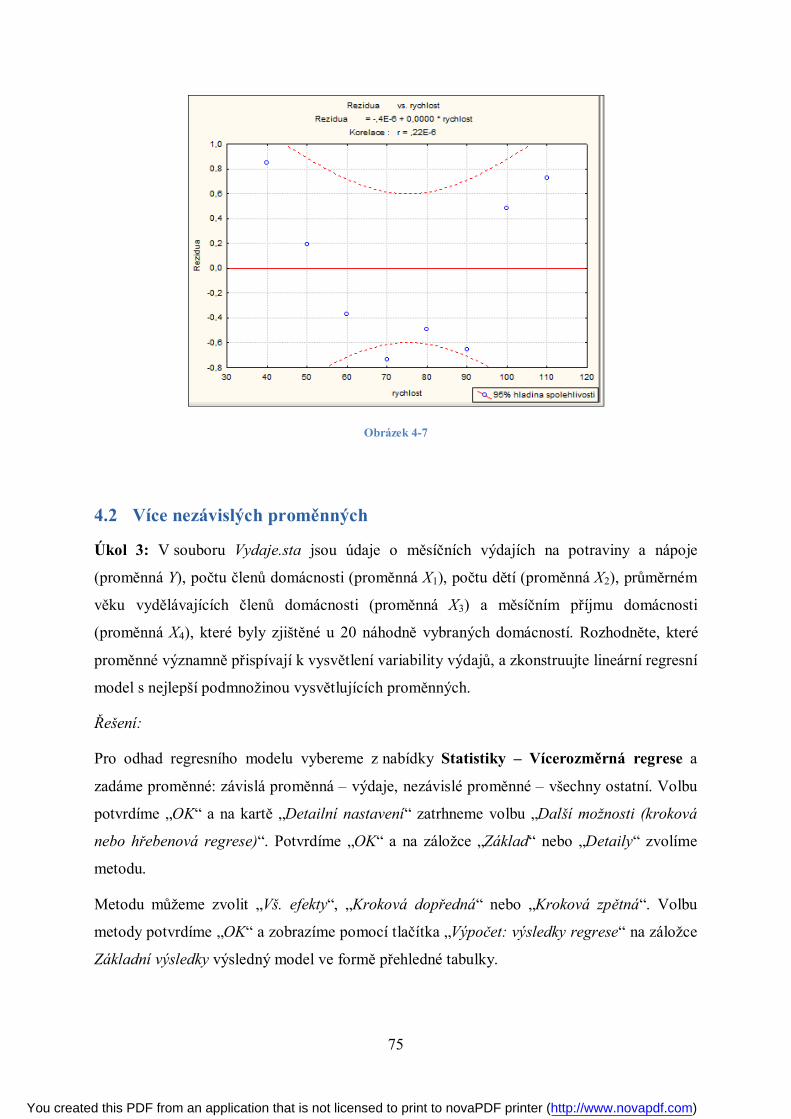
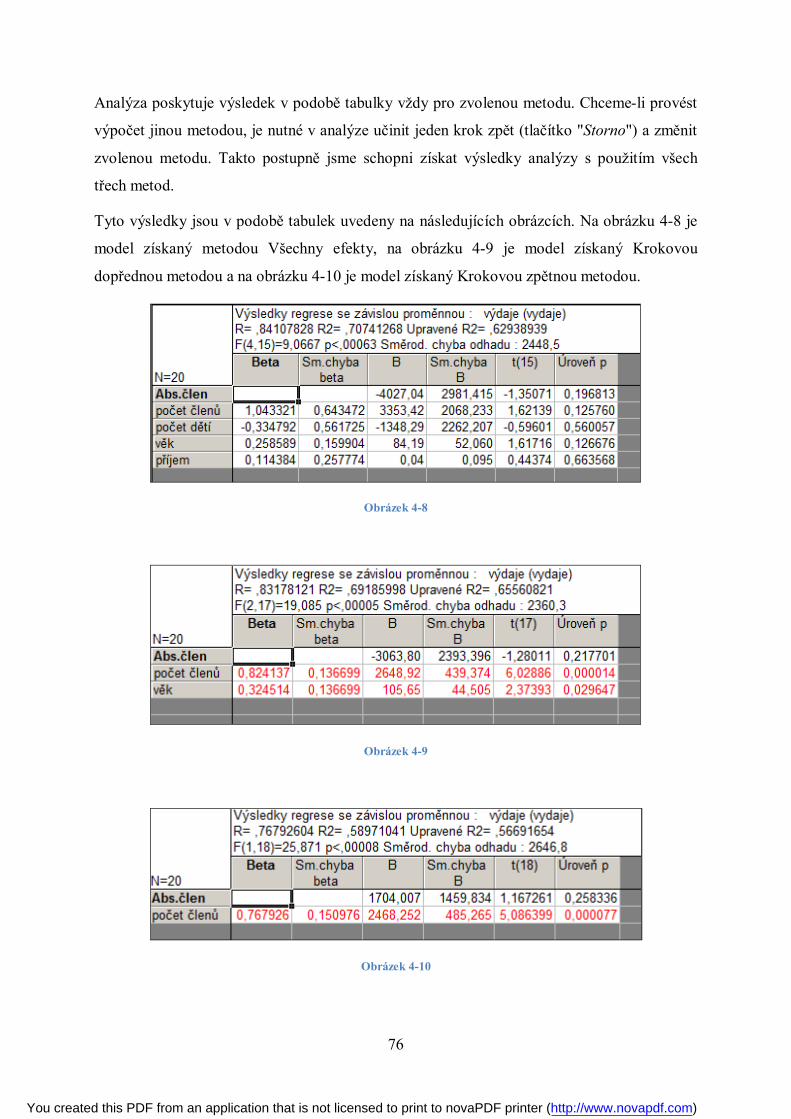
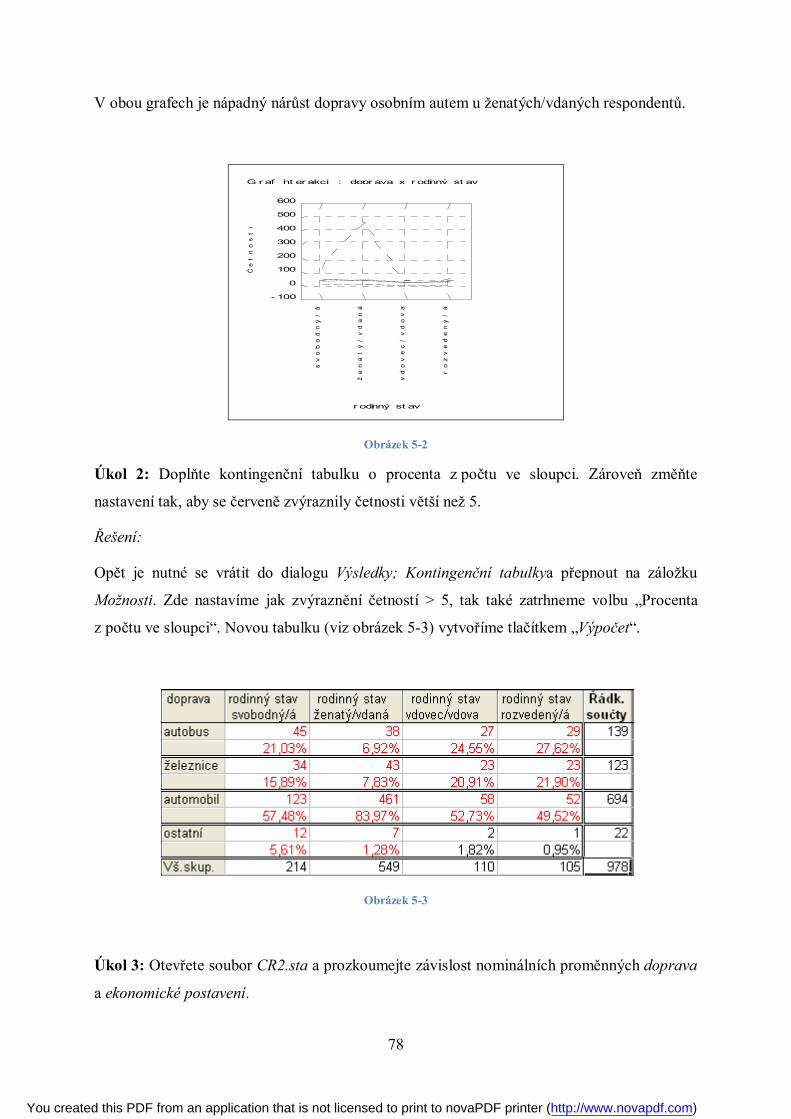
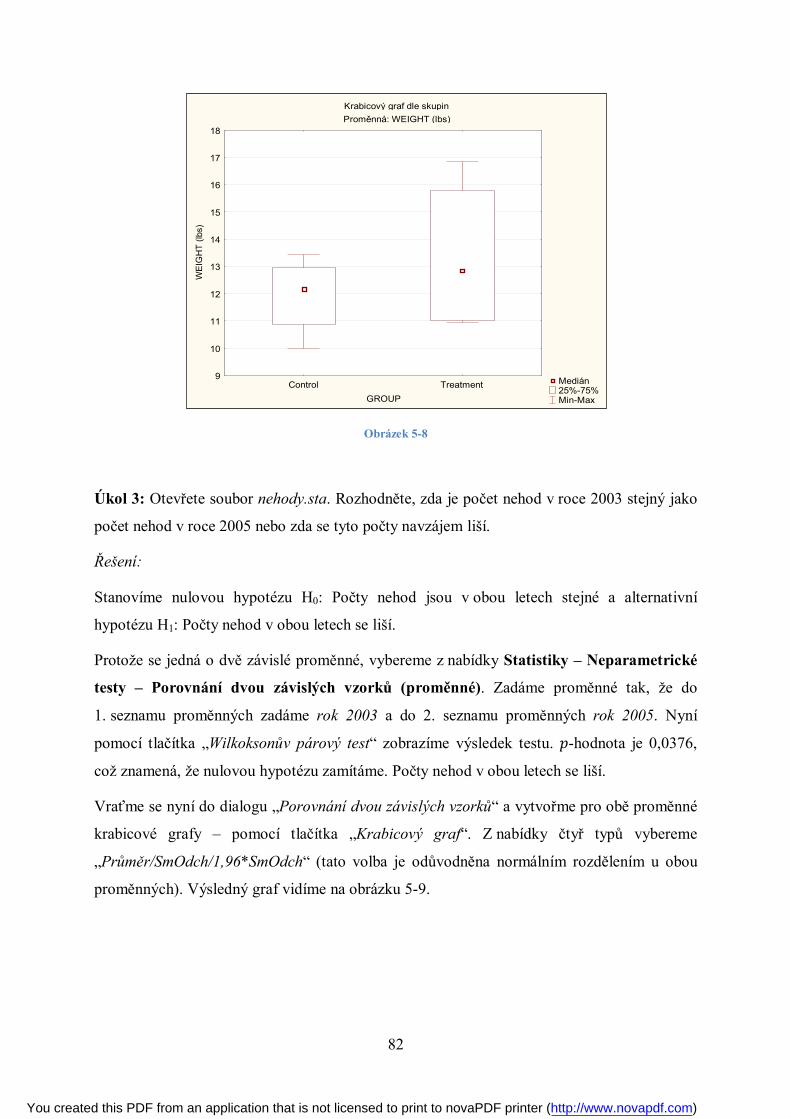
Page 1
VYSOKÁ ŠKOLA POLYTECHNICKÁ JIHLAVA
STATISTICA ÚVOD DO ZPRACOVÁNÍ DAT
Jana Borůvková, Petra Horáčková, Miroslav Hanáček
2013
Katedra matematiky
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 2
Jana Borůvková, Petra Horáčková, Miroslav Hanáček STATISTICA – ÚVOD DO ZPRACOVÁNÍ DAT
1. vydáníISBN 978-80-87035-79-5
Vydala Vysoká škola polytechnická Jihlava, Tolstého 16, Jihlava, 2013 Tisk Ediční oddělení VŠPJ, Tolstého 16, Jihlava Za jazykovou a věcnou správnost obsahu díla odpovídá autor. Text neprošel jazykovou ani redakční úpravou.
© Jana Borůvková, Petra Horáčková, Miroslav Hanáček, 2013
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 3
Vážení čtenáři,
dostává se vám do ruky studijní text primárně určený studentům katedry zdravotnických
studií, jehož obsahem je popis základních statistických metod a jejich aplikace s využitím
statistického softwaru STATISTICA. V této oblasti se jedná o poměrně ojedinělý autorský
počin, který umožňuje seznámit se v českém jazyce se základním využitím programu
STATISTICA pro zpracování statistických dat.
Text je rozdělen do tří stejně strukturovaných částí. V první, teoretické, části lze nalézt
stručný popis základních statistických metod a způsob jejich využití při analýze dat. Na tuto
část navazují Řešené příklady softwarem STATISTICA, ve které naleznete podrobný popis
postupu při zpracování dat včetně interpretací výsledků spočítaných tímto softwarem. Studijní
text je završen krátkou sbírkou úkolů a příkladů určených k samostatnému řešení, aby bylo
čtenáři umožněno ověřit si, že studovanou problematiku pochopil a umí ji v praxi aplikovat.
Jak již bylo řečeno, všechny tři části obsahují shodná témata. Jedná se o popisnou statistiku
(třídění dat a výpočet příslušných charakteristik), grafickou prezentaci dat, korelační analýzu,
regresní analýzu a testování hypotéz (t-testy, neparametrické testy a chí-kvadrát test
o nezávislosti).
Tento studijní text pokrývá jednosemestrovou výuku statistiky s hodinovou dotací 0/1, takže
si v žádném případě neklade za cíl úplný a vyčerpávající popis studované tématiky ani do
hloubky ani do šířky. Cílem autorů bylo vytvořit studijní text, který bude prvním průvodcem
studentům i vyučujícím VŠPJ v případě, že se rozhodnou zpracovat svá data získaná pro
seminární práce, bakalářské práce nebo odborné články s využitím softwaru STATISTICA,
který je na VŠPJ dostupný jak studentům, tak i vyučujícím.
kolektiv autorů
Jihlava, březen 2013
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 4
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 5
5
Obsah
Teoretická část
1 Popisná statistika 8
1.1 Základní statistické pojmy ........................................................................................8
1.2 Typy dat ...................................................................................................................8
1.3 Základní zpracování statistických údajů ....................................................................9
1.4 Charakteristiky polohy (úrovně) ............................................................................. 12
1.5 Charakteristiky variability ...................................................................................... 14
1.6 Charakteristiky šikmosti a špičatosti ....................................................................... 15
2 Grafická prezentace dat 15
2.1 Grafické znázornění dat tříděných bodovým tříděním ............................................. 16
2.2 Grafické znázornění dat tříděných intervalovým tříděním ....................................... 18
2.3 Grafické znázornění závislosti dvou proměnných – bodový graf ............................. 21
2.4 Grafické znázornění časové řady – spojnicový graf ................................................ 23
3 Korelační analýza 24
4 Regresní analýza 28
5 Testování hypotéz 29
5.1 Postup při testování hypotéz ................................................................................... 29
5.2 Chyba I. a II. druhu ................................................................................................ 31
5.3 Rozdělení statistických testů ................................................................................... 31
5.4 Kontingenční tabulky ............................................................................................. 33
5.5 Neparametrické testy .............................................................................................. 34
5.6 T-testy .................................................................................................................... 36
Řešené příklady softwarem Statistica
1 Sběr dat a jejich příprava pro import do softwaru Statistica 41
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 6
6
1.1 Import dat do softwaru Statistica ............................................................................ 43
1.2 Kontrola dat, práce s proměnnými .......................................................................... 46
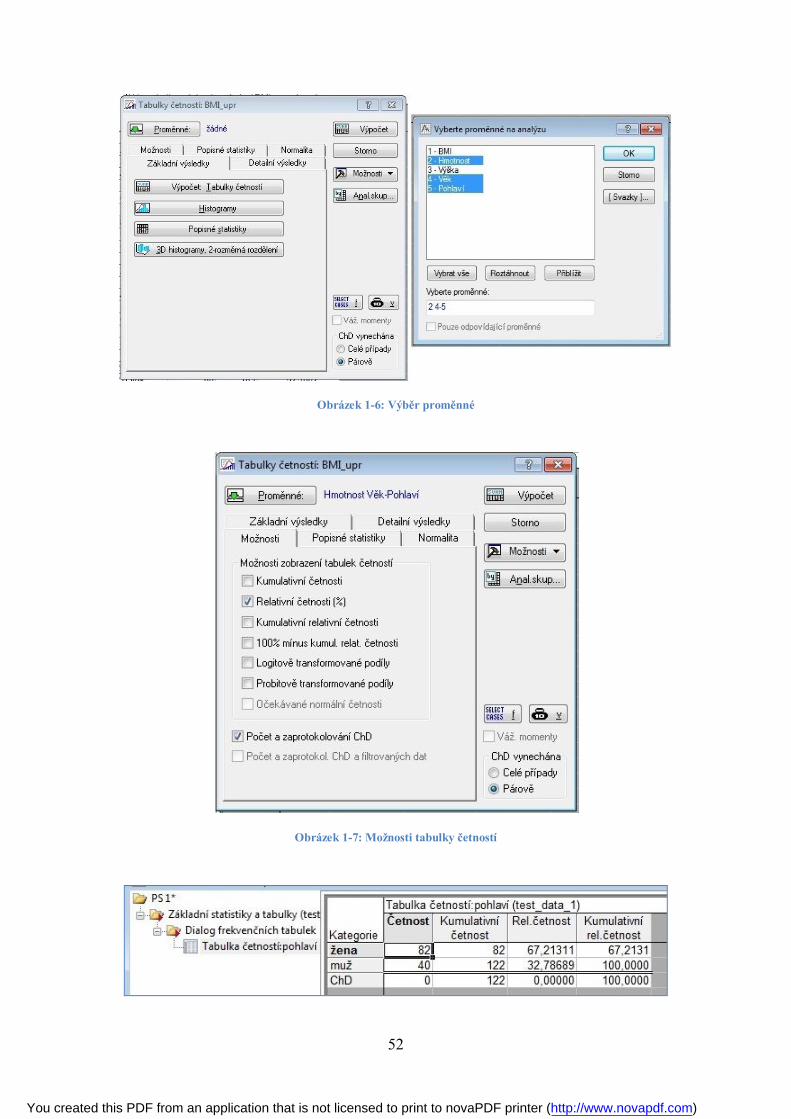
1.3 Tabulky četností ..................................................................................................... 49
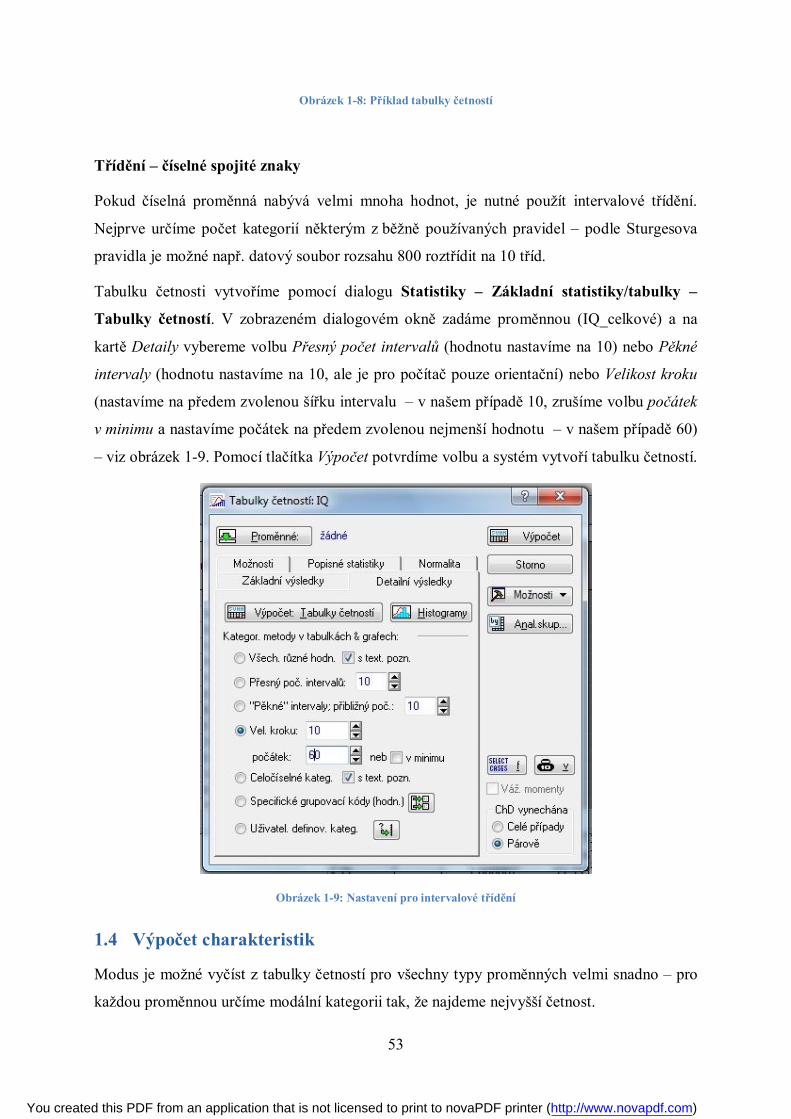
1.4 Výpočet charakteristik ............................................................................................ 53
2 Grafická prezentace dat 54
2.1 Grafická prezentace kategoriálních dat ................................................................... 54
2.2 Filtr, kategorizované grafy ...................................................................................... 56
2.3 Spojitá proměnná.................................................................................................... 60
2.4 Závislost proměnných – bodový graf ...................................................................... 62
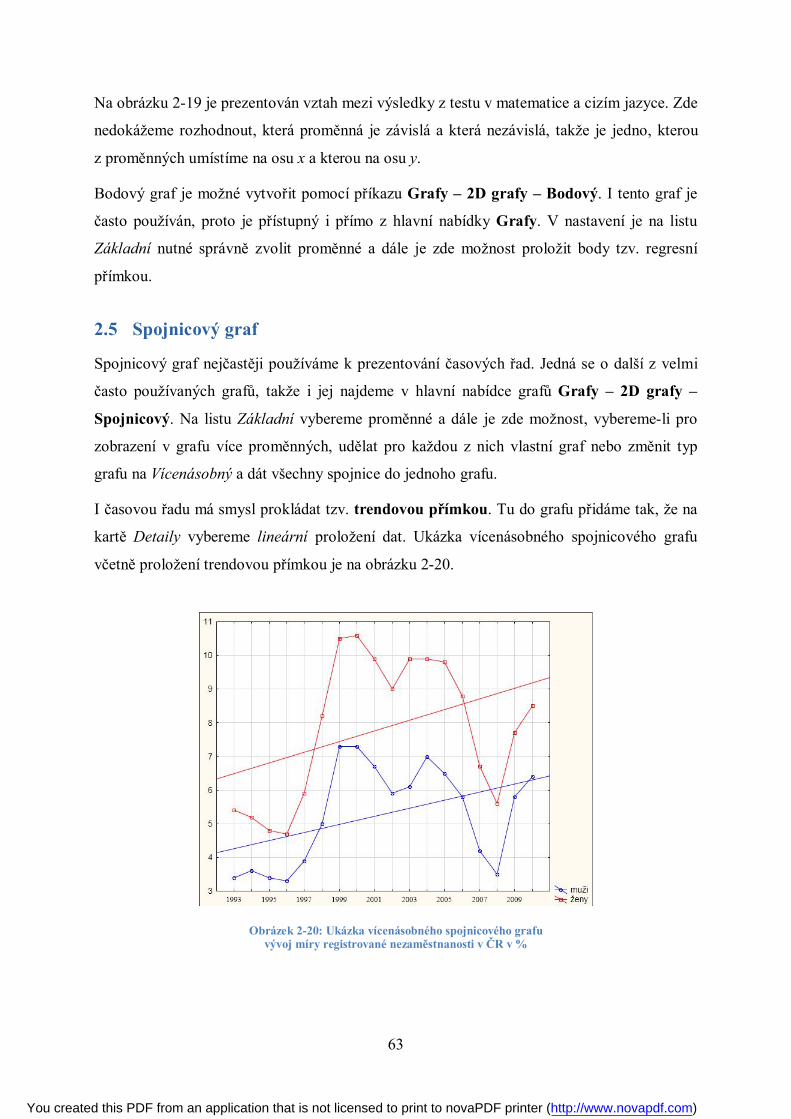
2.5 Spojnicový graf ...................................................................................................... 63
3 Korelační analýza 64
3.1 Pearsonova korelační analýza ................................................................................. 64
3.2 Pořadová korelace .................................................................................................. 68
4 Lineární regrese 70
4.1 Jedna nezávislá proměnná ...................................................................................... 70
4.2 Více nezávislých proměnných ................................................................................ 75
5 Testování hypotéz 77
5.1 Kontingenční tabulky ............................................................................................. 77
5.2 Neparametrické testy .............................................................................................. 80
5.3 T-testy .................................................................................................................... 84
Příklady k procvičení
1 Popisná statistika 88
2 Grafické zpracování dat 93
3 Korelační analýza 95
4 Regresní analýza 96
5 Neparametrické testy 98
6 Parametrické testy 100
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 7
7
Teoretická část
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 8
8
1 Popisná statistika
Se statistickým zpracováním dat se setkáváme už od starověku. Tehdy se jednalo o soupisy
obyvatel, nejčastěji pro daňové účely. V dnešní době už neexistuje vědní obor, ve kterém by
se nepracovalo s hromadnými daty a k jejich vyhodnocení by se nevyužilo statistických
metod. Údajů, které získáváme je často mnoho, proto je musíme zpracovat, zpřehlednit.
