ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZE Fakulta elektrotechnická GAČR 102/02/0124 „Hlasové technologie v podpoře informační společnosti Souhrnný přehled aktivit řešitelských kolektivů Editoři sborníku Prof. Ing. Pavel Sovka, CSc. Doc. Ing. Petr Pollák, CSc. 16. února 2004
Transcript
ČESKÉ VYSOKÉ UČENÍ TECHNICKÉ V PRAZEFakulta elektrotechnická
GAČR 102/02/0124„Hlasové technologie v podpoře
informační společnostiÿ
Souhrnný přehled aktivit řešitelskýchkolektivů
Editoři sborníkuProf. Ing. Pavel Sovka, CSc.Doc. Ing. Petr Pollák, CSc.
16. února 2004
GAČR 102/02/0124„Hlasové technologie v podpoře informační společnostiÿSouhrnný přehled aktivit řešitelských kolektivů
Editoři:Prof. Ing. Pavel Sovka, CSc.Doc. Ing. Petr Pollák, CSc.
Laboratoř zpracování řeči a analýzy signálůČeské vysoké učení technické v PrazeFakulta elektrotechnická, Katedra teorie obvodůTechnická 2, 166 27 Praha 6 - Dejvice
http://noel.feld.cvut.cz/speechlab
Poděkování:Tato publikace vznikla za podpory grantu GAČR 102/02/0124 „Hlasové technologie vpodpoře informační společnostiÿ.
vydalo nakladatelství ČVUT, Zikova 4, 166 36 Praha 6, v únoru 2004
ISBN: 80-1-XXXXX-X
OBSAH 1
Obsah
ČVUT, Fakulta elektrotechnická, Praha 3
ZČU, Katedra kybernetiky, Plzeň 13
Technická univerzita, Liberec 20
Karlova univerzita, Ústav fonetiky, Praha 26
VUT, Fakulta informatiky, Brno 36
AV ČR, Ústav radioelektroniky, Praha 42
AV ČR, Ústav informatiky, Praha 47
2 OBSAH
Předmluva
Vážení čtenáři,
dostává se vám do rukou sborník shrnující a prezentující odborné aktivity řešitelskýchpracovišt komplexního grantu GA 102/02/0124 „Hlasové technologie v podpoře infor-mační společnostiÿ. Sborník přináší souhrnné informace o zaměření a výsledcích sedmivýzkumných týmů, které mohou být užitečné studentům, doktorandům a pracovníkůmz oblasti řečových technologií. Svým souhrnným pojetím se tento sborník liší od svéhopředchůdce editovaného prof. Nouzou a vydaného Technickou univerzitou v Liberci v roce2001 zaměřeného na zasvěcený pohled na problematiku počítačového zpracování řeči.
Každé pracoviště komplexního grantu je představeno stručným souhrnem aktivit a stě-žejních publikací. Kromě aktuálních informací obsahuje text nebo citované práce i struč-nou historii odrážející návaznost na práce vykonané v rámci komplexního projektu GA102/96/K087 „Teorie a aplikace hlasové komunikace v češtiněÿ.
Doufáme, že sborník poskytne užitečné informace nejen řešitelům grantu, ale rovněž i širšítechnické veřejnosti. Přivítáme jakékoliv další náměty na zlepšení, popřípadě rozšířenísborníku.
e-mail: [email protected] Abstrakt Po natočení filmu Schindlerův seznam založil režisér Steven Spielberg nadaci Shoah Visual History Foundation (VHF) s cílem shromáždit archiv videonahrávek svědectví lidí, kteří přežili holocaust. Nesmírné utrpení obětí holocaustu prezentované v těchto výpovědích se má stát studijním materiálem pro současnou i nastupující generaci a má být základem výchovy k toleranci lidí na celém světě. Do současné doby shromáždila VHF více než 52 tisíc výpovědí v 32 jazycích. K vyhledávání důležitých informací ve svědeckých výpovědích budou využity nejnovější technologie z oblasti automatického rozpoznávání mluvené řeči. Tyto problémy řeší prestižní projekt MALACH (Multilingual Access to Large Spoken Archives), k jehož řešení byla přizvána i Západočeská univerzita v Plzni, která se má, společně s MFF UK v Praze, podílet na zpracování jazyků střední a východní Evropy. Dalšími řešiteli projektu MALACH jsou IBM, Johns Hopkins University v Baltimore, University of Maryland a Shoah Visual History Foundation. Počítá se s tím, že moderní digitální videoarchiv svědeckých výpovědí lidí, kteří přežili holocaust, bude prostřednictvím ”rychlého” Internet 2 zpřístupněn zájemcům po celém světě. Očekává se, že terminály, které budou umožňovat online napojení do digitálního archivu VHF v Los Angeles, budou ve vybraných muzeích, univerzitách, pamětních centrech II. svět. války ap. Projekt MALACH je řešen od září roku 2001. Práce, které probíhají na katedře kybernetiky ZČU v Plzni jsou zaměřeny zejména na zpracování akustické části videonahrávek, na přípravu systému rozpoznávání řeči a provedení základních testů. Na každý rok je plánováno zpracování jednoho jazyka. První skupinu jazyků tvoří čeština, ruština, slovenština a polština. Pro trénování akustických modelů jsou vybírány 15 minutové úseky výpovědí od cca 400 řečníků. Tyto segmenty řeči jsou definovaným způsobem anotovány. Řeč na nahrávkách je spontánní a je velmi ovlivněna emocionálním stavem řečníka i jeho stářím (průměrný věk řečníků je cca 75 let). Ve spontánní řeči, zvláště českých výpovědí, je velké množství hovorových slov a gramaticky nesprávných vazeb, což velmi znesnadňují práci spojenou s přípravou jazykového modelu (textový materiál vhodný pro trénování jazykových modelů spontánní české řeči v podstatě neexistuje). I pro relativně objemný slovník cca 50k slov stále velké množství OOV (Out Of Vocabulary) slov velmi znesnadňuje funkci rozpoznávače. Při zpracování českých výpovědí byly proto navrženy speciální způsoby konstrukce slovníků i postupy při zpracování jazykových modelů. Současné výsledky rozpoznávání českých výpovědí jsou plně srovnatelné s výsledky, které dosahuje IBM při zpracování anglických výpovědí. Práce na systému rozpoznávání ruských výpovědí jsou ve finální fázi. Práce na návrhu systému rozpoznávání slovenštiny a polštiny se rozbíhají. Nejvýznamnější publikace [1] Psutka, J., Iljuchin, I., Ircing, P., Psutka, J.V., Trejbal, V., Byrne, W., Hajič, J., Gustman, S.: Building
LVCSR System for Transcription of Spontaneously Pronounced Russian Testimonies in the MALACH Project: Initial Steps and First Results. TSD 2003. Lecture Notes in Artificial Intelligence 2807, Springer-Verlag, Berlin, Heidelberg 2003, pp. 327-332.
[2] Psutka, J., Ircing, P., Psutka, J.V., Radová, V., Byrne, W., Hajič, J., Mírovský, J., Gustman, S.: Large Vocabulary ASR for Spontaneous Czech in the MALACH Project. –In: Proceedings of 8th European Conference on Speech Communication and Technology EUROSPEECH’2003, Geneva, Switzerland, 2003, pp. 1821-1824.
[3] Psutka, J., Ircing, P., Psutka, J.V., Radová, V., Byrne, W., Hajič, J., Gustman, S.: Towards Automatic Transcription of Spontaneous Czech Speech in the MALACH Project. TSD 2003. Lecture Notes in Artificial Intelligence 2807, Springer-Verlag, Berlin, Heidelberg 2003, pp. 214-219.
[4] Psutka, J., Ircing, P., Psutka, J.V., Radová, V., Byrne, W., Hajič, J., Gustman, S., Ramabhadran, B.: Automatic Transcription of Czech Language Oral History in the MALACH Project: Resources and Initial Experiments. TSD 2002. Lecture Notes in Artificial Intelligence 2448, Springer-Verlag, Berlin, Heidelberg 2002, pp. 253-260.
e-mail: [email protected] Abstrakt Úloha rozpoznávání řeči s velkými slovníky je řešena zejména v kontextu zpracování vysoce flexivních jazyků, jejichž jedním reprezentantem je i mluvená čeština. Bohatá flexe způsobuje obrovský nárůst položek ve slovníku a i když čítá takový slovník obvykle desítky tisíc slov, přesto běžná řeč, kterou chceme rozpoznávat, obsahuje standardně velké procento slov mimo slovník. Navíc, relativně volná struktura české věty ztěžuje konstrukci robustního jazykového modelu. Při rozpoznávání spontánní řeči se přidává další problém, který je specifický zejména pro mluvenou češtinu, a to je velké množství používaných nespisovných slov. Vzhledem k tomu, že statistiky jazykových modelů jsou běžně získávány z rozsáhlého textového materiálu, který je obvykle gramaticky korektní, vznikají tak při konstrukci systému rozpoznávání spontánní řeči obtíže s nedostatkem „materiálu“ pro trénování těchto modelů. To vše velmi znesnadňuje úlohu rozpoznávání narozdíl například od rozpoznávání mluvené angličtiny. Naše práce jsou proto soustředěny především na překonání výše uvedených problémů. Experimentuje se s jazykovými modely, které kombinují slovní n-gramy s n-gramy založenými na lematech a slovních druzích (POS tag). Byly též navrženy jazykové modely konstruované pomocí morfémů (kmeny a koncovky). Na snížení slov mimo slovník je zaměřena též metoda dvou či víceprůchodového rozpoznávání. Rozsáhlé experimentální práce jsou prováděny s využitím licencovaného dekodéru firmy AT&T, který využívá ve své činnosti principy teorie konečných automatů. Funkčnost navržených postupů je ověřována na úlohách rozpoznávání čtené i spontánní řeči Nejvýznamnější publikace [1] Byrne, W., Hajič, J., Ircing, P., Krbec, P., Psutka, J.: Morpheme Based Language Models for Speech
Recognition of Czech. TSD 2000. Lecture Notes in Artificial Intelligence 1902, Berlin, Heidelberg, Springer-Verlag 2000. pp. 211-216.
[2] Ircing, P.: Large Vocabulary Continuous Speech Recognition of Highly Inflectional Language (Czech). Disertační práce. Katedra kybernetiky, FAV ZČU, Plzeň 2003.
[3] Ircing, P., Krbec, P., Hajič, J., Psutka, J., Khudanpur, S., Jelinek, F., Byrne, W.: On Large Vocabulary Continuous Speech Recognition of Highly Inflectional Language – Czech. –In: 7th European Conference on Speech Communication and Technology EUROSPEECH’2001, Denmark, Aalborg, 2001, pp. 487-490.
