Gottfried Wilhelm Leibniz Universität Hannover Fakultät für Elektrotechnik und Informatik Institut für Praktische Informatik Fachgebiet Software Engineering Extraktion und Visualisierung ortsbezogener Informationen mit Tag-Clouds Bachelorarbeit im Studiengang Informatik von Oliver Flohr Prüfer: Prof. Dr. Kurt Schneider Zweitprüfer: Prof. Dr.-Ing. habil. Monika Sester Betreuer: M.Sc. Tristan Wehrmaker, M.Sc. Daniel Eggert Hannover, 18.08.2011
Transcript
Gottfried Wilhelm
Leibniz Universität Hannover
Fakultät für Elektrotechnik und Informatik
Institut für Praktische Informatik
Fachgebiet Software Engineering
Extraktion und Visualisierungortsbezogener Informationen mit
Tag-Clouds
Bachelorarbeit
im Studiengang Informatik
von
Oliver Flohr
Prüfer: Prof. Dr. Kurt Schneider
Zweitprüfer: Prof. Dr.-Ing. habil. Monika Sester
Betreuer: M.Sc. Tristan Wehrmaker, M.Sc. Daniel Eggert
Hannover, 18.08.2011
Zusammenfassung
Informationen so aufzubereiten, dass sie für eine bestimmte Situation nützlich sind, isteine große Herausforderung. In solchen Situationen soll ein Benutzer, wenn er sich aneinem fremden Ort befindet, mit Hilfe des Android Smartphone interessante und wis-senswerte Informationen anzeigen lassen. Um dies bewerkstelligen zu können, musses eine georeferenzierte Informationsquelle geben. Außerdem muss ein Konzept vor-handen sein, um diese Daten zu sammeln und so aufzubereiten, dass der Benutzerdiese auch nützlich findet. Es muss eine Visualisierung dieser Daten geben, da derPlatz zur Anzeige auf Smartphones sehr begrenzt ist.
Als georeferenzierte Informationsquelle wird die Online-Enzyklopädie Wikipedia ge-nutzt, diese ist frei zugänglich und auch sehr umfassend. In dieser Arbeit wird dasKonzept zur Sammlung und Aufbereitung von relevanten Daten behandelt. Zur In-formationsvisualisierung wird die Methode der Schlagwortwolke (engl. Tag-Cloud)verwendet.
ii
Abstract
It is a major challenge to prepare useful information for a particular situation. In thissituation an Android smartphone user wants to display interesting and important factsabout an unknown place. To manage this task existence of a geo-referenced source ofinformation has to be ensured. In order to collect and prepare this data a creation ofconcept is needed. Due to limited display space, it is necessary to construct a suitablevisualization of this data.
Wikipedia is used as a geo-referenced information resource, because it has open-accessand it offers global geo-referenced information. This thesis covers the concept of col-lecting and preparing relevant data. To visualize information a tag cloud is used.
iii
Danksagung
Ich danke allen, die mich beim Erstellen dieser Arbeit unterstützt haben. Insbesonderedanke ich M.Sc. Tristan Wehrmaker und M.Sc. Daniel Eggert für die hervorragendeBetreuung.
Mobile Geräte wie Smartphones, Mobiltelefone, Netbooks und Tablets sind in unse-rer Zeit unerlässlich. Egal ob man sich zu einem Treffen verabreden, die neuesten In-formationen erfahren oder sich einfach nur unterwegs beschäftigen will. Durch dasmobile Internet wird dieser Aufschwung noch verstärkt, da man jederzeit verfüg-bar sein kann. Jedes dieser mobilen Geräte kann mehrere Sensoren (GPS-, Gyroskop-,Kompass-, Beschleunigungs- oder Lichtsensor) haben und jedes mobile Geräte benö-tigt ein Betriebssystem. Für viele dieser Betriebssysteme können Anwendungen (so-genannte Apps) geschrieben werden, die dann auf dem Handy laufen.
Viele Informationen sind im Internet vorhanden. Wenn man unterwegs ist, dann ver-fügt man meistens nicht über Informationen der näheren Umgebung. Hier lässt sichdurch GPS und das mobile Internet Abhilfe schaffen. Dabei ist Wikipedia eine Mög-lichkeit um an Informationen zu gelangen. Von 1.255.130 deutschsprachigen Artikelnsind 207.872 geo-referenziert (Stand 27.05.2011) [Wik11]. Da das Display von solchenGeräten sehr klein ist, muss die Visualisierung der Informationen so aufbereitet wer-den, dass diese gut erkennbar bleiben. Hier bietet es sich an, die Technik der Tag-Clouds zur Visualisierung zu verwenden.
1.2. Ziel dieser Arbeit
Im Rahmen der Arbeit soll ein Konzept entwickelt und implementiert werden, dasentlang einer Route raumbezogene Informationen aus verschiedenen Quellen abfragt(Wikipedia, Flickr). Diese sollen inhaltlich gefiltert und als Tag-Clouds visualisiertwerden. Um das Ziel erreichen zu können, muss sich zu Beginn in einen bestehendenPrototypen des Instituts für Kartographie und Geoinformatik eingearbeitet werden.Im praktischen Teil dieser Arbeit soll dann die Umsetzung der Konzepte auf Basisdes zur Verfügung gestellten Prototypen erfolgen. Des Weiteren sollen Erweiterungs-möglichkeiten untersucht werden (etwa die Integration mit Kartendarstellungen oderIntegration von Bilddaten). Abschließend soll geprüft werden, ob die Umsetzung alsRESTful Webservice sinnvoll ist, um so auch anderen Endgeräten Zugriff auf die ent-wickelten Mechanismen zu geben.
1
1. Einleitung
1.3. Struktur dieser Arbeit
Diese Bachelorarbeit besteht aus fünf Kapiteln. In Kapitel 1 wird in einer Einleitungdas Thema näher gebracht.
Kapitel 2 beschäftigt sich mit den Grundlagen, die nötig sind, um das Konzept verste-hen zu können. Dabei wird die Android-Entwicklungsumgebung behandelt. Dann aufden Begriff Tag-Cloud und deren Darstellungsarten eingegangen. Zum Schluss wirdder Softwarearchitekturstil REST abgehandelt.
In Kapitel 3 wird der bestehende Prototyp analysiert. Dabei wird der Konzeptansatzund dann der strukturelle Aufbau des Prototypen besprochen.
Die nachfolgenden Kapitel beschäftigen sich mit dem Kern dieser Arbeit. Dabei wirdsich in Kapitel 4 mit den Filtern auseinandergesetzt. Es werden die eingesetzten Filterund deren benötigten Voraussetzungen zur Realisierung beschrieben.
Danach folgt in Kapitel 5 die Visualisierung der Tag-Cloud. Dabei wird auf die An-wendungsoberfläche und die Farbwahl eingegangen.
In Kapitel 6 wird der Web-Service abgehandelt. Es wird der eigene Web-Service, einemögliche REST Implementierung, die Route zwischen zwei Punkten näher betrachtetund danach werden weitere Quellen für die Schlagwörter der Tag-Cloud untersucht.
In Kapitel 7 wird die Implementierung des Konzeptes umgesetzt. Der erste Abschnittdes Kapitels befasst sich mit der Architektur. Im darauf folgenden Abschnitt wirddas Client-Server-Modell beschrieben. Die nächsten Abschnitte beschäftigen sich mitder Umsetzung der Filterung, der Visualisierung und dem Routen Web-Service. ZumSchluss werden sonstige Anpassungen am Prototypen geschildert.
Abschließend werden in Kapitel 8 die wichtigsten Ergebnisse dieser Arbeit zusam-mengefasst, ein Fazit über die Arbeit abgegeben und ein Ausblick auf zukünftige Er-weiterungen und Ansätze gegeben.
2
2. Grundlagen
In diesem Kapitel werden die Grundlagen zur Bearbeitung der Aufgabe näher be-trachtet. Dabei wird zuerst auf das zugrunde liegende Betriebssystem eingegangen.Als nächstes werden der Begriff Tag-Cloud und die Arten der Darstellung beschrie-ben. Zum Schluss wird der Softwarearchitekturstil REST näher betrachtet, mit der eineeinheitliche Schnittstelle umgesetzt werden kann.
2.1. Android
Google gründete die Open Handset Alliance1. Diese ist ein Zusammenschluss vonüber 80 Firmen, zur Schaffung von offenen Standards für Mobilgeräte. Die Open Hand-set Alliance war an der Wertentwicklung von Android beteiligt. Android ist eine Platt-form und ein Betriebssystem für mobile Geräte. Durch die offene Entwicklungsum-gebung und die gute Dokumentation kann jeder Programmierer Anwendungen fürAndroid in der Programmiersprache Java schreiben.
Der Aufbau der Android-Architektur ist klar abgegrenzt. Die einzelnen Komponentensind dabei folgende[Bec10]:
• Die Activity ist der sichtbare Teil einer Anwendung. Vergleichbar mit der Viewaus dem Design Pattern MVC.
• Der Service erledigt Hintergrundprozesse und ist damit Vergleichbar mit demController.
• Der Content Provider verwaltet Daten und abstrahiert die darunter liegendePersistenzschicht und ist damit Vergleichbar mit dem Model.
• Der Broadcast Receiver empfängt Systemnachrichten, z.B. Störungen oder schwa-chen Akku.
• Die Intents tauschen Daten zwischen den Komponenten aus.
• Die Views sind einzelne User Interface Komponenten, z.B. Table, List, Grid, etc.
• Der Resource Manager greift auf Non-Code Ressourcen einer Anwendung zu,z.B. Bilder oder Strings.
• Der Notification Manager leitet Signale von Ereignissen an den Benutzer weiter,wie z.B. Vibration oder eine Tonausgabe.
Die Systemarchitektur ist in mehreren Schichten aufgebaut [Bec10], wie in Abbildung2.1 zu sehen ist.
In der untersten Schicht wird ein Linux-Kernel Version 2.6 für die Hardware Kompo-nenten verwendet. In der darüber liegenden Schicht werden die Android-Laufzeitumgebungmit der Dalvik Virtual Machine und die Bibliotheken für grundlegende Funktionalitä-ten, z.B. Datenbanken, Netzwerkzugriff, 3D-Grafik verwendet. Der Anwendungsrah-men stellt die oben genannten Komponenten zur Verfügung. Auf der obersten Schicht,der Anwendungsschicht, werden nun Standard- und selbst geschriebene Anwendungenbereitgestellt.