Pokud takto učiníme např. pomocí tabulek rozdělení četností, grafickou vizualizací dat nebo
pomocí některých charakteristik popisné statistiky (průměr, střední hodnoty, extrémní
hodnoty,…) jsme na začátku statistického zpracování dat, protože zatím jde jen o prvotní
popis resp. o přiblížení se podstatě věci. V dnešní době bychom se také těžko obešli bez
zpracování dat pomocí některého statistického softwaru, jako je např. Statistica, SPSS,
případně statistických funkcí v běžném MS Excel nebo OpenOffice.
1.1 Základní statistické pojmy
Většinou současně analyzujeme více objektů, událostí, procesů, skutečností. Ty sami o sobě
ještě netvoří statistiku. Statistika se tedy zabývá zpracováním a zkoumáním hromadných
jevů. Množina zkoumaných objektů se ve statistice nazývá statistický soubor. Počet prvků
této množiny nazýváme rozsah souboru a značíme ho 푛. Základní prvky statistického
pozorování se nazývají statistické jednotky. Celý statistický soubor se nazývá populace
nebo základní soubor. Pokud z populace vybereme podle předem stanovených pravidel
množinu statistických jednotek, nazýváme ji výběrový soubor nebo vzorek. Je to část
základního souboru, kterou zkoumáme a pokud jsme data získali v souladu s teorií
pravděpodobnosti, můžeme získané výsledky zobecnit na celou populaci.
Statistické jednotky mají řadu různých vlastností, které potom dál analyzujeme. Nazýváme je
proměnné (případy, statistické znaky). Hodnoty, které proměnná nabývá, nazýváme
obměna statistického znaku.
1.2 Typy dat
Z hlediska základního zpracování dat dělíme proměnné na dva základní typy:
1. kategoriální, 2. spojité.
Kategoriální proměnné dále dělíme na:
a. nominální (vždy slovní),
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 9
9
b. ordinální slovní, c. ordinální číselné.
Kategoriální proměnné jsou ty, u kterých je počet obměn statistického znaku „rozumný“.
Nelze přesně říci, co ještě považujeme za rozumný počet, protože to závisí i na rozsahu
souboru. Zpravidla budeme počet obměn považovat za rozumný, bude-li menší než 10. Ale
máme-li soubor velkého rozsahu (několik tisíc statistických jednotek), může být za rozumný
počet obměn považováno i 20 či 25 obměn statistického znaku.
Nominální proměnné jsou vždy slovní. Je pro ně typické to, že obměny této proměnné
nemají žádné přirozené pořadí. Příkladem může být používaný dopravní prostředek pro cestu
do školy/práce. Pořadí, v jakém vyjmenováváme obměny statistického znaku, se řídí jejich
významností, tedy četností, s jakou se v datech vyskytují.
Ordinální proměnné mohou být jak slovní, tak i číselné. Obměny statistického znaku mají
vždy přirozené pořadí, které je nutné respektovat. Například nejvyšší dosažené vzdělání je
smysluplné uvádět v pořadí: základní, středoškolské bez maturity, středoškolské s maturitou,
bakalářské, magisterské a doktorské.
Spojité proměnné jsou vždy číselné a vykazují se vysokým počtem obměn statistického
znaku. Počet obměn je tak vysoký, že jejich vyjmenování nepřináší již lépe vypovídající
pohled na data, jak je tomu v případě kategoriální proměnné. Proto u této proměnné nestačí
obměny vyjmenovat, ale je nutné je seskupit do intervalů a nadále prezentovat jako intervaly,
případně jako středy těchto intervalů.
1.3 Základní zpracování statistických údajů
Výsledkem statistického šetření je zpravidla databáze s mnoha řádky a sloupci a ani zkušený
pracovník z nich mnoho nevyčte. Informace musíme zpřehlednit, abychom jednoduše viděli,
jakých hodnot daná proměnná nabývá a kolikrát se obměny vyskytují, tzv. četnosti. Tuto
činnost nazýváme třídění dat a pro každou proměnnou vytvoříme tabulku rozdělení
četností (frekvenční tabulku).
1.3.1 Bodové třídění
Bodové třídění používáme pro kategoriální proměnné (nominální a ordinální) s „rozumným“
počtem obměn (zpravidla do 10, ale pro soubory s velkým rozsahem třeba i 15 nebo 20).
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 10
10
Takto můžeme třídit počet narozených dětí, známky ve škole, pohlaví, kraje, míru souhlasu
s výrokem vyjádřenou např. na škále 1–7,…
Tabulka rozdělení četností obsahuje:
pořadové číslo obměny (nemusí být uvedeno) 푖, hodnotu znaku 푥 , absolutní četnost 푛 , relativní četnost 푝 , můžeme uvádět v % (100푝 %), kumulativní relativní četnost 푘푝 , můžeme uvádět v % (100푘푝 %).
Kumulativní relativní četnost u nominálních dat nemá smysl (neexistuje přirozené pořadí dat).
Pro absolutní četnost platí (푛 je rozsah souboru)
푛 = 푛.
Pro relativní četnost platí
푝 = 푛푛 .
Pro kumulativní relativní četnost platí
푘푝 = 푝 .
Ukázka bodového třídění nominálního (tedy slovního) znaku je v tabulce 1-1. Obměny jsou
seřazeny podle absolutní četnosti sestupně.
Tabulka1-1: Příklad tabulky rozdělení četností pro nominální znak
푥 푛 푝
Jihlava 11578 0,236
Havl. Brod 10515 0,214
Žďár nad Sázavou 9489 0,193
Třebíč 8815 0,180
Pelhřimov 8711 0,178
Celkem 49108 1,000
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 11
11
V tabulce 1-2 je ukázka bodového třídění ordinálního znaku. Obměny jsou seřazeny podle
přirozeného pořadí.
Tabulka 1-2: Počet dětí v rodině, příklad tabulky rozdělení četností diskrétní kardinální proměnné
푥 푛 푝 푘푝
0 125 0,063 0,063
1 561 0,281 0,344
2 924 0,463 0,807
3 324 0,162 0,969
4 58 0,029 0,998
6 3 0,002 1,000
Celkem 1995 1,000 x
1.3.2 Intervalové třídění
Intervalové třídění používáme pro číselnou proměnnou, která má velké množství obměn,
takže by potom bodové třídění nemělo smysl. Hodnoty znaků sdružujeme do intervalů, které
mají obvykle (pro jednoduchost) stejnou šířku, značíme ji ℎ. Hledaný počet intervalů
zpravidla závisí na počtu pozorování a můžeme ho vyjádřit např. pomocí Sturgesova pravidla
푘 = 1 + 3,3 log푛,
kde 푘 je počet intervalů a 푛 rozsah souboru.
Intervaly volíme tak, aby se nepřekrývaly a těsně na sebe navazovaly. Pro odlehlé hodnoty
nevytváříme samostatný interval, ale zahrneme je do prvního nebo posledního intervalu.
Tabulka rozdělení četností obsahuje:
pořadové číslo obměny (nemusí být uvedeno), značíme 푖,
intervaly,
středy intervalů 푥 ,
absolutní četnost 푛 ,
relativní četnost 푝 , můžeme uvádět v procentech (100푝 %),
kumulativní relativní četnost 푘푝 , můžeme uvádět v procentech (100푘푝 %).
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 12
12
Vzorce pro absolutní četnost, relativní četnost a kumulativní relativní četnost jsou stejné jako
u bodového třídění.
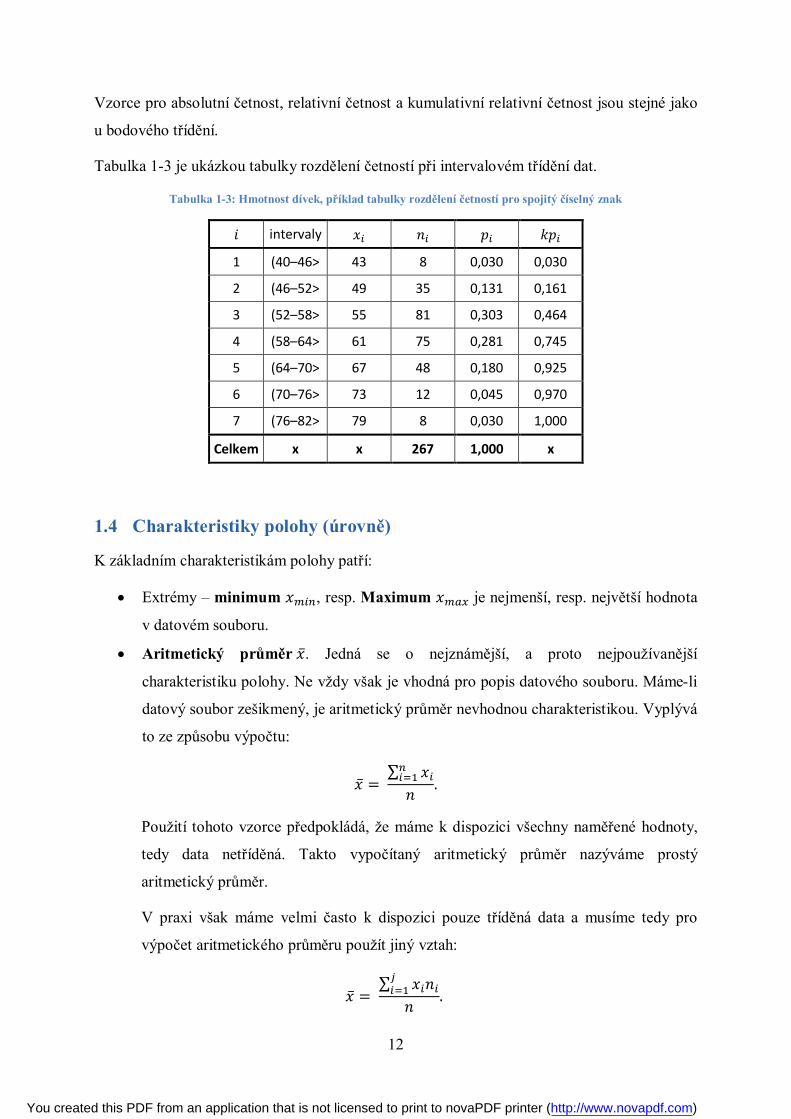
Tabulka 1-3 je ukázkou tabulky rozdělení četností při intervalovém třídění dat.
Tabulka 1-3: Hmotnost dívek, příklad tabulky rozdělení četností pro spojitý číselný znak
푖 intervaly 푥 푛 푝 푘푝
1 (40–46> 43 8 0,030 0,030
2 (46–52> 49 35 0,131 0,161
3 (52–58> 55 81 0,303 0,464
4 (58–64> 61 75 0,281 0,745
5 (64–70> 67 48 0,180 0,925
6 (70–76> 73 12 0,045 0,970
7 (76–82> 79 8 0,030 1,000
Celkem x x 267 1,000 x
1.4 Charakteristiky polohy (úrovně)
K základním charakteristikám polohy patří:
Extrémy – minimum 푥 , resp. Maximum 푥 je nejmenší, resp. největší hodnota
v datovém souboru.
Aritmetický průměr 푥̅. Jedná se o nejznámější, a proto nejpoužívanější
charakteristiku polohy. Ne vždy však je vhodná pro popis datového souboru. Máme-li
datový soubor zešikmený, je aritmetický průměr nevhodnou charakteristikou. Vyplývá
to ze způsobu výpočtu:
푥̅ = ∑ 푥푛 .
Použití tohoto vzorce předpokládá, že máme k dispozici všechny naměřené hodnoty,
tedy data netříděná. Takto vypočítaný aritmetický průměr nazýváme prostý
aritmetický průměr.
V praxi však máme velmi často k dispozici pouze tříděná data a musíme tedy pro
výpočet aritmetického průměru použít jiný vztah:
푥̅ = ∑ 푥 푛
푛 .
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 13
13
Takto vypočítaný aritmetický průměr nazýváme vážený aritmetický průměr.
Máme-li data tříděná bodovým tříděním, vychází prostý aritmetický průměr i vážený
aritmetický průměr stejně. V případě intervalového třídění jsou data charakterizovaná
pouze středem intervalu, tříděním dochází ke ztrátě původních hodnot, a proto i prostý
aritmetický průměr z původních dat se zpravidla nepatrně liší od váženého
aritmetického průměru.
Medián 푥. Střední hodnota. Pokud datový soubor není symetrický nebo obsahuje
odlehlou hodnotu, je lepší charakteristikou než aritmetický průměr. Medián dělí
soubor na dvě poloviny.
Při lichém počtu hodnot n je medián prostřední hodnota seřazených dat푥( )
푥 = 푥 ,
při sudém počtu hodnot 푛 je medián průměr dvou prostředních hodnot seřazených dat
푥( )
푥 = 푥 + 푥
2 .
Dolní kvartil 푥 , , horní kvartil 푥 , . Dolní kvartil udává hodnotu 25 % nejnižších
hodnot, horní kvartil 75 % nejnižších hodnot.
Percentil (푝-kvantil) 푥 odděluje 푝 % nejnižších hodnot souboru.
Modus 푥. Nejčetnější hodnota. Problém této charakteristiky je, že při intervalovém
třídění se může velmi lišit od hodnoty určené z původních dat. Některé soubory
mohou mít i více modů.
Pro číselné proměnné můžeme počítat všechny výše vyjmenované charakteristiky polohy. Pro
ordinální slovní znaky lze určit pouze modus a kvantily (zejména medián, případně kvartily).
Občas však interpretace trochu „pokulhává“ (např. prostřední hodnotou nejvyššího vzdělání
u zkoumaného vzorku může být něco mezi ZŠ a SŠ).
U nominálních proměnných má smysl určit pouze modus.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 14
14
1.5 Charakteristiky variability
Často se setkáváme se situací, že dva nebo více souborů bude mít stejné charakteristiky
polohy (průměr, medián,…), ale jinak se budou od sebe výrazně lišit. Proto je potřeba
charakteristiky polohy doplnit charakteristikami variability.
Základní charakteristiky variability:
Variační rozpětí 푅. Uvádí škálu (šířku intervalu), ve které se pohybují všechny
hodnoty souboru, tzn. rozdíl největší a nejmenší hodnoty znaku. Jeho předností je
snadnost a rychlost výpočtu, nevýhodou je, pokud v souboru máme odlehlé hodnoty,
jeho malá vypovídací schopnost.
푅 =푥 −푥 .
Mezikvartilové rozpětí 푄. Rozdíl mezi horním a dolním kvartilem. Udává, jak je
široký interval, ve kterém je 50% prostředních hodnot. Tato míra variability už není
ovlivněná extrémními hodnotami proměnné, takže vypovídací schopnost je vyšší než
u rozpětí.
푄 = 푥 , −푥 , .
Rozptyl 푠 . Nejčastější charakteristika variability, která se počítá jako průměrná
kvadratická odchylka od průměru. Rozptyl má interpretační nevýhodu, že není ve
stejných jednotkách jako původní hodnoty.
푠 = ∑ (푥 −푥̅)
푛 − 1 = ∑ 푥 − 푛푥̅
푛 − 1 .
Směrodatná odchylka 푠. Odmocnina rozptylu, která má stejnou vypovídací
schopnost jako rozptyl a je ve stejných jednotkách jako původní data.
푠 = 푠 .
Variační koeficient 푣. Směrodatná odchylka a rozptyl jsou vhodné k porovnání
variability souborů, které mají stejné průměry. Pokud se průměry porovnávaných
souborů liší je potřeba spočítat variační koeficient, který je většinou uváděn
v procentech.