[4] Ircing, P., Psutka, J.: Comparison of Word-based and Class-based Language Models for Speech Recognition of the Czech Weather Forecast. –In: The 11th Annual International Conference on Signal Processing Applications and Technology ICSPAT’2000, Dallas 2000, U.S.A. (on CDROM)
[5] Ircing, P., Psutka, J.: Fitting Class-Based Language Models into Weighted Finite-State Transducer Framework. –In: Proceedings of 8th European Conference on Speech Communication and Technology EUROSPEECH’2003, Geneva, Switzerland, 2003, pp.1873-1876.
[6] Ircing, P., Psutka, J.: Two-Pass Recognition of Czech Speech Using Adaptive Vocabulary. TSD 2001. Lecture Notes in Artificial Intelligence 2166 , Berlin, Heidelberg, Springer-Verlag 2001, pp.273-277.
[7] Psutka, J., Ircing, P., Radová, V.: Experiments with the Recognition of Highly Inflected Spoken Language (Czech) in the Large Vocabulary Task. –In: The 5th World Multiconference on Systemics, Cybernetics SCI’2001, Orlando, U.S.A., 2001, pp. 559-564.
[8] Psutka, J., Psutka, J.V., Ircing, P., Hoidekr, J.: Recognition of Spontaneously Pronounced TV Ice-Hockey Commentary. –In: Proceedings of the ISCA&IEEE Workshop on Spontaneous Speech Processing and Recognition SSPR 2003, Tokyo, Japan, 2003, pp.83-86.
e-mail: [email protected] Abstrakt Výzkum hlasových dialogových systémů se opírá o bohaté zkušenosti pracoviště získané v oblasti automatického rozpoznávání mluvené řeči a hlasové syntézy. Výzkum hlasových dialogových systémů je zaměřen především pro potřeby telefonních aplikací, tzv. IVR systémů. Jednodušší hlasové telefonní aplikace mohou komunikovat s uživatelem podle zápisu dialogu napsaném v jazyce VoiceXML, s jehož pomocí vývojář hlasové aplikace může nadefinovat průběh dialogu, gramatické struktury popisující množinu rozpoznávaných frází pro každou jednotlivou fázi dialogu a p řehrávání textů - obdržených například dotazem do databáze aplikace - hlasovou syntézou. Příkladem hlasové aplikace, která je postavena na uvedeném řešení a je provozovaná katedrou kybernetiky na Západočeské univerzitě v Plzni (ZČU) již třetím rokem, je hlasový informační systém informující zájemce o studium na ZČU o výsledcích jejich přijímacího řízení na ZČU. V popředí současného zájmu výzkumu jsou však sofistikovanější hlasové dialogové systémy umožňující komunikaci s uživatelem v přirozeném jazyce. Za tímto účelem je intenzivně zkoumána oblast porozumění mluvené řeči, modelování úlohy včetně jejího kontextu, o které se dialog vede, řízení dialogu a generování vhodné odezvy (akce) dialogového systému, kterou je nutno přetransformovat do podoby akustického řečového signálu. Pro potřeby úspěšného zvládnutí tohoto rozsáhlého úkolu je prováděn výzkum v řadě dílčích problematik jako je například automatické rozpoznávání souvislé mluvené řeči s velkými slovníky, vhodná reprezentace jazykového modelu a jeho adaptace a dekódovací techniky umožňující rozpoznávání v reálném čase, statistické metody zpracování přirozeného jazyka za účelem porozumění, reprezentace znalostí a metody strojového učení automatického obdržení znalostí z trénovacích dat, hledání vhodného kritéria řízení a strategie řízení dialogu. Příkladem úrovně současného stavu výzkumu a jeho aplikačního využití je probíhající konstrukce hlasového dialogového systému poskytujícího volajícímu informace o vlakových spojích. Nejvýznamnější publikace [1] Jelínek, L.: Design of Semantic Language Model for Czech Train Timetable Inquiry Processing. –In:
International Workshop Speech and Computer SPECOM’2002, St. Petersburgh, Russia. pp. 19-22. [2] Jelínek, L.: Design of Language Model for Train Timetable Inquiries Processing. –In: Proceedings of the 10th
Czech-German Workshop on SPEECH PROCESSING’2001. Prague 2001, pp.71-74. [3] Jelínek, L.: Porozumění telefonickému dotazu pro automatickou dopravní informační službu. Disertační
práce. Katedra kybernetiky, FAV ZČU, Plzeň 2003. [4] Müller, L., Šmídl, L., Jurčíček, F.: Rejection and Key-Phrase Spotting Techniques Using Mumble Model in a
Czech Telephone Dialogue System. –In: The Proceedings of the 6th International Conference on Spoken Language Processing ICSLP2000. Beijing, China 2000. Volume I., pp.134-137.
[5] Müller, L., Šmídl, L., Jurčíček, F. Psutka, V.J.: Benefit of Mumble Model to the Czech Telephone Dialogue System. –In: The 11th Annual International Conference on Signal Processing Applications and Technology ICSPAT’2000, Dallas 2000, U.S.A. (on CDROM)
[6] Šmídl, L., Müller, L., Psutka, J.: VoiceXML Based Telephone Dialog System Providing Access to Entrance Examination Results Stored in the University Database. –In: The 6th World Multiconference on Systemics, Cybernetics SCI’2002, Orlando, U.S.A., 2002, pp. 276-280.
[7] Šmídl, L., Prcín, M., Jurčíček, F.: How to Detect Speech in Telephone Dialogue Systems. –In: Proceedings of EURASIP Conference on Digital Signal Processing for Multimedia Communications and Services ECMCS 2001, Hungary, Budapest, 2001. (on CD-ROM)
[8] Zahradil, J., Müller, L., Jůza, P.: Key-Phrase Spotting Technique Used in Telephone Dialog System Accessing E-mails via Voice. –In: The 6th World Multiconference on Systemics, Cybernetics SCI’2002, Orlando, U.S.A., 2002, pp. 381-384.
ZČU, Katedra kybernetiky, Plzeň 17
Zpracování řečového signálu pro účely rozpoznávání řeči
e-mail: [email protected] Abstrakt Výzkum v oblasti zpracování řečového signálu je zaměřen především na problematiku nalezení vhodné parametrizace řečového signálu, akustického modelování, řešení problému úspěšné práce systému automatického rozpoznávání mluvené řeči v hlučném prostředí, detekce neřečových úseků a stanovení míry důvěry rozpoznané promluvy. V oblasti parametrizace řečového signálu je zkoumána řada parametrizačních technik, zejména pak metoda PLP, pozornost je upřena též na výběr a extrakci vhodných informativních příznaků a metody jejich dekorelace jako např. PCA či LDA. Pro robustní metody rozpoznávání je zkoumána řada metod potlačujících přítomnost šumové složky (jak aditivní tak konvoluční) v akustickém signálu pracujících na úrovni parametrizace akustického signálu nebo na úrovni akustického modelu. V oblasti akustického modelování se věnuje pozornost struktuře modelů, technik odhadu parametrů modelu a ocenění přesnosti těchto odhadů. Standardním modelem je HMM a technikou odhadu MLE nebo MAP (v případě adaptace pak metoda MLLR). V souvislosti s robustními metodami je též věnována pozornost modelování neřečových událostí. Neřečové události mohou být detekovány i detektorem neřečových úseků, který je vyvíjen pro účely zlepšení výsledků technik normalizujících přenosový kanál, pro detekci začátku a konce promluvy v hlasových dialogových systémech s možností skákání do řeči a pro zkrácení doby odezvy dialogového systému na řečový vstup uživatele. Opět především pro potřeby hlasových dialogových systémů a systémů hledání klíčových slov (frází) je také prováděn výzkum nalezení a stanovení vhodné míry důvěry v rozpoznanou promluvu i její jednotlivá slova. Pro stanovení míry důvěry jakožto i pro řešení nalezení OOV slov je prováděn výzkum struktury sběrových modelů (garbage, filler, mumble models). Jak pro práci detektoru řeči tak pro stanovení míry důvěry rozpoznaného slova či promluvy je intenzivně zkoumána úloha nalezení vhodných příznaků pro tyto úlohy. Opět jako v úloze parametrizace řečového signálu i zde se řeší úloha extrakce informativních příznaků. Mezi zkoumané metody patří metody modifikované PCA, LDA a VSM (Vector Support Machines). Nejvýznamnější publikace [1] Bartoš, T., Müller, L.: Rejection technique based on the mumble model. TSD 2002. Lecture Notes in
Artificial Intelligence 2448, Springer-Verlag, Berlin, Heidelberg 2002, pp. 221-228. [2] Müller, L., Bartoš, T.: Statistically Based Approach to Rejection of Incorrectly Recognized Words. –In:
The 7th International Conference on Spoken Language Processing ICSLP2002. Denver, U.S.A. 2002. pp. 857-860.
[3] Müller, L., Psutka, J.V.: Selection of an Optimum Speech Parameterization for Continuous Speech Recognition System Using a Telephone Channel. –In: The 5th World Multiconference on Systemics, Cybernetics and Informatics SCI’2001, Orlando, U.S.A., 2001, pp. 542-545.
[4] Müller, L., Psutka, J., Šmídl, L.: Design of Speech Recognition Engine. TSD 2000. Lecture Notes in Artificial Intelligence 1902, Berlin, Heidelberg, Springer-Verlag 2000, pp. 259-264.
[5] Psutka, J.V., Müller, L.: Optimization of some parameters in the speech-processing module developed for the speaker independent ASR system. –In: Proceedings of the 7th World Multiconference on Systemics, Cybernetics and Informatics SCI’2003, Orlando, U.S.A., 2003, pp. 414-418.
[6] Psutka, J., Müller, L., Psutka, J.V.: Comparison of MFCC and PLP Parameterization in the Speaker Independent Continuous Speech Recognition Task. –In: 7th European Conference on Speech Communication and Technology EUROSPEECH’2001, Denmark, Aalborg, 2001, pp. 1813-1816.
[7] Psutka, J., Müller, L., Psutka, J.V.: The Influence of a Filter Shape in the Telephone-Based Recognition Module Using PLP Parameterization. TSD 2001. Lecture Notes in Artificial Intelligence 2166, Berlin, Heidelberg, Springer-Verlag 2001, pp. 222-228.
[8] Prcín, M., Müller, L., Šmídl, L.: Statistical Based Speech/Non-speech Detector with Heuristic Feature Set. –In: The 6th World Multiconference on Systemics, Cybernetics SCI’2002, Orlando, U.S.A., 2002, pp. 264-269.
