České vysoké učení technické v Praze Fakulta elektrotechnická Diplomová práce WEBové rozhraní pro úlohy zpracování řečového signálu Milan Václavík Vedoucí práce: Doc. Ing. Petr Pollák, CSc Studijní program: Elektrotechnika a informatika dobíhající magisterský Obor: Informatika a výpočetní technika únor 2008
Transcript
České vysoké učení technické v PrazeFakulta elektrotechnická
Diplomová práce
WEBové rozhraní pro úlohy zpracování řečového signálu
Milan Václavík
Vedoucí práce: Doc. Ing. Petr Pollák, CSc
Studijní program: Elektrotechnika a informatika dobíhající magisterský
Obor: Informatika a výpočetní technika
únor 2008
ii
Poděkování
Děkuji všem, kteří měli se mnou trpělivost a umožnili mi dokončit tuto práci.
iii
iv
Prohlášení
Prohlašuji, že jsem svou diplomovou práci vypracoval samostatně a použil jsem pouze podkladyuvedené v přiloženém seznamu.
Nemám závažný důvod proti užití tohoto školního díla ve smyslu §60 Zákona č. 121/2000Sb., o právu autorském, o právech souvisejících s právem autorským a o změně některých zákonů(autorský zákon).
Tato diplomová práce se zabývá demonstrací zvýrazňování a rozpoznávání řeči. Jedná se o mul-tiplatformní aplikace typu klient – server, které jsou uživatelům dostupné s pomocí WWWprohlížeče — jedná se o aplety. V první části práce je vytvořen klientský program, který umož-ňuje uživateli nahrát audiosignál, který je následně odeslán na server, kde se provádí zvolenámetoda zvýraznění řeči. Zvýraznění řeči je provedeno s pomocí externího programu CtuCopy(univerzální nástroj pro zvýrazňování řeči a parametrizaci). Audiosignál se zvýrazněnou řečí jeposlán zpět klientovi, který provádí vizualizaci audiosignálu a to s pomocí časového průběhua spektrogramu nebo ho může přehrát. Ve druhé části diplomové práce se zabývám realizacídemonstrace rozpoznávání řeči na základě hlasového ovládání WWW stránek. Uživatel můžehlasem ovládat samotnou WWW stránku — posun stránky nahoru/dolu, aby si mohl zobrazitskrytý text, může se posouvat v historii zobrazených WWW stránek směrem vřed/vzad a můžehlasem zobrazovat WWW stránky, na které ukazují hypertextové odkazy. Hlasové ovládáníWWW stránek je demonstrováno na simulaci hlasového vytáčení telefonního čísla a na hlaso-vém výběru osoby ze seznamu členů katedry, který umožní zobrazit kontaktní informace o danéosobě. Simulace hlasového vytáčení telefonního čísla je založena na rozpoznávání souvislé sadyčíslovek a dvou symbolů (#, *), oddělených krátkou pauzou. Výběr osob ze seznamu je zalo-žen na rozpoznání jména, příjmení, příjmení a jména, jména a příjmení. Součástí demonstraceje vytvoření výkonového detektoru řeči, který zajišťuje, že je rozpoznávaná pouze platná řeč.Vlastní rozpoznávání mluvené řeči je realizováno na straně serveru s pomocí sady nástrojůHTK.
Summary
This diploma thesis deals with the demonstration of speech enhancement and speech recognitiontasks. The solution is based on multiplatform applications on the basis of WWW appletsusing the architecture „client — server“. Within the initial part I have created the programrecording locally audio signal on client side and sending its then to the server where furtherprocessing is realized. The first application deals with algorithms for speech enhancement basedon spectral subtraction which is implemented in external program „ctucopy“ (the more generaltool for speech enhancement and parameterization) running at the server side. The new audiosignal is sent back to the client which can observe it as waveform or spectrogram. It is alsopossible to play original or enhanced speech signal on the client side. Secondly, I realized ademonstration of speech recognition within a voice controlled WWW pages. User can controlby voice scrolling of WWW pages (up, down), browsing in the history of pages, or showing newpages according to standard WWW links. Two simple task were chosen for this demonstrativepurposes: simulation of telephone number dialing and on department personnel list with briefcontact information. An important part of this application was the creation of energy baseddetector of speech activity as only the signal containg a speech should be sent to the server sidefor the recognition. Speech recognizer implemented at the server is based on standard HMMmodelling and external programs from HTK Toolkit were used for this purpose. Training ofHMM models was not a part of this work.
Komunikace prostřednictvím mluvené řeči je základní a nejpřirozenější způsob přenosu infor-mace mezi lidmi. V dnešní době s rostoucím vývojem výpočetní techniky vznikají projekty,které se snaží, aby se plnohodnotným partnerem člověka v mluveném dialogu mohl stát i po-čítač. Tyto projekty jsou velmi perspektivní a po naplnění svých cílů vedou na přirozenoukomunikaci člověka a stroje (počítač).
Ačkoliv plnohodnotný dialogový režim člověka s počítačem prostřednictvím přirozené ply-nule promlouvané řeči bez jakýchkoli omezení je v současné době stále ještě nedostupný, tak sepostupně objevují úspěšná dílčí řešení. Tato řešení nacházejí uplatnění v průmyslové a společen-ské praxi. Ve většině aplikací jde o problémově orientovaná řešení, kdy komunikace je tématickyomezená, rozpoznávaný slovník se týká určité konkrétní oblasti či systém pracuje v prostředís definovaným rušivým pozadím a podobně.
Standardní dialogové systémy jsou nasazovány v těch praktických úlohách, kdy jde o hla-sovou komunikaci s databázovými systémy, a to zejména, je-li osoba vzdálena od systému amůže s ním komunikovat například pouze prostřednictvím telefonního spojení. Typickými pří-klady jsou: vzdálený přístup k informačním a rezervačním systémům, objednávka zboží potelefonu, technická podpora produktu (počítač, modem, telefon, internetové připojení od pro-videra, apod.). Výhodou uvedeného způsobu komunikace je to, že informace či služba mohoubýt účastníkovi k dispozici nonstop a z jakéhokoliv místa.
Široce využívány jsou i dílčí komponenty hlasových dialogových systémů (moduly syntézya rozpoznávání řeči). Všeobecné využití například nacházejí různé systémy ovládání strojůa zařízení hlasovými povely či automatický přepis diktátu (vhodné zejména jsou-li oči i rucečlověka zaměstnány jinou činností nebo v případě využití tělesně handicapovanými lidmi). Dalšíužitečnou aplikací může být automatický telefonní operátor, který propojí hovor po vysloveníjména volaného. Systémy automatického rozpoznávání lze s výhodou nasazovat i v takovýchúlohách, kdy je třeba vyhledat informace v rozsáhlých řečových databázích (například v archívuzaznamenaných schůzí a jednání, v archivu televizních a filmových dokumentů a podobně).
Sluchově handicapovaní lidé zase ocení automatické (on-line) titulkování televizních pořadů(sportovní přenosy, diskuse, apod.), kde není předem k dispozici textová podoba dané promluvy.
Praktické využití se nachází i v oblasti automatického převodu psaného textu na mluvenouřeč, které dosáhlo v poslední době již vysoké přirozenosti umělé řeči. Příkladem je předčítáníelektronicky uložených textů, mobilní operátoři nabízejí možnost čtení SMS zpráv, apod. Tytovlastnosti zejména ocení zrakově postižení lidé nebo lidé s poruchami řeči.
Rovněž se začíná pracovat i na aplikacích automatického překladu z jednoho jazyka dodruhého, které předpokládají řečový vstup v jednom jazyce, automatické rozpoznání promluvy,automatický překlad do druhého jazyka s následnou syntézou přeložené věty.
Chceme-li, aby se partnerem člověka v mluveném dialogu stal počítač, musí se algoritmickya technicky vyřešit několik relativně komplikovaných úloh, které se týkají zejména zpracovánířečového signálu, počítačové syntézy a automatického rozpoznávání řeči a „strojového“ poro-zumění významu rozpoznávaných promluv.
Komunikační proces
Přenos mezi mluvčím a posluchačem bez podpory technických prostředků se považuje za analo-gový. Průběh akustického tlaku ve vzduchu je spojitý jak v čase, tak v okamžitých hodnotách.Elektrický signál z mikrofonu je obrazem časového průběhu akustického tlaku a je taktéž ana-logový.
Pro analogové signály je významným parametrem přenosového média šířka frekvenčníhopásma, ve kterém je signál bez zkreslení přenesen. Lidský sluch je schopen slyšet zvuky ve
2 KAPITOLA 1. ÚVOD
frekvenčním intervalu 20 Hz až 16 kHz.Analogové systémy hlasových technologií jsou v současné době na okraji zájmu technického
vývoje. Hlasové technologie stojí na číslicové technice a využití počítačů. Avšak znalosti z oblastianalogových systémů jsou v řadě aplikací východiskem pro vývoj číslicových systémů.
Jeden z možných typických řetězců, digitálního přenosu, který zprostředkovává sdělení in-formace mezi dvěma osobami hlasem, ukazuje obrázek 1.1.
Obrázek 1.1: Komunikační proces
Hlasový signál vytvoří mikrofon, za kterým je obvykle zapojen zesilovač. Již na tomtomístě nás musejí zajímat nejen vlastnosti mikrofonu, ale i frekvenční vlastnosti a nelineárnízkreslení zesilovače. V praxi se můžeme setkat s tím, že analogový signál je nejen zesilován,ale i komprimován ve svém rozkmitu. V algoritmech dalšího digitálního zpracování se takovánelineární transformace musí brát v úvahu. Frekvenční vlastnosti zesilovače jsou významnéz hlediska následující diskretizace signálu v čase, tj. vzorkování.
V systémech, ve kterých se digitalizuje analogový signál frekvenčně omezený do telefonníhopásma, je běžné použití vzorkovací frekvence 8 kHz. V systémech, kde je požadován kvalitnějšíhlasový signál (pro přenos, syntézu i rozpoznávání), zachycující identitu mluvčího, barvu hlasu,jeho intonační rysy, a podobně, používáme analogového kanálu s širším frekvenčním pásmema tomu odpovídající vyšší vzorkovací frekvenci, typicky 16 kHz, objevují se však již systémy
KAPITOLA 1. ÚVOD 3
pracující s řečí vzorkovanou 48 resp. 44.1 kHz.Vzorky hlasového signálu jsou vedeny do analogově-číslicového převodníku, který signál
kvantuje a digitalizuje. Proces digitalizace vede k narušení signálu kvantizačním šumem. Přirekonstrukci hlasového signálu na přijímací straně je kvantizační šum činitelem zhoršujícímjeho srozumitelnost.
Kvantizace a digitalizace jsou procesy, které mapují spojitý interval maximálního rozkmituanalogového signálu na interval diskrétních číselných hodnot, jejichž počet závisí na počtu bitů,kterými je digitalizovaný signál reprezentován.
Uvedené zpracování řečového signálu je považováno za bezeztrátové, což znamená, že lzezískat z digitálního signálu v D/A převodníku signál se stejným časovým průběhem, jaký mělsignál původní, jen s tím, že je narušen kvantizačním šumem.
Digitalizovaný hlasový signál je obrazem akustického tlaku, který zachytil mikrofon. Nenítedy reprezentantem ideální artikulace, ale nese řadu vad, které komunikaci v konkrétníchpodmínkách provázejí. Za neodstranitelné považujeme vady způsobené samotným mluvčímpři artikulaci (nemoc, stres, opilost). Posluchač je obvykle schopen porozumět takto narušenépromluvě, avšak v automatických rozpoznávačích řeči se těmito problémy musíme zabývat. Jinénarušení hlasového signálu může pocházet z prostředí, ve kterém je mikrofon umístěn. Patřísem dozvuky a ozvěny v uzavřených prostorech, hluky a rušivé zvuky, například v jedoucímautomobilu, v kanceláři, výrobním provozu, na hlučné ulici či hlasy jiných mluvčích. V těchtopřípadech jde o narušení signálu, pro která jsou vyvíjeny algoritmy umožňující jejich redukci,či úplné odstranění. Tyto věci řeší blok v obrázku „Zvýraznění“.
Blok „Kodér“ upravuje digitální data do podoby, která je vhodná pro digitální přenos.Úkolem „Dekodéru“ je přivést do bloku rekonstruujícího hlasový signál potřebná digitálnídata. Blok „D/A“ zahrnuje všechny algoritmy vedoucí z číselné reprezentace signálu k jehoanalogové podobě. Výstupem tohoto bloku je většinou schodovitý časový průběh napětí, jehožobálka má tvar analogového časového průběhu hlasového signálu. Pro použití ve sluchátku neboreproduktoru musí být průběh napětí korigován vhodným analogovým filtrem.
4 KAPITOLA 1. ÚVOD
KAPITOLA 2. OBECNÝ POPIS PROBLÉMU 5
2 Obecný popis problému
Ve své diplomové práci se zaměřuji na demonstraci algoritmů „zvýraznění řeči“ (implementaceprogramu, který vizualizuje zvukové soubory u kterých došlo k zvýraznění řeči s pomocí vhod-ných algoritmu) a na demonstraci jednoduché úlohy „rozpoznávání řeči“ (převod řeči na text).Obě demonstrační úlohy předpokládají hlasový vstup ze vzdáleného počítače, hlasový vstup jesnímán s pomocí apletů na WWW stránce.
S podrobnějším popisem zpracování řeči se lze seznámit v publikacích [1] a [2].
2.1 Zvýrazňování řeči
Pod pojmem zvýrazňování řeči si často představíme potlačování (redukci) šumů v řeči snímanémikrofonem. Rozdíl mezi oběma úlohami ovšem existuje, neboť redukce šumů nemusí vést kezvýraznění řeči a naopak zvýrazněním řeči se nemusí dosáhnout redukce šumů. Například ostře-ním spektra používaným pro zvýrazňování řeči pro sluchově postižené dochází k zesílení řeči (azároveň šumu) v okolí formantových kmitočtů. Problém redukce šumů se vyskytuje při použitítelefonních přístrojů a rozpoznávačů řeči v hlučném prostředí, jakým může být kabina auto-mobilu, hlučná ulice, konferenční místnost, . . . V tomto případě je řeč rušena (kontaminována)šumy, které se přičítají, tedy aditivními šumy. Přenáší-li se řeč přenosovým kanálem (případtelefonie), nebo je-li snímána v místnosti, kde jsou přítomny odrazy, dochází k jejímu zkresleníkonvolučními šumy. Konvoluční šumy jsou tedy způsobeny odrazy či přeslechy v přenosovécestě, nebo změnami jejich parametrů. V závislosti na typu a množství šumů může kvalita řečivýrazně kolísat. Potlačování aditivních a konvolučních šumů v řeči je nezbytným předpoklademjejího dalšího kvalitního zpracování, neboť jak metody komprese a přenosu řeči, tak i metodyrozpoznávání jsou citlivé na přítomnost těchto šumů. Tuto citlivost v obou případech způsobujímetody parametrizace řeči.
2.1.1 Základní principy metod redukce šumů
Podívejme se nyní na možnosti redukce aditivních šumů, tedy zvýrazňování řeči kontaminovanéaditivními šumy, které jsou nekorelované s řečovým signálem. Ve všech praktických situacíchlze očekávat, že přijímaná řeč obsahuje nějaký typ aditivního šumu. Typickými aplikacemi jsouzpracování a přenos řeči z hlučných ulic a provozů, pilotních kabin, jakož i předzpracování řečipro sluchové protézy nebo implantáty.
Mezi základní charakteristiky používané při redukci šumů patří statistiky druhých řádů:korelace, spektra a spektrální hustoty, koherence.
Pro odhady parametrů se používají metody odhadů založené na různých kritériích, nejčastěji
• metoda nejmenších čtverců a její modifikace (metoda nejmenší střední kvadratické chyby),
• metoda maximální věrohodnosti,
• metoda maximalizace aposteriorní pravděpodobnosti.
Pro redukci šumů se pak používají následující techniky:
• Filtrace v časové a frekvenční oblasti — v tomto případě filtr potlačuje šum, ale záro-veň může i zkreslit řeč. Používá se Wienerova a Kalmanova filtrace, filtrace adaptivnímpredikčním filtrem, adaptivním hřebenovým filtrem a podobně.
• Kompenzace v časové frekvenční oblasti — v tomto případě systém potlačuje šum přimůže dojít ke zkreslení řeči.
6 KAPITOLA 2. OBECNÝ POPIS PROBLÉMU
• Modelování řeči — tento přístup provádí analýzu řeči se šumem s cílem získat její mo-del, který je následně opraven. Pokud je požadována zvýrazněná řeč, je provedena jejísyntéza. Oprava modelu je často prováděna iteračním algoritmem při použití omezujícíchpodmínek, jak v rámci jednoho segmentu, tak i mezi segmenty.
• Systémy s využitím prostorové informace, která umožňuje směrovat příjem k mluvčímu apotlačit šum z jiných směrů. Systémy využívají pole mikrofonů a dokáží separovat signályze snímané směsi signálů, ovšem za dosti omezujících podmínek, které při zpracování řečinebývají často splněny.
Potlačování aditivních šumů není jednoduchou a rovněž ani uzavřenou záležitostí. Příčinouje velká rozmanitost rušivých šumů vedoucí na relativně složité systémy s výpočetně nároč-nými algoritmy. Stále platí, že neexistuje univerzální metoda použitelná pro potlačování šumův celém spektru aplikací, která by byla snadno technicky realizovatelná. Z tohoto důvodu nelzeposkytnout obecný recept pro řešení úlohy zvýrazňování řeči rušené aditivními šumy. V každémkonkrétním případě je potřeba alespoň přibližně analyzovat charakter šumu (stacionaritu, kore-lační vlastnosti, jeho výkon vzhledem k úrovni výkonu řeči, počet zdrojů rušení a podobně). Nazákladě provedené analýzy je možné provést první výběr nebo návrh struktury včetně algoritmua provést simulace. Konečná struktura obvykle tvoří kompromis mezi požadovanou efektivitoua technickou realizovatelností.
2.2 Detekce a rozpoznávání řeči
Na zobrazeném obrázku 2.1 lze vidět princip detekce a rozpoznávání řeči — převod řeči na text.
Obrázek 2.1: Detekce a rozpoznávání řeči
2.2.1 Detekce řečové aktivity
Detekce řečové aktivity v analyzovaném signálu je často významnou částí mnoha aplikací zpra-cování řečového signálu. Nalezneme ji ve vstupních modulech systémů rozpoznávání řeči, kdydetekujeme začátek a konec rozpoznávané promluvy, v mnoha algoritmech zvýrazňování řeči,kdy v řečových pauzách odhadujeme měnící se charakteristiky šumového pozadí, v komunikač-ních systémech, kdy vyvstává požadavek na zakódování a přenesení pouze té části promluvy,která obsahuje informaci. Existuje velké množství algoritmů detekce řečové aktivity (VAD -Voice Activity Detection). Principiálně lze uvažovat dvě základní skupiny uvedených algoritmů:deterministické a stochastické.
2.2.1.1 Deterministické metody detekce řeči
Deterministické algoritmy VAD jsou založeny na principech analýzy základních charakteristikřečového signálu a z nich odvozené vhodné kriteriální funkce, na základě které je možné rozlišitúseky signálu s řečovou aktivitou a řečové pauzy. Kriteriální funkce se pak obvykle srovnávás prahem pro výsledné rozhodnutí o přítomnosti řeči v daném úseku signálu. Srovnávání kriteri-ální funkce s prahem definovaným pouze na základě analýzy zpracovávaného signálu je základnícharakteristikou této skupiny algoritmů.
KAPITOLA 2. OBECNÝ POPIS PROBLÉMU 7
Hlavní rozdíly mezi jednotlivými algoritmy této skupiny jsou dané volbou kritéria pro rozho-dování o řečové aktivitě. Zjednodušeně lze konstatovat, že principiálně je nutné nalézt takovýprůběh kriteriální funkce, která pak může být prahovatelná. Z tohoto hlediska se nejčastějipoužívají následující algoritmy:
• výkonové (energetické) — rozhodují na základě nárůstu krátkodobého výkonu při přítom-nosti řečové aktivity.
• kepstrální (spektrální) — rozhodují na základě rozdílu ve spektrálních charakteristikáchaktuálního segmentu a rušivého pozadí.
• koherenční — uvažují nárůst průměrné koherence při přítomnosti řečového signálu.
2.2.1.2 Stochastické metody detekce řeči
Stochastické algoritmy jsou založeny na stochastických metodách (HMM, GMM), principechumělé inteligence (neuronové sítě), a podobně. Charakteristickým rysem uvedených algoritmůje nutnost trénovací fáze na reprezentativním vzorku dat. Výslednou detekci řeči pak ovlivňujínejenom charakteristiky aktuálně analyzovaného signálu, ale rovněž vnitřní parametry systémunastavené na základě trénovací množiny signálů.