Abbildung 2.1.: Die Android Systemarchitektur nach [Bec10]
4
2. Grundlagen
2.2. Tag-Cloud
In diesem Kapitel wird der Begriff Tag-Cloud und dessen Herkunft beschrieben. Dannwerden die verschiedenen Visualisierungsformen der Tag-Cloud abgehandelt und zumSchluss wird die Berechnung der Gewichtung erläutert. Ein Beispiel für eine Tag-Cloud befindet sich in Abbildung 2.2
baby band barcelona california canada
canon germany nikon
snowrock
parisdance me
tokyo watertexas vacationsky
Abbildung 2.2.: Beispiel einer Tag-Cloud
Mobilgeräte sind meist sehr klein und haben dadurch auch nur einen kleinen Bild-schirm. Deshalb müssen auf wenig Raum viele Informationen angezeigt werden kön-nen. Dafür bietet sich eine Tag-Cloud an. Eine Tag-Cloud (zu Deutsch: Schlagwort-oder Stichwortwolke) ist eine Visualisierungs- und Navigationsform im Web 2.0, diedurch Flickr1 und delicious2 bekannt geworden ist. Eine Tag-Cloud ist eine zweidi-mensionale gewichtete Liste, in der eine bestimmte Teilmenge von Tags angezeigtwird. Die Popularität eines Tags wird über dessen Schriftgrad (relativ zu den ande-ren Tags) abgebildet. Tags sind meist über Hyperlinks mit den Ressourcen verbunden,die sie beschreiben [Loh09].
2.2.1. Gestaltung
Da die Tag-Cloud eine Visualisierungstechnik ist, ist die Gestaltung der Tag-Cloud einwichtiger Aspekt dieser Arbeit. Hierzu gibt es verschiedene Ansätze, die in [Loh09]untersucht wurden. Dabei wurden die verschiedenen Nutzerziele ermittelt. Nutzer-ziele sind Absichten, die ein Nutzer hat, wenn er eine Tag-Cloud benutzen will. DieErgebnisse der Untersuchung aus [Loh09], die hier verwendet werden, wurden durchEyetracking, Zeitmessung und Nutzerbewertung ermittelt. Deshalb wird zuerst aufdie Art der Gestaltung eingegangen und danach auf das jeweilige Nutzerziel.
Es werden vier Arten der Gestaltung in der Abbildung 2.3 näher betrachtet [Loh09]:
Abbildung 2.3.: Für den Korpus Frankreich erstellte Tag-Clouds: a) Sequentielles Layout(alphabetische Sortierung), b) Zirkuläres Layout (abnehmende Popularität), c) Cluster-Layout (Themencluster), d) Referenzdarstellung (sequentiell, alpha. Sortierung, keineGewichtung der Tags) nach [Loh09].
a) Sequentielles Layout
Das Sequentielle Layout hat eine horizontale oder vertikale Ausrichtung der Tags undkann nach verschiedenen Kriterien (z.B. Alphabetisch, nach Popularität oder Chro-nologie) sortiert werden. Dabei werden die Gewichtungen der einzelnen Tags durchverschiedenen Schriftgrößen dargestellt. Das Ziel des Nutzers ist es einen bestimmtenTag schneller finden zu können.
b) Zirkuläres Layout
Das Zirkuläre Layout beginnt im Mittelpunkt mit den populärsten Tags, also den Tags,die am größten gewichtet sind und geht absteigend in Richtung der Ränder. Dabeiwird weniger auf die alphabetische Reihenfolge geachtet, sondern nur auf die Tagsmit den größten Gewichten, die vom Zentrum nach außen absteigend sortiert werden.Das Nutzerziel ist es die populärsten Tags schnell finden zu können.
6
2. Grundlagen
c) Cluster-Layout
Beim Cluster-Layout werden die thematische Verwandtschaften der Tags ermittelt undähnliche Tags räumlich näher zueinander positioniert. Dabei muss es zu den Gewich-ten, den Links und den Namen der Tags noch eine thematische Zuordnung geben.Diese ist bei sehr vielen Quellen für Tags nicht gegeben. Das Nutzerziel hierbei ist,Tags zu einem bestimmten Thema schneller finden zu können.
d) Referenzdarstellung
Die Referenzdarstellung ist eine ganz normale alphabetische Darstellung der Tags. Da-bei werden die Gewichte nicht beachtet, sodass jeder Tag die gleiche Schriftgröße be-sitzt. Diese Art der Gestaltung dient als Vergleich zu den anderen drei Arten der Ge-staltung. Aus der Untersuchung von [Loh09] ging hervor, dass es zu dieser Darstel-lung keine besonderen Nutzerziele gab.
Außerdem zeigten sich folgende Beobachtungen über alle Layouts [Loh09]:
• Große Tags ziehen die Aufmerksamkeit an sich.
• Tags im linken, oberen Quadranten erhalten im Vergleich die meiste Aufmerk-samkeit.
• Der Schwerpunkt der Aufmerksamkeitsverteilung liegt meist in der Mitte derTag-Cloud.
2.2.2. Berechnung der Gewichtung
Jede Schriftgröße eines Tags wird anhand seiner Gewichtung berechnet. Dabei spielennoch andere Faktoren zur Berechnung der Schriftgröße eine Rolle. Die Schriftgrößewird nach folgender Formel berechnet [Wäs10]:
Die Schriftgröße (Formel 2.1) für ein Tag i, wird aus einer Anfangsschriftgröße Min-
FontSize und aus dem Produkt des Vergrößerungsfaktor IncreaseFactor und dem Ge-wichtungsfaktors Weight erzeugt.
Weight(i) =⌈
fi − fmin
fmax − fmin
⌉
(2.2)
wobei Weight(i) der Gewichtungsfaktor für Tag i, fi die Häufigkeit dieses Tags, fminder niedrigste vorkommende Häufigkeitswert und fmax der höchste ist.
7
2. Grundlagen
2.3. Representational State Transfer (REST)
Der Representational State Transfer ist ein Softwarearchitekturstil für verteilte Hyper-media-Informationssysteme. Der Begriff REST wurde von Roy Fielding in seiner Dis-sertation im Jahr 2000 geprägt [Fie00]. Die Grundlage für REST bilden Ressourcen, dievom Server verwaltet werden. Die Ressourcen werden durch URIs1 eindeutig iden-tifiziert und vom Client als Repräsentation der jeweiligen Ressource über den URIabgerufen.
Grundprinzipien
Die Grundprinzipien werden zur Verdeutlichung durch ein Beispiel veranschaulicht.Die Grundprinzipien von REST sind [Til09]:
Ressourcen mit eindeutiger Identifikation
Ressourcen sind eindeutig identifizierbar über ein URI. Dabei stellt der URI sicher,dass auf eine Ressource von einer Vielzahl von Clients zugegriffen werden kann. Einekonsistente Adressierbarkeit erleichtert es, einen Webservice für andere Anwendun-gen anzubieten.
Ein paar Beispiele für sinnvolle URIs: [Til09]
http://example.com/orders?year=2008
http://example.com/customers/1234
http://example.com/products/4554
Bei REST ist es nicht wichtig, wie die URIs aufgebaut sind. Man sollte auf eine sinn-volle und einheitliche Struktur achten.
Beispiel:
Bei Amazon stellt jedes Produkt eine Ressource, mit einer eindeutigen URI dar. Sokönnen Links zu verschiedenen Produkten gespeichert werden, indem man sich derenURI speichert.
Verknüpfungen/Hypermedia
Ressourcen können miteinander verknüpft werden [Til09]. Das ist ein Vorteil am Web,dabei ist noch wichtiger, dass die Steuerung des Applikationsflusses richtig verwendetwird. Bei den Hypermedia werden Ressourcen anwendungsübergreifend verknüpft.Dadurch können alle Ressourcen die im Web existieren miteinander verknüpft wer-den.
1Uniform Resource Identifier ist ein ID die zur Identifizierung einer Ressource verwendet wird, Def.RFC 3986
8
2. Grundlagen
Beispiel:
Bei Amazon kann ein Produkt (eine Ressource) auf mehrere weitere Ressourcen ver-linkt werden. Zum Beispiel das Produkt mit den Produktinformationen ist eine Res-source. Dann könnte eine weitere Ressource die Produktbeschreibung sein und ei-ne weitere die Kundenrezensionen zu diesem Buch. Ein Beispiel für eine Verlinkungkönnte wie folgt aussehen [Til11]:
<order s e l f = ’ ht tp :// example . org/0E6C2BC1094C ’ ><item>
<amount>23</amount><product r e f = ’ ht tp ://amazon . com/products/A31138B3 ’ />
</item><customer r e f = ’ ht tp :// example . net /4E8F−891D’ />< l ink r e l = ’ items ’ r e f = ’ ht tp :// example . com/EFDBE4A38931 ’ />
</order>
Standardmethoden
Die Standardmethoden sind GET, POST, PUT, DELETE [Til09]. Bei der GET-Methodewird eine Repräsentation, eine Darstellung der Ressource, vom Server angefordert.Dabei ist die GET-Methode sicher, das bedeutet das man keine Verpflichtungen beimAufruf eingeht. GET ist idempotent, das bedeutet, dass man die Methode beliebig oftausführen kann und immer die gleichen Ergebnisse zurückbekommen kann. Die Me-thoden PUT und DELETE sind auch idempotent. Bei PUT wird eine Ressource ange-legt oder geändert. Bei DELETE eine angegebene Ressource gelöscht. POST schicktan den Server eine Menge an Daten zu weiteren Verarbeitung. Dadurch können neueRessourcen entstehen oder bestehende geändert werden.
Beispiel:
GET Anfrage übermitteln [Til11]:
GET /people /{ id }/ t i m e s l o t s ? s t a t e = f r e eHost : example . com
Unterschiedliche Repräsentationen
Eine Ressource ist auf dem Server verfügbar [Til09]. Wenn nun ein Client vom Servereine Ressource anfordert, bekommt er eine Repräsentation dieser Ressource zurück.Dabei gibt der Client an, welches Format er gerne für die Repräsentation hätte.
9
2. Grundlagen
Beispiel:
GET /customers /0000 HTTP/1.1Host : example . comAccept : a p p l i c a t i o n /xml ; t e x t /html
Durch eine GET-Methode übermittelt der Server dem Client eine Repräsentation derRessource, je nachdem welches dieser bereitstellt, entweder ein XML-Format oder einText-Format.
Beispiel: Es sollen Informationen von einem Buch abgefragt werden. Der Client akzep-tiert nur das XML-Format. Die Ressource (das Buch) liegt auf dem Server und wirdnun vom Client mit einer GET-Methode aufgerufen. Bei der GET-Anfrage stellt derServer fest, dass der Client nur das XML-Format akzeptiert. Also übermittelt der Ser-ver dem Client die XML Repräsentation dieser Ressource.
Statuslose Kommunikation
Das letzte Prinzip ist die statuslose Kommunikation [Til09]. Statuslos bedeutet, dassClient und Server strikt voneinander getrennt sind. Eine Anfrage vom Client an denServer wird nicht gehalten und ist damit in sich geschlossen. Ein weiterer Vorteil istdie dadurch entstandene Skalierbarkeit. Anfragen können ganz einfach auf mehrereServer verteilt werden, da es keine Sitzungsverwaltung gibt. Den Status kann man mitCookies auf der Client-Seite halten. Dies ist aber nicht empfehlenswert. Deshalb sollteman besser eine eigene Ressource erschaffen die den Status repräsentiert.