18 ZČU, Katedra kybernetiky, Plzeň
Počítačová syntéza řeči
zpracoval: Ing. Jindřich Matoušek, Ph.D., katedra kybernetiky FAV ZČU, Univerzitní 8, 30614 PLZEŇ Tel: 377 632 530 , Fax: 377 632 502
e-mail: [email protected] Abstrakt Syntéza řeči patří mezi významné úlohy komunikace člověk-počítač. Pro dialog vedený pro člověka v co nejpřijatelnější podobě, je nezbytné, aby vedle rozpoznávání řeči byl stroj schopen řeč rovněž vytvářet, a to jak ve srozumitelné, tak i přirozené formě. Nejobecnější úlohou počítačové syntézy řeči je syntéza řeči z textu (text-to-speech, TTS), kdy je úkolem TTS systému „p řečíst“ libovolný text. TTS systém se typicky skládá ze 2 modulů: modulu zpracování textu a vytváření řeči. Zatímco modul zpracování textu provádí převod textu na jeho výslovností podobu, modul vytváření řeči má na starost vlastní produkci řeči. Syntetizéry řeči z textu je možné použít ve všech systémech, kde je požadován hlasový výstup (např. automatické čtení e-mailů, SMS, knih, atd.). Na našem pracovišti je řešena úloha syntézy řeči z textu komplexně. Vytvořili jsme plně funkční TTS systém ARTIC (ARtificial Talker In Czech). Pro samotné vytváření řeči používáme v současné době nejúspěšnější přístup – konkatenační syntézu řeči. Tato metoda produkce řeči ke své funkci využívá inventář řečových jednotek a speciální algoritmy pro úpravu prozodických vlastností řeči a „vyhlazené“ spojování řečových jednotek v proudu výstupní řeči. Problematice konstrukce inventáře jsme věnovali velkou pozornost a navrhli postup pro jeho automatické vytváření (od návrhu řečového korpusu až po modelování a segmentaci řečových jednotek) pomocí statistických metod známých zejména z oblasti automatického rozpoznávání řeči. Jazykově nezávislých vlastností tohoto postupu jsme využili i pro syntézu jiných jazyků (např. němčina). V současné době rozšiřujeme možnosti modulu vytváření řeči o schopnost výběru „optimálních“ realizací řečových jednotek v reálném čase syntézy řeči (tzv. unit-selection). Po zajištění vysokého stupně srozumitelnosti se nyní soustředíme i na zvyšování přirozenosti řeči vytvářené naším systémem. Pro tento účel vyvíjíme algoritmy pro analýzu textu (např. automatický přepis číslovek, zkratek, fonetická transkripce, apod.) a odhad prozodických vlastností řeči z textu. Současná verze TTS systému využívá sadu heuristik a pravidel pro generování prozodických charakteristik vytvářené řeči (např. detekce promluvových úseků, odhad kontury základního hlasivkového tónu, atd.). Pracujeme rovněž na statistických metodách pro odhad prozodických charakteristik z reálných dat. Nejvýznamnější publikace [1] Matoušek, J., Psutka, J.: ARTIC: A New Czech Text-to-Speech System Using Statistical Approach to
Speech Segment Database Construction. -In: The Proceedings of the International Conference on Spoken Language Processing ICSLP2000. Beijing, China 2000. Volume IV, pp.612-615.
[2] Matoušek, J., Tihelka, D., Psutka, J., Hesová, J.: German and Czech Speech Synthesis Using HMM-Based Speech Segment Database. TSD 2002. Lecture Notes in Artificial Intelligence 2448, Springer-Verlag, Berlin, Heidelberg 2002, pp. 173-180.
[3] Matoušek, J., Tihelka, D., Psutka, J.: Automatic Segmentation for Czech Concatenative Speech Synthesis Using Statistical Approach with Boundary-Specific Correction. –In: Proceedings of 8th European Conference on Speech Communication and Technology EUROSPEECH 2003, Geneva, Switzerland, 2003, pp. 301-304.
[4] Matoušek, J., Psutka, J., Krůta: Design of Speech Corpus for Text-to-Speech Synthesis. –In: 7th European Conference on Speech Communication and Technology EUROSPEECH 2001, Denmark, Aalborg, 2001, pp. 2047-2050.
[5] Romportl, J., Tihelka, D., Matoušek, J.: Sentence Boundary Detection in Czech TTS System Using Neural Networks. –In: Proceedings of 7th International Symposium on Signal Processing and its Application ISSPA2003. France, Paris 2003, pp. 247-250.
[6] Romportl, J., Tihelka, D., Matoušek, J.: Prosody as a Causal System. –In: 13 th Czech-German Workshop on Speech Processing. Prague, Czech Republic, 2003.
[7] Tychtl, Z., Matouš, K.: The Phase Substitutions in Czech Harmonic Concatenative Speech Synthesis. TSD 2003. Lecture Notes in Artificial Intelligence 2807 , Springer-Verlag, Berlin, Heidelberg 2003, pp. 333-340.
[8] Tychtl, Z., Psutka, J.: Corpus-Based Database of Residual Excitations Used for Speech Reconstruction from MFCCs. –In: 7th European Conference on Speech Communication and Technology EUROSPEECH’2001, Denmark, Aalborg, 2001, pp. 2259-2262.
e-mail: [email protected] Abstrakt Při komunikaci mluvenou řečí člověk využívá kromě akustické podoby řeči také vizuální složku, tedy pohyby úst, popř. mimiku celého obličeje nebo gestikulaci rukou apod. To se projevuje obzvláště, pokud má poslouchající osoba vady sluchu nebo pokud je komunikace vedena v zašuměném prostředí. Naším cílem je zohlednit tento fakt i při řešení úloh z oblasti řečové komunikace člověk-stroj. V rámci audiovizuálního zpracování řeči jsou na našem pracovišti řešeny úlohy audiovizuální syntézy řeči, audiovizuálního rozpoznávání řeči, sledování pohybů hlavy nebo rtů (head-tracking, lip-tracking) a zpracování znakové řeči. Projekt audiovizuální syntézy řeči (talking head) doplňuje možnosti řečového syntetizéru ARTIC vyvíjeného na našem pracovišti. Cílem je vyvinout animovaný třírozměrný videorealistický model lidské hlavy, který bude parametricky řízen pomocí speciálního kódu poskytnutého syntetizérem ARTIC. Model hlavy je třírozměrný uměle vytvořený trojúhelníkový model. Je navržen tak, aby rty byly parametricky řiditelné pomocí speciální parametrizace. Ta byla získána z namluveného audiovizuálního řečového korpusu, který obsahuje jak akustickou tak vizuální složku. Pohyby rtů jsou tedy odvozeny od pohybů rtů skutečného řečníka. Cílem projektu audiovizuálního rozpoznávání řeči je doplnit systém rozpoznávání řeči o rozpoznávání vizuální složky, tedy pohybu rtů. Systém je navržen tak, aby při rozpoznávání obzvláště v zašuměném prostředí zvyšoval úspěšnost rozpoznávání analyzováním pohybů rtů řečníka. Systém je testován na audiovizuálním řečovém korpusu pro rozpoznávání získaném v prostředí jedoucího vozidla, do kterého byla nainstalována kamera pro nahrávání audiovizuálních dat. V rámci řešení uvedených úloh jsou účinně kombinovány algoritmy zpracování řeči s algoritmy zpracování digitalizovaného obrazu a počítačového vidění. Toto spojení přináší slibné výsledky na poli vědeckého výzkumu v oblasti komunikace člověka se strojem.
Nejvýznamnější publikace [1] Císař, P., Železný, M.: Feature Selection for the Czech Speaker Independent Automatic Lip-Reading. –In:
Proceedings of 7th International Workshop on Electronics, Control, Measurement and Signals, ECMS´2003. Liberec 2003, pp. 12-16.
[2] Císař, P., Železný, M.: Using of Lip-Reading for Speech Recognition in Noisy Environments. –In: Proceedings of the 12th Czech-German Workshop on SPEECH PROCESSING’2003, Prague 2003.
[3] Císař, P., Krňoul, Z., Novák, J., Železný, M.: Approach to an audio-visual speech synthesis using concatenation-based method. –In: Proceedings of the 11th Czech-German Workshop on SPEECH PROCESSING’2002, Prague 2002.
[4] Krňoul, Z., Železný, M.: Coarticulation Modeling for the Czech Audio-Visual Speech Synthesis. –In: Proceedings of 7th International Workshop on Electronics, Control, Measurement and Signals, ECMS´2003. Liberec 2003, pp. 64-68.
[5] Krňoul, Z., Železný, M.: The Automatic Segmentation of the Visual Speech. –In: Proceedings of the 12th Czech-German Workshop on SPEECH PROCESSING ’2003, Prague 2003.
[6] Železný, M., Císař, P.: Czech Audio-Visual Speech Corpus of a Car Driver for In-Vehicle Audio-Visual Speech Recognition. –In: Proceedings of AVSP 2003. France, St. Jorioz 2003, pp. 169-173.
[7] Železný, M., Císař, P., Krňoul, Z., Novák, J.: Design of an Audio-Visual Speech Corpus for the Czech Audio-Visual Speech Synthesis. –In: The 7th International Conference on Spoken Language Processing ICSLP2002. Denver, U.S.A. 2002. pp. 1941-1944.
[8] Železný, M., Krňoul, Z.: Czech Audio-Visual Speech Synthesis with an HMM-trained Speech Database and Enhanced Coarticulation. –In: 3rd WSEAS International Conference on Signal, Speech and Image Processing (ICOSSIP’2003). Greece, Rethymno 2003.
20 Technická univerzita, Liberec
Laboratoř počítačového zpracování řeči na TU v Liberci
Prof. Ing. Jan Nouza, CSc.
Katedra elektroniky a zpracování signálů, Fakulta mechatroniky, TUL
E-mail: [email protected] Tým: Prof. Ing. Jan Nouza, CSc., Ing. Miroslav Holada, Ing. Jindra Drábková, Ing. Dana Nejedlová, Ing. Josef Chaloupka, Ing. Petr David, RNDr. Petr Kolář, Ing. Jan Kos, Ing. Jindřich Žďánský WWW: http://itakura.kes.vslib.cz/kes/ Přehled řešené problematiky:
• Výzkum v oblasti rozpoznávání řeči – zpracování signálu a akustické modelování Kos, Žďánský, Nouza
• Výzkum v oblasti rozpoznávání řeči – modelování jazyka, zejména pro češtinu Nouza, Drábková, Nejedlová, Kolář, Žďánský
• Výzkum v oblasti rozpoznávání řeči – dekódování spojité řeči pro rozsáhlé
slovníky Nouza
• Výzkum v oblasti rozpoznávání řeči – aplikace v úlohách diktování do počítače
Nouza, Nejedlová
• Výzkum v oblasti rozpoznávání řeči – dialogové a distribuované systémy Holada, Drábková,
• Výzkum v oblasti rozpoznávání řečníka a automatické segmentace audio
záznamů David
• Výzkum a aplikace v oblasti audiovizuálního zpracování řeči
Chaloupka, Nouza, Holada
Technická univerzita, Liberec 21
Výzkum v oblasti rozpoznávání řeči
Prof. Ing. Jan Nouza, CSc., Ing. Miroslav Holada, Ing. Jindra Drábková, Ing. Dana Nejedlová, RNDr. Petr Kolář, Ing. Jan Kos, Ing. Jindřich Žďánský
Laboratoř počítačového zpracování řeči na TU v Liberci
Katedra elektroniky a zpracování signálů, Fakulta mechatroniky, TUL Hálkova 6, 461 17 Liberec 1
Oblast automatického rozpoznávání řeči je tradiční a zároveň nejvýznamnější oblastí výzkumu v liberecké Laboratoři počítačového zpracování řeči. Hlavním cílem je studovat, navrhovat a zároveň realizovat metody a strategie, které jsou prakticky použitelné zejména pro rozpoznávání mluvené češtiny. Výzkum je až na malé výjimky založen na vlastních implementacích klíčových komponent, takže může být a také bývá doveden až do fáze funkčních prototypů či skutečně provozovaných aplikací.
