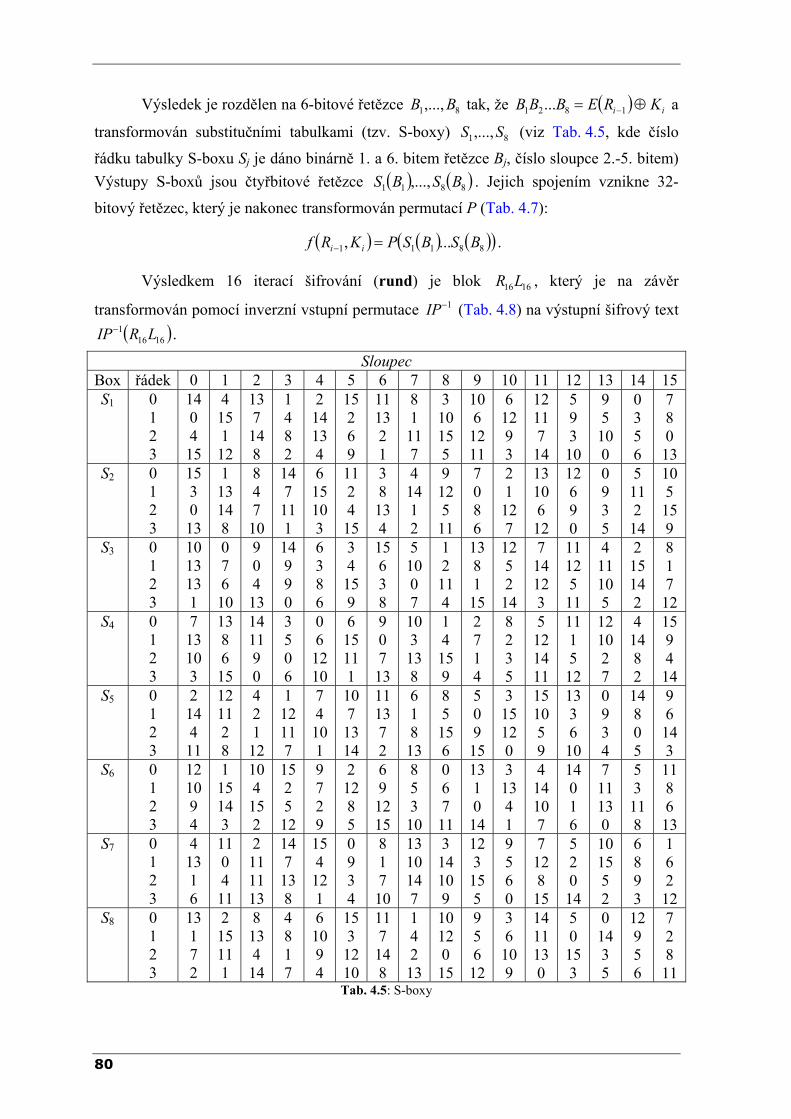
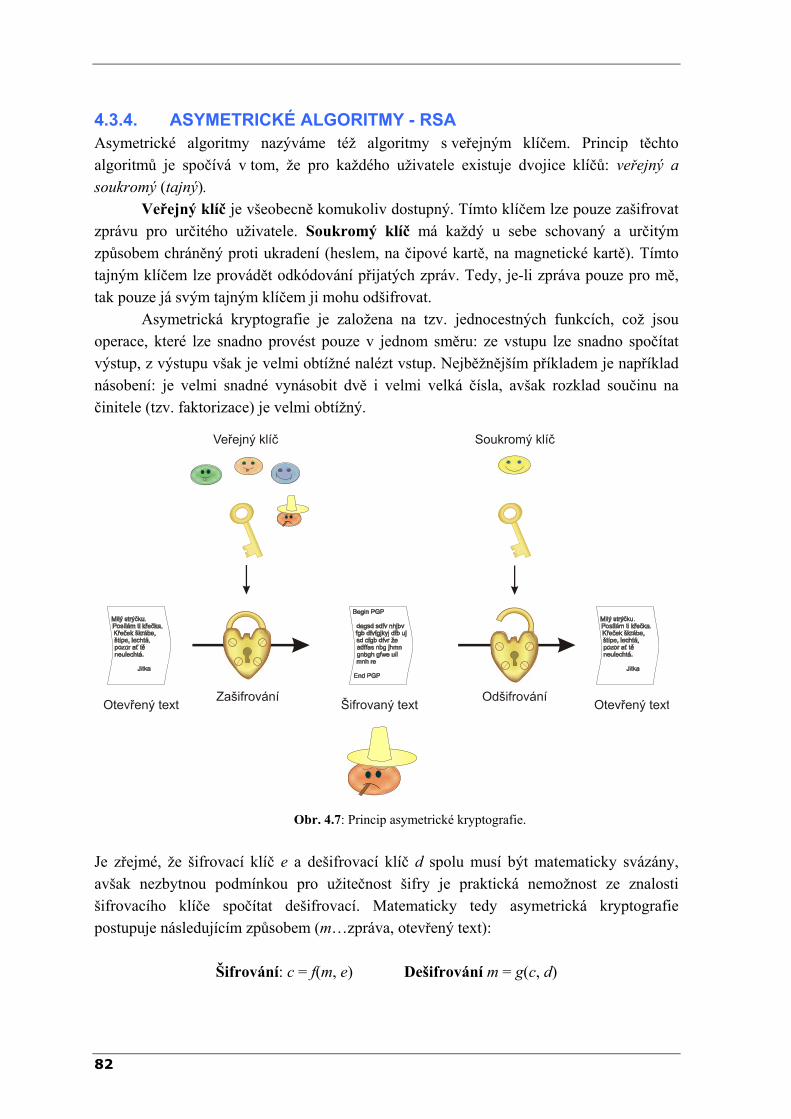
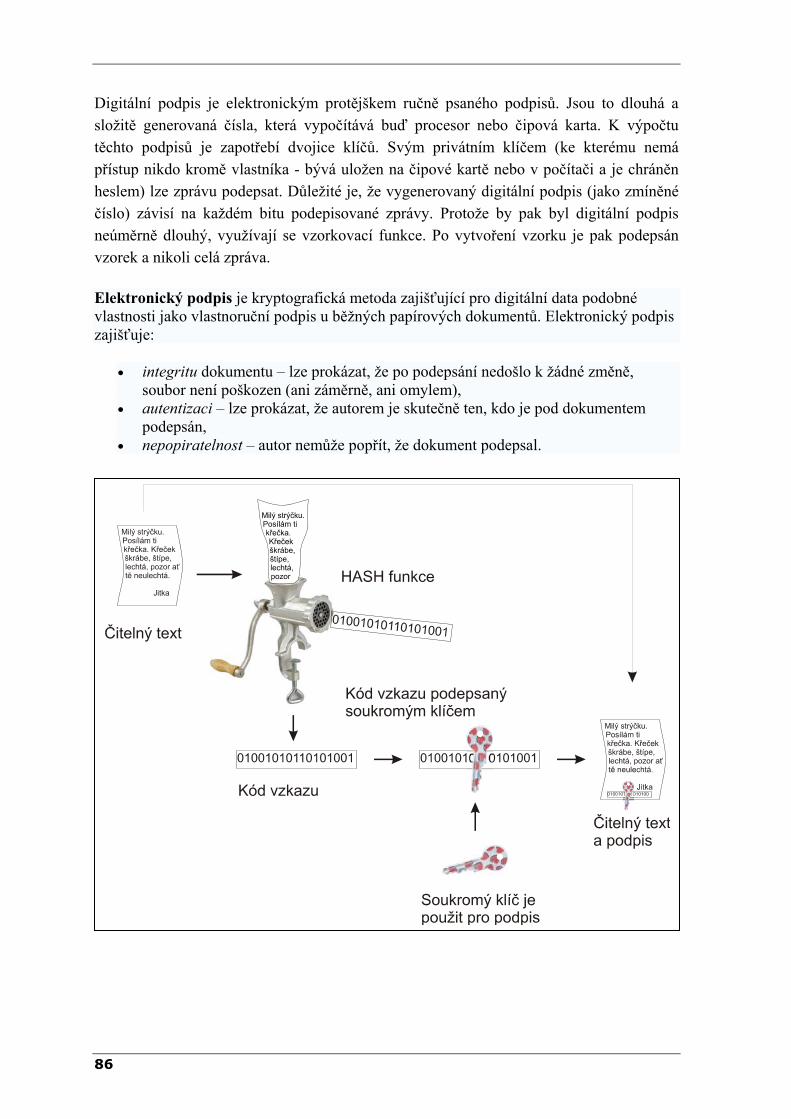
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ FAKULTA STROJNÍHO INŽENÝRSTVÍ ODBOR APLIKOVANÉ INFORMATIKY Ing. Radomil Matoušek, Ph.D. METODY KÓDOVÁNÍ VER. 1.9 Studijní text vznikl s podporou projektu FRVŠ 3420/2006 Brno 2006
Transcript
VYSOKÉ UČENÍ TECHNICKÉ V BRNĚ FAKULTA STROJNÍHO INŽENÝRSTVÍ
ODBOR APLIKOVANÉ INFORMATIKY
Ing. Radomil Matoušek, Ph.D.
METODY KÓDOVÁNÍ
VER. 1.9
Studijní text vznikl s podporou projektu FRVŠ 3420/2006 Brno 2006
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK i
DOHODNUTÁ SYMBOLIKA III ÚVOD IV
1. KÓDOVÁNÍ 1
1.1. BĚŽNÉ PŘÍKLADY KÓDOVÁNÍ 1 1.1.1. KÓDOVÁNÍ ZNAKŮ PANA SAMUELA F. B. MORSEHO, TZV. MORSEOVKA 1 1.1.2. ČÁROVÝ KÓD 1 1.1.3. ENDIANITA – ZPŮSOB KÓDOVÁNÍ ČÍSEL V ELEKTRONICKÉ PAMĚTI 5 1.1.4. KÓDOVÁNÍ ZNAKŮ POMOCÍ ASCII TABULKY 6 1.1.5. ČÍSELNÉ SOUSTAVY 8 1.2. GRAYŮV KÓD 10 1.3. ZÁKLADNÍ POJMY 11 1.4. BLOKOVÉ A PREFIXOVÉ KÓDOVÁNÍ 12 1.4.1. BLOKOVÉ KÓDOVÁNÍ 12 1.4.2. PREFIXOVÉ KÓDOVÁNÍ 13 1.4.3. KONSTRUKCE PREFIXOVÉHO KÓDU 14
2. MINIMÁLNÍ KÓDOVÁNÍ – TEXTOVÁ KOMPRESE 17
2.1. MORSEŮV PRINCIP 20 2.2. NEJKRATŠÍ KÓD - HUFFMANOVA KONSTRUKCE 21 2.2.1. HUFFMANNOVA KONSTRUKCE BINÁRNÍHO KÓDU (1952) 23 2.2.2. HUFFMANNOVA KONSTRUKCE OBECNÉHO KÓDU 26 2.2.3. FANOVA-SHANNONOVA KONSTRUKCE BINÁRNÍHO KÓDU 27 2.2.4. METODA POTLAČENÍ NUL 28 2.2.5. METODA PROUDOVÉHO KÓDOVÁNÍ - RLE ALGORITMUS 28 2.2.6. SLOVNÍKOVÉ METODY – LEMPEL-ZIV KÓDOVÁNÍ 29 2.2.7. MOVE-TO-FRONT FILTER (MTF) 31 2.2.8. BURROWS-WHEELEROVA TRANSFORMACE (BWT) 32
3. BEZPEČNOSTNÍ KÓDOVÁNÍ – DETEKČNÍ A KOREKČNÍ KÓDY 35
3.1. OBJEVOVÁNÍ CHYB 37 3.2. HAMMINGOVA VZDÁLENOST A GEOMETRICKÁ INTERPRETACE 38 3.2.1. HAMMINGOVA VZDÁLENOST 38 3.2.2. GEOMETRICKÁ INTERPRETACE 39 3.3. ZABEZPEČUJÍCÍ SCHOPNOST KÓDU 40 3.3.1. DETEKČNÍ SCHOPNOST KÓDU 40 3.3.2. KOREKČNÍ SCHOPNOST KÓDU 41 3.3.3. DEKÓDOVÁNÍ 42 3.3.4. INFORMAČNÍ ZNAKY 42 3.4. LINEÁRNÍ KÓDY 44 3.4.1. STRUČNÁ TEORIE LINEÁRNÍCH BINÁRNÍCH BLOKOVÝCH KÓDŮ 45 3.5. GENERUJÍCÍ MATICE 50 3.6. KONTROLNÍ MATICE 52 3.6.1. DUÁLNÍ KÓD 52 3.6.2. PRINCIP ZABEZPEČENÍ (DEKÓDOVÁNÍ POMOCÍ SYNDROMU) 53 3.7. PERFEKTNÍ KÓDY 54 3.8. HAMMINGOVY KÓDY 55 3.8.1. PRINCIP ROZŠÍŘENÍ KÓDU 55 3.9. GOLAYOVY KÓDY 57
ii
3.10. CYKLICKÉ KÓDY 58
4. KRYPTOGRAFICKÉ KÓDOVÁNÍ - KRYPTOGRAFIE 63
4.1. NÁZVOSLOVÍ 64 4.1.1. STEGANOGRAFIE 65 4.1.2. SUBSTITUČNÍ ŠIFRY 65 4.1.3. TRANSPOZIČNÍ ŠIFRY 65 4.2. HISTORICKÉ POZNÁMKY 66 4.2.1. KRYPTOGRAFIE ŘECKA A ŘÍMA 66 4.2.2. CAESAROVA ŠIFRA 67 4.2.3. TEMNÝ STŘEDOVĚK 67 4.2.4. VIGENEROVA ŠIFRA 68 4.2.5. VZESTUP KRYPTOGRAFIE – VÁLKA A TELEGRAF 69 4.2.6. VERMANŮV KRYPTOSYSTÉM 70 4.2.7. MODERNÍ DOBA 71 4.3. SYMETRICKÉ A ASYMETRICKÉ ŠIFROVÁNÍ 72 4.3.1. KERCKHOFFŮV PRINCIP 73 4.3.2. SYMETRICKÉ ALGORITMY 74 4.3.3. DES (DATA ENCRYPTION STANDARD) 76 4.3.4. ASYMETRICKÉ ALGORITMY - RSA 82 4.3.5. HASHOVACÍ FUNKCE 84 4.3.6. DIGITÁLNÍ PODPIS 85
METODY KÓDOVÁNÍ
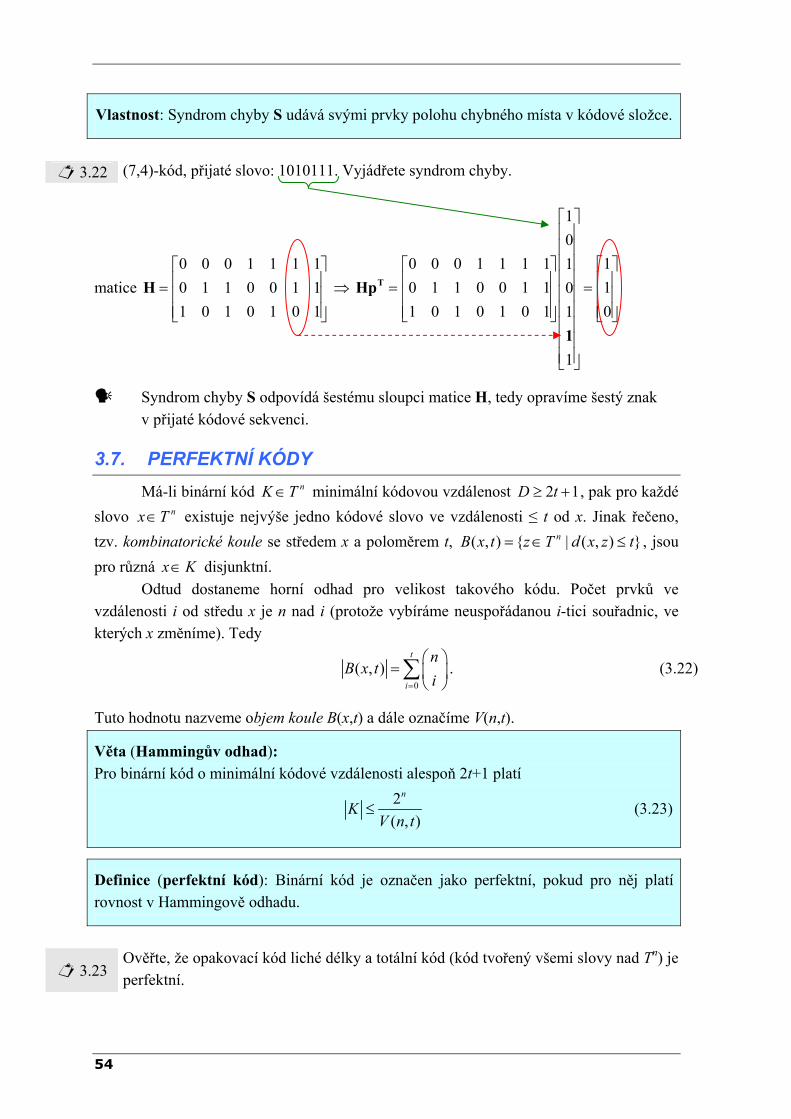
2006 – Radomil MATOUŠEK iii
Dohodnutá symbolika
Pro snazší orientaci v dokumentu i jeho příslušnou pragmatičnost byly zvoleny piktogramy, které vhodně navádějí čtenáře k danému cíli. V úvodu hlavních kapitol je výpravnou formou uvedena . Na závěr kapitol jsou položeny kontrolní otázky , přes které by měl čtenář „projít“, pokud chce danou kapitolu prohlásit za ujasněnou. Některé kapitoly jsou rovněž zakončeny odkazem na vědomostní kviz v elektronické podobě, ve kterém si může čtenář, v podstatě zábavnou formou, ověřit své vědomosti v dané oblasti. Součástí studijního textu je množství příkladů , z nichž některé jsou vzorově řešeny, jiné obsahují nápovědu či další úkol . Jednou ze stěžejních částí tohoto elektronického textu jsou interaktivní příklady , které intuitivním způsobem umožní čtenáři rychle pochopit podstatu prezentovaného problému (na CD adresář /flash). Tyto příklady lze volat, jak přímo z elektronické verze tohoto dokumentu, tak je nalézt a spustit samostatně z dále uvedeného web odkazu. Celý text je doplněn příslušnou foto dokumentaci , která by ho jinak neúměrně rozšiřovala. Základní referenční zdroje jak literární, tak elektronické jsou uvedeny včetně stručného a komentáře. V textu jsou zařazeny některé historické poznámky či jiné zajímavosti , které doufejme vhodně „doplňují atmosféru“ diskutovaného tématu.
Jak bylo uvedeno, předkládaný učební text je ve své elektronické formě provázán s řadou interaktivních příkladů, doplňkových obrazových dokumentů a dále dostupných hypertextů. Přesto, že plná funkčnost tohoto učebního textu je umožněna pouze v elektronické podobě, byl text tvořen i se zřetelem na jeho možnou čistě textovou podobu. V této formě je tedy možné učební text bez problému samostatně vytisknout a využít ke studiu. Užité interaktivní, samostatně funkční aplikace jakož i vlastní text jsou dostupné na www.uai.fme.vutbr.cz/~matousek/tik/index.html. K plné funkčnosti aplikací je třeba mít nainstalovány následující softwarové technologie:
Adobe Reader Adobe Flash Player
motivace odkaz na interaktivní příklady příklady další úkol, nápověda odkaz na doprovodnou dokumentaci kviz vědomostí kontrolní otázky poznámka, zajímavost literatura, reference
CodeExamples7.swf Demonstrační aplikace k teorii kódů.
Teorie kódování je jedna z nejfantastičtějších součástí současné informatiky. Zabývá se jak konstrukcemi kódu, tak studiem jejich vlastností. Její působení, ať si to uvědomujeme či ne, je skutečně všudypřítomné. Je tomu tak nyní, bylo tomu před mnoha lety a bude tomu, jak se dá předpokládat, i v časech budoucích, a to mnohem, mnohem intenzivněji. Vznik současné teorie kódování je v podstatě datován již od čtyřicátých let, a to pracemi Shannona , které byly věnovány teorii informace a dále hlavně Hamminga s Golayem, kteří zkonstruovali první lineární kódy. Praktický boom pak nastal s příchodem „použitelné“ výpočetní techniky.
Kódování lze dle účelu rozdělit na několik samostatných částí, které se v praxi mohou dokonce velmi často prolínat:
• Minimální kódování (komprese dat): Jedná se o způsob kódování, jehož účelem je zmenšit objem dat ve zprávě. Dle práce s informací je toto kódování dále děleno na bezztrátové a ztrátové. Typickými a prakticky všem známými představiteli první skupiny jsou komprimační programy (ARJ, ZIP, RAR, aj.). Reprezentanty druhé skupiny jsou většinou nástroje pracující s obrazem nebo zvukem, a z nich vyplývající datové formáty (JPEG, MPG, MP3, aj.).
• Bezpečnostní kódování (Samoopravné kódy): Toto kódování je užito pro přenos informace reálným přenosovým kanálem, tj. kanálem, kde může dojít k ovlivnění přenášené informace vlivem chyby. Smyslem bezpečnostního kódováni je detekovat, případně i přímo opravit vzniklou chybu. Jedním z nejfrekventovanějších představitelů využití části této teorie kódů je realizace zabezpečení paketů v síti internet, tzv. CRC kódem.
• Kryptografické kódování (kryptografie): V tomto případě se jedná o kódování mající vztah k utajení informace. Tento typ kódování je nejčastěji znám a skloňován jedním slovem – „šifrování“. Šifrování obecně zahrnuje, jak jednoduché postupy známé z rébusů či junáckých her, tak opravdu silné algoritmy k jejichž prolomení by při současné technice nestačilo ani stáří vesmíru. O tom, že informace mohou mít „cenu zlata“ není pochyb. Utajení takovéto informace má pak cenu snad ještě vyšší.
Aparát teorie kódování sahá od praktických inženýrských implementací až po čistě teoretické aspekty, zahrnující mnoho matematických disciplín jako teoretickou informatiku, kombinatoriku, algebru , aj. Základní znalost těchto partií matematiky je pro další studium tohoto textu předpokládána. V rámci předkládaného základního kurzu metod kódování samozřejmě není možné vše obsáhnout. Základní informace podané v tomto textu by však měly sloužit jako dobrý základ pro pochopení funkce a možnosti konstrukce vybraných kódů. Text není v žádném případě publikován v matematickém stylu (důkazy předložených vět je možné naleznout v uvedené literatuře) a ani si tento cíl neklade. Elektronickou součástí tohoto textu jsou interaktivní příklady, na kterých si může čtenář vyzkoušet zda prezentované látce rozumí či naopak. Seznam použitých a doporučených zdrojů pro případné další studium je vždy uveden na konci dané kapitoly, včetně stručného komentáře k uvedenému zdroji. Ze současných autorů bych chtěl na tomto místě, mimo jiných, poděkovat a zároveň jmenovat prof. Jiřího Adámka, který svojí skvělou publikací Kódování výrazně přispěl i k mému zájmu o tento obor. Dále děkuji neodmyslitelně těm mým nejbližším, kteří to se mnou po dobu přípravy tohoto textu neměli lehké.
V Brně, 23. 12. 2006. Autor.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK v
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 1
1. KÓDOVÁNÍ Equation Chapter 1 Section 1
„Alea iacta est.“ Gaius Iulius Caesar
Poté co Caesar neuposlechl rozhodnutí senátu a počátkem roku 49 př. n. l. překročil Rubikon, pronesl známou sentenci: „Kostky jsou vrženy“. Pokud dnes mnozí z nás hrají čas od času tuto hru náhody pravděpodobně danou informaci o stavu dění neříkají. Místo toho pečlivě zapisují výsledky dosažených hodů. Představme si, že hrajeme kostky a máme poměrně jednoduchá pravidla hry typu sečti výsledky všech hodů a zapiš je na list papíru. Málo kdo by asi hod šestky zapsal jako šest ok, což je reálné zobrazení stavu kostky. Většinou všichni zapíší číslici 6. Ano je to tak, právě jste uskutečnili kódování! Systém kostek generuje konečnou množinu stavů, my volíme systém pravidel a tyto stavy kódujeme do množiny námi zvolených symbolů (například číselných hodnot).
1.1. Běžné příklady kódování Dále si ukážeme některé běžně užívané systémy kódování, jejichž význam již
čtenář pravděpodobně zná.
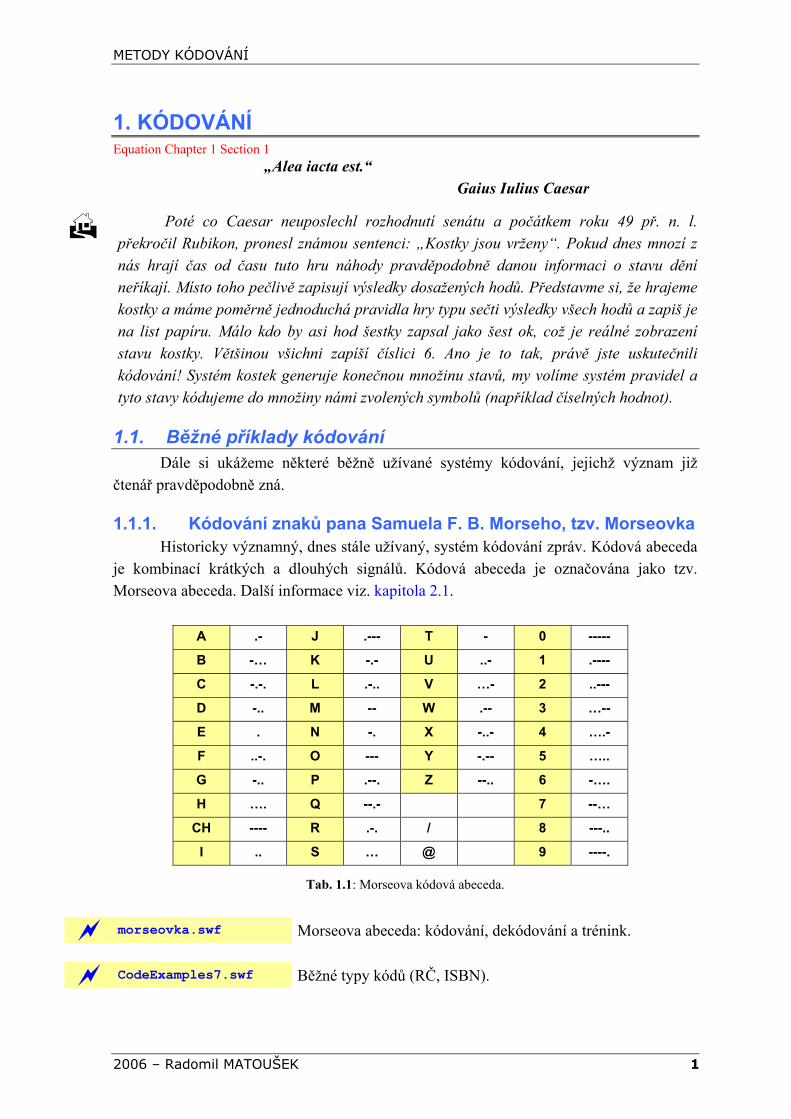
1.1.1. Kódování znaků pana Samuela F. B. Morseho, tzv. Morseovka Historicky významný, dnes stále užívaný, systém kódování zpráv. Kódová abeceda
je kombinací krátkých a dlouhých signálů. Kódová abeceda je označována jako tzv. Morseova abeceda. Další informace viz. kapitola 2.1.
A .- J .--- T - 0 -----
B -… K -.- U ..- 1 .----
C -.-. L .-.. V …- 2 ..---
D -.. M -- W .-- 3 …--
E . N -. X -..- 4 ….-
F ..-. O --- Y -.-- 5 …..
G -.. P .--. Z --.. 6 -….
H …. Q --.- 7 --…
CH ---- R .-. / 8 ---..
I .. S … @ 9 ----.
Tab. 1.1: Morseova kódová abeceda.
morseovka.swf Morseova abeceda: kódování, dekódování a trénink.
CodeExamples7.swf Běžné typy kódů (RČ, ISBN).
2
1.1.2. Čárový kód Čárové kódy řadíme do oblasti tzv. „automatické identifikace“, jinak řečeno do
oblasti kdy k registraci dat neužíváme klávesy. Do stejné oblasti můžeme rovněž zařadit magneticky a elektronicky čitelné kódy, např. na kreditních kartách nebo strojově čitelné písmo OCR.
Symbol čárového kódu se skládá z tmavých čar a ze světlých mezer, které se čtou pomocí snímačů vyzařujících většinou červené světlo . Toto světlo je pohlcováno tmavými čárami a odráženo světlými mezerami. Snímač zjišťuje rozdíly v reflexi a ty přeměňuje v elektrické signály odpovídající šířce čar a mezer. Tyto signály jsou převedeny v číslice, popř. písmena, která obsahuje příslušný čárový kód. To tedy znamená, že každá číslice či písmeno je zaznamenáno v čárovém kódu pomocí předem přesně definovaných šířek čar a mezer. Data obsažená v čárovém kódu mohou zahrnovat takřka cokoliv: číslo výrobce, číslo výrobku, místo uložení ve skladu, číslo série nebo dokonce jméno určité osoby, které je např. povolen vstup do jinak uzavřeného prostoru.