Beispiel: Der Warenkorb bei Amazon ist ein klassisches Beispiel. Dieser wird zu einereigenen Ressource, sodass man den Warenkorb jederzeit abrufen kann.
10
3. Prototypenanalyse
Vom Institut für Kartographie und Geoinformatik (kurz ikg) wurde ein Prototyp be-reitgestellt, der nachfolgend analysiert wird. Zuerst wird der Konzeptansatz zur Tag-Cloud Visualisierung näher erläutert. Dieser ist schon im Prototypen umgesetzt wor-den und wird in den nächsten Kapiteln erweitert. Dann folgt der strukturelle Aufbaudes Prototypen. Dieser wird anhand von zwei Paketdiagrammen gezeigt, die aus einerClient- und Server-Seite bestehen. Nach dem Aufbau wird in einen neuen Abschnittuntersucht, ob es sinnvoll ist den Prototypen weiterzuentwickeln.
3.1. Konzeptansatz
Das Konzept beschreibt, wie die Tag-Cloud anhand von 5 Schritten realisiert wird. InAbbildung 3.1 werden alle 5 Schritte gezeigt.
Im ersten Schritt macht der Benutzer eine Eingabe zu einer gewünschten Position unddem Suchradius auf einer Karte.
Im zweiten Schritt wird das Umfeld ermittelt, dabei werden die Koordinaten der an-gegebenen Position und der Radius vom Endgerät an den Server gesendet. Der Serverdurchsucht die Datenbank mit allen georeferenzierten Wikipedia Artikeln. Dabei sindauf dem Server nur die Links zu den Artikeln gespeichert. Anhand der Koordinatenund dem Radius werden nun alle zutreffenden Links rausgesucht und alle Inhalte derWikipedia Artikel aufgerufen.
Im dritten Schritt werden alle Wörter gezählt und gefiltert (siehe Kapitel 4.1), sodassnur noch ein kleiner Teil der Inhalte übrig bleibt.
Im vierten Schritt werden die Wörter, die am häufigsten gezählt wurden, als Schlag-wörter zusammen mit dem berechneten Gewicht und dem Link zum Wikipedia Arti-kel zusammengefasst.
Im fünften Schritt werden abschließend die gefilterten Schlagwörter an das Endgerätzurückgeschickt und als Tag-Cloud aufbereitet und visualisiert.
11
3. Prototypenanalyse
Nachfolgend werden die 5 Schritte zur Darstellung der Tag-Cloud näher erläutert[Egg10]:
Benutzer Interaktion
1. Route
planen
2. Umfeld
ermitteln
3. Tags
filtern
4. Tag-Cloud
generieren
5. Tag-Cloud
visualisieren
Abbildung 3.1.: Prozessablauf des Konzeptansatzes, nach [Egg10]
1. Route planen
Eine Person, die sich an einem fremden Ort befindet, verfügt nur über wenige orts-bezogenen Informationen und könnte bedeutende Orte oder wichtige Ereignisse ver-passen. Durch GPS-fähige Smartphones und andere mobile Geräte ist es möglich denBenutzer mit raumbezogenen Informationen zu unterstützen. Dieser kann sich danneinen ersten Eindruck von seiner Umgebung schaffen. Der Anwender startet die Ap-plikation und tritt in einen Dialog mit dem Smartphone ein. In der Anwendung isteine Karte vorhanden, auf dieser der Benutzer einen Punkt auswählt und einen Radi-us festlegt. Aus dem gewählten Punkt werden nun die Koordinaten als Längen- undBreitengrad ermittelt.
2. Umfeld ermitteln
Der Längen- und Breitengrad werden nun zusammen mit dem Radius vom Endge-rät (Client) zum Server gesendet. Auf dem Server ist eine Datenbank angelegt. JederEintrag besteht aus einem Hyperlink zu einem deutschsprachigen Wikipedia Arti-kel und einer geographischen Koordinate. Wenn keine geographische Koordinate exi-stiert, gibt es auch keinen Eintrag. Der Server empfängt nun den Längengrad, Breiten-grad und den Radius und vergleicht die Datenbankeinträge. Alle im Radius liegendeEinträge werden nun nacheinander verarbeitet. Dazu werden zu jedem Hyperlink dieArtikel aufgerufen, und der komplette Inhalt in einer Liste zwischengespeichert, bisalle Einträge abgearbeitet wurden.
3. Tags filtern
Die Liste von Wikipedia Artikeln wird nun Wort für Wort durchgegangen, jedes Wortwird dabei durch vier Filter geschickt. Alle Wörter, die nicht gefiltert wurden, werdengespeichert. Die genaue Beschreibung der Filterung erfolgt im Kapitel 4.1.
12
3. Prototypenanalyse
4. Tag-Cloud generieren
Um eine Tag-Cloud erstellen zu können, braucht man noch ein Gewicht, das die Text-größe widerspiegelt. Deshalb wird für jedes Wort ein Gewicht erstellt (zur Berechnungsiehe Kapitel 2.2.2). Es wurde noch eine weitere Besonderheit eingefügt, die es ermög-licht, die Gewichtung der einzelnen Artikel zu beeinflussen. Dabei wird der Abstandder Artikel zum gewählten Punkt ermittelt. Je näher ein Artikel zum gewählten Punktliegt, desto größer ist seine Gewichtung. Das hat den Vorteil, dass Artikel, die sich nä-her an dem gewählten Punkt befinden, stärker in die Berechnung einfließen. Die ver-bleibenden Wörter werden zusammen mit dem berechneten Gewicht und dem Linkzum Wikipedia Artikel in einer Tag-Cloud-Liste gespeichert.
5. Tag-Cloud visualisieren
Zum Schluss wird die Tag-Cloud-Liste an das Endgerät zurückgeschickt, als Tag-Cloudaufbereitet und visualisiert. Zur Aufbereitung wird jedes der Schlagwörter der Tag-Cloud-Liste in einem Dialogfenster je nach Art der Tag-Cloud-Gestaltung (siehe Ka-pitel 2.2.1) dargestellt. Dabei wird die Textgröße jedes Schlagwortes anhand seinerGewichtung festgelegt. Das Dialogfenster wird nun auf der Karte im Zentrum des ge-wählten Punktes visualisiert. Wenn ein weiterer Punkt vom Anwender gewählt wird,dann soll zwischen den beiden Punkten eine Verbindung dargestellt werden. Da aufeiner straßenbezogenen Karte arbeiten wird, sollen die Dialogfenster als Route entlangder Straßen verbunden werden.
3.2. Aufbau des Prototypen
Um den Prototypen leichter verstehen zu können, werden die Pakete von den Klassengezeigt. Zu den Paketen werden auch die wichtigsten Klassen mit deren Aufgabe be-schrieben. Das Ganze wurde in einer Übersicht für die Client-Seite in Abbildung 3.2und für die Server-Seite in Abbildung 3.3 zusammengestellt.
3.2.1. Client
Die wichtigsten externen Pakete sind android und die com.google.android.maps. Das Pa-ket android stellt die Plattform der internen Klassen dar. Das Paket de.hannover.uni.ikg.lbstagcloud.client enthält die für den Client wichtigen Klassen um die Applikation star-ten und ausführen zu können. Die Klasse TagCloudApplication stellt die Anwendungdar. Nach dem Start der Anwendung wird die Klasse StartActivity aufgerufen. Dieseist der sichtbare Teil der Anwendung und ist mit der Java typischen „Main“- Methodevergleichbar. Die Klasse GetTagCloudTask stellt eine Verbindung zum Server her undgibt Meldungen über den Status der Übertragung aus.
13
3. Prototypenanalyse
Das Paket de.hannover.uni.ikg.lbstagcloud.client.overlays beinhaltet alle Klassen die nötigsind um eine Visualisierung auf der Karte zu ermöglichen. Sobald man auf der Appli-kation einen neuen Punkt darstellen möchte, wird die Klasse MarkRegionOverlay auf-gerufen. Diese stellt visuell einen Kreis dar, der solange in der Größe verändert werdenkann, wie die Klasse des MasterTouchListener einen Touch (Finger auf dem Touchscreendes Smartphones) spürt. Die letzte wichtige Klasse ist TagCloudOverlay, diese stellt alleArten der Gestaltung (siehe Kapitel 2.2.1) der Tag-Cloud dar. Die interne Klasse Loca-tionCloud ist eine Erweiterung der Klasse Cloud, die sich in der OpenCloud Bibliothek[mca08] befindet.
android com.google.android.maps
...lbstagcloud.client
...lbstagcloud.client.overlays
Application Activity MapActivity
StartActivityTagCloudApplication GetTagCloudTask
MarkRegionOverlayMasterTouchListener
OpenCloud.jar
TagCloudOverlay
Overlay
LocationCloud
Cloud
Server
Abbildung 3.2.: Paketdiagramm Prototyp Client
3.2.2. Server
Vor der Erweiterung des Prototypen befanden sich alle Klassen im Paket de.hannover.uni.ikg.lbstagcloud.server.main. Die Klasse TagCloudServer wurde als Thread implemen-tiert und initialisiert die Filter. Damit konnte eine Client-Applikation gleichzeitig aufden Server zugreifen, der Server war dann solange belegt bis der Client mit der Anfra-ge fertig war. Mit der Klasse JdbcCloudSpaceQuery wird eine Verbindung zum MySQLServer aufgebaut. Auf dem MySQL Server waren alle Positionen und URL´s der geore-ferenzierten Wikipeida Artikel gespeichert. Anhand der Position der einzelnen Artikelund dem Radius wurde dann eine SQL-Anfrage geschickt.
Die SQL-Anfrage an den MySQL Server:
SELECT Ti te l_de , l a t , lonFROM pub_C_geo_idWHERE ( l a t > ( l a t − b u f f e r ) AND l a t < ( l a t + b u f f e r )AND lon > ( lon − b u f f e r ) AND lon < ( lon + b u f f e r )AND Country IS NOT NULL AND Country <> ’ ’
14
3. Prototypenanalyse
Zurückgeliefert werden alle Artikel, die im Radius liegen. Jeder gelieferte Artikel wirdals URLRequest übergeben. Die Klasse URLRequest holt sich über den Wikipedia Serverden Text des einzelnen Artikels. Die Klasse URLRequestResult fasst alle URLRequestszusammen und gibt diese an den TagCloudServer weiter. Der TagCloudServer verarbeitetdie URLRequests zu einer Tag-Cloud und schickt diese an den Client zurück.
ThreadTagCloudServer
OpenCloud.jar
Cloud
JdbcCloudSpaceQuery
URLRequest URLRequestResult
...lbstagcloud.server.main
Main
java.lang.thread
Client
Abbildung 3.3.: Paketdiagramm Prototyp Server
3.2.3. Bewertung des Prototypen
In diesem Abschnitt wird festgestellt, warum es sinnvoll ist den Prototypen weiter-zuentwickeln und nicht von vorne zu programmieren. Die Grundlage des Konzeptsist im Prototyp schon vorhanden, der mit ein paar Änderungen gut weiterentwickeltwerden kann. Deshalb werden nachfolgend Gründe genannt, die für die Weiterent-wicklung sprechen.