V poslední době je hlavní pozornost věnována rozpoznávání řeči v podmínkách velmi rozsáhlých slovníků v souladu s potřebami češtiny. Pro ni byla vytvořena celá sada univerzálních i aplikačně orientovaných slovníků s dodatečnými informacemi pro rozpoznávání (výslovnost, četnost, kategorizace, apod.) – viz [NEJ03a], [NEJ03b], [NEJ03c], [DRA03a], [KOL03]. Pro takto velké slovníky byly navrženy a implementovány rychlé algoritmy dekódování, a to pro izolovanou i spojitou řeč - [NOU02c], [NOU02e]. Na jejich základě byly navrženy a realizovány dva prototypy diktovacího systému. Systém pro izolované diktování je schopen pracovat v reálném čase se slovníkem o velikosti do 1 miliónu slov s úspěšností kolem 85 % (bez fáze adaptace), spojité diktování je zatím možné pouze se slovníkem do cca 25 tisíc slov s úspěšností kolem 65 % - [NOU03], [DRA03b]. Pro automatický přepis záznamů řeči byl vytvořen systém pracující se slovníkem 100 tisíc slov s odezvou, která je zatím asi 4x delší než doba vlastní promluvy. Je zde využíváno několik typů jazykových modelů vhodných pro specifické potřeby češtiny - [NOU02a], [DRA03a], [DRA02], [NEJ02b], [NEJ02c].
Další aktivity zahrnují oblasti distribuovaného rozpoznávání pro systémy typu klient – server ([HOL03b, [HOL03c]) a vývoj prakticky orientovaných systémů pro hlasových dialog s počítačem, zejména prostřednictvím telefonní linky - [NOU02d], [SEM03], [NOU02b].
Publikované práce (za poslední dva roky)
[DRA03a] DRÁBKOVÁ, J.: Formation of Classes for Continuous Speech Language Model and Building the Large Tagging Vocabulary for Czech Language. In Proc. of 13th Czech-German Workshop „Speech Processing". Prague, September 2003.
[DRA03b] DRÁBKOVÁ, J.: How good is speech recognition performed by human and by machine? In Proc. of 6th International Workshop on Elektronics, Control, Measurment and Signals – ECMS 2003. Liberec, June 2003. pp. 79-83
[NEJ03a] NEJEDLOVÁ, D.: Construction of a Dictation System for Czech Physicians. In Proc. of 13th Czech-German Workshop „Speech Processing". Prague, September 2003.
22 Technická univerzita, Liberec
[NEJ03b] NEJEDLOVÁ, D., NOUZA, J.: Building of a Vocabulary for the Automatic Voice-Dictation System. In 6th International Conference TSD 2003. České Budějovice, September 2003, Springer-Verlag, Heidelberg, pp. 301-308,
[NEJ03c] NEJEDLOVÁ, D.: Building and Evaluation of a Large Vocabulary for a Czech Voice Dictation System. In Proc. of 6th International Workshop on Elektronics, Control, Measurment and Signals – ECMS 2003. Liberec, June 2003. pp. 74-78.
[ZDA03] ŽĎÁNSKÝ , J., NOUZA, J.: Experimental Optimization of the Continuous Speech Recognition System. In Proc. of 13th Czech-German Workshop „Speech Processing". Prague, September 2003.
[NOU03] NOUZA, J.: Voice Dictation into a PC: Recent Research State at TUL. In Proc. of 6th International Workshop on Elektronics, Control, Measurment and Signals – ECMS 2003. Liberec, June 2003. pp. 69-73
[HOL03b] HOLADA, M.: Internet Speech Recognition Server. In Proc. of 7th World Multiconference on Systemics, Cybernetics and Informatics – SCI 2003. Orlando-USA, July 2003. Volume IV. pp. 388-391
[HOL03c] HOLADA, M.: Design a Prototype of Client – Server Speech Recognition System. In Proc. of 6th International Workshop on Elektronics, Control, Measurment and Signals – ECMS 2003. Liberec, June 2003. pp. 26-29
[SEM03] SEMENEC, P., HOLADA, M.: The Acoustic Model of Phone Line for ASR Databases Recorded by Microphone. In Proc. of Radioelektronika 2003. Brno, May 2003. pp. 364-367
[KOL03] KOLÁŘ, P.: Two-level Morphology of Czech. In Proc. of 6th International Workshop on Elektronics, Control, Measurment and Signals – ECMS 2003. Liberec, June 2003. pp. 49-53. ISBN 80-7083-708-X
[DRA02] DRÁBKOVÁ, J.: Language model based on the Czech morphology. In Proc. of 12th Czech-German Workshop „Speech Processing". Prague, September 2002. pp. 70-73.
[HOL02a] HOLADA, M.: Desing of distributed recognition system via Internet. In Proc. of 12th Czech-German Workshop „Speech Processing". Prague, September 2002. pp. 79-83
[NEJ02a] NEJEDLOVÁ, D.: Building a 20K Vocabulary and Language Model for Czech Language. In Proc. of 12th Czech-German Workshop „Speech Processing". Prague, September 2002. pp. 66-69
[NEJ02b] NEJEDLOVÁ, D.: Comparative Study on Bigram Language Models for Spoken Czech Recognition. In Proc. of TSD 2002. Brno, September 2002. pp. 197-204
[NEJ02c] NEJEDLOVÁ, D., NOUZA, J.: Language Model Support for Continuous Speech Recognition in Czech Language. In Proc. of IASTED International Conference "SPPRA 2002". Greece, Crete June 2002. pp. 541 - 546.
[NOU02a] NOUZA, J., DRÁBKOVÁ, J.: Combining Lexical and Morphological Knowledge in Language Model for Inflectional (Czech) Language. In Proc. of 6th Int. Conference on Spoken Language Processing. Denver USA, September 2002.
[NOU02b] NOUZA, J., KOLÁŘ, P., CHALOUPKA, J.: Voice Chat with a Virtual Character: The Good Soldier Švejk Case Project. In Proc of TSD 2002. Brno, September 2002. pp. 445-448
[NOU02c] NOUZA, J.: Strategies for Developing a Real-Time Continuous Speech Recognition System for Czech Language. In Proc. of TSD 2002. Brno, September 2002. pp. 189-196
[NOU02d] NOUZA, T., NOUZA, J., DRÁBKOVÁ, J.: An Efficient Graphic System for Developing Voice Operated Applications. In Proc. of SCI 2002. Orlando USA, July 2002, Volume I. pp. 239-244.
[NOU02e] NOUZA, J.: Building a System for Recognition of Fluently Spoken Czech. In Proc. of Radioelektronika 2002. Bratislava, May 2002. pp. 166-169.
Technická univerzita, Liberec 23
Výzkum a aplikace v oblasti audiovizuálního zpracování řeči
Ing. Josef Chaloupka, Prof. Ing. Jan Nouza, CSc., Ing. Miroslav Holada
Laboratoř počítačového zpracování řeči na TU v Liberci
Katedra elektroniky a zpracování signálů, Fakulta mechatroniky, TUL Hálkova 6, 461 17 Liberec
Jedním z moderních směrů vývoje a výzkumu v oblasti zpracování řeči je zaměření se na její vizuální složku. V Laboratoři počítačového zpracování řeči se v současné době (2003) zabýváme audiovizuální syntézou a audiovizuálním rozpoznáváním řeči.
V počáteční fázi byla vytvořena česká verze třírozměrné animované mluvící hlavy Baldi [CHA02c]. Ta je součástí programového balíku CSLU, distribuovaného Univerzitou (Health & Science University) v Oregonu, USA. Její česká verze byla prvním systémem audiovizuální syntézy řeči pro tento jazyk. Model hlavy mluví pomocí TTS syntetizátoru z ÚRE nebo využívá nahrávky přirozené lidské řeči [CHA02b]. Jeho mírně upravená verze byla použita v ukázkovém multimodálním projektu Švejk [NOU02b], v němž jsme se poprvé pokusili o spojení modulů rozpoznávání spojité řeči, audiovizuální syntézy a generátoru dialogu. Byl vytvořen i speciální test zjišťující, nakolik je mluvící hlava srozumitelná pro neslyšícího člověka. Výsledky ukázaly, že česká verze Baldiho může napomoci vnímání řeči, zároveň se však prokázala nutnost vytvořit mluvící tvář přímo pro český jazyk. Od konce roku 2002 byla proto na našem pracovišti vyvíjena vlastní mluvící hlava Chatter [CHA02d]. Pro potřeby modelování pohybu úst a mimických svalů bylo vytvořeno a zpracováno velké množství audiovizuálních nahrávek [CHA03d]. Při vlastní analýze vizuální části nahrávek byly použity jednoduché metody zpracování a rozpoznávání obrazu [CHA03c]. Výsledkem je nový systém české audiovizuální syntézy řeči [CHA03b]. Při vývoji mluvící hlavy byly využity i metody pro detekování a nalezení tváře a rtů v obraze [CHA03a]. Tyto metody jsou v současné době používány pro vytvoření systému audiovizuálního rozpoznávání řeči.
Do oblasti vizualizace spadá i dlouholetý projekt týkající se vývoje softwaru pro podporu výuky metod rozpoznávání. Na základě požadavků z řady akademických pracovišť, na nichž se používá náš produkt VISPER, byla vytvořena nová verze tohoto výukového a experimentálního systému, která nyní obsahuje moduly pro ilustraci metod rozpoznávání spojité řeči - [HOL03a].
Publikované práce (za poslední dva roky)
[CHA03a] CHALOUPKA, J.: The Face Detection and Lips Tracking for Audio-Visual Speech Recognition. In Proc. of 13th Czech-German Workshop „Speech Processing". Prague, September 2003.
