25
Vyhledávání v multimediálních databázích Tomáš Skopal KSI MFF UK 6. Metrické přístupové metody (MAM) 1. část – multidimenzionální metody a principy MAM
| Date post: | 30-Dec-2015 |
| Category: |
Documents |
| Upload: | axel-walter |
| View: | 28 times |
| Download: | 0 times |

Vyhledávání v multimediálních databázích
Tomáš SkopalKSI MFF UK
6. Metrické přístupové metody (MAM) 1. část – multidimenzionální metody a principy MAM

Osnova
motivace využití multidimenzionálních metody
přímé použití – indexování vektorových dat a příslušná omezení
nepřímé použití – indexování mapovaných vektorů principy metrických přístupových metod
míry efektivity vyhledávání reprezentace datového prostoru
nadrovinové dělení prostoru hyper-kulové dělení prostoru
vlastnosti metrik užívané k filtrování při dotazech

Motivace
drahá podobnostní funkce (omezíme se na metriky)
velký objem dat velký počet uživatelů kladoucích dotazy
potřeba rychlé metody vyhledávání, minimalizující spotřebu strojového času

Multidimenzionální metody (1)
původní řešení – využítí metod vícerozměrného indexování (např. R-strom, X-strom, VA-file, atd.), a to buď přímo – pokud data už jsou vektory nepřímo – indexováním vektorů, které vznikly jako výstup
mapovacích metod většinou optimalizováno pro window queries (dotaz je
obdélník) většinou obdélníkové regiony v prostoru
jednoduchá reprezentace snadná tvorba nadregionů, slučování/rozdělování regionů, atd. snadné filtrační operace – dotazování obdélníkem
někdy kulové (SS-strom) či jiné tvary regionů (pyramidový strom), případně kombinace koule/obdélník (SR-strom)

Multidimenzionální metody (2)
výhody využití existujících, prověřených a optimalizovaných metod (většinou) nezávislost organizace indexu na konkrétní metrice lze využít vlastností vektorových prostorů
– tj. objem, povrch, atd. lze indexovat nejen body, ale geometrie (např. polygony) – využití v
CAD, GIS, atd. ovšem pro účely „bodového“ modelu podobnostního vyhledávání
nepoužitelné nevýhody
shlukování podle objemu či povrchu nemusí být ideální pro shlukování podle vzdáleností – vede k neoptimálnímu filtrování
většinou optimalizováno pro minimalizaci pouze I/O nákladů pouze vektorová data anebo nutnost přemapovat (potom je třeba
počítat s false hity a výsledek dofiltrovat) efektivita vyhledávání velmi rychle klesá s rostoucí dimenzí (tzv. prokletí
dimenzionality, viz pozdější přednášky)
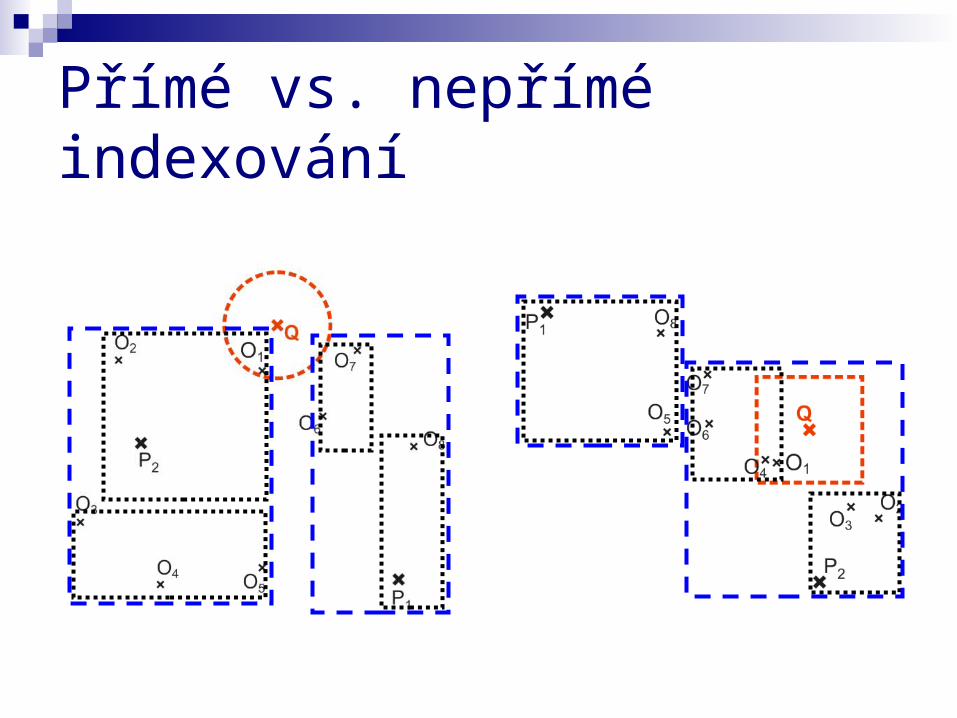
Přímé vs. nepřímé indexování