Der Prototyp ist geeignet zur Weiterentwicklung, aus folgenden Gründen:
• Der strukturelle Aufbau ist verständlich und nachvollziehbar.
• Ausreichend dokumentiert.
• Die Erweiterungen lassen sich gut anknüpfen.
• Die Klassen sind klar voneinander getrennt.
Aus diesen oben genannten Gründen ist es empfehlenswert den Prototypen weiterzu-entwickeln und nicht neu anzufangen.
15
4. Filterung
Im Rahmen dieser Arbeit wurden die bestehenden Filter weiterentwickelt, und einneuer Filter wurde implementiert. Im ersten Abschnitt werden die eingesetzten Filterbeschrieben. Zusätzlich zur Filterung muss geprüft werden, ob ein Schlagwort auchder Wortstamm ist. Im zweiten Abschnitt wird die Wortstammermittlung geschildert.Dies gehört noch zum Thema Filterung, da es passieren kann, dass Schlagwörter mehr-mals in die Tag-Cloud mit aufgenommen werden, die den gleichen Wortstamm, aberunterschiedliche Formen besitzen (z.B. Anlage / Anlagen).
4.1. Eingesetzte Filter
Die Filterung ist ein weiterer wichtiger Aspekt dieser Arbeit. Da längere Texte durch-sucht und alle Wörter einzeln gezählt werden, kommen auch viele Wörter mit in dieErgebnismenge, die nicht angezeigt werden sollen. Deshalb gibt es verschiedene Fil-ter, die diese unerwünschten Wörter herausfiltern, sodass nur noch die Wörter übrigbleiben, die relevant sind. Folgende Filter werden verwendet (siehe Abbildung 4.1):
Wikipedia Längen-filter
Blacklist-filter
Wortstamm-filter
Trefferzahl-filter
Abbildung 4.1.: Reihenfolge der verwendeten Filter
1. Längenfilter
Der Längenfilter verwirft alle Wörter mit der Länge, die kleiner als eine bestimmteAnzahl an Zeichen ist. Somit werden z.B. viele Artikel oder Füllwörter schon vorabherausgefiltert.
2. Blacklistfilter
Der Blacklistfilter verwirft alle Wörter, die in der Blacklist vorkommen. In der Blacklistsind alle unerwünschten Wörter aufgeführt. Dieser Filter ist sehr regions- und sprach-abhängig. Die verwendete Quelle spielt auch eine große Rolle, da Wörter, die häufigin der Quelle genutzt werden, nicht mit aufgeführt werden sollen. Ein Beispiel vonWikipedia wäre das Wort „[Bearbeiten]“.
16
4. Filterung
3. Sammeln
Die ersten beiden Filter werden sequentiell für jedes Wort durchgelaufen. Bevor derWortstammfilter verwendet werden kann, müssen alle vorgefilterten Wörter zwischen-gespeichert werden. Aus Softwareentwickler-Sicht soll die Laufzeit gering gehaltenwerden. Dies wird durch die Vorfilterung gewährleistet, da weniger Wörter bearbei-tet werden müssen. Der Wortstamm- und Trefferzahlfilter sollen über die gesammelteMenge laufen.
4. Wortstammfilter
Der Wortstammfilter ist der wichtigste Filter. Dieser sucht von jedem Wort den Wort-stamm und fügt ihn zu der Ergebnismenge hinzu (siehe Kapitel 4.2). Ohne diesenFilter würden Schlagwörter mehrfach in unterschiedlichen Formen in die Tag-Cloudgeschrieben werden. Ein Beispiel dafür wäre das Wort Anlage / Anlagen. Dieser Filterwar nicht im Prototypen vorhanden.
5. Trefferzahlfilter
Nachdem der Wortstammfilter alle Wörter in die Stammform gebracht hat, wird derTrefferzahlfilter angewendet. Dieser Filter nimmt sich die populärsten Schlagwörter,und der Rest wird dann verworfen. In dieser Arbeit werden die populärsten 50 Schlag-wörter verwendet, da maximal 50 Wörter in die Tag-Cloud Darstellung passen. Diegefilterten Wörter werden dann vom Server an das Gerät übermittelt.
4.2. Wortstammermittlung
Um den Wortstammfilter umsetzen zu können, muss zu jedem Wort die Grundformund der Wortstamm ermittelt werden. Zur Wortstammermittlung muss im Vorfeldauf den Begriff der Morphologie, deren Klassifikation und deren Verwendung zurWorstamm-, Wurzelermittlung eingegangen werden.
Die Morphologie („Formlehre“) untersucht die systematischen Beziehungenzwischen Wörtern und Wortformen oder - prozedural ausgedrückt - die Regeln,nach denen Wörter/Wortformen gebildet werden. [Car10]
Jedes Wort besitzt verschiedene Formen (z.B. der Fuchs: des Fuchses, dem Fuchs, denFuchs). Bei der Morphologie wird untersucht, wie diese Formen gebildet werden undwelche dazu Regeln es gibt.
In der Morphologie gibt es verschiedene Klassifikationen [Car10].
Freie Morpheme können ohne Kontext geäußert werden (z.B. Fuchs). Dem gegenübersind gebundene Morpheme, wie z.B. des Fuchses - Genetiv Singular, die nur nach einenNomen auftauchen können.
17
4. Filterung
Die für diese Arbeit relevante Einteilung bilden die Grund- und die peripheren Morph-eme (engl. Word stem). Mit den peripheren Morphemen können von Wörter deren Beu-gung (Flexion), Wortableitung (Derivation) und Wortzusammensetzung (Komposition)erzeugt werden.
Zur Ermittlung der peripheren Morpheme gibt es verschiedene Ansätze. Zum einen gibtes den Porter Stemming Algorithmus [Por80]. Dieser Algorithmus nutzt die Verkür-zungsregel, bei der das Wort solange verkürzt wird, bis dieses eine Minimalanzahlvon Silben besitzt. Dieser Algorithmus wurde ursprünglich für die englische Spracheentwickelt, ist aber schon für viele andere Sprachen umgesetzt worden. Da der PorterStemming Algorithmus nicht mit einer hundertprozentigen Genauigkeit arbeitet, kannes bei einigen Wörtern zu Over- / Understemming führen, wo entweder zu viel oder zuwenig abgeschnitten wird. Gerade nicht englischsprachige Umsetzungen vom PorterStemming Algorithmus sind recht ungenau.
Um die Ungenauigkeit zu vermeiden wird ein anderer Algorithmus verwendet. DerWörterbuch-Suchalgorithmus (engl. Dictionary Look-up) ermittelt das periphere Mor-phem anhand eines Wörterbuches [Car10]. Der große Vorteil bei der Verwendung ei-nes Wörterbuches ist, dass dadurch die Genauigkeit höher wird. Aber man benötigteine zusätzliche Datenstruktur, mehr Speicherplatz und eine längere Laufzeit.
Für dieses Konzept ist der Wörterbuch Suchalgorithmus trotzdem sehr gut geeignet,da wir nur eine kleine Menge (ca. 50 Wörter) auf den Wortstamm zurückführen wol-len.
4.3. Gewichtung zum Umkreismittelpunkt
Die Gewichtung zum Umkreismittelpunkt war in dem Prototypen Konzept noch nichtberücksichtigt, dort waren alle Artikel in dem gewählten Radius gleich gewichtet. DasKonzept wurde um diesen Punkt erweitert. Es werden Artikel, die näher an dem aus-gewählten Punkt sind höher gewichtet, da diese relevanter für den Benutzer sind.Hierzu muss eine Abstandsberechnung von Raumkoordinaten durchgeführt werden.Dafür muss ein Verfahren angewendet werden, um den Abstand zwischen zwei Raum-koordinaten zu berechnen. Nachdem der Abstand ermittelt wurde, muss eine Formelentwickelt werden, die zu allen Artikeln eine Gewichtung festlegt.
4.3.1. Abstandsberechnung
Durch ein geodätisches Bezugssystem wird die Form der Erde durch ein Ellipsoidenangenähert [dL06]. Dabei werden auch die Abflachung der Erde an den Polen unddie Ausrichtungen am Äquator berücksichtigt. Da die Erde keine richtige Ellipsoidendarstellt, werden je nach Region auf der Erde andere Parameter für das Bezugssystemgewählt. Das Bezugssystem mit der geringsten Abweichung zu den einzelnen Regio-nen der Erde ist das World Geodetic System 1984 (WGS 84) [dL06]. Dieses ist in Europaweit verbreitet.
18
4. Filterung
4.3.2. Verwendeter Algorithmus
In dieser Arbeit wurde zuerst der Algorithmus zur Abstandsberechnung von Vincen-tys [Vin75] umgesetzt. Dieser kann sehr genaue Werte liefern, da er anhand eines Refe-renzellipsoides den Abstand auf der Erde berechnet. Aus Softwareingenieurssicht istdieser Algorithmus aber viel zu aufwendig, da er über mehrere Iterationen den Ab-stand annähert. In dieser Arbeit wird der Abstand auch nicht direkt verwendet, son-dern ins Verhältnis zu den anderen Punkten gesetzt. Diese sind durch den Radius desUmkreismittelpunktes alle sehr nahe beieinander, sodass die Erdkrümmung vernach-lässigt werden kann. Es wird eine einfachere Methode zur Entfernungsberechnungverwendet [Kom11]. Dabei wird die Erdoberfläche als Ebene angesehen, und mit demSatz des Pythagoras die Entfernung bestimmt. Der Abstand der Breitenkreise ist im-mer konstant 111.3 km. Für die Längenkreise wird der Wert in Abhängigkeit von dergeografischen Breite berechnet. Am Äquator ist dieser 111.3 km, an den Polen hinge-gen 0. Deshalb wird er mit 111.3∗cos(lat) ausgerechnet.
52°
111.3 km
dist
ance
10°
9°
53° 54°51°
111.3 * cos(lat)
Abbildung 4.2.: Abstandsberechnung
Die verbesserte Formel zur Abstandsberechnung lautet [Kom11]:
l a t = ( l a t 1 + l a t 2 ) / 2 ;
dx = 111 .3 ∗ cos ( l a t ) ∗ ( lon1 − lon2 ) ;
dy = 111 .3 ∗ ( l a t 1 − l a t 2 ) ;
d i s t a n c e = s q r t ( dx ∗ dx + dy ∗ dy ) ;
Dabei sind lat1, lat2 die Breiten- und lon1, lon2 die Längegrade. distance ist die Ent-fernung in km. Der Kosinus muss auf Bogenmaß eingestellt sein.