2.2.1.3 Návrh výkonového detektoru řeči
Ve své diplomové práci jsem realizoval výkonový detektor řeči, nejjednodušší detektor začátkua konce promluvy použitelný v případech, kdy nepředpokládáme příliš vysokou úroveň rušivéhopozadí. Vychází se z jednoduchého předpokladu, že přítomnost řečové aktivity znamená nárůstvýkonu signálu.
Na druhou stranu lze jistě očekávat selhání tohoto algoritmu za přítomnosti silnějšího ruši-vého pozadí. V tomto případě budou slabší úseky signálu maskovány silnějším aditivním šumema nedojde k výraznějšímu nárůstu výkonu signálu. Zejména neznělé úseky řečového signálu jsouv principu nízkoenergetické, a tak jsou v silnějším šumu jen obtížně detekovatelné na základěvýkonového kritéria. Za přítomnosti rušivého pozadí budou tedy při výkonové analýze častodetekovatelné pouze segmenty se silnějšími, převážně znělými, úseky řeči.
Odhad výkonu signálu obvykle realizujeme blokově, zejména s ohledem na další zpracovánířečového signálu, které je v naprosté většině případů realizováno na bázi krátkodobé analýzysegmentovaného signálu, tj. při rozkladu na segmenty délky N posouvané po signálu s kokemM, je i -tý analyzovaný segment signálu x[n] daný vztahem
xi[n] = x[i ·M + n]. (2.1)
Krátkodobý výkon v i -tém segmentu se pak spočítá na základě elementárního vztahu
Pi =1N
N−1∑
n=0
x2i [n]. (2.2)
Finální rozhodnutí o přítomnosti řeči se provádí po získání kriteriální funkce vhodným pra-hováním. Výběr vhodného algoritmu závisí na konkrétní aplikaci, rozhodovací kritéria mohoubýt někdy i kombinací několika podmínek. V principu však jde v různých modifikacích o dvazákladní přístupy: pevné nebo adaptivní prahování.
Konkrétní použitý algoritmus výkonového detektoru řečové aktivity popisuje obrázek 5.2na stránce 21.
8 KAPITOLA 2. OBECNÝ POPIS PROBLÉMU
2.2.2 Rozpoznávání řeči
Ačkoliv byl na poli zpracování řečového signálu a jeho klasifikace učiněn obrovský pokrok, přestoje zatím konstrukce zařízení, které by bylo schopno rozpoznat promluvu jakéhokoliv řečníkaužívajícího libovolná slova daného jazyka vzdálenou budoucností. Důvody, proč rozpoznávánířeči je obtížné, souvisí jednak s variabilitou řečníka, s prostředím, ve kterém je rozpoznávanářeč pronášena, ale i se složitostí řešené úlohy:
• Hlas jedné osoby se liší od hlasu jiných osob. Je to způsobeno zejména odlišnými parame-try hlasového ústrojí, ale i odlišným způsobem artikulace. To má za následek, že každýčlověk má obvykle jinou barvu hlasu, jiný přízvuk, odlišné tempo řeči a podobně. Systémyrozpoznávání řeči lze proto dělit na systémy na řečníku závislé (jsou trénovány na hlaskonkrétního řečníka a nebo malé skupiny řečníků) a na systémy na řečníku nezávislé (jsoutrénovány na hlasy stovek i tisíců různých řečníků).
• Hlas jednoho člověka může být odlišný v různých situacích. Řečový signál se mění, kdyžčlověk vysloví stejnou promluvu potichu, nahlas, šeptem, nebo když je nachlazen či rozči-len. Ve skutečnosti je v podstatě nemožné, aby jede člověk řekl ve dvou různých situacíchstejné slovo naprosto stejným způsobem. To je způsobeno především proměnlivostmi ča-sování, tj. časové délky celého slova i poměrné délky jeho jednotlivých částí. V souvislépromluvě navíc přistupuje známý jev koartikulace, který může pozměnit fonetické vlast-nosti začátku a konce slova v závislosti na kontextu okolních slov.
• Měnící se akustické pozadí, tj. přítomnost okolního šumu a rušení přenosového kanálu,může způsobovat značné problémy při rozpoznávání řeči. Vyšší úroveň šumu napříkladztěžuje identifikaci začátku a konce slova.
• Na správnou funkci rozpoznávače řeči má značný vliv i složitost řešené úlohy. Je zřejmé,že mnohem snazší je rozpoznávání izolovaných slov (například číslovek nebo povelů) z re-lativně malého slovníku, než rozpoznávání diskrétního diktátu (slova jsou vyslovovánaizolovaně s krátkou mezislovní pauzou), kdy slovník čítá například tisíce slov. Nejobtíž-nější úlohou je rozpoznávání souvislé řeči, kdy řečník vybírá slova z rozsáhlého slovníku(desítek tisíc slov). Významný vliv na správnou funkci systému má i to, zda promlouvanářeč je čtená řeč a nebo zda jde o spontánně pronášenou promluvu. U spontánně proná-šené promluvy totiž řečník velmi často vkládá do proudu vyslovovaných slov mnoho tzv.neřečových událostí (hlasité „váhání“, slyšitelné nádechy), řečník vysloví jen jednu neboněkolik prvních hlásek daného slova a začne vyslovovat stejné slovo znovu a nebo začnemluvit zcela o něčem jiném.
Z hlediska aplikovaných metod rozpoznávání lze klasifikátory řeči dělit na ty, které pracujína principu porovnávání se vzory a na klasifikátory pracující s využitím statistických metod.
2.2.2.1 Rozpoznávání řeči na základě porovnávání se vzory
Tato skupina metod byla aktuální v sedmdesátých a osmdesátých létech, kdy byla často apliko-vána zejména v klasifikátorech izolovaně vyslovených slov. Slovo je zde zpracováno jako celek,přičemž je klasifikováno do té třídy (třídy jsou tvořeny jednotlivými slovy ve slovníku), k jejímužvzorovému obrazu (vzorovému slovu reprezentovanému posloupností příznakových vektorů) mánejmenší vzdálenost. Klíčovou otázkou je zde určení vzdálenosti mezi dvěma obrazy slov. Tatovzdálenost je obvykle určována na základě aplikace metody dynamického programování, přikteré se hledá taková nelineární transformace časové osy jednoho z obrazů, při níž dojde k po-rovnávání obou obrazů s nejmenší výslednou vzdáleností. Tento algoritmus pracuje s efektemnelineární časové normalizace, přičemž kolísání v časové ose je modelováno časově nelineární
KAPITOLA 2. OBECNÝ POPIS PROBLÉMU 9
„bortivou“ funkcí (DTW - Dynamic Time Warping) s přesně specifickými vlastnostmi. Časovérozdíly mezi dvěma řečovými obrazy jsou přitom eliminovány „borcením“ jedné z časových ostakovým způsobem, že je dosaženo maximální shody s druhým obrazem.
2.2.2.2 Statistické metody rozpoznávání řeči
V této skupině je přístup ke klasifikaci založen na statistických metodách, ve kterých jsou slova acelé promluvy modelovány pomocí tzv. skrytých Markovových modelů (HMM - Hidden MarkovModels). Jednotlivá slova přitom mohou být modelována jako celek jedním skrytým Markovýmmodelem slova, a nebo jsou mnohem častěji konstruovány skryté Markovovy modely subslovníchjednotek (například slabik, fonémů, trifonů, apod.) a promluva je modelována zřetězením těchtoelementárních modelů. Pro každou elementární jednotku jsou pak v procesu trénování stanovenyna základě trénovací množiny promluv parametry odpovídajícího Markova modelu a neznámápromluva je rozpoznána na základě toho, jaká posloupnost slov tvořená řetězcem odpovídajícíchmodelů subslovních jednotek generuje promluvu s největší pravděpodobností.
2.2.2.3 Princip rozpoznávače řeči
Cílem mé diplomové práce nebyla realizace rozpoznávače řeči, ale jeho demonstrace, proto jsempoužil vytvořený rozpoznávač, který pracuje na principu statistických metod rozpoznávání řeči.Tento rozpoznávač se nachází v sadě nástrojů HTK [3]. Sada nástrojů je standardním profe-sionálním prostředkem k detekci řeči, rozpoznávání řeči, trénování parametrů Markovovýchmodelů řeči, apod. HTK je k dispozici zdarma včetně zdrojového kódu a modely vytvořenétímto nástrojem je možno použít i komerčně. Není ovšem možno dále distribuovat samotnéHTK.
Následující obrázek 2.2 zobrazuje nezbytné části, které jsem musel zajistit, aby použitýrozpoznávač rozpoznával českou promluvu.
Obrázek 2.2: Parametry rozpoznávače řeči
Rozpoznávač - bližší popis parametrů rozpoznávače HVite ze sady nástrojů HTK je po-drobně popsán v dokumentaci HTK [3].
Akustický signál - nahraná promluva, která má být rozpoznána.
10 KAPITOLA 2. OBECNÝ POPIS PROBLÉMU
Gramatika - definuje pořadí slov ze slovníku, které rozpoznávač využívá k rozpoznání řeči.Rozpoznávač rozpozná pouze ta slova / krátká spojení řeči, která jsou uvedena v grama-tice.
Slovník - definuje slova, která bude rozpoznávač schopen rozpoznat. Slovník se skládá z jed-notlivých dvojic - textového přepisu a rozkladu daného slova na jednotlivé hlásky . Roz-poznávač nerozpoznává slova na základě textového popisu daného slova, ale na základěhlásek.
HMM modely elementární řeči - obsahují statistické vlastnosti elementární řeči, vznikajítrénováním z velkých databází řeči. Tyto modely jsem převzal z diplomové práce [17].
2.3 Demonstrace zvýrazňování a rozpoznávání řeči v praxi
Cílem demonstrace zvýrazňování a rozpoznávání řeči je navrhnout takový systém, který by bylpoužitelný na co nejvíce počítačích a dostupen co největšímu možnému okruhu uživatelů. Totokritérium nejlépe splňuje internet, proto bylo rozhodnuto, že demonstrační aplikace budou míthlasový vstup ze vzdáleného počítače a budou realizována s pomocí apletů.
Aplety jsou většinou kratší programy, které se používají na WWW stránkách, tj. dají sevčlenit do HTML kódu. To znamená, že se nespouštějí přímo jako aplikace, ale spustí se ote-vřením HTML dokumentu WWW prohlížečem, který umí s aplety pracovat. Aplety jsou psányv jazyce Java, který umožňuje plnou přenositelnost programu na libovolnou platformu beznutnosti jejich překladu na této platformě.
Oba programy ke své činnosti potřebují programy třetí strany:
• Samotný rozpoznávač mluvené řeči (sada nástrojů HTK)
• Program ctucopy, který provádí zvýrazňování řeči.
Ve své práci jsem navrhl demonstraci na základě architektury klient — server, kde klien-tem je samotný aplet, který nahrává data z mikrofonu, posílá je na server, ze kterého přijímápředzpracovaná data, která dále zpracuje. Server běží na webovém serveru, který poskytujedané aplety, server přijímá nahraná data, která zpracuje (zvýrazní řeč nebo rozpozná hlasovýpovel) a následně klientovi vrací zpracovaná data.
KAPITOLA 3. PŘENOS ŘEČOVÉHO SIGNÁLU PO INTERNETU 11
3 Přenos řečového signálu po internetu
V první verzi prototypu programu SEDemo (demonstrace zvýrazňování řeči) jsem navrhl komu-nikaci mezi klientem a serverem s pomocí HTTP protokolu, kde se celý demonstrační programskládal nejen z Java apletu, ale i z komponent html stránky (tlačítek a textových polí). Ideabyla taková, že pomocí apletu nahraji audiosignál, který uložím na disk. Poté s pomocí htmlformuláře vyberu tento nahraný signál, odešlu ho na server, kde bude zpracován buď s pomocíCGI skriptu a nebo PHP. Po provedení zvýraznění řeči by se pak zobrazilo dialogové okno,které by umožnilo uložit (stáhnout) zpracovaný signál. Poté by se signál nahrál v apletu, kterýby jej umožnil přehrávat či vizualizovat.
Toto řešení má některé podstatné výhody, ale bohužel nevýhody převládají a odsuzují tentoprvní návrh prototypu k nezdaru. Hlavní výhodou tohoto řešení je to, že veškerá komunikaceprobíhá s pomocí HTTP protokolu, to znamená, že na daném serveru, může být nastavena silnábezpečností politika ohledně síťového provozu. Dany server (webový) může tedy propouštětpouze komunikaci na jednom portu, na kterém běží webový server. Pokud mezi klientem aserverem se nachází nějaký firewall, který propouští pouze komunikaci mezi klientem a webovýmserverem, tak bude tento prototyp vždy fungovat správně, aniž by se musela snížit bezpečnostnípolitika na serveru.
Hlavní nevýhodou tohoto řešení se přílišná složitost ovládání. Uživatel musí nejprve ručněuložit nahraný signál, poté ho musí znovu vybrat a s pomocí odeslání formuláře odeslat naserver. Jakmile je vypočte nový soubor, tak uživatel je nucen ho uložit a pak ho musí opětručně načíst v apletu.
Ve druhém prototypu jsem se snažil zjednodušit počet operací, které musí uživatel udělat,aby vizualizoval zvýrazněné signály. Napadlo mě, že by aplet mohl přímo sám odeslat nahranýsignál na server, kde by byl dál zpracován. Opět jsem se snažil, aby komunikace probíhalas pomocí HTTP protokolu. Avšak tento prototyp také neuspěl. Nejprve jsem měl problémy, jaks pomocí Java apletu posílat vlastní formuláře — jak realizovat načtení souboru a stisk tlačítkana formuláři. Po usilovném hledání na internetu jsem nakonec našel řešení, které umožňovalopřenést textovou zprávu z apletu na server. Když jsem se poté pokoušel přenést binární soubor,tak jsem nebyl schopen ho na straně serveru s pomocí PHP sestavit do původní podoby. Tentonedostatek jsem vyřešil později, když jsem objevil program bin64, který umí převést binárnísoubor na textovou zprávu a naopak.
Tím jsem vyřešil problém, jak automaticky poslat data na server, kde se zpracovaly, alezískání nových dat ze serveru byl neřešitelný problém. Uživatel musel čekat, než se zobrazildialog, aby mohl zpracovaná data uložit na disk a otevřít je v apletu — nebyl jsem schopenpoznat, kdy se dokončil výpočet na serveru, abych mohl nová data automaticky stáhnout.Bohužel i tento prototyp byl odsouzen k nezdaru, i když by uživatel přetrpěl několikero klikání,než by zobrazil grafický průběh signálu, přesto by byl tento způsob zcela nepoužitelný ve druhémprogramu SCWP, kde se předpokládá pouze hlasové ovládání WWW stránky bez jakéhokolivovládání s pomocí myši či klávesnice.
Naštěstí jsem byl úspěšný při realizaci třetího prototypu, kdy jsem se seznámil díky skriptům[12] s novými technikami komunikace mezi klientem a serverem. Můj problém nejlépe vyřešilatechnika komunikace s pomocí vytvoření soketového spojení mezi klientem a serverem, kde jekomunikace zajišťována s pomocí TCP protokolu. Můj nově vytvořený prototyp bez problémuuměl automaticky přenášet mezi klientem a serverem binární data. Tento úspěch má však menšínevýhodu, danou způsobem komunikace. Aby tento způsob komunikace správně fungoval, musíbýt na počítači, na kterém poběží server, otevřen port, přes který bude server komunikovats klienty. Otevření nového portu znamená snížení bezpečnostní politiky na „webovém serveru“,protože neznámý útočník může zneužít tento port k napadení sytému. Samozřejmě, pokud semezi klientem a serverem nacházejí další „firewally“, tak musí být také nastaveny tak, aby
12 KAPITOLA 3. PŘENOS ŘEČOVÉHO SIGNÁLU PO INTERNETU
propouštěly komunikaci na daném novém portu.Při realizaci třetího prototypu jsem si uvědomil, že bude třeba navrhnout server tak, aby
dokázal obsloužit několik klientů najednou. Způsob realizace paralelního serveru jsem vybíralz následujícího seznamu:
Paralelní server s předpřipravenými procesy - je spuštěn určitý počet procesů, kdy každýz procesů dokáže zpracovávat jeden požadavek. Výhodou je rychlá reakce na příchod po-žadavku.
Paralelní server se společným zpracováním - pokud lze obsluhovat více klientů v rámcijednoho procesu, lze vytvořit server, který bude zpracovávat i více požadavků souběžně.Výhodou tohoto typu serveru je rychlá reakce na příchod požadavku, volnost v počtuobsluhovaných událostí. Avšak se musíme omezit na obsluhu krátkých požadavků odjednotlivých klientů.
Paralelní server s dynamickým vytvářením procesů - při příchodu požadavku je spuš-těn nový proces pro obsluhu požadavku. Výhodou je šetření zdrojů počítače, když nevíme,kolik souběžných požadavků bude třeba obsloužit. Tímto způsobem lze obsluhovat i velmiodlišné typy klientů. Problém je však zpoždění při vytváření nového procesu.
Paralelní server s předběžným dynamickým vytvářením procesů - tato technika kom-binuje určitý počet předpřipravených procesů, který je postupně doplňován o další dy-namicky vytvářené tak, aby při příchodu požadavku byl pokud možno k dispozici volnýproces.
Vzhledem k tomu, že mé programy jsou určeny k demonstracím tak nepředpokládám, žebudou spouštěny dennodenně od rána do večera, ale že se občas během dne párkrát spustí, protojsem realizoval paralelním server s dynamickým vytvářením procesů. S vlastní implementacíserveru mě pomohla kniha [13].
Aby se na počítači, na kterém poběží server zbytečně neotevírali dva porty — aplikaceSEDemoa SCWP by měly svůj vlastní port, čímž by se snížila bezpečnost, tak jsem vytvořilserver, který je pro oba programy stejný a ke své činnosti potřebuje mít povolen jeden port,skrz který bude komunikovat s klienty. .
KAPITOLA 4. APLIKACE (APLET) SEDEMO — „ZVÝRAZNĚNÍ ŘEČI“ 13
4 Aplikace (aplet) SEDemo — „zvýraznění řeči“
Program SEDemo vznikl za účelem demonstrace zvýraznění řeči. Program umožňuje načíst zesouboru akustický signál nebo jej umí nahrát z mikrofonu. Tento akustický signál je poslézeodeslán na server, který na základě zvoleného algoritmu provede zvýraznění řeči. Nově vzniklýakustický signál je odeslán zpět klientovi, který provede vizualizaci audiosignálu — zobrazíčasový průběh a spektrogram. Na základě zobrazení spektrogramů, lze zjistit, který z algoritmůprovádí lepší zvýraznění řeči na daném typu akustického signálu.
Při vytváření programu jsem se inspiroval knihou [14], která byla zaměřena na demonstro-vání algoritmů digitálního zpracování signálu (DSP - Digital Signal Processing). V této knizebyla popisována architektura digitálního zpracování audiosignálu, podle které jsem vytvořilprogram SEDemo.
4.1 Architektura digitálního zpracování audiosignálu
Proces zpracování zvuků, můžeme rozdělit na jednotlivé části, které budou obsluhovány zaříze-ními. Tato zařízení mohou mezi sebou komunikovat a sdílet společné informace. Pod pojmemzařízení, je myšlen softwarový modul, který pracuje s digitálními vzorky. Spojením těchto za-řízení vznikne „řetězec zařízení“, který může být znázorněn jako série bloků v blokovém dia-gramu, kde vlevo vstupuji zvuková data, která jsou zpracovávaná jednotlivými bloky a končív nejpravějším bloku. Toto schéma je znázorněno na následujícím obrázku 4.1:
Obrázek 4.1: Řetězec zařízení
Každé zařízení můžeme pojmenovat a rozdělit podle typu operace, které provádí. V tétoarchitektuře se rozlišují čtyři druhy zařízení:
1. Zdrojové zařízení — toto zařízení poskytuje zvuková data následujícím zařízením. Datamohou byt například získána:
• ze zvukové karty
• z mikrofonu
• ze vstupního souboru (AU, WAV, . . .)
• LINE INPUT
V řetězci zařízení, se může najednou vyskytovat právě jedno vstupní zařízení a musí býtumístěno úplně vlevo.
2. Processor — toto zařízení zpracovává a různě modifikuje data na svém vstupu. Tato mo-difikovaná data poskytuje na svém výstupu. S pomocí tohoto typu zařízení lze napříkladvytvářet různé efekty v audiosignálu: echo, reverze, . . .
Libovolný počet těchto zařízení můžeme vložit na jakékoliv místo v řetězci.
3. Monitor — toto zařízení slouží pouze k zobrazování dat na svém vstupu, na svůj výstupposkytuje nezměněná data. S pomocí toho zařízeni, lze zobrazovat: amplitudový průběh,spektrogram, .. .
Tento typ zařízení, můžeme v libovolném počtu a kamkoliv umístit do řetězce.
14 KAPITOLA 4. APLIKACE (APLET) SEDEMO — „ZVÝRAZNĚNÍ ŘEČI“
4. Výstupní zařízení — toto zařízení pouze přijímá vstupní data. Přijatá data buď odešlena výstup počítače (sluchátka, reproduktory) nebo je uloží do souboru (AU, WAV, . . .).
