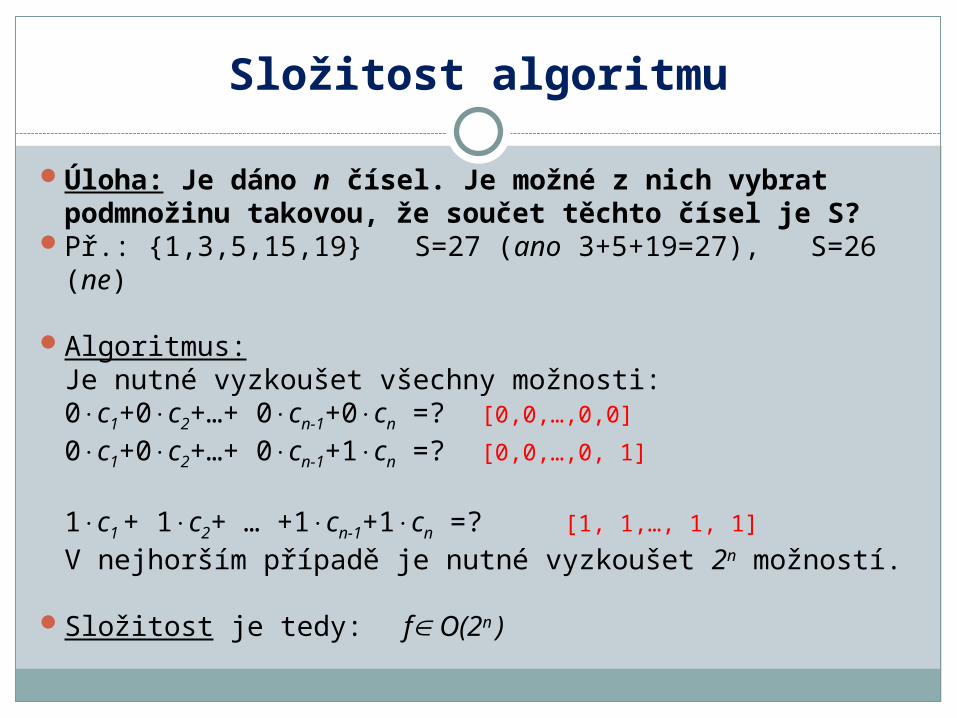
Úloha: Je dáno n čísel. Je možné z nich vybrat podmnožinu takovou, že součet těchto čísel je S?
V nejhorším případě je nutné vyzkoušet 2n možností.
Složitost je tedy: f O(2n )
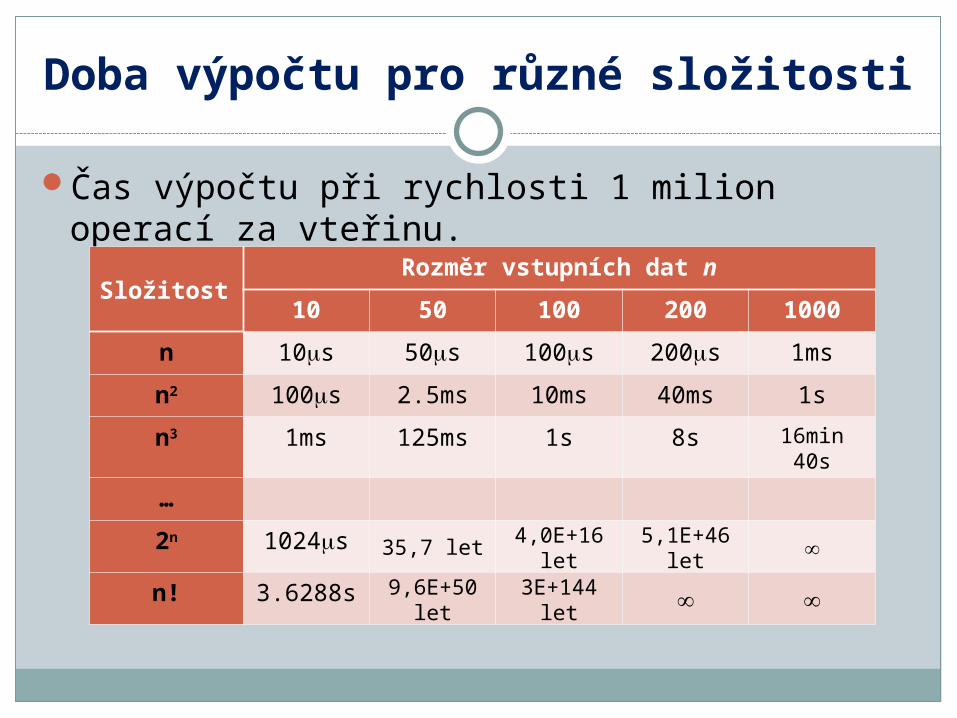
Doba výpočtu pro různé složitosti
Čas výpočtu při rychlosti 1 milion operací za vteřinu.
