22
Projekt RAINBOW vícecestná extrakce informací z webu Vojtěch Svátek Seminář KEG, 6.11.2002
| Date post: | 31-Dec-2015 |
| Category: |
Documents |
| Upload: | chiquita-clayton |
| View: | 20 times |
| Download: | 0 times |

Projekt RAINBOWvícecestná extrakce informací z webu
Vojtěch SvátekSeminář KEG, 6.11.2002

Osnova
• Historie (a prehistorie) projektu• Popis současného stavu• SWOT analýza projektu• Možné směry do budoucna

Historie a prehistorie
• Prehistorie– studie o inteligentních systémech a Internetu (1998)– metavyhledávací systém VŠEvěd (1998-1999)– experimenty s analýzou URL (1999-2000)
• Historie– diskuse o vícecestné analýze WWW (1999-2001)– implementace infrastruktury (2000-2002)– “jednoúlohová” aplikace M. Vacury (2000-2002)– experimenty s lingvistickou analýzou (2001 -2002)

Inteligentní systémy a internet
• P. Berka, jaro 1998• Studie přístupná na http://lisp.vse.cz/~berka/ai-inet.htm– vyhledávací a metavyhledávací systémy– navigační asistenti– …
• Východisko pro vlastní vývoj...

Metavyhledávací systém VŠEvěd
• Webová část realizována skripty v PERLu (M. Sochorová, 1998)– Předání dotazu více vyhledávačům– Extrakce výsledků (“screen-scraping”)
• “Znalostní” sloučení a přeuspořádání výsledků realizováno v CLIPS (P. Berka, 1999)– uspořádání podle “relevance”– seskupení podle kategorií
(ne tématických, ale “typů” stránek!)– doplnění z vlastní báze “případů”
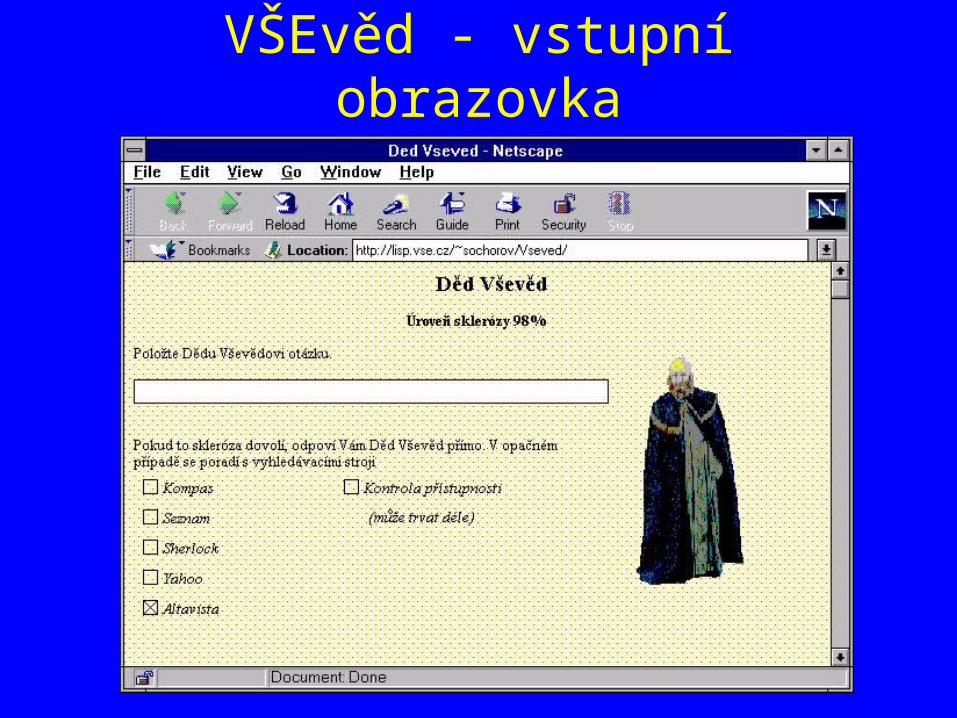
VŠEvěd - vstupní obrazovka
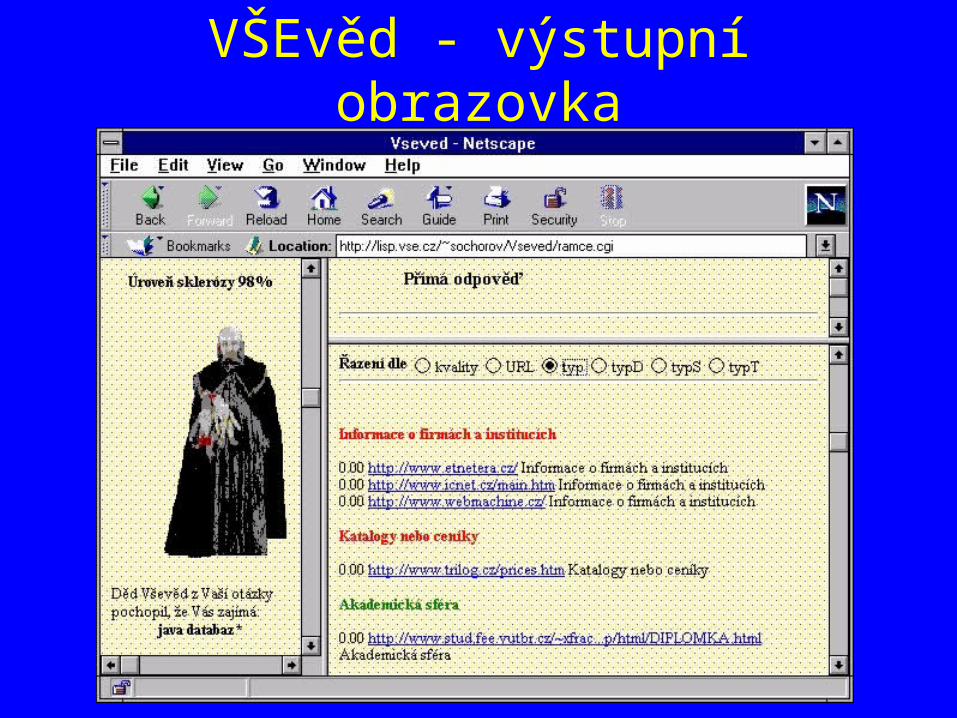
VŠEvěd - výstupní obrazovka