Symbol začíná znakem start, pak následují vlastní data s případným kontrolním součtem, a na konci je znak stop. Šířka čar a mezer, jakož i jejich počet, je dán specifikací symboliky příslušného kódu. Termín "symbolika" se používá pro popis pravidel, specifikujících způsob jakým se kódují data do čar a mezer čárových kódů.
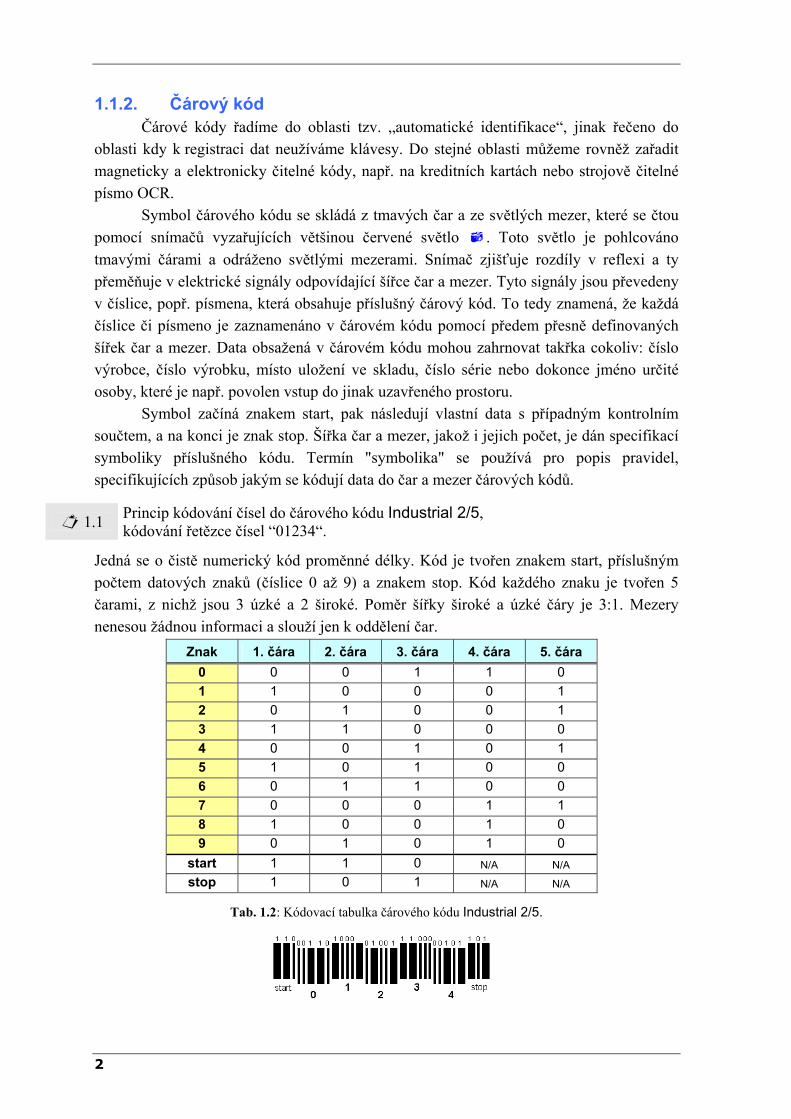
1.1 Princip kódování čísel do čárového kódu Industrial 2/5, kódování řetězce čísel “01234“.
Jedná se o čistě numerický kód proměnné délky. Kód je tvořen znakem start, příslušným počtem datových znaků (číslice 0 až 9) a znakem stop. Kód každého znaku je tvořen 5 čarami, z nichž jsou 3 úzké a 2 široké. Poměr šířky široké a úzké čáry je 3:1. Mezery nenesou žádnou informaci a slouží jen k oddělení čar.
Charakteristika nejznámějších typů čárových kódů: CODE39 první kód vytvořený pro kódovaní alfanumerických znaků již v roce
1974, časté použití v průmyslu, zdravotnictví nebo obchodě, INTERLAVED přijat jako standard v přepravě kontejnerů, CODABAR většinou používán v knihovnictví, evidenci krevních vaků,
expresních přepravních službách, CODE128 kóduje kompletní tabulku znaků ASCII 128, CODE11 vysoká hustota, použití v mikroelektronice, UPC a EAN nejpopulárnější kódy známé především z prostředí obchodů se
zbožím, PDF417 nová generace čárového kódu - dvourozměrný (2D) čárový kód ,
obsáhne mnohem více informací, má také schopnost detekce a oprav chyb při porušení kódu.
1.2 Princip kódování znaků do čárového kódu EAN 13 kódování řetězce čísel “8591234123457“.
Jedná se o numerický kód pevné délky. Obsahuje dva stejné okrajové znaky (start ≡ „S“/stop ≡ „S“), dělicí znak „D“ a 13 numerických znaků (číslice 0 až 9). Symbol čárového kódu EAN 13 lze najít na obalu téměř každého zboží , které si zakoupíte v obchodě. Symbol bývá často doplněn "lidsky čitelnými" číslicemi, které uvádí, co je vlastně symbolem čárového kódu zakódováno. Pokud jsou první tři číslice 859, jedná se o
zboží, vyrobené v České republice. Nosičem informace v kódu EAN 13 jsou
čáry i mezery. Mohou mít různou šířku, která je ale vždy násobkem šířky nejužšího elementu. Šířka nejužšího elementu představuje základní délkovou jednotku. Každý zakódovaný znak má v symbolu čárového kódu EAN 13 délku přesně 7 základních jednotek.
Na základě pevné délky kódu znaku (7 jednotek) byly vytvořeny pro kódování číslic 0 až 9 tři znakové sady, pojmenované A, B a C. Znakové sady jsou uvedeny v následující tabulce. Symbol čárového kódu EAN 13 je uprostřed rozdělen dělicím znakem na dvě části, zvané pole. První pole je vlevo od dělicího znaku, druhé pole je vpravo.
Tab. 1.3: Kódovací tabulka pro čárový kód EAN.
4
První pole: Pokud by byly všechny kódy brány z jedné znakové sady, bylo by možno do každého pole zakódovat 6 znaků. Podíváte-li se ale na vytištěný symbol EAN 13, uvidíte, že v prvním (levém) poli je 7 znaků.
Je zde totiž použita „finta“, která umožní do tohoto pole přidat ještě jeden znak tím, že se pro kódování nepoužije jen jedna znaková sada, ale použijí se dvě. Dělá se to pro to, že do prvního pole je třeba umístit 7 znaků (kód země a kód výrobce).
První číslice kódu země není přímo reprezentována čárovým kódem, ale vyplývá z označení sad, z níž se berou kódy pro 2. až 7. číslici, tj. šestici číslic v prvním poli. Pro zdůraznění této anomálie se v „lidsky čitelné“ numerické reprezentaci symbolu čárového kódu píše první číslice vlevo od levého okrajového znaku a ne spolu s ostatními šesti číslicemi uvnitř prvního pole.
Česká republika má přidělen kód země 859, první číslice je tedy 8, ale v prvním poli budou kódy číslic 5, 9 a další 4 číslice patřící k označení kódu výrobce. Jak vyplývá z následující tabulky, budou v našem případě brány kódy šesti znaků v prvním poli ze znakových sad A, B, A, B, B, A. Dekodér čárového kódu pak z této skutečnosti odvodí, že první číslicí má být číslice 8.
Tab. 1.4: Dekódování první číslice kódu EAN
Druhé pole: V tomto poli je zakódováno číslo výrobku (5 číslic) a znak kontrolního součtu (1 číslice). Všechny znaky jsou zde kódovány ze znakové sady C. Znak kontrolního součtu vypočteme tak, že všech 12 číslic podrobíme následující matematické operaci. Stejnou operaci pak provede po sejmutí čárového kódu dekodér čtecího zařízení a dospěje-li ke stejnému výsledku, bude pokládat čtení za úspěšné. Výpočet:
Sečtou se hodnoty číslic na sudých pozicích a výsledek se vynásobí třemi. Sečtou se hodnoty číslic na lichých znakových pozicích. Sečtou se obě výsledné hodnoty a výsledek se zaokrouhlí nahoru na celé desítky. Kontrolní číslice je rozdíl zaokrouhlené a původní hodnoty.
Výpočet kontrolní číslice pro řetězec čísel 859123412345 Součet sudých pozic: 5+1+3+1+3+5 = 18
Článek se věnuje historii vzniku čárového kódu. Popisuje počátky vzniku čárového kódu na univerzitách, požadavky jednoho obchodního potravinového řetězce spojené s prací Bernarda Silvera a Norberta Josepha Woodlanda, kteří si svoji práci nechali později patentovat, následné pronikání čárového kódu do obchodních řetězců a instalaci scannovacích systémů.
[online] Adams, Russ Universal Product Code (UPC) and EAN Article Numbering Code (EAN) Page (in Bar Code 1)
Autor v článku podává obecnou charakteristiku UPC a EAN. Zabývá se srovnáním kódů, charakteristikou jednotlivých verzí a obecnými otázkami jakými jsou např: jak získat UPC či jak získat seznam všech kódů produktů.
1.1.3. Endianita – způsob kódování čísel v elektronické paměti Endianita je způsob kódování čísel v elektronické paměti, který definuje, v jakém
pořadí se uloží jednotlivé bajty příslušného datového typu. Endiánovatost je základní filosofií dané platformy a všeobecně platí, že portování programů či dokonce operačních systémů z malého endiánu na velký a naopak je velice obtížné a v řadě případů je nutné celé přeprogramování.
Prozatím jediným druhem procesoru, který je schopen pracovat jak s malým tak velkým endianem, tj. tzv. bi-endian, je procesor PowerPC. Big-endian: V tomto případě se na paměťové místo s nejnižší adresou uloží nejvíce významný bajt a za něj se ukládají ostatní bajty až po nejméně významný bajt .
1.3 32bitové číslo 0x4A3B2C1D se na adresu 100 uloží následujícím způsobem:
Little-endian: V tomto případě se na paměťové místo s nejnižší adresou uloží nejméně významný bajt a za něj se ukládají ostatní bajty až po nejvíce významný bajt .
1.4 32bitové číslo 0x4A3B2C1D se na adresu 100 uloží následujícím způsobem:
Původ slova (big a little endian) je u Gulliverových cest Jonathana Swifta, kde se národ liliputánů dělil místo na politické strany na dvě nesmiřitelné skupiny - jedna rozbíjela vajíčko na měkko na tlustším konci (big endian) a druhá na tenčím (little endian).
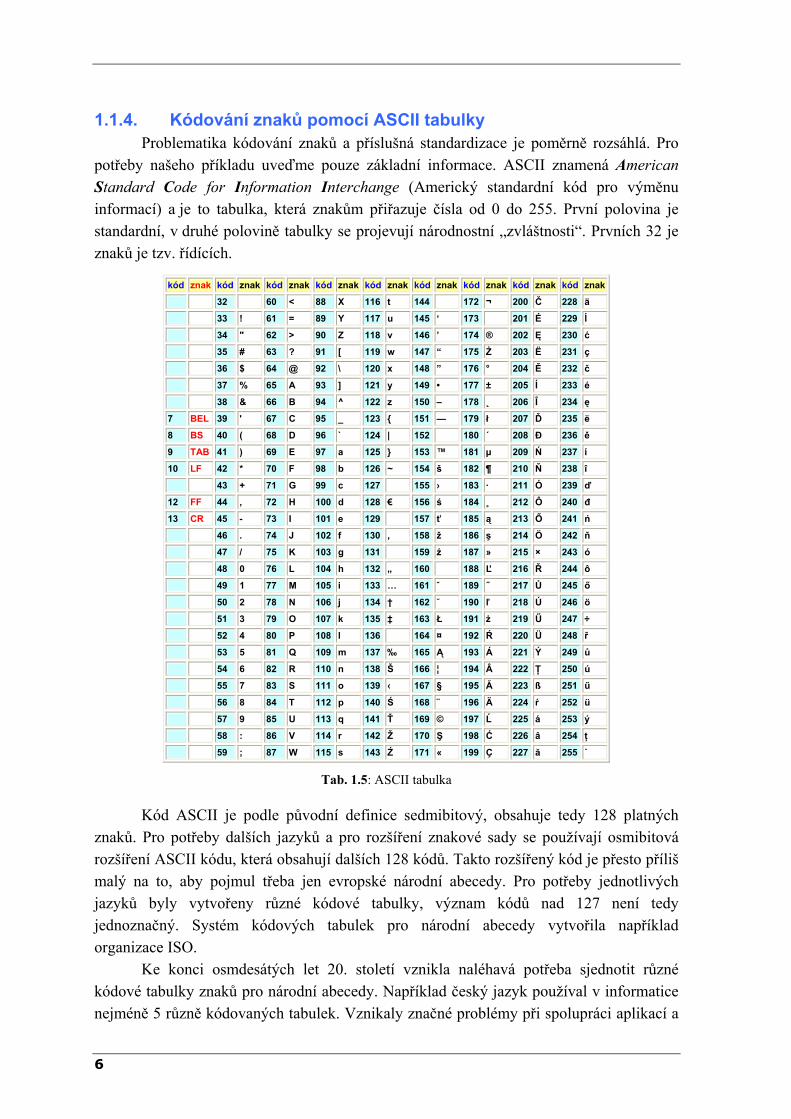
1.1.4. Kódování znaků pomocí ASCII tabulky Problematika kódování znaků a příslušná standardizace je poměrně rozsáhlá. Pro
potřeby našeho příkladu uveďme pouze základní informace. ASCII znamená American Standard Code for Information Interchange (Americký standardní kód pro výměnu informací) a je to tabulka, která znakům přiřazuje čísla od 0 do 255. První polovina je standardní, v druhé polovině tabulky se projevují národnostní „zvláštnosti“. Prvních 32 je znaků je tzv. řídících.
kód znak kód znak kód znak kód znak kód znak kód znak kód znak kód znak kód znak
Kód ASCII je podle původní definice sedmibitový, obsahuje tedy 128 platných znaků. Pro potřeby dalších jazyků a pro rozšíření znakové sady se používají osmibitová rozšíření ASCII kódu, která obsahují dalších 128 kódů. Takto rozšířený kód je přesto příliš malý na to, aby pojmul třeba jen evropské národní abecedy. Pro potřeby jednotlivých jazyků byly vytvořeny různé kódové tabulky, význam kódů nad 127 není tedy jednoznačný. Systém kódových tabulek pro národní abecedy vytvořila například organizace ISO.
Ke konci osmdesátých let 20. století vznikla naléhavá potřeba sjednotit různé kódové tabulky znaků pro národní abecedy. Například český jazyk používal v informatice nejméně 5 různě kódovaných tabulek. Vznikaly značné problémy při spolupráci aplikací a
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 7
při přenosech dat mezi programy a různými platformami. Podobná situace byla ve všech jazycích, které nevystačily se základní 7bitovou tabulkou ASCII znaků.
V té době vznikly současně dva projekty pro vytvoření jednotné univerzální kódovací tabulky znaků. Byl to projekt ISO 10646 organizace ISO a projekt Unicode. Norma ISO definuje tzv. UCS - Universal Character Set.
Kolem roku 1991 došlo k dohodě a projekty spojily své úsilí na vytvoření jednotné tabulky. Oba projekty stále existují a publikují své standardy samostatně, ale tabulky znaků jsou kompatibilní a jejích rozšiřování je koordinováno.
Unicode verze 1.1 odpovídá normě ISO 10646-1:1993, Unicode 3.0 odpovídá ISO 10646-1:1993, Unicode 4.0 odpovídá třetí verzi ISO 10646. Všechny verze Unicode od 2.0 výše jsou kompatibilní, jsou přidávány pouze nové znaky, existující znaky nejsou vyřazovány nebo přejmenovávány. Poslední verzí je prozatím Unicode 5.0.
Znak Unicode může být až 31 bitů dlouhý. Tento rozsah pokrývá všechny známé znakové sady jazyků na Zemi, včetně japonského nebo čínského písma. Používá se dále pro fonetické abecedy (pro zápis výslovnosti), speciální vědecké a matematické symboly, kombinované znaky a podobně. Každý znak má jednoznačný číselný kód a svůj název.
UTF-8 je zkratka pro UCS Transformation Format. Je to způsob kódování řetězců znaků Unicode/UCS do sekvencí bajtů. Varianta UTF-16 kóduje řetězce do posloupností 16bitových slov (2 bajty), varianta UTF-32 do 32 bitových slov (4 bajty). UTF-8 je definováno v ISO 10646-1:2000 Annex D, v RFC 3629 a v Unicode 4.0.
Některé starší aplikace (dosud) UTF-8 nepodporují. Na druhé straně pro některé systémy je UTF-8 již jedinou používanou znakovou sadou, např. jazyk Java nebo XML. Unicode pro vnitřní zápis znaků používá Microsoft Office od verze 97.
Přirozené kódování znaků Unicode/UCS do 2 nebo 4 bajtů se nazývá UCS-2 a UCS-4. Pokud se nespecifikuje jinak, ukládá se nejprve nejvýznamnější bajt (tzv. konvence Big-endian).
Stránka nabízejí kompletní specifikaci všech standardů Unicode, včetně připravovaného standardu Unicode 5.0. Domovská stránka je zpravována přímo organizací garantující tento standard a je tak vhodným zdrojem pro studium této tématiky.
[online] Wikipedia, the free encyclopedia ASCII
URL: http://en.wikipedia.org/wiki/Ascii,
Ucelené informace o ASCII kódování, včetně rozdělovníku na další témata související se standardizací znakových sad (Unicode, UTF-8 aj.). Na stránkách je možné naleznout kompletní ASCII tabulku, včetně ojasnění významovosti tzv. řídících znaků atd.
Stránka obsahuje dokument popisující ECMA standard definující řídící funkce a jejich kódovou reprezentaci (tzv. escape sekvence) pro užití v 7-bitovém kódu a rozšířeném 7,8-bitovém kódu.
1.1.5. Číselné soustavy Číselná soustava je v podstatě způsob kódové reprezentace čísel. Výpočetní stroje
mohou být zkonstruovány na základě libovolné číselné soustavy, nicméně všechny moderní počítače jsou založeny na soustavě binární, která pro nás v teorii kódování bude mít základní význam.
Zda kvantové, optické, chemické, biologické či mechanické počítače budoucnosti nastolí nový trend se „uvidí“.
Základ či báze (anglicky radix, česky budeme značit jako z) číselné soustavy definuje maximální počet číslic, které máme v dané soustavě k dispozici. Mezi nejčastěji používané číselné soustavy patří:
desítková dekadická z = 10, dvojková binární z = 2, šestnáctková hexadecimální z = 16.
Každé číslo vyjádřené v těchto soustavách může mít část celočíselnou a část desetinnou. Uvedené soustavy řadíme mezi polyadické, ve kterých se číslo vyjadřuje součtem mocnin základu dané soustavy vynásobených příslušnými platnými číslicemi.
Existují i soustavy nepolyedrické, které není možné výše uvedeným aditivním způsobem vyjádřit, jako příklad uveďme soustavu zbytkových tříd.
1.5 Vyjádření čísla 5 v soustavě (2,3,5) zbytkových tříd. Nepolyedrická soustava.
Obecné celé číslo je zde vyjádřeno jako celočíselný zbytek po dělení prvočíslem. Číslo 5 bude v soustavě (2,3,5) zobrazeno následovně:
2 2 2
3 3 3
5 5 5
5 2 2 15 1 3 25 1 5 0
a
a
a
N a z RN a z RN a z R
= + = ⋅ += + = ⋅ += + = ⋅ +
kde N je převáděné číslo, z jsou základy soustavy a R zbytky po dělení.
Čísla v soustavě (2,3,5):
N R2 R3 R5 N R2 R3 R5 N R2 R3 R5
0 0 0 0 11 1 2 1 22 0 1 2
1 1 1 1 12 0 0 2 23 1 2 3
2 0 2 2 13 1 1 3 24 0 0 4
3 1 0 3 14 0 2 4 25 1 1 0
4 0 1 4 15 1 0 0 26 0 2 1
5 1 2 0 16 0 1 1 27 1 0 2
6 0 0 1 17 1 2 2 28 0 1 3
7 1 1 2 18 0 0 3 29 1 2 4
8 0 2 3 19 1 1 4 30 0 0 0
9 1 0 4 20 0 2 0
10 0 1 0 21 1 0 1
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 9
Nejznámější polyedrickou soustavou je soustava desítková. Číslo se v ní vyjadřuje jako součet mocnin deseti (tj. základu z = 10) vynásobených jednoduchými součiniteli. Součinitelé mohou nabývat hodnoty z množiny {0,1,...,9}; prvky této množiny jsou označovány jako číslice. Číslo A lze zapsat jako:
Běžnější je zhuštěná forma zápisu: A= anan-1 ... ai ... a1a0.
Při zobecnění pro jiný základ z získáme např. pro:
z = 2 dvojkovou - binární soustavu a∈{0,1} z = 8 osmičkovou - oktanovou soustavu a∈{0,1,…,7} z = 16 šestnáctkovou - hexadecimální soustavu a∈{0,1,…9,A,B,…F}
1.6 Převody v běžných polyedrických soustavách
Číslo v soustavě o základu zk (kde z a k jsou přirozená čísla) lze převést do soustavy o základu z jednoduše tak, že každou k-tici číslic nižší soustavy nahradíme číslicí soustavy vyšší, např.: (0101 1010)2 = (5A)16
Poziční – každá číslice v daném čísle má jednoznačně určenu svoji váhu významnosti. Obecně platí, že kladné číslo může být zapsáno pozičně následovně:
1 2 1 0 1 2( , ... , ... )n n m zN a a a a a a a− − − −= , kde 1na − je nejvyšší významová číslice, ma− nejméně
významová číslice a z je základ číselné soustavy. 1.7 Vyjádření čísla π na 2 desetinná místa. 10(3,14)π = , tj. 0 1 2
10(3 10 1 10 4 10 )π − −= ⋅ + ⋅ + ⋅ .
Nepoziční – zde hodnota čísla není dána pouze umístěním číslice v dané sekvenci. Využívá se zde například sčítání číslic, případně jednoduchých pravidel dekódování jejich sekvencí.
1.8 Římské číslice a například vyjádření čísla 2007: (MMVII)Římská nepoziční soustava
10
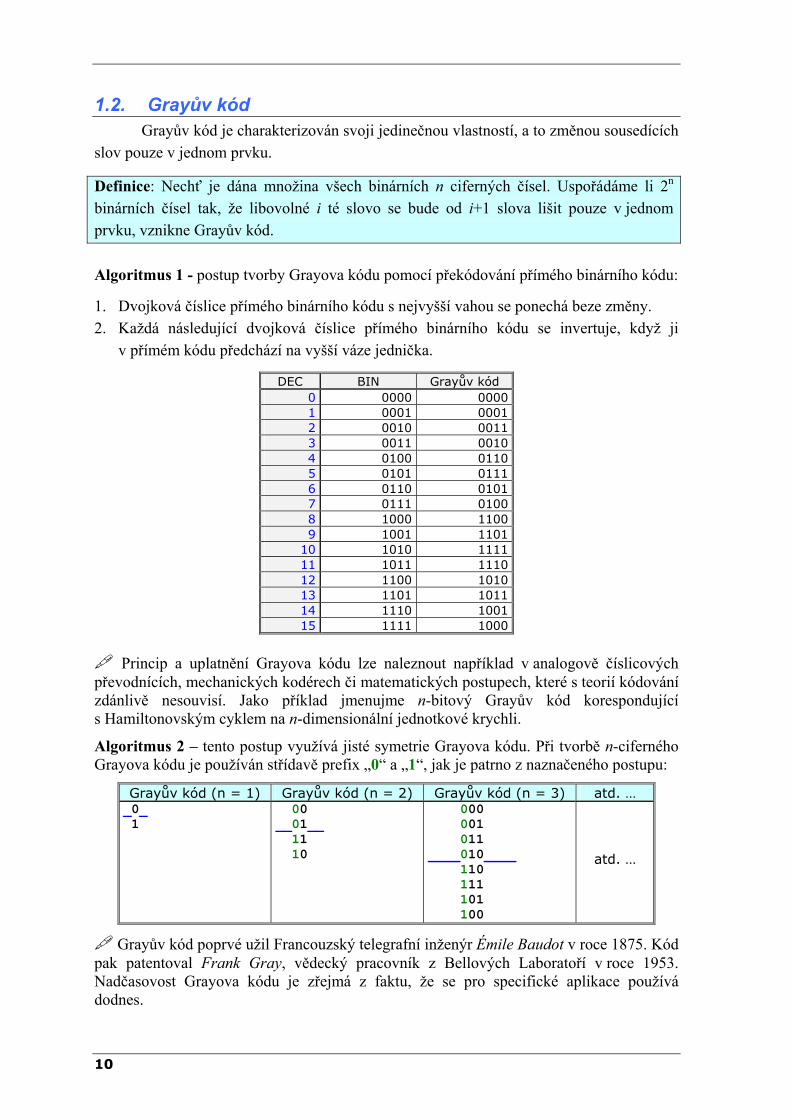
1.2. Grayův kód Grayův kód je charakterizován svoji jedinečnou vlastností, a to změnou sousedících
slov pouze v jednom prvku.
Definice: Nechť je dána množina všech binárních n ciferných čísel. Uspořádáme li 2n binárních čísel tak, že libovolné i té slovo se bude od i+1 slova lišit pouze v jednom prvku, vznikne Grayův kód.
Algoritmus 1 - postup tvorby Grayova kódu pomocí překódování přímého binárního kódu:
1. Dvojková číslice přímého binárního kódu s nejvyšší vahou se ponechá beze změny. 2. Každá následující dvojková číslice přímého binárního kódu se invertuje, když ji
Princip a uplatnění Grayova kódu lze naleznout například v analogově číslicových
převodnících, mechanických kodérech či matematických postupech, které s teorií kódování zdánlivě nesouvisí. Jako příklad jmenujme n-bitový Grayův kód korespondující s Hamiltonovským cyklem na n-dimensionální jednotkové krychli.
Algoritmus 2 – tento postup využívá jisté symetrie Grayova kódu. Při tvorbě n-ciferného Grayova kódu je používán střídavě prefix „0“ a „1“, jak je patrno z naznačeného postupu:
Grayův kód (n = 1) Grayův kód (n = 2) Grayův kód (n = 3) atd. … _0_ 1
00 __01__ 11 10
000 001 011 ____010____ 110 111 101 100
atd. …
Grayův kód poprvé užil Francouzský telegrafní inženýr Émile Baudot v roce 1875. Kód pak patentoval Frank Gray, vědecký pracovník z Bellových Laboratoří v roce 1953. Nadčasovost Grayova kódu je zřejmá z faktu, že se pro specifické aplikace používá dodnes.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 11
1.3. Základní pojmy KÓDOVÁNÍ je předpis, který každému prvku konečné množiny A přiřazuje právě jedno slovo v konečné množině B. Je to tedy zobrazení
*:K A B→ (1.1) KÓD je chápán jako množina všech kódových slov K(a) (kde a jsou zdrojové znaky), kterými vyjadřujeme jednotlivé stavy systému. Konečná množina všech slov B* může být vyjádřena ve formě tabulky, nebo pomocí dohodnutého systému pravidel, tedy algoritmem. Pojem slovo na množině B v tomto případě znamená konečnou (a neprázdnou) posloupnost prvků této množiny (k-prvkový vektor), tedy posloupnost b1b2…bk, kde bi∈B pro i = 1,2,…,k. Dále mluvíme o slově délky k. Slova délky 1 pak ztotožňujeme s prvky množiny B. Příkladem kódu, kde dochází k nahrazení znaků binárními slovy je následující tabulka:
1.9 Příklad použití tohoto kódu k zakódování numerické zprávy: 716 → 011100010110.
Poznámka 1.: Z hlediska praxe je pro nás nejdůležitější binární kódování, tj. takové, které má dva kódové znaky (0 a 1).
Poznámka 2.: Význam mají jen prostá kódování, tj. taková, kdy různým zdrojovým znakům odpovídají vždy různá kódová slova.
Poznámka 3.: Každé kódování zdrojových znaků (1.1) můžeme rozšířit na kódování zdrojových zpráv, tedy slov na abecedě A.
*
1 2 1 2( ) ( ) | ( ) | | ( )n nK a a a K a K a K a=… … . (1.2)
Tím vznikne zobrazení * * *:K A B→ , (1.3)
které každé zdrojové zprávě přiřadí její kódovou zprávu.
1.10 *(1986) (1) | (9) | (8) | (6) 0001100110000110K K K K K= =
Zdrojová abeceda a její prvky jsou zdrojové znaky.
Kódová abeceda a její prvky jsou kódové znaky.
12
Při přechodu z jednoho kódu do druhého se může měnit počet kódových znaků, jejich četnost a pravděpodobnost výskytu v kódovém slově, jak uvidíme v části pojednávající o prefixovém kódování, kap. 1.4.2. Při procesu kódování tak může docházet ke změně redundance. V případě minimální redundance, tj. max. entropie, tak kódování povede k tzv. minimálnímu kódu, kap. 2, použitelnému v kanálech bez rušení (v reálném kanálu, kde je možné zanedbat rušení). Jelikož reálné kanály jsou vždy s rušením, je naopak mnohdy žádoucí redundanci v kódu zvyšovat za účelem detekce, případně korekce chyb, což vede k tzv. bezpečnostnímu (protichybovém) kódování, kap. 3.
Definice: Řekneme, že kódování (1.1) je jednoznačně dekódovatelné, jestliže ze znalosti zakódované zprávy K*(a1 a2 … an) můžeme vždy jednoznačně určit zdrojovou zprávu a1a2…an; stručně, jestliže je kódování zpráv (1.3) prostým zobrazením.