R-strom a varianty
vyvážená hierarchie minimálních ohraničujících obdélníků, v listech data
logaritmická složitost základních operací (vložení, vymazání, bodový dotaz)
R*-strom vylepšená heuristika pro rozdělování přeplněných uzlů – kromě
minimálního objemu MBR také povrch a překryv forced reinsert (vynucené znovuvložení) pro předcházení
častých štěpení – znovuvloží se ty objekty, které jsou nejdále od středu regionu (zvyšuje se také využití uzlů)
R+-strom MBR se nepřekrývají – velká režie konstrukce, obzvlášť při
vysoké dimenzi
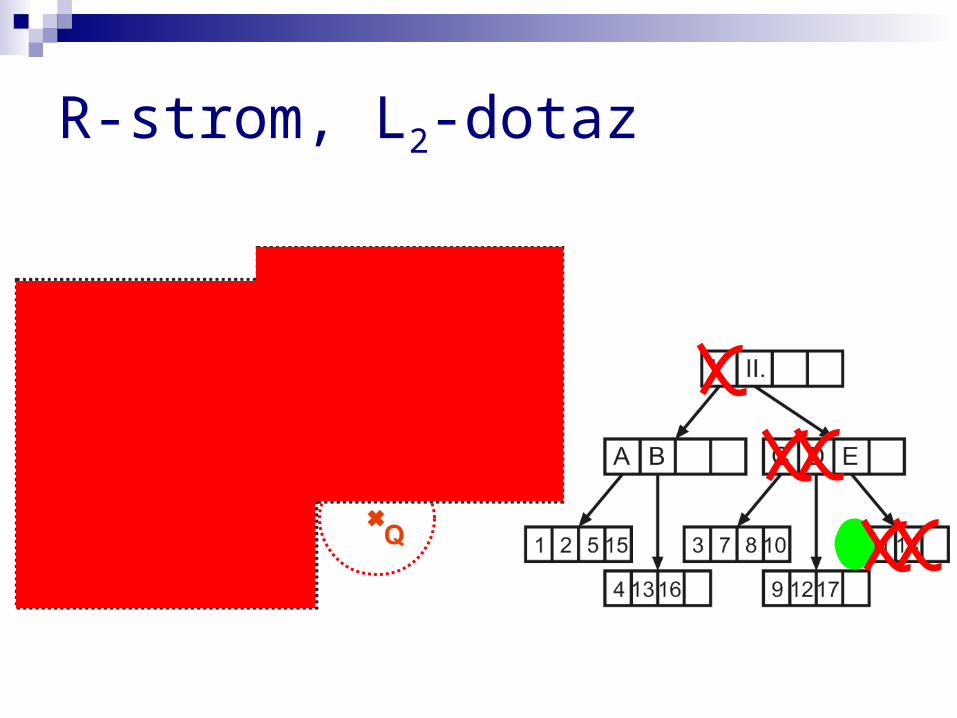
R-strom, L2-dotaz
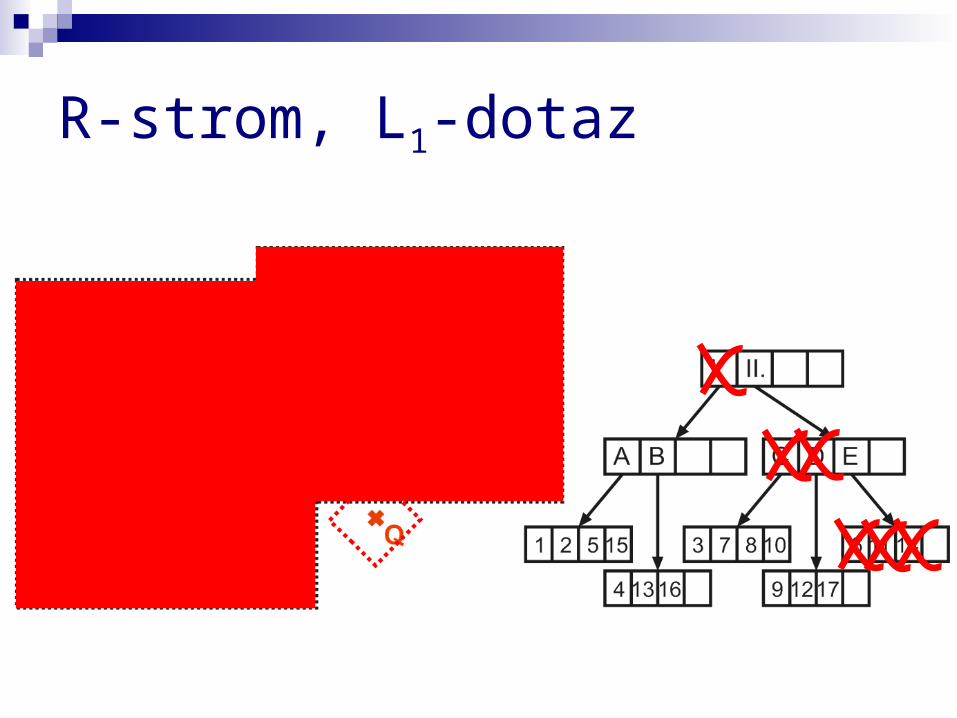
R-strom, L1-dotaz

