58
Pracujeme s programem R Základy
| Date post: | 12-Jul-2019 |
| Category: |
Documents |
| Upload: | nguyenxuyen |
| View: | 233 times |
| Download: | 0 times |

Pracujemes programem R
Základy

R je program a R je jeho programovací jazyk
• V programu R pracujeme pomocí příkazů jazyka R, který patří mezi interpretační jazyky.
• Interpretační vs. kompilační programovací jazyky
• Interpretační jazyk• Prvotní součástí každého provedení příkazu* je jeho překlad (zpravidla do strojového kódu **), po
přeložení se příkaz vykoná. Překlad je součástí běhu programu, děje se při každém běhu, tedy opakovaně. Z toho vyplývá, že interpret je pomalý. Mezi interpretační jazyky patří JavaScript, R***, rané verze Basicu.
• Kompilačních jazyk• Překlad programu se děje jako samostatná operace před jeho během. Vzniklý přeložený modul (exe),
pak opakovaně spouštíme. Ve srovnání s interprety vysoká rychlost programu, horší ladění. Patří sem jazyky FORTRAN, C++.
* Příkaz – nejmenší jednotka programu vyjadřující nějakou činnost. Program se vykonává po příkazech.* *Strojový kód – Jediný programovací jazyk, kterému procesor počítače rozumí – jehož příkazy umí vykonat.
Proto se programy napsané v ostatních programovacích jazycích musí před jejich spuštěním přeložit do strojového kódu.
***Funkce, které jsou součástí jazyka R, jsou zpravidla „předpřeloženy“ do tzv. bytového kódu. To způsobuje, že jejich běh je rychlejší.

R je funkcionální programovací jazyk
• Imperativní vs. funkcionální programování
• Imperativní programování – program je souhrn příkazů přesně popisujících jak se dostaneme k výsledku.
• Funkcionální programování – voláme příslušnou funkci, která vrací řešení problému či jeho části. Při volání poskytujeme funkcím vstupní data ve formě jejich argumentů.
“To understand computations in R, two slogans are helpful:
Everything that exists is an object*.
Everything that happens is a function call."
— John Chambers
*Objekty programu jsou zobrazením (dle potřeby často zjednodušeným) objektů reálného světa.Objekty programu R popisují svojí strukturou řešený problém.

Příklad (1)
• C# je imperativní programovací jazyk. Chceme-li zde vypočítat průměr, musíme vyjít z příslušného vzorce a ten naprogramovat jako funkci. Pak tuto funkci s příslušnými argumenty (čísla, z nichž chceme průměr spočítat) voláme.
• V R již existuje funkce mean(), kterou s příslušnými argumenty jen voláme.

Příklad (2)
• Experimentálně získanými daty chceme proložit regresní přímku. V R je k tomuto účelu naprogramovaná funkce lm(), které při volání předáme všechny potřebné informace – model (přímka), který má daty proložit, a naše data.
• Funkce lm() vrací objekt, jehož vlastnosti popisují proloženou přímku a její statistické charakteristiky. Vlastnosti tohoto objektu lze nejen získat, ale objekt lze použít jako argument při volání jiných funkcí, které jeho struktuře rozumí a opět objektově poskytují další informace o řešeném problému.
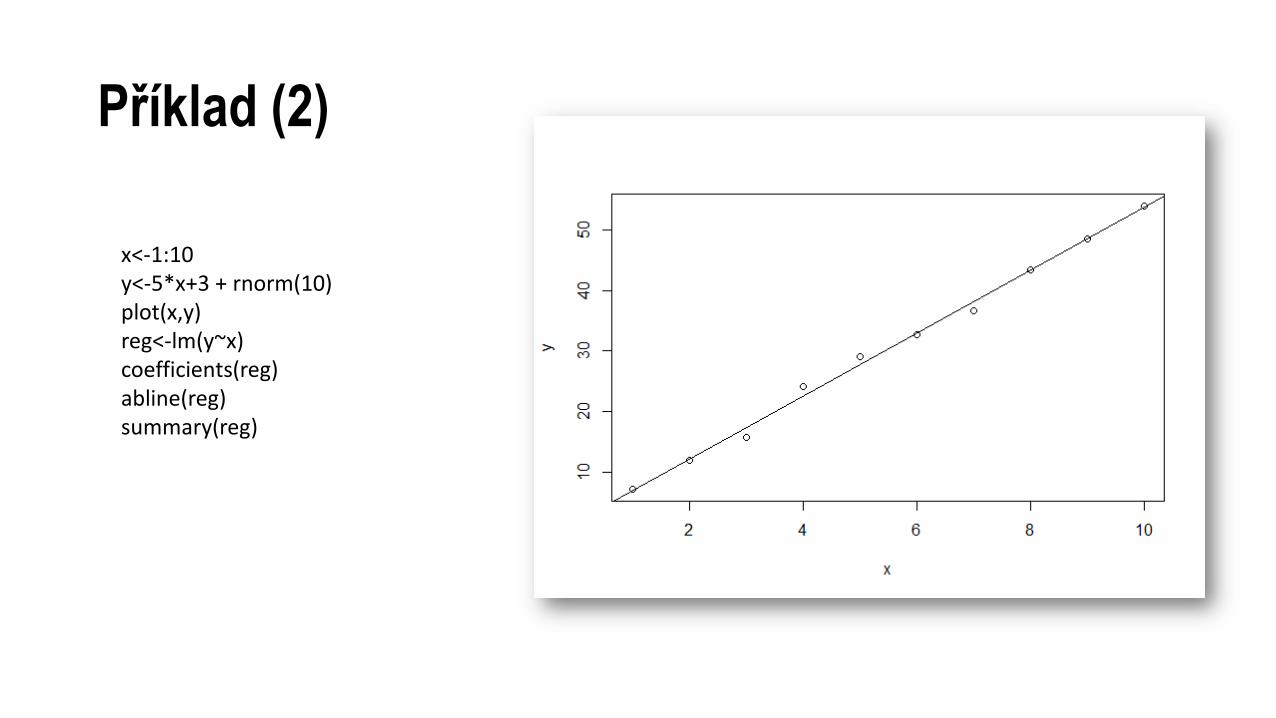
Příklad (2)
x<-1:10y<-5*x+3 + rnorm(10)plot(x,y)reg<-lm(y~x)coefficients(reg)abline(reg)summary(reg)