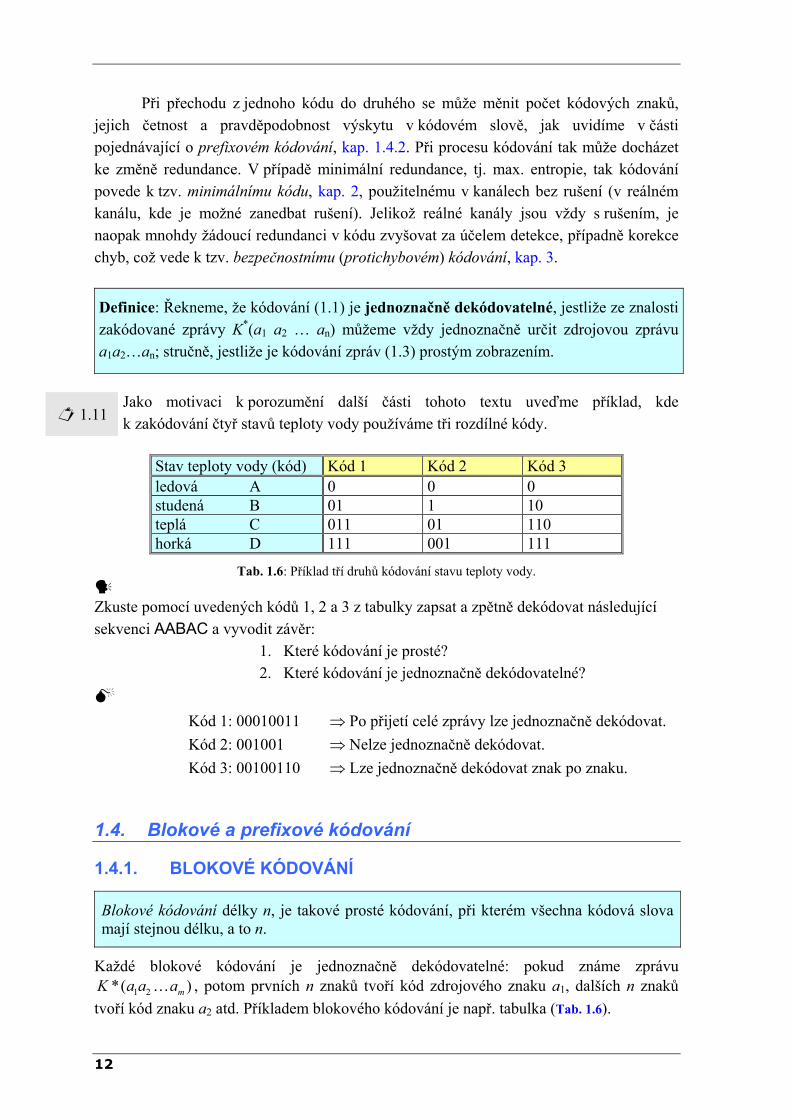
1.11 Jako motivaci k porozumění další části tohoto textu uveďme příklad, kde k zakódování čtyř stavů teploty vody používáme tři rozdílné kódy.
Stav teploty vody (kód) Kód 1 Kód 2 Kód 3 ledová A 0 0 0 studená B 01 1 10 teplá C 011 01 110 horká D 111 001 111
Tab. 1.6: Příklad tří druhů kódování stavu teploty vody.
Zkuste pomocí uvedených kódů 1, 2 a 3 z tabulky zapsat a zpětně dekódovat následující sekvenci AABAC a vyvodit závěr:
1. Které kódování je prosté? 2. Které kódování je jednoznačně dekódovatelné?
Kód 1: 00010011 ⇒ Po přijetí celé zprávy lze jednoznačně dekódovat.
Kód 2: 001001 ⇒ Nelze jednoznačně dekódovat. Kód 3: 00100110 ⇒ Lze jednoznačně dekódovat znak po znaku.
1.4. Blokové a prefixové kódování
1.4.1. BLOKOVÉ KÓDOVÁNÍ
Blokové kódování délky n, je takové prosté kódování, při kterém všechna kódová slova mají stejnou délku, a to n.
Každé blokové kódování je jednoznačně dekódovatelné: pokud známe zprávu 1 2*( )mK a a a… , potom prvních n znaků tvoří kód zdrojového znaku a1, dalších n znaků
tvoří kód znaku a2 atd. Příkladem blokového kódování je např. tabulka (Tab. 1.6).
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 13
1.4.2. PREFIXOVÉ KÓDOVÁNÍ Mějme binárně zakódovanou informaci o teplotě vody:
Stav teploty vody (kód) Kód 1 ledová A 0 Studená B 01 teplá C 011 horká D 111
Jaké si nyní můžeme položit otázky? Co z nich vyplývá?
1. Je zvolené kódování prosté? ⇒ ANO 2. Je zvolené kódování jednoznačně dekódovatelné? ⇒ ANO 3. Kdy jsme schopni zprávu dekódovat? ⇒ Po přijetí celé zprávy, a to odzadu. 4. Šlo by to i lépe (dekódovat znak po znaku)? ⇒ ANO! ⇒ Prefixové kódování.
PREFIX slova b1b2…bk je každé ze slov b1, b1b2…, b1b2… bk.
Definice (prefixový kód): Kódování se nazývá prefixové, jestliže je prosté a žádné kódové slovo není prefixem jiného kódového slova.
Poznámka 1.: Prefixové kódování je vždy jednoznačně dekódovatelné. Poznámka 2.: Každé blokové kódování je prefixové. Poznámka 3.: Prefixové kódy jsou jediné kódy, které lze dekódovat znak po znaku.
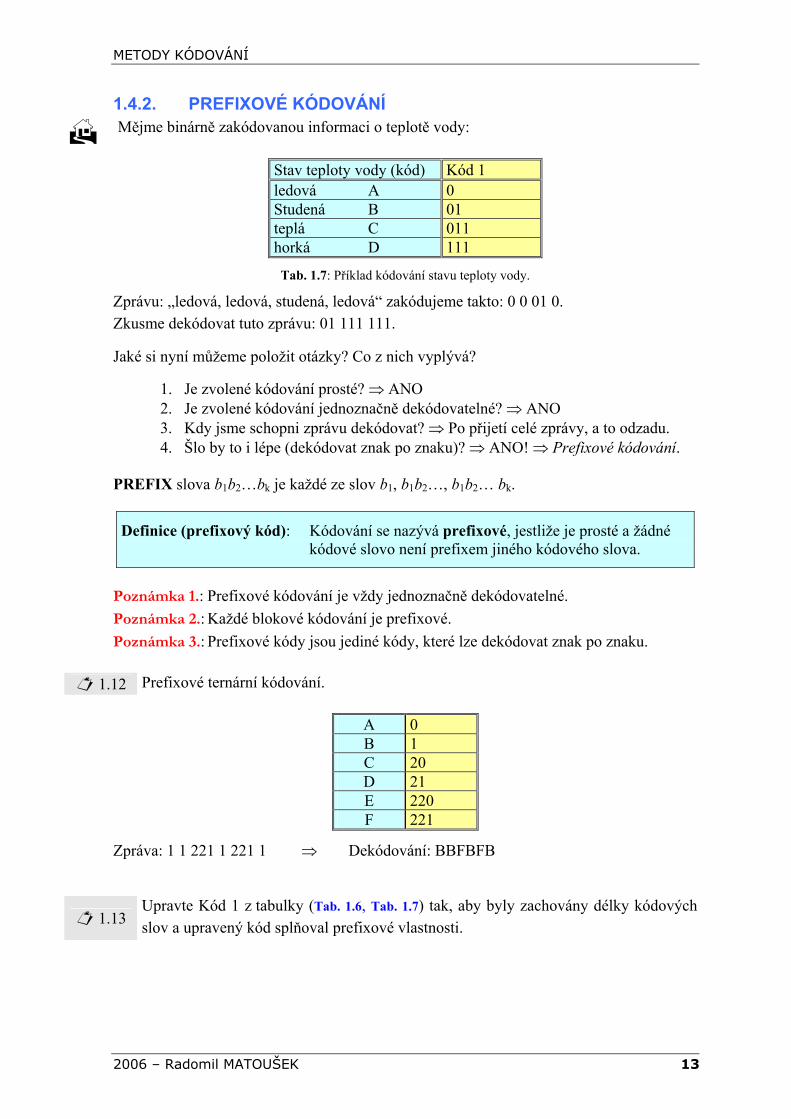
1.12 Prefixové ternární kódování.
A 0 B 1 C 20 D 21 E 220 F 221
Zpráva: 1 1 221 1 221 1 ⇒ Dekódování: BBFBFB
1.13 Upravte Kód 1 z tabulky (Tab. 1.6, Tab. 1.7) tak, aby byly zachovány délky kódových slov a upravený kód splňoval prefixové vlastnosti.
14
1.4.3. KONSTRUKCE PREFIXOVÉHO KÓDU Pro konstrukci prefixového kódu stačí znát požadované délky d1,d2,…dr kódových
slov pro jednotlivé zdrojové znaky a1,a2,…ar.
Poznámka: Mechanismus tvorby kódu je zřejmý z definice (prefixový kód). Jak ale volit délky kódových slov? Odpovědí je tzv. Kraftova nerovnost.
Odvození Kraftovy nerovnosti:
Dále budeme pro jednoduchost předpokládat, že zdrojové znaky jsou uspořádány tak, aby délky kódových slov tvořily neklesající posloupnost, d1≤d2≤…≤dr.
• Pro případ binárního kódu existuje 12d slov délky d1 a mezi nimi volíme slovo K(a1). • Při volbě slova K(a2) se musíme vyvarovat všem slovům délky d2 s prefixem K(a1);
jejich počet je 2 12d d− . • Protože platí 2 1 22 2d d d− < , můžeme volit K(a2) jako některé zbývající slovo délky d2. • Při volbě slova K(a3) (již vznikají jisté potíže) se musíme vyhnout všem slovům
s prefixem K(a1), jejichž počet je 3 12d d− , a všem slovům s prefixem K(a2), kterých je 3 22d d− .
• Potřebujeme, aby celkový počet 32d slov délky d3 byl alespoň o 1 větší než počet slov, kterým se vyhýbáme, tj. 3 1 3 2 3 32 2 1 2 / 2d d d d d d− − −+ + ≤ ⋅
31 22 2 2 1dd d −− −+ + ≤ • Podobně pro čtyři a více je nutné (i postačující), aby platilo:
1 22 2 2 1rd d d− − −+ + + ≤… (1.4)
Poznámka: Tato podmínka je nutná jak v případě prefixových kódů, tak i v případě jednoznačně dekódovatelných kódů, jak plyne z McMillanovy věty.
Věta (Kraftova nerovnost): Při kódování n znaky můžeme sestavit prefixový kód s délkami slov d1,d2,…dr, právě když platí tzv. Kraftova nerovnost.
1 2 1rd d dn n n− − −+ + + ≤… (1.5)
Poznámka 1.: Z existence prefixového kódu plyne Kraftova nerovnost (dále též KN). Poznámka 2.: Kraftova nerovnost nezaručuje, že daný kód je prefixový. Pouze zaručuje,
že prefixový kód s danými délkami kódových slov musí existovat.
1.14 Existuje binární prefixové kódování číslic desítkové soustavy, které používá jen slov déky max. 5 a číslice 0 má kód 0?
1.15 Kolik znaků má mít kódová abeceda k zakódování 25 znaků do blokového kódu, n=2.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 15
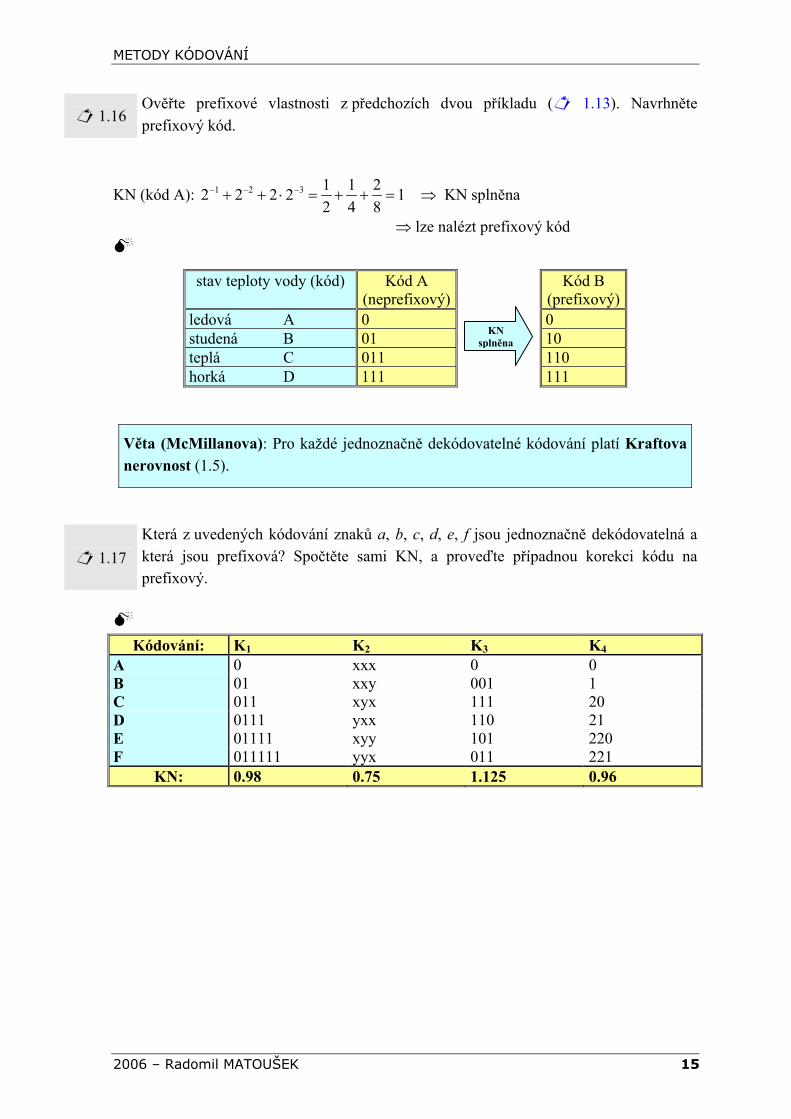
1.16 Ověřte prefixové vlastnosti z předchozích dvou příkladu ( 1.13). Navrhněte prefixový kód.
KN (kód A): 1 2 3 1 1 22 2 2 2 1 KN splněna2 4 8
− − −+ + ⋅ = + + = ⇒
⇒ lze nalézt prefixový kód
stav teploty vody (kód) Kód A (neprefixový)
Kód B (prefixový)
ledová A 0 0 studená B 01 10 teplá C 011 110 horká D 111
111
Věta (McMillanova): Pro každé jednoznačně dekódovatelné kódování platí Kraftova nerovnost (1.5).
1.17 Která z uvedených kódování znaků a, b, c, d, e, f jsou jednoznačně dekódovatelná a která jsou prefixová? Spočtěte sami KN, a proveďte případnou korekci kódu na prefixový.
Kódování: K1 K2 K3 K4
A 0 xxx 0 0 B 01 xxy 001 1 C 011 xyx 111 20 D 0111 yxx 110 21 E 01111 xyy 101 220 F 011111 yyx 011 221
KN: 0.98 0.75 1.125 0.96
KN splněna
16
Jaká je výhoda prefixového kódu? Znáte jeho definici?
Musí být blokový kód také prefixový?
Odvoďte Kraftovu nerovnost.
Existuje binární prefixové kódování číslic 0,1,…,9, které používá jen slov délky nejvýše 5 a číslice 9 má kód 0?
Najděte ternální prefixový kód znak; A,B,C,D,E,F s předepsanými délkami kódových slov 2,2,1,1,2,2.
Co říká věta McMillanova? Platí i opak?
Jaký je princip čárového kódu?
Je --/---/.-./…/./..-/…-//-.-/---/-..//-…/../-./.-/.-./-./../?
Jaký je rozdíl mezi polyedrickou a nepolyedrickou číselnou soustavou?
Profesor David A. Huffman stál při zrodu fakulty informatiky na kalifornské univerzitě a získal mnoho ocenění (kromě jiného medaili R. W. Hamminga ). David Huffman svůj „skromný“ nápad nikdy nepatentoval a ani nechtěl:).
Jak to však všechno začalo? Byla to výzva, jakých se denně na univerzitách a vysokých školách po celém světě urodí desítky. Profesor umožnil svým studentům vyhnout se zkoušce, když vyřeší jistý problém. Jednalo se o problém dosažitelnosti nejkratšího prefixového kódování (ve vztahu k informační entropii). Studenti ovšem nevěděli, že se jedná o nevyřešenou úlohu.
Davidu Huffmanovi na univerzitě v Ohiu se ke zkoušce nechtělo, jenže úloha se zdála téměř neřešitelná. Když už chtěl nechat bádání a začít se na závěrečnou zkoušku učit, zadíval se na papír s poznámkami, které zlostně vyhodil do koše. V tu chvíli ho to napadlo…
D. A. Huffman později publikoval svůj nápad v práci nazvané Metoda pro vytvoření kódu s minimální redundancí (A Method for the Construction of Minimum Redundancy Codes). Jeho řešení pomocí binárního stromu bylo velmi prosté a zároveň elegantní. Ale také velmi účinné v praxi. V tu dobu již působil na MIT (Massachusetts Institute of Technology), kde také získal rok nato doktorát.
Minimální kódování je způsob kódování, jehož účelem je zmenšit objem dat ve
zprávě. Tento proces kódování se běžně označuje jako datová komprese, či komprimace dat. Inverzní proces je pak označován jako expanze. Dle práce s informací je možné datovou kompresi dělit na bezeztrátovou a ztrátovou.
V současnosti se pro přenos dat používají převážně metody digitální komunikace. Digitální data se na rozdíl od analogových jednodušeji uchovávají, lépe zabezpečují proti chybám i proti případnému zneužití. Přenos a práce s informacemi jako je zvuk, obraz a video v digitálním tvaru má za následek velké paměťové nároky a užití velkých šířek přenosového pásma. Tyto skutečnosti by měly za následek zvyšování nákladů na uchování a přenos informace v této podobě. Cíl je tedy jasný, adekvátně zachovat původní informaci a s použitím minimálního kódování snížit ekonomické či energetické náklady.
Pokud má být použití komprimace efektivní, musí umožňovat reprodukci
komprimované informace v požadované kvalitě. Požadovaná kvalita může být v rozpětí od požadavku úplné rekonstrukce původní informace (například komprimace textu), až po omezení přenášeného frekvenčního pásma (zvuková informace), počtu zobrazovaných barev (obrazová informace, video) nebo počtu rozlišitelných zobrazovacích prvků informace (obraz, video, dynamika zvukového signálu).
18
Cílem datové komprese je tedy převést data z původní reprezentace, dále též označované jako původní soubor, či vstupní proud do nové úspornější formy, dále též označované jako zkomprimovaný soubor, či výstupní proud a zároveň umožnit kdykoliv opět získat originál nebo jeho aproximaci.
Účelem minimálního kódování je vždy snížit redundanci původních dat.
Na vyjádření efektivnosti metod komprimace můžeme zavést tzv. kompresní poměr nebo jeho převrácenou hodnotu tzv. faktor komprimace:
Poznámka: Pro posouzení „kvality“ kompresních metod, je velmi vhodné vědět, jaký je jejich kompresní poměr při kompresi obvyklé třídy komprimovaných dat. Pro tyto účely byly sestaveny kolekce souborů, které se standardně využívají při testování „úspěšnosti“ navržených komprimačních algoritmů.
K hlavním testovacím korpusům patří tzv.: • A.C.T. (Archive Comparison Test) – soubor benchmarků k otestování bezeztrátových
kompresních algoritmů, http://compression.ca/act/. Odkaz obsahuje tabulku s porovnáním hlavních komprimačních programů.
• The Canterbury Corpus – často užívaný soubor benchmarků k testování bezeztrátových kompresních algoritmů, http://corpus.canterbury.ac.nz/.
Metody komprese lze dělit podle mnoha kritérií. Jedním z možných je rozhodování na základě použitých technik komprese, nebo na základě kvality reprodukce původních dat:
Bezeztrátová komprese dat: Užité algoritmy nám zaručují 100% rekonstrukci původních nezkomprimovaných dat. Z pochopitelných důvodů mají tyto metody horší kompresní poměr. Hlavní oblastí aplikace je komprese obrazu a komprese textu (textová komprese) na která bude v tomto textu stručně uvedena.
Příklady postupů: • Morseův princip • Huffmanovy kódy • Fannova-Shannova konstrukce • Metoda potlačení nul • Metody proudového kódování RLE • Slovníkové metody LZx • BWT transformace s následným entropickým kódováním
Ztrátová komprimace: Užité kompresní algoritmy vypouští některé méně významné informace. Po dekompresi tak získáváme jen aproximaci originálu (přípustné pro multimediálními data, ne pro text nebo například astronomické fotografie – „hvězda sem hvězda tam“). Počítačové komprimační programy, které užívají ke zmenšení objemu dat metod ztrátové komprese, jsou v některých případech též kombinovány s algoritmy bezeztrátovými. Účelnější členění těchto typů komprese pro práci s multimediálními daty je tedy následující:
Stránka nabízí patrně nejlepší rozdělovník s odkazy na téma datové komprese. Stručně uveďme, že je možné přejít na stránky věnující se přímo komprimačním algoritmům (bezeztrátovým i ztrátovým), metodám kódování, problematice kódování obrazu, specifickým normám H.261, H.263, MPEG-4 aj., moderním metodám komprese založených na využití wavelet transformace či fraktálního kódování.
Když v únoru roku 1837 vypsal Kongres Spojených Států soutěž na zlepšení tehdejší informační soustavy, nikdo netušil, že dojde k převratnému vývoji zadané technologie. Než uvedeme podstatu jeho objevu, řekněme si nejdříve méně významnou „kuriozitu“: autorem objevu byl malíř, amatérský fyzik, kterému zrovna přálo štěstí v podobě vypsání zmíněné soutěže, a to zrovna v době, kdy prováděl pokusy s novou konstrukcí telegrafu. Ke zkonstruování telegrafu použil mimo jiné nástěnné hodiny a malířský stojan, co také shánět jiného? Další originalita je v principu telegrafu. Soutěž byla vypsána na zdokonalení optického telegrafu již známé podstaty. Pan Samuel Inlay Breese Morse se však pustil do elektromagnetického telegrafu. Slovo „kuriosita“ bylo použito z toho důvodu, že návrat k optickým přenosovým technologiím, byť v radikálně jiné podobě, je současným trendem.
Již v září 1837, byl předveden veřejnosti nový Morseův telegrafní přístroj využívající nový způsob kódování znaků. A tak amatérský fyzik a malíř Samuel F. B. Morse patentoval svůj vynález a získal tím i vypsanou cenu Kongresu. Jeho způsob kódování využíval sériový přenos dat, což jak se ukázalo, bylo v oné době, kdy funkci kodéru a dekodéru zastával člověk, zjevně to nejlepší. Ještě za života (27.4.1791-2.4.1872) se pan Samuel F. B. Morse dočkal několika realizací svého vynálezu. Ta první byla v květnu roku 1844 na trase, jejíž délka byla 60 km, a to mezi městy Washington a Baltimore.
Morseův kód je technicky realizován tak, že jsou k písmenovým symbolům
(zdrojová abeceda) přiřazeny elektrické impulsy dvou délek. Delší impuls, dosahoval trojnásobnou délku impulsu kratšího. Toto doporučení se vztahovalo k potřebám telegrafie v návaznosti na fyziologické adaptační schopnosti lidského sluchu i zraku. Rozdílnost těchto elektrických impulsů se po převodu na signál akustický nebo vizuální presentovala v podobě teček a čárek. Morseův kód však není binární, jak by se mohlo zdát. Jedná se o ternární kód, kdy oním třetím znakem je mezera. Tento prvek ve vysílání jakoby „neslyšíme“, ale je nezastupitelně používán k správnému dekódování prvků abecedy. Obecně v tomto kódu nebyla stanovena maximální délka slova nebo dokonce počet jednotlivých prvků v kódovém slově. Skladba všech tří prvků v kódovém slově byla závislá na frekvenci výskytu písmenových symbolů v anglickém (americkém) komunikačním prostředí.
Morseův princip spočívá v tom, že písmenům s velkou pravděpodobností výskytu jsou přiřazeny kódová slova s kratšími časovými intervaly a naopak.
Morseův kód se tedy skládá z časově odlišných kódových složek (nerovnoměrný kód). Časové intervaly pro jednotlivé složky jsou realizovány jako celistvé násobky; u Morseova kódu se používá časové relace: T ... tečka i vnitřní mezisložková mezera, 3T ... čárka. Pro kód je vyjadřovaná pouze relativní časová jednotka trvání kódových složek. Rychlost je, podobně jako při psaní na klávesnici, limitována fyziologickými a nervo-svalovými schopnostmi daného člověka.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 21
2.2. Nejkratší kód - Huffmanova konstrukce
Předpokládáme, že jsme zjistili přesnou frekvenci znaků zdrojové abecedy a1a2…ar. To znamená, že pro každý znak ai známe pravděpodobnost pi toho, že na náhodně zvoleném místě zdrojové zprávy je zapsáno ai. Platí Σpi=1 a 0≤ pi≤1. Označme délky kódových slov pro dané kódování d1, d2,… ,dr a odpovídající pravděpodobnosti výskytu těchto slov p1, p2,… ,pr. Našim cílem je najít nejkratší kód, přesněji prefixový kód, jehož průměrná délka slova d je nejmenší možná.
1 1 1 1 r rd d p d p d p= + +… (2.2)
2.1 Které z uvedených kódování znaků a, b, c, d, e, f je jednoznačně dekódovatelné a které je prefixová? Spočtěte sami KN, a proveďte případnou korekci kódu na prefixový.
znak * + a B pravděpodobnost 0,4 0,2 0,2 0,2 Kód na abecedě {0,1} 0 10 110 111 Kód na abecedě {0,1,2} 0 1 20 21
Definice (nejkratší kód): Nejkratším n znakovým kódováním zdrojové abecedy a1, a2, …, ar s pravděpodobnostmi výskytu p1, p2, …,pr se rozumí prefixové kódování této abecedy pomocí n znaků, které má nejmenší možnou průměrnou délku slova d .
D.A.Huffman (čti: Hafmen) objevil v roce 1952 algoritmus, který při zadané pravděpodobnosti výskytu zdrojových symbolů pi vytvoří kód minimální délky d .
Hoffmanův algoritmus kódováni je jedním z klasických algoritmů užívaných pro bezeztrátovou kompresi dat (bezeztrátové komprese PKZIP, BZIP2, PBZIP2 aj., v jistém kroku jinak ztrátové komprese JPEG, MP3). Prakticky existují dva typy Huffmanova kódování, a to kódování statické a kódování adaptivní (dynamické). V dalším textu se budeme věnovat jeho statické variantě. Stěžejní myšlenka, v podobě algoritmu, se nejdříve objevila v Fanon-Shannonově kódu. Základní myšlenkou je zakódování znaků podle počtu jejich výskytů ve vstupu tak, že znaky, které se vyskytují nejčastěji, mají nejkratší kód. Huffmanova konstrukce byla později značně zefektivněna zavedením Burrows-
22
Wheelerova transformace (BWT) spolu s tzv. Move-To-Front (MTF) filtrem. Nutno podotknout, že ve variante (RLE + BWT + Huffman) a implementaci v Open Source programech BZIP2 (PBZIP2) algoritmus poráží, či je rovným soupeřem jiných, draze licencovaných kompresních algoritmů (aritmetická komprese, slovníkové metody aj.).
Úvodní poznámky: Huffmanův algoritmus generuje binární stromy, kde uzly cesty z počátečního do
koncového uzlu umožňují vytvořit kódová slova. Huffmanovy kódy jsou prefixové kódy minimální délky. Huffmanův algoritmus přiřazuje slova dle Morseova principu. Huffmanův algoritmus není a nebyl nikdy patentován.
Statická varianta: Statická metoda je dvoufázová, nejprve se provede výpočet četnosti, resp. pravděpodobnosti výskytu daného znaku ve vstupním proudu. Dále se dle algoritmu vypočte prefixový kód, tj. provede se zakódování znaků zdrojové abecedy pomocí prefixového kódu z kódové abecedy. Tento algoritmus používá tzv. binární stromy, kde hodnoty uzlů od kořene k listům stromu tvoří jednotlivá kódová slova. U tohoto algoritmu bude dále prezentována i varianta nad rozšířenou kódovou abecedou. Adaptivní varianta: Metoda vycházející z předchozí statické varianty. Zásadním rozdílem adaptivních kódů je pouze jeden průchod textem. Celý proces funguje tak, že algoritmus opět vytvoří binární strom, jehož listy jsou jednotlivé znaky. Poté začne kódovat, u každého znaku si však vede statistiku kolikrát se v textu vyskytl. Takto nám vzniká po každém zakódovaném znaku nová statistika a tedy i nový strom, který je přehodnocen po každém znaku. Implementace tohoto algoritmu je ovšem poněkud časově náročnější
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 23
2.2.1. HUFFMANNOVA KONSTRUKCE BINÁRNÍHO KÓDU (1952) • Zdrojové znaky uspořádáme podle pravděpodobností tak, aby platilo: p1≥p2≥…≥pr. • Pokud máme jen dva zdrojové znaky (r = 2), je nejkratší kód zřejmý:
znak a1 a2 kód K 0 1
• Pro případ tří znaků (r = 3) pracujeme s tzv. redukovanou abecedou a1 a a1,2, která má pravděpodobnost výskytu p1 a p2,3 = p2 + p3:
znak a1 a2,3 kód K 0 1
Kódové slovo „1“ rozdělíme na dvě slova „10“ a „11“ a dostaneme nejkratší kód původní abecedy:
znak a1 a2 a3 kód K 0 10 11
• Stejně postupujeme v případě libovolného počtu r zdrojových znaků. Definujeme redukovanou abecedu a1, a2, …, ar-2, ar-1,r s příslušnými pravděpodobnostmi výskytu znaků ai. Znovu uspořádáme znaky podle pravděpodobností a najdeme nejkratší kód K. Pak původní abeceda má nejkratší kód, vzniklý z redukované abecedy a rozdělení slova K(ar-1,r) na dvě:
znak a1 a2 … ar-2 ar-1 ar kód K K(a1) K(a2) … K(ar-2) K(ar-1) K(ar)
Tento princip redukce shrňme do následujících, zcela ekvivalentních algoritmů:
Algoritmus 1 (postup vhodný pro „ruční“ výpočet):
1. Zdrojové znaky uspořádáme tak, aby platilo: p1≥p2≥…≥pr (nerostoucí posloupnost). 2. Znaky a1, a2, …, ar napíšeme pod sebe a vedle nich jejich pravděpodobnosti. 3. Sečteme poslední dvě pravděpodobnosti a výsledek zařadíme do posloupnosti dle
2. 4. Sečteme poslední dvě dosud nesečtené pravděpodobnosti a výsledek opět zařadíme. 5. Krok 4. opakujeme až do součtu pravděpodobností = 1. 6. Poté přiřazujeme kódová slova od prvního znaku a1 směrem k dalším dle
prefixového principu. Nekódová slova využíváme jako použitelné prefixy mimo poslední součet.