X-strom vychází z R*-stromu uzly se štepí tak, aby nedocházelo k překryvům
využívá se historie štěpení (reprezentovaná binárním stromem) pokud dojde na štěpení vnitřního uzlu X, mohou nastat
dva případy obě kořenové větve historie štepení (binárního stromu) obsahují
víceméně stejný počet listů – potom dojde k rozštěpení uzlu X jedna větev historie obsahuje výrazně více listů – potom se uzel
X neštěpí, ale zvětší se jeho kapacita (stane se z něj tzv. superuzel)
X-strom vykazuje výrazně lepší výkonnost pro středně dimenzionální data než R*-strom
pro vysokodimenzionální data ovšem selhává (jako ostatně všechno), takže je lepší použít sekvenční průchod

VA-file
pole signatur, kde každá signatura aproximuje jeden datový vektor
v podstatě jde o kompresi každá souřadnice se reprezentuje několika málo bity,
místo několika bytů signatura aproximuje vektor, tj. lze ji chápat jako MBR,
uvnitř něhož se datový vektor nachází vyhledávání v první fázi odfiltruje signatury (MBRs),
které nepřekrývají dotaz – zbytek se dofiltruje jako obyčeně – na skutečných vektorech
je vhodný pro indexování vysokodimenzionálních dat, protože index (pole signatur) je z disku načítáno sekvenčně, tj. rychle
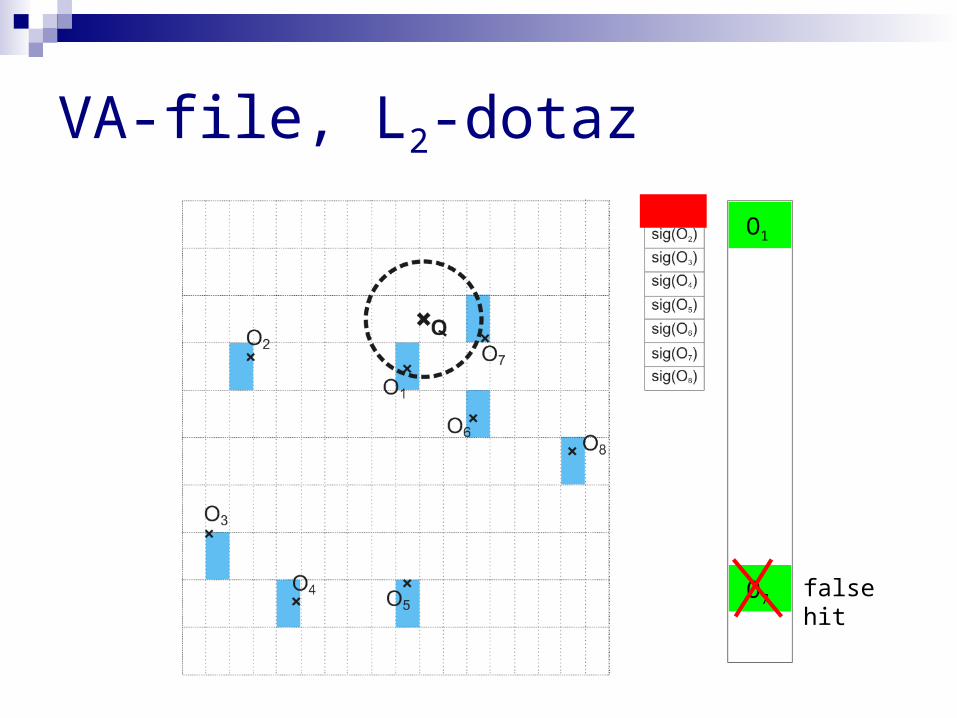
VA-file, L2-dotaz
O1
O7 false hit

Problém filtrace
průnik dvou koulí stejné metriky – triviální jak obecně zjistit průnik dvou koulí rozdílných metrik?