Práce s proměnnými (1)
• Proměnnou rozumíme místo v paměti, které označíme jménem. Do proměnné budeme ukládat data – objekty R.
• Jména proměnných (symboly, identifikátory).
• Platné jméno se skládá z písmen, číslic, teček a podtržítek, začíná písmenem či tečkou, kterou nenásleduje číslice (jméno jako .6bicyklu není platné). Vyplatí se používat popisná jména. Pozor na objekty se jménem začínajícím tečkou (taková jména běžně nedělejme), R s nimi někdy (ls(), rm()) zachází jinak než s ostatními objekty.
• Jako jméno proměnné nelze použít klíčové slovo jazyka R. Seznam klíčových slov získáme příkazem ?reserved. Postupně se s některými seznámíme.
• Uzavřeme-li jakoukoli posloupnost znaků do zpětných apostrofů (backquotes), je to platné jméno.
• Program R rozlišuje malá a velká písmena
• Přiřazení dat proměnné děláme pomocí <-, =, assign(). Doporučení: užívejme <-.
• Syntax: jmenoprom <- hodnota > if<-8Error: unexpected assignment in "if<-"> `if`<-8 ; `:-{}`<-c(4,5,6) # OK

Práce s proměnnými (2) – výpis a odstranění proměnných• Seznam platných jmen získáme příkazem ls(). Tento příkaz běžně proměnné s názvem
začínajícím tečkou nevidí, protože jeho argument all.names je standardně nastaven na FALSE (viz help). Seznam platných jmen je též na kartě Environment prostředí RStudia(bez jmen začínajících tečkou).
• Příkazy • str(x) # zobrazí vnitřní strukturu objektu označeného proměnnou x
• ls.str() # výpis hodnot proměnných včetně struktury
• Odstranění proměnné name uděláme příkazem – rm(name), který volá funkci rm().
• Odstranění všech proměnných rm(list=ls()).
• Objekty s názvem začínajícím tečkou však neodstraní. V tom případě je třeba rm(list=ls(all.names=TRUE)).

Příkaz R
• V příkazech R voláme funkce zápisem jména funkce s argumenty v závorkách
• Příklad: y<-log(100,base = 10)
• Připomeňme, že program R rozlišuje malá a velká písmena.
• Nejmenší jednotkou, kterou lze vykonat, je příkaz jazyka R.
• Zapisujeme jej do příkazového řádku Console programu R či RStudia. K vykonání jej odesíláme klávesou Enter.
• Příkazy jazyka R lze též v RStudiu zapisovat do textového souboru jako skript R (File/New File/R Script) a potom je vykonat najednou (Ctrl+Alt+R), či postupně (Ctrl+R, Ctrl+Enter). Soubory se skripty vytvořené RStudiem mají příponu R a jsou asociovány RStudiu. Uvedené klávesové zkratky platí také pro RStudio.
• Do příkazového řádku lze zapsat více příkazů oddělených středníkem.
• Znaky zapsané za symbolem # slouží jako komentář.
• Příklady příkazůa<-5 ; b<-10 ; c<- a + b # Definujeme proměnné a=5, b=10, c=a+b.
ls() # Voláním funkce ls() vypisujeme seznam proměnných prostředí. Viz též další snímek.

R jako kalkulačka
> x<-10
> y<-20
> x+y
[1] 30
> x/y
[1] 0.5
> log(x) # přirozený logaritmus deseti
[1] 2.302585
> log10(x)
[1] 1

Běh programu (skriptu) v RStudiu
• V RStudiu vytvoříme příkazem File/New File/R Script kartu, do které zapisujeme příkazy jazyka R.
• Zkopírujeme sem blok již známých příkazů.
• Tlačítkem Source karty vykonáme celý script.
• Tlačítkem Run vykonáme příkazy po řádcích,či vyznačených blocích.
• Skript lze příkazem File/Save, či tlačítkem Saveuložit do souboru *.R.
• Příkazem File/Open File lze opět uložený skriptotevřit v prostředí RStudia.
x<-1:10y<-5*x+3 + rnorm(10)plot(x,y)reg<-lm(y~x)coefficients(reg)abline(reg)summary(reg)

Funkce a jejich argumenty
• Návratovou hodnotu - výsledek funkce získáme jejím voláním
• Volání: jméno funkce, argumenty v závorkách• Argumenty s počátečními hodnotami: jmenoargumentu=hodnota - jsou volitelné.
Nezadáme-li tento argument, vezme si funkce ke zpracování jeho počáteční hodnotu (nezadáme-li argument base funkce log, pak má tento hodnotu základu přirozených logaritmů).
• Argumenty bez počátečních hodnot jsou povinné či volitelné (poznáme z nápovědy či z chování funkce).
• Pořadí a jména argumentů• Zadáme-li hodnoty argumentů v pořadí daném definicí funkce (viz nápověda), netřeba
specifikovat jména argumentů (log(100, 10).
• Přiřazujeme-li při volání do jména argumentu hodnotu, netřeba dodržet pořadí argumentů (log(base = 10, x=100)). Toto přiřazení se dělá zásadně pomocí znaku rovnítko.
log(x, base = exp(1))

Příklad
Syntax funkce log: log(x, base = exp(1))
Argument x je povinný, argument base je volitelný, nezadáme-li jej, má hodnotu základu přirozených logaritmů (exp(1)).> log(256,4) # nezadáváme-li jména argumentů, nutno uvést argumenty ve správném pořadí.
[1] 4
> log(x=256, base=4) # zadáváme-li jméno argumentu, přiřazujeme mu hodnotu rovnítkem.
[1] 4
> log(base=4, x=256) # zadáváme-li jména argumentů, je pořadí argumentů libovolné.
[1] 4

Běžné matematické funkce v R - příklady
• logaritmus - log(x), log10(x),log2(x)
• exponenciela - exp(x)
• goniometrické funkce – sin(x), cos(x), tan(x)
• druhá odmocnina - sqrt(x)
• absolutní hodnota – abs(x)
• faktoriál - factorial(x)