푣 = 푠푥̅
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 15
15
1.6 Charakteristiky šikmosti a špičatosti
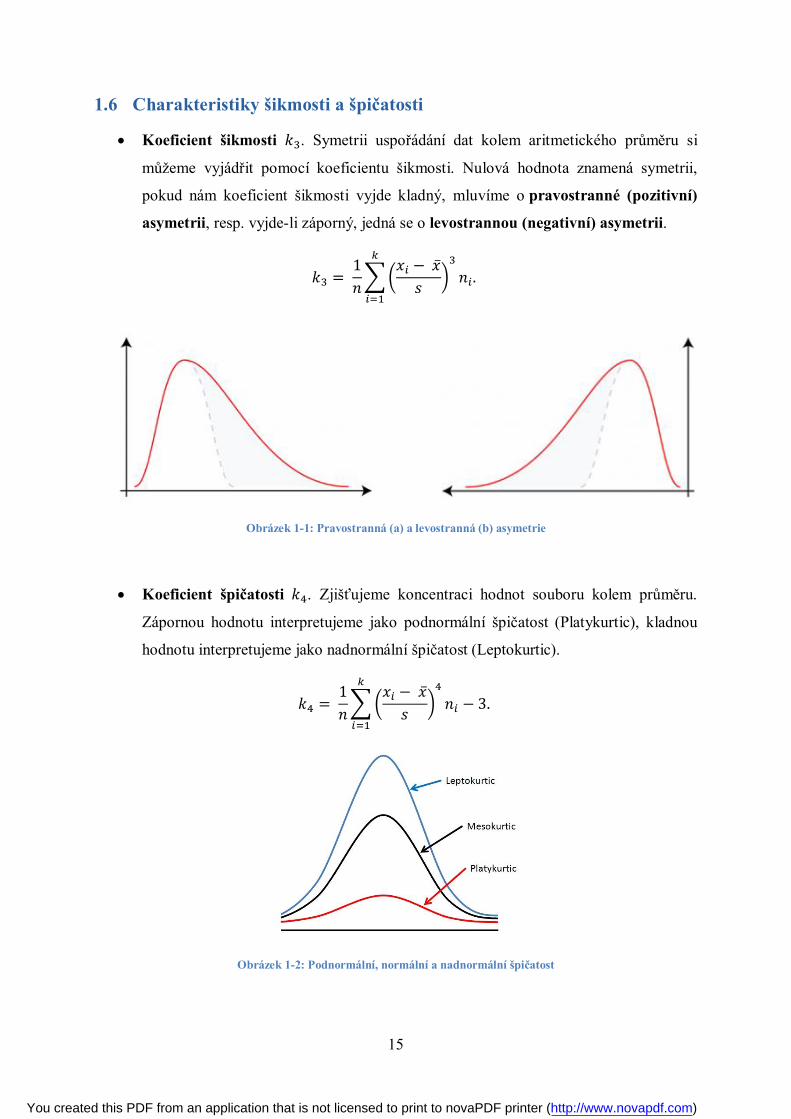
Koeficient šikmosti 푘 . Symetrii uspořádání dat kolem aritmetického průměru si
můžeme vyjádřit pomocí koeficientu šikmosti. Nulová hodnota znamená symetrii,
pokud nám koeficient šikmosti vyjde kladný, mluvíme o pravostranné (pozitivní)
asymetrii, resp. vyjde-li záporný, jedná se o levostrannou (negativní) asymetrii.
푘 = 1푛
푥 −푥̅푠 푛 .
Obrázek 1-1: Pravostranná (a) a levostranná (b) asymetrie
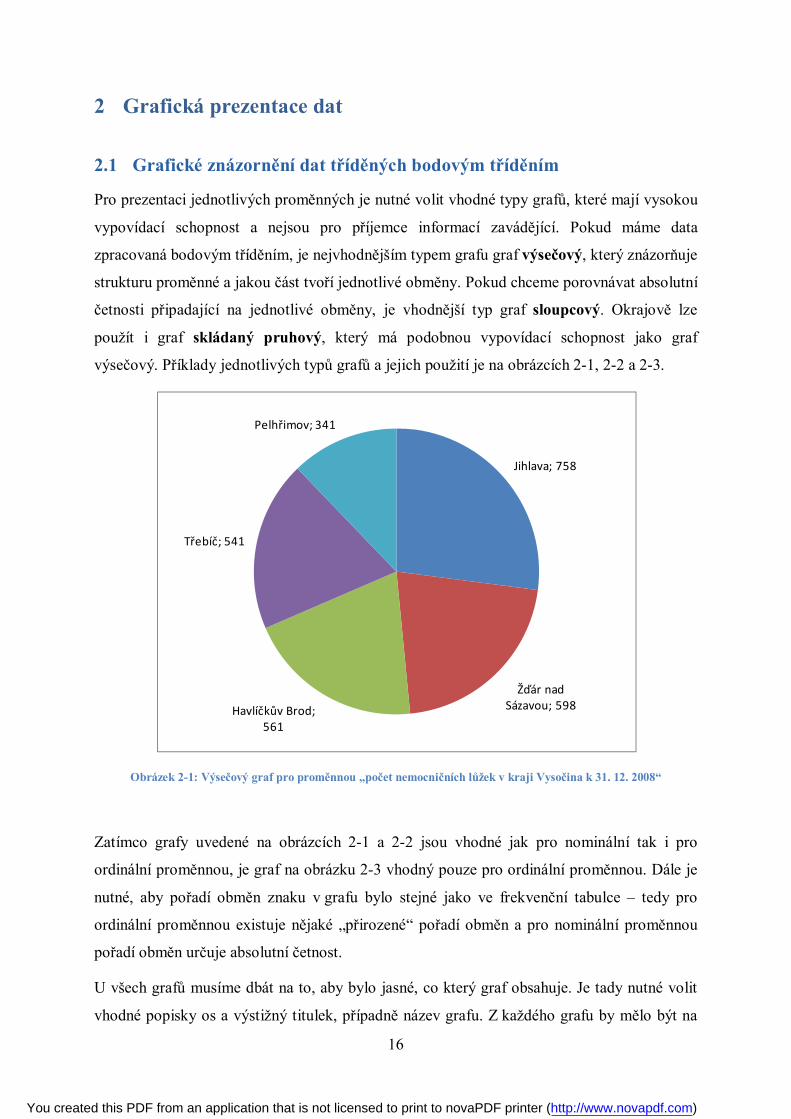
Koeficient špičatosti 푘 . Zjišťujeme koncentraci hodnot souboru kolem průměru.
Zápornou hodnotu interpretujeme jako podnormální špičatost (Platykurtic), kladnou
hodnotu interpretujeme jako nadnormální špičatost (Leptokurtic).
푘 = 1푛
푥 − 푥̅푠 푛 − 3.
Obrázek 1-2: Podnormální, normální a nadnormální špičatost
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 16
16
2 Grafická prezentace dat
2.1 Grafické znázornění dat tříděných bodovým tříděním
Pro prezentaci jednotlivých proměnných je nutné volit vhodné typy grafů, které mají vysokou
vypovídací schopnost a nejsou pro příjemce informací zavádějící. Pokud máme data
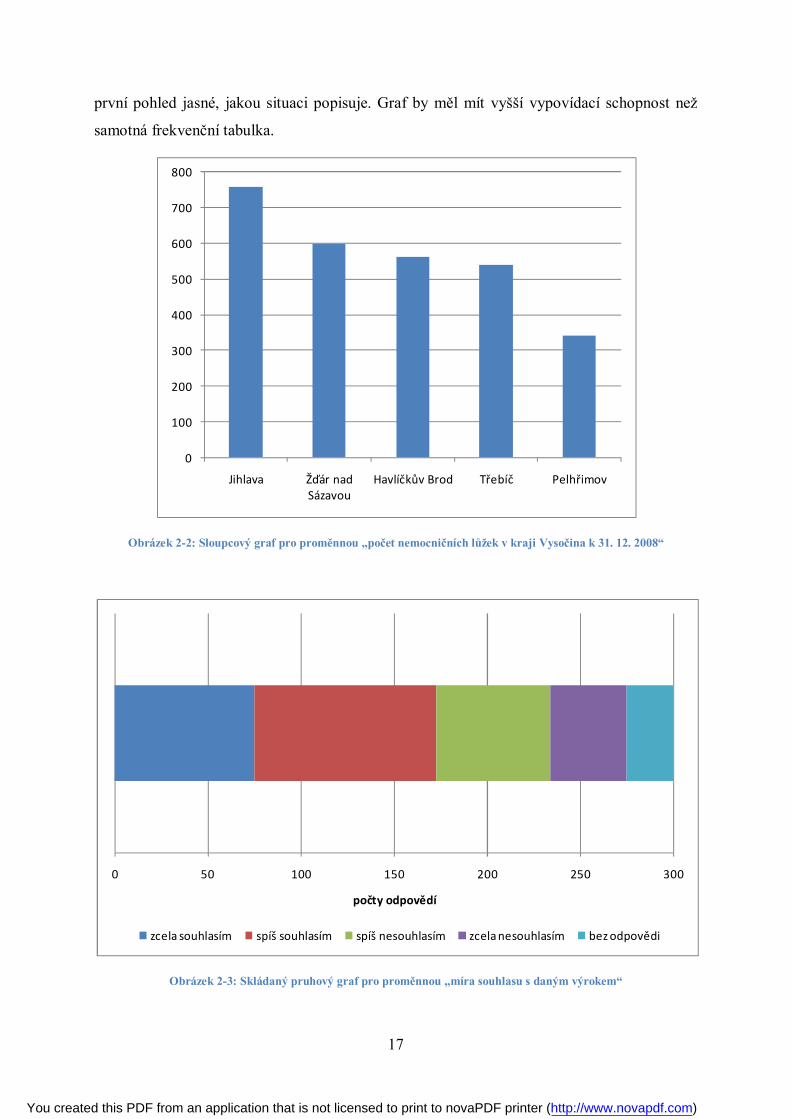
zpracovaná bodovým tříděním, je nejvhodnějším typem grafu graf výsečový, který znázorňuje
strukturu proměnné a jakou část tvoří jednotlivé obměny. Pokud chceme porovnávat absolutní
četnosti připadající na jednotlivé obměny, je vhodnější typ graf sloupcový. Okrajově lze
použít i graf skládaný pruhový, který má podobnou vypovídací schopnost jako graf
výsečový. Příklady jednotlivých typů grafů a jejich použití je na obrázcích 2-1, 2-2 a 2-3.
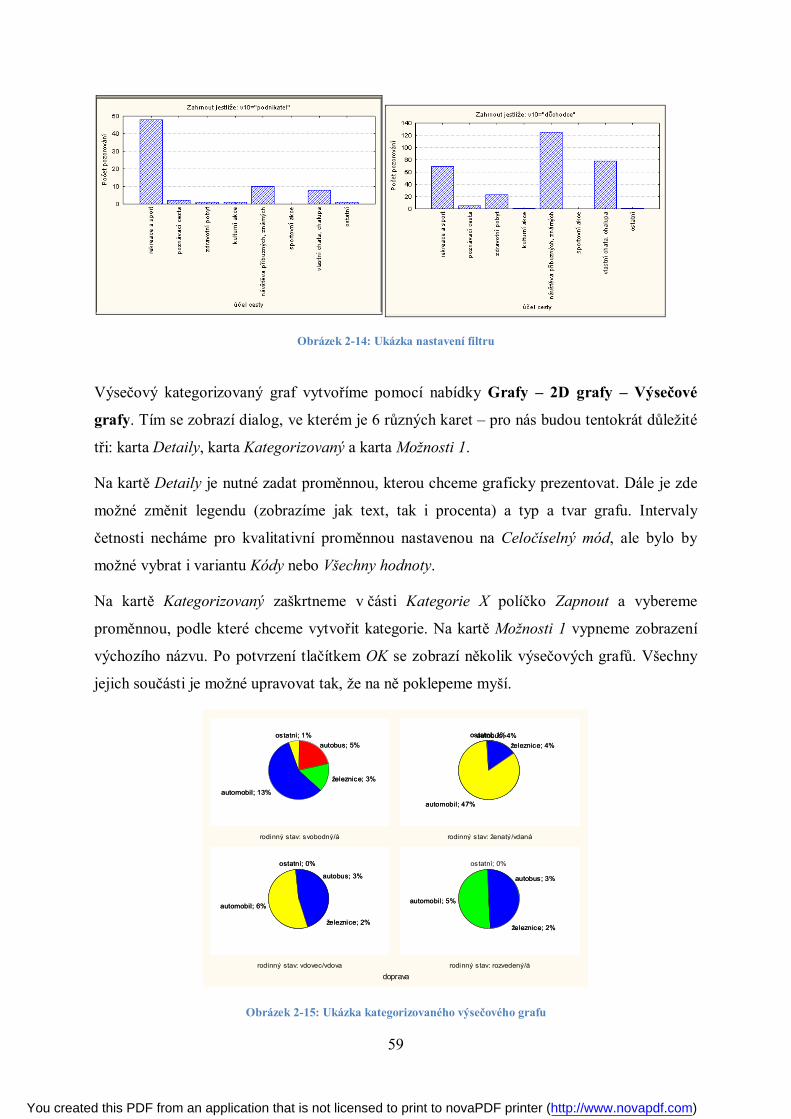
Obrázek 2-1: Výsečový graf pro proměnnou „počet nemocničních lůžek v kraji Vysočina k 31. 12. 2008“
Zatímco grafy uvedené na obrázcích 2-1 a 2-2 jsou vhodné jak pro nominální tak i pro
ordinální proměnnou, je graf na obrázku 2-3 vhodný pouze pro ordinální proměnnou. Dále je
nutné, aby pořadí obměn znaku v grafu bylo stejné jako ve frekvenční tabulce – tedy pro
ordinální proměnnou existuje nějaké „přirozené“ pořadí obměn a pro nominální proměnnou
pořadí obměn určuje absolutní četnost.
U všech grafů musíme dbát na to, aby bylo jasné, co který graf obsahuje. Je tady nutné volit
vhodné popisky os a výstižný titulek, případně název grafu. Z každého grafu by mělo být na
Jihlava; 758
Žďár nad Sázavou; 598Havlíčkův Brod;
561
Třebíč; 541
Pelhřimov; 341
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 17
17
první pohled jasné, jakou situaci popisuje. Graf by měl mít vyšší vypovídací schopnost než
samotná frekvenční tabulka.
Obrázek 2-2: Sloupcový graf pro proměnnou „počet nemocničních lůžek v kraji Vysočina k 31. 12. 2008“
Obrázek 2-3: Skládaný pruhový graf pro proměnnou „míra souhlasu s daným výrokem“
0
100
200
300
400
500
600
700
800
Jihlava Žďár nad Sázavou
Havlíčkův Brod Třebíč Pelhřimov
0 50 100 150 200 250 300
počty odpovědí
zcela souhlasím spíš souhlasím spíš nesouhlasím zcela nesouhlasím bez odpovědi
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 18
18
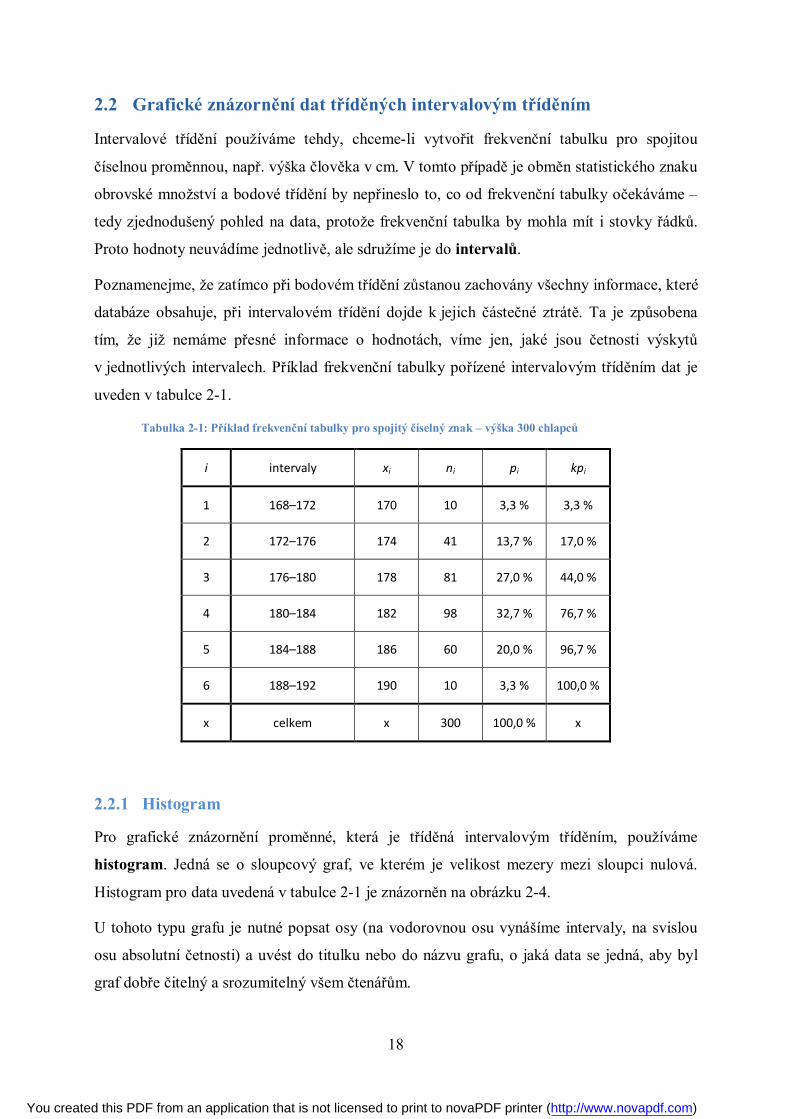
2.2 Grafické znázornění dat tříděných intervalovým tříděním
Intervalové třídění používáme tehdy, chceme-li vytvořit frekvenční tabulku pro spojitou
číselnou proměnnou, např. výška člověka v cm. V tomto případě je obměn statistického znaku
obrovské množství a bodové třídění by nepřineslo to, co od frekvenční tabulky očekáváme –
tedy zjednodušený pohled na data, protože frekvenční tabulka by mohla mít i stovky řádků.
Proto hodnoty neuvádíme jednotlivě, ale sdružíme je do intervalů.
Poznamenejme, že zatímco při bodovém třídění zůstanou zachovány všechny informace, které
databáze obsahuje, při intervalovém třídění dojde k jejich částečné ztrátě. Ta je způsobena
tím, že již nemáme přesné informace o hodnotách, víme jen, jaké jsou četnosti výskytů
v jednotlivých intervalech. Příklad frekvenční tabulky pořízené intervalovým tříděním dat je
uveden v tabulce 2-1.
Tabulka 2-1: Příklad frekvenční tabulky pro spojitý číselný znak – výška 300 chlapců
i intervaly xi ni pi kpi
1 168–172 170 10 3,3 % 3,3 %
2 172–176 174 41 13,7 % 17,0 %
3 176–180 178 81 27,0 % 44,0 %
4 180–184 182 98 32,7 % 76,7 %
5 184–188 186 60 20,0 % 96,7 %
6 188–192 190 10 3,3 % 100,0 %
x celkem x 300 100,0 % x
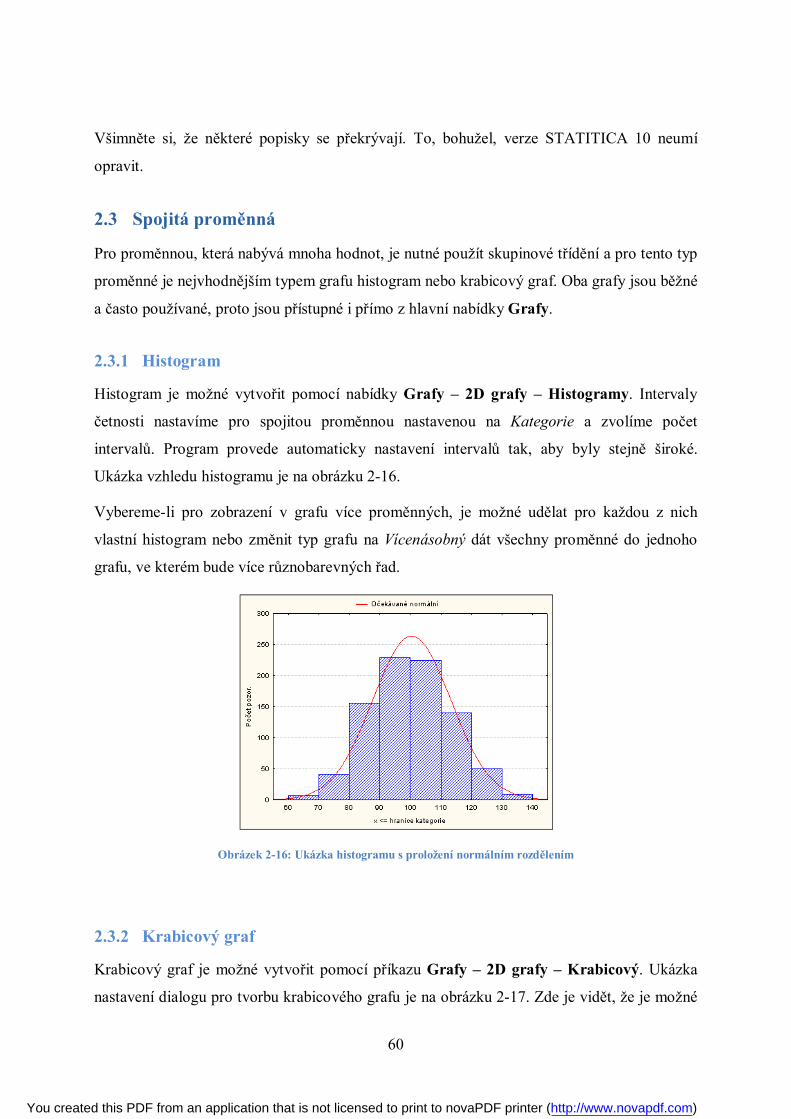
2.2.1 Histogram
Pro grafické znázornění proměnné, která je tříděná intervalovým tříděním, používáme
histogram. Jedná se o sloupcový graf, ve kterém je velikost mezery mezi sloupci nulová.