Analýza URL
• Původně vyvinuta pro seskupování ve VŠEvědu, aplikace v CLIPS (P. Berka)
• Sleduje výskyt řetězců v jednotlivých částech URL (zvl. “directory” a “filename”)
• Frekvenční analýza řetězců v rozsáhlém souboru URL; rozpoznávání oddělovačů (V. Svátek)
• Desambiguace řetězců typu “art”, “pub”..., pomocí dalších informací z vyhledávače (induktivní logické programování - M. Kavalec)
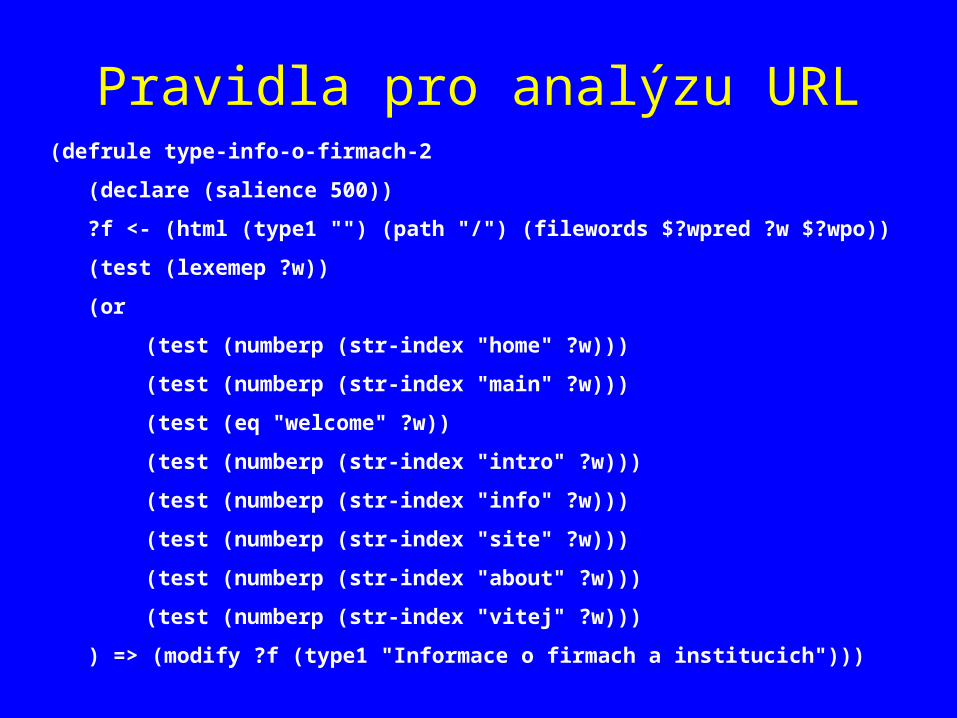
Pravidla pro analýzu URL(defrule type-info-o-firmach-2
(declare (salience 500))
?f <- (html (type1 "") (path "/") (filewords $?wpred ?w $?wpo))
(test (lexemep ?w))
(or
(test (numberp (str-index "home" ?w)))
(test (numberp (str-index "main" ?w)))
(test (eq "welcome" ?w))
(test (numberp (str-index "intro" ?w)))
(test (numberp (str-index "info" ?w)))
(test (numberp (str-index "site" ?w)))
(test (numberp (str-index "about" ?w)))
(test (numberp (str-index "vitej" ?w)))
) => (modify ?f (type1 "Informace o firmach a institucich")))