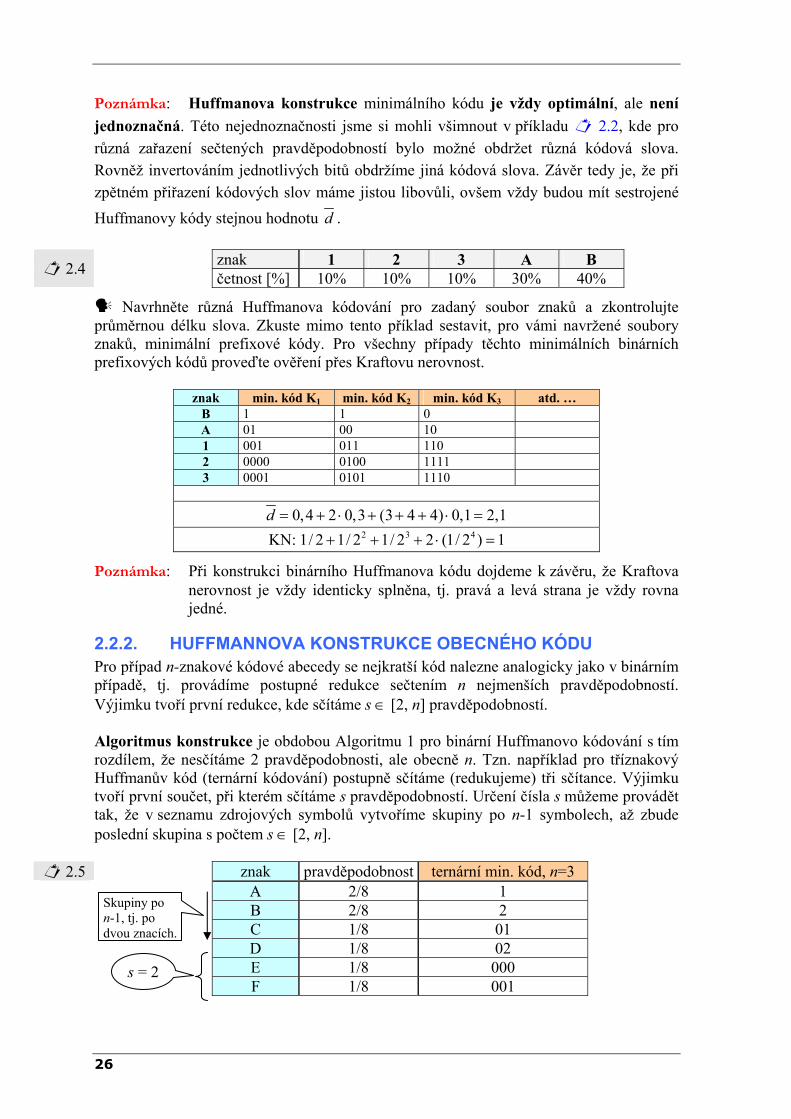
znak 1 2 3 A B 2.2 četnost [%] 10% 10% 10% 30% 40%
min. kód znak pravděpodobnost 1 ⇒ konec0 0,6 1 B 0,4
00 0,3 01 A 0,3
000 0,2 001 1 0,1
0000 2 0,1 0001 3 0,1
24
Algoritmus 2 (generovaný binární strom):
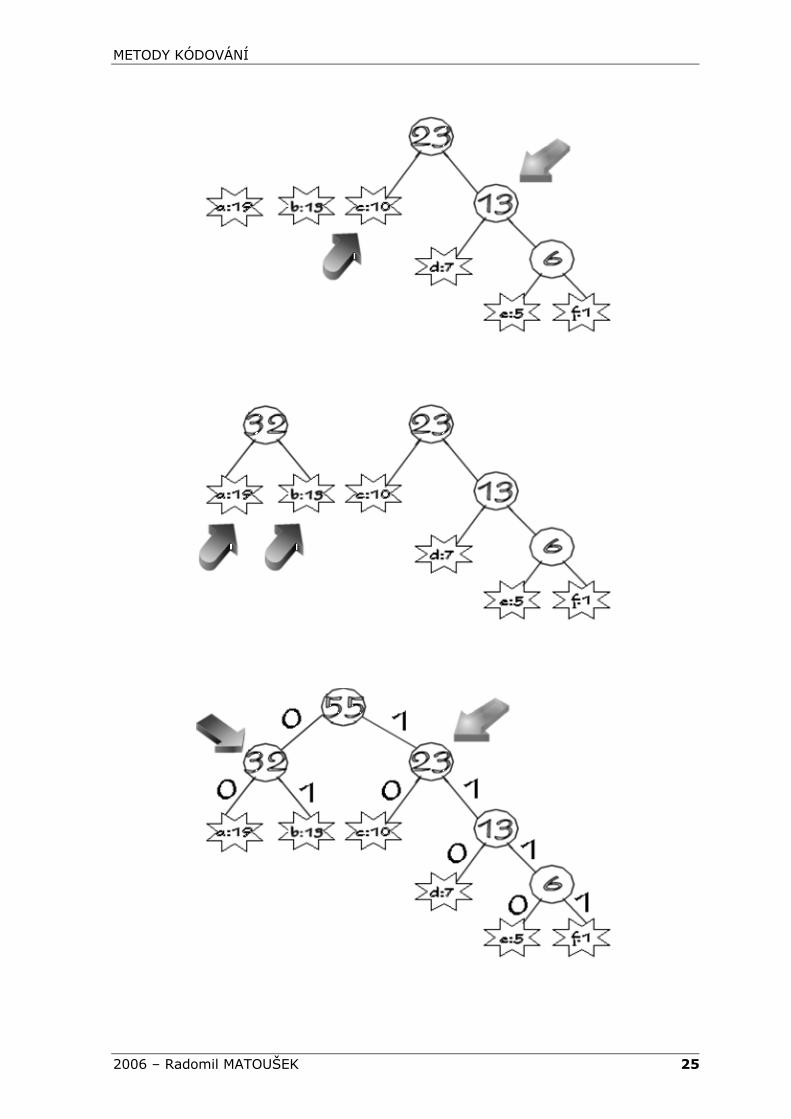
Jednotlivé znaky (u kterých známe jejich četnost) umístíme jako samostatné vrcholy, a z nich postupně budujeme binární prefixový strom. Množinu tvořenou vrcholy označíme například X. Vezmeme z X dva prvky (vrcholy = znaky) s nejmenším ohodnocením (kde ohodnocením rozumíme jejich četnosti) a spojíme je tak, že z nich uděláme bratry, přičemž jejich otec bude mít ohodnocení rovnající se součtu četností jeho synů. Právě užité prvky z množiny vyjmeme a namísto nich přidáme do X jejich otce. Tento postup rekurzivně opakujeme do té doby, než bude množina X jednoprvková. Tento jediný prvek je kořenem našeho Huffmanova stromu vyjadřující minimální prefixový kód.
znak a b c d e f 2.3 četnost [počet znaků] 19 13 10 7 5 1
Vybereme dva prvky s nejmenší četností a vytvoříme k nim vrchol reprezentující jejich otce, který má četností rovnající se součtu četností jeho synů.
Vybrali jsme tedy vrcholy „e“ a „f“. K nim vytvoříme jejich otce.
Nyní potřebujeme znovu vybrat vrcholy s nejmenšími četnostmi z množiny X (v ní již nejsou vrcholy „e“ a „f“). Vezmeme tedy nově vytvořený vrchol (tj. ten s ohodnocením 6) a vrchol „d“ (ohodnocení 7).
Další postup je analogický a jistě lze domyslet z následujících obrázků.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 25
26
Poznámka: Huffmanova konstrukce minimálního kódu je vždy optimální, ale není jednoznačná. Této nejednoznačnosti jsme si mohli všimnout v příkladu 2.2, kde pro různá zařazení sečtených pravděpodobností bylo možné obdržet různá kódová slova. Rovněž invertováním jednotlivých bitů obdržíme jiná kódová slova. Závěr tedy je, že při zpětném přiřazení kódových slov máme jistou libovůli, ovšem vždy budou mít sestrojené Huffmanovy kódy stejnou hodnotu d .
znak 1 2 3 A B 2.4 četnost [%] 10% 10% 10% 30% 40%
Navrhněte různá Huffmanova kódování pro zadaný soubor znaků a zkontrolujte průměrnou délku slova. Zkuste mimo tento příklad sestavit, pro vámi navržené soubory znaků, minimální prefixové kódy. Pro všechny případy těchto minimálních binárních prefixových kódů proveďte ověření přes Kraftovu nerovnost.
znak min. kód K1 min. kód K2 min. kód K3 atd. … B 1 1 0 A 01 00 10 1 001 011 110 2 0000 0100 1111 3 0001 0101 1110
Poznámka: Při konstrukci binárního Huffmanova kódu dojdeme k závěru, že Kraftova nerovnost je vždy identicky splněna, tj. pravá a levá strana je vždy rovna jedné.
2.2.2. HUFFMANNOVA KONSTRUKCE OBECNÉHO KÓDU Pro případ n-znakové kódové abecedy se nejkratší kód nalezne analogicky jako v binárním případě, tj. provádíme postupné redukce sečtením n nejmenších pravděpodobností. Výjimku tvoří první redukce, kde sčítáme s ∈ [2, n] pravděpodobností. Algoritmus konstrukce je obdobou Algoritmu 1 pro binární Huffmanovo kódování s tím rozdílem, že nesčítáme 2 pravděpodobnosti, ale obecně n. Tzn. například pro tříznakový Huffmanův kód (ternární kódování) postupně sčítáme (redukujeme) tři sčítance. Výjimku tvoří první součet, při kterém sčítáme s pravděpodobností. Určení čísla s můžeme provádět tak, že v seznamu zdrojových symbolů vytvoříme skupiny po n-1 symbolech, až zbude poslední skupina s počtem s ∈ [2, n].
2.5 znak pravděpodobnost ternární min. kód, n=3 A 2/8 1 B 2/8 2 C 1/8 01 D 1/8 02 E 1/8 000 F 1/8 001
s = 2
Skupiny po n-1, tj. po dvou znacích.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 27
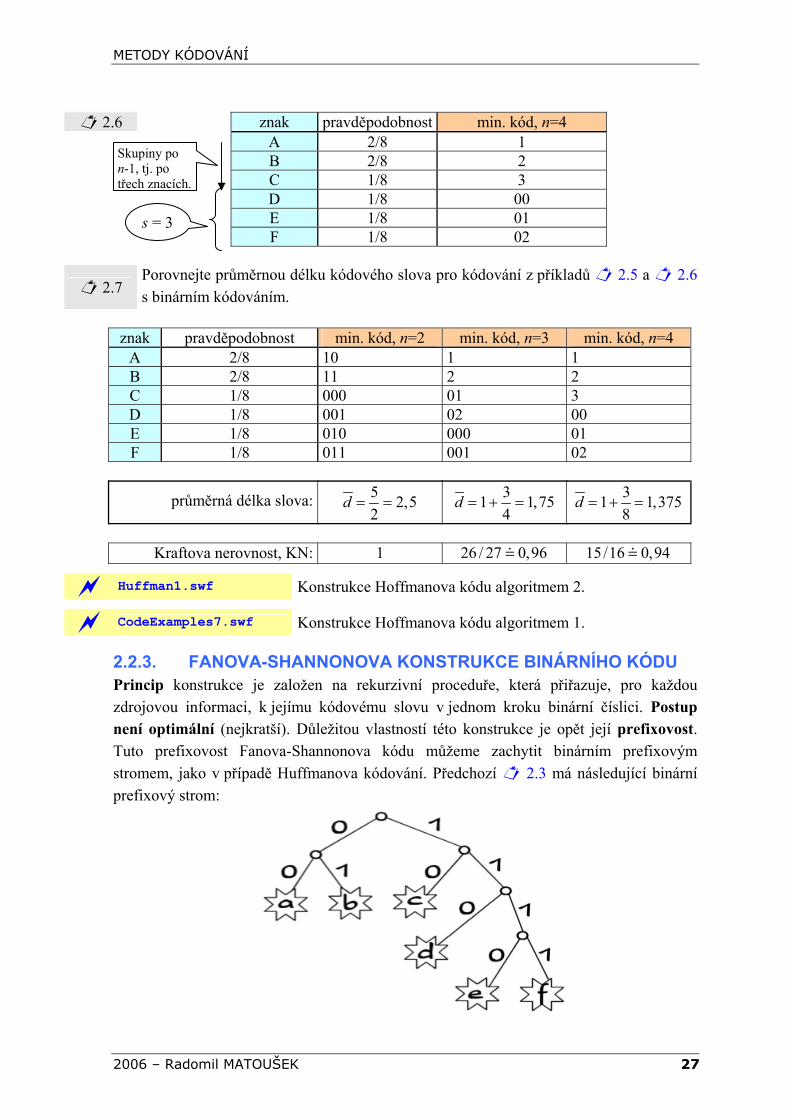
2.6 znak pravděpodobnost min. kód, n=4
A 2/8 1 B 2/8 2 C 1/8 3 D 1/8 00 E 1/8 01 F 1/8 02
2.7 Porovnejte průměrnou délku kódového slova pro kódování z příkladů 2.5 a 2.6 s binárním kódováním.
znak pravděpodobnost min. kód, n=2 min. kód, n=3 min. kód, n=4
A 2/8 10 1 1 B 2/8 11 2 2 C 1/8 000 01 3 D 1/8 001 02 00 E 1/8 010 000 01 F 1/8 011 001 02
průměrná délka slova: 5 2,52
d = = 31 1,754
d = + = 31 1,3758
d = + =
Kraftova nerovnost, KN: 1 26 / 27 0,96 15/16 0,94
Huffman1.swf Konstrukce Hoffmanova kódu algoritmem 2.
CodeExamples7.swf Konstrukce Hoffmanova kódu algoritmem 1.
2.2.3. FANOVA-SHANNONOVA KONSTRUKCE BINÁRNÍHO KÓDU Princip konstrukce je založen na rekurzivní proceduře, která přiřazuje, pro každou zdrojovou informaci, k jejímu kódovému slovu v jednom kroku binární číslici. Postup není optimální (nejkratší). Důležitou vlastností této konstrukce je opět její prefixovost. Tuto prefixovost Fanova-Shannonova kódu můžeme zachytit binárním prefixovým stromem, jako v případě Huffmanova kódování. Předchozí 2.3 má následující binární prefixový strom:
s = 3
Skupiny po n-1, tj. po třech znacích.
28
Každý Fanon-Shannonův kód lze samozřejmě zapsat takovýmto binárním stromem, kde písmena vstupní abecedy jsou v listech a jejich kódy tvoří cesta od kořene do daného vrcholu.
Poznámka 1: Pokud by kód nebyl prefixový, pak by na cestě do nějakého listu muselo ležet nějaké písmeno vstupní abecedy. Poznámka 2: Fanův-Shannonův binární prefixový strom nemusí být z hlediska minimálního kódování, na rozdíl od Huffmanova, vždy optimální, jak již bylo uvedeno.
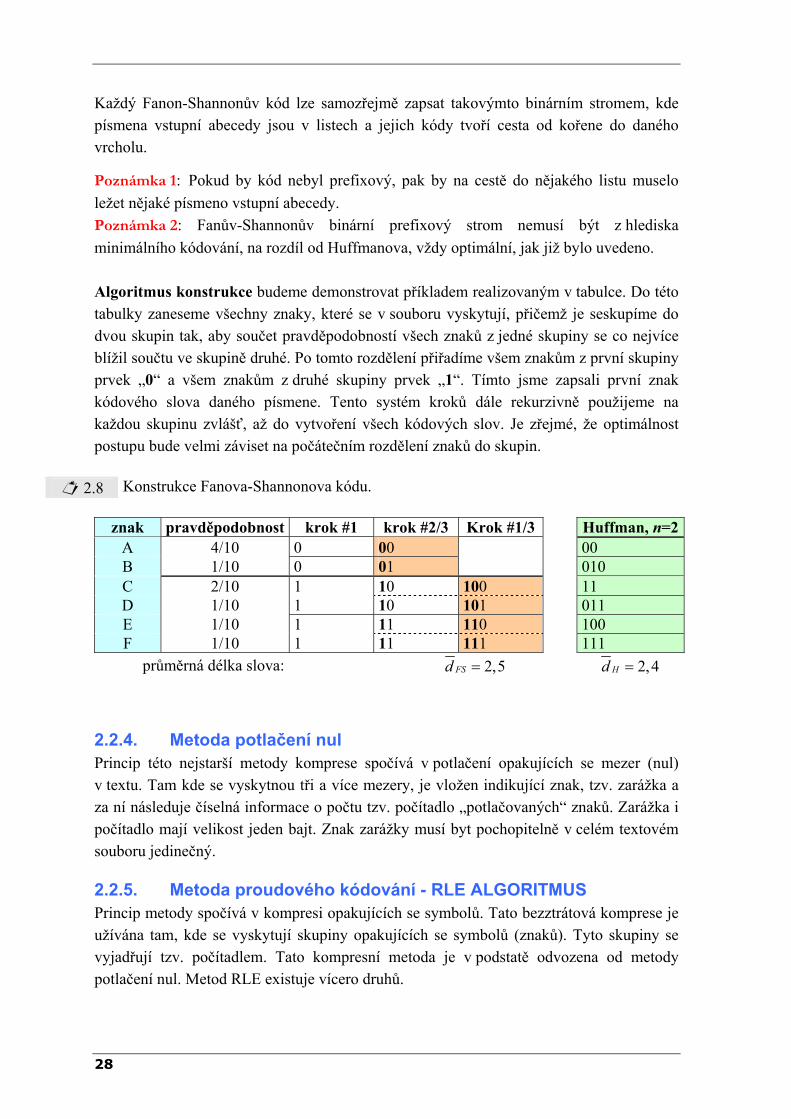
Algoritmus konstrukce budeme demonstrovat příkladem realizovaným v tabulce. Do této tabulky zaneseme všechny znaky, které se v souboru vyskytují, přičemž je seskupíme do dvou skupin tak, aby součet pravděpodobností všech znaků z jedné skupiny se co nejvíce blížil součtu ve skupině druhé. Po tomto rozdělení přiřadíme všem znakům z první skupiny prvek „0“ a všem znakům z druhé skupiny prvek „1“. Tímto jsme zapsali první znak kódového slova daného písmene. Tento systém kroků dále rekurzivně použijeme na každou skupinu zvlášť, až do vytvoření všech kódových slov. Je zřejmé, že optimálnost postupu bude velmi záviset na počátečním rozdělení znaků do skupin.
2.8 Konstrukce Fanova-Shannonova kódu.
znak pravděpodobnost krok #1 krok #2/3 Krok #1/3 Huffman, n=2A 4/10 0 00 00 B 1/10 0 01 010 C 2/10 1 10 100 11 D 1/10 1 10 101 011 E 1/10 1 11 110 100 F 1/10 1 11 111 111
průměrná délka slova: 2,5FSd = 2,4Hd =
2.2.4. Metoda potlačení nul Princip této nejstarší metody komprese spočívá v potlačení opakujících se mezer (nul) v textu. Tam kde se vyskytnou tři a více mezery, je vložen indikující znak, tzv. zarážka a za ní následuje číselná informace o počtu tzv. počítadlo „potlačovaných“ znaků. Zarážka i počítadlo mají velikost jeden bajt. Znak zarážky musí byt pochopitelně v celém textovém souboru jedinečný.
2.2.5. Metoda proudového kódování - RLE ALGORITMUS Princip metody spočívá v kompresi opakujících se symbolů. Tato bezztrátová komprese je užívána tam, kde se vyskytují skupiny opakujících se symbolů (znaků). Tyto skupiny se vyjadřují tzv. počítadlem. Tato kompresní metoda je v podstatě odvozena od metody potlačení nul. Metod RLE existuje vícero druhů.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 29
Počítadlo: zvláštní symbol tzv. indikátor (zarážka) – počítadlo – znak. Užití: například PCX, nebo preprocessing pro další typ komprese (Huffman)
RLE (Run Length Encoding) někdy též RLC (Run Length Compression) tedy definuje speciální znak, pomocí kterého je identifikována komprimovaná sekvence. Po indikátoru komprimace obvykle následuje znak, který je komprimován a poté následuje údaj o počtu opakování tohoto znaku. Pokud použijeme standardní kódy ASCII nebo EBCDIC, je vhodné jako indikátor komprimace (zarážku) vybrat takový symbol, který se jinak ve vstupním proudu dat nevyskytuje. Princip je patrný z následujícího příkladu.
TOK DAT
Ic (indikátor) X (libovolný znak) pz (počítadlo)
2.9 RLE komprese.
Původní data Komprimovaná data
A bbbbbbb9.99 A Icb79.99 Name: …………… Name: Ic.15
Poznámka: Zarážka i počítadlo mohou být sloučeny do jednoho byte: 11pppppp.
CodeExamples7.swf Více variant komprese textu pomocí RLE.
RLE.swf Demonstrace užití RLE pro komprimaci obrazových dat.
2.2.6. Slovníkové metody – Lempel-Ziv kódování Tento algoritmus byl navržen v roce 1977 Abrahamem Lempelem a posléze vylepšen v
roce 1978 Jacobem Zivem. Dnes se proto můžeme setkat s tímto algoritmem jako LZ77 nebo LZ78. Vývoj však ještě pokračoval a v roce 1984 byl upraven pro potřeby hardwarových řadičů Terrym Welschem, tento má potom zkratku LZW. Algoritmus LZ77 funguje následovně. Algoritmus pracuje se dvěmi částmi textu zároveň. První je aktuální okno - to, které komprimujeme, a druhé tzv. sliding window - tedy posuvné okno. V posuvném okně se snažíme nalézt co nejdelší řetězec obsažený v aktuálním okně, na který posléze v aktuálním okně vytvoříme odkaz. Poznámka: Velikost posuvného okna musí být dostatečně velká, abychom mohli najít požadovaný řetězec a zároveň dostatečně malá, aby komprimace netrvala příliš dlouho. Velikost bufferu se obecně pohybuje v kilobajtech.
2.10 LZ77 komprese.
Vstupní proud: Leze leze po železe Výstupní proud: Leze l[2,3] po že[5,4]
30
Algoritmus LZ78 je do jisté míry podobný LZ77. Tento algoritmus nepoužívá sliding window, ale tvoří si vlastní slovník. Do tohoto zapisuje již nalezená spojení znaků. Při čtení souboru tedy přečte řetězec, pokud je obsažen ve slovníku, nahradí ho příslušným odkazem, v opačném případě ho připíše do slovníku. Algoritmus komprese začíná s prázdným slovníkem a řetězcem L obsahujícím první znak zdrojového souboru. Vždy po přečtení dalšího znaku c zjistí, jestli se řetězec L+c vyskytuje ve slovníku. Pokud ano, pouze prodlouží řetězec L o znak c, jinak zapíše např. 12-ti bitový odkaz do slovníku nebo (pokud řetězec L obsahuje jediný znak) pouze znak, ale opět 12-ti bitově. V tomto případě tedy čísla 0-255 jsou jednotlivé znaky a čísla 256-4095 indexy do slovníku. Pokud se slovník zaplní dříve než je přečten celý soubor, je celý slovník smazán a začíná se plnit znovu. Někdy se pro zlepšení účinnosti místo smazání slovníku používá algoritmus LRU (last-recently-used) pro odstranění nepoužívaných řetězců ze slovníku. Vzhledem k tomu, že slovník se plní od nejnižších pozic, je pro zlepšení kompresního poměru výhodné začít kódy ukládat pouze 9-ti bitově a teprve kdy se slovník více zaplní, postupně je rozšiřovat až na např. na 12 bitů.
2.11 Sestavte fragment pseudo-programu pro kompresi LZW dle výše uvedeného postupu. L = readChar while (!eof(input)) { c = readChar if (Lc ve slovníku) L = Lc else { zapsat kód pro řetězec L přidat Lc do slovníku L = c } }
2.12 Zkomprimujte pomocí LZ78 vstupní proud: WEB-WEB-WEB! Řetězec L Přečtený znak Výstup Nová položka ve slovníku W W E W (256) = WE E B E (257) = EB B - B (258) = B- - W - (259) = -W W E Řetězec WE již je ve slovníku WE B (256) (260) = WEB B - B- W (258) (261) = B-W W E WE B WEB ! (260) (262) = WEB! ! (eof) ! Dekompresní algoritmus postupně čte kódy, zapisuje jim příslušející řetězce a přidává nové řetězce do slovníku. Do slovníku je vždy přidán řetězec reprezentovaný předcházejícím kódem a první znak z řetězce s aktuálním kódem. V případě, že byl přečten kód, kterému ještě nebyl přiřazen řetězec (to se stane např. pokud původní text obsahoval několik stejných znaků za sebou), je do slovníku přidán řetězec skládající se z
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 31
předcházejícího řetězce a jeho posledního znaku. V průběhu dekomprese má dekompresor stejný slovník jako kompresor. read last write last while (!eof(input)) { read code write řetězec table[code] (nebo znak code) přidání řetězce table[last]+prvni znak table[code] do slovníku last = code } Tabulku řetězců lze přímo indexovat přečteným kódem (pokud je větší než 0xFF, jinak jde o jediný znak a ten stačí zapsat na výstup). Stačí, když tabulka bude obsahovat kód prefixu a nově přidaný znak. Postupným procházením tabulky podle kódu prefixu tak dostaneme odzadu celý řetězec reprezentovaný přečteným kódem. Problém nastane, pokud byl přečten kód řetězce, který ještě není v tabulce. To se opravdu stát může: při kompresi zjistíme, že řetězec (cL)c jetě není ve slovníku, proto ho přidáme a jako začátek nového řetězce vezmeme c, pokud na vstupu následuje Lcx, zapíšeme kód pro cLc a přidáme (cLc)x do slovníku. Při dekompresi přečteme kód pro cLc (který ještě není v tabulce) a ... Teď již je vidět, že stačí, kdy do tabulky přidáme frázi skládající se z předcházejícího řetězce (last) a jeho prvního znaku, celou tuto frázi zapíšeme na výstup a jako nový řetězec last vezmeme jeho první znak.
LZx.swf Slovníkový algoritmus LZ77.
2.13 Projděte si známé datové formáty GIF, TIF. PNG, PDF a zjistěte užité metody komprese.
2.2.7. Move-to-Front Filter (MTF) MTF transformuje znaky, které mají charakteristiku často se vyskytujících stejných znaků za sebou na nuly. To je pochopitelně vstup velice výhodný pro Huffmanovo kódování. MTF kódování: K zakódování budeme potřebovat jednu pomocnou strukturu a tou je zásobník naplněný tak, že na i-tém místě v zásobníku je znak s (ASCII) kódem i. Postup kódování je následující. Postupně bereme znaky ze vstupu a na výstup dáváme číslo pozice v zásobníku, kde se znak nachází a znak přesuneme na začátek zásobníku. Výhoda z toho plynoucí pro druh vstupu, který máme, je zřejmá. První znak posloupnosti stejných znaků ve vstupu je kódován číslem své pozice na zásobníku, poté se přesune na začátek zásobníku (jeho pozice je tudíž po tomto přesunu 0) a všechny další (stejné) znaky z posloupnosti se kódují jako 0.
2.14 Jak bude vypadat vstupní proud „ammtt aass“ po průchodem MTF filtrem (ASCII)?
97 109 0 116 0 35 3 0 116 0
MTF.swf Move-To-Front filtr.
32
MTF dekódování: Zde není mnoho co říci, protože dekódování u MTF probíhá skoro stejně jako kódování. Vezmeme posloupnost čísel a budeme postupovat naprosto stejně jako u kódování s tím malým rozdílem, že na výstup nebudeme dávat čísla, nýbrž znaky jim odpovídající.