Histogram pro data uvedená v tabulce 2-1 je znázorněn na obrázku 2-4.
U tohoto typu grafu je nutné popsat osy (na vodorovnou osu vynášíme intervaly, na svislou
osu absolutní četnosti) a uvést do titulku nebo do názvu grafu, o jaká data se jedná, aby byl
graf dobře čitelný a srozumitelný všem čtenářům.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 19
19
Obrázek 2-4: Histogram – výška chlapců
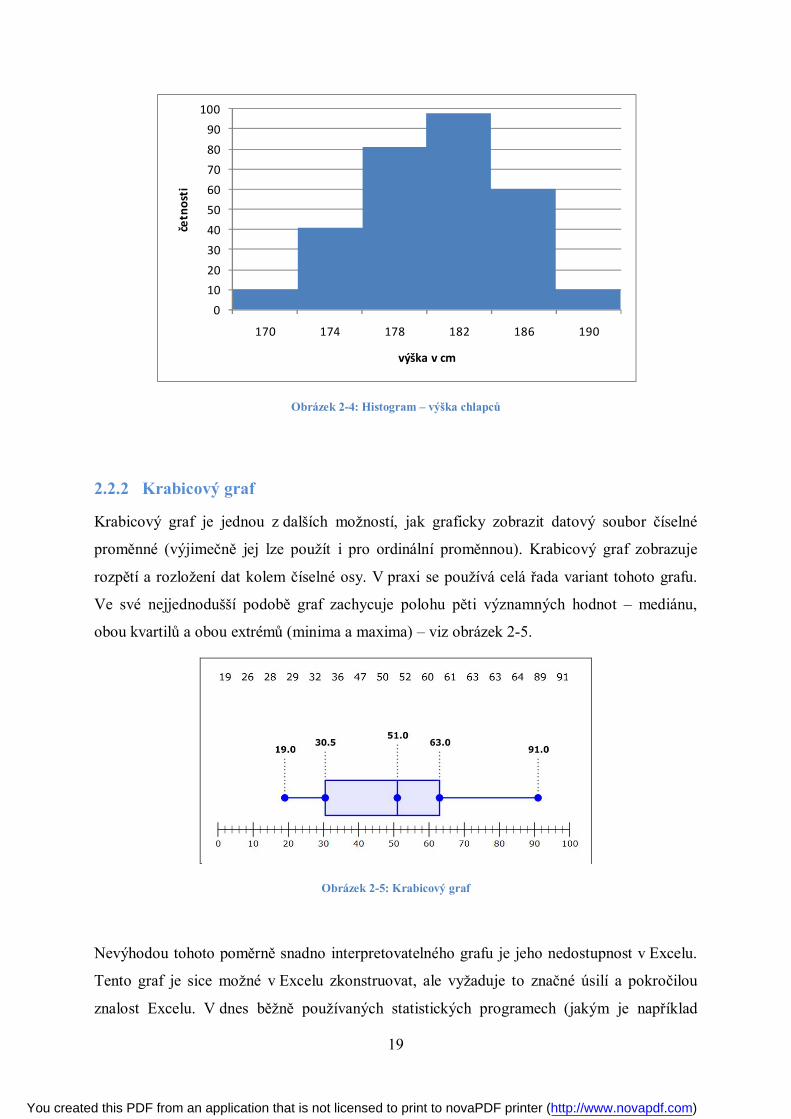
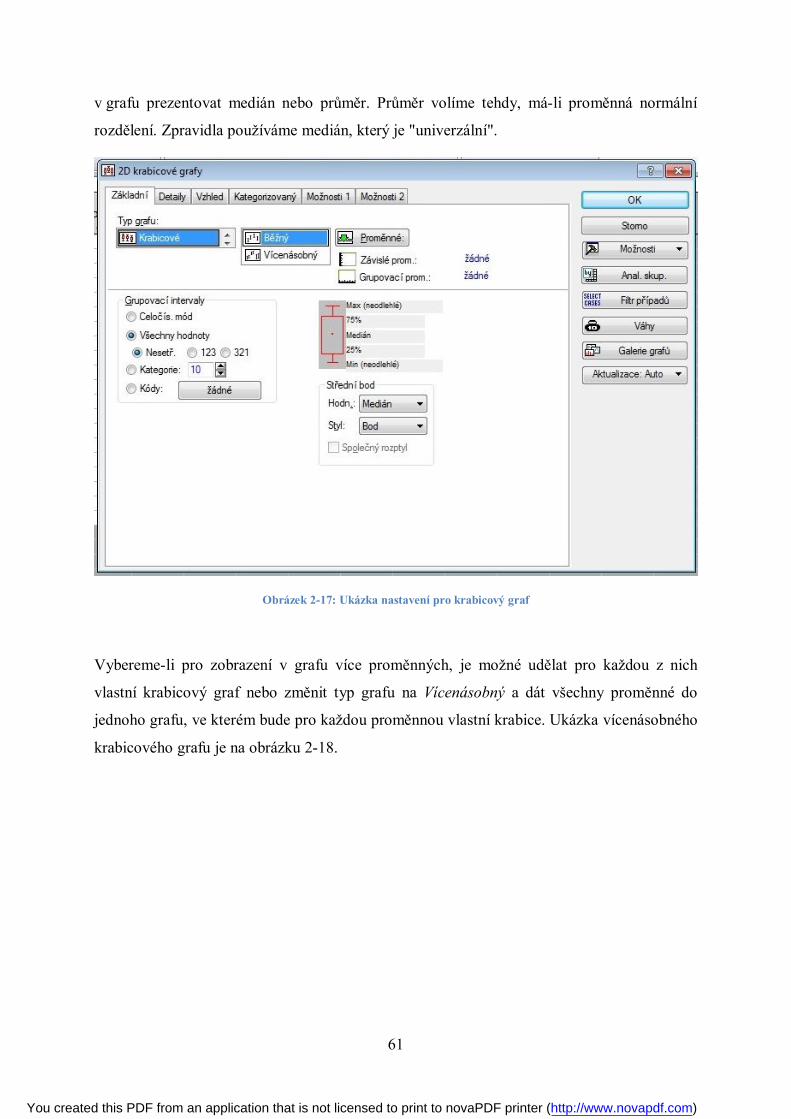
2.2.2 Krabicový graf
Krabicový graf je jednou z dalších možností, jak graficky zobrazit datový soubor číselné
proměnné (výjimečně jej lze použít i pro ordinální proměnnou). Krabicový graf zobrazuje
rozpětí a rozložení dat kolem číselné osy. V praxi se používá celá řada variant tohoto grafu.
Ve své nejjednodušší podobě graf zachycuje polohu pěti významných hodnot – mediánu,
obou kvartilů a obou extrémů (minima a maxima) – viz obrázek 2-5.
Obrázek 2-5: Krabicový graf
Nevýhodou tohoto poměrně snadno interpretovatelného grafu je jeho nedostupnost v Excelu.
Tento graf je sice možné v Excelu zkonstruovat, ale vyžaduje to značné úsilí a pokročilou
znalost Excelu. V dnes běžně používaných statistických programech (jakým je například
0102030405060708090
100
170 174 178 182 186 190
četn
osti
výška v cm
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 20
20
Statistica) však lze krabicové grafy konstruovat jednoduše. Tyto softwary dokážou též
detekovat tzv. odlehlé a extrémní hodnoty a v grafu je vyznačit.
V tom případě nevynášíme do grafu minimum a maximum, ale kromě mediánu a kvartilů
vynášíme tzv. horní a dolní vnitřní hradbu a horní a dolní vnější hradbu. Jejich poloha se
odvozuje od mezikvartilového rozpětí IQR:
horní vnější hradba x0,75 + 3IQR
horní vnitřní hradba x0,75 + 1,5IQR
horní kvartil x0,75
medián x0,5
dolní kvartil x0,25
dolní vnitřní hradba x0,25 – 1,5IQR
dolní vnější hradba x0,25 – 3IQR
Hodnoty, které leží mezi vnitřní a vnější hradbou (dolní nebo horní) se nazývají odlehlé
a zpravidla se vyznačují kroužkem, hodnoty ležící za vnějšími hradbami se nazývají extrémní
a vyznačují se hvězdičkou.
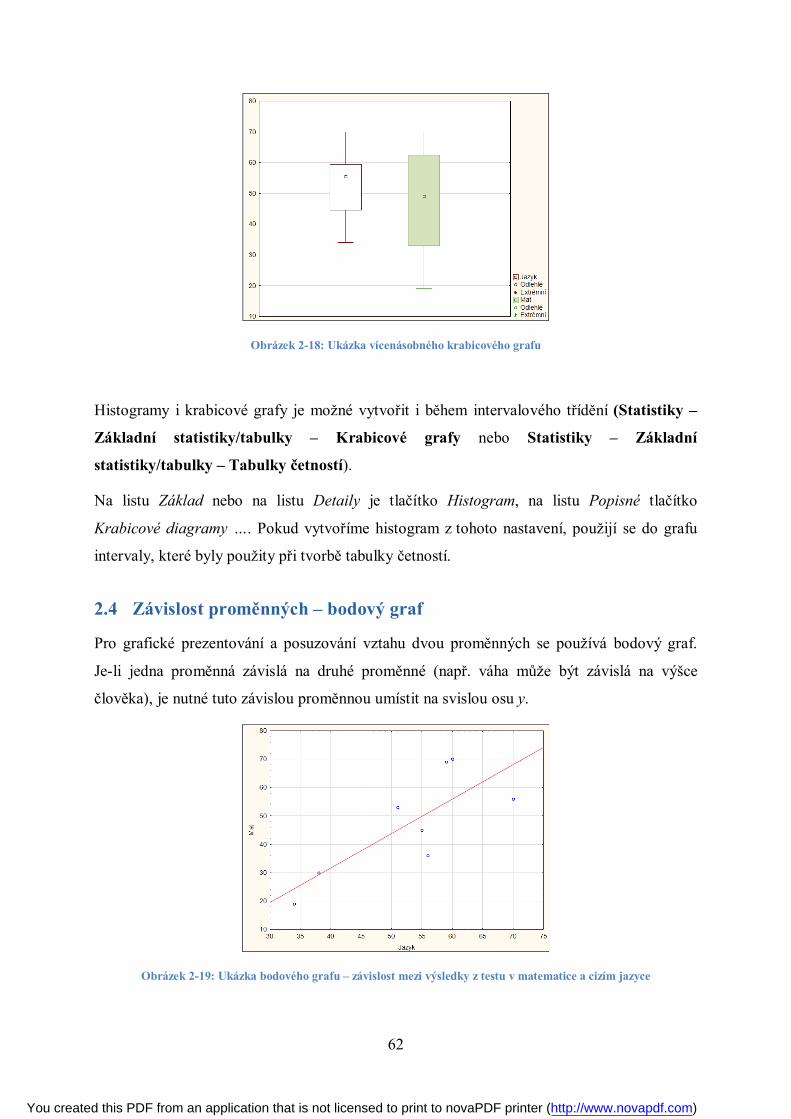
Příklad krabicového grafu je uveden na obrázku 2-6 Krabice vyznačuje oblast mezi kvartily
a vousy vnitřní hradby. V datech jsou 3 odlehlé hodnoty, extrémní hodnoty se v datovém
souboru nevyskytly.
Obrázek 2-6: Krabicový graf s odlehlými hodnotami
Pokud se data řídí normálním rozdělením, je možné do krabicových grafů použít místo
mediánu průměr a směrodatnou odchylku nebo směrodatnou chybu místo IQR.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 21
21
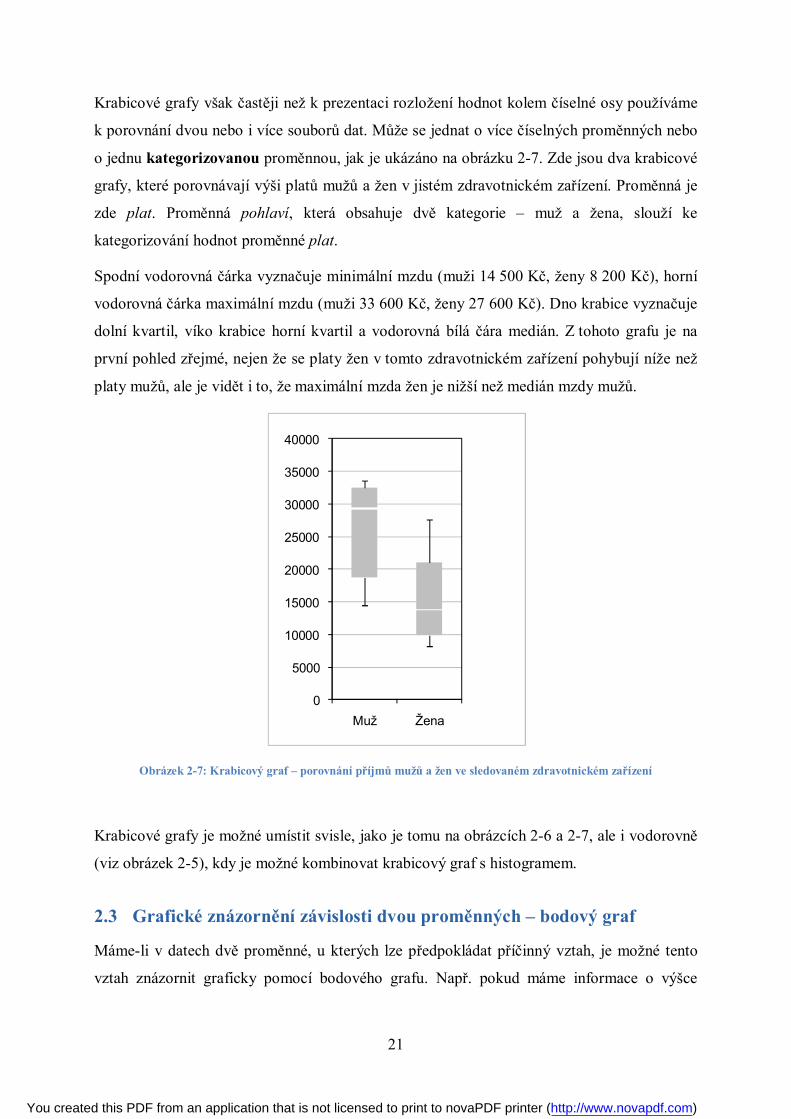
Krabicové grafy však častěji než k prezentaci rozložení hodnot kolem číselné osy používáme
k porovnání dvou nebo i více souborů dat. Může se jednat o více číselných proměnných nebo
o jednu kategorizovanou proměnnou, jak je ukázáno na obrázku 2-7. Zde jsou dva krabicové
grafy, které porovnávají výši platů mužů a žen v jistém zdravotnickém zařízení. Proměnná je
zde plat. Proměnná pohlaví, která obsahuje dvě kategorie – muž a žena, slouží ke
kategorizování hodnot proměnné plat.
Spodní vodorovná čárka vyznačuje minimální mzdu (muži 14 500 Kč, ženy 8 200 Kč), horní
vodorovná čárka maximální mzdu (muži 33 600 Kč, ženy 27 600 Kč). Dno krabice vyznačuje
dolní kvartil, víko krabice horní kvartil a vodorovná bílá čára medián. Z tohoto grafu je na
první pohled zřejmé, nejen že se platy žen v tomto zdravotnickém zařízení pohybují níže než
platy mužů, ale je vidět i to, že maximální mzda žen je nižší než medián mzdy mužů.
Obrázek 2-7: Krabicový graf – porovnání příjmů mužů a žen ve sledovaném zdravotnickém zařízení
Krabicové grafy je možné umístit svisle, jako je tomu na obrázcích 2-6 a 2-7, ale i vodorovně
(viz obrázek 2-5), kdy je možné kombinovat krabicový graf s histogramem.
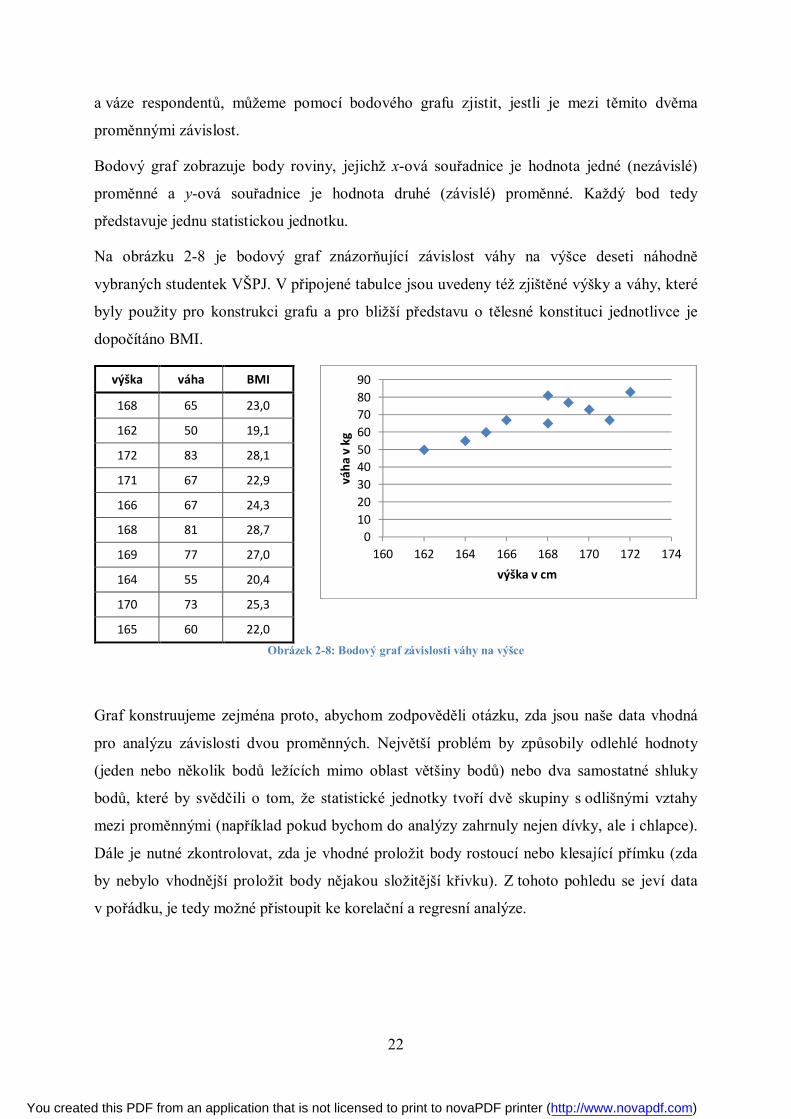
2.3 Grafické znázornění závislosti dvou proměnných – bodový graf
Máme-li v datech dvě proměnné, u kterých lze předpokládat příčinný vztah, je možné tento
vztah znázornit graficky pomocí bodového grafu. Např. pokud máme informace o výšce
0
5000
10000
15000
20000
25000
30000
35000
40000
Muž Žena
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 22
22
a váze respondentů, můžeme pomocí bodového grafu zjistit, jestli je mezi těmito dvěma
proměnnými závislost.
Bodový graf zobrazuje body roviny, jejichž x-ová souřadnice je hodnota jedné (nezávislé)
proměnné a y-ová souřadnice je hodnota druhé (závislé) proměnné. Každý bod tedy
představuje jednu statistickou jednotku.
Na obrázku 2-8 je bodový graf znázorňující závislost váhy na výšce deseti náhodně
vybraných studentek VŠPJ. V připojené tabulce jsou uvedeny též zjištěné výšky a váhy, které
byly použity pro konstrukci grafu a pro bližší představu o tělesné konstituci jednotlivce je
dopočítáno BMI.
výška váha BMI
168 65 23,0
162 50 19,1
172 83 28,1
171 67 22,9
166 67 24,3
168 81 28,7
169 77 27,0
164 55 20,4
170 73 25,3
165 60 22,0
Obrázek 2-8: Bodový graf závislosti váhy na výšce
Graf konstruujeme zejména proto, abychom zodpověděli otázku, zda jsou naše data vhodná
pro analýzu závislosti dvou proměnných. Největší problém by způsobily odlehlé hodnoty
(jeden nebo několik bodů ležících mimo oblast většiny bodů) nebo dva samostatné shluky
bodů, které by svědčili o tom, že statistické jednotky tvoří dvě skupiny s odlišnými vztahy
mezi proměnnými (například pokud bychom do analýzy zahrnuly nejen dívky, ale i chlapce).