V řetězci zařízení, se může vyskytovat najednou právě jedno výstupní zařízení a musí býtumístěno úplně vpravo.
Ve výše uvedeném obrázku 4.1, bude tedy první zařízení „Zařízení 1“ vstupním zařízením.„Zařízení 2“ až „Zařízení N-1“ jsou typu monitor nebo processor. Poslední zařízení „Zařízení N“je výstupní zařízení.
Tato architektura se také někdy nazývá „pull architecture“, protože jednotlivé vzorky zvu-kových dat, jsou předávány mezi zařízeními. Na požadavek výstupního zařízení, začne vstupnízařízení poskytovat zvuková data. Tato data si předávají ostatní zařízení (processor, monitor)až nakonec skončí u výstupního zařízení.
Aby byla zajištěna kompatibilita mezi mezi různými zařízeními, tak všechna zařízení musejívycházet ze společného předka (zařízení) — musí implementovat jeho vlastnosti. Mezi nejdůle-žitější vlastnosti patří:
• Musí umět přijímat data a poskytovat je dále.
• Musí umět zjistit a nastavit počet kanálů.
• Musí umět zjistit a nastavit hodnotu sampling rate.
4.2 Navržená zařízení
V následují části jsou popsána implementovaná zařízení v programu SEDemo. Všechna zařízeníjsou omezena těmito požadavky:
• Počet kanálů je maximálně 2 (mono, stereo). (V aktuální verzi programu se pracuje pouzes jedním kanálem — přijde-li na vstup stereo signál, tak je vzápětí automaticky zkonver-tován na signál s jedním kanálem.).
• Hodnota sampling rate je v intervalu 8000 Hz – 44100 Hz
• Vzorky dat, jsou uloženy v datovém typu: 16-bit znaménkový integer. Vzorky tedymohou nabývat hodnot v intervalu: −32768 až +32767.
4.2.1 Vstupní zařízení
V programu jsou definovány tato „vstupní zařízení“:
• WAV — Načítá data ze vstupního souboru typu *.wav ve formátu: PCM (typ 1), 8-bitmu law G.711 (typ 7).
• AU — Načítá data ze vstupního souboru typu *.au ve formátu: 8-bit mu law G.711 (typ1), 8-bit linear PCM (typ 2), 16-bit linear PCM (typ 3).
• BIN — Načítá data ze vstupního souboru typu *.bin ve formátu: 16-bit linear PCM.
• SPEC — Načítá data ze vstupního souboru typu *.spec pro zobrazení spektrogramu.Data jsou uložena ve formátu HTK.
• MIC — Získává data přímo z mikrofonu.
KAPITOLA 4. APLIKACE (APLET) SEDEMO — „ZVÝRAZNĚNÍ ŘEČI“ 15
4.2.2 Monitor
V programu jsou definovány tyto „monitory“:
• Scope — Zobrazí časový průběh signálu v samostatném okně.
• ScopeSpectrogram — V jednom okně zobrazí časový průběh signálu a jeho spektro-gram.
• Spectrogram — Zobrazí spektrogram signálu v samostatném okně.
4.2.3 Processor
Tato zařízení se skládají z klientské a serverové části. Klientská část posílá data na vzdálený ser-ver, kde je provedeno zvýraznění řeči nebo je proveden výpočet dat pro zobrazení spektrogramu.Server po skončení svého výpočtu odešle nová data zpět klientovi, který je dále zpracuje —zobrazí grafické průběhy, přehraje je apod. Popis činnosti klientské a serverové části se nacházív kapitole 6.
• Zvýraznění řeči — provede zvýraznění řeči v daném signále.
• Výpočet spektrogramu — z daného signálu vypočte data pro zobrazení spektrogramu.
4.2.4 Výstupní zařízení
V programu jsou definovány tato „výstupní zařízení“:
• AU — Ukládá data do souboru ve formátu *.au
• WAV — Ukládá data do souboru ve formátu *.wav
• BIN — Ukládá data do souboru ve formátu *.bin — 16 bit liner PCM.
• PLAYER — Vstupní data zahazuje, umožňuje pohyb dat v řetězci zařízení.
• PCM PLAYER — Přehrává zvuková data.
4.3 Vizualizace dat
Na základě volby zobrazení grafického průběhu v hlavním menu programu — položka Zobrazjsou nabídnuty tyto grafické průběhy: zobraz vstupní signál a vstupní spektrogram, vstupnísignál a výstupní signál, vstupní spektrogram a výstupní spektrogram, výstupní signál a výstupníspektrogram, vstupní/výstupní signál, vstupní/výstupní spektrogram.
Tyto grafické výstupy jsou zobrazeny s pomocí následujících vytvořených „řetězců zařízení“.
4.3.1 Zobrazení vstupního průběhu a vstupního spektrogramu
• První blok v řetězci 4.2 představuje vstupní zařízení, které načítá data ze vstupníhoaudiosignálu.
• Druhý blok v řetězci představuje monitor, který zobrazí pouze jeden grafický průběh, nadata druhého průběhu musí počkat.
• Prostřední velký blok představuje processor, který zajišťuje výpočet dat pro zobrazeníspektrogramu.
• V předposledním bloku už má monitor data i pro zobrazení spektrogramu.
• Poslední výstupní zařízení spouští „proudění“ dat v řetězci a přijatá data zahazuje.
16 KAPITOLA 4. APLIKACE (APLET) SEDEMO — „ZVÝRAZNĚNÍ ŘEČI“
Obrázek 4.2: Zobrazení vstupního průběhu a vstupního spektrogramu
4.3.2 Zobrazení výstupního průběhu a výstupního spektrogramu
Obrázek 4.3: Zobrazení výstupního průběhu a výstupního spektrogramu
• První blok v řetězci 4.3 představuje vstupní zařízení, které načítá data ze vstupníhoaudiosignálu.
• Druhý blok v řetězci představuje processor, který zajistí zvýraznění řeči v audiosignálu.
• Třetí blok v řetězci představuje monitor, který zobrazí pouze grafický průběh výstupníhosignálu (nově získaný audiosignál), na data druhého průběhu musí počkat.
KAPITOLA 4. APLIKACE (APLET) SEDEMO — „ZVÝRAZNĚNÍ ŘEČI“ 17
• Čtvrtý blok představuje další processor, který zajišťuje výpočet dat pro zobrazení vý-stupního spektrogramu.
• V předposledním bloku už má monitor data i pro zobrazení spektrogramu.
• Poslední výstupní zařízení spouští „proudění“ dat v řetězci a přijatá data zahazuje.
4.3.3 Zobrazení ostatních grafických průběhu
Zbývající grafické průběhy se získají kombinací předchozích obrázků 4.2 a 4.3. Ve skutečnosti,se dané průběhy zobrazí trochu jinak — použije se optimalizace. Jakmile se už jednou vypo-čítají data pro zobrazení daného audiosignálu, tak se uloží do paměti. V okamžiku, kdy budutato data potřebná, tak se rovnou přečtou z paměti, čímž dojde k urychlení výpočtů — zobra-zení grafických průběhu. Pokud by se tato optimalizace neprovedla, tak by se nejen zbytečněpřetěžoval server, který by stále znovu počítal stejná data, ale také by samotné zobrazovánídat trvalo příliš dlouho.
4.3.4 Použití apletu na html stránce
Postup použití apletu na html stránce je uveden v kapitole 7.2.1
4.3.5 Popis zdrojových kódů
Zdrojové kódy tohoto apletu se nacházejí na přiloženém CD v adresáři:sedemo/src/.
Popis jednotlivých souborů je uveden v příloze C.Podrobný popis fungování apletu SEDemo je popsán ve zdrojovém kódu a v přiložené
dokumentaci na CD [6].
4.3.6 Nezbytné podpůrné balíčky
Program SEDemo používá ke své činnosti baličky *.jar, které rozšiřují jeho vlastnosti. Tytobalíčky obsahují přeložené *.class soubory a další všechny potřebné zdroje, jako jsou obrázky,pomocné soubory,. . .
Tyto balíčky jsou nezbytnou součástí programu, bez kterých nelze úspěšně přeložit zdrojovésoubory a také bez nich nelze úspěšně spustit aplikaci (applet).
4.3.6.1 JavaHelp 2.0 02
Tento balíček slouží k vytváření integraci uživatelské nápovědy do aplikací nebo appletů aje zdarma k dispozici na WWW stránkách [15], kde je také popsán způsob instalace. Násle-dující uvedená publikace [4] popisuje používání systému JavaHelp. Stažený archív JavaHelpuobsahuje několik knihoven (balíčků *.jar), program SEDemo z nich pouze vyžaduje java-help/lib/jhall.jar — soubor obsahuje všechny třídy vztahující se k systému nápovědy Java-Help, včetně těch, které jsou nezbytné k tvorbě katalogu indexovaných slov.
4.3.6.2 Java Media Framework 2.1.1e
Tento balíček slouží jako programové rozhraní (API) pro aplikace a applety, které manipulujíse zvukovými a video daty na profesionální úrovni.
JMF 1.0 API (Java Media Player API) umožňuje programátorům vyvíjet Java programypro přehrávání zvukových dat (time-based media). JMF 2.0 API rozšiřuje rozhraní o podporuzáznamu a ukládaní dat, řízení zpracování dat během přehrávání, uživatelská rozhraní pro
18 KAPITOLA 4. APLIKACE (APLET) SEDEMO — „ZVÝRAZNĚNÍ ŘEČI“
práci se streamovými daty. Dále definuje pluginy API, které umožňují pokročilým vývojářůmsnadněji vyvíjet uživatelské rozšíření funkcí JMF.
Tento balíček lze stáhnout na WWW stránkách [16], kde je také popsán způsob instalace.
4.4 Závěr
Demonstrace zvýrazňování řeči je realizována programem SEDemo, jehož hlavní náplní je umož-nit uživateli nahrát krátkou řečovou promluvu nebo načíst nějaký audiosignál. Druhou hlavníčástí programu je výběr algoritmu zvýraznění řeči, která se provede na straně serveru. Efek-tivita jednotlivých algoritmů se nejlépe porovnává na zobrazených spektrogramech vstupního(původního) signálu a výstupního (upraveného — zvýrazněného) signálu. Princip celého pro-gramu je založen na vytváření „audio řetězce“, do kterého se vkládají různá zařízení (vstupní,výstupní, monitor, filtr), která postupně upravují vstupní signál — například první zařízenív řetězci umí nahrát nebo načíst vstupní signál, druhé zařízení může zobrazit vstupní signál,třetí zařízení může signál různě modifikovat, ve čtvrtém zařízení můžeme zobrazit tento novýupravený signál či ho může pouze přehrát v reproduktorech či uložit do souboru. Tento modu-lární systém umožňuje rozšířit vlastnosti celého programu SEDemo pouhým přidáním novéhomodulu — zařízení.
KAPITOLA 5. APLET SCWP — „ROZPOZNÁVÁNÍ ŘEČI“ 19
5 Aplet SCWP — „rozpoznávání řeči“
Program SCWP je sada navzájem spolupracujících apletů, které umožňují hlasové ovládáníWWW stránek. Aplety mezi sebou komunikují s pomocí předávání zpráv. Na následujícímobrázku 5.1 je vidět princip fungování programu SCWP.
Obrázek 5.1: Princip fungování programu SCWP
Jméno programu SCWP vzniklo složením počátečních písmen anglického názvu SpeechControlled Web Pages (hlasové ovládání WWW stránek).
První aplet na obrázku se jmenuje SR (Speech Recognizer). Pokud tento aplet detekujeřeč, tak nahraje hlasový povel, který vzápětí pošle na server. Na serveru dojde k rozpoznáníhlasového povelu na textový povel, který je vrácen zpět apletu SR. Jakmile aplet SR obdržítextový povel, tak ho předá svému sousedovi — apletu CWP a pak opět čeká, zda-li nedošlok detekci řeči, aby mohl nahrát hlasový povel — celý cyklus se poté opakuje znovu.
20 KAPITOLA 5. APLET SCWP — „ROZPOZNÁVÁNÍ ŘEČI“
Druhý aplet na obrázku se jmenuje CWP (Control Web Page). Tento aplet se stará o ovlá-dání samotné WWW stránky. Na základě rozpoznání přijatého textového povelu provádí tytočinnosti:
• Zobrazí novou WWW stránku, která odpovídá vybrání hypertextového odkazu.
• Posouvá WWW stránku nahoru nebo dolu, aby bylo možné číst skryté části dokumentu
• Provádí posun vpřed / vzad v historii zobrazených WWW stránek.
Neznámý povel, který neumí zpracovat pošle svému následujícímu sousedovi — apletu TE-LEPHONE.
Předposlední aplet TELEPHONE se stará o zobrazení telefonu s digitálním číselníkem.Na základě přijatého povelu zobrazuje „vytočené číslo“. Pokud tento aplet nerozpozná textovýpovel, tak ho pošle dál svému sousedovi.
Poslední aplet představuje možnost přidání další apletů, které budou dále zpracovávat „ne-známý“ povel.
Pokud aplet nemá žádného svého souseda, tak neznámý povel, který neumí zpracovat zahodía čeká na nový povel.
5.1 Aplet SR
Tento aplet SR má na starosti nahrání hlasového povelu, jeho následné odeslání na servera příjem zpracovaného hlasového povelu, který obdrží jako textovou zprávu. Tento textovýhlasový povel odešle svému registrovanému sousedovi. Zjednodušeně lze říci, že má na starostirozpoznání hlasového příkazu.
5.1.1 Principiální popis apletu
Tento aplet se principiálně skládá ze tří hlavních částí:
• První část má na starosti pouze neustálé nahrávání dat z mikrofonu, jakmile je apletzobrazen na WWW stránce. Nahraná data posílá druhé části — detektoru řeči.
• Detektor řeči analyzuje nahraná data a rozhoduje, zda-li nahraná data obsahují platnouřeč nebo „dlouhou pauzu“. Pouze tehdy, je-li detekována platná řeč dochází k ukládánířeči na lokální počítač. Jakmile je detekován konec řeči, tak na řadu přijde třetí hlavníčást — rozpoznávač řeči. Přesáhne-li doba detekování souvislé řeči 10 sekund, tak detektorřeči automaticky ukončí nahrávání hlasového povelu. Tím se ošetří možná chybná detekcekonce řeči, kdy je „šum na pozadí“ detekován jako platná řeč.
• Třetí poslední důležitou částí je rozpoznání řeči. Tento aplet se navenek chová jako roz-poznávač řeči — nahraje řeč a vrátí textový přepis mluveného slova, ale ve skutečnostio rozpoznání mluveného slova požádá server, který provede vlastní rozpoznání. Principskutečného rozpoznávače je popsán v kapitole 6.2.
KAPITOLA 5. APLET SCWP — „ROZPOZNÁVÁNÍ ŘEČI“ 21
5.1.1.1 Princip detektoru řeči
Detektor řeči je založen na principu výkonového detektoru (viz. kapitola 2.2.1.3), kde se vycházíz jednoduchého předpokladu, že přítomnost řečové aktivity znamená nárůst výkonu signálu.
Detektor řeči neustále dostává na svůj vstup nahraná data z mikrofonu, tyto data ukládádo několika bufferů, se kterými dále pracuje. Cyklus detektoru řeči se skládá z několika fází:
1. Z fáze inicializace. V této fázi detektor nastaví práh kriteriální funkce, která budeurčovat, zda-li došlo k detekci řeči nebo dlouhé pauzy. Hodnota kriteriální funkce senastaví na základě nahraného šumu z okolí mikrofonu. V této fázi se nesmí mluvit domikrofonu, jinak by se nastavila příliš vysoká mez. Inicializace trvá 2 sekundy, po tutodobu se ukládají data z mikrofonu do bufferu, ze kterého se pak vypočítá prahová hodnota— Prahový výkon.
Prahový výkon se spočítá podle vzorce
Pprah = Ps + 3 · Pstd, (5.1)
22 KAPITOLA 5. APLET SCWP — „ROZPOZNÁVÁNÍ ŘEČI“
kde Ps je střední hodnota okamžitého výkonu
Ps =1N·N−1∑
i=0
Pi (5.2)
Pstd je standardní odchylka okamžitého výkonu
Pstd =
√√√√√N−1∑i=0
(Pi − Ps)2
N − 1, (5.3)
a Pi je okamžitý výkon, který se počítá ze vzorků analyzovaného segmentu délky N, tj.
Pi =N−1∑
n=0
s2n (5.4)
Velikost bufferu pro výpočet okamžitého výkonu odpovídá součinu vzorkovací frekvencenahraného signálu mikrofonem a zvolenou dobou pro výpočet segmentu okamžitého vý-konu, což v mém případě je 10 ms. Délka bufferu ve vzorcích je pak dána
N = 10ms · fs = 0.01s · 16000Hz = 160 (5.5)
2. Fáze detekce elementární řeči. Jakmile proběhne inicializace a je vypočten prahovývýkon, tak se v cyklu začne vypočítávat pouze okamžitý výkon (aktuální výkon), který sebude porovnávat s vypočtenou hodnotou prahového výkonu. Je-li okamžitý výkon většínež prahový výkon, tak byla detekována elementární řeč (detektor vrací hodnotu 1), jinakje detekována elementární pauza (detektor vrací hodnotu 0).
3. Fáze detekce řeči. Díky předchozí fázi jsme získali sadu číslic — 0 nebo 1, které určují,zda-li byla detekována elementární řeč v segmentu řeči o velikosti 10ms. Tyto hodnoty ob-sahují elementární detekci řečové aktivity, která obsahuje mnoho krátkodobých chybnýchrozhodnutí neboť lidský hlas je velice dynamický. Jednotlivé hlásky se vyslovují různěrychle a jsou mezi nimi různě krátké prodlevy, také krátkodobá rušení jsou detekovánajako řeč, apod.
Abychom byly schopni skutečně rozlišit řeč, která se skládá ze slov a krátkých pauz,mezi jednotlivými slovy, musíme ještě rozdělit detekovanou elementární řeč na jednotlivésegmenty, ze kterých zjistíme, zda-li byla detekována řeč nebo dlouhá pauza.
Tato primitivní detekce řeči se sleduje v segmentech délky 0.5 sekund. Obsahuje-li tentosegment více než 20% řečové aktivity tak předpokládáme přítomnost řeči a dochází k uklá-dání snímaného signálu na lokální počítač. Pokud detektor od této chvíle zjistí, že večtyřech segmentech za sebou nebyla detekována řeč, tak ukončí svou činnost — přestanenahrávat data z mikrofonu a nahranou řeč pošle rozpoznávači, který převede řeči v akus-tickém signálu na text.
Jakmile je detektor aktivován, tak se celý cyklus znovu opakuje.
KAPITOLA 5. APLET SCWP — „ROZPOZNÁVÁNÍ ŘEČI“ 23
5.1.2 Popis vzhledu apletu
Navržený aplet je vidět na WWW stránce a skládá se ze tří částí, které můžeme vidět naobrázku 5.3.
Obrázek 5.3: Grafický vzhled apletu SR
Pod první částí se skrývá tlačítko, které umožňuje manuální vypnutí / zapnutí rozpoznávánířeči. Jakmile je zobrazen tento aplet, tak automaticky dojde ke spuštění rozpoznávání řeči.Popisek tlačítka má různé barvy pozadí a textu, v závislosti na tom, v jaké stavu se nacházírozpoznávač hlasového povelu. Rozpoznávač řeči se může nacházet v různých stavech, kteréjsou uvedeny v následující tabulce 5.1.
Popis Barva Význam
Rozpoznávač vypnut Modrá Rozpoznávač je vypnut — hlasové ovládání nefunguje.Inicializace Červená Inicializace rozpoznávače, nastavuje se práh citlivosti.
Tento práh určuje od jaké intenzity hlasitosti nahra-ného signálu bude detektor řeči indikovat platnou řečnebo ticho (pauzu).
Očekávám příkaz Zelená Detektor řeči nezaznamenal žádnou řeč.Detekována řeč Zelená Detektor řeči zaznamenal řeč.
Rozpoznávám příkaz Červená Rozpoznávač rozpoznává hlasový povel, po rozpoznánípříkazu provede odpovídající činnost. V této fázi jenahrávání z mikrofonu vypnuto
Tabulka 5.1: Stavy apletu hlasového vstupu
Jednotlivé změny stavu rozpoznávače řeči se neprovádí okamžitě, ale s menší prodlevou.Druhá část obsahuje textový popis Poslední přijatý příkaz: a nakonec v poslední části se
zobrazuje poslední přijatý příkaz.
5.1.3 Použití apletu na html stránce
Je velmi vhodné umístit tento aplet na html stránku tak, aby byl stále vidět, i když posouvámestránkou nahoru / dolu, aby jsme viděli zbytek skrytého textu na obrazovka. Aplet je třeba stálevidět proto, aby jsme věděli, v jaké fázi se zrovna nachází rozpoznávač — aby jsem zadávalihlasový povel ve správnou dobu — ve fázi Očekávám příkaz.