19
4. Filterung
4.3.3. Berechnung der neuen Gewichtung
Die Gewichtung der Tags wird im Bezug auf den Abstand zum Umkreismittelpunktberechnet. Im ersten Schritt werden pro Artikel alle Gewichte der Tags normal berech-net. Im Anschluss wird dann zu jedem Artikel der jeweilige Faktor berechnet und mitallen Tags des Artikels faktorisiert. Durch die nachfolgende Formel wird der Faktorpro Artikel (a) berechnet:
FactorWeight(a) =distanceradiusdistance(a)
(4.1)
wobei FactorWeight(a) den Faktor widerspiegelt. distanceradius ist die Strecke des Such-radius, distance(a) ist der Abstand des jeweiligen Artikels.
Nachdem alle Tags der jeweiligen Artikel ermittelt wurden, werden alle Tags des Arti-kels mit dem dazugehörigen FactorWeight faktorisiert und als neues Gewicht des Tagsausgegeben. Die Formel aus 2.2 wird um FactorWeight erweitert, sodass die Formellautet:
Weight(i) =⌈
fi ∗FactorWeight(a)− fminfmax − fmin
⌉
(4.2)
In Abbildung 4.3 wird die neue Entfernungsgewichtung aus der Anwendung gezeigt.Zum Vergleich wird der Prototyp und die Anwendung ohne Gewichtung dem gegen-übergestellt.
(a) Prototyp (b) Client ohne Entfer-nungsgewichtung
(c) Client mit Entfer-nungsgewichtung
Abbildung 4.3.: Entfernungsgewichtung Prototyp - Client
20
5. Visualisierung
Die Visualisierung der Tag-Cloud ist ein weiterer Aspekt dieser Arbeit. Am Anfangdes Abschnitts wird die GUI (graphical user interface) gezeigt. Dabei wird auf dieFarbwahl der Elemente eingegangen. Dann folgt der strukturelle Ablauf des Konzepts,dieser wird anhand von sechs Screenshots gezeigt.
5.1. Farbwahl
Die graphische Kommunikation spielt eine wichtige Rolle in der Kartographie. Größe,Helligkeitswert, Muster, Farbe, Richtung und Form werden als graphische Variablen(nach Bertin) definiert [dL06]. Bei der verwendeten Google Maps Karte kann kein Ein-fluss auf diese graphischen Variablen genommen werden. Deshalb müssen die selbst-gewählten graphischen Variablen gut sichtbar und unterscheidbar zu der Kartendar-stellung sein. Farben besitzen zudem gute trennende und selektive Eigenschaften [dL06]. ZurTag-Cloud Visualisierung wurde ein rechteckiger Kasten mit Dunkelgrauwerten ver-wendet. Die Schrift hat eine Helligkeitsabstufung zum Kasten, um eine Zuordnung zudiesem herzustellen. Des Weiteren wird zur Unterscheidung für den Radius (Abbil-dung 5.1c) die Farbe Rot verwendet. Die letzte selbstgewählte Farbe ist Hellgrün, dieeine Routenstrecke zwischen 2 Punkten auf der Karte miteinander verbindet. Durchdie Android-Umgebung lässt sich eine neue Farbwahl sehr leicht anpassen.
5.2. Anwendungsoberfläche
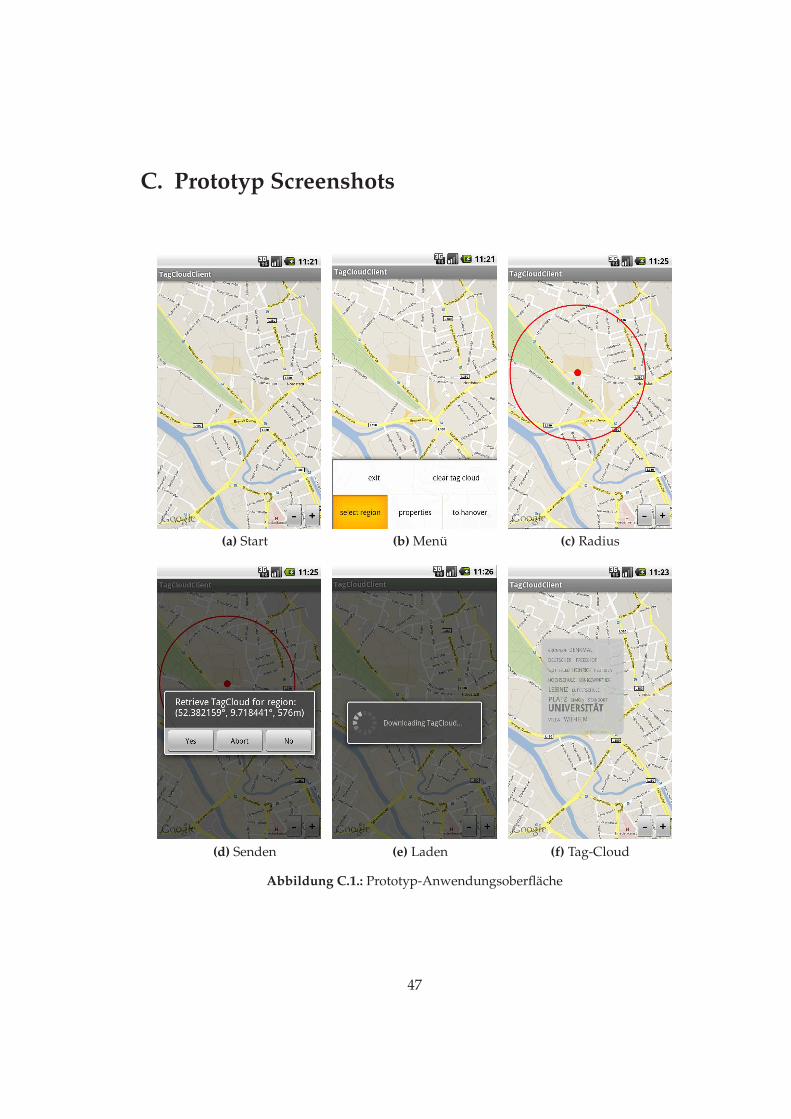
Das Ziel in diesem Abschnitt ist es, die Schnittstellen, die Funktionalität und die Kor-rektheit, also die Software-Ergonomie [May99], zu optimieren. Dazu wird das Konzeptaus dem Kapitel 3 nochmal als visuelle Oberfläche gezeigt. In Abbildung 5.1 wird derAblauf anhand von Scrennshots aus der Anwendung gezeigt. Im Bild 5.1a ist der Tag-CloudClient im laufenden Zustand. Beim Bild 5.1b wird nun das Menü aufgerufen. Beidem Bild 5.1c startet der Ablauf und bei Bild 5.1d wird auf die Bestätigung gewartetdie Daten an den Server zu senden. Dann wird bei dem Bild 5.1e auf die Rücksendungder Tag-Cloud gewartet. Schließlich wird bei dem Bild 5.1f die Tag-Cloud ausgegeben.
Wie auf dem Bild 5.1f zu erkennen ist, wird hier die Gestaltungsart des zirkulären Lay-outes verwendet. Die Gestaltungsarten der Tag-Cloud wurden im Grundlagen Kapitel2.2.1 erklärt, und deren Umsetzung befindet sich in Kapitel 7.3.
Auf der nächsten Seite werden die sechs Bilder gezeigt.
Zu Beginn dieses Kapitels wird die Definition des Web-Service geklärt und der Web-Service des Konzepts besprochen. Dann wird eine Umsetzung des REST-Ansatzeszum Konzept näher betrachtet. Als nächstes wird ein Fazit abgegeben, ob eine REST-Implementierung sinnvoll wäre. Der nächste Abschnitt beschäftigt sich mit den Ver-bindungen zwischen zwei Punkten. Diese sollen als Route entlang einer Straße darge-stellt werden. Diese Route wird als Anfrage an den Google Direction Server gesendet,ein Objekt wird zurückgeliefert und verarbeitet. Zum Schluss werden die verschiede-nen Quellen betrachtet (Wikipedia, Flickr,...), die einen Web-Service bereitstellen. Zuden verschiedenen Quellen gehört auch, welche Anforderungen nötig sind, damit die-se Quellen auf das Konzept erweitert werden können.
6.1. Tag-Cloud Web-Service
Ein Dienst ist eine im Netzwerk verfügbare, lose gekoppelte Softwarekomponen-te, welche wohldefinierte Schnittstellen implementiert und mit standardisiertenProtokollen aufgerufen werden kann. [Lüb08]
Im TagCloudClient wird zurzeit ein externer Webservice verwendet. Der WikipediaWeb-Service holt und verarbeitet den Inhalt von georeferenzierten Wikipedia Artikeln.Nach der Definition haben Wikipedia und viele weitere Webseiten eine Web-Service-Schnittstelle. Das Tag-Cloud Konzept besitzt durch diese Definition noch keinen voll-ständigen Web-Service, da das Prinzip der wohldefinierten Schnittstelle nicht erfülltist. Deshalb wird nachfolgend eine mögliche REST-Implementierung ausgearbeitet.
6.2. REST-Ansatz
Beim bisherigen Client-Server-Austausch werden Daten mit einem serialisierten Ja-va Objekt übermittelt. Vom Client zum Server wird der Radius und die Position alsBreitengrad und Längengrad gesendet. Diese werden verarbeitet, und es wird die ferti-ge Cloud zurückgeliefert. Der Client-Server-Austausch ist sehr speziell und nicht öf-fentlich. Es wird ein spezielles Format vom Server zum Client übermittelt, das bishernur für Java implementiert ist. Deshalb soll ein REST-Ansatz überlegt werden, damitauch andere Plattformen Zugang zu der Serverkomponente bekommen können. Da-bei werden zuerst die benötigten Ressourcen beschrieben und dann welche Strukturnötig ist. Dann wird der Ablauf einer Anfrage anhand eines Beispiels durchgeführt.Zum Schluss werden die Vor- und Nachteile zur Implementierung besprochen.
23
6. Untersuchung von Web-Services
6.2.1. Ressourcen
Für den geplanten REST-Ansatz müssen Ressourcen definiert werden. Für das Kon-zept wird nur eine einfache Datenstruktur angelegt, da es weder Accounts noch enormgroße Datenmengen gibt. Es werden eine API und Ressourcen benötigt, die API unddie Ressourcen werden in einer Tabelle 6.1 zusammengefasst.
Operation Methode Ressource Funktion
Darstellung der Tag-Cloud GET /{cloud} /{?lat= ...&lon=...&buf=...}
Tabelle 6.1.: Tag-Cloud Ressourcen
6.2.2. Denkbare Umsetzung
Nachdem die Ressourcen identifiziert wurden, wird ein Beispiel für einen Ablauf ge-zeigt.
3. GET Der Client will nun die Ressource zurückbekommen und sendet ein GET anden Server. Der Client erlaubt ein XML oder ein JSON Objekt.
GET tagcloud ? l a t =52.374444& lon =9.738611& buf =101.521Host : ht tp :// ikg . uni−hannover . de/Accept : a p p l i c a t i o n /xml ; a p p l i c a t i o n / json
Nun sendet der Server eine Repräsentation der Ressource an den Client zurück.