Dále je nutné zkontrolovat, zda je vhodné proložit body rostoucí nebo klesající přímku (zda
by nebylo vhodnější proložit body nějakou složitější křivku). Z tohoto pohledu se jeví data
v pořádku, je tedy možné přistoupit ke korelační a regresní analýze.
0102030405060708090
160 162 164 166 168 170 172 174
váha
v k
g
výška v cm
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 23
23
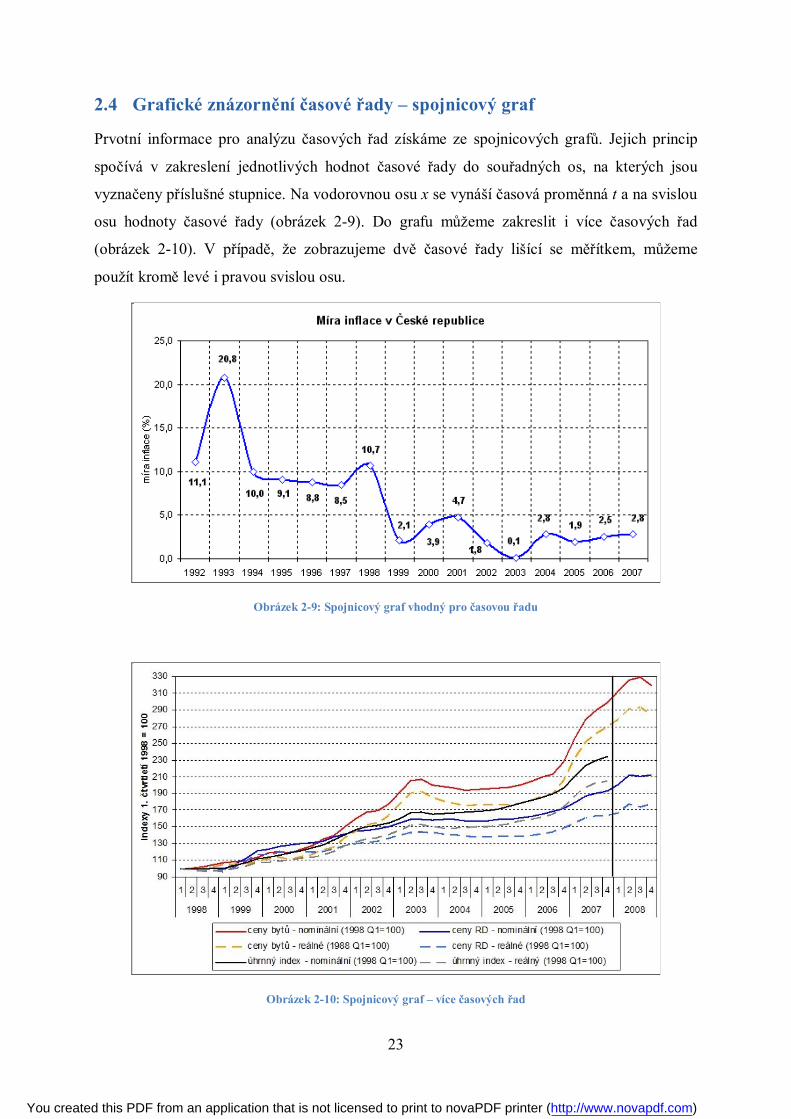
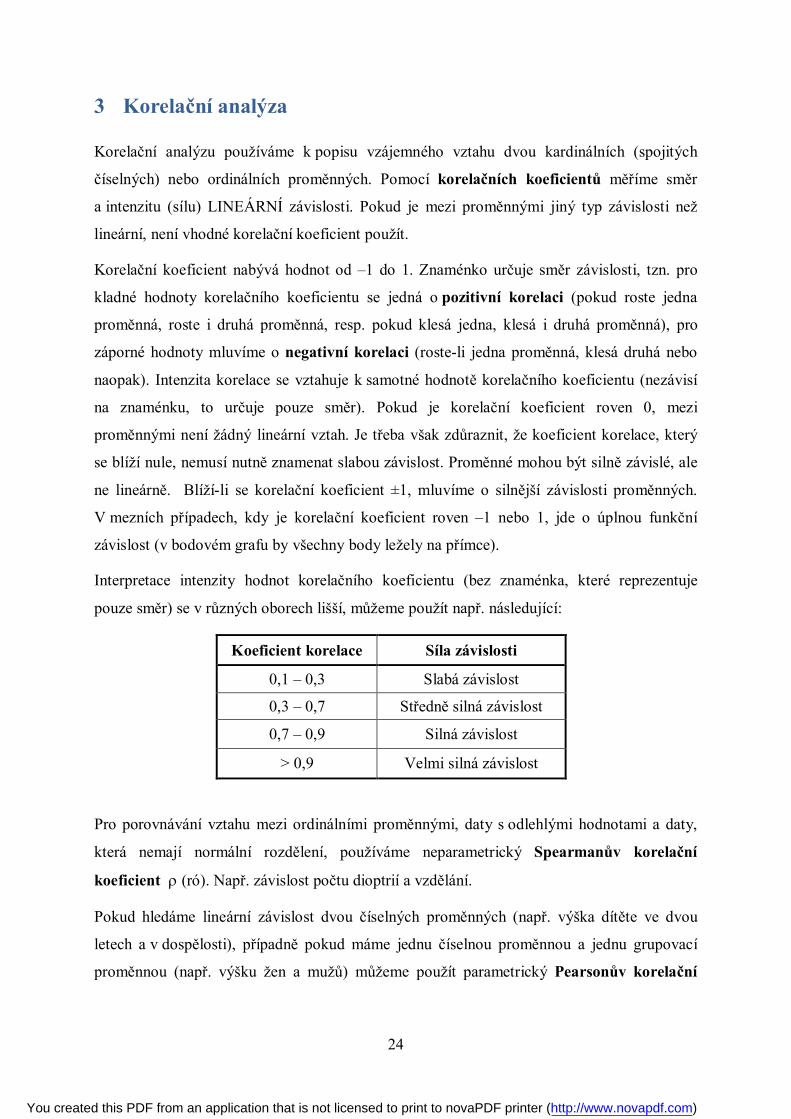
2.4 Grafické znázornění časové řady – spojnicový graf
Prvotní informace pro analýzu časových řad získáme ze spojnicových grafů. Jejich princip
spočívá v zakreslení jednotlivých hodnot časové řady do souřadných os, na kterých jsou
vyznačeny příslušné stupnice. Na vodorovnou osu x se vynáší časová proměnná t a na svislou
osu hodnoty časové řady (obrázek 2-9). Do grafu můžeme zakreslit i více časových řad
(obrázek 2-10). V případě, že zobrazujeme dvě časové řady lišící se měřítkem, můžeme
použít kromě levé i pravou svislou osu.
Obrázek 2-9: Spojnicový graf vhodný pro časovou řadu
Obrázek 2-10: Spojnicový graf – více časových řad
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 24
24
3 Korelační analýza
Korelační analýzu používáme k popisu vzájemného vztahu dvou kardinálních (spojitých
číselných) nebo ordinálních proměnných. Pomocí korelačních koeficientů měříme směr
a intenzitu (sílu) LINEÁRNÍ závislosti. Pokud je mezi proměnnými jiný typ závislosti než
lineární, není vhodné korelační koeficient použít.
Korelační koeficient nabývá hodnot od –1 do 1. Znaménko určuje směr závislosti, tzn. pro
kladné hodnoty korelačního koeficientu se jedná o pozitivní korelaci (pokud roste jedna
proměnná, roste i druhá proměnná, resp. pokud klesá jedna, klesá i druhá proměnná), pro
záporné hodnoty mluvíme o negativní korelaci (roste-li jedna proměnná, klesá druhá nebo
naopak). Intenzita korelace se vztahuje k samotné hodnotě korelačního koeficientu (nezávisí
na znaménku, to určuje pouze směr). Pokud je korelační koeficient roven 0, mezi
proměnnými není žádný lineární vztah. Je třeba však zdůraznit, že koeficient korelace, který
se blíží nule, nemusí nutně znamenat slabou závislost. Proměnné mohou být silně závislé, ale
ne lineárně. Blíží-li se korelační koeficient ±1, mluvíme o silnější závislosti proměnných.
V mezních případech, kdy je korelační koeficient roven –1 nebo 1, jde o úplnou funkční
závislost (v bodovém grafu by všechny body ležely na přímce).
Interpretace intenzity hodnot korelačního koeficientu (bez znaménka, které reprezentuje
pouze směr) se v různých oborech lišší, můžeme použít např. následující:
Koeficient korelace Síla závislosti
0,1 – 0,3 Slabá závislost
0,3 – 0,7 Středně silná závislost
0,7 – 0,9 Silná závislost
> 0,9 Velmi silná závislost
Pro porovnávání vztahu mezi ordinálními proměnnými, daty s odlehlými hodnotami a daty,
která nemají normální rozdělení, používáme neparametrický Spearmanův korelační
koeficient (ró). Např. závislost počtu dioptrií a vzdělání.
Pokud hledáme lineární závislost dvou číselných proměnných (např. výška dítěte ve dvou
letech a v dospělosti), případně pokud máme jednu číselnou proměnnou a jednu grupovací
proměnnou (např. výšku žen a mužů) můžeme použít parametrický Pearsonův korelační
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 25
25
koeficient 푟. V tomto případě musí být splněny předpoklady použití Pearsonova koeficientu
korelace:
lineární vztah mezi proměnnými,
neexistence odlehlých hodnot,
normální rozdělení dat (pro proměnné rozdělené pomocí grupovací proměnné je nutný
předpoklad normality v jednotlivých skupinách, např. výška žen, výška mužů).
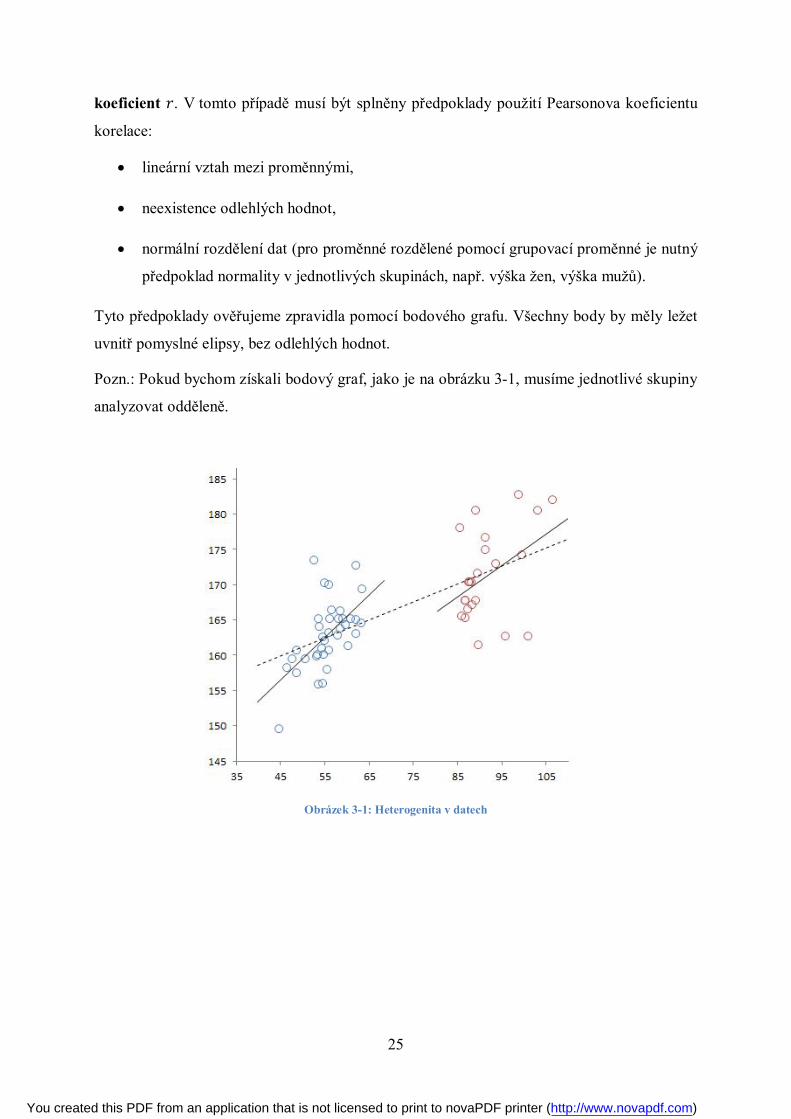
Tyto předpoklady ověřujeme zpravidla pomocí bodového grafu. Všechny body by měly ležet
uvnitř pomyslné elipsy, bez odlehlých hodnot.
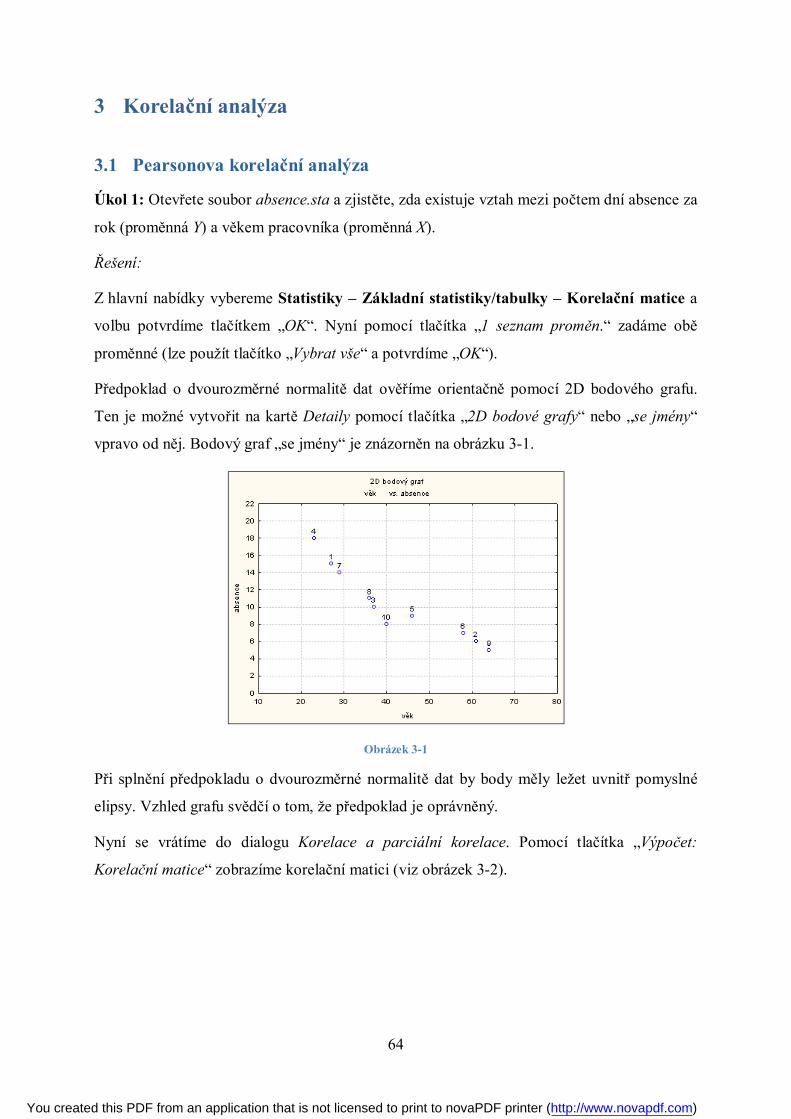
Pozn.: Pokud bychom získali bodový graf, jako je na obrázku 3-1, musíme jednotlivé skupiny
analyzovat odděleně.
Obrázek 3-1: Heterogenita v datech
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 26
26
Obrázek 3-2 ukazuje různé hodnoty koeficientů korelace pro různé typy bodových grafů.
Zdroj: wikipedia.org
Obrázek 3-2: Korelační koeficienty vybraných bodových grafů
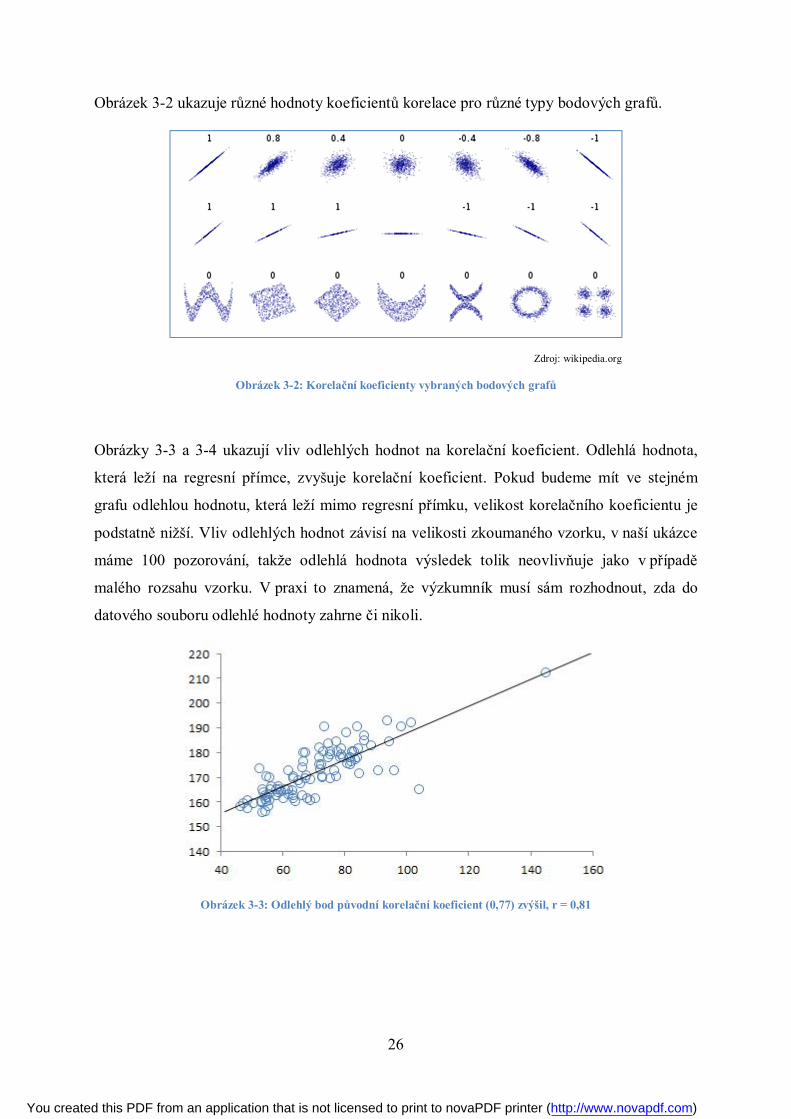
Obrázky 3-3 a 3-4 ukazují vliv odlehlých hodnot na korelační koeficient. Odlehlá hodnota,
která leží na regresní přímce, zvyšuje korelační koeficient. Pokud budeme mít ve stejném
grafu odlehlou hodnotu, která leží mimo regresní přímku, velikost korelačního koeficientu je
podstatně nižší. Vliv odlehlých hodnot závisí na velikosti zkoumaného vzorku, v naší ukázce
máme 100 pozorování, takže odlehlá hodnota výsledek tolik neovlivňuje jako v případě
malého rozsahu vzorku. V praxi to znamená, že výzkumník musí sám rozhodnout, zda do
datového souboru odlehlé hodnoty zahrne či nikoli.