Pevné umístění na html stránce se docílí pomocí kaskádových stylů (CSS), konkrétně s po-mocí atributu position:fixed. Bohužel, ne všechny WWW prohlížeče implementují celý standardkaskádových stylů, takže se musí tento atribut obcházet s pomocí různých „hacků“, které všakv pozdějších verzích prohlížeče nemusejí fungovat, jakmile napraví své chyby. Tento problém sev současné době týká WWW prohlížeče Internet Explorer verze nižší než 7. Prohlížeče MozillaFirefox a Internet Explorer 7 tuto vlastnost CSS stylu podporují.
Aplet nelze vložit do rámce, protože musí být schopen komunikovat s ostatními aplety,které se vyskytují na stránce podle toho, o jakou html stránku jde. Sice na oficiálních WWW
24 KAPITOLA 5. APLET SCWP — „ROZPOZNÁVÁNÍ ŘEČI“
stránkách [5] píší ze to sice lze, ale tato vlastnost není podporována přímo „Java API“ a nekaždý WWW prohlížeč tuto vlastnost podporuje.
Aplet se vloží na html stránku s pomocí této značky html jazyka s těmito povinnými para-metry:
Zdrojové kódy tohoto apletu se nacházejí na přiloženém CD v adresáři:scwp/src/cz/cvut/fel/mihlon/scwp/sr:
AlarmClock.java Tato třída zajistí, že se bude nahrávat řeč pouze po omezenou dobu. Ideálnídoba je okolo 10s.
FormatControls.java Obsahuje a nastavuje parametry Audioformátu, který slouží k nasta-vení vlastností pro nahrávání či přehrávání audiosignálu.
Mic.java Zajišťuje nahrávání z mikrofonu.
SendDataDialog.java Posílá data na server, který je zpracuje a vrátí zpět. Během komu-nikace se serverem zobrazí dialog, který informuje o průběhu komunikace a nedovolujecokoliv dělat. Až komunikace skončí, tak ukončí dialog.
SpeechDetector.java Detekuje řeč při nahrávání z mikrofonu.
SpeechRecognizer.java Nahrávání příkazu z mikrofonu, následně odešle příkaz (audio) naserver, příjem dekódovaného povelu (text) a odeslání příkazu (text) registrovanému ap-pletu.
SpeechRecognizerProxy.java Simuluje nahrávání příkazu z mikrofonu, následné odeslánípříkazu (audio) na server, dekódování příkazu na serveru, příjem dekódovaného povelu(text). Příkaz odešle registrovanému appletu.
KAPITOLA 5. APLET SCWP — „ROZPOZNÁVÁNÍ ŘEČI“ 25
Podrobný popis fungování apletu SR je popsán ve zdrojovém kódu a v přiložené dokumentacina CD [7].
5.2 Aplet CWP
Tento aplet CWP má na starosti ovládání samotné WWW stránky.
5.2.1 Principiální popis apletu
Na základě rozpoznání přijatého textového povelu, uvedeného v tabulce 5.2 provádí tyto čin-nosti:
Hlasový příkaz Akce
dolu Posun WWW stránky nahoru.nahoru Posun WWW stránky dolu.vpřed Posun vpřed v historii zobrazených WWW stránek.zpět Posun vzad v historii zobrazených WWW stránek.
hypertextový odkaz Zobrazí WWW stránku, na kterou ukazuje hypertextový odkaz.
Tabulka 5.2: Hlasové ovládání WWW stránky
1. Zobrazí novou WWW stránku, která odpovídá vybrání hypertextového odkazu. Jakmile jetento aplet aktivní, tak si stáhne aktuálně zobrazenou stránku. Tuto stránku postupněanalyzuje — hledá v ní definice hypertextových odkazů. Jakmile nějaký hypertextovýodkaz nalezne, tak z něj vybere „název hypertextového odkazu“, který je zobrazen nahtml stránce a samotnou „adresu hypertextového odkazu“. Tyto dvě hodnoty uloží doasociativního pole, kde je klíčem název a hodnotou je adresa.
Klíčem je buď přesný název hypertextového odkazu a nebo jeho kombinace. Pokud novývkládaný „klíč“ už existuje v daném poli, tak se do pole vloží (přidá) pouze „hodnota“,takže lze s pomocí jednoho „klíče“ získat více hodnot. Zda-li se má do asociativního polevkládat pouze přesný název hypertextového odkazu či jeho kombinace, určuje parametrapletu exactlinks v html stránce.
V okamžiku, kdy se má zobrazit nová stránka, která je určena hypertextovým odkazem,se zjistí, že daný klíč odpovídá více stránkám, tak se zobrazí html stránka, která informujeo této shodě. Na stránce se objeví seznam všech hypertextových odkazů, které odpovídajídanému klíči a uživatel je upozorněn, že má blíže specifikovat, kterou stránku chce vlastnězobrazit.
Tato situace nastane, když chce uživatel na demonstrační stránce zjistit kontaktní infor-mace o členu Katedry teorie obvodů. Na úvodní stránce je zobrazen seznam všech členů— je tam uvedeno jméno a příjmení, které slouží jako hypertextový odkaz html stránkus kontaktními údaji. Aplet CWP získá tyto hypertextové odkazy a vytvoří dva klíče nasamotný odkaz: jméno a příjmení. Shoda nastane při výběru některých odkazů, kde seshodují jména osob. Uživatel je na tuto shodu upozorněn a musí vybrat danou osobus pomocí jména a příjmení, příjmení a jména nebo s pomocí příjmení.
2. Posouvá WWW stránku nahoru nebo dolu, aby bylo možné číst skryté části dokumentu.Posun stránky je zajištěn s pomocí volání příkazů (funkcí) JavaScriptu.
3. Provádí posun vpřed / vzad v historii zobrazených WWW stránek. Zobrazování stránekv historii je prováděno s pomocí volání příkazů (funkcí) JavaScriptu.
26 KAPITOLA 5. APLET SCWP — „ROZPOZNÁVÁNÍ ŘEČI“
4. Pokud aplet zjistí, že přijatý příkaz neodpovídá žádnému hypertextovému odkazu a anipříkazu pro ovládání WWW stránky, tak tento příkaz pošle svému registrovanému apletu,který tento příkaz dále zpracuje. Pokud u tohoto apletu není registrován žádný aplet, kterýby zpracoval tento příkaz, tak zahodí neznámý příkaz a požádá aplet SR, aby nahrál novýpříkaz.
5.2.2 Popis vzhledu apletu
Tento aplet nemá žádný grafický výstup.
5.2.3 Použití apletu na html stránce
Vzhledem k tomu, ze aplet nemá žádný grafický výstup, lze jeho define v html stránce umístitkdekoliv. Jelikož tento aplet přímo volá funkce JavaScriptu, je třeba, aby měl tento aplet povo-lené spouštění funkcí JavaScriptu. Vlastní těla funkcí JavaScriptu jsou uložena v samostatnémsouboru. Jméno tohoto souboru musí být uvedeno v těle html stránky.
Html stránka musí obsahovat tyto řádky: Aplet se vloží na html stránku s pomocí tétoznačky html jazyka s těmito povinnými parametry:
Zdrojové kódy tohoto apletu se nacházejí na přiloženém CD v adresáři:scwp/src/cz/cvut/fel/mihlon/scwp/cwp:
ControllWebPages.java Ovládá webové stránky: zobrazuje nové stránky, provádí historiipříkazu: krok vpřed, vzad; posun textu v html stránce: nahoru, dolu; nasleduje hypertex-tové odkazy.
SetProxyDialog.java Zobrazí dialog, který umožní nastavit proxy nastaveni pro přístupk html stránkám.
Podrobný popis fungování apletu CWP je popsán ve zdrojovém kódu a v přiložené doku-mentaci na CD [7].
5.3 Aplet TELEPHONE
Tento aplet TELEPHONE se stará o zobrazení telefonu s digitálním displejem a demonstrujehlasové vytáčení telefonního čísla, které se pak zobrazí na displeji.
5.3.1 Principiální popis apletu
Aplet demonstruje hlasové vytáčení telefonního čísla, které musí být řečeno po jednotlivých čís-licích. Na telefonním displeji se zobrazuje maximálně 12 místní číslo, pokud se řekne více číslic,tak jsou zbylá číslice ignorována. Každé nově zadané telefonní číslo vždy přemaže předchozízadané číslo.
5.3.2 Popis vzhledu apletu
Na 5.4 uvedeném obrázku je zobrazen vzhled apletu — digitální telefon s displejem.
Obrázek 5.4: Grafický vzhled apletu TELEPHONE
28 KAPITOLA 5. APLET SCWP — „ROZPOZNÁVÁNÍ ŘEČI“
Telefonní číselník se skládá nejen z číslovek, ale i ze dvou speciálních znaků, jejich výslovnostje tato:
• # - hash, mřížka
• * - hvězdička
5.3.3 Použití apletu na html stránce
Tento aplet se může v html stránce umístit kdekoliv, kde je třeba, aby byl vidět.
Zdrojové kódy tohoto apletu se nacházejí na přiloženém CD v adresáři:scwp/src/cz/cvut/fel/mihlon/scwp/telephone:
Telephone.java Zobrazí telefon ovládaný hlasem.
Podrobný popis fungování apletu TELEPHONE je popsán ve zdrojovém kódu a v přiloženédokumentaci na CD [7].
5.4 Server SCWP
Vzhledem k tomu, že programy SCWP a SEDemo používají stejného klienta pro odesílání apříjem dat ze vzdáleného serveru, který je také pro oba programy stejný, bude princip klientaserveru popsán v kapitole 6.
KAPITOLA 5. APLET SCWP — „ROZPOZNÁVÁNÍ ŘEČI“ 29
5.5 Závěr
Demonstraci rozpoznávání řeči jsem realizoval s pomocí programu SCWP, který demonstrujehlasové ovládání WWW stránek (posun html stránky nahoru/dolu, aby se zobrazil skrytý text,pohyb v historii zobrazených stránek směrem vřed/vzad a především demonstruje zobrazovánínových WWW stránek na základě hlasového výběru hypertextového odkazu). Demonstrace jerealizována na simulaci hlasového vytáčení telefonního čísla, kde se rozpoznává sada jednotli-vých číslovek a dvou symbolů (#, *) oddělených krátkou pauzou. Druhou částí je zobrazeníkontaktních informací o dané osobě na seznamu člunů katedry, kdy je výběr založen na rozpo-znání jména, příjmení, jména a příjmení, příjmení a jména dotyčné osoby.
Tyto demonstrační WWW stránky se ovládají pouze hlasem. Proto jsem musel nejprve im-plementovat detektor řečové aktivity — použil jsem výkonový detektor, který detekuje řeč nazákladě nárůstu krátkodobého výkonu při přítomnosti řečové aktivity. Během realizace a prak-tického testování detektoru řeči jsem zjistil, že úspěšnost správné detekce řeči nezávisí pouzena nastavení vhodné kriteriální funkce, ale také na počátečním nastavení nahrávacích parame-trů mikrofonu. Pokud je citlivost mikrofonu příliš nízká či moc vysoká, tak detektor špatněreaguje — buď musíme do mikrofonu hodně křičet nebo detektor detekuje řeč při výskytu vý-raznějšího šumu na pozadí. Tento detektor je vhodný používat v relativně klidném prostředí(kancelář), kdy detektor není moc ovlivňován okolním šumem. Detektor není vhodný k pou-žívání ve venkovním prostředí, protože toto prostředí je obklopeno dynamickým šumem (hlukaut, procházející lidé, apod.), který by ovlivňoval funkčnost detektoru — byla by detekovánafalešná řeč. Tyto nevýhody by se daly částečně odstranit přidáním dalších kriteriálních funkcí.
Vlastní rozpoznání mluvené řeči je realizováno s pomocí sady nástrojů HTK. Abych mohlrozpoznávat česká slova, tak jsem musel zajistit vytvoření českého slovníku, gramatiky a získáníčeského HMM modelu elementární řeči. Během uživatelského testování demonstrace hlasovéhoovládání WWW stránek, jsem si ověřil, že úspěšnost rozpoznávání řeči je velice závislé navytvořeném slovníku a gramatice. Úspěšnost rozpoznání je tím větší, pokud se slovník skládáze slov, které se mezi sebou výrazně liší. V mé demonstraci hlasového vytáčení telefonního čísla,se vyskytují souběžně dva velice podobné příkazy — číslovka 5 (pět) a zpět (posun v historiiWWW stránek). Tyto dvě slova se liší pouze v prvním písmenu — „z“. Proto většina testovanýosob měla problémy, když chtěli použít příkaz zpět — místo toho se na displeji telefonu zobrazilačíslovka 5. Proto je vhodné v další verzi programu SCWP změnit příkaz zpět na jiný název,třeba dozadu.
Další parametr který výrazně ovlivňuje úspěšnost rozpoznání řeči je vytvoření vhodné gra-matiky. Čím gramatika obsahuje méně pravidel, tím se lépe rozpoznávač trefí do správnéhoslova, protože vychází ze statistických informací. Program SCWP by se mohl v další fázi vývojerozšířit tak, aby docházelo k dynamickému generování gramatiky — gramatika by obsahovalapouze ta slova, ze kterých uživatel aktuálně vybírá. Například na stránce, kde je zobraz seznamčlenů katedry, nejprve uživatel vybírá osobu na základě 20 jmen a 20 příjmení + 4 příkazy proovládání WWW stránky. Když uživatel vybere osobu podle jména, tak gramatika pracuje se 44slovy ze slovníku. Pokud uživatel vybere jméno, které patří více osobám, například Jan, tak zezobrazí WWW stránka, která upozorňuje uživatele, že došlo ke shodě a nabídne nový seznamosob, kteří se jmenují Jan. Uživatel teď volí osobu z 5 Janů (1 Jan + 5 příjmení + 4 příkazy).Proto nově vygenerovaná gramatika by měla skládat pouze z 10 slov.
Dalším nezanedbatelným parametrem je i vhodná volba HMM modelů elementární řeči.Tento model ovlivňuje správnost rozpoznání na nákladě natrénování fonémů — rozpoznávačmůže dobře reagovat na rychlou, pomalou řeč, na řeč, která se vyskytuje v hlučném prostředíapod.
30 KAPITOLA 5. APLET SCWP — „ROZPOZNÁVÁNÍ ŘEČI“
KAPITOLA 6. KLIENT / SERVER SEDEMO A SCWP 31
6 Klient / Server SEDemo a SCWP
Následující popisované části jsou stejné pro oba programy SEDemo a SCWP.Klienti obou programů, komunikuji se vzdáleným serverem s pomocí tohoto zobrazeného
schématu 6.1:
Obrázek 6.1: Komunikace klienta
V první fázi klient navazuje se serverem spojení. Je-li spojení úspěšně navázáno, tak muodešle číslo ID akce, kterou má server provést. V další části klient odešle hodnotu samplerate nahraného audiosignálu a samozřejmě i samotný audiosignál. Jakmile server získá celýaudiosignál od klienta, tak provede vlastní výpočet s přijatým audiosignálem na základě přijatéhodnoty ID. Pokud server rozpoznává hlasový příkaz, tak ke své činnosti nepotřebuje znáthodnotu sample rate nahraného audiosignálu, klient může poslat libovolnou hodnotu. Tatohodnota je důležitá pouze tehdy, má-li se provést zvýraznění řeči. Pokud výpočet na straněserveru proběhl úspěšně, tak server o tom informuje klienta, kterému pak vzápětí pošle upravenýaudiosignál a komunikace mezi klientem a serverem skončí. Zjistí-li však server, že došlo k chyběběhem zpracovávání audiosignálu, tak to oznámí klientovi, který ihned ukončí komunikaci seserverem.
Činnost serveru je velice podobná klientovi, což můžeme vidět na následujícím schématu6.2:
32 KAPITOLA 6. KLIENT / SERVER SEDEMO A SCWP
Obrázek 6.2: Komunikace serveru
Server stále čeká na spojení od klienta. Jakmile se klient spojí se serverem, tak server vytvořínový proces, který bude obsluhovat právě připojeného klienta. Po vytvoření nového procesu,server čeká na nové spojení od dalšího klienta — navržený server umí pracovat s několikaklienty najednou. Nově vytvořený proces přijme od klienta číslo ID, hodnotu sample rate audi-osignálu a samotný audiosignál. Proces na základe přijatého ID provede určenou akci s přijatýmaudiosignálem. Provede jednu činnost z těchto akcí:
• Vypočte data pro zobrazení spektrogramu.
• Provede zvýraznění řeči v audiosignálu.
• Rozpozná hlasový příkaz v audiosignálu — převede mluvenou řeč do textové podoby.
Požadované výpočty proces provádí s pomocí spouštění externích programu ctucopy a ná-strojů sady HTK. Po skončení výpočtů pošle proces klientovi návratový kód externích programů.Pokud výpočty proběhly bez žádných problémů, vrací hodnotu 0 a výsledný zpracovaný soubor(audiosignál nebo textový příkaz), jinak vrací chybový kód. V posledním kroku proces ukončíkomunikaci s klientem.
Server po celou dobu komunikace s klientem vytváří logovací soubory — standardní a chy-bový výstup externích programů. Z těchto záznamů se dá zjistit, jaký klient komunikuje se ser-
KAPITOLA 6. KLIENT / SERVER SEDEMO A SCWP 33
verem, zda-li výpočet proběhl správně a nebo slouží k hledání chyb, pokud dochází ke špatnékomunikaci mezi klientem a serverem.
Vytvoření těchto logovacích souborů nebylo triviální záležitostí, protože je musel vytvářetsamotný server a ne externí programy. Realizaci vytvoření logovacího systému jsem se inspirovalčlánkem [8]
V následující části budu popisovat, jaké kroky provádí server, aby se mohla realizovat de-monstrace:
• zvýrazňování řeči — server provádí zpracování audiosignálu, výsledek se poté vizualizujev programu SEDemo.
• rozpoznávání řeči — server provádí rozpoznávání mluvené řeči, kterou uloží do textovéhosouboru. Tato uložená řeč pak slouží k hlasovému ovládání WWW stránek.
Server provádí zvýrazňování řeči a výpočet dat pro zobrazení spektrogramu na základě spouš-tění externího programu ctucopy [10] ([11]). Server na základě přijatého ID zjistí, zda-li máz přijatého audiosignálu počítat data pro zobrazení spektrogramu a nebo má-li provést zvý-raznění řeči — výběr algoritmu zvýraznění řeči je také dán hodnotou přijatého ID. Dalšímnezbytným parametrem pro spouštění programu ctucopy je přijatá hodnota sample rate au-diosignálu.
V předchozí kapitole 2.2.2 jsem se zabýval teorií rozpoznávání řeči. V této části budu popisovat,co je vše třeba udělat, aby mohl server rozpoznávat mluvenou řeč. Server rozpoznává řeč nazákladě spouštění externích programů, které jsou součástí sady nástrojů HTK. Tyto nástrojerozpoznávají řeč na základě statistických informací.
Když si připomeneme obrázek 2.2, tak aby rozpoznávač rozpoznával česká slova, musímepředevším zajistit tyto vstupní data:
• akustický signál
• gramatiku
• slovník
• HMM modely elementární řeči
6.2.1 Získání akustického signálu
Akustický signál je nahrán s pomocí klientského programu SCWP a je uložen do audio formátuWAV. Tento nahraný signál je klientem odeslán na server.
6.2.2 Vytvoření gramatiky
Gramatika definuje pořadí slov ze slovníku, které rozpoznávač využívá k rozpoznání řeči. Roz-poznávač rozpozná pouze ta slova / krátká spojení řeči, která jsou uvedena v gramatice. Vzhle-dem k tomu, že je rozpoznávač založen na základě statistických metod, tak je velice nevhodné,aby rozpoznávač pracoval pouze s jednou velkou gramatikou slov. Pokud by byla gramatikapříliš veliká, rozpoznávač by se často mýlil, čím bude gramatika menší, tím snadněji se buderozhodovat, které slovo / krátké spojení řeči bylo řečeno.
34 KAPITOLA 6. KLIENT / SERVER SEDEMO A SCWP
Na základě vytvoření slovníku všech slov, na které reaguje hlasové ovládání WWW stránkya na charakteru demonstrace, jsem vytvořil tři různé gramatiky, které se používají na různýchdemonstračních html stránkách.
Gramatika se definuje v textovém souboru, ale rozpoznávač nepracuje přímo s tímto soubo-rem, ale nejprve ji musí převést do svého formátu, kterému rozumí. Tato konverze se provádís pomocí nástroje HTK - HParse:
HParse gramatika wdnet
Výstupní soubor wdnet představuje vygenerovanou vnitřní formu gramatiky, se kterou pracujerozpoznávač.
Způsob vytvoření gramatiky je popsán v dokumentaci [3]. V následující části zobrazujivytvořené gramatiky. Všechny tři gramatiky mají společnou větev pro ovládání samotné WWWstránky.