<cloud s e l f = ’ ht tp :// ikg . uni−hannover . de/tagcloud/cloud/h4310 ’ ><item>
<amount>52</amount>< p o s i t i o n > l a t =52.374444& lon =9.738611& buf =101.521 </ p o s i t i o n >
<Tags><Tag>
<Name> U n i v e r s i t ä t </Name><Weight> 0 . 5 </Weight><Score>22 </Score><Date> 1 0 . 0 8 . 2 0 1 1 ; 1 5 : 3 1 : 0 6 </Date><Links>
<Link>http ://de . wikipedia . org/wiki/Uni_Hannover </Link><Link>http ://de . wikipedia . org/wiki/Welfenschloss </Link>
</Links></Tag>
<Tag>. . . . . . . . .
</Tag></Tags>
</item></cloud>
24
6. Untersuchung von Web-Services
6.2.3. Bewertung
Die Bewertung zur REST-Implementierung erfolgt durch eine Auflistung und Bewer-tung der Vor- und Nachteile, Tabelle 6.2. Am Ende des Abschnitts wird ein Fazit abge-geben.
Vorteile Nachteile
einheitliche Schnittstelle Zeitaufwandeinfach zu erweitern Kostenaufwand
Tabelle 6.2.: Bewertung REST
Der größte Nachteil ist der zusätzliche Zeitaufwand. Durch die zusätzlich geleisteteArbeit, die jemand zur Umsetzung aufbringen muss, entstehen hohe Kosten. Wenndas Konzept, dagegen, noch für weitere Plattformen umgesetzt werden soll. Könntendie Vorteile der einheitlichen Schnittstelle und die einfache Erweiterung den aufge-wendeten Zeitaufwand begleichen.
Das Fazit der vorangegangenen Bewertung ist, dass wenn sich das Konzept durchsetztund weiterentwickelt wird, es lohnenswert ist die Serverkomponente frei zugänglichzu machen und als REST zu implementieren.
6.3. Route
Im Prototypen wurden die geografischen Punkte per Luftlinie miteinander verbun-den. Dies soll nun mit einer Route bewerkstelligt werden. Eine Route ist der Weg zwi-schen geografischen Punkten. In diesem Konzept sollen ausgewählte Punkte auf ei-ner straßenbezogenen Karte miteinander verbunden werden. Die Android-Plattformbesitzt zwar eine Google Maps Karte. Die Algorithmen zur straßenbezogenen Verbin-dung sind aber sehr aufwendig und wurden nicht implementiert. Deshalb werdendie Routen zwischen den Punkten mithilfe eines HTTP-Aufrufs der Google DirectionAPI[Goo10] berechnet.
Eine Google Directions API Anfrage besteht aus einer HTTP-URL und hat die Form[Goo10]:
http ://maps . google . com/maps/api/ d i r e c t i o n s /output ? parameters
Der Output kann entweder als JSON (JavaScript Object Notation) oder als XML (Ex-tensible Markup Language) erfolgen.
Es gibt mehrere URL-Anfrageparameter, die mit der HTTP Anfrage gesendet werden:
• origin (erforderlich), dabei wird die Adresse oder der Breiten- und Längengraddes Startpunkts als Textwert übermittelt.
25
6. Untersuchung von Web-Services
• destination (erforderlich), dabei wird die Adresse oder der Breiten- und Längen-grad des Zielpunkts als Textwert übermittelt.
• mode (optional) sind die Transportarten. Diese ist standardmäßig auf driving ein-gestellt, kann aber auch als walking oder bicycling eingestellt werden.
• waypoints (optional) sind die Wegpunkte, die zwischen dem Start -und Ziel-punkt führen sollen. Diese können als Adresse oder der Breiten- und Längen-grad angegeben werden.
• alternatives (optional) gibt Alternativen zu der Route zurück, dafür muss dieEinstellung auf true gesetzt sein.
• avoid (optional) kann angegeben werden, ob tolls (Mautstraßen) oder highways(Autobahnen) vermieden werden sollen.
• language (optional) ist die Sprache, in der die Ergebnisse zurückgegeben werdensollen.
• sensor (erforderlich) soll feststellen, ob die Routenanfrage von einem Gerät miteinem Standortsensor kommt. Der Wert muss true oder false annehmen.
Eine Beispiel Anfrage [Goo10]:
http ://maps . google . com/maps/api/ d i r e c t i o n s / j son ? o r i g i n =Boston ,MA&d e s t i n a t i o n =Concord ,MA&waypoints=Charlestown ,MA|Lexington ,MA&sensor= f a l s e
Wenn die Anfrage übermittelt wurde, bekommt man ein JSON-Objekt zurück (dieJSON-Ausgabe befindet sich im Anhang A). Ein wichtiges Element aus dem Objektsind die Polylinien. Die Polylinien werden dann in einem „Layer“ gezeichnet undüber die Karte gelegt. Dabei bilden die einzelnen Polylinien, aneinander gefügt, dieRoute zwischen den beiden Punkten. Mehr zur Darstellung der Route im Kapitel 7.4.
6.4. Weitere Quellen
Die primäre Quelle für das Konzept ist Wikipedia. Wikipedia hat eine eigene API (dieMediaWiki API)[Wik08]. Auf diese wird zugegriffen, wenn der Inhalt eines Artikelsverarbeitet wird. Nachfolgend sollen noch andere Quellen untersucht werden. Dabeimüssen mehrere Anforderungen erfüllt werden, damit sich eine Quelle für die Anwen-dung eignet. Die Quelle muss über geeignete Tags, über georeferenzierte Koordinaten(auch Geotagging genannt) verfügen. Die Quelle muss auch über eine Schnittstelleverfügen, damit man an die Tags gelangen kann (hier Web-Service API). Darüber hin-aus muss der Tag der Quelle noch einen Link zum Artikel besitzen.
26
6. Untersuchung von Web-Services
Weitere Quelle Tags GeoTagging Web-Service API Link Art des InhaltesWikipedia " " " " Artikel
Flickr " " " " FotosAmazon " $ " " *Artikel
Google Place " " " " Kategoriendelicious " " " " BookmarksGeoRSS " " " " RSS-Dienst
Tabelle 6.3.: Quellen Anforderungen
Durch die Tabelle 6.3 hat sich ergeben, dass Flickr und Google Place als Erweiterung ge-eignet sind. Bei Flickr müssen aber ein paar Änderungen vorgenommen werden, damitrelevante Informationen dargestellt werden können. Es werden primär Fotos hochge-laden und mit Tags versehen, somit können die Tags von den Fotos in der Tag-Cloudvisualisiert werden. Amazon eignet sich nicht als Quelle, da es zwar einen WebserviceAPI besitzt, diese hat aber keine georeferenzierte Koordinaten. Mit Google Place kön-nen verschiedene Kategorien eingetragen werden, Ort und Radius sind auch vorhan-den. Diese Anwendung ist nicht frei zugänglich, es wird eine API-Client-ID benötigt.Bei delicious kann jeder Benutzer Bookmarks anlegen, diese müssen aber in eine nütz-liche Verbindung mit ortsbezogenen Informationen gebracht werden. GeoRSS ist einRSS-Dienst und kann zum Beispiel bei delicious verwendet werden. Falls eine Quelleimplementiert werden soll, muss diese auf ihre in das Konzept betrachtet werden.
27
7. Implementierung
In diesem Kapitel wird die Umsetzung der Android-Applikation veranschaulicht. DerName dieser Applikation lautet „TagCloudClient“. Als erstes wird auf die Architek-tur der Android Applikation eingegangen. Dabei wird mithilfe von einem Sequenz-diagramm der Ablauf der Tag-Cloud-Visualisierung gezeigt. Dann wird das Client-Server-Modell mit der Schichtenarchitektur und dem Austausch beschrieben. Die näch-sten Abschnitte beschäftigen sich mit der Umsetzung der Filterung, der Visualisierungund dem Routen Web-Service. Anschließend werden sonstige Anpassungen am Pro-totypen geschildert.
7.1. Architektur
Die Architektur beschreibt das Zusammenspiel der einzelnen Komponenten, dies wirdmithilfe von UML Diagrammen verdeutlicht. Zuerst wird mit Hilfe von zwei Sequenz-diagrammen ein kompletter Durchlauf gezeigt. Das Client-Server-Modell zeigt die be-nötigten Komponenten und wie diese miteinander interagieren.
7.1.1. Ablauf der Anwendung
Es wird das Zusammenspiel der Klassen vom Client (Abbildung 7.1) und danach dievom Server (Abbildung 7.2) gezeigt.
Wenn die Anwendung gestartet ist, wird die Klasse StartActivity ausgeführt. Die An-wendung befindet sich im laufenden Zustand. In diesem Zustand kann auf der Goo-gle Maps Karte gezoomt und sich auf der Karte bewegt werden. Wenn nun ein neuerPunkt angegeben wird, wird die Methode toggleMarkRegion() aufgerufen. Diese ändertden Zustand des MarkRegionOverlays. Solange der Benutzer das Display berührt, wirdein Radius visuell „gezogen“. Wenn nun der Finger die Oberfläche des Displays ver-lässt, wird der Zustand wieder zurückgesetzt, und es wird die Methode onRegionSet()ausgeführt. Dadurch wird die Klasse GetTagCloudTask aufgerufen. Diese öffnet einenOutputStream und sendet drei Parameter (Längen- ,Breitengrad und Radius) an denServer. Der Server verarbeitet die Anfrage über ein (Object-) InputStream (der Serverwird in Abbildung 7.2 beschrieben). Wenn die Verbindung zum Server beendet wurdewird die Methode onPostexecute() aufgerufen. Diese initialisiert die Klassen RouteOver-lay und TagCloudOverlay. Bei RouteOverlay wird geprüft, ob es schon mehr als einenPunkt auf der Karte gibt. Wenn das der Fall ist, wird getPath() aufgerufen. Es wird eineAnfrage an Google geschickt und die Route wird zwischen dem letzten und dem neu-sten Punkt dargestellt (siehe Kapitel 6.3). TagCloudOverlay stellt danach die Tag-Cloudvisuell dar.
Die Klasse TagCloudServer ist die ganze Zeit aktiv und horcht auf eine Anfrage. Wennder Client eine Verbindung aufbaut, wird ein neuer SocketThread gestartet. Dieser er-laubt mehreren Benutzer gleichzeitig auf den Server eine Tag-Cloud generieren zulassen. Im Prototyp war dies noch nicht möglich. Der SocketThread führt dann die Me-thode getWikipediaText() aus. Diese ruft dann die Klasse JdbcCloudSpaceQuery auf. Dortwerden alle Wikipedia Einträge der MySQL-Datenbank ermittelt. Mit getArticle() wirddann der Abstand und die neue Gewichtung der ermittelten Artikel berechnet. Dasalles wird zum SocketThread zurückgegeben.