SložitostRozměr vstupních dat n
10 50 100 200 1000
n 10s 50s 100s 200s 1ms
n2 100s 2.5ms 10ms 40ms 1s
n3 1ms 125ms 1s 8s 16min 40s
…
2n 1024s 35,7 let 4,0E+16 let
5,1E+46 let
n! 3.6288s 9,6E+50 let
3E+144 let
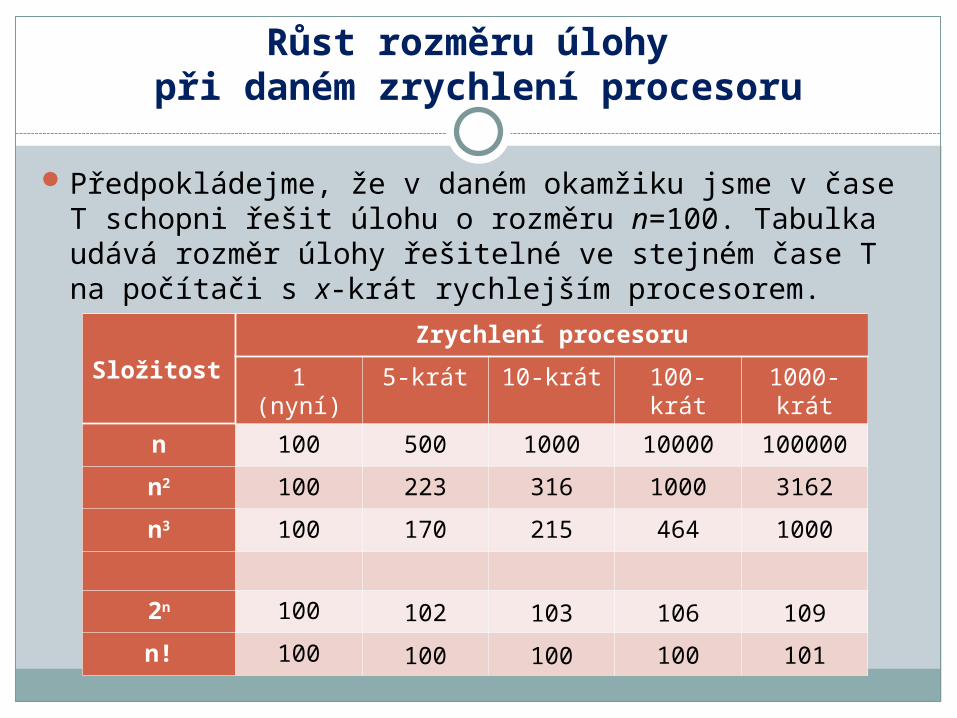
Růst rozměru úlohy při daném zrychlení procesoru
Předpokládejme, že v daném okamžiku jsme v čase T schopni řešit úlohu o rozměru n=100. Tabulka udává rozměr úlohy řešitelné ve stejném čase T na počítači s x-krát rychlejším procesorem.
SložitostZrychlení procesoru
1 (nyní) 5-krát 10-krát 100-krát 1000-krát
n 100 500 1000 10000 100000
n2 100 223 316 1000 3162
n3 100 170 215 464 1000
2n 100 102 103 106 109
n! 100 100 100 100 101
Praktický pohled na složitost
Úlohy řešitelné v polynomiálně omezeném čase považujeme za prakticky řešitelné, zatímco úlohy s exponenciální složitostí jsou již pro relativně malé hodnoty n prakticky nezvládnutelné.
Pro programátora je samozřejmě důležité, zda algoritmus, který programuje, má složitost O(n), O(n2) nebo O(n4), ale z teoretického hlediska je zásadní rozdíl mezi složitostí polynomiální („rychlé“ algoritmy) a složitostí exponenciální.
Algoritmus se složitostí O(n1000) samozřejmě nelze považovat za rychlý, ale pro většinu praktických problémů řešitelných v polynomiálně omezeném čase známe algoritmy s relativně nízkým stupněm polynomu.
Praktický pohled na složitost
Většinou se ukazuje, že jestliže pro určitý problém existuje algoritmus řešící daný problém v polynomiálně omezeném čase, na základě důkladné analýzy a pochopení podstaty problému se podaří navrhnout prakticky použitelný algoritmus s rozumným stupněm polynomu.
Pro libovolnou třídu složitosti O(nk), kde k>0 lze samozřejmě zkonstruovat problém, který není řešitelný v čase O(nk), ale dá se řešit v čase O(nk+1). Naštěstí jde o uměle konstruované problémy bez praktického využití.
Teoretický pohled na složitost
Z teoretického hlediska není nutné se zabývat rozdílem mezi algoritmy se složitostí O(n) a O(n3), neboť je považujeme za dostatečně rychlé a zvládnutelné.
Proto můžeme přistoupit k zjednodušujícímu pohledu na celou problematiku, kdy zanedbáme rozdíly mezi různými stupni polynomiální složitosti a budeme nadále uvažovat pouze dvě třídy problémů – třídu se složitostí polynomiální a třídu s exponenciální složitostí.
Algoritmy s exponenciální složitostí jsou typicky spjaté s tzv. metodou „hrubé síly“ (brute-force search), kdy se pokoušíme řešit problém úplným prohledáním celého stavového prostoru (tj. vyzkoušením všech možností).
Třída P (PTIME)
DEF: Nechť t:NR+ je funkce. Časová třída složitosti TIME(t(n)) obsahuje všechny jazyky, které jsou rozhodnutelné Turingovým strojem v čase O(t(n)).
Příklad: Třída TIME(n2) obsahuje všechny jazyky,které jsou rozhodnutelné Turingovým strojem v čase O(n2).
Navrhněte vhodný algoritmus pro tuto úlohuUrčete složitost navrženého algoritmuNavrhněte případně algoritmus rychlejší
Cvičení
Úloha 3: V zadané posloupnosti reálných čísel P1 délky N1 nalezněte nejdelší úsek, který neobsahuje žádný prvek z druhé zadané posloupnosti P2 o délce N2.