6.2.2.1 Gramatika — „intro“
Tato gramatika slouží k vybrání html stránky, na které je podrobněji demonstrováno hlasovérozpoznání. Následující obrázek 6.3 zobrazuje grafické znázornění navržené gramatiky. Z ob-rázku lze vidět, že na začátku a na konci akustického signálu se může nebo nemusí nacházetdlouhá pauza (symbol #SIL#). Podle gramatiky může rozpoznávač v jednom kroku reagovatbuď na povel nebo na výběr stránky.
Tato gramatika slouží k výběru osob, u kterých se má zobrazit kontaktní informace. Následujícíobrázek 6.4 zobrazuje grafické znázornění navržené gramatiky. Z obrázku lze vidět, že na začátkua na konci akustického signálu se může nebo nemusí nacházet dlouhá pauza (symbol #SIL#).Podle gramatiky může rozpoznávač v jednom kroku reagovat buď na povel nebo na výběr osobypodle jména a příjmení, příjmení a jména, příjmení nebo jen podle jména.
Tato gramatika slouží k simulaci hlasového vytáčení telefonního čísla. Následující obrázek 6.5zobrazuje grafické znázornění navržené gramatiky. Z obrázku lze vidět, že na začátku a nakonci akustického signálu se může nebo nemusí nacházet dlouhá pauza (symbol #SIL#). Podlegramatiky může rozpoznávač v jednom kroku reagovat buď na povel nebo na sadu jednotlivýchčíslic oddělených krátkou pauzou (symbol #SP#).
Vlastní soubor s gramatikou vypadá takto:
$cisla = devět | dvě | hash | hvězdička | jedna |
nula | osum | pět | sedm | tři | šest | čtyři;
$povely = dolu | nahoru | vpřed | zpět;
([#SIL#] ( $povely | <$cisla #SP#> ) [#SIL#] )
36 KAPITOLA 6. KLIENT / SERVER SEDEMO A SCWP
Obrázek 6.5: Gramatika - telephone
6.2.3 Vytvoření slovníku
Slovník definuje slova, která bude rozpoznávač schopen rozpoznat. Slovník se skládá z jednot-livých dvojic - textového přepisu a rozkladu daného slova na jednotlivé fonémy. Rozpoznávačnerozpoznává slova na základě textového popisu daného slova, ale na základě fonémů. Rozkladslova a jeho jazykových variant na jednotlivé fonémy jsem provedl s pomocí programu lexfig.
Pro správnou činnost rozpoznávače stačí vytvořit jeden veliký slovník, protože rozpoznávačbude rozpoznávat pouze ta slova, která má uvedena v gramatice.
Jednotlivé řádky ve slovníku se nemusejí skládat pouze z jednoho slova, ale mohou se skládatz více různých slov, které jsou mezi sebou odděleny znakem krátké pauzy (#SP#). Navenek setyto slova chovají, jako jedno slovo. Díky této vlastnosti si mohu ušetřit práci s vyhodnocovánímrozpoznaných slov a s tvorbou gramatiky.
Když chci na html stránce obsahující členy Katedry teorie obvodů vybrat nějakou osobu,abych o ní získal nějaké informace, tak nemusím provádět výběr osoby na základě extra přijatéhojména a extra přijatého příjmení (po té bych musel na základě obou kombinaci prohledávatvšechny hypertextové odkazy, než bych nalezl shodu, což by bylo časově náročné), ale proveduvýběr osoby na základě jednoho přijatého slova (díky tomu, že slovo bude jedinečné, tak nazákladě jednoho kroku naleznu příslušný hypertextový odkaz v asociativním poli).
Například, pokud budu chtít získat informace o osobě — Bergl Petr, tak vytvořím tentozáznam ve slovníku:
Bergl_Petr b e r g l
Bergl_Petr b e r g l sp p e t r
Bergl_Petr p e t r sp b e r g l
Petr p e t r
Danou osobu mohu vybrat na základě: jména, příjmení, jména a příjmení, příjmení ajména. „Klíč“ Bergl Petr je v celém slovníku jedinečný a vznikl sloučením názvu hypertextovéhoodkazu.
6.2.4 HMM modely elementární řeči
HMM modely obsahují statistické vlastnosti elementární řeči, vznikají trénováním z velkýchdatabází řeči. Tyto modely jsem získal od Katedry teorie obvodů. K těmto HMM modelůmjsem také získal seznam všech fonémů, které jsou obsaženy v HMM modelech.
6.2.5 Rozpoznávání řeči
Server na základě přijatého ID zjistí, že má provést rozpoznání řeči a také, jakou má k tomupoužít gramatiku. Poté volá příslušný skript, který provede rozpoznání mluvené řeči na text.V následující části popíši skript, který provede rozpoznání řeči. Tento skript je principiálně
KAPITOLA 6. KLIENT / SERVER SEDEMO A SCWP 37
stejný pro všechny tři gramatiky, liší se jen obsahem gramatiky a místem uložení spouštěcíhoskriptu.
17 $CESTA_HTK/HCopy -A -T 7 -C $CESTA_NASTAVENI/config \
18 -S $CESTA_NASTAVENI/codetr.scp
19
20 $CESTA_HTK/HVite -C $CESTA_NASTAVENI/config2 \
21 -o ST -A -T 7 -H $CESTA_NASTAVENI/macros \
22 -H $CESTA_NASTAVENI/hmmdefs \
23 -S $CESTA_NASTAVENI/test.scp -l "*" \
24 -i $CESTA_NASTAVENI/recout.mlf \
25 -w $CESTA_NASTAVENI/wdnet -p 0.0 -s 5.0 \
26 $CESTA_NASTAVENI/slovnik \
27 $CESTA_NASTAVENI/monophones1
28
29 sed -f $CESTA_NASTAVENI/sed.rules \
30 $CESTA_NASTAVENI/recout.mlf > "$1.command"
31
32 echo "$1.command"
• Zobrazený skript se spouští s jedním parametrem, který určuje umístění a jméno souboru,který obsahuje nahraný audiosignál. Audiosignál musí být uložen v audio formátu WAV.Hodnota parametru je uložena v proměnné $1.
• Proměnná CESTA HTK určuje adresář, který obsahuje programy se sady nástrojů HTK.
• Proměnná CESTA NASTAVENI určuje adresář, který obsahuje konfigurační soubory prosamotný rozpoznávač.
• Na řádcích 6 – 12 se provádí test, zda-li je skript spuštěn se správným počtem parametrů.
• na řádcích 14 a 15 se dynamicky vytvářejí konfigurační soubory
• Příkaz HCopy na řádku 17 provede předzpracování audiosignálu.
• Příkaz HVite na řádku 20 provede vlastní rozpoznání řeči. Výsledek uloží do souborurecout.mlf
38 KAPITOLA 6. KLIENT / SERVER SEDEMO A SCWP
• Význam jednotlivých parametrů příkazů HCopy a HVite je popsán v dokumentaci HTK[3].
• Příkaz sed na řádku 29 provede filtraci výsledku: ze souboru odstraní komentář a nedů-ležité řádky, takže získá pouze požadovaný příkaz. Vzhledem k tomu, že nástroje HTKneumí přímo pracovat s českou diakritikou, jsou česká písmena zaprána v Unicode kó-dování. Program sed také provádí konverzi Unicode znaků na české znaky (ISO8859-2).Výsledné české slovo je uloženo do souboru $1.command
• Poslední příkaz na řádku 32 pouze vypíše získané slovo na standardní výstup, čímž sezapíše do logovacího souboru serveru.
KAPITOLA 7. INSTALACE PROGRAMŮ NA WEBOVÝ SERVER 39
7 Instalace programů na webový server
V následující části popisuji instalaci obou programů (SEDemo a SCWP) na webový server.
7.1 Instalace serveru
V této části se bude popisovat instalace serveru, který je společný pro oba programy SEDemoa SCWP, na počítač, na kterém je nainstalovaný Linux a webový server. Spolu s uvedenýmpopisem zobrazuji i konkrétní příklady postupů, u kterých předpokládám, že je bude provádětLinuxový administrátor, který daným příkazů rozumí a proto je nebudu podrobně popiso-vat. Všechna nastavení v konfiguračních souborech odpovídají nastavením, která jsou uvedenáv příkladech. Pokud se bude server instalovat do jiných adresářů, je třeba upravit i konfiguračnísoubory serveru !
1. Nejprve se musí v daném operačním systému vytvořit nějaký uživatel, pod kterým sebude spouštět server spolu s programy třetích stran.
linux#> useradd -m milase
2. V domovském adresáři nového uživatele je třeba vytvořit nějaký adresář, do kterého senahrají data „serveru“.
linux#> cd /home/milase
linux#> mkdir MilaSE
3. Z přiloženého CD zkopírovat obsah adresáře server/ do nově vytvořeného adresáře. Zko-pírován bude archív sedemo scwp-server.tar.bz2, který je třeba rozbalit.
Tento archív obsahuje tyto data — další adresáře: bin/, ctucopy, cz/, htk-bin/, htk-src/,log/, rc/, rozpoznavac/, tmp/
bin Adresář obsahuje spustitelné soubory programů třetích stran.
ctucopy Adresář pro obsahuje zdrojové a binární kódy programu ctucopy.
cz Přeložené kódy vlastního serveru
htk-bin Adresář pro binární data sady programu HTK.
htk-src Adresář pro zdrojová data sady programu HTK.
log Adresář pro záznam logovacích informaci od serveru
rc Adresář obsahuje spouštěcí rc-skript, který automaticky spouští server po zapnutínebo restartování počítače.
rozpoznavac Adresář obsahující konfigurační soubory rozpoznávače
40 KAPITOLA 7. INSTALACE PROGRAMŮ NA WEBOVÝ SERVER
tmp Adresář pro ukládání dočasných dat.
4. Z internetové adresy [9] stáhnout zdrojové kódy HTK tools: HTK-3.4.tar.gz a rozbalitje do adresáře htk-src. Podle instalačního návodu uvnitř archívu HTK tools je třebanástroje HTK přeložit a nainstalovat do adresáře htk-bin. Po instalaci nástrojů HTK jetřeba vytvořit symbolické linky na tyto spouštěcí programy: HParse, HVite, HCopy doadresáře bin.
linux#> cd /home/milase/MilaSE/bin
linux#> ln -s ../htk-bin/bin/HParse .
linux#> ln -s ../htk-bin/bin/HVite .
linux#> ln -s ../htk-bin/bin/HCopy .
5. Z internetové adresy [10] stáhnout zdrojové kódy programu ctucopy: CtuCopy_3.0.11.tar.bz2a rozbalit je do adresáře ctucopy. Podle instalačního návodu uvnitř archívu je třebaprogram přeložit. Po instalaci programu ctucopy je třeba vytvořit symbolický odkaz naspouštěcí program: ctucopy do adresáře bin.
6. Zkopírovat rc-skript SEDemoSCWPserver z adresáře rc do systému a vytvořit pří-slušné odkazy v init levelech, aby se server vždy automaticky spustil po zapnutí neborestartování počítače. Tento rc-skript je psán pro Linux Fedora Core, pokud v danémpočítači je nainstalována jiná verze Linuxu, je třeba tento skript přepsat podle možnostídaného operačního systému !
7. Pokud je na daném počítači spuštěn firewall, je třeba ho nakonfigurovat tak, aby pro-pouštěl komunikaci z venku na port serveru a zpět. Konkrétní hodnota daného portu jedefinována ve zdrojovém kódu serveru.
KAPITOLA 7. INSTALACE PROGRAMŮ NA WEBOVÝ SERVER 41
8. Posledním krokem je spuštění samotného serveru. Server pak poté běží pod právy nověvytvořeného uživatele (milase) a také externí programy, které spouští běží pod tímtouživatelem.
linux#> /etc/init.d/SEDemoSCWPserver start
9. Server se ukončí příkazem: /etc/init.d/SEDemoSCWPserver stop. Status serveru (zda-liběží nebo ne) se zjistí příkazem: /etc/init.d/SEDemoSCWPserver status.
7.2 Instalace klienta (apletu)
7.2.1 SEDemo
Zkopírujte z přiloženého CD obsah adresáře klient/SEDemo/ do adresáře, ze kterého Vášwebový server zobrazuje WWW stránky (/var/www/html/, /home/uživatel/public html/,apod.). Z CD si zkopírujete tyto soubory: sedemo-button.png, sedemo.html, SEDemo.jar s SE-Demo.jnlp, .java.policy.
SEDemo.jar Obsahuje přeloženou distribuci programu SEDemo.
SEDemo.jnlp Konfigurační soubor pro spuštění programu s pomocí Java Web Start, kde sedefinuje umístění archívu přeloženého programu (SEDemo.jar), určení minimální verzeJavy ke spuštění (pokud v daném systému není nainstalována požadovaná verze, tak seautomaticky nabídne možnost stažení požadované verze).
sedemo-button.png Obrázek tlačítka, které spouští program SEDemo
42 KAPITOLA 7. INSTALACE PROGRAMŮ NA WEBOVÝ SERVER
sedemo.html Jednoduchá html stránka (obrázek 7.1), která umožňuje spuštění programu SE-Demo. Ačkoliv je program SEDemo navržen jako aplet (také se dá spustit jako samostatnáaplikace), tak velice doporučuji spouštět program s pomocí technologie Java Web Start,než s pomocí značky applet v těle html souboru. Java Web Start umožňuje spouštětaplikace, jako by to byly aplety (automaticky jsou spouštěny se zapnutým modelem za-bezpečení — viz. 7.3.1), v samostatném okně. Java Web Start také umožňuje spouštětlibovolné programy s různými verzemi Javy, aniž by se musel provádět nějaký zásahv systému. Spuštění programu s pomocí Java Web Start je docíleno s pomocí definicehypertextového odkazu v html stránce: <a href="SEDemo.jnlp">
Obrázek 7.1: Úvodní html stránka SEDemo
.java.policy Soubor zásad zabezpečení pro úspěšné spuštění apletů (viz. kapitola 7.3.1). Tentosoubor zásad je nabídnut ke stažení na html stránce sedemo.html
7.2.2 SCWP
Zkopírujte z přiloženého CD obsah adresáře klient/SCWP/ do adresáře, ze kterého Vášwebový server zobrazuje WWW stránky (/var/www/html/, /home/uživatel/public html/,apod.). Z CD si zkopírujete tyto soubory: classes/, index.html, namesake.php, people/people,scwp.js, tbinfo.php, telephonebook.php, telephone.html
index.html Úvodní stránka — rozcestník, ze které se dají zobrazit tyto html stránky:
• Simulace hlasového vytáčení telefonního čísla.
• Stránka zobrazující informace o členech Katedry teorie obvodů.
telephone.html Stránka umožňující simulaci hlasové vytáčení telefonního čísla. Stránka zob-razuje telefon s displejem, který zobrazuje „vytočené“ telefonní číslo.
KAPITOLA 7. INSTALACE PROGRAMŮ NA WEBOVÝ SERVER 43
telephonebook.php Stránka zobrazující seznam lidí na Katedře teorie obvodů.
people/people Tento soubor people v adresáři people definuje informace, které se zobrazíu dané osoby. Každý řádek v tomto souboru představuje informace o právě jedné osobě,oddělovačem jednotlivých záznamů je znak &. Jeden vzorový řádek s popisem vypadátakto (ačkoliv příklad zobrazuje čtyři řádky, tak ve skutečnosti jde o dva řádky):
tbinfo.php Stránka zobrazuje informace o osobě, které jsou napsány v souboru people/people.
namesake.php Tato stránka oznamuje, že vybraná osoba ze seznamu nebyla jednoznačněurčena — osoba byla vybrána podle jména — v seznamu se vyskytuje více osob, sestejným jménem, proto je teď třeba vybrat osobu podle jména.
scwp.js Definice JavaScriptu, který se používá na html stránkách.
classes/ Tento adresář obsahuje přeložený program (aplet) SCWP.
7.3 Nastavení práv apletu / aplikace
7.3.1 Model zabezpečení v Javě
Aplety šířené v internetu s pomocí WWW prohlížečů představují neodmyslitelnou přítomnostbezpečnostního rizika, neboť cizí kód je spouštěn lokálně. Autoři jazyka Java proto na zmíněnériziko mysleli už při návrhu prvních verzí. Výsledkem je model zabezpečení nazývaný pískoviště(sandbox).
Model pískoviště je bezpečnostní prostředí okolo systému či aplikace, které je většinou posta-veno na zákazu potenciálně nebezpečných činností (přístup k souborům, k síťovým připojením,apod.).
Proto v prostředí jazyka Java existuje mechanismus, který zajišťuje, že jak lokální, taki vzdálený kód lze spouštět uvnitř specifických bezpečnostních domén založených na soubo-rech zásad zabezpečení (security policy files), jež určují, které programy mohou používat kteréprostředky.
Výchozí bezpečnostní politika jazyka Java je taková, že programy jazyka Java spuštěnélokálně mají plný přístup ke všem souborům a prostředkům poskytovaným systémem hostícímvirtuální stroj jazyka Java (model zabezpečení je vypnut). Zatím co programy spuštěné s pomocíWWW prohlížeče — aplety jsou automaticky spouštěny se zapnutým modelem zabezpečení aprovádějí svoji činnost v rámci působení svého „pískoviště“, kde je jejich činnost omezena.
Vzhledem k tomu, že mé programy — SEDemo a SCWP jsou spouštěny uvnitř pískoviště apotřebují přistupovat k systémovým prostředkům, tak je nezbytné, aby se na lokálním počítačivytvořil soubor zásad zabezpečení. Obsah tohoto souboru musí povolit nezbytné akce, kteréjsou nezbytné ke správné činnosti obou programů.
V následující části budu popisovat vytvoření minimálního souboru zásad zabezpečení. S úpl-ným popisem jednotlivých druhů zásad oprávnění se lze seznámit v knize [4].
44 KAPITOLA 7. INSTALACE PROGRAMŮ NA WEBOVÝ SERVER
7.3.2 Soubory zásad zabezpečení
Při instalaci prostředí jazyka Java (JRE - Java Runtime Environment) bez ohledu na to, zdaje toto prostředí instalováno samostatně nebo jako součást sady JDK (Java Development Kit),je instalován rovněž konfigurační soubor zabezpečení a implicitní soubor zásad. Konfiguračnísoubor zabezpečení se nazývá java.security a obsahuje oddíl podobný tomu, co je zobrazenv následujícím výpisu.
# The default is to have a single system-wide policy file,
Tento oddíl definuje implicitní soubory zásad, jde o obyčejné textové soubory, které neob-sahují formátovací znaky. První soubor představuje výchozí systémové nastavení zásad opráv-nění. Proměnná prostředí Javy $java.home představuje domovský adresář prostředí JRE(ne JDK !). Vzhledem k tomu, že tento soubor představuje „systémový soubor“, tak ve většiněpřípadů nemůže tento soubor přímo upravovat běžný uživatel. Proto je v zobrazeném výpisedefinován i uživatelský soubor, který může běžný uživatel upravovat. Implicitně se tento sou-bor v počítači nenachází, je vytvářen uživatelem teprve tehdy, když ho skutečně potřebuje.Proměnná prostředí Javy $user.home představuje domovský adresář právě přihlášenéhouživatele. V operačním systému UNIX (Linux) jde o adresář /home/uživatel, v MS Windowsjde většinou o adresář (záleží to na konkrétní verzi) C:/Documents and Settings/uživatel.
7.3.2.1 Vytvoření vlastního souboru zásad
Soubory zásad lze vytvářet a upravovat s pomocí libovolného textového editoru, který neukládáspolu s textem i formátovací znaky (velikost písma, tučné písmo, apod.). K uvedeným činnostemlze také použít nástroj policytool, který je dodáván jako součást sady prostředí Java JDK.Tento nástroj umožňuje ze seznamu zásad vybírat ty zásady, které chceme upravit a takéčástečně nabízí výběr hodnot, které můžeme nastavit.
Následující výpis zobrazuje minimální seznam zásad zabezpečení, který je třeba nastavit,aby mé programy (SEDemo a SCWP) fungovaly správně:
V následující části popisuji význam minimálního souboru zásad zabezpečení.
Třída oprávnění java.io.FilePermission
S pomocí této třídy FilePermission se uděluje oprávnění k užití souboru nebo adresáře. Tentotyp oprávnění vyžaduje dva řetězce. První specifikuje cíl oprávnění (soubor nebo adresář), zatímco druhý řetězec obsahuje seznam operací (činností), které lze s daným objektem vykonávat.
<< ALL FILES >> Specifikované operace jsou platné pro všechny soubory a adresáře v da-ném souborovém systému bez ohledu na umístění.
KAPITOLA 7. INSTALACE PROGRAMŮ NA WEBOVÝ SERVER 45
read Program může číst obsah adresářů a souborů.
write Program může vyvářet nové soubory a měnit obsah stávajících souborů.
delete Program smí mazat soubory a adresáře.
Oba programy (SEDemo a SCWP) vytváří v domovském adresáři uživatele adresář, do kte-rého ukládají dočasné soubory. Program SEDemo umožňuje kamkoliv uložit nahraný signál(řeč).