Běžné operátory v R - precedence
• [ indexing
• ^ exponentiation (right to left)
• - + unary minus and plus
• : sequence operator
• * / multiply, divide
• + - (binary) add, subtract
• < > <= >= == != ordering and comparison
• ! negation
• & and
• | or
• -> rightwards assignment
• <- assignment (right to left)
• = assignment (right to left)
• ?
Precedenci operací lze zvýšit jejich uzavřením do ().
https://stat.ethz.ch/R-manual/R-devel/library/base/html/Syntax.html

Příklady
• > x<-1:10
• > -x^2
• [1] -1 -4 -9 -16 -25 -36 -49 -64 -81 -100
• x>3
• [1] FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
• > x[(x > 1) & (x < 5)]
• [1] 2 3 4

Uzavření příkazu do závorek ()
• Uzavřeme-li výraz či příkaz do kulatých závorek (), získáme příslušnou návratovou hodnotu.
> x<-4+5 # Má přiřazení hodnotu?> (x<-4+5) # Ano, je to hodnota výrazu vkládaného do proměnné[1] 9

Datový typ v programovacím jazyku
• Určuje množinu hodnot, kterých může proměnná tohoto typu nabýt.
• Určuje množinu operací, které lze s touto proměnnou dělat.

Atomické datové typy R
• Integer
• Double
• Character
• Logical
• Complex (vynecháme)
• Raw (vynecháme)
• > x<-5L ; typeof(x)• [1] "integer"• > x<-5 ; typeof(x)• [1] "double"• > x<-"Jan" ; typeof(x)• [1] "character"• > x<-TRUE ; x<-FALSE ; x<-T ; x<-F ; typeof(x)• [1] "logical"

Základní datové typy v R
http://adv-r.had.co.nz/Data-structures.html

Práce s datovými typy
•Kontrola a převod typu• typeof() určuje typ dat
uložených v paměti
• kontrola typu is funkcí (is.integer() ….)
• převod typu as funkcí (as.integer() ….)
• > x<-10
• > typeof(x)
• [1] "double"
• > z<-"Pokus"
• > typeof(z)
• [1] "character"
• > is.double(x)
• [1] TRUE
• > a<-10L
• > typeof(a)
• [1] "integer"
• > b<-as.double(a)
• > typeof(b)
• [1] "double"

Vektor – základní datový typ R
Vektor – indexovaný souhrn prvků stejného atomického typu (funkce typeof()poskytuje pro všechny tyto prvky tentýž výsledek). Index prvku vektoru udává jeho pořadí. Indexy tvoří posloupnost přirozených čísel počínaje jedničkou.
Vektor je základní datová jednotka, se kterou R pracuje. R nezná skaláry. Místo toho pracuje s jednosložkovými vektory.
> x<-5> x[1][1] 5> x[1] 5> x[2]<-6> x[1] 5 6> length(x)[1] 2
KLÍČOVÉ FUNKCEtypeof() – udává typ prvků vektorulength() – udává počet prvků vektoru.

Tvorba vektoru
• Funkce• c() – tvorba vektorů z prvků, kombinace (konkatenace) vektorů
• seq(), operátor dvojtečka.x1<-c(1,2,5,8); x2<-c(x1,10,12)
s <-seq(0,99,3) ; sd1<-1:5
• Přístup k prvkům vektoru – indexy prvků v hranatých závorkách.• a[3]<-2
• a[c(1,3,5)]

Tvorba vektorů - posloupností
• x<-from:to
• seq(from, to)
• seq(from, to, by= )
• seq(from, to, length.out= ) # určíme počet členů
• Příklady:
> x<-1:10
> x
[1] 1 2 3 4 5 6 7 8 9 10
> x<-seq(1,16,5)
> x
[1] 1 6 11 16
> x<-seq(0,1,length.out = 11)
> x
[1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0

Vektorová aritmetika, vektorizace, recyklace
• Operace s vektory jsou sice interně dělány člen po členu (memberwise), ale v jedné R operaci, vykonané jedním příkazem - vektorizace (vectorization).a = c(1, 3, 5, 7)b = c(1, 2, 4, 8)5 * a # vynásobení každé složky vektoru a pěti – jde vlastně o recycling (viz dále).a + b # sečtení dvou vektorů po složkácha/b # vydělení každé složky vektoru a odpovídající složkou vektoru b.
• Recyklace (Recycling). Jsou-li dva vektory nestejné délky, je nejdříve délka kratšího z nich, opakováním jeho složek od první, prodloužena na délku delšího. Teprve potom je s těmito stejně dlouhými vektory provedena žádaná operace.u = c(10, 20, 30, 40, 50)v = c(1, 2, 3)u + vu/v

Subsetting vektoru – pomocí [
• Tvorba: x <- c(88,5,12,13)
• Získání jednoho prvku – pomocí jeho indexu: x[2]
• Odstranění jednoho prvku – určením jeho záporného indexu: x<-x[-2]
• Získání více prvků - vektor indexů: x[c(3, 1)], x[2:4]
• Odstranění více prvků - záporný vektor indexů: x[-c(3, 1)], x[-(2:4)]
• Získání prvků na některých pozicích(o určitých indexech) - vektorem logických hodnot – TRUE (T) na jeho určité pozici navrátí, FALSE (F) na jeho určité pozici nenavrátí prvek z této pozice: x[c(TRUE, FALSE, TRUE, TRUE, FALSE) #navrátí první, třetí a čtvrtý prvek.
• Je-li tento logický vektor kratší, dochází k jeho recyklaci, je-li delší, nadbytečné prvky se nevyužijí.
• x[c(T,F)] vrací prvky vektoru x o lichých hodnotách indexů.
• Získání prvků formulací pomínky: x[conditionForElements]:

Změna hodnoty, přidání prvků do vektoru
• x[specifikace indexů] <- nové hodnoty
• Příklady na práci s vektory: • x <- c(88,-5,12,13)
• x <- c(x[1:3],168,x[4]) # insert 168 before the 13
• x[3:6] ; x[x>0]
• Počet prvků vektoru lze snadno zvětšit zadáním hodnoty do neexistujícího prvku.
• Počet prvků vektoru lze snadno změnit změnou hodnoty funkce length()
• Příklady:
> x <- c(88,5,12,13)> x[c(2,5)]<-c(10,20)> x[1] 88 10 12 13 20> x[7]<-50> x[1] 88 10 12 13 20 NA 50
> v<-c(1,5,9,7,3)> length(v)[1] 5> length(v)<-7> v[1] 1 5 9 7 3 NA NA> length(v)<-3> v[1] 1 5 9