2.2.8. Burrows-Wheelerova transformace (BWT) BWT byla uvedena roku 1994 pány Davidem Burrowsem a Michaelem Wheelerem, ale
vymyšlena byla již v roce 1984 Wheelerem. Transformace představuje velice elegantní postup, který přeskupí znaky vstupního textu tak, že shodné znaky budou pravděpodobně vedle sebe. Tato pravděpodobnost vychází z vlastností jazyka. BWT je pouze transformace, která permutuje vstupní proud a přidává jedno pomocné číslo. Při užití v komprimačních programech pouze tzv. předzpracovává vstupní proud a je tedy nutné dále zařadit skutečnou komprimační metodu (v tomto ohledu je možné ještě využít transformaci MTF). Následovat mohou samostatně případně v kombinaci metody RLE, slovníkové, Hoffmanův algoritmus aj. Typickou kombinaci je právě BWT+Hoffmanův algoritmus, na který se nevztahuje žádný patent (to je také asi hlavní důvod, proč je použit v programu bzip2). BWT – algoritmus transformace (kódování) Vstupní text se zpracovává po blocích o konstantní velikosti. Čím jsou bloky větší, tím je kódování účinnější (ve výsledné permutaci budou pravděpodobně delší posloupnosti stejných znaků). Skutečné účinnosti BWT dosahuje pro bloky délky desítek tisíc znaků (někdy se díky zpracovávání po blocích tomuto algoritmu také říká Block Sorting algorithm).
Mějme tedy blok o délce N, vytvoříme si N cyklických posunů o jeden znak doleva Tímto vzniká pomyslná matice N*N, kde v řádcích jsou právě cyklické posuny původního bloku.
Dalším krokem je lexikografické setřídění řádků této matice (setřídění podle abecedy). Poslední sloupec matice je výsledná transformace! K této permutaci musíme ještě
přidat číslo řádku, na kterém se v seřazené matici nalézá původní vstupní proud.
Poznámka: Proč mají stejné znaky tendenci seskupovat se k sobě? Dobrým příkladem je anglický určitý člen "the". Toto slovo se v anglickém textu vyskytuje velice často. Jaká situace nastane v naší matici N*N? Bude-li se řetězec "the" v bloku vyskytovat 50 krát, pak v matici bude 50 krát v posledním sloupci znak "t" (díky rotacím). To ale znamená, že na prvních dvou místech se 50 krát ocitnou znaky "he". Je tedy velice provděpodobné, že řádky začínající na "he" budou (po lexikografickém setřídění) blízko u sebe a velice pravděpodobně budou hned pod sebou. A to samé musí samozřejmě platit i pro poslední znaky těchto řádku (to je právě znak "t").
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 33
BWT – algoritmus zpětné transformace (dekódování) Vytvoříme tzv. transformační vektor , což je pole čísel z rozmezí 1-N (indexy řádků), kde na i-tém místě je index řádku, který vznikne rotací i-tého řádku (nebo tak spíše vznikne text v něm). Takový vektor nám úplně postačuje k rekonstrukci vstupu. Známe totiž řádek, kde se vyskytuje první písmeno (nechť je to řádek j) a tedy máme k dispozici první písmeno původního vstupu (první sloupec). A taky víme, kde se nachází druhé písmeno textu - je v prvním sloupci na řádku, kam ukazuje j-tá složka transformačního vektoru (po rotaci se druhé písmeno dostane na první místo)! Nyní tedy zbývá ukázat si, jak vektor sestrojit. Pro písmena, která se vyskytují ve vstupu pouze jednou to není těžké. Řekněme, že jsme na řádku i a v prvním sloupci je písmeno "x", když na tento řádek zrotujeme do leva, pak se písmeno "x" dostane na konec. Z toho vyplývá: vektor[i]="číslo řádku, kde je v posledním sloupci znak "x"". Ale co když nastane situace, že se znak "x" vyskytuje ve vstupu několikrát? Pak v posledním sloupci najdeme více znaků "x" a který je tedy ten náš zrotovaný? Vezměme první výskyt znaku "x" v prvním sloupci (první od shora), pak mu odpovídá (ukazuje tam transformační vektor) první výskyt "x" v posledním sloupci. Proč? Vyplývá to z toho, že řetězce jsou lexikograficky setříděny, vyskytuje-li se na prvním místě vícekrát znak "x", pak se tyto řetězce musí lišit na druhém místě (pro jednoduchost - jinak můžou být stejné i na druhém místě a lišit se až na některém dalším, ale princip je stejný). Po rotaci se tento druhý znak dostane na první místo a znak "x" na poslední. A právě ten druhý znak nyní rozhoduje o pořadí řádku, čili o pořadí znaku "x" v posledním sloupci. Tento princip platí stejně i pro i-tý výskyt znaku "x".
Obecně lze nalézt dva postupy zpětné rekonstrukce. Postup BWT je nejlépe patrný z následující interaktivní flash prezentace. Postup rekonstrukce označený jako BWT1 je původní variantou navrženou autory. Detailní popis je možné naleznout v základním dokumentu autorů, který je dostupný jako technical report SRC-RR-124 na linku společnosti HP http://www.hpl.hp.com/techreports/Compaq-DEC/SRC-RR-124.html.
CodeExamples7.swf Burrows-Whelerova transformace.
[online] non-commercial project by Graphic&Media Lab. Compression Links Info
Jak lze rozdělit kompresní metody z hlediska zachování informačního obsahu
komprimovaného souboru? Co je to kompresní poměr?
Jak zní Morseův princip?
Jaká je maximální velikost počítadla u metody potlačení nul?
Jaké varianty RLE komprese znáte? Kde se tato komprese používá?
Jak a pomocí čeho je definován nejkratší kód?
Demonstrujte Huffmanovu konstrukci binárního i obecně n-arního kódu. V tomto kontextu se vyjádřete ke Kraftově nerovnosti.
Popište Fanovu-Shannonovu konstrukci. Vede tato konstrukce k minimálnímu kódu a proč?
Jaké dva stěžejní kompresní algoritmy jsou využity u programu BZIP2 a proč jsou použity?
Jaký je základní princip slovníkových metod komprese?
Popište princip BW transformace a alespoň jeden způsob inverzní BW transformace. Uveďte použití.
Jsou MTF a BWT kompresní algoritmy?
Lze použít bezztrátové kompresní metody pro komprimaci multimediálních dat? Pokud ne tak proč? Pokud ano tak uveďte příklad.
Vysvětlete, proč u dalších redukcí není potřeba v Hoffmanově konstrukci zjišťovat počet sčítanců (začněte od ternálního kódu).
Kolik znaků musí mít kódová abeceda, jestliže chceme najít prefixový kód průměrné délky slova < 1,6 pro následující zdrojovou abecedu (dvojice znak/pravděpodobnost): A/0,22; B/0,15; C/0,12; D/0,1; E/0,1; F/0,08; G/0,06; H/0,05; I/0,05; J/0,04; K/0,03.
Pro předchozí případ Hoffmanovy konstrukce na binární abecedě realizujte Fanovu-Shannonovu konstrukci a srovnejte KN a průměrnou délku slova.
Na slově sasanka demonstrujte BWT transformaci.
kvizKomprese.swf Malý test vědomostí..
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 35
3. Bezpečnostní KÓDOVÁNÍ – detekční a korekční kódy Equation Section (Next)
Země se vzdaluje a kolem létají hvězdy, náhle začne někdo mluvit tajemným hlasem: „Asi jen málokdo ví, že ve vesmíru je ještě jedna úplně stejná sluneční soustava jako ta naše. A tedy i naše země má své zrcadlo. Na této zemi se dějí události ve stejnou dobu a čas jako u nás, ale s drobnými odchylkami, protože jejich systém má při přenosu informací chyby, které si označuje jako -X- a zapisuje do své databáze. Chyby jsou detekovány a podle možností opraveny. Systém tyto chyby kontroluje programem pomocí tzv. kontrolního metru.“ Ten program se jmenuje "METR X"
Bezpečnostní kódování (protichybové kódování, detekční a korekční kódování) je
užito pro přenos informace reálným přenosovým kanálem, tj. kanálem, kde může dojít k ovlivnění přenášené informace vlivem chyby (šum, ztráta informace). Smyslem bezpečnostního kódováni je detekovat, případně i přímo opravit vzniklou chybu. Možné chybě čelíme zavedením přídavné informace k přenášeným datům. V dalším budeme uvažovat pouze typ chyby, která vznikne změnou vyslaného znaku za jiný, tj. příjemce obdrží jiný znak, než odesilatel původně vyslal.
Bezpečnostní kódy uměle zvyšují redundanci, za účelem zabezpečení informace před možnými chybami.
Základní myšlenka použití bezpečnostních kódů je velmi jednoduchá - původní
znaky se podle přesně definovaných pravidel transformují na znaky jiného typu (např. osmibitové znaky se přidáním jednoho paritního bitu převedou na devítibitové). Teprve ty se pak skutečně přenesou a příjemce si je převede zpět do jejich původního tvaru.
Bezpečnostní kódy jsou v zásadě dvojího typu, a to:
detekční kódy - error-detection codes, které umožňují pouze rozpoznat (detekovat), že přijatý znak je chybný, a
korekční kódy, resp.: samoopravné kódy - self-correcting codes, které kromě detekce chyby umožňují i opravu chybně přeneseného znaku, takže jej není nutné přenášet znovu (což u detekčního kódu obecně nutné je).
Jak může kód objevovat či opravovat chyby? Tak, že k původní informaci přidává
další, která z hlediska zprávy sice nenese novou informaci, ovšem informačně postihuje strukturu původní nezabezpečené informace. Po takovémto zvýšení redundance je možné v případě chybného přenosu detekovat vzniklou chybu, případně jí i opravit. Typickým příkladem redundantního zdroje, který v tomto kontextu má charakter zabezpečení, je běžná řeč.
36
Příkladů, kdy je nutné, aby vysílající i přijímající strana „mluvili o stejné věci“, je celá
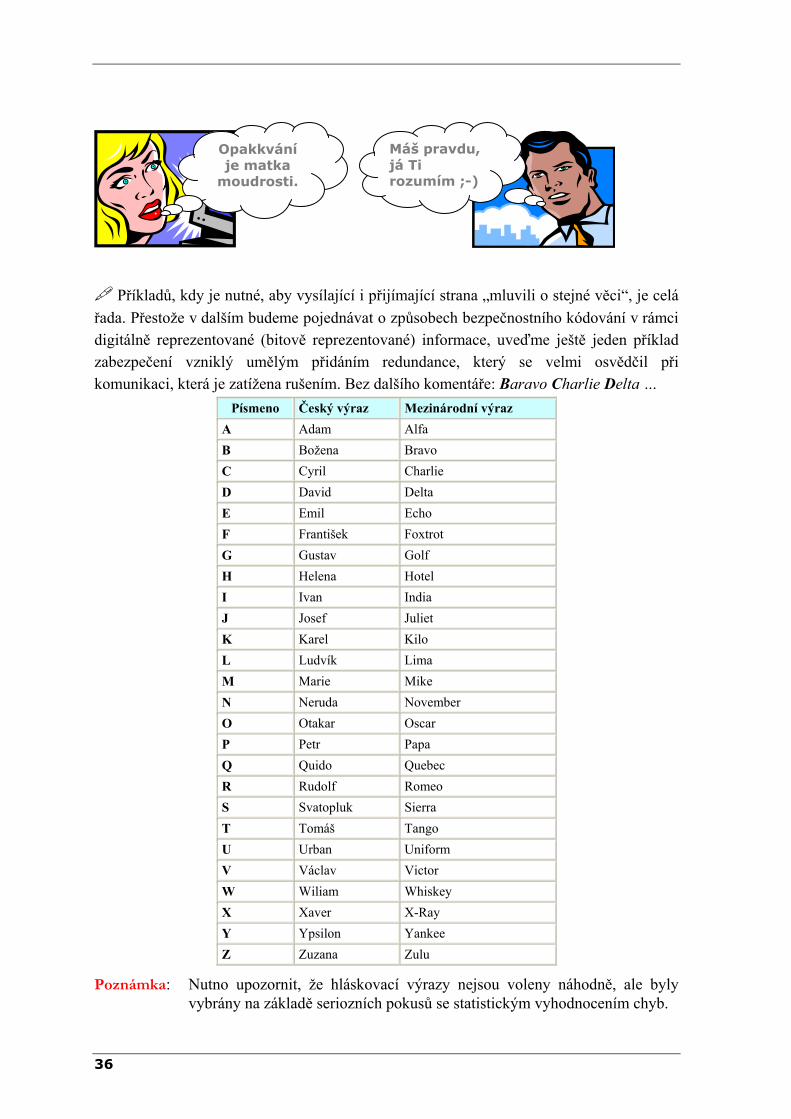
řada. Přestože v dalším budeme pojednávat o způsobech bezpečnostního kódování v rámci digitálně reprezentované (bitově reprezentované) informace, uveďme ještě jeden příklad zabezpečení vzniklý umělým přidáním redundance, který se velmi osvědčil při komunikaci, která je zatížena rušením. Bez dalšího komentáře: Baravo Charlie Delta …
Písmeno Český výraz Mezinárodní výraz A Adam Alfa B Božena Bravo C Cyril Charlie D David Delta E Emil Echo F František Foxtrot G Gustav Golf H Helena Hotel I Ivan India J Josef Juliet K Karel Kilo L Ludvík Lima M Marie Mike N Neruda November O Otakar Oscar P Petr Papa Q Quido Quebec R Rudolf Romeo S Svatopluk Sierra T Tomáš Tango U Urban Uniform V Václav Victor W Wiliam Whiskey X Xaver X-Ray Y Ypsilon Yankee Z Zuzana Zulu
Poznámka: Nutno upozornit, že hláskovací výrazy nejsou voleny náhodně, ale byly vybrány na základě seriozních pokusů se statistickým vyhodnocením chyb.
Opakkvání je matka
moudrosti.
Máš pravdu, já Ti rozumím ;-)
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 37
3.1. OBJEVOVÁNÍ CHYB
Dále budeme do „odvolání“ pracovat s blokovým kódem K na nějaké konečné abecedě T. Množina všech slov délky n je
{ }1 2... | , 1,2,...,n
n iT t t t t T i n= ∈ = . (3.1) Pokud délka všech slov v kódu K je rovna n, potom nK T⊆ a slova množiny Tn dělíme na kódová slova (v K) a nekódová slova (v Tn-K). V reálném kanále vysíláme kódová slova a přijímáme slova z množiny Tn. Pokud přijmeme nekódové slovo, říkáme, že jsme detekovali chybu. Pokud jsme přijali kódové slovo, pak je buď vše v pořádku, nebo jsme chybu nedetekovali. Mluvíme o t-násobné chybě (t = 1,2,3,…), jestliže počet chybných míst je nejvýše t. Tedy například ze slova 1111 může dvojnásobná chyba vytvořit slovo 0110 ale i 1110. Kód K objevuje t-násobné chyby, jestliže při vyslání kódového slova a vzniku t-násobné chyby je přijaté slovo vždy označeno jako nekódové. Neboli, pro každé slovo v1v2…vn kódu K a každé jiné slovo w1w2…wn takové, že pro nejvýše t indexů i platí vi ≠ wi, je w1w2…wn nekódové slovo.
3.1 Konstrukce kódu „dva z pěti“.
Kód „dva z pěti“. Jde o binární kód délky 5, tedy K⊆{0,1}5, který je tvořen množinou slov obsahujících právě dvě jedničky. D=2 ⇒ kód detekuje (objevuje) jednoduché chyby.
Poznámka 1: Srovnejte s kódem dle tabulky Tab. 1.2. Poznámka 2: Tyto kódy se označují jako tzv. izokódy. Typickou vlastností je konstantní
počet 1 a 0, což je vlastně vnitřní parita.
Kolik kódových slov bude mít kód 3 z 7? Vypište několik kódových slov tohoto kódu. Speciálním případem izokódů jsou tzv. ekvidistantní kódy. Základní odlišnost spočívá
v tom, že obsahují i nulovou složku a Hammingova vzdálenost (kap. 3.2.1) libovolných dvou kódových slov je konstantní. Navrhněte ekvidistantní kód 2 z 6.
38
3.2 Konstrukce opakovacího kódu.
Opakovací kód. Pro případ velkého šumu můžeme každý znak abecedy T n-krát opakovat. Například ternární opakovací kód délky 5 má kódová slova 00000, 11111, 22222. D=n ⇒ kód detekuje (n-1) násobné chyby a koriguje t násobné pro t<n/2.
3.3 Konstrukce opakovacího kódu.
Sudá parita; též kód celkové kontroly parity. Jedná se o nejznámější a hojně užívaný bezpečnostní kód. Kód náleží do skupiny detekčních kódů, tj. D=2 ⇒ kód detekuje (objevuje) jednoduché chyby. Princip spočívá v přidání jednoho, tzv. paritního bitu k původnímu nezabezpečenému slovu. Tento bit zajistí, že v zabezpečované sekvenci bude sudý počet jednotkových bitů, a tedy výsledek mod 2 bude 0.
Pro 4 prvkový blokový kód máme 3 prvky informační a jeden zabezpečující. 000 0000 100 1001 001 0011 101 1010 010 0101 110 1100 011 0110 111 1111
Tab. 3.2: Sudá parita.
3.2. Hammingova vzdálenost a geometrická interpretace
3.2.1. HAMMINGOVA VZDÁLENOST
Hammingova vzdálenost Hδ dvou slov v1v2…vn a w1w2…wn je definována jako počet odlišných znaků těchto slov, tj. velikost množiny {i|i=1,2,…,n, vi≠wi}.
VÁHA w kódové složky je dána počtem jedniček v kódové složce. Nejvyšší vahou je pak myšlen jedničkový bit umístěný nejvíce vlevo.
Minimální kódová vzdálenost (kódová vzdálenost) D, blokového kódu K, je spočtena jako minimální Hammingova vzdálenost mezi dvěma různými kódovými složkami.
Kódová vzdálenost je důležitou charakteristikou kódu z hlediska jeho zabezpečující schopnosti proti chybám. S rostoucím D se zvyšuje zabezpečovací schopnost kódu, bohužel roste též jeho redundance.
Obr. 3.1: Jednotková krychle a geometrická interpretace kódu.
Určete kódovou vzdálenost v tomto příkladu a odpovězte kolikanásobnou chybu je kód schopen odhalit. Je prezentovaný kód schopen korigovat chybu?
O jaký kód by se mohlo jednat? Ověřte kódovou vzdálenost v příkladu 3.1
Hammingovu vzdálenost dvou kódových složek můžeme geometricky interpretovat jako počet hran krychle kterými je třeba projít na cestě vedoucí od jedné složky ke druhé.
40
Poznámka 1: Hammingova vzdálenost je metrikou na množině Tn všech slov délky n.
H i ii
a bδ = −∑ . (3.2)
Poznámka 2: Blokový kód minimální kódové vzdálenosti D objevuje t-násobné chyby pro
všechna t < D, ale není schopen objevit všechny D-násobné chyby. To znamená, že pokud v kódovém slově změníme t znaků, potom:
a) nevznikne kódové slovo, jestliže t ≤ D-1, b) může vzniknout kódové slovo jestliže t = D.
3.3. Zabezpečující schopnost kódu Jak již bylo řečeno, vyslaná kódová složka Ai může být v důsledku rušivých vlivů E v přenosovém kanálu přijata jako složka Bj: Bj = Ai ⊕ E. Počet chybných prvků t v přijaté kódové složce je roven vzdálenosti mezi přijatou a vyslanou kódovou složkou.
( ) ( ) ( , )i j H i jt w E w A B A Bδ= = ⊕ = . (3.3)
3.6 A1 = 0101 se vlivem chyby změní na B1 = 0100, pak t = 1.
Chyba v t prvcích (t-násobná chyba) určité kódové složky mění její vzdálenost od všech složek kódu o t jednotek. K některým se o t jednotek přibližuje, od jiných se o t jednotek vzdaluje.
3.7 Vliv D na detekci, respektive korekci chyb.
Pro D = 1 a t = 1 Vznik nedetekovatelné chyby. D = 2 Lze detekovat všechny jednoduché chyby. D = 3 Lze detekovat všechny trojnásobné chyby a navíc korigovat jednonásobnou chybu.
3.3.1. DETEKČNÍ SCHOPNOST KÓDU Aby bylo možné detekovat chyby násobnosti td a menší, nesmí již uvnitř ani na
povrchu koule o poloměru dt ležet žádný jiný vrchol n-rozměrné jednotkové krychle,
odpovídající platné kódové složce. Cestu po hranách n-rozměrné jednotkové krychle, která je ve skutečnosti lomená, lze pro jednoduchost zobrazit jako přímku:
Obr. 3.2: Detekční schopnost kódu.
Kód který je schopný detekovat td chybných prvků musí mít kódovou vzdálenost D ≥ td+1.
Ai Aj
td
D ≥ td+1
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 41
3.3.2. KOREKČNÍ SCHOPNOST KÓDU Pravděpodobnost výskytu chyby klesá s rostoucí násobností chyby za předpokladu, že výskyty chyb v jednotlivých prvcích kódové složky jsou vzájemně nezávislé. Při příjmu nepoužité (chybné) kódové složky je možné proto předpokládat, že s největší pravděpodobností byla vyslána ta platná kódová složka, která má od přijaté nejmenší vzdálenost. Kód schopný korigovat (opravit) tc chybných prvků musí mít kódovou vzdálenost D ≥ 2tc + 1 pro lichá D a D ≥ 2tc + 2 po sudá D.
Detekční schopnost: D ≥ td+1 Korekční schopnost pro D lichá: D ≥ 2tc + 1 pro D sudá: D ≥ 2tc + 2
Tab. 3.3: Nerovnosti pro výpočet detekční a korekční schopnosti kódu.
uniKostka2.swf Praktická ukázka detekční a korekční schopnosti kódu.
3.8 Kód dvourozměrné kontroly parity (křížové parity), též iterační kód.
Jde o významný kód, který vznikl jako kombinace dvou kódů celkové kontroly parity. Informační znaky zapíšeme do matice (p,q). Kódová vzdálenost D = 2*2 = 4 ⇒ koriguje jednonásobnou chybu tc.
Obr. 3.3: Princip zabezpečení bloku dat pomocí křížové parity.
Poznámka: Jak uvidíme dále, kód celkové kontroly parity i kód křížové parity patří ke kódům lineárním. Lineární kódy jsou pro teorii zabezpečovacích kódů nejvýznamnější. Příkladem nelineárního kódu je pak například inverzní kód.
krizovaParita.swf Předvedení křížové parity pro zvolený blok binárních dat.
3.9 Inverzní kód
Vysílaná kódová složka se opakuje beze změny, je-li v informační části sudý počet nul. V případě lichého počtu nul v informační části se po informační části vyšle její inverze. Kódová vzdálenost tohoto kódu je D = 4. Může tedy korigovat jednonásobnou chybu. Princip je patrný z následující tabulky.
parita řádků
parita sloupců
křížová parita
42
znak Kódová složka G L X
vysláno: přijato:
překódováno:
01011 01011 00011 01011 00011 10100
01001 10110 01011 10110 01011 10110
10111 01000 10111 00000 10111 11111
proces korekce:
00011
⊕10100 10111
01011
⊕10110 11101
10111
⊕11111 01000
Tab. 3.4: Princip kódování a dekódování pomocí inverzního kódu.
CodeExamples7.swf Inverzní kód.
3.3.3. DEKÓDOVÁNÍ Dekódování je libovolné zobrazení : nT Kδ → (3.4) Poznámka 1: Dekódování není inverzní postup ke kódování informačních znaků. Poznámka 2: V případě bezpečnostních kódu mluvíme o dekódování odstraňující chyby,
tj. zobrazení (3.4).
3.3.4. INFORMAČNÍ ZNAKY U některých kódů můžeme rozdělit znaky na informační (lze libovolně zvolit) a kontrolní (jsou plně určeny volbou informačních znaků). Definice (kódování informačních znaků): Nechť nK T⊆ je blokový kód délky n. Jestliže existuje prosté zobrazení ϕ množiny všech
slov délky k na množinu všech kódových slov. : kT Kϕ → , řekneme, že kód K má
k informačních znaků a n-k kontrolních znaků. Zobrazení ϕ se nazývá kódování informačních znaků.
⇒ má polovinu informačních a polovinu kontrolních znaků Například pro n=6 … Kódování informačních znaků 3: T Kϕ → definujeme předpisem 1 2 3 1 1 2 2 3 3( )v v v v v v v v vϕ =
Místo chyby v informační části
Místo chyby v zabezpečovací části
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 43
Definice (systematičnost kódu): Blokový kód nK T⊆ se nazývá systematický, jestliže existuje číslo k<n takové, že pro každé slovo v1…vk v Tk existuje právě jedno kódové slovo v1…vkvk+1… vn. Kódování
: kT Kϕ → definované předpisem ϕ(v1…vk) = v1…vkvk+1… vn se nazývá systematické.
3.12 opakovací kód lineární, systematický k=1 sudá parita lineární, systematický k=n-1 koktavý kód lineární, není systematický
Poznámka 1: Minimální vzdálenost D systematického kódu nemůže překročit n-k
kontrolních znaků o více než jeden.
1D n k≤ − + (3.5)
Poznámka 2: Problémem je obvykly požadavek:
• přenést mnoho informace a • opravit velký počet chyb.
⇒ kompromis Poznámka 3: je důležitý i způsob jakým se opravy realizují ⇒ speciální třídy kódů INFORMAČNÍ POMĚR je poměr informačních znaků ke všem znakům.
kRn
= (3.6)
44
3.4. LINEÁRNÍ KÓDY
Základní myšlenkou teorie bezpečnostních kódů je zavedení algebraických operací sčítání a násobení na abecedě T, takže se T stane tělesem a Tn n-rozměrným lineárním prostorem. Blokový kód K délky n je lineární, jestliže tvoří lineární podprostor prostoru Tn.
Poznámka 1: Pro tyto kódy lze užít mocný algebraický aparát. Poznámka 3: Běžné kódy jsou lineární. Poznámka 3: V dalším výkladu se spíše omezíme na binární kódy, tj. {0,1}T = . Operace logického součtu a součinu jsou definovány následovně a tvoří na množině {0,1} těleso:
⊕ 0 1 ⊗ 0 1
0 0 1 0 0 0 1 1 0 1 0 1
Tab. 3.5: Příklad tří druhů kódování stavu teploty vody.
3.13 Vyjádření binárních kódů rovnicemi.
• Sudá parita 1 2 ... 0nv v v+ + + = (3.7)
• Opakovací kód 1 2 1 3 10, 0, 0nv v v v v v+ = + = + =…
• Koktavý kód 1 2 3 4 10, 0, 0n nv v v v v v−+ = + = + =…
Poznámka 4: Z lineární algebry víme, že všechna řešení homogenní soustavy lineárních rovnic o n neznámých tvoří lineární prostor, tedy podprostor prostoru Tn. To znamená, že řešením je i:
1. součet dvou řešení 1 1 2 2( , , , )n nv w v w v w+ = + + +v w …
2. skalární násobek 1 2( , , , )nt tv tv tv=v …
Definice (lineární kód): Binární kód K se nazývá lineární, jestliže je podprostorem lineárního prostoru {0,1}n, tj. jestliže součet dvou kódových slov je kódové slovo. Je-li K podprostorem dimenze k, mluvíme o lineárním (n,k)-kódu. Poznámka 5: Dimenze k je ovšem počet prvků libovolné báze. Například celý prostor {0,1}n má dimenzi n, protože má bázi:
1
2
100 0010 0
000 1n
==
=
ee
e
……
…
.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 45
Poznámka 6: Kód celkové kontroly parity je (n,n-1)-kód, jeho báze je například:
1
2
1
100 01010 01
000 11n+
==
=
bb
b
……
…
• Každé slovo bi má dvě jedničky a je tedy dle (3.7) kódovým slovem. • Slova jsou lineárně nezávislá (po oddělení poslední jedničky tvoří bázi prostoru {0,1}n-1) • Každé slovo v1v2…vn sudé parity je součtem těchto slov. Poznámka 7: Každý lineární (n, k)-kód má k informačních a n-k kontrolních znaků. KONTROLNÍ MATICE KÓDU: Je-li binární kód popsán soustavou homogenních lineárních rovnic, potom matice H této soustavy se nazývá kontrolní maticí kódu.
Slovo je označeno jako kódové, pokud je splněna následující podmínka:
T T=Hv 0 1 2, nK v v v∈ =v v … (3.8)
Řadu binárních kódů lze považovat za lineární podprostory prostoru {0,1}n. Tyto kódy můžeme stručně popsat jejich bází tj. generující maticí G, nebo jejich kontrolní maticí H. Poznámka 8: Dimenze kódu je rovna počtu informačních znaků.
3.4.1. Stručná teorie lineárních binárních blokových kódů Lineární kódy zaujímají v teorii kódování velmi významné místo. Výklad jejich teorie vyžaduje znalosti algebry těles a lineárních prostorů. K této podkapitole uveďme, že není pro studium dalších částí textu nevyhnutelná a je pouze rozšiřující! Přesto, je hloubavému čtenáři doporučena, včetně prostudování dalších uvedených zdrojů literatury. Poznámka 1: Pro připomenutí uveďme že těleso je zhruba řečeno algebraická struktura se sčítáním a násobením, splňující všechny vlastnosti „prototypu“ těles – množiny reálných čísel. Tento „prototyp“ je dán velkým počtem axiomů, tak velkým, abychom mohli v každém tělese počítat a nemuseli přemýšlet nad tím, jaké úpravy ještě lze provést. Mnohem horší je ověřování, že určitá algebraická struktura všechny tyto axiomy splňuje. Poznámka 2 (Konečné těleso): V teorii kódování hrají roli jen konečná tělesa, u nichž není třeba axiomy ověřovat – stačí znát jednoduchý popis všech těles. Konečné těleso je v podstatě určeno počtem svých prvků, což je mocnina prvočísla. Počet těchto prvků je řád tělesa. Tyto tělesa se označují jako Galoisova tělesa a značí se GF(q), v našem případě prezentovaných binárních kódu se bude jednat o GF(2)
46
Další stručný výklad této podkapitoly budeme dělat tak, aby bylo zřejmé, že předpoklad binárnosti kódu není vždy podstatný a některé úvahy mohou být rozšířeny na libovolné jiné abecedě { }0,..., 1Y p= − (pro odlišení použito značení Y místo jinak pro abecedu
uváděného T). Základem je, že binární abecedu { }0,1Y = můžeme chápat jako těleso se
sčítáním „+“ podle modulu 2 a obyčejným násobením „.“ Tak jak je patrné z tabulky Tab.