např. koule a obdélník, tj. L2(Q,rQ) a L(Oi,rOi), resp. vážená L
diamant a elipsa, tj. L1(Q,rQ) a kvadr.forma(Oi,rOi)
netriviální i ve vektorovém prostoru, natož obecně v metrickém

Metrické přístupové metody - motivace využití dobrých vlastností multidimenzionálních metod
struktura indexu, diskový management, atd. + vlastnosti „šité na míru“ vyhledávání podle podobnosti
rozsahové a k-NN dotazy indexování obecných metrických sad nástrojem pro tvorbu indexu je metrika (a samozřejmě data)
popis dat metrickými regiony – ty jsou „kompatibilní“ s dotazovými regiony, takže lze lehce filtrovat
nová míra nákladů na indexování/vyhledávání – množství výpočtů vzdáleností
zobecnění (vzhledem k multidimenzionálním metodám) nejen vektorová data, ale obecně cokoliv, co lze měřit metrikou
specializace (vzhledem k multidimenzionálním metodám) dopředu se specifikuje metrika, podle které se bude vyhledávat obecně nelze vyhledávat podle jiných metrik (nepočítá-li daná metoda s
nějakou třídou metrik, např. Lp)

Metrické přístupové metody (1)
vybudování indexurozdělení dat do tříd ekvivalence
hierarchická struktura plochá struktura
vhodný popis tříd určení relevance třídy k dotazu geometrický popis nízké náklady
prostorové – velikost indexu časové – zjištění relevance k dotazu
Metrické přístupové metody (2)
implementace serializace indexu pro uložení
na sekundární paměti vs. uložení v operační paměti
statická vs. dynamická konstrukce indexu