[CHA03b] CHALOUPKA, J.: The Czech Computerized Talking Head "Chatter". In Proc. of 7th World Multiconference on Systemics, Cybernetics and Informatics – SCI 2003. Orlando-USA, July 2003. Volume IV. pp. 320-323
24 Technická univerzita, Liberec
[CHA03c] CHALOUPKA, J.: The Czech Audio-Visual Speech Synthesizer System. In Proc. of 6th International Workshop on Elektronics, Control, Measurment and Signals – ECMS 2003. Liberec, June 2003. pp. 30-33. ISBN 80-7083-708-X
[CHA03d] CHALOUPKA, J.: Multimodal Signal Processing and Research. In Proc. of Radioelektronika 2003. Brno, May 2003. pp. 388-389
[NOU02b] NOUZA, J., KOLÁŘ, P., CHALOUPKA, J.: Voice Chat with a Virtual Character: The Good Soldier Švejk Case Project. In Proc of TSD 2002. Brno, September 2002. pp. 445-448.
[CHA02a] CHALOUPKA, J.: Development of New Czech 3-D Talking Head. In Proc. of 12th Czech-German Workshop „Speech Processing". Prague, September 2002. pp. 54-58.
[CHA02b] CHALOUPKA, J., NOUZA, J., DRÁBKOVÁ, J.: Developing an Artificial Talking Head for Czech Language. In Proc. of SCI 2002. Orlando USA, July 2002, Volume III. pp. 232-236.
[CHA02c] CHALOUPKA, J., NOUZA, J., PŘIBIL, J.: Czech-Speaking Artificial Face. In Proc. of Biosignal 2002. Brno, June 2002. pp. 403-405.
[CHA02d] CHALOUPKA, J.: Talking Head: How Much Comprehensible Is It? In Proc. of Radioelektronika 2002. Bratislava, May 2002. pp. 202-205. ISBN 80-227-1700-2
[HOL03a] HOLADA, M., NOUZA, J.: VISPER II - Enhanced Version of the Educational Software for Speech Processing Courses. In Proc. of the 8th European Conference on Speech Communication and Technology EuroSpeech 2003. Geneva-Switzerland, September 2003. pp. 3169-3172
Technická univerzita, Liberec 25
Výzkum v oblasti rozpoznávání řečníka a automatické segmentace audio
záznamů
Ing. Petr David
Laboratoř počítačového zpracování řeči na TU v Liberci Katedra elektroniky a zpracování signálů, Fakulta mechatroniky, TUL
Do výzkumných aktivit liberecké Laboratoře počítačového zpracování řeči byla v roce 2001 zařazena i oblast rozpoznávání řečníka. Námi vyvíjený systém je určen pro plně automatickou identifikaci a verifikaci osob na základě mluvené řeči. Nejnovější oblastí výzkumu je i automatická segmentace audio záznamů. Náš systém pro identifikaci a verifikaci řečníka je založen na technice gaussovských mixturových modelů (GMM). Správné nastavení parametrů (složení vektoru příznaků, množství gaussovských složek v závislosti na trénovacích datech …) je velmi důležité pro optimální funkci stochastického systému [DAV02b]. Identifikace osob, která má proběhnout v reálném čase, klade specifické požadavky na rychlost odezvy systému. Je nutné zvolit takovou konfiguraci parametrů, která zajistí dostatečnou rychlost rozpoznávače při minimálním zhoršení rozpoznávacího skóre [DAV02a], [DAV03b]. Na rozpoznávání řečníka volně navazuje téma automatické segmentace audio záznamů. První výsledky s dělením audio signálu na řeč, hudbu a okolní ruch byly uvedeny v [DAV03c]. Následovat bude segmentace na jednotlivé mluvčí, témata a věty. V našem případě jsme se zaměřili nejprve na televizní zpravodajství. Segmentace takto rozsáhlých multimediálních záznamů vyžaduje speciální nástroje. Jedním z těchto nástrojů je i TRANSCRIBER, který byl použit v projektu zaměřeném na vytvoření mezinárodní databáze televizního zpravodajství [DAV03a]. Tato databáze bude sloužit pro další vývoj v oblasti automatického přepisu zpráv, záznamů konferencí, apod.
Publikované práce (za poslední dva roky)
[DAV03a] DAVID, P.: Using TRANSCRIBER Tool for Broadcast News Transcription. In Proc. of 13th Czech-German Workshop „Speech Processing". Prague, September 2003.
[DAV03b] DAVID, P.: Presentation of Real-time System for Automatic Speaker Identification and Verification. In Proc. of 7th World Multiconference on Systemics, Cybernetics and Informatics – SCI 2003. Orlando-USA, July 2003. Volume IV. pp. 372-376
[DAV03c] DAVID, P.: Unsupervised Segmentation of Audio Recordings. In Proc. of 6th International Workshop on Elektronics, Control, Measurment and Signals – ECMS 2003. Liberec, June 2003. pp. 17-20.
[DAV02a] DAVID, P.: Presentation of real-time system for automatic speaker identification. In Proc. of 12th Czech-German Workshop „Speech Processing". Prague, September 2002. pp. 74-78.
[DAV02b] DAVID, P.: Experiments with Speaker Recognition using GMM. In Proc. of Radioelektronika 2002. Bratislava, May 2002. pp. 353-357.
26 Karlova univerzita, Ústav fonetiky, Praha
Fonetický ústav Filozofické fakulty Univerzity Karlovy v grantu GA ČR 102 /02/0124
Ve shodě s vstupním projektem se práce zaměřuje na výzkum zvukových jevů, jejichž konkrétní a dostatečně podrobný popis je potřebný k tomu, aby bylo možno lépe pracovat se zvukovou podobou češtiny v oblasti hlasových technologií při rozšiřujících se nárocích na praktické aplikace. Podstatnou částí výzkumu je vždy percepční ověření relevance jednotlivých charakteristik zjištěných analýzou. V některých případech je při tom nutno podstatně modifikovat dosavadní teoretické koncepty. Některé ze sledovaných jevů nebo mluvních situací nebyly dosud v češtině popsány.
Adresa: Fonetický ústav FF UK Nám. Jana Palacha 2, Praha 1, PSČ116 38 http://fu.ff.cuni.cz
Složení týmu: Prof. PhDr. Zdena Palková, CSc. (odpovědný řešitel) [email protected]; tel
Výzkum prozodických charakteristik češtiny relevantních pro systematickou materiálovou analýzu mluvené řeči Tým: Z. Palková, J.Veroňková, J. Volín Abstrakt
Technické možnosti počítačového zpracování zvukového signálu řeči dovolují zkoumat podrobněji než dříve relace jednotek používaných v popisu zvukové struktury jazyka ke konkrétním zvukovým parametrům a výzkum opírat o velké soubory zvukových textů. Zároveň však vzniká nutnost vymezení těchto jednotek a jejich hierarchie zpětně ověřovat, doplňovat a případně modifikovat. To je také podmínkou pro vytvoření vhodného pojmového aparátu pro práci s korpusem zvukových textů (např. pro přizpůsobení systému ToBI).
Ve výzkumu se zaměřujeme dlouhodobě především na vyšetřování jazykově relevantních aspektů průběhu F0 v češtině, a to na dvojí hierarchické rovině. Na strukturní úrovni slova hledáme vlastnosti, které umožňují segmentaci zvukového kontinua na přízvukové takty. Na strukturní úrovni věty zjišťujeme podrobnější údaje o funkčních schématech rozlišujících hlavní typy výpovědi. Nově byl zahájen výzkum relevantních aspektů spádových změn v intonaci češtiny. 1. Zvukové charakteristiky přispívající k rozpoznání zvukového slova jako jednotky
Při určování jednotek na suprasegmentální rovině je podstatné stanovení vztahu mezi segmentací kontinua a výskytem zvukových prominencí. Na funkční rovině slova se často pracuje s jednotkou přízvukový takt a prominencí je slovní přízvuk. Tradiční přístup činí východiskem slovní přízvuk a přízvukový takt bývá definován do značné míry formálně.
Při aplikaci v analýze běžně mluvených textů, ale také v syntéze, se takový přístup setkává s obtížemi v jazycích, v nichž nepřízvučné slabiky nejsou redukovány v trvání ani kvalitě a tzv. přízvučné slabiky nevykazují dostatečně často předvídatelné vlastnosti v hodnotách F T I (ani v relaci k slabikám sousedním). V češtině se jeví vhodnější hledat určující vlastnosti taktu v lineárním průběhu zvukových kvalit po celé jeho délce, přičemž výzkum ukazuje relevanci zejména průběhu F0 a trvání segmentů.
a) Systematický výzkum se zatím zaměřil na zjišťování kontur F0, které kohezi taktu jakožto jednotky podporují nebo naopak oslabují. Východiskem jsou série testů na materiálu, ve kterém segmentace na takty rozhoduje o významu výpovědi. Dosud byly sledovány především sekvence dvou a tříslabičných taktů, které mají v češtině nejvyšší frekvenci a z hlediska zvukového největší variabilitu. V jedné části materiálu je určujícím faktorem odlišné umístění mezitaktové hranice uvnitř téže sekvence slabik (např. /světlo/ vnímají/ vs. /světlo v ní / mají/), v druhé části stojí v opozici dvoutaktové a jednotaktové řešení dané sekvence (např. /proti/ vnějším/ vs. /protivnějším/). Úroveň shody posluchačů ve prospěch jednoho z řešení, také ve vztahu k původnímu záměru mluvčího, je porovnávána s údaji o zvukových vlastnostech jednotlivých položek, zejména kontury F0 (analýza Praat, Multi Speech).V analogických testech pořízených syntézou je modifikován pouze průběh F0.