3.5. nY je potom lineární prostor nad tělesem Y. Lineárním kódem K délky n nazveme každý lineární podprostor prostoru nY . Lineární podprostor K má jistou dimezi k a právě tolik bázových vektorů (v našem případě jsou tyto vektory kódovými slovy). Tyto vektory můžeme napsat jako řádky nějaké matice G typu nk × . Všechny vektory prostoru K (tj. všechna kódovaná slova) je možno obdržet jako lineární kombinace řádků matice G. Jeden z možných zápisů lineárního kódu K je tedy způsob pomocí matice G, kterou nazveme vytvářející, či generující maticí kódu. Zkoumejme nyní vektory prostoru nY kolmé na K. Tyto tvoří nulový prostor k podprostoru K, dimenze kn − s vytvářející maticí H s rozměrem ( ) nkn ×− . Protože pro
všechny v K∈ platí H 0Tv = (nulový vektor), můžeme matici H (resp. TH ) nazvat kontrolní maticí kódu K. Kontrola, zda slovo v patří do K anebo ne, se provede pomocí již vzpomínaného součinu vektoru v s transponovanou maticí TH matice H. Pokud je výsledkem součinu nulový vektor, tak v K∈ , když je nenulový, tak v K∉ . Následující jednoduchá věta je jednou ze základů algebraické teorie kódů detekujících a opravujících chybu.
Věta: Nechť K je kód a H je vytvářející matice nulového prostoru ke K. Potom když v K∈ a ( ),0v mρ = (0 je nulový vektor), tak existuje m lineárně závislých sloupců
matice H. Naopak, když v H existuje m závislých sloupců, tak existuje v K∈ , pro které ( )0 ,0v mρ< ≤ .
Důkaz: Sloupce matice H jsou řádky matice TH , pro které platí 0Tv =H . Protože
( ),0v mρ = , obsahuje v právě m nenulových složek; nechť jsou to 1i -ta, …, mi -ta. Ty jsou
potom nenulovými koeficienty lineární kombinace 1i -tého, …, mi -tého sloupce, které se
rovnají nulovému vektoru, a tedy 1i -tý, …, mi -tý sloupce jsou lineárně závislé. Naopak,
když 1i -tý, …, mi -tý sloupce jsou lineárně závislé, musí existovat koeficienty 1i
v ,…,mi
v
lineární kombinace těchto sloupců, která se rovná nenulovému vektoru, přičemž alespoň jeden z koeficientů je rozdílný od nuly. Když potom vezmeme
1iv , …,
miv za složky vektoru
v a ostatní složky zvolíme nulové, platí pro vektor v, že 0Tv =H , takže v K∈ a navíc ( )0 ,0v mρ< ≤ .
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 47
Poznámka 1: Když ( )K mρ = , tak v H existuje m lineárně závislých sloupců, ale všechny
( )1−m -tice sloupců jsou nezávislé.
Poznámka 2: Je též zřejmé, že záměnou pořadí složek kódových slov kódu K, tedy záměnou pořadí sloupců ve vytvářející matici G, se nezmění ( )Kρ , a teda ani schopnost
kódu K detekovat a opravovat chyby. Pro dimenzi k kódu K můžeme tedy předpokládat, že právě prvních k sloupců matice G je lineárně nezávislých. Potom vhodným lineárním kombinováním řádků matice G (které můžeme při lineárním kódu K provést) dostaneme bázi a k ní odpovídající matici G ve tvaru
12 1
21 2
1
1 0 0G 0 1 0
0 0 1k
n k
n k
k kn k
E B
b bb bb b
−
−
−
⎛ ⎞⎜ ⎟⎜ ⎟
= ⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠
… …… …… …
. (3.9)
Tedy ( )kG = E ,B , kde kE je jednotková matice s k řádky. Libovolné kódové slovo
je lineární kombinací s koeficienty 1a , …, ka bázových vektorů (řádku matice G), a proto
musí mít tvar
⎟⎠
⎞⎜⎝
⎛ ∑ ∑ ∑ −i i i
kiniiiiik papapaaaa ,...,,,...,, 2121 . (3.10)
Stačí, když se budeme věnovat jen těmto kódům, tj. kódům, u kterých slova mají prvních k míst informačních a zbývajících kn − kontrolních (tj. jsou jen lineární kombinací prvních k míst). Takový kód pak nazveme systematickým kódem. Když máme systematický kód K s vytvářející maticí ( )k ,=G E B , potom
vytvářející matice H nulového prostoru ke kódu K má tvar ( )Tn k, −= −H B E protože
potom skutečně platí
( )Tk
n k
0,...,00,...,0−
−⎛ ⎞ ⎛ ⎞⋅ = =⎜ ⎟ ⎜ ⎟
⎝ ⎠⎝ ⎠
BG H E B
E. (3.11)
Tedy H je vytvářející matice nulového prostoru právě ke kódu K a ne k žádnému „většímu“ podprostoru.
3.14 Mějme 2≥n je libovolné, 1−= nk .
n 1
1( , )
1−=G E , a tedy
T n k
11...1, 1−−
⎛ ⎞= ⎜ ⎟⎝ ⎠EB
H
Jde o kód s kontrolou parity, protože pro libovolné slovo ( )1... na a K∈ platí
11 −++= nn aaa ... , a tedy ( ) ( )111 2 −++=++ nn aaaa ...... . Při binárním kódování tento kód
vždy odhalí jednu chybu, při jiném jen když chyba naruší paritu.
48
3.15 Mějme dánu matici G, resp. H. Jaká slova jsou kódová?
= = (v každém nenulovém slově jsou alespoň tři jednotky).
Kód K opravuje jednu chybu – například když ve slově 6 1 1 0 0 0 0 1k = dojde
k chybě na druhém místě a přijmeme 1 0 0 0 0 0 1v = , jediné slovo v K, které se od v liší jen na jednom místě je právě k6. Pomocí kontrolní matice H identifikujeme chybu takto: mělo by platit 0Tv =H (skutečně platí 6 0Tk =H ), ale po výpočtu jsme obdrželi
(1,1,0)Tv =H , nesouhlasí tedy první a druhá kontrola. Přitom první kontrolní číslice je součet 1., 2. a 3. číslice, druhá 1., 2. a 4. a třetí 1., 3. a 4. číslice. V prvních dvou kontrolách je a ve třetí není 2. číslice, v ní musí být chyba, a tedy nulu na 2. místě třeba nahradit jednotkou. Když na místo k6 přijmeme 1 1 0 0 0 1 1w = , dostaneme ( )0,1,0Tw =H . Chyba
je jen v druhé kontrole, a to proto, že druhá kontrolní číslice je chybná a tedy je třeba jedničku na 6. místě nahradit nulou.
3.16 Vytvořte systematický kód K s vytvářející maticí ( )2 ,=G E B , který opravuje dvě
chyby. Kód má opravovat 2 chyby, tedy pro všechny Kv∈ , 0v ≠ musí platit ( ),0 5vρ ≥ . Když
( )2 ,=G E B , ( )Tn 2, −=H B E musí být 6≥n , ale když v řádcích G musí být alespoň 5
jednotek, v řádcích B musí být po 4 jednotkách, přičemž všechny čtveřice sloupců v
( )Tn 2, −=H B E musí být nezávislé, tedy 7≥n .
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 49
Jedno možné řešení pro 8=n .
⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
=
100000100100001000100011000100110000100100000101
H
⎟⎟⎠
⎞⎜⎜⎝
⎛=
1111001000111101
G
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
11001111111100100011110100000000
K
Ján Černý Entropia a informácia v kybernetike
Alfa, 1981, Bratislava, SK
Malá, ale velmi šikovná knížka. Kniha je psána v matematickém duchu a velmi srozumitelnou formou uvede čtenáře do problematiky dle názvu.
Thomas M. Cover, Joy A. Thomas Elements of INFORMATION THEORY (second edition)
Wiley, 2006, New Jersey, USA, ISBN 0-471-24195-4
Obsáhlá kniha zahrnující jak velmi důkladně prezentovanou teorii informace, tak i některé „přináležející“ partie teorie kódů. Kniha obsahuje množství důkazů a doprovodných příkladů. Pojetí knihy je hlavně teoretické. Pro rozvoj vědomostí tzv. matematické informatiky je tato kniha vhodnou „studijní potravou“.
Jaroslav Blažek a kol. Algebra a teoretická aritmetika
SPN, 1983, Praha, CZ
Klasická vysokoškolská učebnice algebry. Je psána pro studium tj. „slušně“. Pozn.: „…jinak psané knihy se zde nesnažím ani doporučovat.“.
Fantasticky napsaná kniha o algebře. Pokud hodláte proniknout k pojmům jako teorie grup, izomorfizmus aj. tak neváhejte. Doporučil bych druhé vydání této knihy.
Jiří Adámek Kódování
SNTL, 1989, Praha, CZ
Dle mého názoru asi nejlepší vstupní kniha do „světa kódů“. Monografie žádném případě nepostrádá matematického ducha a přitom neodradí čtenáře z technicky zaměřené vysoké školy.
50
3.5. GENERUJÍCÍ MATICE Lineární (n, k)-kód má celkem qk kódových slov, protože kódová slova můžeme vyjádřit jejich k souřadnicemi ve zvolené bázi a každá souřadnice má q možných hodnot. Kód je q-znakový, jestliže abeceda T (těleso) má počet znaků q. GENERUJÍCÍ MATICE: Lineární (n, k)-kód s k≠0 je určen svojí (libovolnou) bází b1,b2,…,bk. Pokud napíšeme těchto k slov (bází) pod sebe, vznikne tzv. generující matice daného kódu G.
1 2[ ]Tk=G b b b… (3.12)
Matice G typu (n,k) je generující maticí lineárního kódu, jestliže • každý její řádek je kódovým slovem, • každé kódové slovo je lineární kombinací řádků, • řádky jsou lineárně nezávislé, takže hodnost matice G je rovna k.
3.17 Binární kód celkové kontroly parity v délce n=4, má následující generující matici:
1 0 0 10 1 0 10 0 1 1
⎡ ⎤⎢ ⎥= ⎢ ⎥⎢ ⎥⎣ ⎦
G .
KÓDOVÁNÍ INFORMAČNÍCH ZNAKŮ Jestliže zvolíme generující matici G, tj. bázi kódu b1,b2,…,bk, je každé kódové slovo určeno svými k souřadnicemi v této bázi.
To znamená, že zobrazení : kT Kϕ →
definované předpisem 1 2 1 1 2 2 1 2( ) ( )kk k k ku u u u u u u u u Tϕ = + + + ∈b b b… … …
(3.13) nebo maticově ( ) ( )kTϕ = ∈u uG u , je prosté zobrazení množiny všech slov délky k na množinu všech kódových slov. Je to tedy kódování informačních znaků dle definice kódování informačních znaků. SYSTEMATICKÝ KÓD Systematické kódy jsou ty lineární kódy, které mají generující matici tvaru
[ ]=G E B , (3.14)
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 51
kde E je jednotková matice řádu k a platí
[ ] [ ]
11 1,
21 2,1 2 1 2 1
1 ,
1 0 0 00 1 0 0
0 0 0 1
n k
n kk k k n
k k n k
b bb b
u u u u u u v v
b b
−
−+
−
⎡ ⎤⎢ ⎥⎢ ⎥ =⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
… …
… … … , (3.15)
kde v=vk+1…vn je vektor v=uB.
Věta (ekvivalence lineárních kódů): Každý lineární kód je ekvivalentní se systematickým lineárním kódem.
Poznámka: Důkaz předchozí věty dává návod, jak hledat ekvivalentní systematický kód:
v generující matici přehodíme sloupce tak, aby první k sloupce byly lineárně nezávislé. Tento postup ukážeme na příkladu D15.
3.18 Kód má následující generující matici:
1 1 0 0 0 00 0 1 1 0 00 0 0 0 1 1
⎡ ⎤⎢ ⎥= ⎢ ⎥⎢ ⎥⎣ ⎦
G .
Kód zjevně není systematický. Přehodíme-li druhý a pátý sloupec, tj. provedeme-li permutaci [1, ,3,4, ,6]π = 5 2 , dostaneme následující generující matici
1 0 0 0 1 0' 0 0 1 1 0 0
0 1 0 0 0 1
⎡ ⎤⎢ ⎥= ⎢ ⎥⎢ ⎥⎣ ⎦
G
systematického kódu K', ekvivalentního s koktavým kódem. Kódová slova kódu K' jsou všechna slova u1u2u3u3u1u2.
Přehodíme-li druhý a třetí řádek matice G', dostaneme jinou generující matici kódu K':
[ ]1
1 0 0 0 1 0' | 0 1 0 0 0 1
0 0 1 1 0 0
⎡ ⎤⎢ ⎥= = ⎢ ⎥⎢ ⎥⎣ ⎦
G E B .
Věta (kódová vzdálenost systematického (n,k) kódu): Kódová vzdálenost D lineárního systematického (n,k) kódu je rovna váze jeho nejlehčí nenulové složky.
52
Stačí, ke zjištění D, použít tuto větu pouze na řádky matice G?
Poznámka: Každý binární lineární kód obsahuje buď jen slova sudé váhy (váhou je myšlen počet nenulových znaků ve slově), nebo stejný počet slov sudé i liché váhy.
Kolik slov sudé váhy a kolik liché váhy má následující lineární kód? Jakou má
kódovou vzdálenost?
1 1 0 1 0 10 1 1 0 1 01 1 1 1 1 1
⎡ ⎤⎢ ⎥= ⎢ ⎥⎢ ⎥⎣ ⎦
G
3.6. KONTROLNÍ MATICE
Definice (kontrolní matice): Kontrolní matice lineárního kódu K je taková matice H z prvků abecedy T, pro kterou platí: slovo v = v1v2… vn (v Tn) je kódové, právě když splňuje následující podmínku.
T T=Hv 0 1 2, nK v v v∈ =v v … (3.16)
Věta (vztah matic G a H): Lineární kód s generující maticí [ ]k=G E B má kontrolní matici | 'n k−⎡ ⎤= −⎣ ⎦
TH B E , kde
BT je transponovaná matice B a E'n-k je jednotková matice.
Nalezněte kontrolní matici kódu celkové parity.
3.6.1. DUÁLNÍ KÓD Na prostoru Tn definujeme obvyklým způsobem skalární součin pro libovolná dvě slova u = u1…un a v = v1…vn.
1 1 2 2 n nu v u v u v∗ = + + +u b … (3.17)
3.19 Pro těleso Z2
5 bude platit: 11010 * 01011 = 1 + 1 = 0. Definice (duální kód): Duální kód lineárního kódu nK T⊆ je kód nK T⊥ ⊆ všech slov u1u2…un v Tn, která mají s každým slovem v K skalární součin roven nule.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 53
Tedy: , právě když 0 pro K K⊥∈ ∗ = ∀ ∈u u v v (3.18)
Věta (dualita kódu): Duální kód K ⊥ lineárního (n,k) kódu K má n k informačních znaků, a je tedy (n,n-k) kódem. Generující matice kódu K je kontrolní maticí kódu K ⊥ (a naopak).
3.20 Jaký bude duální kód opakovacího kódu délky 5?
K řešení tohoto příkladu se podívejte na kód celkové kontroly parity.
3.21 Pokračování příkladu 3.18.
[ ]1
1 0 0 0 1 0' | 0 1 0 0 0 1
0 0 1 1 0 0
⎡ ⎤⎢ ⎥= = ⎢ ⎥⎢ ⎥⎣ ⎦
G E B ⇒ 1
0 0 1 1 0 0' | 1 0 0 0 1 0
0 1 0 0 0 1
Tn k−
⎡ ⎤⎢ ⎥⎡ ⎤= =⎣ ⎦ ⎢ ⎥⎢ ⎥⎣ ⎦
H B E
Nyní provedeme inverzní permutaci a obdržíme:
0 0 1 1 0 0' 1 1 0 0 0 0
0 0 0 0 1 1
⎡ ⎤⎢ ⎥= ⎢ ⎥⎢ ⎥⎣ ⎦
H ⇒ formální úprava ⇒ 1 1 0 0 0 0
'' 0 0 1 1 0 00 0 0 0 1 1
⎡ ⎤⎢ ⎥= ⎢ ⎥⎢ ⎥⎣ ⎦
H ⇒
KONSTATOVÁNÍ: „koktavý“ kód je tzv. samoduální kód, tj. platí K K ⊥= ,
u tohoto typu kódu je generující matice zároveň maticí kontrolní.
3.6.2. PRINCIP ZABEZPEČENÍ (dekódování pomocí syndromu) Bezpečnostní kódování informace odpovídá vztahu (3.15), dále tedy: Vyslaný zabezpečený kód: [ V ] = [ I ] [ G ] (3.19) ↓ reálný kanál Přijatý kód s možnou chybou: [ P ] = [ V ] ⊕ [ Err ] (3.20) Musí platit (3.16), pokud ne, je pravá strana označována jako tzv. syndrom chyby [ S ], protože platí: [ S ]T = [ H ] [ P ]T = [ H ] ([ V ]T ⊕ [ E ]T) = [ H ] [ V ]T ⊕ [ H ] [ E ]T = [ H ] [ E ]T (3.21)
0T
informace Generující matice kódu
54
Vlastnost: Syndrom chyby S udává svými prvky polohu chybného místa v kódové složce.
Syndrom chyby S odpovídá šestému sloupci matice H, tedy opravíme šestý znak v přijaté kódové sekvenci.
3.7. PERFEKTNÍ KÓDY Má-li binární kód nK T∈ minimální kódovou vzdálenost 2 1D t≥ + , pak pro každé
slovo nx T∈ existuje nejvýše jedno kódové slovo ve vzdálenosti ≤ t od x. Jinak řečeno, tzv. kombinatorické koule se středem x a poloměrem t, ( , ) { | ( , ) }nB x t z T d x z t= ∈ ≤ , jsou pro různá x K∈ disjunktní.
Odtud dostaneme horní odhad pro velikost takového kódu. Počet prvků ve vzdálenosti i od středu x je n nad i (protože vybíráme neuspořádanou i-tici souřadnic, ve kterých x změníme). Tedy
0
( , )t
i
nB x t
i=
⎛ ⎞= ⎜ ⎟
⎝ ⎠∑ . (3.22)
Tuto hodnotu nazveme objem koule B(x,t) a dále označíme V(n,t).
Věta (Hammingův odhad): Pro binární kód o minimální kódové vzdálenosti alespoň 2t+1 platí
2( , )
n
KV n t
≤ (3.23)
Definice (perfektní kód): Binární kód je označen jako perfektní, pokud pro něj platí rovnost v Hammingově odhadu.
3.23 Ověřte, že opakovací kód liché délky a totální kód (kód tvořený všemi slovy nad Tn) je perfektní.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 55
3.8. HAMMINGOVY KÓDY Hammingovy kódy tvoří významnou třídu kódů, které opravují jednoduché chyby. Kódy se snadno dekódují a jsou tzv. perfektní, tj. mají nejmenší myslitelnou redundanci. Hammingův binární kód s m kontrolními znaky (m=2,3,4,…) má délku 2m-1, takže dostáváme binární (2m - 1, 2m – m - 1)-kód, tj. (3,2)-kód, (7,4)-kód, (15,11)-kód, atd.
Poznámka: Informační poměr roste rychle k 1, například pro kód délky 26-1=63 je informační poměr (63-6/63)>0,9.
Věta H1: Binární lineární kód opravuje jednoduché chyby, právě když sloupce jeho kontrolní matice jsou nenulové a navzájem různé. Věta H2: Hammingovy binární kódy jsou perfektní kódy pro jednoduché opravy. Tato vlastnost je charakterizuje, tj. každý perfektní binární kód pro jednoduché opravy je Hammingův kód.
3.8.1. Princip rozšíření kódu Rozšířený HAMMINGŮV KÓD je binární kód, vzniklý rozšířením Hammingova kódu o znak celkové kontroly parity. Je to tedy (2m,2m – m - 1)-kód všech slov 1 2 2mv v v…
takových, že 1 2 2 1mv v v−
… je kódové slovo Hammingova kódu a 1 22 2 1m mv v v v−
= + + +… .
Poznámka: Minimální vzdálenost Hammingova kódu je 3 a minimální vzdálenost rozšířeného Hammingova kódu je 4.
Princip ROZŠÍŘENÍ KÓDU (extension) spočívá v přidání znaku celkové kontroly parity ke každému řádku kontrolní matice a dále doplnění řádku jedniček. Tzn., že z (n,k)-kódu K vytvoříme (n+1,k)-kód K všech slov v1v2…vnvn+1 takových, že platí
Definice (Hammingův kód): Binární kód se nazývá Hammingův, jestliže má kontrolní matici, jejíž sloupce jsou všechna nenulová slova dané délky a žádné z nich se neopakuje.
permutace sloupců
56
1 2 1 1 2 a n n nv v v K v v v v+∈ = + + +… … (3.24)
Kontrolní matice rozšířeného kódu má pak tvar: *
0
01 1 1
⎡ ⎤⎢ ⎥⎢ ⎥=⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
HH
Poznámka 1: Původní kontrolní rovnice tedy zůstávají (ovšem bez proměnné vn+1) a navíc přibývá rovnice v1 + v2 + … + vn + vn+1 = 0.
Poznámka 2: Jestliže má binární kód K minimální kódovou vzdálenost D, má rozšířený kód minimální kódovou vzdálenost D+1, pro D liché a D, pro D sudé.
3.25 Zrealizujte rozšíření (7,4)-kódu (tj. zrealizujte (8,4)-kód).
Poznámka: KONSTRUKCE KÓDOVÝCH SLOV H(8,4)-kódu: ◊ Rozšíříme kanonický tvar kontrolní matice H(7,4) dle (3.24) na H(8,4). ◊ K tomu abychom získali generující matici je třeba provést algebraické
úpravý vedoucí na kanonický tvar, tj. na systematickou variantu Hammingova kódu. Úprava spočívá v přičtení prvních tří řádků ke čtvrtému.
3.26 Sestavte generující matici rozšířeného Hammingova (8,4)-kódu (systematického i nesystematického) a na základě vlastností matic H a G učiňte závěr.
Protože dimenze obou kódů je 4, stačí ověřit, že skalární součin libovolných dvou řádků je roven 0.
kontrolní bity sudé parity
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 57
3.9. GOLAYOVY KÓDY
Golayovy kódy patří k nejvýznamnějším binárním kódům a to ve variantě G23 a rozšířené G24. Kód G23 je spolu s Hammingovým a opakovacím kódem jediným perfektním binárním kódem. Kód G23 má 12 informačních a 11 kontrolních znaků. Tyto kódy zavedeme opět pomocí matice G.
Golayův kód: Golayovy kódy zavádíme jako systematické binární kódy délky 23 a 24. Levou polovinu generující matice tvoří matice jednotková. Pravá polovina sestává ze čtvercové matice B11, doplněné o řádek 11…1 v případě G23 a dále o sloupec 11…10 v případě G24.
23
1 1 1 1
⎡ ⎤⎢ ⎥
= ⎢ ⎥⎢ ⎥⎣ ⎦
G E B 23
11
1 1 1 1 0
⎡ ⎤⎢ ⎥
= ⎢ ⎥⎢ ⎥⎣ ⎦
G E B (3.25)
Matice B vznikne cyklickými posuvy svého prvního řádku, tj. slova B1 o jednu pozici doprava.
0 3 5 6 7 8 9 101 2 4
1 0 0 0 0 01 1 1 1 1 1
b b b b b b b bb b b
⎡ ⎤= ⎣ ⎦B (3.26)
Poznámka 1: Toto slovo má jedničku na místě i = 0,1,…10, právě když je i čtvercem
modulo 11, tj. pro 02 mod 11, 12 mod 11, 22 mod 11, atd.
Poznámka 2: Kód G24 je samoduální, tj. 24 24G G⊥ = . Případný důkaz: Stačí ukázat, že skalární součin dvou libovolných řádků matice G24 je nulový, tj. radeki * radekj = 0. Potom totiž lineární prostor G24 je podprostorem duálu 24G⊥ , a protože dimenze duálu je 24 –12 = 12
(stejná jako dimenze prostoru G24), plyne odtud 24 24G G⊥ = .
Věta: Golayův kód G23 je perfektní pro opravy trojnásobných chyb.
Poznámka: Minimální vzdálenost G23 kódu je 7 a rozšířeného G24 kódu je 8.
Věta (Tietäväinenova a Van Lintova): Jediné netriviální perfektní binární kódy jsou tyto:
a) Hammingovy kódy pro jednoduché chyby, b) Golayův kód pro trojnásobné chyby a kódy s ním ekvivalentní, c) opakovací kódy délky 2t+1 (pro t-násobné chyby), kde t = 1,2,3,….
58
3.10. CYKLICKÉ KÓDY
Cyklické kódy, též CRC, patří k velmi rozšířené skupině lineárních kódů. Přes svoji relativní jednoduchost konstrukce skýtají mocný a aplikovatelný prostředek v protichybovém zabezpečovacím procesu. Matematická teorie cyklických kódů je založena na popisu vlastností konečných těles. Specifickou vlastností těchto kódů je vlastnost, podle které se též nazývají. Tato vlastnost spočívá v tom, že cyklickým posunem platné kódové složky vzniká opět platná kódová složka. Definice cyklických kódů je tak vzhledem k dalekosáhlým důsledkům překvapivě jednoduchá.
Definice (Cyklický kód):
Lineární kód se nazývá cyklický, jestliže pro každé kódové slovo je také kódovým slovem.
v0v1…vn-1 [V1] = [ v1v2…vn-1vn]
vn-1v0v1…vn-2 [V2] = [ v2v3…vnv1]
Kódová slova můžeme zapisovat jako polynomy, přičemž každý polynom je pouze jiným zápisem kódového slova:
v0v1…vn-1 ≡ v0 + v1x + … + vn-1xn-1 (3.27) Poznámka: Indexy zde píšeme od nuly z dále zřejmých důvodů.
3.27a Příklad manipulace se sloven v abecedě {0,1,2}, např. pro: 2010100.
1. Mějme slovo v abecedě {0,1,2}, např.: 2010100. 2. Pak můžeme psát toto slovo dle (3.27) jako polynom 2 + x2 + x4. 3. Cyklickým posunem vznikne slovo 0201010. 4. Tedy polynom 2x + x3 + x5 = x(2 + x2 + x4). 5. Což je x-násobek původního polynomu. 6. Dalším cyklickým posuvem vznikne slovo 0020101. 7. Tedy polynom 2x2 + x4 + x6 = x2(2 + x2 + x4) atd.
Poznámka 1: Ukazuje se tedy, že pro každé kódové slovo zapsané jako polynom v(x),
jsou i všechny násobky p(x)v(x) kódová slova.
⇒ Existuje jediné kódové slovo, tzv. generující polynom, které vytváří celý kód, jelikož kódová slova jsou všechny násobky generujícího polynomu.
Cyklickým posunem platné kódové složky vzniká opět platná kódová složka.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 59
Z definice generující matice víme, že tyto polynomy tvoří bázi kódu. Pro generující polynom g(z) (n,k)-kódu K tedy platí:
1) Stupeň polynomu g(z) je n-k. 2) Kód K sestává ze všech násobků polynomu g(z) v prostoru Tn, tedy:
{ }( ) ( ) | ( ) nK q z g z q z T= ∈ .
3) Polynom g(z), z.g(z), ..., zk-1.g(z) tvoří bázi kódu K. 4) Polynom g(z) dělí polynom zn - 1 beze zbytku.
U cyklických kódů můžeme také kontrolní matici nahradit kontrolním polynomem:
( ) ( 1) / ( )nh z z g z= −
Pro každý polynom v(z), pro který platí: ( ) ( ) 0v z h z⋅ = splňuje kontrolní matice podmínku
⋅ =T TH v 0 .
3.27b …pokračování předchozího příkladu.
8. V tomto příkladu uvažujeme lineární prostor T 7, máme zde operaci sčítání a násobení polynomů, tj. naše algebraická struktura „se velmi obohatila“, místo pouhého násobení vektoru skalárem zde můžeme násobit dva vektory (ve smyslu obvyklého součinu dvou polynomů).
9. „Ale je tu ALE“: co když je součin dvou polynomů polynom stupně vyššího než 6? 10. Provedeme další posun, tj. 1002010 ⇒ 1 + 2x3 + x5, který již bohužel není
součinem x3(2 + x2 + x4), protože tento součin obsahuje člen x7. 11. „Nic však není ztraceno“: Při cyklickém posunu se koeficient u x7 přemístí na nulté
místo vektoru (místo s indexem 0). 12. Místo polynomu x3(2 + x2 + x4) = 2x3 + x5 + x7 dostáváme polynom 1 + 2x3 + x5.