Aplikace běžných funkcí na vektor
• > vec<-c(1,3,5,8,9)
• > sum(vec)
• [1] 26
• > mean(vec)
• [1] 5.2
• > median(vec)
• [1] 5
• > summary(vec)
• Min. 1st Qu. Median Mean 3rd Qu. Max.
• 1.0 3.0 5.0 5.2 8.0 9.0

Příklady
• Skalární součin • cena<-c(12,15,20) ; pocet<-c(10,20,25)• CelkCenaVyr<-cena*pocet• CelkCena<-sum(CelkCenaVyr)
• Udělat vektor
• Udělat vektor

Matice (dvojrozměrná pole)
• matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE, dimnames = NULL)
x<-1:5
m<-matrix(x,2)
m
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 1
> str(m)
int [1:2, 1:3] 1 2 3 4 5 1
> dim(m)
[1] 2 3
Počet řádků, sloupců, prvků
• nrow(m) ; ncol(m) ; length(m)
• > nrow(m)
• [1] 2
• > ncol(m)
• [1] 3
• > length(m)
• [1] 6
Tvorba
Obdélníkové schéma prvků téhož typu (funkce typeof() poskytuje pro všechny tyto prvky stejný výsledek)uspořádaných do m řádků a n sloupců – matice typu m x n.

Funkce dim()
• Navrací počet řádků a sloupců matice.
• Dovolí též tyto atributy matice měnit (replacement function)• Celkový počet prvků matice (určený funkcí length()) však musí být zachován
> m<-matrix(1:10, 2)
> str(m)
int [1:2, 1:5] 1 2 3 4 5 6 7 8 9 10
> attributes(m)
$dim
[1] 2 5
> dim(m)
[1] 2 5
> dim(m)<-c(5,2)> dim(m)[1] 5 2> m
[,1] [,2][1,] 1 6[2,] 2 7[3,] 3 8[4,] 4 9[5,] 5 10Co se stane, když dochází
změnou dim ke změně počtu prvků matice? Vyzkoušejte. Změnou dim() lze z vektoru udělat matici.

Matice z vektorů – cbind(), rbind()
> x<-c(5,6,9)
> y<-c(7,3,6)
> m<-cbind(x,y)
> m
x y
[1,] 5 7
[2,] 6 3
[3,] 9 6
• Na stejných vektorech vyzkoušejte funkci rbind().

Matice - subsetting• Jeden prvek
• a[1,2] # prvek z prvního řádku a druhého sloupce
• Podmatice• a[2:4,c(1,3)] # druhý až čtvrtý řádek, první a třetí sloupec
• Jeden a více řádků• a[2,] # druhý řádek, všechny sloupce• a[c(1,3),] # první a třetí řádek, všechny sloupce
• Jeden a více sloupců• a[,3] ; n<-m[,c(1,5,6)] # všechny řádky, třetí sloupec ; všechny řádky, sloupce 1, 5, 6
• Podmínky na řádky a sloupce (vyzkoušejte)• m[m[,2]>5,] ; m[m[,2]>5,m[2,]<8]• m[m[,1] > 1 & m[,2] > 5,]• n<-m[,-3]
• Případné redukci počtu dimenzí zabráníme parametrem drop=F.
> m<-matrix(1:10, 2)> m[,3] [1] 5 6> m[,3, drop=F]
[,1][1,] 5[2,] 6

Funkce apply() – operace s řádky a sloupci
> mtc<-matrix(1:10,2)
> mtc
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
> apply(mtc,1,sum)
[1] 25 30
> apply(mtc,2,sum)
[1] 3 7 11 15 19
> apply(mtc,1,mean)
[1] 5 6
> apply(mtc,2,mean)
[1] 1.5 3.5 5.5 7.5 9.5
Syntax:apply(X, MARGIN, FUN, ...)
X – maticeFUN – jméno funkceMARGIN=1 – funkce FUN pracuje s řádkyMARGIN=2 – funkce FUN pracuje se sloupci.

Matice – funkce t() a funkce summary()
> mtc<-t(mtc) # transpozice
> mtc
[,1] [,2]
[1,] 1 2
[2,] 3 4
[3,] 5 6
[4,] 7 8
[5,] 9 10
> summary(mtc) # sumární charakteristiky sloupců
V1 V2
Min. :1 Min. : 2
1st Qu.:3 1st Qu.: 4
Median :5 Median : 6
Mean :5 Mean : 6
3rd Qu.:7 3rd Qu.: 8
Max. :9 Max. :10

Řešení soustavy lineárních algebraických rovnic
• K řešení používáme funkci solve()
• Zadáme-li dva argumenty, matici soustavy a vektorpravých stran, solve() se pokusí vrátit řešení soustavy.
• Zkoušku děláme maticovým součinemmatice soustavy a vektoru řešení soustavy.
• Tento maticový součin realizujeme operátorem %*%.
> a<-matrix(c(10,2,1,-4,12,-2,5,7,14),nrow = 3)> a
[,1] [,2] [,3][1,] 10 -4 5[2,] 2 12 7[3,] 1 -2 14> b<-c(2,9,4)> solve(a,b)[1] 0.2335526 0.5115132 0.3421053> x<-solve(a,b)> a %*% x
[,1][1,] 2[2,] 9[3,] 4
Data Frames
• Data frame ~ tabulka dat
• Data frame ~ matice, jejíž sloupce mohou mít různé datové typy..
• Děláme jej funkcí data.frame().
• length(dataframe) ; names(dataframe) – počet a jména složek data.frame
> dx<-seq(0,10,0.1)> dy<-dx^2> plot(dx,dy)> df<-data.frame(dx,dy)
> dfn<-data.frame(jmena=c("Jana","Hana","Karla","Alena","Mirka"),platy=c(29000,31000,32000,35000,34500))