Analýza výsledků poskytuje určitou představu o stupni závislosti posluchače na významu či zvuku při rozhodování v takto mezní jazykové situaci. V přirozeném materiálu je 73% případů správně rozpoznáno při shodě nejméně 60% posluchačů. Žádáme-li shodu posluchačů nad 80%, je správně rozpoznáno 46% případů. Výsledky dovolují také konkretizovat některé vlastnosti melodických kontur, které podporují nebo naopak oslabují koherenci přízvukového taktu jako jednotky. Kontury s pozitivní tendencí řadíme do kategorie pro češtinu typických zvukových průběhů slova či jednotky téhož řádu. (Řidší) kontury s negativní tendencí mají
28 Karlova univerzita, Ústav fonetiky, Praha
patrně platnost mezních (limitujících) hodnot. - V současné době začíná výzkum víceslabičných taktů s monosylabem v první pozici.
b) V paralelním výzkumu začínáme také sledovat, zda a do jaké míry jsou zvukové
vlastnosti podporující či omezující kohezi taktů při hodnocení posluchačů ovlivňovány delším kontextem. Případy opozic umožňujících dvoutaktové či jednotaktové řešení slabičné sekvence (viz výše) byly zařazeny do dvojznačného kontextu o délce nejméně jednoho dalšího taktu z každé strany. Poslechové testy byly pak provedeny ve dvou variantách, s kontextem a bez kontextu. Při vyloučení kontextu poklesla poznatelnost záměru mluvčího ze 74% na 67% při 60% shody posluchačů. Změna hodnocení o více než 20% postihla v průměru 30% položek. Při vyloučení kontextu se dále zvyšuje možnost obráceného hodnocení a klesá více identifikace jednoho taktu než identifikace taktové sekvence
2. Zvukové charakteristiky diferencující melodémy pro posluchače
Jako v řadě jazyků, také v češtině vyjadřuje melodie výpovědi modální postoj mluvčího v dané komunikační situaci. Jak známo, odlišuje výpovědi ukončené od neukončených a v rámci výpovědí ukončených je jediným prostředkem odlišujícím zjišťovací otázku od deklarativní výpovědi. Pro vyjádření těchto funkcí se ustálila 3 schémata, tzv. melodémy, melodém ukončující klesavý (pro věty oznamovací, rozkazovací a doplňovací otázky) ukončující stoupavý (pro zjišťovací otázky) a neukončující (užívaný uvnitř delších výpovědí, případně při přerušení výpovědi).
a) Základní podoba melodémů byla popsána a výzkumy ji potvrzují. Značná variabilita
intonace v běžné řeči však vede k přesahům mezi schématy a vynucuje si podrobnější popis. Předmětem soustavného výzkumu je analýza melodických variant s cílem získat další údaje o melodických charakteristikách, které jsou určující pro posluchače při rozpoznávání melodémů. Výzkum se soustřeďuje na případy, ve kterých jsou si varianty různých melodémů podobné a ve kterých může docházet k záměně typů vět. Přechodové pásmo lze najít téměř mezi všemi typy výpovědí, ovšem s nestejnou frekvencí. Časté jsou přesahy mezi konturami deklarativních a neukončených výpovědí, a také mezi konturami neukončených výpovědí a zjišťovacích otázek.
Výzkum používá texty, které svou syntaktickou a sémantickou stavbou mohou být realizovány jako kterýkoli ze základních výpovědních typů. Jejich variantní zvuková realizace slouží jako základ percepčních testů, v nichž posluchači určují typ výpovědi. Výzkum se soustřeďuje na melodémy tříslabičné a delší, zejména pro velkou variabilitu jejich realizací a tím větší možnost záměn typů vět. V úvahu je brán mluvní styl, zejména rozdíl čteného a mluveného projevu a stupeň připravenosti projevu.
Testy jsou sestavovány jak na bázi přirozeného signálu, tak na bázi syntézy. V relaci k analýze průběhu F0 umožňují formulovat hypotézy o relevantnosti konkrétních melodických kontur pro posluchače. Při zpracovávání výsledků testů je v současné době zkoumán vliv nářečního pozadí posluchačů na percepční hodnocení jednotlivých typů. Ukazuje se, že tento vliv je významný zejména u zjišťovacích otázek; ty jsou realizovány dvěma způsoby, z nichž jeden se užívá spíše v Čechách a druhý spíše na Moravě.
b) Podobně jako v 1.b) byl zahájen paralelní výzkum směrem ke zjištění vlivu delšího kontextu na rozhodování posluchačů o typu výpovědi. Klasické pojetí popisu předpokládá, že melodický průběh tohoto taktu je dostatečný pro realizaci a rozpoznání melodému (tj. typu výpovědi). Ukazuje se však, že i zde určitou roli hraje širší kontext, zejména u variant nedostatečně typických a málo zřetelných. Výzkum se zatím soustřeďuje na zjištění potenciálního vlivu předcházejícího kontextu na percepční hodnocení melodému. Metodou je
Karlova univerzita, Ústav fonetiky, Praha 29
porovnávání výsledků paralelních testů na bázi plné a zkrácené verze jinak totožných dokladů z přirozené řeči. Rozdíly v hodnocení jsou prokazatelné, nevykazují však jednotný trend. Týkají se menšího počtu jednotlivých případů a z hlediska shody s původním záměrem mluvčího mohou znamenat změnu oběma směry, k zlepšení i k zhoršení. U poslechových testů na bázi syntézy je testována míra rozpoznání modality výpovědi se stejně realizovaným melodémem, avšak různým melodickým průběhem počáteční části. 3. Výzkum spádových jevů v intonaci češtiny
Průběžný pokles intonace ve výpovědi bývá zařazován mezi univerzální vlastnosti zvukových textů. Představuje značně složitou problematiku, ve které se kříží řečové a jazykové motivace. Pro odlišení jednotlivých aspektů bude třeba získat a vhodně analyzovat rozsáhlý materiál a v neposlední řadě nalézt i relevantní postupy pro takovou analýzu.
Chování deklinace v češtině dosud nebylo téměř vůbec zpracováno. První etapa výzkumu se zaměřuje na zjišťování deklinačního spádu u nádechových úseků ve čteném projevu a navazuje přitom na rozsáhlou analýzu J. Volína na bázi angličtiny. Přijatou metodou je regresní analýza celých kontur, materiálem jsou rozhlasové zpravodajské texty (12 mluvčích). Výsledkem je zjištění, že 89,9 % nádechových úseků deklinaci vykazuje. Trend hodnot F0 ve zbylých nádechových úsecích je stoupavý, ve více než polovině případů však nevýznamně. Odstranění závěrečného melodému celkový trend většinou ještě zesílí. Průměrný deklinační spád je -0,37 SD·s-1 pro všechny nádechové úseky a -0.44 SD·s-1 pro úseky deklinující. Tato zjištění je ovšem ještě nutno dále analyzovat a zjistit lingvistické i extralingvistické příčiny variability deklinačních hodnot.
Kontaktní osoby pro jednotlivá témata: (1) Z. Palková, (2) J. Veroňková-Janíková, (3) J.Volín
Publikace Palková, Z, Volín,J. (2003): The role of F0 contours in determining foot boundaries in
Czech. In: Proceedings of the 15th ICPhS, Barcelona, Vol 2, p 1783-1786 Palková, Z., Veroňková, J. : Influence of context to distinguish melodemes. In: Speech
Processing, 13th Czech – German Workshop, Prague, 2003, v tisku Palková, Z., Volín,J.: The influence of the acoustic context on the perception of the
foot boundaries. In: Phonetica Pragensia X, AUC Philologica, Karolinum Press, Praha , v tisku
Volín, J. : F0 deklination in Czech and English breath-groups. In: Phonetica Pragensia X, AUC Philologica, Karolinum Press, Praha, v tisku
30 Karlova univerzita, Ústav fonetiky, Praha
Výzkum vybraných zvukových charakteristik mluvené češtiny s perspektivním zaměřením na diferenciaci mluvčích B. Hedbávná, P. Machač, R. Skarnitzl, D. Studenovský Abstrakt
Výzkum individuální variability zvukových jevů se zaměřením na charakteristiku jednotlivých mluvčích vyžaduje, aby byl k dispozici základní popis dostatečně obsáhlého materiálu na bázi dostatečně podrobné klasifikace. Výzkum se zaměřuje na rozšíření a doplnění údajů o češtině v několika směrech, na různé úrovni zpracování problematiky.
Systematicky jsou shromažďovány údaje o kvalitativních a částečně kvantitativních hodnotách vokálů jakožto relativně stabilních segmentů v řeči. Teprve zahájen byl výzkum diftongů, o nichž dosud chybí v češtině základní informace a je nejprve nutno ověřit vhodné postupy analýzy. Rozvíjí se popis zvukových charakteristik k na bázi koartikulačních jevů. K určujícím problémům patří jejich vhodná klasifikace. Výzkum se opírá o materiál specializované fonetické databáze, která se již několik let průběžně buduje ve FÚ a která poskytuje dostatečně bohatou základnu variant pro jednotlivé sledované jevy. 1. Spektrální odlišnosti vokalických systémů individuálních mluvčích
Základním materiálem pro výzkum jsou nahrávky přirozené souvislé řeči profesionálních rozhlasových mluvčích, s rovnoměrným zastoupením mužů a žen. Zkoumány jsou krátké i dlouhé samohlásky ve všech pozicích ve slově.
Pro analýzu se využívá programů Cool Edit, Praat, Multi Speech, výstupy automatické analýzy však nejsou spolehlivé; výzkum preferuje ruční odečet formantových frekvencí ze spekter, nezbytná je vždy kontrola poslechem.
Výzkum je zaměřen na dvě úzce propojené oblasti: Měření formantových frekvencí samohlásek s cílem aktualizovat poznatky o současné
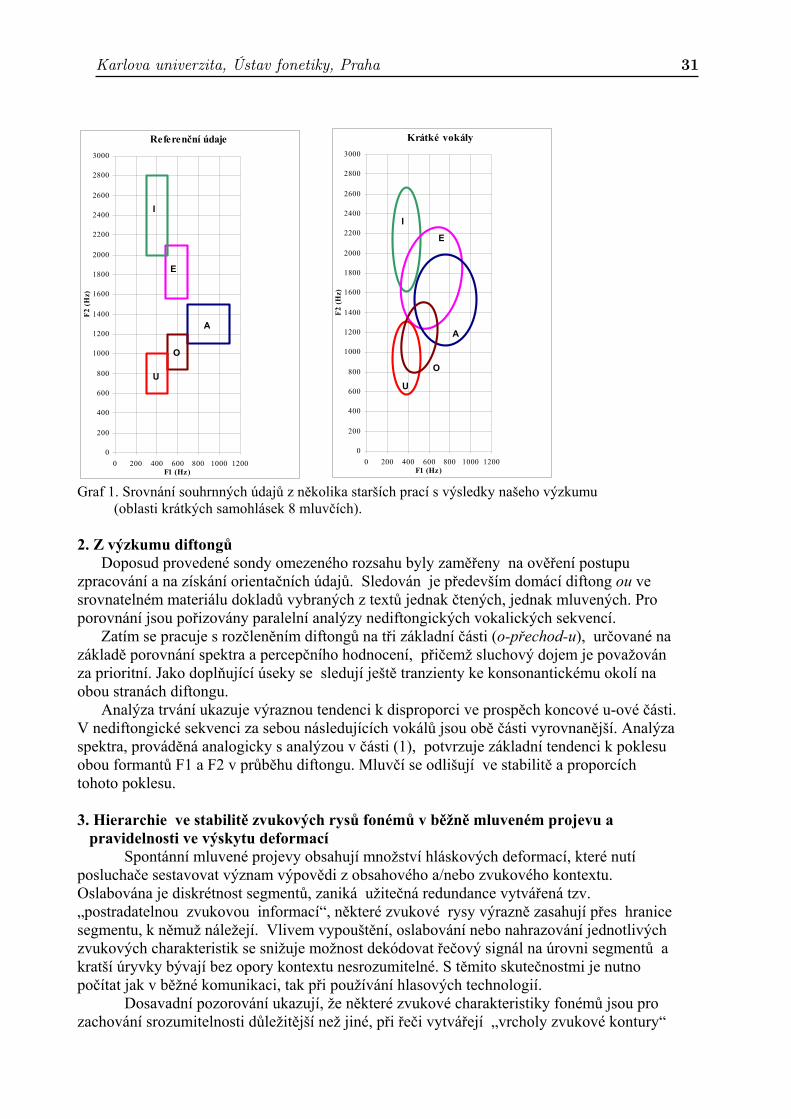
situaci v mluvené češtině, také s využitím novějších analyzačních metod. Oproti starším údajům z výzkumů prováděných většinou na laboratorním materiálu (izolované vokály, slabiky či slova) se v našich výsledcích objevuje nedostatečná diferenciace jednotlivých samohláskových typů a posun všech oblastí do středu formantového pole. Přesahy jsou tak značné (viz Graf1.), že za jejich zdroj nelze považovat jazykový vývoj, nýbrž především nedbalou výslovnost, zejména při nadměrně rychlém tempu; krátké samohlásky jsou postiženy více než dlouhé.