Třída oprávnění java.util.PropertyPermission
Virtuální stroj jazyka Java využívá řadu systémových proměnných. Je-li nepřátelský programschopen upravovat hodnoty systémových vlastností, může narušit správnou funkci ostatníchprogramů spuštěných ve stejné instanci virtuálního stroje jazyka Java.
Tato třída oprávnění očekává dvě hodnoty:
• Název vlastnosti nebo skupiny vlastností, k níž má být udělen přístup.
• Typ přístupu, který má být udělen.
* Nahrazuje všechny vlastnosti.
read Aplikace může pouze číst hodnoty systémových proměnných.
Oba programy zjišťují, kde je domovský adresář uživatele, aby v něm mohly vytvořit dočasnésoubory, k tomu je také třeba znát znak oddělovače adresářů.
Třída oprávnění javax.sound.sampled.AudioPermission
S pomocí této třídy AudioPermission se uděluje oprávnění k používání audio zařízení.
record Aplikace může nahrávat data z mikrofonu.
Oba programy ke své činnosti vyžadují schopnost nahrávat data z mikrofonu.
Třída oprávnění java.net.SocketPermission
S pomocí této třídy SocketPermission se uděluje oprávnění k používání operací se sokety.Samotné oprávnění se skládá ze dvou položek:
• Název hostitele (název DNS počítače v síti, případně jeho IP adresa) a port.
• Seznam akcí, které lze při operacích souvisejících s daným hostitele a portem povolit.
* Lze vytvořit připojení k libovolnému počítači dostupného v rámci sítě.
connect Umožňuje lokálnímu počítači vytvářet soketové připojení k jiným počítačům.
Použitím tohoto pravidla se zamezí zobrazení varovného dialogu, že program navazuje spo-jení se vzdáleným počítačem.
46 KAPITOLA 7. INSTALACE PROGRAMŮ NA WEBOVÝ SERVER
KAPITOLA 8. USEABILITY TESTOVÁNÍ WEBOVÉ APLIKACE SEDEMO A SCWP 47
8 Useability testování webové aplikace SEDemo a SCWP
8.1 Účel
Otestovat webové rozhraní aplikací SEDemo (demonstrace zvýrazňování řeči) a SCWP (demon-strace rozpoznávání řeči) na WWW stránkách http://noel.feld.cvut.cz/speechlab/ v sekcidemonstrace. Je třeba ověřit funkčnost nabízených vlastností a odhalit problematické částiprogramu z hlediska uživatele (špatně navržené prvky programu, složité ovládání,. . .)
8.2 Cíle testování
Otestovat uživatelskou část aplikace SEDemo a hledat problematické oblasti pro uživatele:
• Nahrát krátký řečový úsek.
• Prozkoumávání časového průběhu signálu — Zoomování průběhu.
• Přehrávání signálu.
• Nastavení parametrů pro nahrávání signálu.
• Výběr filtrů pro zvýraznění řeči.
Otestovat uživatelskou část aplikace SCWP a hledat problematické oblasti pro uživatele:
• Hlasový výběr WWW stránky.
• Simulace hlasového vytočení čísla
• Výběr stránky, zobrazující informace o dané osobě
• Hlasové ovládání WWW stránky — Zobrazení předchozí stránky, posun stránky na-horu/dolu.
8.3 Profil uživatele
Každý, kdo má minimální zkušenosti s prací s PC a používání mikrofonu.
8.3.1 Persony
• Martin — Martinovi je 18 let, navštěvuje stření školu už třetím rokem a příští rok hočeká maturita. Martin je spíše průměrným studentem. Ve volném čase buď fotí zajímavépředměty nebo s kamerou natáčí zajímavé události. S používáním počítače nemá žádnéproblémy, protože často s jeho pomocí upravuje fotografie/záběry z kamery, občas ho taképoužívá k hraní her, brouzdání po internetu a nebo pro sledování filmů. S počítačem seseznámil už jako malé dítě, protože ho velmi často používal jeho otec k práci.
• Lenka — Lenka je docela plachá dívka, které je 22 let. Před dvěma lety ukončila středníškolu. Lenka pracuje jako servírka v malé restauraci. Lenka má doma pět měsíců počítač,který využívá k brouzdání na internetu, čtení emailů a k četu s přáteli. Před pár dny se jípodařilo použít spojení s kamarády přes Skype, z čehož byla velmi nadšená. Naneštěstí sejí podařilo smazat nějaké důležité systémové soubory na jejím počítači, takže ho nemohlapoužívat celý týden, než jí ho bratr opravil.
48 KAPITOLA 8. USEABILITY TESTOVÁNÍ WEBOVÉ APLIKACE SEDEMO A SCWP
8.4 Testy
8.4.1 Screener
8.4.1.1 Úvod
Program SEDemo je určen pro užší okruh uživatelů, kteří se zabývají zpracováním řečovéhosignálu. Program demonstruje některé algoritmy pro zvýraznění řeči, proto v cílové skupinětesterů se musí vyskytovat nějaká osoba, která se dobře orientuje v této oblasti.
Program SCWP demonstruje rozpoznávání řeči — hlasové ovládání WWW stránek. Protoje určen pro široký okruh uživatelů, kteří by rádi uvítali hlasové ovládání PC a mají aspoňminimální zkušenosti s používáním počítače.
Posouzení zkušeností s používáním PC se bude provádět jednak podle doby, kterou uživatelPC používá a dále podle způsobů, jakým počítač používá.
8.4.1.2 Kritéria
Počet účastníků: 4.D1: 1 uživatel, který skoro nepoužívá multimediální programy, 1 uživatel který používá
multimediální programy, 2 uživatele aktivně se pracující v oblasti „zpracování řeči“D2: 1 uživatel s menšími zkušenostmi s PC, 1 uživatel s většími zkušenostmi, 2 uživatele
s každodenním stykem s PC
KAPITOLA 8. USEABILITY TESTOVÁNÍ WEBOVÉ APLIKACE SEDEMO A SCWP 49
8.4.1.3 Dotazník
1. Používáte počítač
[ ] nikdy, nikde
[ ] doma
[ ] v práci
[ ] ve škole
[ ] jinde, kde ? . . . . . . . . .
2. Jak dlouho počítač používáte?
3. Kolik času u počítače strávíte?
[ ] méně než hodinu týdně
[ ] hodinu až pět hodin týdně
[ ] hodinu až pět hodin denně
[ ] více než pět hodin denně
4. Za jakým účelem PC používáte?
[ ] programování
[ ] přístup k internetu/emailu
[ ] kancelářská práce (psaní dokumentů)
[ ] hraní her
[ ] používání multimediálních programů
[ ] jiný, jaký ? . . . . . . . . .
5. Chtěl by jste mít možnost ovládat PC hlasem ?
[ ] ano
[ ] ne
6. Měl byste zájem zúčastnit se testování internetové aplikace
[ ] ano
[ ] ne
7. Který den v týdnu a v kolik hodin mát čas ? (test může trvat 20. . .30 minut)
[ ] pondělí, čas . . . . . . . . .
[ ] úterý, čas . . . . . . . . .
[ ] středa, čas . . . . . . . . .
[ ] čtvrtek, čas . . . . . . . . .
[ ] pátek, čas . . . . . . . . .
[ ] sobota, čas . . . . . . . . .
[ ] neděle, čas . . . . . . . . .
50 KAPITOLA 8. USEABILITY TESTOVÁNÍ WEBOVÉ APLIKACE SEDEMO A SCWP
8.4.2 Seznámení testera s testovanými programy
Ke správnému používání programů, musíte mít správně nastaveno nahrávání z mikrofonu vevašem operačním systému, nainstalovanou Javu (verze 6 a vyšší) a nakonec je třeba nahrát dovašeho počítače soubor — Soubor zásad pro Javu.
8.4.2.1 Program SEDemo
Tento program umožňuje načítat soubory obsahující nahranou řeč a nebo umožní přímo sinahrát nějaký krátký řečový úsek promluvy. Hlavním účelem tohoto programu je demonstracealgoritmů „zvýrazňování řeči“, kde si může uživatel na základě grafických průběhů signálu(amplitudový průběh, spektrogram) pozorovat rozdíly mezi demonstrovanými algoritmy.
8.4.2.2 Program SCWP
Tento program demonstruje rozpoznávání řeči — hlasové ovládání WWW stránek— zobra-zení WWW stránky na základě hlasového vybrání hypertextového odkazu, zobrazení předchozístránky, posun stránky nahoru/dolu, simulace vytáčení telefonního čísla (výběr telefonního číslana základě jednotlivých číslovek).
KAPITOLA 8. USEABILITY TESTOVÁNÍ WEBOVÉ APLIKACE SEDEMO A SCWP 51
8.4.3 Seznam úkolů
8.4.3.1 Seznam úkolů — SEDemo
1. Chcete si nahrát seznam úkolů na zítřejší práci
(a) Spusťte program SEDemo.
(b) Nahrajte nějakou krátkou větu.
2. V nahraném signálu se Vám zdá, že obsahuje příliš šumu z okolí
3. Pokuste se vylepšit nahraný signál s pomocí zvýraznění řeči
(a) Nastavte filtr: Spektrální odečítání s jednocestným usměrněním VAD.
(b) Prozkoumejte spektrogram upraveného signálu.
(c) Přehrajte si upravený signál.
4. Rozhodl(a] jste se, že nahraný signál byl nahrán nekvalitně a proto ho nahrajete znovus lepšími nahrávacími podmínkami
(a) Změňte vzorkovací frekvenci nahrávaného signálu na 16000 Hz.
(b) Nahrajte nový úkol na zítřek.
(c) Zvýrazněte řeč s pomocí filtru Spektrální odečítání s dvoucestným usměrně-ním VAD.
(d) Do PC uložte upravený signál - úkol na zítřek.
8.4.3.2 Seznam úkolů — SCWP
VEŠKERÉ ÚKONY SE PROVÁDÍ POUZE HLASEM !!!
1. Chcete zavolat svému kolegovi(kolegyni) a zdělit mu(jí) zajímavé informace
(a) Hlasem zobrazte WWW stránku s telefonním přístrojem.
(b) Zadejte hlasem telefonní číslo: # 1 8 6 3
(c) Zadejte hlasem telefonní číslo: * 2 5 7 9 0
2. Chcete zjistit kontaktní informace o svém učiteli na Katedře teorie obvodů
(a) Zobrazte WWW stránku Katedry teorie obvodu.
(b) Zobrazte detaily o učiteli Ondřeji Konopkovi
(c) Zobrazte detaily o učiteli Hanžlovi
(d) Zobrazte detaily o učiteli Petrovi (Struhovský)
3. Chcete zatelefonovat svému kamarádovi Tomáši, zjistěte jeho telefonní číslo, poté vytočtejeho číslo a proberte s ním přípravu na další cvičení.
52 KAPITOLA 8. USEABILITY TESTOVÁNÍ WEBOVÉ APLIKACE SEDEMO A SCWP
8.4.4 Post-test
8.4.4.1 Post-test — SEDemo
1. Jak se Vám líbila webová aplikace SEDemo ?(Zakroužkujte svou volbu - číslo)
(velmi pěkná) 1 2 3 4 5 (hrozná)
2. Ovládání aplikace je:(Zakroužkujte svou volbu - číslo)
(jednoduché) 1 2 3 4 5 (složité)
3. Co by jste nejraději změnili a proč ?
4. Jaká část aplikace byla pro Vás složitá, nepřehledná a proč ?
8.4.4.2 Post-test — SCWP
1. Jak se Vám líbilo hlasové ovládání WWW stránek ?(Zakroužkujte svou volbu - číslo)
(velmi pěkné) 1 2 3 4 5 (hrozné)
2. Ovládání je:(Zakroužkujte svou volbu - číslo)
(jednoduché) 1 2 3 4 5 (složité)
3. Co by jste nejraději změnili a proč ?
4. Jaká část aplikace byla pro Vás složitá, nepřehledná a proč ?
KAPITOLA 8. USEABILITY TESTOVÁNÍ WEBOVÉ APLIKACE SEDEMO A SCWP 53
8.5 Hardwarové vybavení
Kvůli testování, že dané programy jsou nezávislé na operačním systému a WWW prohlížeči,tak testování probíhalo na těchto počítačích:
1. varianta:
PC: Athlon 1GHz, 758MB RAM
OS: Linux (Gentoo)
WWW prohlížeč: Mozilla Firefox 2.0.0.11
2. varianta:
PC: Pentium III, 512MB RAM
OS: Windows XP Home
WWW prohlížeč: Mozilla Firefox 2.0.0.11
3. Informace o mikrofonu: (Media microphone series, Maxxtro)
Directivity omni-directional
Frequency response 20 – 16 kHz
Impedance 600 Ω
Sensitivity −60 db ± 3 db
Cord length 6ft
8.6 Vypracované testy
Vyplněné testy od testovaných osob se nachází v příloze B na straně 63.
8.7 Závěr
Testovaní uživatelé měly nejčastěji tyto problémy s testovanými programy a nebo se jim(ne)líbilo:
• Program SEDemo:
– Chybí informace, že se skutečně nahrává z mikrofonu.
Obrázek 8.1: Useability test - nahrávání řeči
– V některých stavech programu nejednoznačná možnost přehrávání výstupního pro-gramu.
54 KAPITOLA 8. USEABILITY TESTOVÁNÍ WEBOVÉ APLIKACE SEDEMO A SCWP
– Nepřehledné menu.
– Občas problémy během přehrávání — zpomalení celého systému.
– Nižší kvalita ovládacích ikon, ikony znázorňující zvětšení/snížení detailů nejsou ná-zorné.
Obrázek 8.2: Useability test - ovládací panel ikon
• Program SCWP:
– Chybí možnost vybrat znak # s pomocí slova „křížek“.
– Pokud se hlasem vytáčela čísla hodně pomalu, tak často docházelo k chybě — buďse zobrazila úplně jiná číslice a nebo před správnou číslicí se objevila navíc špatnáčíslice.
– Častým problémem bylo se dostat pryč ze stránek, kde se demonstrovalo hlasovévytáčení — problém s příkazem „zpět“, která se vyhodnotilo jako číslovka 5 (pět).
– Uživatelé často začali říkat hlasový povel dříve (v „inicializační“ části rozpoznávače)než měli (správné je říkat příkaz ve fázi „Očekávám příkaz“).
– Když se rychle za sebou zadávaly příkazy a pak se změnila WWW stránka, tak došlok „zamrznutí“ programu — inicializační část nikdy neskončila.
KAPITOLA 9. ZÁVĚR 55
9 Závěr
V rámci diplomové práce jsem se seznámil s problematikou zvýrazňování a rozpoznávání řeči,kterou jsem demonstroval vytvořením programům, které se zabývají demonstrací zvýrazňovánía rozpoznávání řeči. Vytvořil jsem multiplatformní programy — aplety, které jsou nezávislé naoperační systému a jsou nabízeny širokému okruhu uživatelů s pomocí WWW prohlížeče. Vzhle-dem k tomu, že oba programy používají ke své správné činnosti i programy třetích stran, kteréjsou licenčně omezeny, byl jsem nucen navrhnout programy s architekturou klient – server, kdeuživatel v klientské části nahrává daná signál, který je poté odeslán na server, kde je zpracován— proběhne zvýraznění řeči či rozpoznání hlasové promluvy, a výsledek je vrácen klientovi, kdeje dále zpracován. Server je navržen tak, aby byl schopen obsloužit požadavky několika klientůnajednou — jakmile server naváže s pojení s klientem, tak vytvoří nový samostatný proces,který obslouží daného klienta.
Hlavní výsledky mé práce lze shrnout v následujících bodech:
• Vytvořil jsem programy — aplety, které jsou nezávislé na daném operačním systému ajsou poskytovány uživatelům s pomocí WWW prohlížeče.
• Vytvořil jsem klientskou a serverovou část, která umožňuje přenos nahraného audiosignálupo internetu. Server je schopen obsloužit několik klientů najednou.
• Vytvořil jsem program SEDemo, který umožňuje demonstraci zvýraznění řeči v akustic-kém signálu. Hlavní činností programu je vizualizace vstupního (nahraného/načteného)signálu a výstupního (po zvýraznění řeči) signálu s pomocí časových průběhů a spek-trogramu. Vlastní zvýraznění řeči se provádí na serveru s pomocí spouštění externíhoproduktu třetí strany.
• Vytvořil jsem program SCWP, který demonstruje rozpoznávání řeči — umožňuje hla-sové ovládání WWW stránek: pohyb WWW stránky nahoru/dolu, aby se zobrazil skrytýtext, pohyb vpřed/vzad v historii WWW stránek, zobrazování nových WWW stránek nazákladě hlasového výběru hypertextového odkazu. Součástí demonstrace je simulace hla-sového vytáčení telefonního čísla. Vlastní rozpoznání mluvené řeči se provádí na serverus pomocí spouštění externího produktu třetí strany.
• V programu SCWP, jsem vytvořil výkonový detektor řečové aktivity, který umožňujevýhradně hlasové ovládání WWW stránek.
• Provedl jsem uživatelské testy programů SEDemo a SCWP s pomocí skupiny testovanýchuživatelů. Tyto testy slouží k nalezení možných chyb a ke zlepšení celkové použitelnostiprogramů pro široký okruh uživatelů.
Vytvořil jsem programy, které demonstrují základní algoritmy pro zvýrazňování a rozpo-znávání řeči. Programy jsem se snažil vytvářet tak, aby šly dále rozšiřovat pomocí přidanýchmodulů. V další fázi vývoje programů by se mohly programy rozšířit o další pokročilé algoritmyzvýrazňování a rozpoznávání řeči. Také bude třeba opravit chyby, které byly nalezeny s pomocíuživatelských testů. Tyto demonstrační programy jsou umístěné na WWWW stránkách [18].
56 KAPITOLA 9. ZÁVĚR
KAPITOLA 10. LITERATURA 57
10 Literatura
[1] Jan Uhlíř - kol.: Technologie hlasových komunikací, Nakladatelství ČVUT, 2007.
[2] Josef Psutka - kol.: Mluvíme s počítačem česky, Academia, Praha, 2006.
[3] Young, S. - al.: The HTK Book (for HTK Version 3.4), Cambridge University EngineeringDepartment, Cambridge, GB, 2006.
[5] http://java.sun.com/docs/books/tutorial/deployment/applet/index.html: The Java Tuto-rials - Applets.
[6] [příloha CD] Dokumentace popisující činnost programu SEDemo vytvořená s pomocí Ja-vadoc: /javadoc/sedemo/.
[7] [příloha CD] Dokumentace popisující činnost programu SCWP vytvořená s pomocí Java-doc: /javadoc/scwp/.
[8] Michael C. Daconta: When Runtime.exec() won’t - Navigate yourself around pitfallsrelated to the Runtime.exec() method, JavaWorld.com (http://www.javaworld.com/javaworld/jw-12-2000/jw-1229-traps.html), 2000.
[9] The Hidden Markov Model Toolkit (HTK): http://htk.eng.cam.ac.uk/download.shtml
[10] CtuCopy - univerzální nástroj pro zvýrazňování řeči a parametrizaci:http://noel.feld.cvut.cz/speechlab/start.php?page=download&lang=cz, Petr Fousek,2006
[11] Petr Fousek, Petr Pollák : Additive Noise and Channel Distortion-Robust ParametrizationTool - Performance Evaluation on Aurora 2 & 3, EUROSPEECH 2003 [CD-ROM], Berlin:ESCA, 2003, vol. 1, s. 63. ISSN 1018-4074.
[12] Jan Janeček - kol.: Distribuované systémy - cvičení, Vydavatelství ČVUT, 2002.
[13] Ian F. Darwin: Java - kuchařka programátora, Computer Press, Brno, 2006.
[14] Craig A. Lindley: Digital Audio with Java, Prentice Hall, 2000
[15] https://javahelp.dev.java.net/ : The JavaHelp system online help system.
[16] http://java.sun.com/products/java-media/jmf/ : The Java Media Framework API (JMF)enables audio, video and other time-based media to be added to Java applications andapplets.
[17] Josef Rajnoha: Rozpoznávání řeči v reálných podmínkách na platformě standardního PC,diplomová práce, 2006.
[18] http://noel.feld.cvut.cz/speechlab/start.php?page=demos&lang=cz&sub=sedemo : De-monstrace zvýrazňování a rozpoznávání řeči, Milan Václavík, 2008.
58 KAPITOLA 10. LITERATURA
PŘÍLOHA A. UŽIVATELSKÁ PŘÍRUČKA 59
A Uživatelská příručka
A.1 SEDemo
Obrázek A.1: Program SEDemo
Program SEDemo (na obrázku A.1) slouží k demonstraci zvýrazňování řeči. Ke správnéčinnosti programu musejí být splněny tyto podmínky:
A.1.1 Nezbytné nastavení
• V domovském adresáři uživatele musí existovat soubor zásad zabezpečení pro spouš-tění apletu. (viz. kapitola 7.3.1).
• K lokálnímu počítači musí být připojen mikrofon, který je správně nastaven.
• Žádné zařízení v lokálním počítači nesmí přistupovat ke zvukové kartě, ke které je připojenmikrofon (nesmí se přehrávat žádný zvuk, nahrávat data z mikrofonu a podobně) po dobupoužívání programu SCWP.