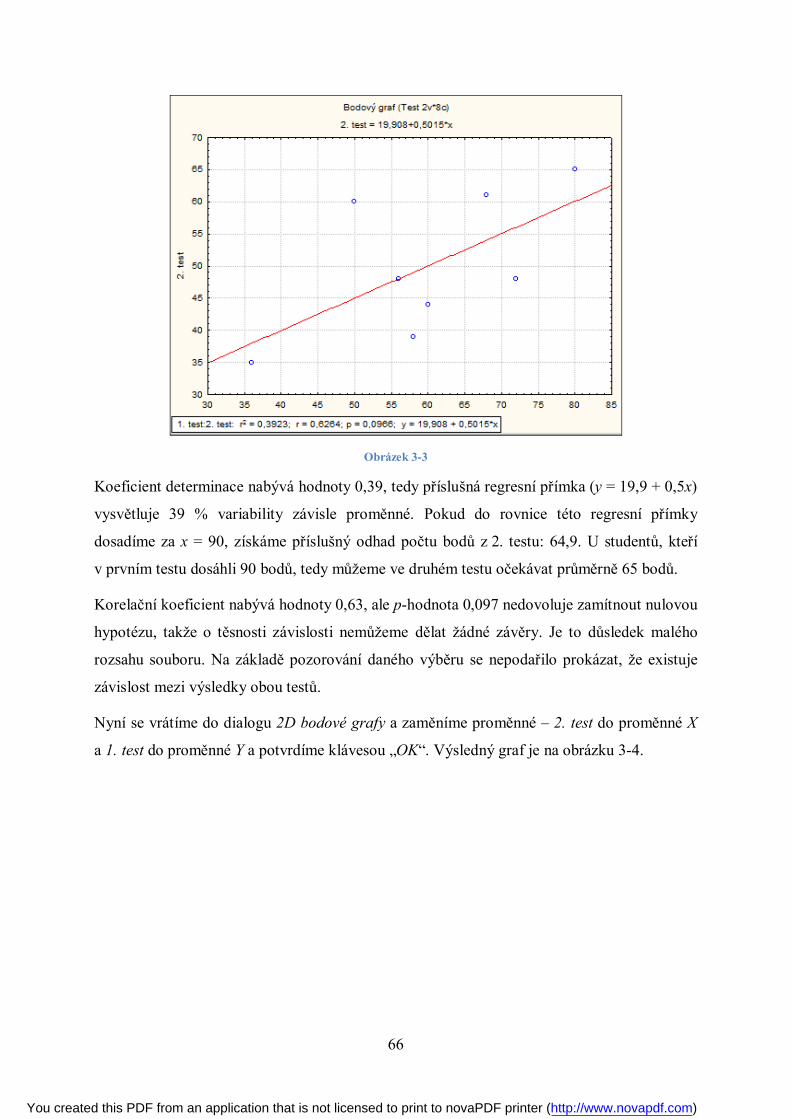
Obrázek 3-3: Odlehlý bod původní korelační koeficient (0,77) zvýšil, r = 0,81
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 27
27
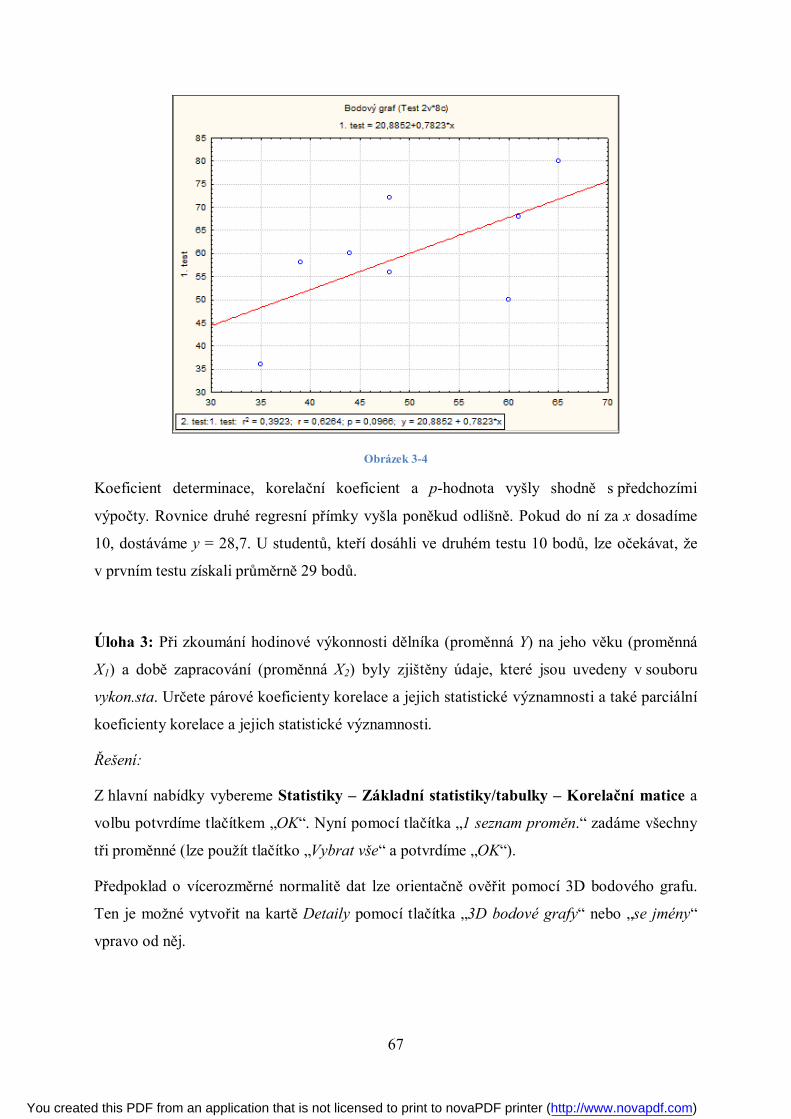
Obrázek 3-4: Odlehlý bod původní korelační koeficient (0,77) snížil, r = 0,537
Úroveň statistické významnosti Pearsonova i Spearmanova korelačního koeficientu
posuzujeme podle 푝-hodnoty, která je zobrazená či naznačena ve výstupech statistických
programů. V programu STATISTICA je statisticky významný korelační koeficient (p < 0,05)
vyznačen červeným písmem. Pokud je 푝 > 0,05, je korelační koeficient statisticky
nevýznamný a je nutné jej považovat za nulový.
Je potřeba zdůraznit, že p-hodnota neukazuje na intenzitu závislosti mezi proměnnými (ta je
dána přímo korelačním koeficientem), ale říká nám, zda je korelační koeficient možné
považovat za nenulový. Statistická významnost korelačního koeficientu je kromě vlastního
lineárního vztahu mezi proměnnými také ovlivněná velikostí vzorku, např. pro malé vzorky
(푛 < 30) nemusí být korelační koeficient 0,4 (středně silná závislost) statisticky významný
(nepotvrdili jsme, že mezi proměnnými je nějaký vztah) a naopak pro velké vzorky (např.
푛 > 100) může být statisticky významná i slabá závislost, kdy je korelační koeficient např.
0,2.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 28
28
4 Regresní analýza
Hlavním úkolem regresní analýzy je najít nejvhodnější regresní funkci, pomocí které můžeme
odhadnout hodnoty závislé proměnné na základě zvolených hodnot nezávislé proměnné.
Např. odhad váhy na základě výšky, odhad střední hodnoty očekávané doby přežití pacienta
s rakovinou na základě jeho zdravotního stavu, odhad doby zmírnění bolesti po aplikaci
určitého množství léku apod.
Posuzujeme tedy vztah závislé proměnné (např. váha) na vybrané nezávislé proměnné (např.
výška). Předpokládáme pouze jednostrannou závislost, tj. závislá (vysvětlovaná) proměnná
zpětně neovlivňuje nezávislou proměnnou. Vysvětlovanou proměnnou zpravidla značíme Y
a vysvětlující proměnnou X. Je-li vysvětlujících proměnný více, používáme pro ně označení
X1, X2, atd.
Lineární regresní funkce má potom tvar 푌 = 푏 + 푏 푋, obecně pro více (n) vysvětlujících
proměnných 푌 = 푏 + 푏 푋 + 푏 푋 +⋯+ 푏 푋 . Tento typ regrese, kterým se budeme
zabývat v našem kurzu, se nazývá (vícenásobná) lineární regrese.
Vhodnost volby lineárního modelu můžeme odvodit z bodového grafu, ve kterém také
můžeme vypozorovat případné vybočující hodnoty, které mohou velmi ovlivnit kvalitu
vytvořeného modelu. Vhodnost modelu nám také ukáže graf reziduí (rozdíl mezi
předpovězenou a pozorovanou hodnotou), kde by rezidua měla být rozmístěna náhodně,
nikoli ve tvaru nějaké funkce.
O kvalitě modelu vypovídá také koeficient determinace, který je zpravidla značený 푅2 (푅 ).
Ten nám říká, kolik procent variability závislé proměnné model vysvětluje pomocí variability
nezávislých proměnných. Upravený koeficient determinace „Upravené 푅2“ slouží
k porovnávání modelů, jež se liší počtem nezávislých proměnných.
Poslední hodnota, na kterou bychom neměli zapomenout, je 푝-hodnota, která určuje
statistickou významnost jak regresní funkce, tak i jednotlivých koeficientů. Pro 푝 < 0,05 je
regresní model, resp. odhad konkrétního koeficientu statisticky významný, tedy nenulový.
Tuto skutečnost vyznačuje program STATISTICA červenou barvou.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 29
29
5 Testování hypotéz
5.1 Postup při testování hypotéz
Kvantitativní výzkum se zaměřuje na hledání vztahů mezi dvěma či více proměnnými.
Hlavním cílem kvantitativního výzkumu je ověřování platnosti teorií pomocí testování
z těchto teorií vyvozených hypotéz.
Proto je hlavní součástí každé analýzy dat statistické testování hypotéz. V této kapitole se
seznámíme s hlavními principy a postupy při tomto procesu, který je tvořen dvěma
základními kroky:
1. Formulace nulové a alternativní hypotézy.
2. Testování hypotézy na hladině významnosti .
5.1.1 Formulace nulové a alternativní hypotézy
Na začátku procesu testování hypotéz je nutné vyslovit dvě hypotézy: nulovou hypotézu a její
negaci, tzv. alternativní hypotézu. V této fázi se nezabýváme pravdivostí těchto hypotéz, ale
stanovíme hypotézy tak, aby vyhovovaly následujícím pravidlům.
Nulovou hypotézu standardně označujeme 퐻 . Je to jednoznačné tvrzení, které většinou
uvádíme ve tvaru, že něco platí (např. průměrná výška žen je stejná jako průměrná výška
mužů, směrodatná odchylka hmotností dívek je stejná jako směrodatná odchylka hmotností
chlapců, počet vykouřených cigaret nezávisí na velikosti sídla, ve kterém respondent žije,
tržby loňského a letošního roku se rovnají, korelační koeficient je roven nule,…). Je to ovšem
také hypotéza, kterou bychom rádi zamítli (vyloučili jednu konkrétní možnost), protože
nezamítnutí nulové hypotézy neznamená, že platí (že jsme ji dokázali), zjistíme pouze, že
nemáme dostatek důkazů na to, abychom ji mohli zamítnout. Naopak zamítnutím nulové
hypotézy konkrétní tvrzení 퐻 vyvrátíme.
Alternativní hypotéza 퐻 je tvrzení, že nulová hypotéza 퐻 neplatí. Alternativní hypotézy
k výše uvedeným nulovým hypotézám by mohly znít např.: průměrná výška mužů a žen se
liší, směrodatné odchylky hmotností dívek a chlapců se liší, počet vykouřených cigaret závisí
na velikosti sídla, ve kterém respondent žije, tržby loňského a letošního roku jsou různé,
korelační koeficient je nenulový.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 30
30
Zatímco nulová hypotéza je platná vždy pouze v jediné situaci, alternativní hypotéza může
být platná, v celé řadě situací.
5.1.2 Testování hypotézy na hladině významnosti
Testování hypotéz s využitím statistického softwaru je poměrně snadná záležitost. Statistický
software nám kromě řady dalších výsledků poskytuje k testované hypotéze tzv. p-hodnotu,
která nám říká, jak velké chyby se dopustíme, zamítneme-li nulovou hypotézu.
Dále je nutné si stanovit, jak velká chyba je pro nás ještě akceptovatelná. Tomuto číslu se při
testování hypotéz říká hladina významnosti a značíme ji . Nejčastěji hladinu významnosti
volíme = 0,05 (5%) nebo = 0,01 (1%). Zamítneme-li nulovou hypotézu na hladině
významnosti 0,05, mluvíme o statisticky významném rozdílu mezi testovanými proměnnými.
V případě, že zamítneme nulovou hypotézu na hladině významnosti 0,01, mluvíme
o statisticky vysoce významném rozdílu.
Ve zdravotnických výzkumech, např. při zavádění nových léků, považujeme hladinu
významnosti 0,01 ještě za velmi vysokou a testování hypotéz v těchto případech (kdy jde
o zdraví či život pacientů) provádíme na několikanásobně nižší hladině významnosti.
Při interpretaci výsledků mohou nastat dvě situace:
1. p-hodnota je menší než hladina významnosti , potom nulovou hypotézu 퐻 musíme
zamítnout a musíme přijmout alternativní hypotézu H ,
2. p-hodnota je větší než hladina významnosti , potom nulovou hypotézu 퐻
nezamítneme, protože pravděpodobnost, že bychom se dopustili chyby, je pro nás již
neakceptovatelná. Měli bychom se vyvarovat špatnému závěru, že jsme potvrdili nebo
dokázali nulovou hypotézu 퐻 . Toto je chybná interpretace výsledku, protože jsme
pouze neměli dostatek důkazů k zamítnutí nulové hypotézy, tzn. nepodařilo se nám
dokázat, že nulová hypotéza 퐻 neplatí. (Výsledek neukázal velkou neshodu mezi
zjištěnou skutečností a testovanou hypotézou.)
Příklad: Interpretace 푝-hodnoty pro 푝 = 0,015, = 0,05: 0,015 < 0,05, proto na hladině
významnosti 5% nulovou hypotézu 퐻 zamítám a přijímám alternativní hypotézu 퐻 .
Kdybychom však v tomto případě zvolili hladinu významnosti 0,01, nemohli bychom již
nulovou hypotézu zamítnout. Test tedy prokázal statisticky významný rozdíl.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 31
31
Zamítnutí nulové hypotézy závisí kromě jiných parametrů také na rozsahu výběru. Jestliže
provedeme výběr rozsahu 1000, je možné, že nulová hypotéza bude zamítnuta, i když by při
rozsahu výběru 100 zamítnuta nebyla.
5.2 Chyba I. a II. druhu
Při testování statistických hypotéz se můžeme dopustit dvou nesprávných závěrů: chybně
zamítneme nulovou hypotézu, která platí, nebo nezamítneme nulovou hypotézu, která ve
skutečnosti ovšem neplatí. Mohou tedy nastat možnosti, které popisuje tabulka
Tab. 5-1.
Tab. 5-1: Chyby při testování hypotéz
Rozhodnutí
Skutečnost 퐻 nezamítneme 퐻 zamítneme
퐻 platí Správně Chyba I. druhu
퐻 neplatí Chyba II. druhu Správně
Chyba I. druhu se označuje a je to podmíněná pravděpodobnost, že zamítneme nulovou
hypotézu za předpokladu, že platí, je to tedy hladina významnosti testu. Pravděpodobnost
1 − se nazývá spolehlivost testu. Standardními hodnotami je = 0,05 nebo = 0,01.
Chyby II. druhu se označuje a je to podmíněná pravděpodobnost, že nezamítneme nulovou
hypotézu za předpokladu, že neplatí. Pravděpodobnost 1 − se nazývá síla testu.
Standardními hodnotami je = 0,2 nebo = 0,1.
5.3 Rozdělení statistických testů
Statistické testy rozdělujeme podle vlastností testovaných proměnných na dvě základní
skupiny: parametrické a neparametrické.
Parametrické testy můžeme použít pouze tehdy, jsou-li splněny všechny předpoklady pro
použití testu. Tyto testy mají větší sílu testu než testy neparametrické.
Neparametrické testy jsou speciální testy, které nevyžadují splnění žádných nebo skoro
žádných předpokladů o charakteru rozdělení studovaných náhodných veličin. Proto mají širší
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 32
32
použitelnost než testy parametrické. Jako nedostatek se uvádí zejména jejich menší síla
(tj. menší schopnost zamítnout nesprávnou nulovou hypotézu) v porovnání s parametrickými
testy.
Jsou-li splněny předpoklady použití parametrických testů, potřebují neparametrické testy
analogických hypotéz větší rozsah náhodného výběru k dosažení stejné síly testu proti
analogickým parametrickým testům.
Statistické testy také můžeme rozdělit podle počtu porovnávaných proměnných.
Jednovýběrové testy srovnávají hodnoty jedné statistické proměnné s referenční hodnotou
(s nějakou danou konkrétní hodnotou), např. jestli je průměrná výška studentů ve skupině
rovna 173 cm nebo zda průměrná teplota pacienta je 36,7°C,….
Dvouvýběrové testy porovnávají dva výběrové soubory a většinou se ptáme, jestli jsou oba
výběry stejné. Nejčastěji testujeme shodnost průměrů a rozptylů. Dvouvýběrové testy dále
dělíme na párové a nepárové.
Párové testy – porovnávají dvě proměnné, mezi kterými existuje nějaká závislost,
např. srovnání ranní a večerní teploty pacienta, srovnání hodnocení CK klienty před
a po zájezdu,… Hodnoty jsou měřené u jednoho subjektu dvakrát, zpravidla v nějakém
časovém odstupu. Z uvedeného vyplývá, že velikost porovnávaných skupin musí být
stejná.
Nepárové testy – testované skupiny jsou nezávislé, např. porovnání délky
hospitalizace ve dvou různých odděleních nemocnice, porovnání spokojenosti klientů
dvou cestovních kanceláří, srovnání průměrné hmotnosti mužů a žen,… Hodnoty jsou
měřené u každého subjektu jedenkrát (jedná se o jednu proměnnou) a rozdělení na dvě
skupiny zajišťuje jiná proměnná, která má právě dvě obměny (dvě oddělení, dvě CK,
pohlaví, …). Porovnávané skupiny tedy mohou mít (a v praxi zpravidla mají) různou
velikost.
Vícevýběrové testy porovnávají více skupin. Analogicky k dvouvýběrovým testům se může
jednat jak o porovnání více proměnných, tak o porovnání více skupin v rámci jedné
proměnné. Vícevýběrové testy nebudou v tomto kurzu studovány.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 33
33
5.4 Kontingenční tabulky
Kontingenční tabulka přehledně shrnuje příslušné četnosti dvou statistických znaků. Záhlaví
řádků je tvořené obměnami jedné proměnné, záhlaví sloupců je tvořené obměnami druhé
proměnné. Kontingenční tabulka také často obsahuje celkové počty jednotlivých, sloupců
a celkový počet všech zkoumaných případů. Četnosti mohou být absolutní i relativní
(procentuální zastoupení).
Typ kontingenční tabulky se určuje počtem řádků 푟 a počtem sloupců 푠, tzn. mluvíme o 푟 × 푠
kontingenční tabulce. Jednotlivé četnosti v kontingenční tabulce označujeme 푛 , kde
푖 = 1, 2,… , 푟 je pořadí řádku, 푗 = 1, 2,… , 푠, je pořadí sloupce, ve kterém hodnota leží.
Kontingenční tabulky 2 × 2 nazýváme asociační (čtyřpolní) tabulky.
Pomocí kontingenčních tabulek můžeme analyzovat závislost dvou kategoriálních
proměnných. Koeficientů závislosti je mnoho a obvykle je klasifikujeme podle
velikosti tabulky (počtu řádků a sloupců),
typu proměnných (nominální, ordinální),
typu závislosti (symetrická, asymetrická).
Závislost dvou nominálních proměnných se nazývá kontingence. Základním testem pro
zjištění vzájemné závislosti dvou kategoriálních proměnných je 흌ퟐ (čteme chí kvadrát) test
o nezávislosti (kapitola 5.5.1).
Ze statistiky chí-kvadrát jsou odvozeny další koeficienty, které v případě nezávislosti
nabývají hodnoty 0. Systém STATISTICA nabízí pro zkoumání závislosti mimo již
zmíněných statistik ještě výpočet koeficientu 훗 (čteme fí), kontingenčního koeficientu C
a Cramerova V.
Pokud bychom měli vyhodnotit intenzitu závislosti pouze jednoho vztahu, pak nejlépe
interpretovatelným koeficientem je Cramerovo V, protože nabývá hodnoty z intervalu 0, 1.
Můžeme tedy říci, zda závislost je velmi slabá – slabší – středně silná – silná. Ostatní
koeficienty se využívají pro porovnání intenzit závislostí (vyhodnocujeme-li intenzitu více
vztahů).
Závislost dvou ordinálních proměnných nazýváme korelace (viz kapitola 3 Korelační
analýza).
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 34
34
5.5 Neparametrické testy
Neparametrické testy používáme zejména pro kategoriální (nominální, ordinální) data, na
malé vzorky nebo na data, která nesplňují předpoklady parametrických testů. Výhodou
neparametrických testů je, že nevyžadují splnění žádných nebo skoro žádných předpokladů.
Mají ovšem tu nevýhodu, že jsou méně citlivé a nemusejí odhalit existující rozdíly mezi
skupinami.
5.5.1 Neparametrické testy pro kategoriální proměnné
5.5.1.1 흌ퟐ test o nezávislosti
흌ퟐ (čteme chí kvadrát) test o nezávislosti používáme pro zjištění závislosti mezi dvěma
nepárovými kategoriálními proměnnými, např. počet vykouřených cigaret závisí na pohlaví,
preference politických stran závisí na velikosti obce, ve které dotazovaný žije, pití
alkoholických nápojů závisí na vzdělání, volba destinace dovolené závisí na počtu dětí
v rodině,…
Nulová hypotéza předpokládá, že mezi pozorovanými a očekávanými četnostmi nebude
rozdíl, tzn. že proměnné budou nezávislé. Pokud se nám podaří zamítnout nulovou hypotézu,
přijmeme alternativní, která zní, že pozorovaná data jsou závislá.