Rozšíření záběru...
• Analýza URL a výstřižku někdy překvapivě úspěšná, má však vždy meze...
• Analýza plného obsahu stránek zajímavější, ovšem pomalejší přechod od metavyhledávacího přístupu k off-line analýze, zvl. celých websites!
• Zpočátku velmi “bezbřehé ” úvahy...

RAINBOW - hlavní principy
• Oddělená analýza různých typů dat– URL: řetězce v jednoduché lineární struktuře– HTML: stromová struktura elementů +
atributy– metadata (META, RDF): slova a fráze
v částečně formalizované struktuře– volný text: struktura vět přirozeného jazyka– odkazová struktura: orientovaný graf– obrázky: bitové mapy (histogramy) atd.

RAINBOW - hlavní principy (2)
• Předávání zpráv mezi nezávislými moduly– technologie webových služeb (WSDL,SOAP)– model “objekt-třída-obsah”
• Základní operace:– vyhledání objektu– určení třídy objektu – extrakce textového obsahu objektu

RAINBOW - scénář použití
• Extrakce “implicitních metadat” o firmě a její nabídce zboží/služeb:– Analýza URL a topologie navede na stránku
s cílovými informacemi– Analýza HTML, metadat a volného textu
detekuje a oklasifikuje cílové informace
• Efektivní práce předpokládá propojení s primárním vyhledávačem (podle klíčových slov)