• Zapnuté a funkční připojení k internetu.
• Nainstalovanou verzi Java JRE (SDK) 1.6 (6) a vyšší.
• WWW prohlížeč musí mít zapnutou podporu Javy.
A.1.2 Popis ovládání
Program SEDemo se skládá z několika částí, které lze vidět na obrázku A.2.
část 1. Hlavní ovládací menu — umožňuje načítat/ukládat audiosignál, přehrávání/nahráváníaudiosignálu, zobrazuje různé grafické průběhy vstupního a výstupního audiosignálu, na-stavuje nahrávací vlastnosti mikrofonu, vybírá algoritmy pro zvýraznění řeči, umí změnit
60 PŘÍLOHA A. UŽIVATELSKÁ PŘÍRUČKA
Obrázek A.2: Popis program SEDemo
lokalizaci programu (česká – anglická), obsahuje integrovanou nápovědu k celému pro-gramu.
část 2. Ovládací panel tlačítek programu, která umožňují: ukládání vstupního nebo výstup-ního audiosignálu, načtení vstupního signálu, nahrávání signálu z mikrofonu, přehrávánívstupního a výstupního signálu, pozastavení a ukončení přehrávání signálu. Poslední třiikony slouží zoomování grafických průběhů: zvětšení, zmenšení a zobrazení celého průběhuv okně.
část 3. Místo pro zobrazení grafických průběhů. Podle přání uživatele se v okně zobrazí buďjeden průběh a nebo dva průběhy. Program umožňuje zobrazovat vždy jen jedno oknos grafickým průběhem signálu. Po nahrávání z mikrofonu nebo načtení audiosignálu zesouboru se vždy automaticky zobrazí grafický průběh: Vstupní signál a vstupní spektro-gram. Pokud s program nedokáže spojit se serverem, aby mohl zobrazit spektrogram, takse zobrazí pouze grafický průběh: Vstupní signál.
část 4. Zobrazený vstupní signál.
část 5. Zobrazený spektrogram vstupního signálu.
část 6. Informační panel, který zobrazuje aktuální informace o zobrazeném signálu: vzorkovacífrekvenci audiosignálu, použitý algoritmus zvýraznění řeči, počet zobrazených segmentůa pásem spektrogramu (celkový počet na zobrazeném průběhu, interval právě zobraze-ných segmentů), počet kanálů zobrazeného audiosignálu (program pracuje pouze s monosignály, pokud se načte stereo signál, tak dojde ke konverzi na mono), zobrazený časovýúsek celého zobrazeného průběhu a časy na jednotlivých krajích zobrazeného průběhusignálu.
PŘÍLOHA A. UŽIVATELSKÁ PŘÍRUČKA 61
A.2 SCWP
Program SCWP je sada navzájem spolupracujících apletů, které umožňují hlasové ovládáníWWW stránek. Ke správné činnosti programů musejí být splněny tyto podmínky:
A.2.1 Nezbytné nastavení
• V domovském adresáři uživatele musí existovat soubor zásad zabezpečení pro spouš-tění apletu. (viz. kapitola 7.3.1).
• K lokálnímu počítači musí být připojen mikrofon, který je správně nastaven.
• Žádné zařízení v lokálním počítači nesmí přistupovat ke zvukové kartě, ke které je připojenmikrofon (nesmí se přehrávat žádný zvuk, nahrávat data z mikrofonu a podobně) po dobupoužívání programu SCWP.
• Zapnuté a funkční připojení k internetu.
• Nainstalovanou verzi Java JRE (SDK) 1.6 (6) a vyšší.
• WWW prohlížeč musí mít zapnutou podporu Javy a JavaScriptu.
A.2.2 Popis ovládání
Hlasové ovládání je demonstrováno na:
• Ovládání samotné WWW stránky:
Hlasový příkaz Akce
dolu Posun WWW stránky nahoru.nahoru Posun WWW stránky dolu.vpřed Posun vpřed v historii zobrazených WWW stránek.zpět Posun vzad v historii zobrazených WWW stránek.
hypertextový odkaz Zobrazí WWW stránku, na kterou ukazuje hypertextový odkaz.
Tabulka A.1: Hlasové ovládání WWW stránky
• Hlasový výběr hypertextových odkazů. K vybrání hypertextového odkazu je třeba řícicelý hypertextový odkaz. Pouze skládá-li se hypertextový odkaz ze jména a příjmení, takdaný hypertextový odkaz lze vybrat s pomocí jména, příjmení, jména a příjmení, příjmenía jména.
• Simulace hlasového vytáčení telefonního čísla. Pod zobrazeným telefonním přístrojem senachází „displej“, který zobrazuje právě vytočené telefonní číslo. Telefonní číslo se zadávácelé najednou po jednotlivých číslicích ! Každé nově zadané číslo přemaže hodnotu nadispleji. Telefonní číslo se může skládat z číslovek 0 - 9 a ze znaků * (hvězdička) a #(mřížka, hash). Telefonní číslo se může skládat z maximálně 12 znaků.
Na každé WWW stránce, na které se demonstruje hlasové ovládání se nachází v pravémhorním rohu aplet „hlasového ovládání“. V tomto apletu se zobrazuje stav „rozpoznávače“ aposlední hlasový příkaz. Po každém zobrazení WWW stránky dojde k automatickému rozpo-znávání hlasového příkazu (automatické nahrávání řeči mikrofonem). Toto nahrávání — rozpo-znávání hlasového příkazu lze kdykoliv ukončit kliknutím myši na zobrazený stav rozpoznávače.Opětovným kliknutím se spustí rozpoznávání hlasového povelu.
62 PŘÍLOHA A. UŽIVATELSKÁ PŘÍRUČKA
Následující tabulka A.2 zobrazuje možné stavy rozpoznávače, které jsou označeny textovýmpopisem a různým barevným pozadím.
Popis Barva Význam
Rozpoznávač vypnut Modrá Rozpoznávač je vypnut — hlasové ovládání nefunguje.Inicializace Červená Inicializace rozpoznávače, nastavuje se práh citlivosti.
Tento práh určuje od jaké intenzity hlasitosti nahra-ného signálu bude detektor řeči indikovat platnou řečnebo ticho (pauzu).
Očekávám příkaz Zelená Detektor řeči nezaznamenal žádnou řeč.Detekována řeč Zelená Detektor řeči zaznamenal řeč.
Rozpoznávám příkaz Červená Rozpoznávač rozpoznává hlasový povel, po rozpoznánípříkazu provede odpovídající činnost. V této fázi jenahrávání z mikrofonu vypnuto
Tabulka A.2: Stavy apletu hlasového vstupu
Hlasový příkaz je třeba zadávat pouze ve stavu rozpoznávače Očekávám příkaz (zelenábarva pozadí). Pokud se začne mluvit v jiné stavu, tak hlasový povel nebude zaznamenán celýa nedojde k jeho správnému rozpoznání.
Pokud se začne mluvit ve fázi inicializace, tak se nastaví příliš vysoká mez pro detekci řeči,poté bude třeba říci hlasový příkaz mnohem více nahlas, jinak detektor nezaznamená hlasovýpovel.
Pokud detektor řeči detekuje řeč, aniž by došlo ke skutečné promluvě, lze ve fázi Detekovánařeč (zelené pozadí) říci požadovaný příkaz, jelikož hlasový příkaz zastíní šum, na který reagovaldetektor řeči.
Detektor řeči umožňuje zadat hlasový povel o maximální době 10 sekund. Poté se ukončínahrávání příkazu a začne se vyhodnocovat zadaný hlasový příkaz.
Jednotlivé změny stavu rozpoznávače řeči se neprovádí okamžitě, ale s menší prodlevou.Správnost rozpoznání hlasového příkazu také závisí na nastavení mikrofonu. Je-li u mik-
rofonu nastavená příliš nízká citlivost nahrávání, tak detektor řeči bude špatně detekovat řeč.Bude-li nastavena příliš vysoká citlivost řeči, tak detektor řeči bude detekovat řeč při každémsebemenším zvuku — rozpoznávač pak budete rozpoznávat šum nebo dojde k velikému zkreslenínahrané řeči, která bude přebuzená a rozpoznávač rozpozná špatný příkaz.
PŘÍLOHA B. VYPRACOVANÉ USEABILITY TESTY 63
B Vypracované useability testy
B.1 Vyplněné testy od 1. uživatele
B.1.1 Dotazník
1. Používáte počítač
[ ] nikdy, nikde
[X ] doma
[ ] v práci
[X ] ve škole
[ ] jinde, kde ? . . . . . . . . .
2. Jak dlouho počítač používáte? 10 let
3. Kolik času u počítače strávíte?
[ ] méně než hodinu týdně
[ ] hodinu až pět hodin týdně
[X ] hodinu až pět hodin denně
[ ] více než pět hodin denně
4. Za jakým účelem PC používáte?
[ ] programování
[X ] přístup k internetu/emailu
[X ] kancelářská práce (psaní dokumentů)
[X ] hraní her
[X ] používání multimediálních programů
[ ] jiný, jaký ? . . . . . . . . .
5. Chtěl by jste mít možnost ovládat PC hlasem ?
[X ] ano
[ ] ne
6. Měl byste zájem zúčastnit se testování internetové aplikace
[X ] ano
[ ] ne
7. Který den v týdnu a v kolik hodin máte čas ? (test může trvat 20. . .30 minut)
[ ] pondělí, čas . . . . . . . . .
[ ] úterý, čas . . . . . . . . .
[ ] středa, čas . . . . . . . . .
[ ] čtvrtek, čas . . . . . . . . .
[ ] pátek, čas . . . . . . . . .
[X ] sobota, čas 16:30
[ ] neděle, čas . . . . . . . . .
64 PŘÍLOHA B. VYPRACOVANÉ USEABILITY TESTY
B.1.2 Post-test
B.1.2.1 Post-test — SEDemo
1. Jak se Vám líbila webová aplikace SEDemo ?(Zakroužkujte svou volbu - číslo)
(velmi pěkná) 1 2 3 4 5 (hrozná)
2. Ovládání aplikace je:(Zakroužkujte svou volbu - číslo)
(jednoduché) 1 2 3 4 5 (složité)
3. Co by jste nejraději změnil a proč ?Grafika — nízká kvalita ovládacích ikon.Pomalé vykreslování (menu — položek menu).
4. Jaká část aplikace byla pro Vás složitá, nepřehledná a proč ?
B.1.2.2 Post-test — SCWP
1. Jak se Vám líbilo hlasové ovládání WWW stránek ?(Zakroužkujte svou volbu - číslo)
(velmi pěkné) 1 2 3 4 5 (hrozné)
2. Ovládání je:(Zakroužkujte svou volbu - číslo)
(jednoduché) 1 2 3 4 5 (složité)
3. Co by jste nejraději změnil a proč ?Ne vždy 100% úspěšnost při vytáčení čísel.Potíže při vrácení WWW stránky „zpět“ na stránce s telefonem.Potíže se zobrazením informací o osobě „Jan“.
4. Jaká část aplikace byla pro Vás složitá, nepřehledná a proč ?
PŘÍLOHA B. VYPRACOVANÉ USEABILITY TESTY 65
B.2 Vyplněné testy od 2. uživatele
B.2.1 Dotazník
1. Používáte počítač
[ ] nikdy, nikde
[X ] doma
[X ] v práci
[X ] ve škole
[ ] jinde, kde ? . . . . . . . . .
2. Jak dlouho počítač používáte? 15 let
3. Kolik času u počítače strávíte?
[ ] méně než hodinu týdně
[X ] hodinu až pět hodin týdně
[ ] hodinu až pět hodin denně
[ ] více než pět hodin denně
4. Za jakým účelem PC používáte?
[ ] programování
[X ] přístup k internetu/emailu
[X ] kancelářská práce (psaní dokumentů)
[X ] hraní her
[X ] používání multimediálních programů
[ ] jiný, jaký ? . . . . . . . . .
5. Chtěl by jste mít možnost ovládat PC hlasem ?
[X ] ano
[ ] ne
6. Měl byste zájem zúčastnit se testování internetové aplikace
[X ] ano
[ ] ne
7. Který den v týdnu a v kolik hodin máte čas ? (test může trvat 20. . .30 minut)
[X ] pondělí, čas 14:50
[ ] úterý, čas . . . . . . . . .
[ ] středa, čas . . . . . . . . .
[ ] čtvrtek, čas . . . . . . . . .
[ ] pátek, čas . . . . . . . . .
[ ] sobota, čas . . . . . . . . .
[ ] neděle, čas . . . . . . . . .
66 PŘÍLOHA B. VYPRACOVANÉ USEABILITY TESTY
B.2.2 Post-test
B.2.2.1 Post-test — SEDemo
1. Jak se Vám líbila webová aplikace SEDemo ?(Zakroužkujte svou volbu - číslo)
(velmi pěkná) 1 2 3 4 5 (hrozná)
2. Ovládání aplikace je:(Zakroužkujte svou volbu - číslo)
(jednoduché) 1 2 3 4 5 (složité)
3. Co by jste nejraději změnil a proč ?Nepřehledné menu.
4. Jaká část aplikace byla pro Vás složitá, nepřehledná a proč ?viz. bod 3.
B.2.2.2 Post-test — SCWP
1. Jak se Vám líbilo hlasové ovládání WWW stránek ?(Zakroužkujte svou volbu - číslo)
(velmi pěkné) 1 2 3 4 5 (hrozné)
2. Ovládání je:(Zakroužkujte svou volbu - číslo)
(jednoduché) 1 2 3 4 5 (složité)
3. Co by jste nejraději změnil a proč ?Potíže při vrácení WWW stránky „zpět“ na stránce s telefonem, častá záměna s číslem 5.
4. Jaká část aplikace byla pro Vás složitá, nepřehledná a proč ?
PŘÍLOHA B. VYPRACOVANÉ USEABILITY TESTY 67
B.3 Vyplněné testy od 3. uživatele
B.3.1 Dotazník
1. Používáte počítač
[ ] nikdy, nikde
[X ] doma
[X ] v práci
[ ] ve škole
[ ] jinde, kde ? . . . . . . . . .
2. Jak dlouho počítač používáte? 3 roky
3. Kolik času u počítače strávíte?
[ ] méně než hodinu týdně
[X ] hodinu až pět hodin týdně
[ ] hodinu až pět hodin denně
[ ] více než pět hodin denně
4. Za jakým účelem PC používáte?
[ ] programování
[ ] přístup k internetu/emailu
[X ] kancelářská práce (psaní dokumentů)
[ ] hraní her
[ ] používání multimediálních programů
[ ] jiný, jaký ? . . . . . . . . .
5. Chtěl by jste mít možnost ovládat PC hlasem ?
[X ] ano
[ ] ne
6. Měl byste zájem zúčastnit se testování internetové aplikace
[X ] ano
[ ] ne
7. Který den v týdnu a v kolik hodin máte čas ? (test může trvat 20. . .30 minut)
[X ] pondělí, čas 15:40
[ ] úterý, čas . . . . . . . . .
[ ] středa, čas . . . . . . . . .
[ ] čtvrtek, čas . . . . . . . . .
[ ] pátek, čas . . . . . . . . .
[ ] sobota, čas . . . . . . . . .
[ ] neděle, čas . . . . . . . . .
68 PŘÍLOHA B. VYPRACOVANÉ USEABILITY TESTY
B.3.2 Post-test
B.3.2.1 Post-test — SEDemo
1. Jak se Vám líbila webová aplikace SEDemo ?(Zakroužkujte svou volbu - číslo)
(velmi pěkná) 1 2 3 4 5 (hrozná)
2. Ovládání aplikace je:(Zakroužkujte svou volbu - číslo)
(jednoduché) 1 2 3 4 5 (složité)
3. Co by jste nejraději změnil a proč ?Jiná ikona lupy — současná je nevýrazná, nic neříkající.
4. Jaká část aplikace byla pro Vás složitá, nepřehledná a proč ?Zvětšování grafických průběhů.
B.3.2.2 Post-test — SCWP
1. Jak se Vám líbilo hlasové ovládání WWW stránek ?(Zakroužkujte svou volbu - číslo)
(velmi pěkné) 1 2 3 4 5 (hrozné)
2. Ovládání je:(Zakroužkujte svou volbu - číslo)
(jednoduché) 1 2 3 4 5 (složité)
3. Co by jste nejraději změnil a proč ?Potíže při vrácení WWW stránky „zpět“ na stránce s telefonem.Rychlost — dlouho to trvá, než se provede nějaký příkaz“.
4. Jaká část aplikace byla pro Vás složitá, nepřehledná a proč ?
PŘÍLOHA B. VYPRACOVANÉ USEABILITY TESTY 69
B.4 Vyplněné testy od 4. uživatele
B.4.1 Dotazník
1. Používáte počítač
[ ] nikdy, nikde
[X ] doma
[X ] v práci
[X ] ve škole
[ ] jinde, kde ? . . . . . . . . .
2. Jak dlouho počítač používáte? 17 let
3. Kolik času u počítače strávíte?
[ ] méně než hodinu týdně
[ ] hodinu až pět hodin týdně
[ ] hodinu až pět hodin denně
[X ] více než pět hodin denně
4. Za jakým účelem PC používáte?
[X ] programování
[X ] přístup k internetu/emailu
[X ] kancelářská práce (psaní dokumentů)
[X ] hraní her
[X ] používání multimediálních programů
[ ] jiný, jaký ? . . . . . . . . .
5. Chtěl by jste mít možnost ovládat PC hlasem ?
[X ] ano
[ ] ne
6. Měl byste zájem zúčastnit se testování internetové aplikace
[X ] ano
[ ] ne
7. Který den v týdnu a v kolik hodin máte čas ? (test může trvat 20. . .30 minut)
[ ] pondělí, čas . . . . . . . . .
[X ] úterý, čas 16:30
[ ] středa, čas . . . . . . . . .
[ ] čtvrtek, čas . . . . . . . . .
[ ] pátek, čas . . . . . . . . .
[ ] sobota, čas . . . . . . . . .
[ ] neděle, čas . . . . . . . . .
70 PŘÍLOHA B. VYPRACOVANÉ USEABILITY TESTY
B.4.2 Post-test
B.4.2.1 Post-test — SEDemo
1. Jak se Vám líbila webová aplikace SEDemo ?(Zakroužkujte svou volbu - číslo)
(velmi pěkná) 1 2 3 4 5 (hrozná)
2. Ovládání aplikace je:(Zakroužkujte svou volbu - číslo)
(jednoduché) 1 2 3 4 5 (složité)
3. Co by jste nejraději změnil a proč ?Občas problémy během přehrávání — zpomalení celého systému.Nejednoznačná možnost přehrávání výstupního signálu.
4. Jaká část aplikace byla pro Vás složitá, nepřehledná a proč ?Přehrávání výstupního signálu — viz bod 3.
B.4.2.2 Post-test — SCWP
1. Jak se Vám líbilo hlasové ovládání WWW stránek ?(Zakroužkujte svou volbu - číslo)
(velmi pěkné) 1 2 3 4 5 (hrozné)
2. Ovládání je:(Zakroužkujte svou volbu - číslo)
(jednoduché) 1 2 3 4 5 (složité)
3. Co by jste nejraději změnil a proč ?Občasné „zamrznutí prohlížeče“.
4. Jaká část aplikace byla pro Vás složitá, nepřehledná a proč ?
PŘÍLOHA C. OBSAH PŘILOŽENÉHO CD 71
C Obsah přiloženého CD
/javadoc/* Tento adresář obsahuje vygenerovanou dokumentaci, programů SEDemo a SCWP,s pomocí programu javadoc. Tato dokumentace dokumentuje zdrojové kódy programů.
/klient/* Tento adresář obsahuje binární kódy programů SEDemo a SCWP spolu s dopl-ňujícími soubory, které se nahrají na webový server — vytvářejí demonstrační WWWstránky, na kterých je předvedena činnost těchto apletů.
/scwp/* Zdrojové soubory programu SCWP.
/sedemo/* Zdrojové soubory programu SEDemo.
/server/* Tento adresář obsahuje instalační soubory serveru SEDemo a SCWP, které se na-hrají na webový server. Tyto adresáře obsahují konfiguračních soubory pro činnost exter-ních programů.
/text/* Tento adresář obsahuje text diplomové práce uložený v PDF souboru.
install.txt Tento soubor obsahuje návod pro instalaci programů SEDemo a SCWP.
readme.txt Tento soubor obsahuje popis ovládání programů SEDemo a SCWP. Také obsahujepodrobnější popis jednotlivých souborů na přiloženém CD.