data.frame – důležité funkce
• Odkaz na sloupec data.frame df pomocí jména je df$jméno
• ncol(df) – počet složek – sloupců - data.frame
• nrow(df) - počet řádků data.frame
• head(df,numrows) – vrací prvních numrows řádků
• tail(df,numrows) - vrací posledních numrows řádků
• summary(df) – aplikuje funkci summary na jednotlivé sloupce df.
• names(df) – jména sloupců
• View(df) - (Rstudio) – zobrazení data.frame
• t(df) - transpozice df -> matrix
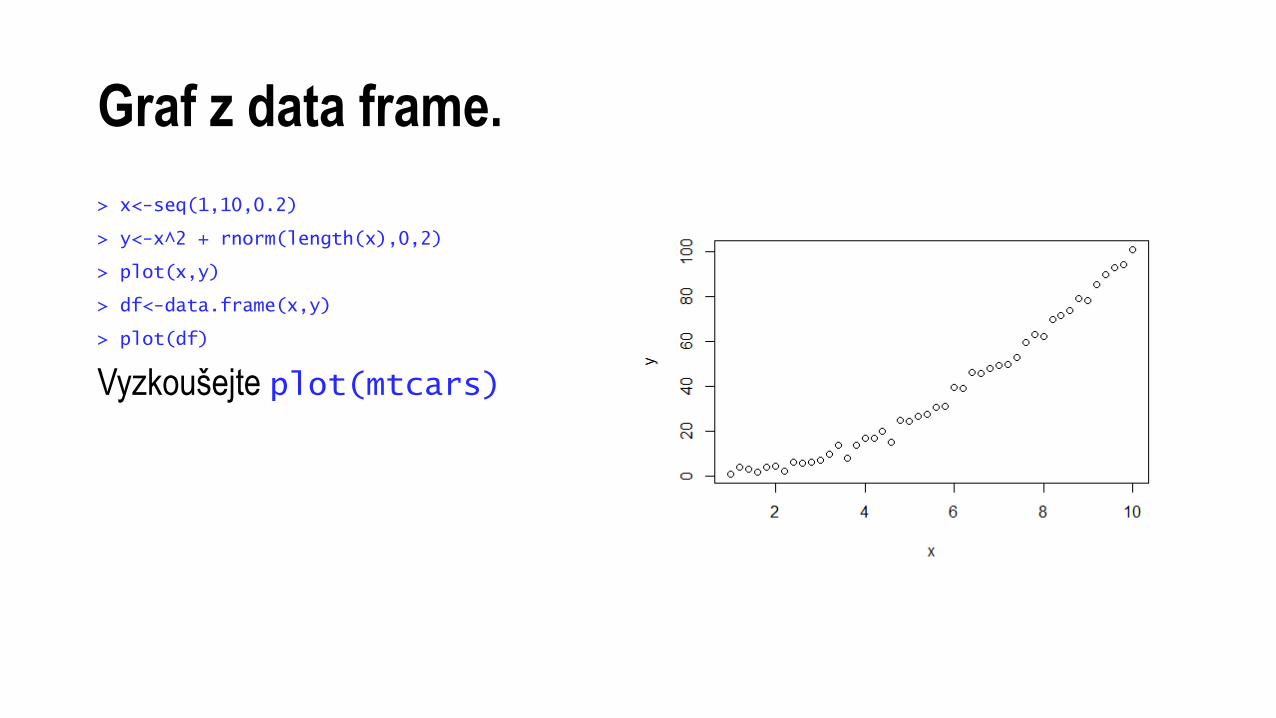
Graf z data frame.
> x<-seq(1,10,0.2)
> y<-x^2 + rnorm(length(x),0,2)
> plot(x,y)
> df<-data.frame(x,y)
> plot(df)
Vyzkoušejte plot(mtcars)

Práce s data frame - přidání, odebrání, editace
• dfm<-data.frame(a=c(2,6,7), b=c("Jan","Karel)) # ?
• dfm<-data.frame(a=c(2,6,7), b=c("Jan","Karel", "Tom"))
• # Přidání prvku
• dfm$d<-c("Hana","Jana","Berta")
• # Odebrání prvku
• dfm$b<-NULL
• # Editace hodnoty v prvku
• dfm$d[2]<-"Kamila"

Data.frame – subsetting
• Stejně jako u matic
• Navíc lze použít při referenci na sloupce jejich jmen: df$colname• str(df)
• df[,1]
• df$dx
• df[1:3,]
• df[df$dy>0 & df$dy<50,]

Souhrnné výpočty se sloupci v data.frame
• V R na tyto výpočty existuje řada funkcí. Podívejme se alespoň na funkci sapply()
• Syntax: sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE)• X – objekt s daty, často data.frame.
• FUN – název funkce, kterou děláme souhrnné výpočty.
• funkce sapply() vrací implicitně datovou strukturu vektor.
• Př: str(mtcars)
sapply(mtcars,mean)

Práce s adresáři
• getwd() - vypíše cestu k pracovnímu adresáři
• setwd(dir) - mění pracovní adresář

Čtení data.frame z textového souboru
• Comma separated values - csv soubor• read.csv(file, header = TRUE, sep = ",") # vrací data.frame
• gDatn <-read.csv('http://www.stat.ubc.ca/~jenny/notOcto/STAT545A/examples/gapminder/data/gapminderDataFiveYear.txt', header = TRUE,sep="\t")
• gDat<-read.csv("gDat.csv",header=T) # vrací data.frame
• dfn<-read.csv("Platy.csv") # vrací data.frame

Zápis data.frame do souboru
• Comma separated values - csv soubor• write.csv(gDat,"gDat.csv") # zápis data.frame do textového souboru gDat.csv, oddělovač čárka.
• Příklad> getwd() # cesta k aktuálnímu adresáři
[1] "C:/Users/Lenovo/Documents"
> write.csv(DataXY,"DataXY.csv")
> Datacsv<-read.csv("DataXY.csv") # přečtení souboru, data v objektu Datacsv, typu data.frame.
> View(Datacsv) # zobrazení dat v RStudiu.

Uložení a čtení objektu binárně
• Používáme funkce save() a load(), přípona souboru .RData.• save(ObjectNames,file=“Path/FileName.RData“) # ObjectNames - jména objektů oddělená čárkou.
• load(“Path/FileName.RData”) # načteme uložené objekty
• Př.:• save(dfn,gDat,file="C:/Users/Lenovo/Documents/data/Databin.RData")
• rm(dfn); rm(gDat)
• load("C:/Users/Lenovo/Documents/data/Databin.RData") # načteme objekty dfn,gDat.
• View(dfn)
• View(gDat)
Poznámka: v cestě k souboru třeba užívat jako oddělovače jen lomítka,zpětné lomítko chápe R jako uvození tzv. „escape sekvence“.