Výpočet 푝-hodnoty se technicky provádí na základě porovnání dvou kontingenčních tabulek
s pozorovanými četnostmi a s očekávanými četnostmi.
Předpoklady testu: očekávané četnosti by měly mít hodnotu nejméně 5 (někteří autoři
navrhují méně přísnější kritérium: alespoň 80 % očekávaných četností má mít hodnotu 5 nebo
vyšší). Pokud máme kontingenční tabulku typu 2 × 2, doporučuje se, aby očekávané četnosti
neklesly pod 10.
Formulce nulové a alternativní hypotézy
퐻 : Mezi proměnnými není závislost.
퐻 : Proměnné jsou závislé.
Poznámka: Obecně tabulku s očekávanými daty můžeme sestavit tak, že jednotlivá pole
kontingenční tabulky přepočítáme podle vzorce 푛∗ = , kde 푅 je součet všech četností
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 35
35
v i-tém řádku, 푆 je součet všech četností v 푗-tém sloupci a 푛 je celkový počet pozorovaných
hodnot. Takto přepočtené očekávané hodnoty využívají očekávaného procentuálního
zastoupení jednotlivých četností.
5.5.1.2 McNemarův test
McNemarův test používáme pro zjištění závislosti mezi dvěma párovými kategoriálními
proměnnými se dvěma obměnami, které jsou opakovaně měřená ve dvou různých časových
obdobích. Příkladem může být srovnání zdravotního stavu pacientů před zahájením a po
skončení léčebné procedury nebo průzkum volby konkrétního politického kandidáta před
zahájením a po skončení jeho volební kampaně.
Formulce nulové a alternativní hypotézy
퐻 : Mezi počátečními a konečnými daty se neprojevila žádná změna (nezávislost).
퐻 : Mezi počátečními a konečnými daty existuje rozdíl (závislost).
5.5.2 Neparametrické testy pro spojité proměnné
5.5.2.1 Mann-Whitney U test
Mann-Whitney U test používáme pro testování rozdílu mezi dvěma nezávislými skupinami
spojité proměnné, např. Liší se sebevědomí (měřeno na škále 0–100 %) žen a mužů? nebo
Liší se hmotnost lidí se světlými a s tmavými vlasy?
Formulce nulové a alternativní hypotézy
퐻 :Mediány obou skupin jsou stejné, tzn. 푥 = 푥 .
퐻 : Mediány obou skupin se liší, tzn. 푥 ≠ 푥 .
5.5.2.2 Wilcoxonův znaménkový test
Wilcoxonův znaménkový test se používá pro porovnání dvou párových (opakovaně
měřených) spojitých proměnných měřených na stejném vzorku, např. Je obava ze statistiky na
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 36
36
začátku a na konci semestru stejná? nebo Je tep pacienta před vpichem jehly stejný jako po
vpichu?
Tento test srovnává pořadí rozdílů konečných a počátečních dat a lze jej použít za
předpokladu, že se data dají od sebe smysluplně odečítat.
Formulce nulové a alternativní hypotézy
퐻 :Mediány obou skupin jsou stejné, tzn. 푥 = 푥 .
퐻 : Mediány obou skupin jsou jiné, tzn. 푥 ≠ 푥 .
5.6 T-testy
V minulé kapitole jsme se seznámili s tzv. neparametrickými testy. Jejich výhodou je, že
nevyžadují splnění žádných nebo skoro žádných předpokladů. Na druhou stranu jsou méně
citlivé a nemusejí zamítnout nulovou hypotézu i v případě existujících rozdílů mezi
skupinami. Pro kategoriální proměnné neexistuje žádná "lepší" varianta testu, ale pro spojité
proměnné lze při splnění konkrétních předpokladů použít tzv. t-testy, které jsou silnější než
testy neparametrické. T-testy tedy mohou zamítnout nulovou hypotézu i v případě, že
neparametrický testu nulovou hypotézu nezamítnul. Z uvedeného vyplývá, že použití t-testu
v případě zamítnutí nulové hypotézy neparametrickým testem je celkem zbytečná práce.
V tabulce Tab. 5-2 je shrnutí mezi uvedenými neparametrickými a parametrickými testy
a jejich vzájemné vztahy.
Tab. 5-2: Příslušné vztahy mezi neparametrickými a parametrickými testy
Neparametrické testy Parametrické testy
흌ퟐ test o nezávislosti ---
McNemarův test ---
Mann-Whitney U test Dvouvýběrový t-test
Wilcoxonův znaménkový test Párový t-test
V této kapitole si ukážeme pouze dva t-testy, které jsou analogiemi k neparametrickým
testům, a to:
dvouvýběrový t-test – porovnáváme, jestli (průměrné) hodnoty dvou nezávislých
výběrů jsou stejné, např. hmotnost mužů a žen,
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 37
37
párový t-test – porovnáváme, jestli (průměrné) hodnoty dvou závislých (párových)
výběrů jsou stejné (mezi dvěma proměnnými může být časová závislost), např.
pacientova ranní a večerní teplota.
V obou případech srovnáváme hodnoty spojité proměnné (teplota) ve dvou kategoriích nebo
událostech (ráno, večer).
5.6.1 Testování rovnosti průměrů
5.6.1.1 Dvouvýběrový t-test
Dvouvýběrový t-test používáme pro srovnání hodnot dvou nezávislých výběrů, kdy
porovnáváme mezi sebou rozdíl spojité proměnné (výška, hmotnost) ve dvou skupinách
(pohlaví, oddělení A a B) (např. Liší se průměrná výška žen a mužů? nebo Je hmotnost
diabetiků na oddělení A a B stejná?). Tento test tedy použijeme v případě, že máme data
rozdělena pomocí tzv. grupovací proměnné do dvou skupin (např. muži a ženy) a chceme
porovnat průměry spojité proměnné (např. výška) pro tyto dvě skupiny.
Vzhledem k tomu, že se jedná o parametrický test, musí být splněny následující předpoklady:
výběry musejí pocházet z normálního rozdělení nebo rozsah souboru musí být větší
než 30,
oba vzorky musí mít stejný rozptyl nebo velmi malý rozdíl v četnostech obou výběrů
(poměr nmax/nmin < 1,5 ).
Tento test testuje následující nulovou hypotézu oproti alternativní hypotéze:
퐻 :휇 = 휇 (průměrné hodnoty obou skupin jsou stejné).
퐻 : 휇 ≠ 휇 (průměrné hodnoty obou skupin nejsou stejné).
5.6.1.2 Párový t-test
Párový t-test (výsledek opakovaného měření) se používá pro srovnání hodnot dvou spojitých
proměnných, které jsou měřené na jedné skupině ve dvou různých okamžicích zpravidla za
působení jiného vlivu, např. počet bílých krvinek před a po užití léku, strach ze statistiky
(škála 0 – 100 %) před začátkem a na konci semestru.
Pro použití tohoto testu musí být splněn následující předpoklad:
proměnné musejí mít normální rozdělení nebo četnost skupiny musí být vyšší než 30.
Tento test testuje následující nulovou hypotézu oproti alternativní hypotéze:
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 38
38
퐻 :휇 = 휇 (průměrné hodnoty obou proměnných jsou stejné).
퐻 : 휇 ≠ 휇 (průměrné hodnoty obou proměnných nejsou stejné).
5.6.2 Testování předpokladů normality
Jestliže četnosti v obou porovnávaných skupinách jsou malé, musíme ověřit, že data z obou
skupin pocházejí z normálního rozdělení. K tomuto účelu nabízí program Statistica dva testy,
které testují následující nulovou hypotézu oproti alternativní hypotéze:
퐻 : Výběr pochází z normálního rozdělení
퐻 : Výběr nepochází z normálního rozdělení
5.6.2.1 Kolmogorov-Smirnovův a Lilieforsův test
Tento test nemá žádné omezující podmínky, proto jím můžeme testovat jakákoli data. Pro
otestování normality používáme v praxi zpravidla Lilieforsovu modifikaci Kolmogorov-
Smirnovova testu. Kolmogorův-Smirnovův test použijeme v případě, že předem známe
parametry rozdělení, tzn. pro normálního rozdělení 푁(휇; 휎 ), kde 휇 je střední hodnota a 휎
rozptyl, Lilieforsův test použijeme, pokud parametry neznáme (většina reálných dat).
5.6.2.2 Shapiro-Wilkův test normality
Jeden z nejsilnějších tesů normality, který používáme v případě, že testujeme normalitu
u souboru menšího rozsahu (zpravidla méně než 2000).
5.6.2.3 Posouzení normality z grafického výstupu
Normalitu proměnné také můžeme posoudit vzhledově podle histogramu nebo tzv. N-P
plotu (normálního grafu), v němž jsou body tvořené pomocí naměřených a očekávaných
hodnot soustředěné kolem přímky, která reprezentuje normální rozdělení proměnné. Čím více
se body budou blížit přímce, tím je lepší soulad mezi našimi hodnotami a normálním
rozdělením.
5.6.3 Testování shody rozptylů
Pokud máme dva výběry různých rozsahů (např. počet mužů několikanásobně převyšuje
počet žen zapojených do výzkumu), musíme pro dvouvýběrové t-testy ještě otestovat
homogenitu rozptylu. Při testování homogenity rozptylu testujeme následující nulovou
hypotézu oproti alternativní hypotéze:
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 39
39
퐻 :휎 = 휎 (rozptyly obou výběrů jsou stejné),
퐻 : 휎 ≠ 휎 (rozptyly obou výběrů nejsou stejné).
Software Statistika nabízí tři testy: F-test, Leveneův test a Brown-Forsythův test.
5.6.3.1 F-test
Předpokladem F-testu je normalita dat.
5.6.3.2 Leveneův test, Brown-Forsythův test
Testy jsou silnější (robustnější) než F-test, dají se použít i pro data, která nemají normální
rozdělení. V Leveneově testu počítáme rozptyl z průměrů, v Brown-Forsythově testu se
rozptyly počítají z mediánů (je tedy ještě robustnější).
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 40
40
Řešené příklady softwarem Statistica
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 41
41
1 Sběr dat a jejich příprava pro import do softwaru Statistica
Při sběru dat je potřeba postupovat co nejefektivnějším způsobem, jaký situace umožňuje.
Pokud údaje existují v elektronické podobě (např. v laboratorním měřicím přístroji nebo
v databázi pacientů), je potřeba najít způsob, jak je efektivně získat. Je velkou chybou data
ručně přepisovat, protože to je časově náročné a pravděpodobnost vzniku chyby je obrovská.
Místo toho je lepší požádat statistika, informatika nebo technika, který dokáže data exportovat
do vhodného programu (nejčastěji Excelu) za pár minut a bez chyb.
Pokud provádíme dotazníkové šetření, je vhodné vždy, pokud to situace umožňuje, nahradit
papírové formuláře elektronickými. Využití webových formulářů eliminuje riziko vzniku
chyby při přepisování údajů do počítače a získaná data je možné ihned analyzovat ve
statistickém programu. Takový postup zvýší kvalitu výzkumu a ušetří čas i energii.
Samozřejmě, že i při využití internetu je nutné mít na paměti, že je musíme oslovovat
záměrně vybrané respondenty a požádat je o vyplnění dotazníku. Nelze postupovat tak, že
dotazník zveřejníme a čekáme, kdo jej objeví a vyplní.
Ať už máme data posbíraná jakýmkoli způsobem, je nutné je před zpracováním převést do
excelovské databáze. Jedná se o tabulku v Excelu, která se řídí několika pravidly:
Jednotlivé řádky tabulky obsahují informace o jednotlivých respondentech – tzn.
tabulka obsahuje tolik řádků, kolik jsme oslovili respondentů + jeden řádek záhlaví.
Záhlaví tabulky obsahuje názvy proměnných (sloupců tabulky) – zpravidla jde
o zkrácené znění otázek z dotazníku. Záhlaví tabulky smí tvořit pouze jeden řádek,
nesmí se zde slučovat buňky.
V prvním sloupci je vhodné uvést číslo respondenta, pro případ nějakých
nesrovnalostí a nutnosti kontroly. Stejně očíslované by měly být dotazníky či jiné
informační zdroje, aby byly propojené s elektronickou podobou dat.
V tabulce nesmí zůstat prázdný řádek nebo prázdný sloupec – to by rozdělilo databázi
na dvě databáze, které by nespolupracovaly. Prázdné buňky databáze obsahovat může
a v praxi i velmi často obsahuje. Pokud chybí informace (např. respondent
neodpověděl), necháme buňku prázdnou, nepíšeme otazník, pomlčku či jiný znak.
Formátování datové tabulky by mělo být co nejjednodušší, zejména nesmí být použito
slučování buněk. Příkladem databáze může být např. tabulka 1-1 z teoretické části.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 42
42
Při zapisování jednotlivých informací do Excelu je nutné znát pravidla, kterými se Excel řídí
a která používá při zpracování informací:
Buňka může obsahovat číslo nebo text. S čísly Excel umí počítat, s texty nikoli, ale
umí je zpracovávat jinými metodami. Je tady nutné rozlišit, co Excel vnímá jako text a
co jako číslo. Ne vždy se jedná o triviální a zřejmou záležitost, takže Excel pomocí
zarovnání informuje uživatele, zda obsah buňky považuje za číslo (zarovná vpravo)
nebo za text (zarovná vlevo). Vyzkoušejte do dvou buněk napsat „6 Kč“ a „6 kč“.
Nepatrná změna (velké K zaměníme za malé k) způsobí, že Excel s první informací
bude schopen počítat, zatímco s druhou nikoli. Projeví se to zarovnáním obsahu
buňky. Aby nedocházelo ke zbytečným nedorozuměním, jednotky uvedeme v záhlaví
sloupce (např. výška v cm) a vlastní data již píšeme bez jednotek.
Pokud zapisujeme do sloupce stejné texty, Excel nám nabízí texty, které jsme již
jednou ve sloupci napsali. Např. když budeme mít proměnnou pohlaví, je možné do
tohoto sloupce napsat muž nebo žena. Jestliže jsme již jednou slovo např. muž napsali,
v dalším řádku stačí napsat m a Excel sám nabízí celé slovo muž. Je vhodné s těmito
nabídkami pracovat a přijímat je pomocí klávesy Enter. Tím zajistíte, že vždy stejný
text napíšete stejně, neboť se nabízí víc variant: muž, muz, Muž, Muz, MUZ atd.
Poté, co dokončíme zápis všech dat, je nutné u všech proměnných (sloupců) provést
kontrolu, jaké informace obsahují. Za tímto účelem použijeme Automatický filtr, který
dokáže zobrazit, přehledný seznam všech obměn, které sloupec obsahuje. Pokud by
některou variantu bylo nutné změnit, je možné ji vyfiltrovat a změnu provést
najednou.
Vzhledem k tomu, že databáze bývají zpravidla obrovské tabulky, je vhodné ukotvit
první řádek, abychom vždy věděli, co který sloupec obsahuje. V tom případě však je
potřeba dávat pozor na skryté řádky a zobrazovat si je klávesovou zkratkou Ctrl +
Home.
Z důvodu rozsahu databáze není nutné celou datovou tabulku označovat. Stačí umístit
aktivní buňku kamkoli do databáze a Excel si databázi načte sám – postupuje od
označené (aktivní) buňky nahoru, dolu, doleva a doprava tak daleko, až najde prázdný
řádek nebo sloupec. Nalezenou oblast potom zpracovává. Proto databáze nesmí
obsahovat prázdný řádek a sloupec. V prvním řádku oblasti je uvedeno pojmenování
sloupců, proto zde (ale ani jinde v databázi) nesmí být použito slučování buněk.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 43
43
Po vytvoření a kontrole databáze je již možné přistoupit k vlastní analýze dat a jejich
prezentaci. V současné době je běžné pro tyto účely použít statistický software, buď Excel,
který obsahuje celou řadu statistických funkcí, ale pro pokročilejší analýzy je vhodné použít
specializovaný statistický software, jakým je např. Statistica, SPSS nebo SAS.
1.1 Import dat do softwaru Statistica
Začínající uživatel programu STATISTICA se pravděpodobně rozhodne pro možnost
připravit si datový soubor v programu MS Excel, neboť se tak bude pohybovat v prostředí
důvěrně známém. Proto je nutné připomenout, jaká pravidla musí platit pro excelovskou
tabulku, aby správně mohla fungovat jako databáze a také aby ji bylo možné vyexportovat do
programu STATISTICA.
Tato tabulka by měla mít
pokud možno co nejjednodušší formátování, v žádném případě nesmí obsahovat
sloučené buňky,
nesmí obsahovat prázdný řádek nebo prázdný sloupec (což neznamená, že nemůže
obsahovat prázdné buňky),
do řádků píšeme odpovědi jednotlivých respondentů (případy resp. záznamy nebo
pozorování), první řádek by měl obsahovat názvy sledovaných vlastností (např.
označení jednotlivých otázek nebo jejich částí),
do sloupců zapisujeme tzv. proměnné (např. odpovědi na jednotlivé otázky nebo jejich
části), první sloupec může obsahovat názvy případů (např. jméno respondenta nebo
označení případu),
všechny informace by měly být uvedeny na jednom listu (tzn. existuje jediná tabulka,
která tvoří databázi).
Takto připravenou tabulku velmi jednoduše naimportujeme do programu STATISTICA při
jeho spuštění.
Spustíme program STATISTICA. (Pokud se kromě vlastního programu otevřela další okna, je
vhodné je zavřít a nechat si otevřené jediné – v tuto chvíli prázdné – okno.) Na panelu
nástrojů jsou dostupné pouze dvě ikony – Nový a Otevřít. Za pozornost stojí i to, že většina
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 44
44
ikon (dostupných i nedostupných) je dobře známa z MS Office – mají nejen stejný vzhled, ale
i funkci.
STATISTICA dokáže importovat data z jiných programů velmi snadno – pomocí dialogu
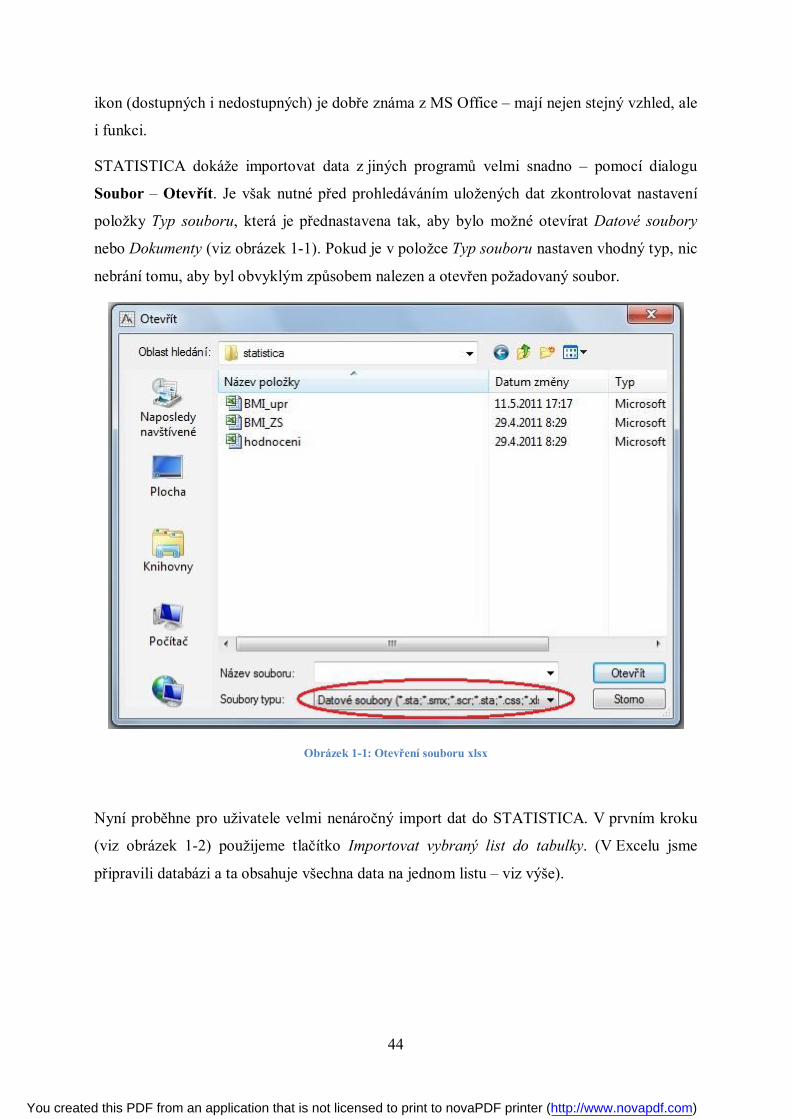
Soubor – Otevřít. Je však nutné před prohledáváním uložených dat zkontrolovat nastavení
položky Typ souboru, která je přednastavena tak, aby bylo možné otevírat Datové soubory
nebo Dokumenty (viz obrázek 1-1). Pokud je v položce Typ souboru nastaven vhodný typ, nic
nebrání tomu, aby byl obvyklým způsobem nalezen a otevřen požadovaný soubor.