Implementace (jaro 2002)
• Stahování, konverze, ukládání a poskytování zdrojových dat (J. Kosek)
• Komunikační infrastruktura (J. Kosek)• Analýza volného textu - extrakce vět
(M. Kavalec)• Extrakce obsahu META tagů (P. Kupka)• Vizualizace výsledků (J. Kosek)
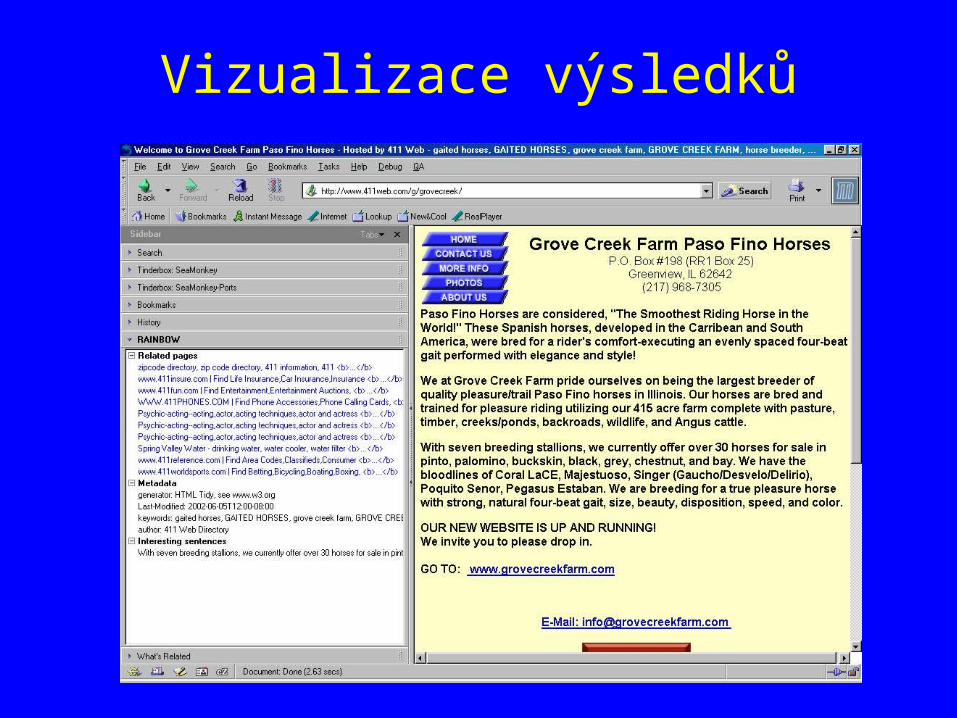
Vizualizace výsledků

Další výstupy z projektu
• Metoda učení “indikativních termínů” ve větě, využívá webový adresář (M. Kavalec, V. Svátek)
• Formální ontologie webových objektů (V. Svátek)
• Soubor programů pro vícecestné rozpoznávání pornografie na WWW (M. Vacura)
• Typologie zajímavých struktur v kódu HTML (J. Klemperer)
• DP o možnostech analýzy topologie odkazů (M. Sajal)

SWOT Analýza (S)
• Problematika vnímána jako aktuální– využití redundance informací na WWW– možnost flexibilního vývoje z komponent
• Získán široký přehled o souvisejícím výzkumu ve světě, navázány kontakty
• Přiměřeně velký a vyvážený tým– znalostní inženýrství (ontologie, PSM, IE)– datové inženýrství (značkovací jazyky,
webové technologie)– strojové učení a data mining

SWOT Analýza (W)
• Neexistuje (zatím) jednotící teorie• Reálně implementována jen velmi malá
část• Chybí grantová podpora (?)• Chybí potenciální “zákazník”, otázka je,
zda se v tuzemsku někdy najde...– většina problémů se asi dá s přijatelnou
kvalitou řešit běžnými prostředky...

SWOT Analýza (O)
• Možnost vzniku mezinárodních publikací a slušně vypadajících disertací (a diplomek)
• Aktivní zapojení do mezinárodních grantů včetně finančního přínosu

SWOT Analýza (T)
• Soubor nesystematických ad hoc řešení, tudíž bez vědeckého přínosu
• Řešení “od zeleného stolu”, odtržené od reality
• Řešení nekompatibilní s používanými standardy
• Vývoj tak zdlouhavý, že se mezitím podoba internetu zásadně změní

Navrhované další kroky
• Vytvoření referenčního vzorku dat, učení a/nebo ověřování dílčích bází znalostí na nich
• Slučování ontologií na podkladě referenčních dat
• Popsání reálných scénářů extrakce informací pomocí abstraktního modelu
• Využívání zkušeností a nástrojů nad XML/RDF• Propojení se “standardním” fulltextovým
systémem (AmphorA, VŠB-TU Ostrava)• Vybudování solidní teorie pro část
problematiky

Další informace
• “Oficiální” stránka projektu RAINBOWhttp://rainbow.vse.cz resp. http://nb.vse.cz/~svatek/rainbowvč. plných textů publikovaných článků
• Diplomka J. Koskahttp://www.kosek.cz/diplomkavč. dokumentace k implementaci a návodu pro vývoj dalších komponent

