29
7. Implementierung
Dieser erzeugt aus den ermittelten Artikeln eine Tag-Cloud. Darauf folgend wird fil-terCloud() aufgerufen die mit dem HunspellFilter die Tag-Cloud nochmal filtert unddann die gefilterte Tag-Cloud zurückgibt. Das Ergebnis wird an den TagCloudServerzurückgeschickt und der SocketThread wird durch close() geschlossen. Die entstandeneTag-Cloud wird mit dem outStream an den Client zurückgeschickt.
7.1.2. Client-Server-Modell
In diesem Client-Server-Modell werden drei Schichten mit einer 3-Tier-Architekturverwendet, es wird eine kooperativen Verarbeitung [Sch05] verwendet. Das bedeu-tet, dass auf der Serverseite die Datenhaltung, Datenverwaltung und die Applikationteilweise verarbeitet wird. Auf der Clientseite werden die aufbereiteten Daten präsen-tiert und übernimmt die Steuerung. Das Modell ist Kooperativ, weil auf beiden Seitenein Teil der Applikation-Verarbeitung übernommen wird.
2. suche Adressen der Artikel die im Bereich des lat, lon, buf liegen
3. gib die Adressen der Artikel zurück
4. gib die Adressliste der Artikel an Wikipedia weiter
5. gib den Inhalt der Artikel zurück
6. filtere den Inhalt und erstelle die Tag-Cloud
7. empfängt die gefilterte Tag-Cloud
In Abbildung 7.3 übernimmt der Server einen Großteil der Arbeit von der Applikati-on, weil die meisten Smartphones im Vergleich zu einem Server recht schwach sindund keine großen Datenmengen verarbeiten können und sollen. Es ist eine Koope-rative Verarbeitung, weil die Google Routenabfrage und Visualisierung vom Clientübernommen wird.
30
7. Implementierung
7.2. Umsetzung der Filterung
In diesem Abschnitt wird die Implementierung der Filterung für die TagCloudClientbesprochen. Dabei werden die, aus dem Kapitel 3, abgehandelten Aspekte nun umge-setzt.
Bibliotheken
Zur Umsetzung der Filterung wurden die OpenCloud [mca08] und die Hunspell [FSF03]Bibliothek verwendet. Die OpenCloud ist eine Java Bibliothek zur Generierung undVerwaltung von Tag-Clouds. Die Hunspell Bibliothek besitzt eine Rechtschreibprü-fung mit Wörterbuch basierten Korrekturvorschlägen und einem morphologischenAnalyser der, auf Wörterbuch Basis, den Wortstamm finden kann. Damit Hunspellgenutzt werden kann muss eine weitere Bibliothek eingebunden werden. Die Java Na-tive Access Bibliothek (kurz JNA) [Git07] ist eine Brücke zwischen Java und „nativen“Bibliotheken.
7.2.1. Filter
Cloudfilter
Der Längenfilter und Blacklistfilter sind in der OpenCloud Bibliothek schon implemen-tiert gewesen. Der Trefferzahlfilter wurde nachträglich eingefügt. Dieser nimmt sich die50 am höchsten gewichteten Schlagwörter und gibt diese weiter. Der Wortstammfilterist schon viel aufwendiger und wird im nächsten Unterabschnitt behandelt.
Hunspell
Der Filter wurde im Rahmen dieser Arbeit entwickelt. Die Klasse HunspellFilter besitztdie Methoden zur Filterung der fertigen Tag-Cloud. Diese Methoden suchen von je-dem Wort den Wortstamm heraus. Hunspell ist nur als C++ Bibliothek verfügbar undmuss mittels der Java Native Library (kurz JNA) eingebunden werden. Die KlassenHunspellLibrary und Hunspell beschäftigen sich mit der richtigen Einbindung. Hun-spell ist Wörterbuch basiert, es wird das Wörterbuch von OpenOffice verwendet. Dasmacht den Wortstammfilter sehr regions- und sprachenabhängig. Für andere Spra-chen, als die deutsche, muss also lediglich ein anderes Wörterbuch eingefügt werden.
31
7. Implementierung
7.2.2. Gewichtung zum Umkreismittelpunkt
Die Gewichtung zum Umkreismittelpunkt wird vor der Filterung aufgerufen. Dabeiwird zu jeden Artikel der Abstand und das neue Gewicht berechnet. Die Liste vonArtikeln die von Wikipedia geladen wird, wird dann an die Klasse CenterScore über-geben. Diese gibt die geographischen Koordinaten an die Klasse Distance weiter. Diedann den Abstand zum Umkreismittelpunkt zu jedem Artikel ausrechnet und spei-chert diesen im Artikel.
7.3. Umsetzung der Visualisierung
Die in Kapitel 2.2 abgehandelten Arten der Gestaltung werden in diesem Abschnittumgesetzt. Dabei sollen erst die eingesetzten Bibliotheken und dann die Umsetzungder Gestaltungsarten näher erläutert werden.
Bibliotheken
Zur Visualisierung wurden die Android plattformabhängigen und die OpenCloud Bi-bliotheken verwendet.
7.3.1. Umsetzung der Gestaltungsarten
Die Gestaltungsarten wurden im Kapitel 2.2.1 schon behandelt, an dieser Stelle wirdgezeigt wie die Gestaltungsarten realisiert wurden.
Das sequentielle Layout war im Prototypen schon umgesetzt, wurde aber um dieHorizontale Orientierung erweitert.
Das Cluster-Layout konnte in dieser Arbeit nicht umgesetzt werden. Was aber eininteressanter Aspekt wäre, da für eine solche Darstellung, Kategorien zu den einzelnenTags zugeordnet werden müssten. Diese sind aber leider nicht für jedes Tag vorhandenund müssten auf einen anderen Weg beschafft werden. Außerdem ist es schwer zubewerten, welches Tag welcher Kategorie zugeordnet wird.
Das zirkuläre Layout geht vom Zentrum mit dem populärsten Tag aus, in Richtungder Ränder. Um dieses umsetzen zu können, musste ein Algorithmus entwickelt wer-den. Dieser wird graphisch in Abbildung 7.4 gezeigt und als Pseudocode umgesetzt.
AutobahnLeibniz Universität
Autobahn AutobahnLeibniz Universität
SE
(a) (b) (c)
Abbildung 7.4.: Umsetzung des zirkulären Layouts
32
7. Implementierung
Pseudocode:
( a ) :S t a r t e Im ZentrumSchre ibe e r s t e s Wort( b ) :Nimm das nächst populäre WortPrüfe für das Wort , ob in d i e s e r Z e i l e l i n k s oder r e c h t s genug
P l a t z i s t .Wenn ja , dann s c h r e i b e es an die e r s t e passende S t e l l e .Wenn nicht , fange abwechselnd oben oder unten eine neue Z e i l e an .Schre ibe das Wort in die Mitte der Z e i l e .( c ) :Solange es Wörter und noch P l a t z in dem D i a l o g f e n s t e r gibt , mache
mit ( b ) wei ter .
Die Referenzdarstellung ist trivial, da sie dieselbe wie das sequentielle Layout ist, nurohne Gewichtung.
In Abbildung 7.5 werden die zwei realisierten Gestaltungsarten gezeigt. Dabei gehö-ren die alphabetische- und die Trefferzahl-Darstellung zum sequentiellen Layout. Diezirkuläre-Darstellung gehört zum zirkulären Layout.
(a) alphabetisch (b) Trefferzahl (c) zirkulär
(d) alphabetisch (e) Trefferzahl (f) zirkulär
Abbildung 7.5.: TagCloudClient-Darstellungen
33
7. Implementierung
7.4. Umsetzung der Routenberechnung
Es wird gezeigt, wie die Daten für die Routenberechnung ermittelt und visuell aufbe-reitet werden.
7.4.1. Routenberechnung
Für die Routenberechnung muss auf die Google Direction API [Goo10] zugegriffen wer-den. Dafür muss eine Http-Anfrage abgeschickt werden, diese benötigt eine URL. DieURL wird aus folgenden Teilen zusammengesetzt:
" ht tp ://maps . google . com/maps/api/ d i r e c t i o n s / j son ? "" o r i g i n =" ( s r c . getLat i tudeE6 ( ) /1.0 E6 )" , " ( s r c . getLongitudeE6 ( ) /1.0 E6 )"&d e s t i n a t i o n =" ( dest . getLat i tudeE6 ( ) /1.0 E6 )" , " ( dest . getLongitudeE6 ( ) /1.0 E6 ) "&mode=driving&sensor=true " )
Es wird ein JSON-Objekt zurückgeliefert. Dieses muss aufgeschlüsselt werden bis mandie Polylinien herausbekommt. Diese sind binär gespeichert und müssen decodiertwerden. Nach der Decodierung erhält man eine Liste von geografische Koordinaten.
7.4.2. Routenvisualiserung
Diese Liste von geografische Koordinaten, welche die Route bilden, werden weiterverarbeitet. Hierfür werden, in einer Schleife, alle Elemente der Liste nacheinanderaufgerufen und dabei zwischen dem aktuellen und dem nächsten Punkt eine Linie ge-zogen. Nach dem die Linie gezogen wurde, wird diese in einem Layer gespeichert. DerLayer wird über die Anwendungskarte gelegt und erscheint somit über den Straßen.Im Prototyp wurden die Punkte per Luftlinie verbunden.
34
7. Implementierung
In der Abbildung 7.6 wird die Routenvisualiserung vom Prototypen und im Vergleichdazu die TagCloudClient-Route gezeigt.
(a) Prototyp (b) TagCloudClient-Route
Abbildung 7.6.: Visualisierung der Route
7.5. Sonstige Anpassungen am Prototypen
Es wurden noch weitere Aspekte umgesetzt. Dazu gehört die erweiterte Struktur desAndroid-Projekts und weitere Anpassungen die im Prototypen nicht vorhanden wa-ren.
7.5.1. Struktur des Android-Projekts
Im Verglich zum Prototypen hat sich viel an den Ressourcen (Ordner res) getan (sie-he Abbildung 7.7). Ressourcen sind sehr wichtig um Android-Konform zu program-mieren. Hier werden alle Variablen ausgelagert. Je nach Situation können diese leichtangepasst werden. In dem Ressourcen-Ordner drawable befinden sich alle Icons undBilder die im TagCloudClient verwendet werden.
35
7. Implementierung
Da es sehr viele unterschiedliche Smartphones gibt müssen auch verschiedene Auflö-sungen dargestellt werden können. drawable -hdpi, -ldpi,-mdpi stellen die selben Iconsund Bilder in einer anderen Auflösung bereit. Der Ordner Layout beinhaltet die Ele-mente der Activity, hier die Google Maps Karte und die zoom-Buttons. Weiter wirdder Menu Ordner für die Menüpunkte einer Anwendung verwendet. Der wichtigsteRessourcen-Ordner ist values, dieser beinhaltet alle Variablen die sich schnell ändernkönnen. Die XML Datei colors speichert alle Farben, dimens alle Größen, strings alleTexte und in styles können ganze Formen gespeichert werden. values kann mit einerEndung für andere Sprachen umgesetzt werden. Um selbst definierte Daten schnelländern zu können, kann man diese in eigenen XML-Dateien auslagern. In diesem Pro-jekt wurden die XML-Dateien server_connection und google_maps_key ausgelagert.