Tato úprava je možná, protože platí x7 = 1. Poznámka 2: Cyklické kódy délky n tedy budeme popisovat jako polynomy stupně < n, které sčítáme a násobíme obvyklým (u polynomů) způsobem, až na to, že pokládáme xn = 1 (a tedy xn+1 = x, xn+2 = x2, atd.). V tomto duchu bychom mohli pokračovat hluboko nad rámec tohoto kurzu. Přes algebru polynomů a faktorové okruhy bychom se postupně dostali k zavedení generujícího a kontrolního polynomu cyklického kódu. Dále se tedy budeme zabývat praktickou stránkou užití CRC kódů a budeme předpokládat, že generující polynomy jsou již dány, například následující tabulkou.
Tab. 3.6: Tabulka generujících mnohočlenů. Cyklický (n,k) kód je kód, jehož kódové složky lze vyjádřit mnohočleny stupně n-1 a méně, jež jsou dělitelné bezezbytku generujícím (vytvořujícím) mnohočlenem G(x) stupně r = n - k. Dále dvojčlen xn + 1 musí být dělitelný G(x) beze zbytku. Označme I(x) mnohočlen jenž reprezentuje přenášenou informaci s k prvky. Postup zabezpečení je pak následující. Každý mnohočlen I(x), vyjadřující nezabezpečenou informaci, se nejprve násobí členem xr, tj. I'(x) = I(x) xr, čímž se stupeň každého členu polynomu I(x) zvýší o r. To je ekvivalentní připsání r nul na konec kódové složky [I]. Potom se I'(x) dělí generujícím mnohočlenem G(x):
'( ) ( ) ( )( )( ) ( ) ( )
rI x I x x R xQ xG x G x G x
⋅= = ⊕
Dělením vznikne podíl Q(x) a zbytek R(x), který může být nejvýše stupně r – 1. Úpravou dostáváme:
( ) ( ) ( ) ( ) nebo také ( ) ( ) ( ) ( ),r rI x x Q x G x R x I x x R x Q x G x⋅ = ⋅ ⊕ ⋅ ⊕ = ⋅
protože v aritmetice modulo 2 se odčítání shoduje se sčítáním. Pravá strana tohoto vztahu zajišťuje dělitelnost I(x) xr ⊕ R(x) beze zbytku. Levá část tvoří zabezpečenou složku n-prvkového kódu:
( ) ( ) ( )rV x I x x R x= ⋅ ⊕
Zbytek po dělení R(x) tedy určuje zabezpečující prvky. Do přenosového kanálu se vysílají nejprve informační prvky a za nimi prvky zabezpečující. Poznámka 3: Vlastní realizace dělení generujícím polynomem je snadno realizovatelná pomocí dvou binárních sčítaček a tří posuvných registrů (pro Hammingův (7, 4)-kód):
Obr. 3.3: Hardwarová realizace dělení generujícím polynomem g(z) = z3 + z + 1
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 61
Do obvodu vstupují koeficienty polynomu u(z) = u0z6 + u1z5 + ... + u6 a vystupují koeficienty podílu q(z) = q0z6 + q1z5 + ... + q6. Po vystoupení posledního koeficientu zůstávají v registrech koeficienty zbytku r(z) = r2z2 + r1z + r0.
3.28 Pro demonstraci zabezpečení přenosu CRC kódem použijeme (7,4) kód s generujícím mnohočlenem dle tabulky Tab. 3.6 G2(x) = x3+x+1.
Určovat zabezpečení budeme pro binární sekvenci [I] = [0001] reprezentovanou mnohočlenem I(x) = 1. I(x) nejprve násobíme členem xr = x3, tedy I'(x) = 1 x3 = x3, což představuje doplnění kódové složky [I] třemi nulami: [I'] = [0001000]. Nyní vydělíme I'(x) generujícím mnohočlenem G3(x):
3 33
3
'( ) 1: ( 1) 1( ) 1
I x xx x xG x x x
+= + + = +
+ +
Zbytek R(x) = x+1 tvoří redundantní část, takže vyslaná složka V(x) bude: 3( ) '( ) ( ) 1V x I x R x x x= + = + + , tj. [V] = [0001011]. Generující matici cyklického (7,4)
kódu můžeme zapsat v maticovém tvaru následovně:
1 0 0 0 1 0 10 1 0 0 1 1 1
[ ]0 0 1 0 1 1 00 0 0 1 0 1 1
G
⎡ ⎤⎢ ⎥⎢ ⎥=⎢ ⎥⎢ ⎥⎣ ⎦
Uvedený kód je schopen detekovat všechny jednoduché a dvojnásobné chyby nebo korigovat všechny jednoduché chyby. Správnost přenosu lze na přijímající straně ověřit dělením polynomu P(x) přijaté kódové složky generujícím mnohočlenem G(x):
( ) ( ) ( ) ( )( ) ( )
( )( )( ) ( ) ( )( ) ( )
r
p
P x I x x R x E xG x G x
R xE xQ x Q x M xG x G x
⋅ + ⊕= =
= ⊕ = ⊕ ⊕
Jestliže mnohočlen chyby E(x) ≠ 0 není dělitelný polynomem G(x) beze zbytku, pak zbytek Rp(x) ≠ 0 indikuje chybu přenosu. Zbytek Rp(x) je roven nule v případě bezchybného přenosu, tj. E(x) = 0 nebo je-li mnohočlen E(x) ≠ 0 dělitelný G(x) beze zbytku, čímž chyba v tomto místě zůstane nezjištěna. Poznámka 4: U počítačových sítí typu Ethernet se používá zabezpečení cyklickým kódem s 32 zabezpečovacími prvky a následujícím generujícím mnohočlenem CRC-32:
32 26 23 22 16 12 11 10 8 7 5 4 2( ) 1G x x x x x x x x x x x x x x x= + + + + + + + + + + + + + + .
CRC1.swf Cyklické kódy (práce s polynomy).
62
Tood K. Moon Error correction Coding
Wiley, 2005, New Persey, USA, ISBN 0-471-46800-0 Stručně: nejobsáhlejší a snad i nejlepší kniha s problematikou detekčních a korekčních kódů.
San Ling, Chaoping Xing Cosiny Tudory
Cambridge UP, 2004, Cambridge, UK, ISBN 0-521-52923-9 Základní kurz teorie detekčních a korekčních kódů.
Uveďte způsob jak objevit trojnásobné chyby, při použití kódu dvourozměrné kontroly parity. Opravuje tento kód dvojnásobné chyby?
Kolik chyb opraví kód 2 z 5, kde ho můžete naleznout?
Najděte dva typy kódů, pro které platí rovnost 1d n k= − + .
Jak je definován informační poměr?
Pro vámi navržený kód dvourozměrné kontroly parity ověřte, že je lineární.
Uveďte příklad nelineárního kódu a dokažte jeho nelinearitu.
Napište tabulku operace sčítání v tělese Z3.
Kolik slov sudé váhy a kolik slov liché váhy má binární kód s následující generující maticí:
1 1 0 1 0 10 1 1 0 1 01 1 1 1 1 1
⎡ ⎤⎢ ⎥= ⎢ ⎥⎢ ⎥⎣ ⎦
G
Pro (7,4)-kód ověřte příjem zprávy [1011101], učiňte závěr.
Co to znamená, když o kódu prohlásíme, že je perfektní? Uveďte, které to jsou.
Předveďte princip rozšíření Hammingova kódu.
Napište kontrolní matici rozšířeného Hammingova (16,11)-kódu. Proč není tento kód samoduální?
Vydělte nad tělesem Z2: 3( 1) /( 1)x x x+ + + .
Generující polynom (7,4)-kódu je 3 1z z+ + , informace je [1001], jaké bude vyslané kódové slovo?
…prohlášení na adresu výzvědné služby, tehdy prvního lorda admirality Winstona Churchilla na počátku I. světové války.
Kryptografické kódování je kódování mající vztah k utajení informace. Tento typ kódování je často označován jako „šifrování“. Důvodem pro šifrování je nutnost přenosu citlivých či tajných dat přes nezabezpečené prostředí (přenosový kanál). Takovým prostředím může být např. poštovní kanál, internet, či jiná veřejná datová síť.
Šifrování obecně zahrnuje, jak jednoduché postupy známé z rébusů či junáckých her, tak opravdu silné algoritmy k jejichž prolomení by časově při současném stavu poznání nestačilo ani stáří vesmíru. O tom, že informace mohou mít „cenu zlata“ není pochyb, utajení takovéto informace má pak cenu snad ještě vyšší, jak již nejednou historie ukázala. Jeden z důkazů pro takovéto tvrzení může být založen na faktu, že USA uvalily na některé speciální typy kódů vojenské embargo a vládní instituce NSA „ukrajuje“ nemalý finanční obnos z resortu ministerstva obrany. Další důkaz o tom, že šifrování může měnit i dějiny, je slavný případ německého kódovacího stroje ENIGMA. V současnosti se s různými formami utajení informace setkáme běžně, a to například: zašifrovaná hesla pro vstup do OS, kreditní karty jištěné tzv. pinem, zabezpečená komunikace po internetu (SSL), šifrování e-mailů, elektronické platby aj. Následující text, je pouze stručnou informací k tomuto velmi komplexnímu oboru matematické informatiky.
Simon Singh Kniha kódů a šifer
Dokořán / ARGO, 2003, Praha, CZ
Skvělý překlad knihy The Code Book Simona Singhta, za který můžeme poděkovat Petru Koubskému a Ditě Eckhardtové. Kniha nás provede populárně naučnou formou metodami tajné komunikace od starého Egypta po budoucnost v podobě kvantové kryptografie. Tuto knihu bych doporučil jako první čtení pro zájemce o tento skvělý a jistě dobrodružný obor, jakým kryptografie i kryptoanalýza bezesporu je.
Bernard Schneier Applied Cryptography (sekond edition): protocols, algorithms, and source code in C
Willey, 1986, New York, USA
Nebudu přehánět, když tuto knihu prohlásím za základní četbu o kryptografii. Autor knihy je sám autorem známého kryptosystému Blow Fish a některých dalších vylepšení. Kniha pojednává o moderní kriptografii a obsahuje základní matematické dodatky (Eulerova funkce, čínská věta o zbytcích, Fermatova věta a j.) vhodné k pochopení prezentovaných kryptosystémů.
Skvělý portál s informacemi o kryptografii. Součástí je kryptografický e-časopis Crypto-World, který vychází cca. 1x měsíčně a lze si zde zdarma zajistit jeho pravidelné zasílání. Na stránky webu i e-časopisu přispívají mimo jiných následující přední čeští odborníci, dnes i světového ohlasu (metoda hledání kolizí pro MD5) jako například pánové (uvedeno bez akademických titulů): Vondruška, Pinkava, Klíma a Rosa.
4.1. Názvosloví Kryptografie je věda o šifrování a dešifrování dat za pomoci matematických metod.
Tedy v případě textových dat můžeme říci, že se kryptografie zabývá transformací tzv. otevřeného textu (srozumitelný, čitelný text, angl. plain text) na šifrovaný text, tj. šifru, kryptogram (angl. cipher text) prostřednictvím šifrování a transformací šifry na otevřený text prostřednictvím dešifrování. Ideální kryptosystémy podporují následující bezpečnostní vlastnosti, a to:
utajení, autentizace a integrita dat, nepopiratelnost.
S pojmem kryptografie musíme ještě zavést pojem kryptoanalýza. Kryptoanalýza se snaží (bez znalosti, či pouze s částečnou znalostí o klíči) dojít k utajovaným datům (metody zahrnují: čistě vědecké přístupy, hrubou strojovou sílu, hrubou lidskou sílu – tzv. pendreková kryptoanalýza). Ke kryptoanalýze je však většinou třeba mnoho analytického myšlení, aplikace matematických metod, hledání cestiček, trpělivosti a štěstí. Kryptografie a kryptoanalýza spolu tvoří jeden obor nazývaný kryptologie.
Definice (kryptografický systém): Kryptografický systém je petice {M,C,K,E,D}, kde M je konečná množina otevřených textů (prostor textu), C je konečná množina možných šifer (prostor šifer), K je konečná množina možných klíčů (prostor klíčů), E je množina šifrovacích funkcí (pravidel, šifrovacích algoritmu), D je množina dešifrovacích funkcí (pravidel, dešifrovacích algoritmu).
Poznámka 1: Stručně systém, který nám umožní šifrovat a dešifrovat, označíme jako
kryptografický systém. Poznámka 2: Užívané pojmy „kryptografický systém“ a „kryptosystém“ můžeme
ztotožnit. “Silné” šifry jsou takové, které „dokáží“ odolat všem kryptoanalytickým metodám, kromě útoku hrubou silou. Slovo „dokáží“ vyjadřuje fakt, že bezpečnost systému je založena na řešení silného (NP-úplného) matematického problému. Obranou proti útoku hrubou silou je obecně zvětšení délky klíče, aby se vyčerpávající prohledávání uskutečnilo v čase, který není realizovatelný nebo je “výpočetně neproveditelný” v potřebném čase. Obecně jsou za silné šifry považovány kvalitní symetrické šifry s délkou klíče nad 70 bitů a u asymetrických šifer typu RSA s délkou klíče nad 700 bitů.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 65
4.1.1. Steganografie Steganografie (z řečtiny: steganós-schovaný, gráphein-psát) je věda zabývající se utajením komunikace prostřednictvím ukrytí zprávy. Jedná se tedy o metody ukrývání zprávy jako takové. Často může být kombinována s kryptografií. Do této skupiny patří různé metody maskování jinak viditelné informace. V moderní době lze tajné texty ukrývat například do souborů s hudbou či obrázků namísto náhodného šumu .
4.1.2. Substituční šifry Substituční šifra obecně nahrazuje každý znak zprávy otevřeného textu jiným znakem podle nějakého pravidla. Aby příjemce získal otevřený text, musí na zašifrovaný text použít inverzní substituci. V klasické kryptografii existují čtyři typy substitučních šifer:
Monoalfabetická substituční šifra (jednoduchá substituční šifra), ve které se každý znak otevřeného textu nahradí příslušným znakem šifrovaného textu.
Homofonní substituční šifra se podobá jednoduché substituční šifře, avšak jeden znak otevřeného textu může byt nahrazen jedním z několika možných znaků šifrovaného textu. Znak „A“ by mohl být nahrazen např. 5, 10, 13 nebo 25, „B“ např. 6 nebo 15. Počet znaků zašifrovaného textu pro jeden znak otevřeného textu se může lišit.
Polygramová substituční šifra je ta, ve které šifrování probíhá mezi skupinami znaků. Skupina „AA“ může být nahrazená skupinou „JH“, „AB“ skupinou „DK“ atd.
Polyalfabetická substituční šifra sa skladá z několika jednoduchých šifer, které se postupně pro jednotlivé znaky otevřeného textu střídají.
4.1.3. Transpoziční šifry Transpozice spočívá ve změně pořadí znaků podle určitého pravidla. Například tak, že otevřený text je zapsán do tabulky po řádcích a šifrový text vznikne čtením sloupců téže tabulky.
4.1 Transpoziční mřížka. Ve čtverci n×n políček je vystřižených n×n/4 políček tak, aby při postupném otáčení o 90° stupňů vzniklé otvory vždy ukazovaly na volné místo k vepsání textu.
Tento typ šifry použil Jules Verne ve své knize
Matyáš Sandorf (Nový hrabě Monte Christo) .
Fleissnerovu otočnou mřížku, poprvé popsal Fleissner Von Wostrowitz v roce 1881.
playfair.swf Demonstrace šifry Play Fair.
66
4.2. Historické poznámky
Následující text nepředstavuje výčet všeho, co je možné nazvat historií kryptografie (zde můžeme doporučit například referenci: Kniha kódu a šifer, Simona Singhla). Text má pouze naznačit jak se vývoj šifer ubíral do doby vývoje metod, které teď označujeme za moderní kryptografii. Jak ale víme, vše je relativní a kvantová kryptografie, či jiné postupy jsou již jistě za dveřmi (možná za vašimi, možná je na nich cedulka NSA).
4.2.1. Kryptografie Řecka a Říma První pokusy o utajení obsahu zpráv jsou známé již ze starého Egypta a
Mezopotámie. Jednalo se o nejprimitivnější systémy, které spočívaly v nějaké mírné, zpravidla neobvyklé úpravě písma. Takovéto malé změny zcela postačovaly, protože již samotná znalost písma byla v té době jistým druhem šifrování. Ze staré Indie jsou známy metody utajení informace uvedené ve známé učebnici erotiky Kámasútře.
Kořeny skutečné kryptologie jsou spjaty až s dějinami Řecka. Téměř každá učebnice šifrování začíná popisem toho, jak Řekové pro utajení zpráv používali následující: oholili svému poslu hlavu, napsali na jeho lebku vzkaz a když mu vlasy opět narostly, mohl se vydat na cestu (odesílatelem zprávy byl Histiaeus a zprávu napsal na hlavu svému oddanému otroku, který ji takto dopravil do Milétu a pomohl tak ke koordinaci povstání proti Peršanům). Takto uvedený způsob utajení informace je označován jako steganografie, a je ho zajisté užíváno dodnes. Řekové však neskončili jen u utajování přenosu zpráv, ale dokázali vyvinout skutečné šifrové systémy. Sparťané, nejbojovnější z Řeků, vymysleli a prokazatelně používali již v pátém století před naším letopočtem zařízení na utajení zpráv. Tento systém představuje nejstarší známé kryptografické zařízení a skládá se ze dvou holí ("skytale" nebo někdy psáno "scytale") přesně stanovené šířky (šířka = symetrický klíč zařízení), na prvou hůl se navinul pás látky, papyru nebo pergamenu. Na tento materiál se potom napsala zpráva. Pás s textem se sejmul a posel (komunikační systém) jej odnesl na místo určení. Tam byl pás látky navinut na druhou hůl a zpráva mohla být přečtena. Tento systém šifrování by se dnes označil jako transpoziční šifra.
Řecký spisovatel Polybius zase vynalezl systém signalizace, který byl později převzat jako další základní kryptografická metoda. Seřadil písmena do čtverce a jejich řady a sloupce očísloval. Každé písmeno je tak reprezentováno dvěma čísly: číslem řady a číslem sloupce. Polybiův čtverec (šachovnice), který umožňuje převod písmen na číslice, se stal základem mnoha dalších šifrových systémů.
Římané nepřevzali tyto systémy od Řeků, vydali se vlastní cestou. Kolem přelomu našeho letopočtu prokazatelně zavedli vojenskou kryptografii. Zprávy mezi legiemi nebyly zasílány otevřeně, ale pomocí záměny otevřeného textu za šifrový text. Julius Caesar vypráví o využití těchto systémů v "Zápiscích o válce galské". Známý životopisec Suetonius pak dokonce prozrazuje, jak systém přesně vypadal. Každé písmeno zprávy bylo zaměněno za písmeno, které leželo o tři místa dále v abecedě. Tento systém by jsme dnes označili jako substituční monoalfabetická šifra. Kryptografie ve starém Římě se stala naprostou samozřejmostí. Mimo podobných záměn se ještě používalo vkládání kódů pro jména osob, zemí apod.
4.2.2. Caesarova šifra Jedná se o tzv. substituční monoalfabetickou šifru. Z hlediska názvosloví moderní
kryptografie by jsme doplnily, že realizovaný kryptosystém je tzv. symetrický kap. 4.3. Algoritmus šifry je realizován tak, že všechna písmena ve zprávě se posunou o tři pozice v abecedě dopředu. Například slovo CAESAR by se šifrovalo jako FDHVDU. Algoritmem šifry je zde posun písmen a heslem (tajným klíčem) je číslo 3.
Obr. 4.2: Princip Caesarovy substituční šifry.
4.2 Nalezněte informace o „šifře“ označené jako ROT13
4.2.3. Temný středověk Skutečná kryptologie se zrodila teprve díky vynikajícím arabským matematikům,
kteří jako první objevili a popsali metody kryptoanalýzy (rok 855 n.l. Abú Bakr Ahmad). Na práce arabských matematiků a kryptologů navázala středověká Evropa.
Významným představitelem evropské kryptografie byl benediktinský opat Johannes Trithemius (1452 - 1518). Kolem roku 1500 napsal první významnější evropskou knihu o šifrování. Trithemius se zabýval převážně substitučními systémy. Zavedl a doporučoval vkládání klamačů do šifrového textu. Jednalo se o náhodné vkládání znaků do textu za
68
účelem ztížení statistického rozboru. Vrcholem tehdejší doby byl jeho následovník francouzský diplomat Blaire de Vigenere.
V 16. století se objevili i první slavní luštitelé. Jedním z největších byl francouzský právník a matematik Francois Viete (1540 - 1610), který luštil zašifrované depeše španělského krále a předával je francouzskému panovníkovi Jindřichu IV. Navarrskému. Trvalo několik let, než na to Španělé přišli. Nevěřili, že je možné jejich složitou záměnu rozluštit a žádali Svatou stolici, aby postavila Vieta před soud, protože musí být spojen s ďáblem. Poznání, že výsledné šifrové texty lze na základě statistických metod luštit, vedlo ke zdokonalování šifrových systémů. Neboť spolehnutí na nedokonalý systém mohlo stát i život, viz. např. popravená skotská královna Marie Stuartovna (1542 - 1587). Stuartovnou užívaný šifrovací monoalfabetický šifrovací systém rozluštil (frekvenční kryptoanalýza) a tím i její ortel zpečetil Thomas Phelippes.
Kryptoanalytikové měli v té době „navrch“ a to i přes to, že už dávno před tím se Leonu Battistovi Albertimu podařil objev tisíciletí s názvem polyalfabetická šifra. Ten však svůj objev nikdy nerozvinul a přenechal tak pomyslnou pochodeň dalším pokračovatelům, byli to Johanes Trithemius, Givanni Portay a konečně Blaire de Vigenere, francouzský diplomat se zcela praktickým zájmem o kryptografii.
4.2.4. Vigenerova šifra Síla Vigenerovy šifry spočívá v tom, že k zašifrování zprávy nepoužívá jednu, ale
26 odlišných šifrových abeced. První šifrovací krok spočívá v tom, že se vytvoří tzv. Vigenerův čtverec, což je otevřená abeceda následovaná 26 šifrovými abecedami, z nichž každá je vůči předchozí posunuta o jedno písmeno. První řádek tedy odpovídá šifrové abecedě s Caesarovým posunem 1. Řádek 2 odpovídá šifrové abecedě s Caesarovým posunem 2 a tak dále. Nejvrchnější řádek čtverce reprezentuje otevřený text. Každé jeho písmeno lze zašifrovat kteroukoliv z 26 šifrových abeced. Pokud například použijeme abecedu 2, pak písmeno A šifrujeme jako C, použijeme-li abecedu 12, šifrujeme ho jako M. Podstata Vigenerovy šifry však spočívá v tom, že se pro zakódování každého písmene použije jiný řádek čtverce, tedy jiná šifrová abeceda. Jinými slovy, odesílatel může zašifrovat první písmeno zprávy pomocí řádku 5, druhé podle řádku 14, třetí řádkem 21 a tak dále. Aby příjemce získal zpět čitelný text, musí vědět, kterým řádkem Vigenerova čtverce šifroval odesílatel každé písmeno zprávy, musí tedy existovat předem dohodnutý systém, podle něhož se řádky střídají. Toho lze dosáhnout pomocí klíčového slova - klíče.
4.3 Postup jak prostřednictvím Vigenerova čtverce zašifrujeme krátkou zprávu: divert troops to east ridge (odkloňte jednotky k východnímu hřebenu), heslo je: WHITE.
Jako první krok napíšeme heslo nad text zprávy – opakovaně, tolikrát, kolikrát je třeba, abychom ji pokryli celou. Z otevřeného textu odstraníme mezery. Pak šifrujeme následujícím způsobem: k zašifrování prvního písmene, jímž je d, se nejprve podíváme, jaké písmeno klíče se u něj nachází. Je to W, čímž je dán řádek Vigenerova čtverce,
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 69
v daném případě řádek 22, jenž začíná právě písmenem W. V průsečíku sloupce označeného d a řádku označeného W najdeme písmeno Z, což je první písmeno hledaného šifrového textu atd.
Klíčové slovo: W H I T E W H I T E W H I T E W H I T E W H I Otevřený text: d i v e r t t r o o p s t o e a s t r i d g e Šifrový text: Z P D X V P A Z H S L Z B H I W Z B K M Z N M
Vrcholem Vigenerovy práce byl jeho Traicté des chiffres (Traktát o šifrách), publikovaný roku 1586. Ironií osudu jej vydal téhož roku, kdy Thomas Phelippes prolomil šifru Marie Stuartovny.
Vzhledem k tomu, o jak silný šifrovací prostředek šlo, zdálo by se přirozené, že se rychle rozšíří do šifrovací praxe po celé Evropě. Stal se však opak: Vigenerova šifra se neujala. Tento zjevně dokonalý systém byl opomíjen po celá dvě následující století.
Vigenere.swf Vigeneruv substituční polyalfabetický šifrovací systém.
4.2.5. Vzestup kryptografie – válka a telegraf První světová válka přivedla na svět první masové použití šifrování v polních
podmínkách. Podnětem k rozvoji kryptologie nebyla jen válka jako taková, ale i rozšíření bezdrátového telegrafu. Např. samotný vstup USA do války byl důsledkem vyluštění obsahu šifrového telegramu – dnes známého jako tzv. Zimmermannův telegram, kde německý ministr zahraničí Zimmermann v telegramu mexické vládě vyzývá Mexiko k válce proti USA. Slibuje v ní mexické straně podporu a územní zisk. Britové telegram zachytili, rozluštili jej a předali USA. Poté, co se prezident Wilson s obsahem telegramu seznámil, svolává Kongres. Ten 2.4.1917 schvaluje vstup USA do války proti Německu.
První světová válka vychovala i prvního z velikánů kryptografie dvacátého století. Stal se jím William Frederic Friedman (1891 - 1969), který v roce 1915 nastoupil dráhu úspěšného kryptologa v americké armádě a vybudoval pro USA vzorně fungující kryptoanalytickou službu. Opravdovou biblí všech kryptologů prvé poloviny dvacátého století se stalo jeho čtyřsvazkové dílo "Základy kryptoanalýzy" z roku 1923.
Nové vyzbrojování ve třicátých letech se tedy nesoustředilo jen na vývoj zbraní, ale i na výrobu šifrovacích zařízení. V Německu bylo sestrojeno snad nejznámější šifrovací zařízení všech dob – legendární ENIGMA , ale i řada dalších důmyslných zařízení, např. kryptografické zařízení LORENZ nebo poněkud slabší zařízení Kryha. Svá řešení vyvíjelo i Japonsko, USA (Sigaba, Hagelin C-38, M-209), Anglie a další státy, které se připravovaly k válce. Jména tvůrců těchto kryptografických zařízení jsou Edward H. Hebern, Hugo Koch, Arvid Gerhard Damm, Alexandr von Kryha, Gilbert Vernam, Boris Hagelin a další.
Druhá světová válka prověřila kvalitu přichystaných šifrovacích zařízení. Zní to až neuvěřitelně, ale s odstupem času, kdy byly příslušné materiály postupně odtajněny, se ukázalo, že většinu tehdy používaných šifrových systémů se podařilo druhé straně prolomit a příslušné zprávy z těchto kanálů využívat. Utajení před veřejností bylo dokonalé. V zájmu neprozrazení, že v Bletchley Parku (hrabství Buckinghamshire) luští zprávy z
70
Enigmy, nezabránil W.Churchil rozbombardování Coventry. Vzhledem k luštění zpráv předávané Enigmou a i Lorenzem o chystaném náletu předem věděl, ale dlouhodobé strategické využívání zpráv z těchto zdrojů postavil nad životy tisíců lidí z tohoto anglického města. Cesta k prolomení tehdejších systémů již nebyla jednoduchá – na luštění se podíleli nejlepší matematici a pro účely luštění zařízení Enigma a Lorenz byly postaveny první stroje, které můžeme dnes nazvat počítače. Úplný popis zařízení Colossus, které sloužilo k luštění zpráv kryptografického zařízení Lorenz, byl například uvolněn teprve v květnu roku 2000. Jiným příkladem kryptografického systému bylo využití indiánů kmene NAVAJO u americké námořní pěchoty k předávání tajných zpráv rádiem. Kódovou řeč, kterou Indiáni předávali ve své mateřštině, se Japoncům nepodařilo odhalit. Američané tento způsob s úspěchem použili ještě ve válce v Severní Koreji a dokonce i v 60. letech ve Vietnamu. Veřejnost byla o úspěchu těchto Indiánů informována až koncem šedesátých let a úplná kódová kniha byla uvolněna k publikování teprve roku 1999.
Druhá polovina dvacátého století je charakteristická 2 pracemi od Claude Elwood Shannona. V časopise Bell Systém Technical Journal v roce 1948 a 1949 otiskuje články "Matematická teorie sdělování" a "Sdělovací teorie tajných systémů". Prvý z článků dal vznik teorii informací, druhý článek pojednával o kryptologii v termínech informační teorie. Pojetí nadbytečnosti (redundancy) je hlavním termínem, který Shannon zavedl. Oba články fakticky odstartovaly moderní pojetí matematického zkoumání základů kryptografie a kryptoanalýzy.
4.2.6. Vermanův kryptosystém Krátce po II. světové válce se začala vyrábět nová kvalitní kryptografická zařízení.
Tato zařízení byla zpravidla založena na velice jednoduchém principu, sčítání otevřeného textu s náhodným heslem. Systém navrhl již roku 1917 Gilbert Vernam, ale teprve z publikované teorie amerického vědce Shannona vyplynulo, že jediný absolutně bezpečný systém je právě sčítání otevřené zprávy se stejně dlouhým náhodným heslem.
Při splnění jistých podmínek, je Vermanův kryptosystém jediným absolutně bezpečným systémem šifrování zpráv.
Poznámka 1: Při objemu dnes předávaných zpráv je tento systém nevyhovující. Jeho význam je v tom, že se jedná o jediný absolutně bezpečný systém.