Metrické přístupové metody (3)
vyhledávánírychlé odfiltrování většiny
irelevantních tříd v indexusekvenční dofiltrování objektů
v kandidátních třídách

Efektivita vyhledávání
strojový čas potřebný pro indexování/vyhledávání počet realizací metriky d počet přístupů na disk (I/O náklady) interní výpočty (internal CPU costs)
předpokládá se výrazně dominantní vliv výpočtů vzdáleností, potom I/O operací, nakonec interních výpočtů
očekávané složitosti metod indexování – subkvadratická složitost, např. O(n log n) vyhledávání – sublineární složitost, např. O(log n)

Reprezentace datového prostoru
pro vytvoření tříd ekvivalence potřebujeme geometrický popis, tj. rozdělení objektů do regionů v prostoru
region by měl poskytovat hrubou informaci o distribuci objektů v něm obsažených
disjunkce datového regionu a dotazového regionu garantuje irelevanci příslušných objektů vůči dotazu, naopak průnik obou regionů negarantuje přítomnost objektu v regionu dotazu
operace zjištění nenulového průniku datového regionu s regionem dotazu by měla být „levná“

Hyper-kulové dělení prostoru
mějme referenční objekt Oi a poloměr rOi potom (Oi, rOi) je „hyper-kulový“ region obsahující všechny objekty jejichž
vzdálenost k Oi ≤ rOi (Oi, rOi) je komplementárně-kulový region, tj. celý prostor U kromě „díry“
(Oi, rOi) kulové regiony lze množinově (resp. logicky) kombinovat – sjednocení,
průnik, rozdíl pozor!! - v metrických prostorech
obecně nelze potvrdit průnik kulového regionu a průniku dvou koulí sjednocení dvou komplementárních
koulí lze pouze vyloučit průnik na základě
kombinace logických spojek

Nadrovinové dělení prostoru
mějme dva referenční objekty, zbytek objektů rozdělíme do dvou tříd tak, že objekty v jedné třídě jsou všechny blíže „svému“ referenčnímu objektu, než ke druhému
obě množiny definují hypotetickou hranici – zobecněnou nadrovinu (generalized hyperplane, zobecnění „hilbertovské“ nadroviny)
lze zobecnit pro více referenčních objektů – kombinace nadrovin

Užívané vlastnosti metrik (1)
pro dvě hyper-koule (Oi, rOi) a (Q, rQ) platí:pokud d(Oi, Q) > rOi + rQ, tak se neprotínají (a naopak)Důkaz: nechť Oj je libovolný bod uvnitř (Oi, rOi)

Užívané vlastnosti metrik (2)
pro hyper-kouli (Q, rQ) a komplementárně-kulový region (Oi, rOi), tj. celý prostor s dírou (Oi, rOi), platí:pokud d(Oi, Q) + rQ < rOi, tak se neprotínují (a naopak)Důkaz: nechť Oj je libovolný bod uvnitř (Oi, rOi), potom

Užívané vlastnosti metrik (3)
pro hyper-prstenec (Oi, rOiUp, rOi
Low) a hyper-kouli (Q, rQ) platí: pokud d(Oi, Q) + rQ < rOi
Low d(Oi, Q) > rQ + rOiUp, potom se neprotínají (a
naopak) – jinými slovy: pokud je dotaz celý uvnitř „malé“ koule nebo celý vně „velké“ kouleDůkaz: vyplývá z předchozích dvou vět

Užívané vlastnosti metrik (4)
pro dva nadrovinou určené regiony (na obr. levý, pravý) platí:pokud d(Oi, Q) – rQ > d(Oj, Q) + rQ, pak první (Oi) region neprotíná dotazpokud d(Oj, Q) – rQ > d(Oi, Q) + rQ, pak druhý (Oj) region neprotíná dotaz stručně: filtrování na základě
horní a dolní hranice vzdálenostíobjektů uvnitř dotazu
kombinací podmínek lze zobecnitpro případ s více referenčními objekty
Oi
Oj

