K prolínání samohláskových oblastí dochází nejen při srovnání samohlásek všech mluvčích, ale i u mluvčích jednotlivě. Spadá-li samohláska svou formantovou strukturou do oblasti samohlásky sousední, je tak posluchačem také vnímána a bez opory významového kontextu může docházet k záměnám. Tento fakt je zásadním problémem mimo jiné pro automatické rozpoznávání řeči i při adaptaci na konkrétního mluvčího. Nalezení individuálních charakteristik mluvčího na základě akustické stavby samohlásek. Mluvčí většinou využívá pouze část možného rozsahu formantových frekvencí pro každou samohlásku. U žen jsou obecně formanty o něco vyšší než u mužů, velké rozdíly však nacházíme i v rámci těchto skupin. Důležitým individuálním rysem je přitom míra stability/variability jednotlivých samohláskových typů a jejich vzájemný vztah, tj. jak jsou diferencovány, případně které oblasti se u mluvčího překrývají. Celkově lze mluvit o individuálním vokalickém systému mluvčího. Počet mluvčích je neustále rozšiřován a výsledky jsou doplňovány. V další etapě výzkumu se začíná s ověřováním vztahu formantové struktury samohlásek k jejich rozpoznání posluchačem bez opory významu.
Karlova univerzita, Ústav fonetiky, Praha 31
Referenční údaje
0
200
400
600
800
1000
1200
1400
1600
1800
2000
2200
2400
2600
2800
3000
0 200 400 600 800 1000 1200F1 (Hz)
F2 (H
z)
I
E
A
O
U
Krátké vokály
0
200
400
600
800
1000
1200
1400
1600
1800
2000
2200
2400
2600
2800
3000
0 200 400 600 800 1000 1200F1 (Hz)
F2 (H
z)
I
E
A
O
U
Graf 1. Srovnání souhrnných údajů z několika starších prací s výsledky našeho výzkumu (oblasti krátkých samohlásek 8 mluvčích). 2. Z výzkumu diftongů
Doposud provedené sondy omezeného rozsahu byly zaměřeny na ověření postupu zpracování a na získání orientačních údajů. Sledován je především domácí diftong ou ve srovnatelném materiálu dokladů vybraných z textů jednak čtených, jednak mluvených. Pro porovnání jsou pořizovány paralelní analýzy nediftongických vokalických sekvencí.
Zatím se pracuje s rozčleněním diftongů na tři základní části (o-přechod-u), určované na základě porovnání spektra a percepčního hodnocení, přičemž sluchový dojem je považován za prioritní. Jako doplňující úseky se sledují ještě tranzienty ke konsonantickému okolí na obou stranách diftongu.
Analýza trvání ukazuje výraznou tendenci k disproporci ve prospěch koncové u-ové části. V nediftongické sekvenci za sebou následujících vokálů jsou obě části vyrovnanější. Analýza spektra, prováděná analogicky s analýzou v části (1), potvrzuje základní tendenci k poklesu obou formantů F1 a F2 v průběhu diftongu. Mluvčí se odlišují ve stabilitě a proporcích tohoto poklesu. 3. Hierarchie ve stabilitě zvukových rysů fonémů v běžně mluveném projevu a
pravidelnosti ve výskytu deformací Spontánní mluvené projevy obsahují množství hláskových deformací, které nutí
posluchače sestavovat význam výpovědi z obsahového a/nebo zvukového kontextu. Oslabována je diskrétnost segmentů, zaniká užitečná redundance vytvářená tzv. „postradatelnou zvukovou informací“, některé zvukové rysy výrazně zasahují přes hranice segmentu, k němuž náležejí. Vlivem vypouštění, oslabování nebo nahrazování jednotlivých zvukových charakteristik se snižuje možnost dekódovat řečový signál na úrovni segmentů a kratší úryvky bývají bez opory kontextu nesrozumitelné. S těmito skutečnostmi je nutno počítat jak v běžné komunikaci, tak při používání hlasových technologií.
Dosavadní pozorování ukazují, že některé zvukové charakteristiky fonémů jsou pro zachování srozumitelnosti důležitější než jiné, při řeči vytvářejí „vrcholy zvukové kontury“
32 Karlova univerzita, Ústav fonetiky, Praha
nezbytné pro správné vnímání obsahu promluvy. Na druhé straně lze doložit, že jednotlivé typy hláskových deformací se prosazují s různou intenzitou, což nasvědčuje tomu, že zvukové rysy hlásek mají různou úroveň stability a z tohoto hlediska je lze rovněž hierarchizovat. Přitom vztah mezi tendencemi obojího typu není vztahem jednoduché přímé závislosti nebo úměry a jeho zjišťování je v začátcích.
V současné fázi výzkumu řešíme otázku, jak jemnou diferenciaci zvukových rozdílů uvnitř jednotlivých typů hlásek je třeba při analýze mluvených projevů zvolit pro dostatečně podrobný popis. K tomu účelu byl vypracován souhrn artikulačně-akustických jevů, které odlišují konkrétní realizaci hlásky od její „ideální podoby“ a jsou v češtině pro svou relativní ustálenost a frekventovanost zobecnitelné a kvantifikovatelné. K ověření použitelnosti a dostatečnosti tohoto inventáře je prováděna poslechová a částečně instrumentální analýza srovnatelných vzorků řeči z materiálu specializované fonetické databáze Fonetického ústavu. Příklad několika tendencí ve stabilitě zvukových rysů: typ hlásky stabilnější rysy méně stabilní rysy vokál znělost, formantový charakter kvantita, kvalita nazální konsonanty nazalita přítomnost závěru znělé explozivy místo přítomnost závěru neznělé sykavky místo, způsob - atd. 4. Akustická charakteristika variant tzv. rázu v češtině
V rámci problematiky koartikulačních jevů má značný význam výzkum jevů s funkcí hraničních signálů, které ovlivňují srozumitelnost zvukového projevu. Jejich použití je vázáno na stavbu daného jazyka a jejich výskyt tak představuje relevantní prvek segmentace souvislého toku řeči, zejména mají-li specifickou akustickou realizaci, zjistitelnou na bázi analýzy spektra.
Takovým prvkem je v češtině tzv. ráz, častý způsob zahájení fonace u vokálů, jsou-li v postavení na začátku slova nebo kmenového morfému. Je to jev rozeznatelný sluchem a jako kategorie fonetického popisu češtiny je do té míry stabilní, že jeho používání v různých pozicích upravuje výslovnostní kodifikace. V realitě řeči má však kategorie rázu více realizací, z hlediska artikulace i akustické podoby značně odlišných. Současný výzkum přináší první konkrétní údaje o akustických vlastnostech rázu.
Pro analýzu byl zvolen výskyt rázu před spojkou a. Tato pozice připouští značnou variabilitu předcházejícího kontextu a dává i možnost sledovat homogenní materiál z hlediska vztahu k syntaktické stavbě. Materiál byl extrahován z textů rozhlasového zpravodajství v realizaci 12ti mluvčích a zahrnoval 126 percepčně nesporných výskytů rázu. Akustická analýza tohoto materiálu (Praat 4.1.7) ukazuje, že dosud užívaný pojem rázu je správnější považovat za střechové označení pro varianty glottalizace před samohláskou v uvedených pozicích. Dva základní typy představuje hlasivková explozíva (glottal stop) a třepená fonace (creak). Každý z těchto typů lze na základě podoby spektra dále klasifikovat do několika podskupin. Liší se četností, ale také trváním. Dosavadní výsledky naznačují, že výskyt některých z těchto podtypů může být podporován fonetickými vlastnostmi hláskového okolí. Lze také očekávat individuální rozdíly mezi mluvčími. Kontaktní osoby pro jednotlivá témata: (1) B. Hedbávná , (2) D. Studenovský, (3) P. Machač, (4) R. Skarnitzl
Karlova univerzita, Ústav fonetiky, Praha 33
Publikace Hedbávná, B.(2003): Czech vocalic system in realizations of individual speakers. In:
Proceedings of the 15th ICPhS, Barcelona 2003, Vol 1, s. 679-682, +Book of Abstracts s. 34 Hedbávná, B: Variability of formant structure of Czech vowels in connected speech.
In: Phonetica Pragensia X, AUC Philologica, Karolinum Press, Praha , v tisku Skarnitzl, R.: Acoustic properties of the glottal stop before the Czech conjunction „a“.
In: Speech Processing, 13th Czech – German Workshop, Prague, 2003, v tisku Skarnitzl,R.: Acoustic categories of nonmodal phonation in the context of the Czech
conjunction “a”. In: Phonetica Pragensia X, AUC Philologica, Karolinum Press, Praha , v tisku
Studenovský, D., Trpák,J: The duration of the Czech diphthongs and Vowel-Vowel Sequences. In: Speech Processing, 13th Czech – German Workshop, Prague, 2003, v tisku
34 Karlova univerzita, Ústav fonetiky, Praha
Strukturní a prozodický popis vybraných typů sdělení se zaměřením na zvukovou komunikaci s počítačem Tým: M. Dohalská, T. Duběda, J. Mejvaldová Abstrakt Tato kapitola výzkumu je zaměřena na hláskové a prozodické postižení různých typů projevu s ohledem na jejich uplatnění v automatizované komunikaci. Motivací pro výzkum spontánní monologické češtiny (zvláště na rytmické úrovni) jsou zvyšující se požadavky na stylovou rozrůzněnost syntézy. Na úrovni hláskové jsme zkoumali mikrointenzitu (vývoj amplitudy v různých fázích artikulace hlásky) a využitelnost hláskových kombinací při tvorbě difonových inventářů. Jako nástroj k percepčnímu ověřování syntetické řeči byla naprogramována speciální aplikace. 1. Syntakticko-prozodické charakteristiky čteného textu ve srovnání se spontánním monologem
V návaznosti na dříve provedený výzkum různých textových "žánrů", u nichž lze očekávat uplatnění v syntéze, jsme se v roce 2003 soustředili na sledování syntakticko-prozodických charakteristik čteného textu ve srovnání se spontánním monologických projevem (Duběda 2003). V obou případech jde o informativní text postojově neutrálního obsahu. Srovnání obou typů projevu je významné jak z teoretického hlediska (různé typy a stupně vztahů mezi syntaxí a prozodickou segmentací), tak z hlediska praktického (důraz kladený na stylovou rozrůzněnost prozodických modulů v syntéze řeči, jež se v současné době nevyhýbá ani dosud okrajovým typům projevu, k nimž se řadí i spontánní řeč).