Lists - seznamy
• List se skládá ze složek, které mohou být navzájem různého typu i délky. Je to heterogenní datová struktura. Složky seznamu můžeme pojmenovat.
• List lze definovat jako vektor, jehož složky mohou být různého typu i délky. Děláme ho funkcí list(). Počet složek – length().
> lst<-list(vc=c(1,2,3,8,9), mn=c("Jan","Karel"), mat=matrix(1:16,2))> length(lst)[1] 3> str(lst)List of 3$ vc : num [1:5] 1 2 3 8 9$ mn : chr [1:2] "Jan" "Karel"$ mat: int [1:2, 1:8] 1 2 3 4 5 6 7 8 9 10 ...> attributes(lst)$names[1] "vc" "mn" "mat"
složky

Výpis seznamů, položky seznamůVýpis seznamu
> lst
$vc
[1] 1 2 3 8 9
$mn
[1] "Jan" "Karel"
$mat
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
[1,] 1 3 5 7 9 11 13 15
[2,] 2 4 6 8 10 12 14 16
• Subsetting pomocí $> lst$mn
[1] "Jan" "Karel”
> typeof(lst$mn)
[1] "character"
> lst$mn[2]
[1] "Karel"
> typeof(lst)
[1] "list"

Práce se složkami seznamu
> lstd<-list(vec=c(1,3,5,9), mat=m)
> sum(lstd$vec)
[1] 18
> mean(lstd$vec)
[1] 4.5
> sum(lstd$mat[1,])
[1] 64

Práce se seznamem – přidání, odebrání, editace, převod na vektorls<-list(a=c(2,6,7), b=c("Jan","Karel"))
# Přidání prvku
ls$d<-c("Hana", "Jana", "Berta")
# Odebrání prvku
ls$b<-NULL
# Editace hodnoty v prvku
ls$d[2]<-"Kamila"
# převedení na vektor funkcí unlist()
unlist(ls)
a1 a2 a3 d1 d2 d3
"2" "6" "7" "Hana" "Kamila" "Berta"

Jednoduché grafy v R
• Package graphics• plot() – bodový či čárový graf (blíže viz argument type) včetně os a popisů
• plot(x, y, ...)
• plot(funkce, from, to, …)
• points() – přidá body do hotového grafu• points(x, y = NULL, type = "p", ...)
• lines() – přidá čárový graf do hotového grafu• lines(x, y = NULL, type = "l", ...)
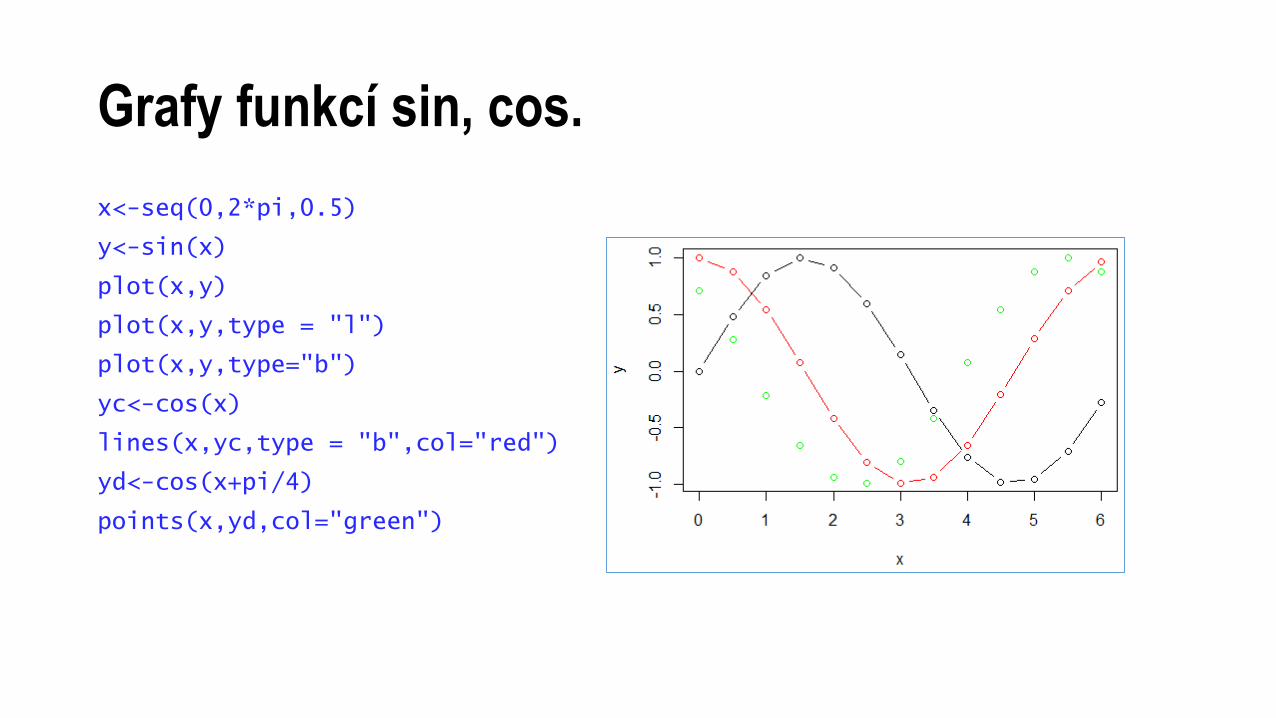
Grafy funkcí sin, cos.
x<-seq(0,2*pi,0.5)
y<-sin(x)
plot(x,y)
plot(x,y,type = "l")
plot(x,y,type="b")
yc<-cos(x)
lines(x,yc,type = "b",col="red")
yd<-cos(x+pi/4)
points(x,yd,col="green")
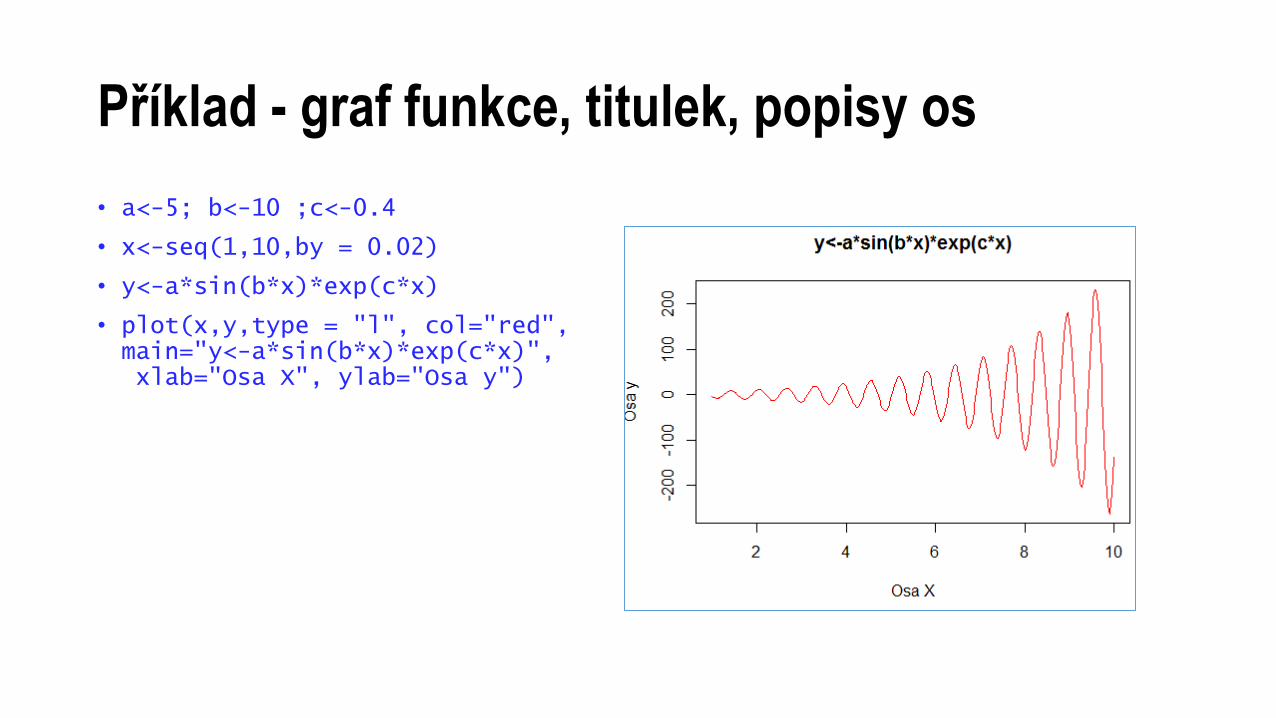
Příklad - graf funkce, titulek, popisy os
• a<-5; b<-10 ;c<-0.4
• x<-seq(1,10,by = 0.02)
• y<-a*sin(b*x)*exp(c*x)
• plot(x,y,type = "l", col="red",main="y<-a*sin(b*x)*exp(c*x)",xlab="Osa X", ylab="Osa y")