Die Klasse SocketThread erlaubt mehreren Clients ein gleichzeitiges Zugreifen auf denServer. Dies war im Prototypen nicht der Fall, der Server war nach einer Client Anfragesolange belegt wie die Anfrage verarbeitet wurde.
Es wurde eine Vererbung für die Darstellungsarten der Tag-Cloud angelegt, damitweitere Arten der Darstellung leichter ergänzt werden können. Wie die nachfolgendeAbbildung 7.8
In diesem Kapitel werden die Ergebnisse dieser Bachelorarbeit zusammengefasst. Dannwird ein Fazit über die Arbeit gezogen, ein Ausblick auf mögliche Erweiterungen ge-geben und vorgeschlagen in welche Richtung das Thema noch gehen kann.
8.1. Zusammenfassung
Das Ziel dieser Arbeit war es ortsbezogene Informationen aus verschiedenen Quellenzu extrahieren und entlang einer Route als Tag-Cloud visuell darzustellen. Zusätzlichsollten Erweiterungsmöglichkeiten untersucht werden, die eine andere Art der Dar-stellung anbieten.
Zum Beginn dieser Arbeit wurden die Grundlagen geklärt. Zuerst wurde erklärt wiedie Entwicklungsumgebung Android aufgebaut ist, mit der die Anwendung geschrie-ben wurde. Dann ging es um den Begriff Tag-Cloud und die Gestaltungsarten. ZumSchluss wurde auf den Softwarearchitekturstil REST eingegangen, und es wurde un-tersucht ob dieser sich als möglicher Web-Service implementierten lässt.
Der bestehende Prototyp wurde analysiert. Dazu wurde ein Konzept erstellt, der struk-turelle Aufbau des Prototypen untersucht und eine Bewertung zum Prototypen abge-geben. Dadurch wurden Grundlagen geschaffen, die eine Weiterentwicklung möglichmachen.
Die Extraktion von ortsbezogenen Informationen, war ein wichtiger Aspekt dieserArbeit. Um relevante Informationen herauszuziehen, wurden mehrere Filter mit ver-schiedenen Aufgaben entwickelt und implementiert.
Nach der Filterung wurden die aufbereiteten Informationen in einer Tag-Cloud vi-sualisiert. Um die Software-Ergonomie zu verbessern, wurde der sichtbare Teil derAnwendung weiterentwickelt.
Beim dem Webservice des Konzepts wurde geprüft, ob eine Umstellung zum RESTfulWebservice sinnvoll wäre. Das Ergebnis der Untersuchung hat gezeigt, dass sich eineUmstellung lohnen würde, wenn noch andere Endgeräte Zugriff auf den Tag-CloudWebservice bekommen könnten. Außerdem wurde mit einer Webservice-Anfrage einestraßenbezogenen Route zwischen zwei Koordinaten berechnet. Abschließend wur-den weitere Quellen als Erweiterungsmöglichkeiten untersucht.
38
8. Zusammenfassung und Ausblick
Auf Basis von den vorangegangenen Untersuchungen wurde nun die Implementie-rung umgesetzt. Dabei wurde zuerst die Architektur aufgezeigt, das Client-Server-Modell beschrieben. Dann wurden die Aspekte der Filterung, der Visualisierung undder Routenberechnung umgesetzt. Dabei ist zusagen, dass bei der Filterung viel Arbeitin den Wortstammfilter und bei der Visualisierung in das zirkuläre Layout investiertwurde. Zum Schluss wurden die sonstige Anpassungen am Prototypen geschildert.
8.2. Fazit
Das Konzept und die Umsetzung zur Tag-Cloud Visualisierung ist sehr interessantund vielversprechend. Ein Benutzer kann sich mit einem Smartphone einfach, schnellund bequem Informationen zu einem Standort ausgeben lassen, die er sonst hätteselbst recherchieren müssen. Durch die strukturierte Implementierung können an vie-len Stellen Erweiterungen vorgenommen werden. Die neu implementierten Filter könn-ten durch eine Anpassung leicht auf andere Sprachen umgestellt werden.
Leider ist die Anwendung zurzeit nur Android Smartphone Besitzern vorbehaltenund ist nur auf Deutsch erhältlich. Die Quellen beziehen sich nur auf die freie Online-Enzyklopädie Wikipedia, hier sollten noch weitere Quellen miteinbezogen werden,um eine größere Vielfalt und Unabhängigkeit schaffen zu können. Bei vielen Anfra-gen, die nahe bei einander liegen kann es schnell zur Unübersichtlichkeit führen, dasich die Tag-Cloud Darstellungen überschneiden. Außerdem kann man sich nur eineRoute darstellen lassen. Es wäre wünschenswert mehrere Anfragen laden und spei-chern zu können.
Zusammenfassend lässt sich sagen, dass die Anwendung gewünschte Ergebnisse lie-fert. Die Bedienung der Anwendung lässt sich schnell verstehen und ist an die Andro-id Konventionen angepasst. Teilweise ist die Anwendung noch etwas verbesserungs-würdig, wenn es um den Inhalt der Informationen geht. Deshalb sollten noch mehrQuellen implementiert werden.
8.3. Ausblick
Das Konzept zur Tag-Cloud Visualisierung und die daraus umgesetzte Anwendungsind nicht ganz ausgereizt. Aus zeitlichen Gründen konnten manche Ansätze nichtweiter verfolgt werden. Nachfolgenden werden die Ansätze beschrieben.
Die Implementierung eines RESTful Webservice ist zu empfehlen, damit andere Platt-formen auf den Server zugreifen können. Außerdem könnte noch eine webbasierteAnwendung geschrieben werden.
Es könnten noch andere Visualisierungsmöglichkeiten überlegt werden. Wie die Inte-gration von Audio-, Bilddaten oder anderen Formen der Textdarstellung.
39
8. Zusammenfassung und Ausblick
Bei einem zu groß gewählten Radius werden zu viele georeferenzierte Punkte abge-fragt, sodass der Server abstürzen könnte. Um dies zu verhindern wurde ein maxi-maler Radius implementiert. Dies ist zwar sinnvoll in Städten, aber in weitläufigenGegenden erscheint einem der Radius zu klein. Ein Lösungsansatz wäre es eine Vor-abfrage, dabei ermittelt der Server nur wie viele Punkte im Radius gefunden wurden.Wenn zu viele Punkte gefunden wurden, gibt der Server dem Client eine Warnmel-dung aus. Oder er verkleinert von sich aus den Radius auf ein Maximum an gewähltenPunkten.
Zur Zeit lässt sich nur eine Abfrage darstellen, es wäre schön Abfragen laden undspeichern zu können. Beim Starten der Applikation befindet man sich sofort auf derKarte. Es müsste eine weitere Activity geschrieben werden, die zuerst aufgerufen wirdund ein Hauptmenü darstellt. Dort kann man dann ein Profil laden und speichern,einfach zur Karte wechseln und die Anwendung beenden.
Abschließend kann noch erwähnt werden, dass durch die Entwicklungsumgebungvon Android die Anwendung sich ganz einfach in andere Sprachen überführen lässt.Hierbei ist zu beachten, dass die Filter und die Quelle auf die jeweilige Sprache umge-stellt werden müssten. Die Schnittstellen sind dafür sauber geschrieben, aber es erfor-dert weitere Arbeit um dies umzusetzen.
40
Literaturverzeichnis
[Bec10] BECKER, Arno und PANT, Marcus: Android 2 Grundlagen und Programmie-rung, Dpunkt Verlag; Auflage: 2. (2010)
[Car10] CARSTENSEN, Kai-Uwe; EBERT, Christian; EBERT, Cornelia; JEKAT, Susanne;KLABUNDE, Ralf und LANGER, Hagen: Computerlinguistik und Sprachtechno-logie : eine Einführung, Spektrum Akad. Verl. (2010)
[dL06] DE LANGE, Norbert: Geoinformatik in Theorie und Praxis, Springer (2006)
[Egg10] EGGERT, Daniel; PAELKE, V.; DAHINDEN, T. und MONDZECH, J.: Loccationbased context awareness throug tag-cloud visualizations, Techn. Ber., Institutfür Kartographie und Geoinformatik, Leibniz Universität Hannover (2010)
[Fie00] FIELDING, Roy Thomas: Architectural Styles and the Design of Network-based Software Architectures. university of California, Irvine (2000):S.Kapitel 5, URL http://www.ics.uci.edu/~fielding/pubs/dissertation/rest_arch_style.htm
[FSF03] FSFHU, Foundation: JNA (2003), URL https://github.com/twall/jna
[Lüb08] LÜBKE, Daniel: An Integrated Approach for Generation in Service-Oriented Ar-chitecture Projects, Dr. Kovac (2008)
[Loh09] LOHMANN, Steffen; ZIEGLER, Jürgen und TETZLAFF, Lena: Ein Blick in dieWolken: Visuelle Exploration von Tag Clouds, in: Mensch & Computer 2009:Grenzenlos frei!?, Oldenbourg Verlag (2009), S. S. 303–312
[May99] MAYHEW, Deborah J.: The Usability Engineering Lifecycle: A Practitioner’sHandbook for User Interface Design, Morgan Kaufmann (1999)
[Vin75] VINCENTY, T.: Direct and inverse solutions of deodesics on the ellipsoidwith application of nested equations (1975), URL http://www.ngs.noaa.gov/PUBS_LIB/inverse.pdf
[Wik08] WIKIMEDIA, Foundation: Media Wiki API (2008), URL http://www.mediawiki.org/wiki/API:Main_page/de
[Wik11] WIKIPEDIA, Foundation: Projekt Georeferenzierung (2011), URLhttp://de.wikipedia.org/wiki/Wikipedia:WikiProjekt_Georeferenzierung/Wikipedia-World
[Wäs10] WÄSCHLE, Katharina: FolkTagCloud, Eine Social-Tagging-Komponente für dasSemantic MediaWiki, Fraunhofer Verlag (2010)
Zusätzlich zur gedruckten Ausgabe liegt dieser Arbeit eine CD bei.
Die CD enthält:
− eine Version dieser Ausarbeitung im PDF Format
− eine Version dieser Ausarbeitung im Latex Format
− Das Programm als Eclipse Android Projekt
− Die Tag-Cloud Application
48
Erklärung der Selbstständigkeit
Hiermit versichere ich, dass ich die vorliegende Bachelorarbeit selbständig und ohnefremde Hilfe verfasst und keine anderen als die in der Arbeit angegebenen Quellenund Hilfsmittel verwendet habe. Die Arbeit hat in gleicher oder ähnlicher Form nochkeinem anderen Prüfungsamt vorgelegen.