Srovnání bylo prováděno primárně na úrovni přízvukové jednotky (taktu), jež má v neutrální čtené češtině dosti prediktibilní lexikální koreláty. Spontánní řeč se naproti tomu vyznačuje vyšším stupněm deakcentuace (ztráty přízvuku), která postihuje nejen jednoslabičná gramatická slova, ale i mnohá jednoslabičná a někdy i víceslabičná plnovýznamová slova. Z hlediska projekce syntaxe na prozodickou segmentaci se spontánní řeč jeví jako méně pravidelná; při aproximaci spontánního projevu v automatické prozodické transkripci je tedy vedle lexikálních a syntaktických vlastností slov tedy třeba více brát v úvahu rytmické faktory. Zároveň je možné pro dosažení autentičtějšího stylu záměrně modelovat rytmické anomálie, např. váhání, expletivní zvuky a negramatické pauzy. 2. Software pro percepční testování
Při výzkumu přirozené i syntetizované řeči je třeba vedle objektivní akustické analýzy systematicky přihlížet k percepčnímu dopadu stimulů, jenž nemusí být s jejich akustickou podstatou v jednoznačném vztahu. K tomuto účelu se užívají percepční (poslechové) testy, v nichž jsou nezávislí respondentni vystaveni připraveným řečovým úsekům spolu s odpovídajícími otázkami. Vedle skupinového testování, vyžadujícího zvukovou nahrávku a potřebný počet formulářů, se často užívají též individuální testy, při nichž respondent poslouchá stimuly přímo z počítače a odpovědi zadává z klávesnice nebo myší. Na 13. Česko-německém workshopu (Duběda & Votrubec 2003) byl představen software umožňující snadnou tvorbu percepčních testů s možností volby různého počtu otázek, různých typů otázek, různého počtu povolených opakování stimulu, různého pořadí otázek a měření času
Karlova univerzita, Ústav fonetiky, Praha 35
reakce. Program nachází široké uplatnění např. při testování přijatelnosti syntetické řeči nebo při významovém rozlišení syntetických stimulů (např. oznamovací věta vs. otázka). 3. Výzkum mikroprozodie spontánní řeči s ohledem na její aplikaci v syntetické řeči
Tématem vědecké stáže T. Dubědy v Laboratoři pro počítačový výzkum řeči na Lausannské univerzitě byl problém mikroprozodie (zejména mikrodynamiky samohlásek) a jejího modelování v syntetické řeči, jež je vzhledem ke svému relativně malému kvalitativnímu dopadu dosud většinou opomíjeno. V kontextu zvýšeného zájmu o "texturu" syntetizovaného signálu však mikroprozodickou složku nelze považovat za nedůležitou. Na rozsáhlém materiálu čtené řeči (čeština, angličtina, francouzština) byly identifikovány vztahy mezi normalizovaným dynamickým profilem samohlásky a jejím trváním, přízvučností, globální intenzitou, spektrálním složením a kontextem. Tyto výsledky byly shrnuty v článku Duběda & Keller (v tisku). V současné době je připravována série percepčních testů, jež mají ukázat, nakolik přispívá mikrodynamické ovlivňování samohlásek k přirozenosti syntetizovaného signálu. 4. Pokračující optimalizace difonového inventáře pro češtinu V návaznosti na tříletý projekt spolupráce s Technickou univerzitou Drážďany jsme pokračovali v optimalizaci elementárních řečových jednotek pro syntézu řeči. Předmětem naší práce byl ženský hlas, obecně považovaný za kvalitativně hůře uchopitelný. Oproti předchozí metodě extrakce difonů ze souvislé řeči jsme nyní použili krátká, mírně hyperartikulovaná pseudoslova. Ukazuje se, že tato metoda nabízí lepší kontrolu segmentální kvality. Kontaktní osoba: Tomáš Duběda Bibliografie Duběda, T. & Keller, E. (v tisku) Microprosodic Aspects of Vowel Dynamics – an Acoustic
Study of French, English and Czech Duběda, T. & Votrubec, J. (2003) Configurable software for individual perception testing,
13th Czech-German Workshop, Prague (v tisku) Duběda, T. (2003) Prosody and Syntax in Spontaneous Speech: Evidence from Czech and
French, Proceedings of the International Congress of Phonetic Sciences, Barcelona Duběda, T. – Machač, P. (2004) Constructing and Optimizing a Diphone Database for Czech
Speech Synthesis, Acta Universitatis Carolinae, Phonetica Pragensia (v tisku)
m UG<8DPSRL�ZTFJl:dTH$>8l:i1jTdT]\i1S(Ln@Co�O8dfp(_bo�DPqJlJ>8p:i1jTD/@r?kst_�ufvKswuPuYo�O&dTDx lJ[`y{z�|Vs(}Y~w|TvPvA|fvKs(�rst_ ab?��Ey{z�|Vs(}�~c|TvPv:|TvKsP�(}
• Výzkum v oblasti modelů tvorby řeči Ing. Robert Vích, DrSc., Dr.-Ing. h.c., Dr.-Ing. Jiří Přibil., Ing. Anna Přibilová, Mgr. Slavomír Nemšák
• Výzkum v oblasti transformace hlasu Ing. Robert Vích, DrSc., Dr.-Ing. h.c., Ing. Anna Přibilová, Ing. Martin Vondra, Ing. Martin Plšek, Mgr. Slavomír Nemšák
Návrh a ověřování prosodických modelů pro češtinu a porovnávání se známými prosodickými modely.
Implementace prosodických modelů to TTS systému Epos a jejich ověřování v praxi.
Modelování prosodie češtiny pomocí umělých neuronových sítí za pomoci systému Epos.
Tvorba řečových inventářů, automatická segmentace řeči pomocí DTW.
Publikované práce
[1] HORÁK, P.: F0-Contour Modelling Using Linear Prediction. In: R. Vích (Ed.): Proc. of the 12th Czech-German Workshop on Speech Processing, Prague, 2002, pp. 46–47, ISBN 80-86269-09-4.
[2] HORÁK, P.: Modelování suprasegmentálních rysů mluvené češtiny pomocí lineární predikce. Doktorská disertační práce FEL ČVUT Praha, 2002.
[3] Horák., P., Sobe, D.: Prosodiemodellierung im freien Text-to-Speech System Epos mit Neuronalen Netzen. In: Proc. of the 14th Conference Elektronische Sprachsignalverarbeitung ESSV, Karlsruhe, 24.–26. September 2003, pp. 265–271, ISSN 0940-6832.
Konstrukce modelu tvorby řeči založeného na zobecněném homomorfním zpracování signálu vhodného pro široké spektrum hlasů, tj. pro mužský, ženský i dětský hlas.
Hledání nových přístupů určování obálky spektra řeči, např. pomocí kepstrální a pseudokepstrální dekonvoluce a pomocí splinů, vhodné zejména pro analýzu a syntézu ženského a dětského hlasu.
Ověřování metod konstrukce modelu hlasového traktu s konečnou impulsní odezvou z vyhlazeného spektra řeči.
Robustní metody detekce základního tónu řeči.
Publikované práce
[1] PLŠEK, M., VONDRA, M.: Detekce základního tónu v zašumělých řečových nahrávkách. [online] http://www.elektrorevue.cz/clanky/02025/, 9 pages.
[2] PLŠEK, M., VONDRA, M.: Pitch Detection in Noisy Speech Recordings. [online] http://www.electronicsletters.com/papers/2002/0010/paper.asp 3/6/2002, ISSN1213-161X, 9 pages.
[3] PLŠEK, M.: Speech Spectrum Smoothing by Cepstrum and Pseudocepstrum Weighting. In: R. Vích (Ed.): Proc. of the 12th Czech-German Workshop on Speech Processing, Prague, 2002, pp. 38-42, ISBN 80-86269-09-4.
[4] PŘIBIL, J., Madlová, A.: Two Speech Synthesis Methods Based on Cepstral Parametrization. In: Radioengineering, Vol. 11, No. 2, June 2002, pp. 35 -39.
[7] VÍCH, R.: Experimente mit der Anwendung der Pseudokorrelation bei der Vokaltrakt-modellierung. In: R. Hoffmann (Ed.) Proc. of the 13th Conference Elektronische Sprachsignalverarbeitung ESSV Dresden, 25.-27. September 2002, Studientexte zur Sprachsignalverabeitung Vol. 24, pp. 253-260, ISSN 0940-6832.
AV ČR, Ústav radioelektroniky, Praha 45
[8] VÍCH, R., SMÉKAL, Z.: Speech Signals and their Models. In: Proc. of the Summer School DATASTAT’01, FOLIA Facultatis Scientiarum Naturalium Universitatis Masarykianae Brunensis, Mathematica 11, Brno 2002, pp. 277-291, ISBN 80-210-3028-3.
[9] SMÉKAL, Z., VONDRA, M., VÍCH, R.: State Space Representation of Cepstral Vocal Tract Model for DSP Implementation. [online] http://www.electronicsletters.com/papers/2002/0013/paper.asp 3/9/2002, ISSN 1213-161X, 13 pages.
[10] VONDRA, M., VÍCH, R.: Design of FIR Vocal Tract Models with Linear and Nonlinear Phase. In: R. Vích (Ed.): Proc. of the 12th Czech-German Workshop on Speech Processing, Prague, 2002, pp. 28-32, ISBN 80-86269-09-4.
46 AV ČR, Ústav radioelektroniky, Praha
Výzkum v oblasti transformace hlasu
Ing. Robert Vích, DrSc., Dr.-Ing. h.c., Ing. Anna Přibilová, Ing. Martin Vondra,
Ing. Martin Plšek, Mgr. Slavomír Nemšák
Ústav radiotechniky a elektroniky Akademie věd České republiky






























































![Case Report CardiacTamponadeasanInitialManifestationofCervicalCancer · 2019. 7. 30. · reporting these entities as an initial presentation of cervical cancer [2]. Herein, we present](https://static.dokumenty.site/doc/80x56/60c89103e8759b4d1c1e1fd0/case-report-cardiactamponadeasaninitialmanifestationofcervicalcancer-2019-7-30.jpg)