Regrese – funkce lm() – linear model
• lm(formula, data, subset, weights,…..)
• formula: y ~ model
• y – vysvětlovaná (závisle) proměnná
• model: výraz obsahující kombinaci prediktorů (vysvětlující - nezávisle proměnné)
• Regrese • lineární a nelineární v parametrech
• lineární model y = ß0f0(x) + ß1f1(x) + ß2f2(x) + ⋯ + ßmfm(x), kde ßj, j = 0,1,…,m, jsou neznámé parametry, jejichž odhady bj regresí hledáme, fj(x) nazýváme regresory.

Základní typy lineárních regresních modelů ve funkci lm().z <- lm(y ~ 1, data = mydata) # proklad konstantou – průměr
z <- lm(y ~ x, data = mydata) # obecná přímka
z <- lm(y ~ x - 1, data = mydata) # přímka procházející počátkem
z1 <- lm(y ~ x1 + x2, data = mydata) # y=a*x1+b*x2+c
z2 <- lm(y ~ x + I(x^2), data = mydata) # regresní parabola
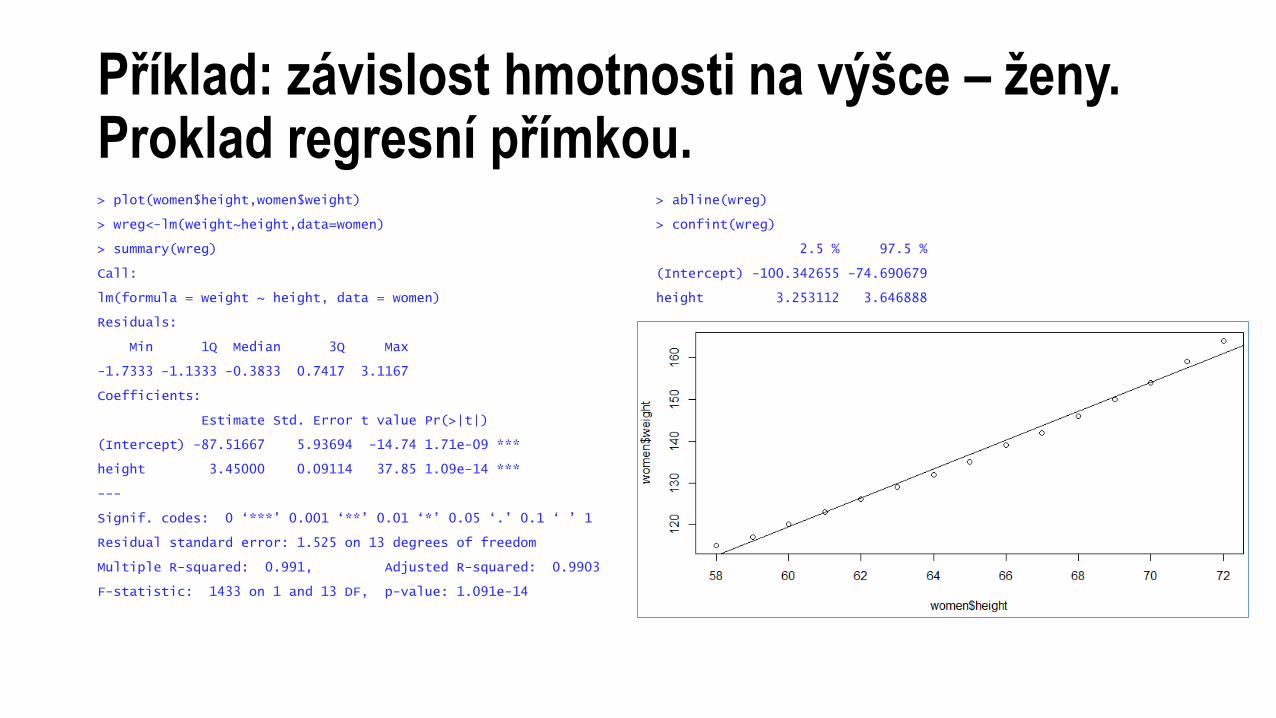
Příklad: závislost hmotnosti na výšce – ženy.Proklad regresní přímkou.> plot(women$height,women$weight)
> wreg<-lm(weight~height,data=women)
> summary(wreg)
Call:
lm(formula = weight ~ height, data = women)
Residuals:
Min 1Q Median 3Q Max
-1.7333 -1.1333 -0.3833 0.7417 3.1167
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -87.51667 5.93694 -14.74 1.71e-09 ***
height 3.45000 0.09114 37.85 1.09e-14 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.525 on 13 degrees of freedom
Multiple R-squared: 0.991, Adjusted R-squared: 0.9903
F-statistic: 1433 on 1 and 13 DF, p-value: 1.091e-14
> abline(wreg)
> confint(wreg)
2.5 % 97.5 %
(Intercept) -100.342655 -74.690679
height 3.253112 3.646888
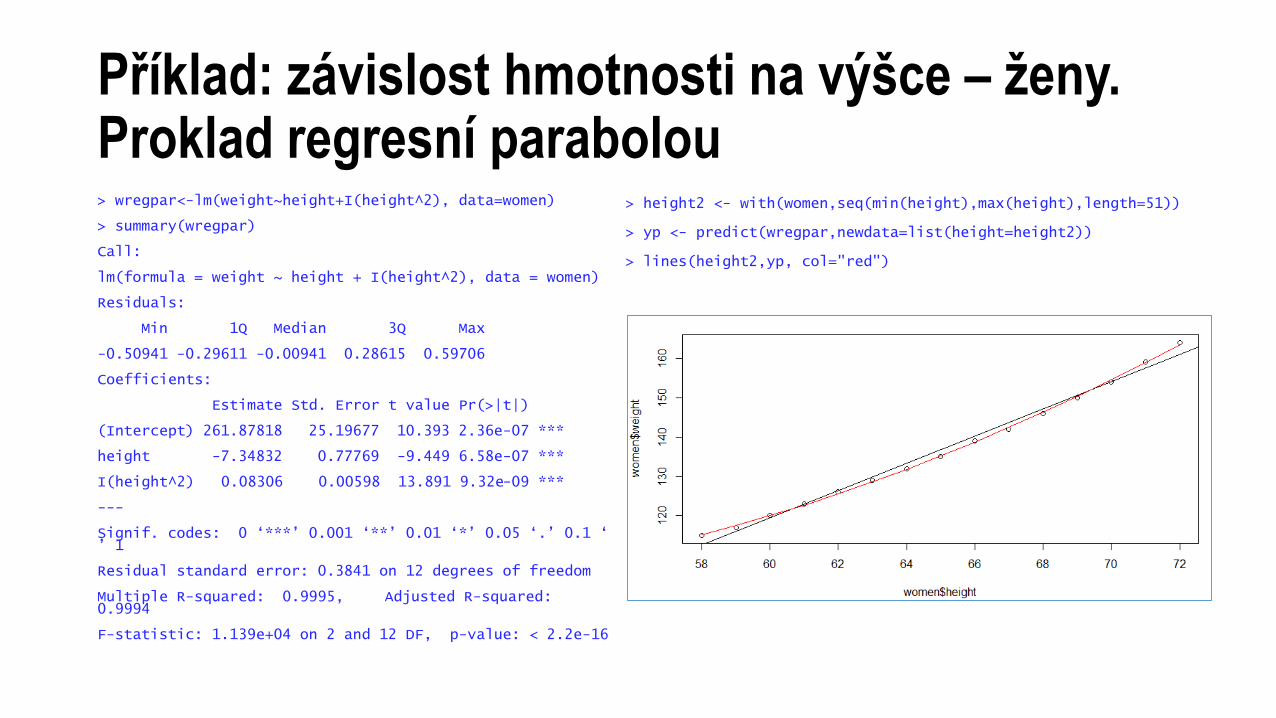