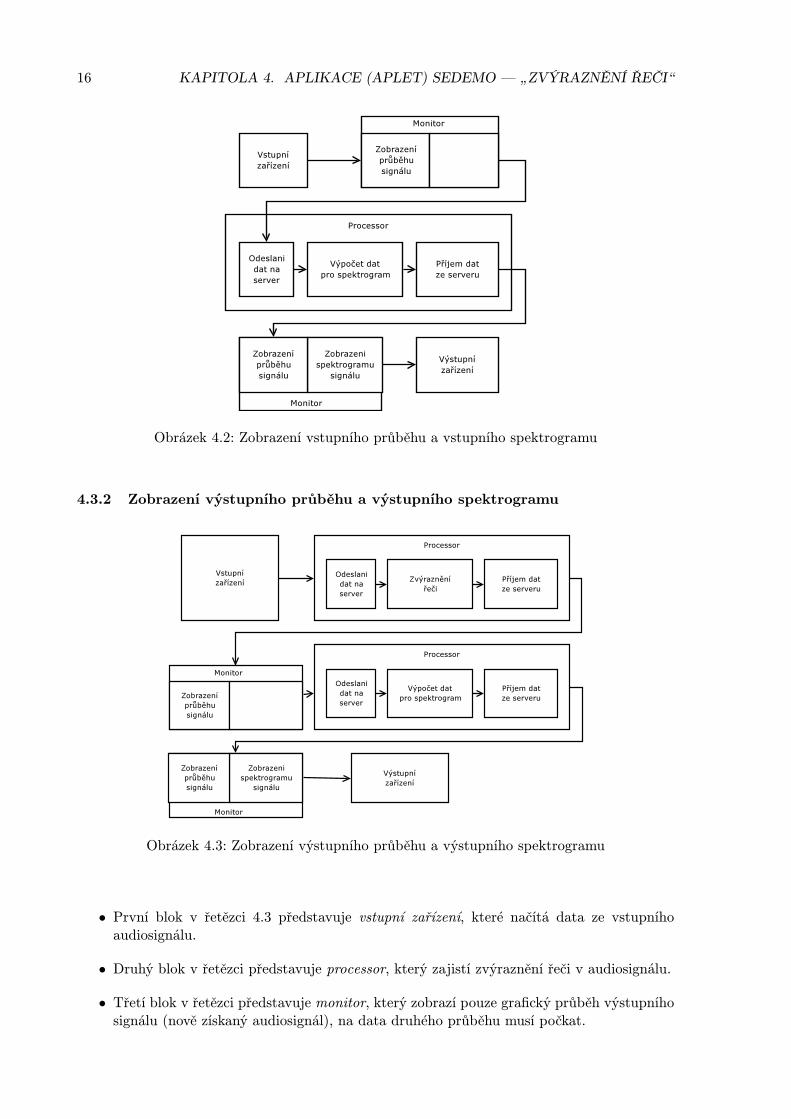


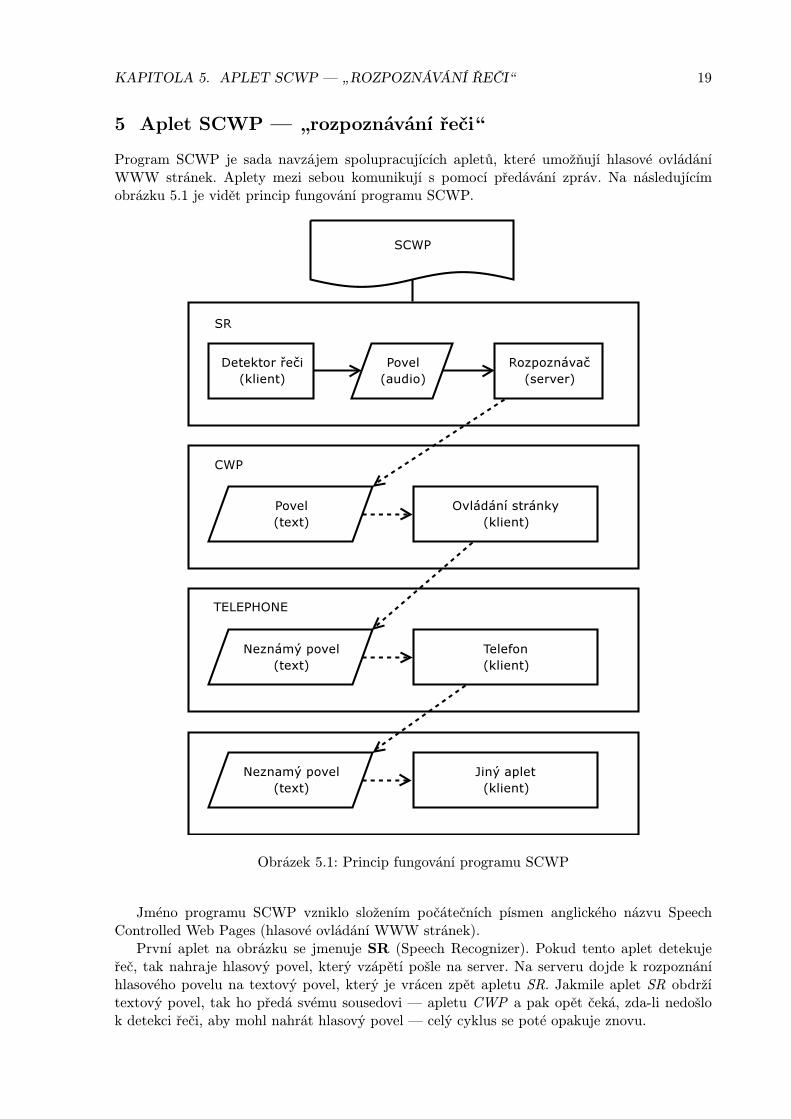

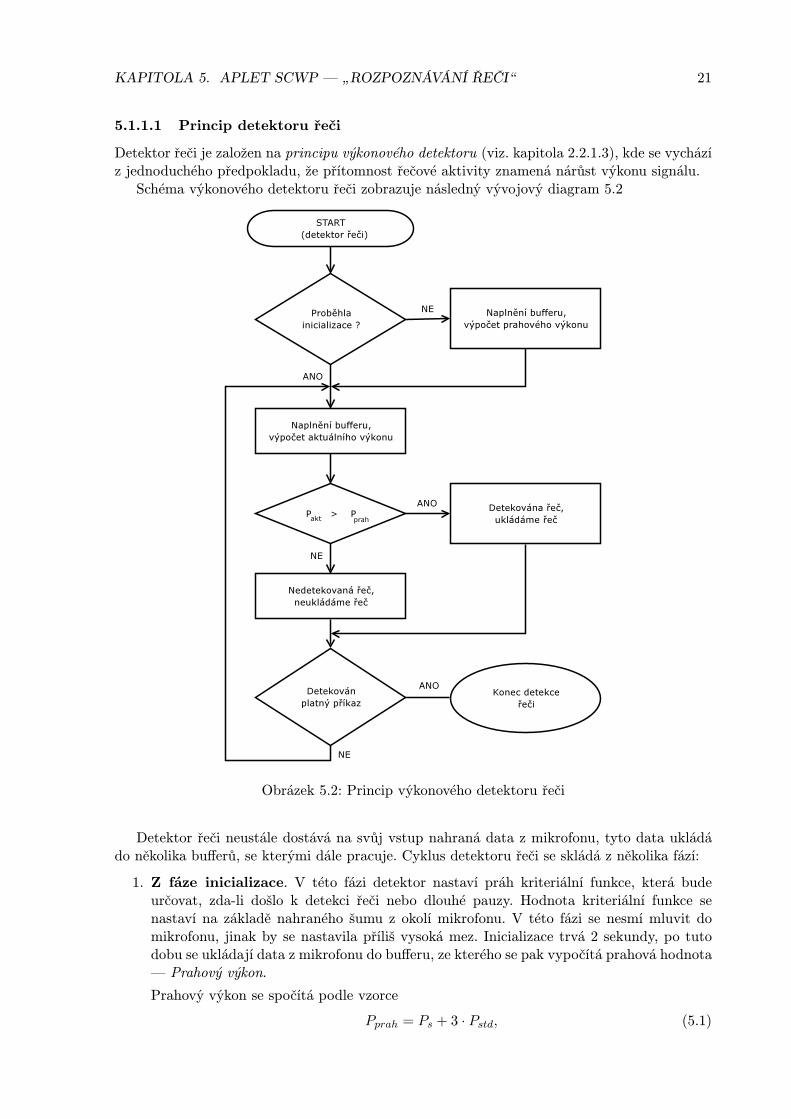









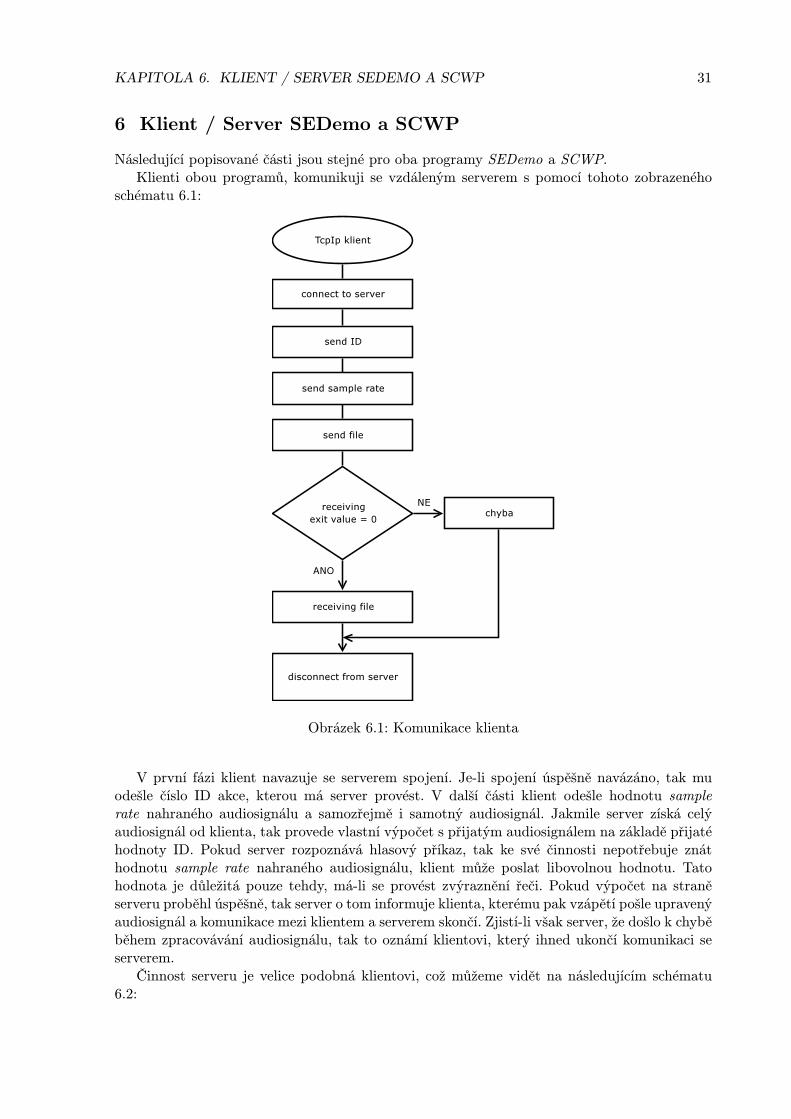



























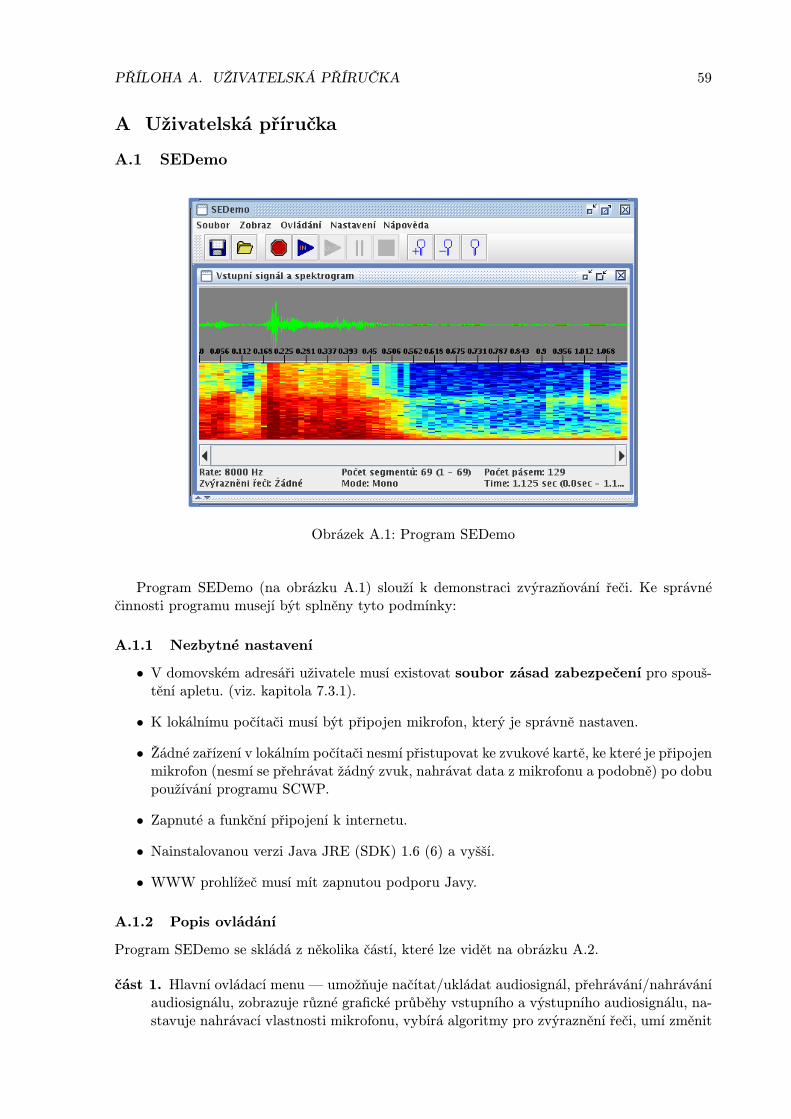
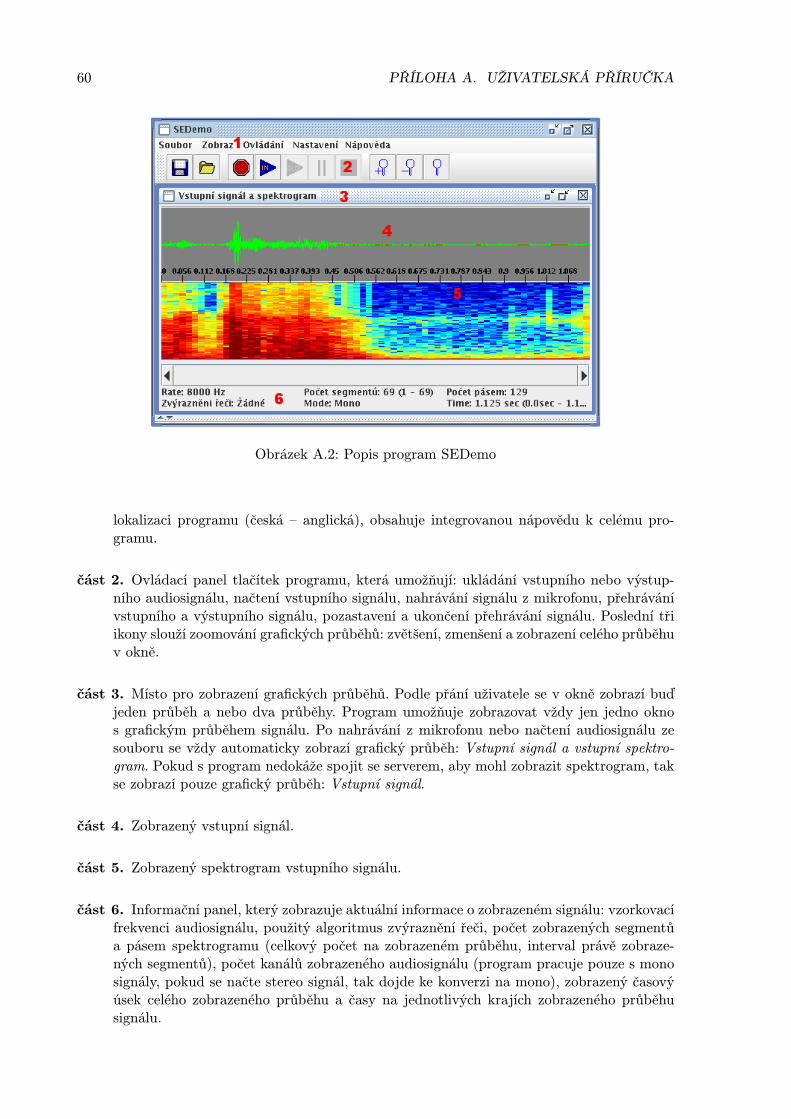

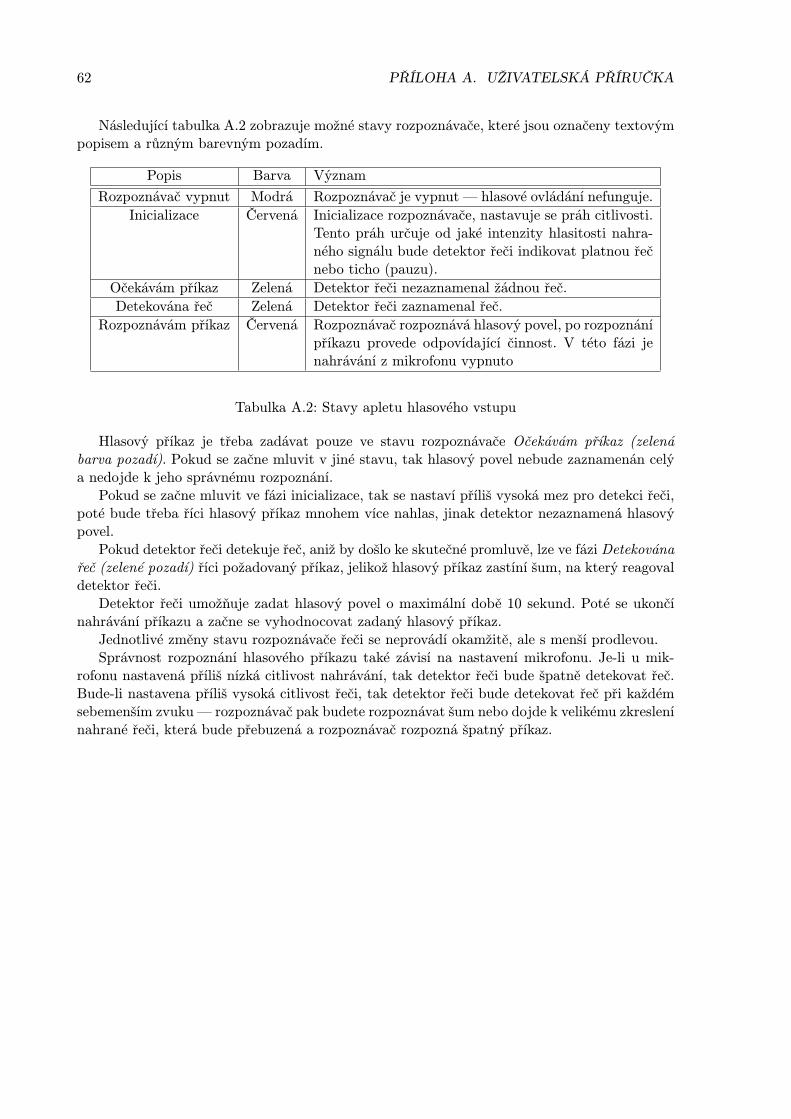













![VYSOKE´ UCˇENI´ TECHNICKE´ V BRNEˇ · API API4, neboli rozhraní pro programovÆní aplikací, je sada rutin, protokolø a nÆstrojø pro tvorbu softwarových aplikací.[2] 1HyperText](https://static.dokumenty.site/doc/80x56/5e91dd7b3b852f6cc01e09d3/vysoke-uceni-technicke-v-brne-api-api4-neboli-rozhran-pro-programovn.jpg)







![Popis importního rozhraní systému RealBonusimport.realbonus.cz/RealBonus_import_dokumentace.pdf · Popis importního rozhraní systému RealBonus.cz Stránka 14 z 27 [seznam-fotek]](https://static.dokumenty.site/doc/80x56/605895b539d2923fad01e73e/popis-importnho-rozhran-systmu-popis-importnho-rozhran-systmu-realbonuscz.jpg)




![SemestrÆlní prÆce KIV/MHSlobaz/mhs/semestralky/2012/Jirkovsky/... · 2012-07-15 · systØmem GNU/Linux. Pro nìkterØ algoritmy zpracovÆní obrazu jsem vyu¾il knihovnu OpenCV[10].](https://static.dokumenty.site/doc/80x56/5f8013fe0555aa1f0e4bc224/semestrln-prce-kiv-lobazmhssemestralky2012jirkovsky-2012-07-15.jpg)