Poznámka 2: Nutné podmínky absolutní bezpečnosti Vermanova kryptosystému: • umíme vyrobit náhodné, stejně pravděpodobné heslo (výroba takového
hesla byla v 60. letech velkým problémem), • máme dostatečně důvěryhodný kanál k transportu hesla na místo určení, • korespondence je tak slabá, že nám nevadí velká spotřeba hesla, • každé heslo lze použít pouze jednou a je tedy potřeba dodržovat určitá
přesně daná pravidla pro zacházení s heslovým materiálem.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 71
Karibská krize na začátku šedesátých let vyvolala potřebu rychlého a bezpečného spojení mezi USA a SSSR. Obě mocnosti se domluvily na vybudování horké linky mezi hlavami obou států. Pro tuto linku byl zvolen právě Vermanův kryptosystém. Horká linka byla uvedena do provozu 30. 8. 1963. Kreml i Bílý dům si vzájemně vyměnily heslové materiály. Otevřené texty se převedly do dálnopisného kódu a sčítaly se s heslovým materiálem, heslová páska byla ihned po použití automaticky ničena, čímž se mělo zamezit jejímu nechtěnému opětovnému použití. Při zavedení tohoto systému se použilo zařízení ETCRRM (Electronic Teleprinter Cryptographic Regenerative Repeater Mixer II).
4.2.7. Moderní doba Kryptologie se v sedmdesátých letech rozšířila z uzavřených komunit tajných
služeb i do civilního sektoru a začala se stávat součástí světové vědy. Objevily se první významné výsledky. V roce 1976 publikovali Whitfield Diffie, Martin Hellman a Ralph Merkle článek o nové závratné myšlence – asymetrické kryptologii (dosud šifrové systémy byly systémy tzv. symetrické). Brzy po zveřejnění teoretického schématu asymetrické kryptografie (1978), se objevuje první šifrový systém. Vžil se pro něj název RSA (zkratka z prvních písmen tvůrců systému Rivest, Shamir a Adelmann). Tento systém se po malých úpravách (především prodloužení klíče a stanovení jistých pravidel, která musí klíče splňovat) používá dodnes.
Na scéně se objevuje první celosvětově uznávaný symetrický algoritmus DES (Data Encryption Standard). Vývoj DES navazuje na vývoj šifrovacího algoritmu Lucifer od Thomase Watsona (IBM). Potřeba standardu jeho vývoj urychluje a DES je v roce 1977 v USA přijat za veřejný standard pro ochranu informací, nikoliv však pro ochranu informací utajovaných! DES šifruje text po blocích délky 64 bitů, aktivní délka klíče je 56 bitů, hlavní prvky, které chrání šifrový text před útoky analytiků, jsou tzv. S-boxy.
Dalším mezníkem je rok 1980 kdy se konala v Santa Barbaře konference věnovaná kryptologii. Konference měla výjimečný ohlas a její další konání pod názvem Krypto trvá dodnes. Vytváří se nezávislá akademická skupina odborníků, kteří v roce 1982 zakládají IACR. Koncem osmdesátých a začátkem 90. let se objevuje celá řada dalších symetrických blokových algoritmů – FEAL, GOST, IDEA, CAST, BLOWFISH atd. Autoři těchto systémů jsou výrazné postavy z komunity IACR. V ČR se v té době komerčně vyvíjí vlastní šifrovací čip SIC5000 (s algoritmem DVK). Současně se zjišťuje, že některé z těchto systémů, ač na první pohled velice podobné svoji strukturou DES, nejsou tak kvalitní a jsou rozbitelné. Japonský FEAL je totálně rozbit. Ale ani DES s délkou klíče „pouze“ 56 bitů nevydržel věčně. V roce 1995 se na veřejnost dostává informace, že NSA vlastní stroj, který je schopen DES vyluštit do 15 minut. Toto zařízení sestrojila firma The Harris Corporation. Později bylo komerčně sestrojeno a předvedeno speciální zařízení DES-cracker (1998). DES musel být nahrazen jiným standardem. Prozatímně to byl 3DES (TripleDES). Nyní je novým standardem AES (Advanced Encryption Standard, 2001). AES je 128bitová bloková šifra, podporující klíče délky 128, 192 a 256 bitů.
Další řada metod se objevila se zavedením technologií elektronických podpisů, jedná se především o tzv. hash MD5 (message digest, otisk délky 128 bitů) a SHA-1 (Secure Hash Algorithm, otisk délky 160 bitů). Koncem roku 1999 přijala evropská komise Směrnici o elektronických podpisech (1999/93/EC) v rámci Evropské unie. V ČR byl e-podpis zaveden zákonem 227/2000 Sb. (plus: NV 304/2001, vyhláška 366/2001).
72
4.3. Symetrické a asymetrické šifrování
Základní rozdělení moderních kryptografických metod je možné dle způsobu práce s klíčem, tj. heslem. V zásadě dnes rozeznáváme dva druhy šifrování a to šifrování s tajným klíčem a šifrování s veřejným klíčem. Oba dva jsou pro bezpečnost důležité. Šifrování s veřejným klíčem je výpočetně a matematicky náročnější, ale má aspekty, které je staví na speciální nenahraditelnou pozici. Šifrování se pak dělí na:
SYMETRICKÉ ŠIFROVÁNÍ někdy též nazývané konvenční, je takový šifrovací algoritmus, který používá k šifrování i dešifrování jediný klíč.
ASYMETRICKÉ ŠIFROVÁNÍ (kryptografie s veřejným klíčem) je skupina kryptografických metod, ve kterých se pro šifrování a dešifrování používají odlišné klíče a to tzv. soukromý a veřejný klíč.
DŮLEŽITÉ POJMY:
S-Box: jeden ze základních stavebních prvků moderní blokové šifry. V zásadě je to booleovská funkce převádějící binární vektor na jiný binární vektor. Pro kryptografické účely jsou tyto funkce studovány a jsou formulovány takové jejich vlastnosti, které poskytují záruky pro bezpečnost výsledné šifry. Tyto vlastnosti jsou obvykle statistického charakteru (např. tzv. kriterium laviny, anglicky Strict Avalanche Criterion, spočívá v požadavku, že při změně jednoho bitu vstupu do S-boxu se s pravděpodobností jedna polovina změní jednotlivé bity výstupu S-boxu).
Jednosměrná funkce: matematická funkce, kterou v jednom směru (přímém) lze snadno spočítat, zatímco v opačném směru (inverzní zobrazení) probíhají výpočty velmi obtížně.
Hashovací funkce: Vstupem (jednosměrné) hashovací funkce je blok proměnné délky (zpráva) a výstupem je blok pevné délky (obvykle 128 či 160 bitů) – hash [čti heš].
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 73
4.3.1. Kerckhoffův princip S implementaci moderních kryptografických systémů souvisí pojem dnes chápané bezpečnosti dat. Tento princip vyslovil poprvé před 150 lety pruský důstojník Kerckhoff.
Utajení a bezpečnost zašifrovaných dat nesmí záležet na utajení postupu, kterým se šifrují. Naopak, vždy se musí předpokládat, že váš nepřítel zná šifru (algoritmus) do nejmenších detailů. Utajení musí spočívat pouze v klíči (hesle), které nezná nikdo jiný.
Tento princip je dnes všeobecně uznáván jako základ úspěšné ochrany dat. Proto se vědci soustředili na vytvoření co nejlepších, veřejně známých šifrovacích postupů (algoritmů), a na ověření toho, že tyto postupy jsou bezpečné.
Takovými postupy jsou například symetrická šifra AES či asymetrická šifra RSA. Jejich bezpečnost je ověřena tím, že i přes mnohaletou práci mnoha tisíc vědců se patrně nikomu z nich nepodařilo objevit způsob, jak tyto postupy „rozbít“.
Skutečně kvalitní systém pro ochranu dat je takový systém, jehož vnitřní funkčnost a detaily jsou dobře známy, ale přesto tato znalost ani v nejmenším nepomůže potenciálním protivníkům v jejich zlomení. Příkladem takového systému je například veřejně popsaný protokol TLS. S jeho pomocí jsou chráněny například bankovní operace při Internet bankingu, tedy transakce velké hodnoty.
Kriteria hodnocení šifer (C.Shannon, 1945): mohutnost nabízeného utajení, délka klíče, jednoduché a rychlé šifrování a dešifrování, šíření chyb, prodloužení zprávy. Dva důležité šifrovací principy (C.Shannon, 1945): • Konfůze: vyžaduje substituci, aby vztah mezi klíčem a šifrovým textem byl co
nejsložitější. • Difůze: vyžaduje transformaci, která rozptyluje statistické vlastnosti otevřeného textu
napříč šifrovým textem. Diskutované metody „prolomení“ šifer jsou: útok hrubou silou, lineární kryptoanalýza, diferenciální kryptoanalýza, timing attack a velmi efektivní pendreková kryptoanalýza.
74
4.3.2. SYMETRICKÉ ALGORITMY Symetrické šifrování je založeno na principu jednoho klíče, kterým lze zprávu jak zašifrovat, tak i dešifrovat. Příkladem symetrického klíče je známý DES (Data Encryption Standard) vyvinutý v 70. letech v USA a již zmíněný v kapitole 4.2.7. Symetrické kódy mají jako hlavní výhodu rychlost algoritmu, algoritmy pro šifrování s veřejným klíčem můžou být i stotisíckrát pomalejší. Na druhou stranu je nutné aby se příjemce i odesílatel dohodli na jednom klíči, který budou znát pouze oni dva. Problémem je tedy distribuce klíče - jak dostat klíč k příjemci aniž by se ho chopil někdo nepovolaný?
Obr. 4.3: Princip symetrické kryptografie.
Symetrické šifry se dále dělí na dva druhy:
• Proudové šifry zpracovávají otevřený text po jednotlivých bitech. RC4, FISH, …
• Blokové šifry rozdělí otevřený text na bloky stejné velikosti a doplní vhodným způsobe, poslední blok na stejnou velikost. U většiny šifer se používá blok o 64 bitech, AES používá 128 bitů. AES, Blowfish, DES, 3DES, IDEA, CÁST, RC2, RC5
Stručná charakteristika některých šifer:
DES: kryptografický standard. Byl vyvinut firmou IBM v sedmdesátých letech. V roce 1977 se stal americkou vládní normou pro šifrování (certifikován NIST – National Institute of Standards and Technology - naposledy v roce 1993). Široce používán, avšak v současné době ho nelze považovat za perspektivní algoritmus. Snaha o jeho vylepšení má označeni 3DES (též TripleDES) IDEA: (International Data Encryption Algorithm) je algoritmus s délkou klíče 128 bitů. Pro svou značnou bezpečnost a vysokou rychlost je považován za vysoce kvalitní algoritmus. IDEA je patentována, majitelem patentu je firma Ascom-Tech. Blowfish: algoritmus s proměnnou délkou klíče (32 – 448 bitů). Blowfish byl navržen v roce 1993 a opublikován v roce 1994 Bruce Scneierem.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 75
CAST: CAST, navržený autory Carlisle Adams a Stafford Taverns, je moderní algoritmus (bloková šifra s délkou bloku 64 bitů). Jeho design je velmi podobný algoritmu Blowfish, obsahuje S-boxy závislé na klíči, dále neinvertibilní funkci f a má strukturu Feistelovy šifry. CAST je patentován firmou Entrust Technologies, která ho však postoupila pro volné užití. Skipjack: Jádro kryptografického chipu Clipper. Pomocí klíče v délce 80 bitů je zpracováván blok otevřeného textu o délce 64 bitů. Vyvinut NSA (National Security Agency). Dlouho utajován, na nátlak veřejnosti byl v červnu 1998 zveřejněn. Algoritmus obsahuje určitá zadní vrátka umožňující zpětnou rekonstrukci klíče. Pro tuto vlastnost (key recovery - možnost zpětného rozkrytí klíče) byl dosti kritizován. AES: Advanced Encryption Standard - norma blokové šifry. Kandidát této normy musel splňovat tyto minimální požadavky:
a) podporovat šifrování bloků o velikosti 128 bitů b) podporovat využívaní klíčů v délkách 128, 192 a 256 bitů
Jako vítěz AES byla 26. května 2002 prijata šifra Rijndael (1998), která je tímto dále označována jako AES. AES je 128 bitová bloková šifra.
symetrasymetr.swf Demonstrace principu kryptosystému soukromého i veřejného klíče.
Stručný výčet vhodných referenčních odkazů
http://csrc.nist.gov/encryption/aes/aes_home.htm příprava kryptografického standartu (pro blokovou šifru) pro 21.století http://www.cs.auckland.ac.nz/~pgut001/links.html Peter Gutmann (jeden z nejlépe zpracovaných přehledů webovských stránek týkajících se kryptologie - možná vůbec nejlepší) http://www.cs.hut.fi/ssh/crypto Tatu Ylönen (bohatý zdroj informací z kryptologické problematiky) http://www.modeemi.cs.tut.fi/~avs/eu-crypto.html politika, legislativa a technologie - Evropa http://www.itl.nist.gov/div897/pubs/fip46-2.htm americký kryptografický standart (DES) http://www.program.com/source/crypto/blowfish.txt algoritmus Blowfish http://zensoft.com/pages/IDEA.html algoritmus IDEA http://www.entrust.com/resources/whitepapers.htm algoritmus CAST http://www.itl.nist.gov/div897/pubs/fip180-1.htm hashovací funkce SHA-1 http://www.globecom.net/(sv)/ietf/rfc/rfc1321.shtml hashovací funkce MD5 http://www.esat.kuleuven.ac.be/~bosselae/ripemd160.html hashovací funkce RIPEMD 160
76
4.3.3. DES (Data Encryption Standard) Kryptoanalytické metody, které je možno užít ke kryptoanalýze jednoduchých kryptosystémů (historické šifry: Césarova i Vingenerova šifra) jsou založeny na tom, že jednoduché šifrovací systémy vytvářejí šifrový text, z jehož statistických vlastností lze dělat jisté závěry. Proto je cílem pokročilých šifrovacích algoritmů transformovat otevřený text rovnoměrně do šifrového textu tak, aby byly šifrové texty stejně pravděpodobné. Teoreticky tuto myšlenku formuloval již C. Shannon (Difůze) a dále ji rozpracoval Horst Feistel při vytváření kryptosystému LUCIFER firmy IBM. Na základě tohoto kryptosystému byl vyvinut a v roce 1977 zaveden v USA šifrový standard DES (Data Encryption Standard), který se stal na dvě desetiletí nejrozšířenějším symetrickým kryptosystémem určeným pro digitální přenos dat.
DES slouží k šifrování bloků 64 bitů (utajovanou zprávu ve formě bitového řetězce je nutno předem rozdělit na 64-bitové bloky a poslední blok doplnit na 64 bitů). Šifrovací klíč je určen 56 bity – existuje tedy celkem 256 možných klíčů. Algoritmus DES provádí postupně 16 iterací šifrovacího schématu tvořeného pevně danými substitucemi, transpozicemi a aplikací (v každém iteračním kroku jiného) 48-bitového klíče, který je pro každou z iterací odvozen ze zadaného 56-bitového klíče. Proto je před vlastním šifrováním nutno připravit ze zadaného (56-bitového) klíče K šestnáct 48-bitových klíčů K1, …, K16. Při vlastní aplikaci klíče se používá bitová operace ⊕ (součet modulo 2).
V dalším popíšeme zvlášť postup odvozování 48-bitových klíčů (tento postup je obvykle nazýván expanzí klíčů) a vlastní šifrovací funkci.
EXPANZE KLÍČŮ: 56-bitový klíč K je zadáván jako 64 bitů (8 bytů), bity č. 8, 16,…, 64 slouží jako paritní kontrola. Z klíče je odvozeno 16 klíčů K1, …, K16, které jsou postupně využívány při šifrování. Postup odvození klíčů Ki (Obr. 4.4) je následující: nejdříve se aplikuje výběrová permutace PC1 – vynechání paritních bitů a transpozice ostatních dle tabulky Tab. 4.1. Výsledkem je 56-bitový řetězec PC1(K) začínající 57. bitem klíče K, za ním následuje 49. bit klíče K a tak dále, na konci je 4. bit klíče K. Tento 58-bitový řetězec je rozdělen na poloviny po 28 bitech: PC1 = C0D0. Pak je v krocích 16,...,1=i provedena v každé polovině určená transpozice (<<<) LSi – daný cyklický posun pozic vlevo (Tab. 4.2): ( )1−= iii CLSC , ( )1−= iii DLSD . Výsledek: ( )PC2i i iK C D= , kde PC2 (Tab. 4.3)
je výstupní výběrová permutace (Subkey), při níž proběhne též zúžení na 48 bitů (není použit např. bit č. 9 řetězce CiDi).
Obr. 4.5: Šifrovací schéma DES (Feistelova struktura)
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 79
ŠIFROVÁNÍ: Schéma šifrování je zachyceno na obrázku Obr. 4.5. Vstupem je šifrovaný 64-bitový blok T (otevřený text) a samozřejmě 16 připravených 48-bitových klíčů K1,…,K16. (subkey 48 bitů, Obr. 4.6) Nejprve proběhne vstupní permutace IP (Tab. 4.4), jejímž výsledkem je 64-bitový blok ( )0 IPT T= začínající 58. bitem bloku T,
pak následuje 50. bit bloku T a tak dále, na konci je 7. bit bloku T. Výsledný blok T0 je poté rozdělen na levou část L0 (prvních 32 bitů) a pravou část R0 (zbývajících 32 bitů). Vlastní šifrování se skládá z 16 iterací (tzv. rund – běžné označení). Pro 16,...,1=i je vstupem i-té iterace výsledek předchozí iterace Ti-1 tvořený levou částí Li-1 a pravou částí Ri-1. Výstupem i-té operace je 64-bitový blok Ti, jehož levá část Li a pravá část Ri jsou určeny takto:
1−= ií RL přemístění pravé poloviny doleva,
( )iiii KRfLR ,11 −− ⊕= výpočet pravé poloviny – použití šifrovací funkce f
s odvozeným klíčem Ki.
Šifrovací funkce f (Obr. 4.6) realizuje vlastní aplikaci klíče: Pravá polovina 1−iR (32 bitů)
je nejdříve rozšířena podle tabulky expanze (Tab. 4.6) na 48 bitový řetězec ( )1−iRE .
Prvních šest bitů je nyní tvořeno 32., 1., 2., 3., 4. a 5. bitem řetězce 1−iR , … a tak dále;
posledních šest bitů tvoří 28., 29., 30., 31., 32. a 1. bit řetězce 1−iR . K výslednému 48-
bitovému řetězci ( )1−iRE je přičten odvozený klíč Ki.
Obr. 4.6: DES F – funkce, Feistelova funkce
80
Výsledek je rozdělen na 6-bitové řetězce 81,..., BB tak, že ( ) ii KREBBB ⊕= −1821 ... a
transformován substitučními tabulkami (tzv. S-boxy) 81,...,SS (viz Tab. 4.5, kde číslo
řádku tabulky S-boxu Sj je dáno binárně 1. a 6. bitem řetězce Bj, číslo sloupce 2.-5. bitem) Výstupy S-boxů jsou čtyřbitové řetězce ( ) ( )8811 ,..., BSBS . Jejich spojením vznikne 32-
bitový řetězec, který je nakonec transformován permutací P (Tab. 4.7):
( ) ( ) ( )( )88111 ..., BSBSPKRf ii =− .
Výsledkem 16 iterací šifrování (rund) je blok 1616LR , který je na závěr
transformován pomocí inverzní vstupní permutace 1−IP (Tab. 4.8) na výstupní šifrový text ( )1616
4.3.4. ASYMETRICKÉ ALGORITMY - RSA Asymetrické algoritmy nazýváme též algoritmy s veřejným klíčem. Princip těchto algoritmů je spočívá v tom, že pro každého uživatele existuje dvojice klíčů: veřejný a soukromý (tajný).
Veřejný klíč je všeobecně komukoliv dostupný. Tímto klíčem lze pouze zašifrovat zprávu pro určitého uživatele. Soukromý klíč má každý u sebe schovaný a určitým způsobem chráněný proti ukradení (heslem, na čipové kartě, na magnetické kartě). Tímto tajným klíčem lze provádět odkódování přijatých zpráv. Tedy, je-li zpráva pouze pro mě, tak pouze já svým tajným klíčem ji mohu odšifrovat.
Asymetrická kryptografie je založena na tzv. jednocestných funkcích, což jsou operace, které lze snadno provést pouze v jednom směru: ze vstupu lze snadno spočítat výstup, z výstupu však je velmi obtížné nalézt vstup. Nejběžnějším příkladem je například násobení: je velmi snadné vynásobit dvě i velmi velká čísla, avšak rozklad součinu na činitele (tzv. faktorizace) je velmi obtížný.
Obr. 4.7: Princip asymetrické kryptografie.
Je zřejmé, že šifrovací klíč e a dešifrovací klíč d spolu musí být matematicky svázány, avšak nezbytnou podmínkou pro užitečnost šifry je praktická nemožnost ze znalosti šifrovacího klíče spočítat dešifrovací. Matematicky tedy asymetrická kryptografie postupuje následujícím způsobem (m…zpráva, otevřený text):
Šifrování: c = f(m, e) Dešifrování m = g(c, d)
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 83
Z hlediska bezpečnosti je nutné podotknout, že teoreticky je možné z veřejného klíče u všech algoritmů vypočítat klíč tajný. Ale dosud je to výpočetně neproveditelné. Se současným výkonem počítačů by se jednalo o tisíciletí. Existují návrhy na zefektivnění kryptoanalýzy – např. TWINKLE pro RSA, ale pro rozumný počet bitů klíče jsou algoritmy stále bezpečné.
Nejvýznamnější představitel této skupiny je algoritmus RSA, který byl objeven
roku 1977 a jeho autoři jsou Ron Rivest, Adi Shamir a Joe Adleman – odtud RSA. Systém je založen na teoreticky jednoduché úvaze: Je snadné vynásobit dvě dlouhá (100-místná) prvočísla, ale bez jejich znalosti je prakticky nemožné zpětně provést rozklad výsledku na původní prvočísla. Součin těchto čísel je tedy veřejný klíč. Přitom obě prvočísla potřebujeme pro dešifrování. Algoritmus RSA je též používán k digitálním podpisům. Vzhledem k tomu, že není znám rychlý algoritmus na faktorizaci velkého čísla, je algoritmus RSA brán jako bezpečný.
RSA – konstrukce
POSTUP (stručně, bez pravidel pro volbu p a q): Veřejný klíč:
n…součin dvou prvočísel p a q (zůstávají utajeny); n = p*q e…volím náhodně, s jistými pravidly – e je menší než (p-1)(q-1) a s tímto součinem nesoudělné
Soukromý klíč: d = e-1 mod ((p-1)(q-1)) Šifrování: c = me mod n Dešifrování: m = cd mod n
4.5 Příklad na RSA – šifrování zprávy m = 123.
p = 61 (první prvočíslo) q = 53 (druhé prvočíslo) n = pq = 3233 (modul, veřejný) e = 17 (veřejný, šifrovací exponent) d = 2753 (soukromý, dešifrovací exponent) Pro zašifrování zprávy 123 probíhá výpočet: šifruj(123) = 12317 mod 3233 = 855 Pro dešifrování pak: dešifruj(855) = 8552753 mod 3233 = 123
symetrasymetr.swf Demonstrace principu kryptosystému soukromého i veřejného klíče.
84
4.3.5. Hashovací funkce Hashovací funkce jsou velmi důležité pro kryptografii a tvorbu digitálních podpisů. Jsou to funkce, které umí udělat vzorek jakéhokoli souboru tak, aby byl závislý na všech bitech původního souboru. Výstupem funkce je tzv. hash (vzorek, fngerprint, otisk) o pevné délce. Hash může sloužit ke kontrole integrity dat, k rychlému porovnání dvojice zpráv, indexování, vyhledávání apod. Formálně je to funkce h, která převádí vstupní posloupnost bitů (či bytů) na posloupnost pevné délky n bitů
:h D R→ , kde |D|>|R|.
Z definice plyne možná existence kolizí, to znamená dvojic vstupních dat (x,y) takových, že h(x)=h(y). Kolize jsou nežádoucí, ale v principu se jim nelze úplně vyhnout. Lze jen snižovat pravděpodobnost, že nastane kolize pro podobná data, například při náhodné změně v části vstupní posloupnosti. Cílem je vysoká pravděpodobnost, že dvě zprávy se stejným kontrolním součtem jsou stejné. Požadavky na hašovací funkce:
a) Odolnost vůči získání předlohy. Pro daný haš c je obtížné spočítat x takové, že h(x)=c. (Hašovací funkce je jednosměrná.)
b) Odolnost vůči získání jiné předlohy. Pro daný vstup x je obtížné spočítat y takové, že h(x)=h(y).
c) Odolnost vůči nalezení kolize. Je obtížné (výpočetně sločité) systematicky najít dvojici vstupů (x,y), pro které h(x)=h(y).
Další obvyklé požadavky zahrnují:
a) Nekorelovatelnost vstupních a výstupních bitů, kvůli znemožnění statistické analýzy.
b) Odolnost vůči skoro-kolizím. Je obtížné nalézt x a y taková, že h(x) a h(y) se liší jen v malém počtu bitů.
c) Lokální odolnost vůči získání předlohy. Je obtížné najít i jen část vstupu x ze znalosti h(x).
Známé hašovací funkce:
o Algoritmus MD5 (Message Digest 5) je založen na specifikaci RFC 1321. Byl vyvinut za účelem odstranění nedostatků algoritmu MD4. Algoritmus MD5 provede čtyři průchody datových bloků (algoritmus MD4 provedl pouze tři průchody) za použití různých číselných konstant pro jednotlivá slova ve zprávě během každého průchodu. Počet 32bitových konstant použitých během výpočtu algoritmu MD5 je 64, takže algoritmus MD5 nakonec vytvoří 128bitový algoritmus hash, který se používá pro kontrolu integrity. I když je algoritmus MD5 náročnější na prostředky, poskytuje silnější integritu než algoritmus MD4.
MD5 je již ale „kompromitovaná“, od srpna 2004 je veřejně znám postup nalezení kolizí. Její bezproblémové využití například pro ověření integrity dat přenášených souborů je pochopitelně možné. Tento algoritmus byl implementován i na HW bázi jako MD5 Processor Core.
o Algoritmus SHA1 (Secure Hash Algorithm 1) byl vyvinut v institutu NIST (National Institute of Standards and Technology), jak je uvedeno ve standardu Federal Information Processing Standard (FIPS) PUB 180-1. Proces výpočtu algoritmu SHA se velmi podobá procesu výpočtu algoritmu MD5. Výsledkem výpočtu algoritmu SHA1 je 160bitový algoritmus hash, který se používá pro kontrolu integrity. Delší algoritmus hash poskytuje lepší zabezpečení, proto je algoritmus SHA bezpečnější než algoritmus MD5. SHA1 je již také „kompromitovaná“, v únoru 2005 byl zveřejněn objev algoritmu, který umožňuje nalézt kolizi podstatně rychleji než hrubou silou, algoritmus je však prozatím výpočetně náročný.
o Algoritmus SHA2 je dosud považován za spolehlivý. o Algoritmus RIPEMD 160: Nejnovějším hashovacím algoritmem je RIPEMD-160,
který byl navržen s cílem nahradit MD4 a MD5. Vytváří (jak vyplývá z jeho názvu) hash v délce 160 bitů. Byl vyvinut v rámci evropského projektu RIPE.
Digitální podpis je elektronickým protějškem ručně psaného podpisů. Jsou to dlouhá a složitě generovaná čísla, která vypočítává buď procesor nebo čipová karta. K výpočtu těchto podpisů je zapotřebí dvojice klíčů. Svým privátním klíčem (ke kterému nemá přístup nikdo kromě vlastníka - bývá uložen na čipové kartě nebo v počítači a je chráněn heslem) lze zprávu podepsat. Důležité je, že vygenerovaný digitální podpis (jako zmíněné číslo) závisí na každém bitu podepisované zprávy. Protože by pak byl digitální podpis neúměrně dlouhý, využívají se vzorkovací funkce. Po vytvoření vzorku je pak podepsán vzorek a nikoli celá zpráva.
Elektronický podpis je kryptografická metoda zajišťující pro digitální data podobné vlastnosti jako vlastnoruční podpis u běžných papírových dokumentů. Elektronický podpis zajišťuje:
• integritu dokumentu – lze prokázat, že po podepsání nedošlo k žádné změně, soubor není poškozen (ani záměrně, ani omylem),
• autentizaci – lze prokázat, že autorem je skutečně ten, kdo je pod dokumentem podepsán,
• nepopiratelnost – autor nemůže popřít, že dokument podepsal.
METODY KÓDOVÁNÍ
2006 – Radomil MATOUŠEK 87
88
Jaká je slabina substitučních monoalfabetických šifer?
Uveďte princip Vigenerovy šifry?
Může existovat absolutně bezpečná šifra? Pokud ano, tak jak se realizuje, pokud ne, tak proč?
Co je to pendreková kryptoanalýza?
Jaký je princip moderní kryptografie?
Vysvětlete princip symetrické a asymetrické kryptografie?
Popište algoritmus RSA, kde jste se s ním setkali? Porovnejte jeho výpočetní náročnost s algoritmem Blowfish.
Popište algoritmus DES, z čeho vycházel, co je to S-Box?
Co je to certifikační autorita, znáte nějakou a co je a k čemu sloužít?
Jaký je princip digitálního podpisu, je v ČR uzákoněn?
Jaký je princip hashovacích funkcí, jaké je jejich užití? Co jsou to kolize a jaký mají praktický význam.