Příklad: závislost hmotnosti na výšce – ženy.Proklad regresní parabolou> wregpar<-lm(weight~height+I(height^2), data=women)
> summary(wregpar)
Call:
lm(formula = weight ~ height + I(height^2), data = women)
Residuals:
Min 1Q Median 3Q Max
-0.50941 -0.29611 -0.00941 0.28615 0.59706
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 261.87818 25.19677 10.393 2.36e-07 ***
height -7.34832 0.77769 -9.449 6.58e-07 ***
I(height^2) 0.08306 0.00598 13.891 9.32e-09 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3841 on 12 degrees of freedom
Multiple R-squared: 0.9995, Adjusted R-squared: 0.9994
F-statistic: 1.139e+04 on 2 and 12 DF, p-value: < 2.2e-16
> height2 <- with(women,seq(min(height),max(height),length=51))
> yp <- predict(wregpar,newdata=list(height=height2))
> lines(height2,yp, col="red")

RProject
• Zpracováváme-li v RStudiu velký celek, vyplatí se pro něj udělat příkazem File/New Project… nový projekt.
• Často volíme pro projekt nový adresář, do kterého se ukládají data projektu.
• RStudio vytvoří v adresáři projektu souborProjectName.Rproj.
• Tento soubor obsahuje důležité volby určujícíchování RStudia při práci s projektem.
• Rproj soubor je asociován RStudiu. To znamená, že poklepáním na něj ve správci souborů (průzkumníku Windows) spouštíme RStudio, které otevírá náš projekt.
• Projekt lze zavřít příkazem File/Close Project, který končí příslušný R proces.
• Projekt lze otevřít příkazem File/Open Project, startující nový R proces.
• Vlastnosti projektu lze měnit v okně příkazu Tools/Project Options. Více se o RProjektech můžeme dočíst na https://support.rstudio.com/hc/en-us/articles/200526207-Using-Projects.

