Obrázek 1-1: Otevření souboru xlsx
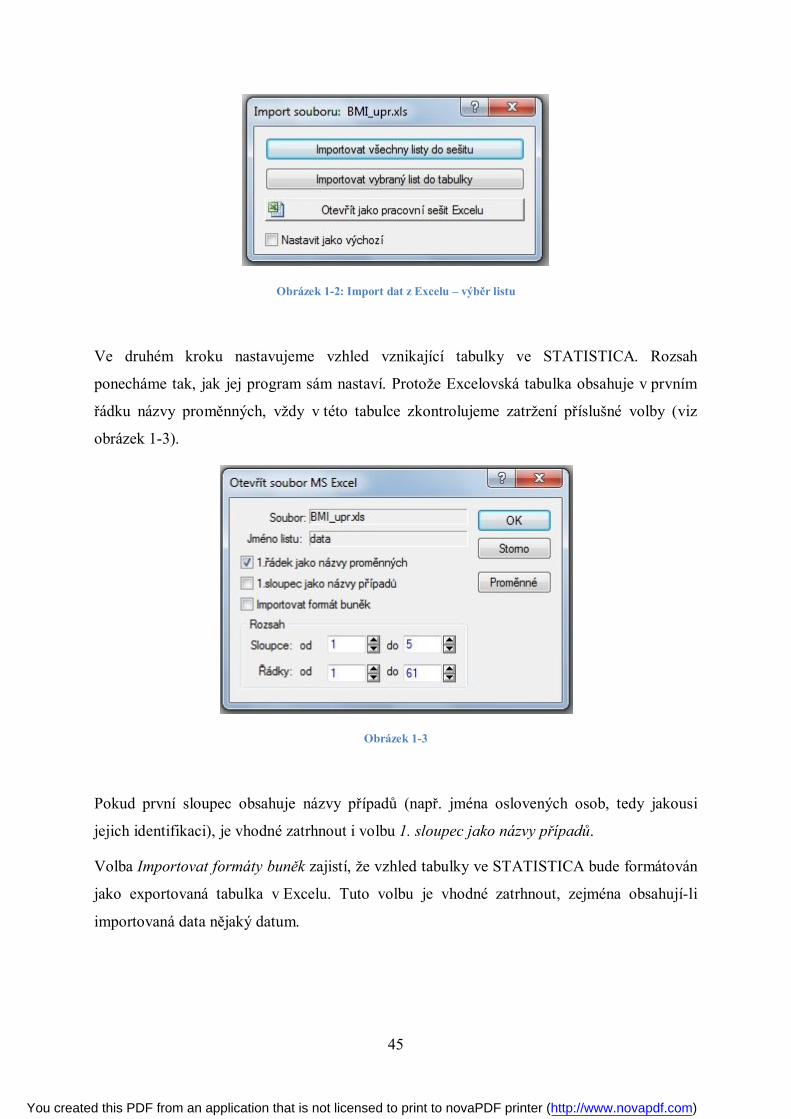
Nyní proběhne pro uživatele velmi nenáročný import dat do STATISTICA. V prvním kroku
(viz obrázek 1-2) použijeme tlačítko Importovat vybraný list do tabulky. (V Excelu jsme
připravili databázi a ta obsahuje všechna data na jednom listu – viz výše).
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 45
45
Obrázek 1-2: Import dat z Excelu – výběr listu
Ve druhém kroku nastavujeme vzhled vznikající tabulky ve STATISTICA. Rozsah
ponecháme tak, jak jej program sám nastaví. Protože Excelovská tabulka obsahuje v prvním
řádku názvy proměnných, vždy v této tabulce zkontrolujeme zatržení příslušné volby (viz
obrázek 1-3).
Obrázek 1-3
Pokud první sloupec obsahuje názvy případů (např. jména oslovených osob, tedy jakousi
jejich identifikaci), je vhodné zatrhnout i volbu 1. sloupec jako názvy případů.
Volba Importovat formáty buněk zajistí, že vzhled tabulky ve STATISTICA bude formátován
jako exportovaná tabulka v Excelu. Tuto volbu je vhodné zatrhnout, zejména obsahují-li
importovaná data nějaký datum.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 46
46
1.2 Kontrola dat, práce s proměnnými
Importovaná data do tabulky systému STATISTICA je nutné prohlédnout a vytvořit si o nich
základní ucelenou představu. Při přepisování získaných dat do elektronické podoby může
dojít k překlepu a je tedy nutné, aby data prošla kontrolou a neobsahovala chybné údaje. Tato
kontrola může ovšem odhalit pouze některé chyby. Když je např. v proměnné Výška uveden
údaj 56 cm, jedná se pravděpodobně o chybu, která mohla vzniknout např. chybným zápisem
čísla 156. Tato chyba se dá odhalit a opravit. Pokud však místo výšky 156 je uvedena výška
165, chyba kontrolou dat odhalena nebude. Proto je nutné při přepisování dat pracovat velmi
pečlivě a nesvěřovat tuto práci lidem, kteří nemají o datech jasnou představu. Protože výška
135 cm může znamenat chybu v datech nebo skutečnost, že byl osloven člověka, který
skutečně měří jen 135 cm (což je málo pravděpodobné, nikoli nemožné). Pouze člověk, který
data získával, ví, zda mezi jeho respondenty člověk s touto výškou skutečně byl, či zda se
jedná o chybu.
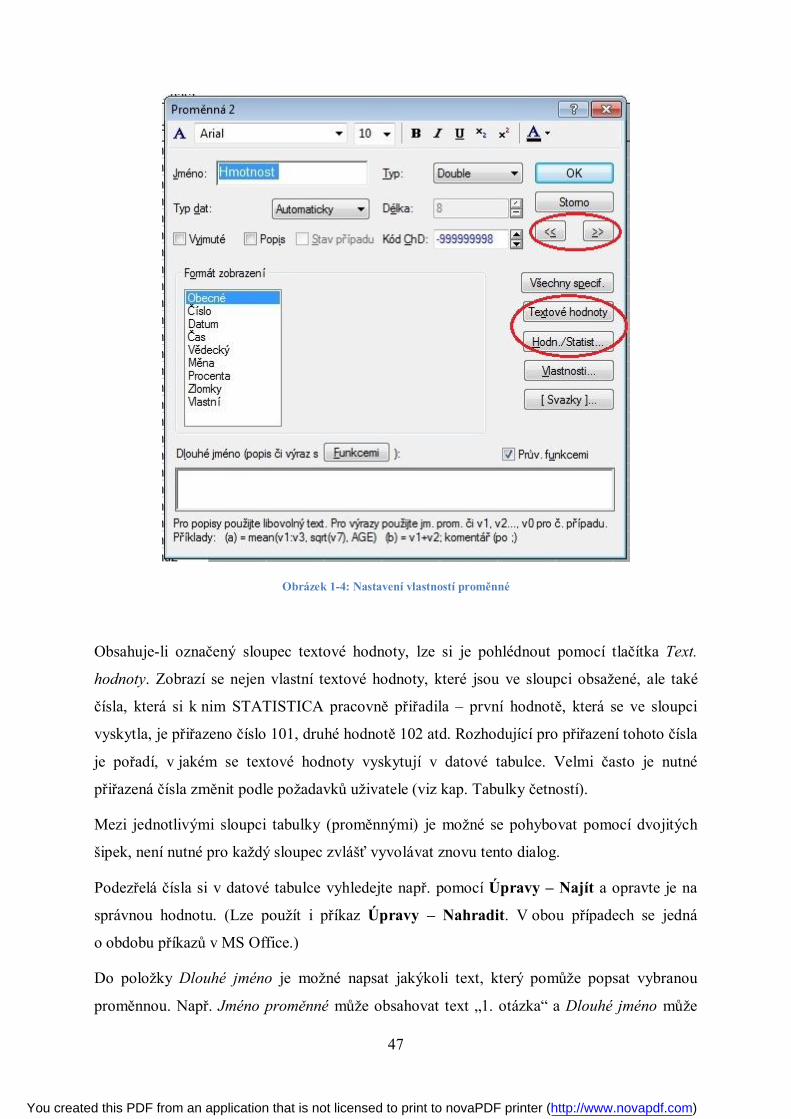
Zběžné prohlédnutí dat za účelem kontroly a získání základní představy o datech je možné
provést pomocí dialogu, který se objeví po poklepání na záhlaví libovolné proměnné. Objeví
se dialog, který je na obrázku 1-4.
Pokud označený sloupec obsahuje číselné hodnoty, lze si obměny tohoto statistického znaku
prohlédnout pomocí tlačítka Hodn./Statist. Zobrazí se vzestupně seřazené obměny dat, takže
je velmi snadné zkontrolovat minimální a maximální hodnotu.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 47
47
Obrázek 1-4: Nastavení vlastností proměnné
Obsahuje-li označený sloupec textové hodnoty, lze si je pohlédnout pomocí tlačítka Text.
hodnoty. Zobrazí se nejen vlastní textové hodnoty, které jsou ve sloupci obsažené, ale také
čísla, která si k nim STATISTICA pracovně přiřadila – první hodnotě, která se ve sloupci
vyskytla, je přiřazeno číslo 101, druhé hodnotě 102 atd. Rozhodující pro přiřazení tohoto čísla
je pořadí, v jakém se textové hodnoty vyskytují v datové tabulce. Velmi často je nutné
přiřazená čísla změnit podle požadavků uživatele (viz kap. Tabulky četností).
Mezi jednotlivými sloupci tabulky (proměnnými) je možné se pohybovat pomocí dvojitých
šipek, není nutné pro každý sloupec zvlášť vyvolávat znovu tento dialog.
Podezřelá čísla si v datové tabulce vyhledejte např. pomocí Úpravy – Najít a opravte je na
správnou hodnotu. (Lze použít i příkaz Úpravy – Nahradit. V obou případech se jedná
o obdobu příkazů v MS Office.)
Do položky Dlouhé jméno je možné napsat jakýkoli text, který pomůže popsat vybranou
proměnnou. Např. Jméno proměnné může obsahovat text „1. otázka“ a Dlouhé jméno může
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 48
48
obsahovat znění otázky „Jste spokojeni ve svém zaměstnání?“. V grafech je potom možné
zobrazit jak Jméno proměnné, tak i Dlouhé jméno, tedy je možné do grafu přidat nejen číslo
otázky, ale i její doslovné znění. To ovšem pouze za předpokladu, že máte položku Dlouhé
jméno vyplněnou.
1.2.1 Chybějící hodnoty
Poměrně často může dojít k tomu, že některé údaje v tabulce chybí. Může to být způsobené
tím, že respondent nechtěl nebo zapomněl zodpovědět otázku nebo je jeho odpověď špatně
čitelná či nastal nějaký jiný problém. Pokud neznáme odpověď, necháváme buňku prázdnou.
V žádném případě ji nevyplňujeme otazníkem, pomlčkou a podobně.
STATISTICA umí s chybějícími daty pracovat, ale pouze v případě, že buňka zůstane
prázdná. Chybějícím datům je přiřazen kód ChD a daná buňka se nezapočítá do platných
případů. Rozsah souboru není pro danou proměnnou roven počtu respondentů, ale je nižší
o počet nevyplněných buněk. (Na obrázku 1-4 si můžete všimnout, že kód ChD je
– 9999999998. Tuto hodnotu neměňte.)
1.2.2 Práce s proměnnými
Velmi často se dostaneme do situace, kdy potřebujeme přidat další proměnné nebo případy,
což ovšem není triviální úkol. V Excelu bychom jednoduše připsali do listu další údaje.
Všimněte si, že v systému STATISTICA toto není možné, protože vaše tabulka má pouze
tolik proměnných a tolik případů, kolik jsme na počátku zadali. Pokud potřebujete přidat další
případy nebo proměnné, musíte nejprve poklepat myší vně definované tabulky a zadat počet
nových proměnných a/nebo případů.
S proměnnými můžeme pracovat i jiným způsobem, který nám kromě přidání proměnných
dovolí také proměnnou odstranit, přesunout nebo kopírovat. Stačí kliknout na záhlaví
proměnných (proměnné) pravým tlačítkem myši a z místní nabídky vybrat operaci, kterou
právě potřebujeme (Přidat proměnné …, Odstranit proměnné …, Přesunout proměnné …,
Kopírovat proměnné …) a zadat jména proměnných, se kterými chceme pracovat.
Přidání proměnné do datové tabulky použijeme zejména v případě, kdy potřebujeme na
základě proměnných z datové tabulky vypočítat novou proměnnou – např. na základě znalosti
výšky a váhy chceme spočítat BMI. Pro jednoduchost předpokládejme, že proměnná výška je
v prvním sloupci datové tabulky a proměnná váha ve druhém sloupci datové tabulky.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 49
49
Přidáme proměnnou, kterou pojmenujeme BMI a zařadíme ji jako třetí sloupec tabulky.
V dialogu vyvolaném poklepáním na záhlaví proměnné (viz obrázek 1-4) zapíšeme do
položky Dlouhé jméno příslušný vzorec, který popisuje výpočet, tedy = v2/v1/10 000. Tento
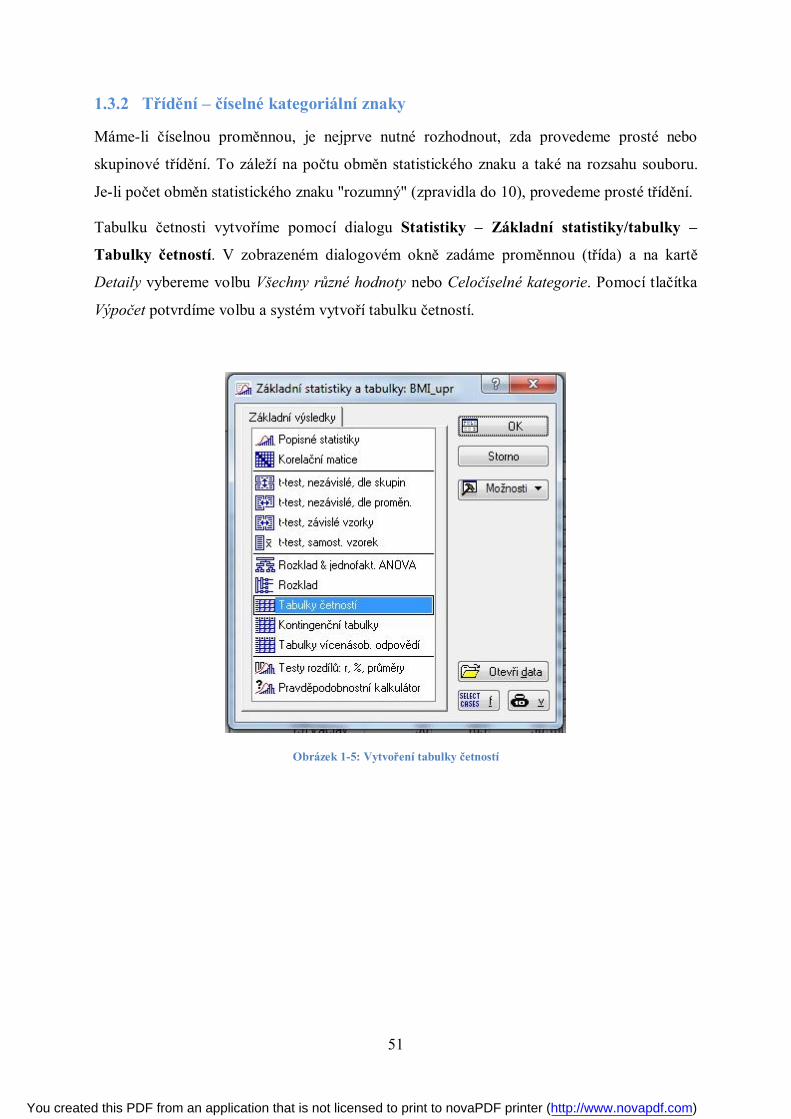
vzorec je nutné uvést znakem =, protože bez něj by nedošlo k výpočtu, program by zápis
považoval za text. Vzorec říká, že pro výpočet BMI budou použita čísla z 1. a 2. sloupce.
Pozor! Je potřeba mít na paměti, že při vkládání, odebírání nebo přesouvání proměnných se
pořadí sloupců mění a není zaručeno, že bude vzorec počítat správně. Tomuto problému
předejdeme tím, že místo pořadí proměnných zadáme do vzorce názvy proměnných, které je
nutné napsat do uvozovek. Tedy: =“váha“/“výška“/10 000. Tento zápis je složitější, musí
obsahovat přesný název proměnné a uvozovky, při výpočtu však vždy dostaneme správné
výsledky. Součet obsahuje vysoký počet desetinných míst. Označíme buňky a pomocí místní
nabídky zformátujeme tak, aby se zobrazila jen dvě desetinná místa. To je možné udělat
i v dialogu, ve kterém zadáváme vzorec, v části Formát zobrazení.
1.3 Tabulky četností
V datové tabulce jsou uloženy informace v podobě netříděných dat. Víme, jakých hodnot
nabývá zvolená proměnná pro jakýkoli případ. Toto je velmi užitečné pro další statistické
analýzy nad daty. Pro přehlednost a základní posouzení jednotlivých proměnných je však
potřeba prezentovat data v jiné podobě, v podobě tříděných dat, tedy pomocí tzv. tabulky
četností. Tato tabulka má pro každou proměnnou minimálně dva sloupce – v jednom jsou
vyjmenované všechny obměny statistického znaku a ve druhém je uvedeno, kolikrát se která
obměna v datovém souboru vyskytuje.
Přesná podoba tabulky četností závisí na typu prezentované proměnné. Z toho pohledu
rozdělujeme proměnné na:
Kategoriální
o Nominální
o Ordinální slovní
o Ordinální číselné
Spojité
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 50
50
1.3.1 Třídění slovních znaků
V tabulce četností jsou obměny slovního znaku vždy uvedeny v pořadí, které odpovídá
číslům, která si k obměnám STATISTICA pracovně přiřadila – první hodnotě, která se ve
sloupci vyskytla, je přiřazeno číslo 101, druhé hodnotě 102 atd.
Vzhledem k tomu, že u ordinální proměnné existuje přirozené pořadí obměn znaku, je nutné
nejprve zkontrolovat, jak toto pořadí STATISTICA nastavila. Poklepáním na záhlaví sloupce
se zobrazí dialog Proměnná X, ve které tlačítkem Textové hodnoty zobrazíte aktuální pořadí
obměn. Pokud neodpovídá přirozenému pořadí, je nutné ve sloupci číslo zadat nová čísla tak,
aby se vytvořilo přirozené pořadí.
Pro nominální proměnnou žádné přirozené pořadí obměn znaku neexistuje. Je však možné
a často i žádoucí jednotlivé obměny vyjmenovat podle důležitosti, tedy podle toho, jak často
se v datech vyskytují – začínáme obměnou, která má nejvyšší četnost a končíme proměnnou
s nejnižší četností. Při nastavení pořadí postupujeme stejným způsobem jako při práci
s ordinální proměnnou.
Při vytváření tabulky četností pro nominální proměnnou postupujeme následujícím způsobem:
V dialogu Statistika vybereme položku Základní statistiky/tabulky a dále Tabulky četností
(viz obrázek 1-5) a potvrdíme volbu tlačítkem OK. Nyní musíme zadat proměnné, pro které
chceme tabulky četností vytvořit. To provedeme pomocí tlačítka Proměnné – zobrazí se
seznam proměnných, ve kterém označíme myší všechny nominální proměnné (při označování
je nutné podržet klávesu CTRL, aby bylo možné vybrat více proměnných) tak, jak je ukázáno
na obrázku 1-6. Výběr proměnných potvrdíme tlačítkem OK. Dříve, než si necháme vypočítat
tabulky četností, ještě na kartě Možnosti zkontrolujeme, zda se v tabulce zobrazí hodnoty,
které požadujeme – relativní četnosti a také zpracování chybějících dat (ChD), absolutní
četnosti se zobrazují automaticky (viz obrázek 1-7). Výslednou tabulku četností vidíme na
obrázek 1-8. Použijeme tlačítko Výpočty a vytvoříme tím pro každou proměnnou vlastní
tabulku četností. V levé části okna je seznam všech vytvořených tabulek, z nichž si můžeme
myší vybírat jednotlivé tabulky. Ty se potom v pravé části okna zobrazují.
Tabulka četností pro ordinální proměnnou by měla obsahovat i kumulativní četnosti. Dříve,
než si necháme vypočítat tabulky četností, ještě na kartě Možnosti zkontrolujeme, zda se
v tabulce zobrazí hodnoty, které požadujeme – kumulativní četnosti, relativní četnosti
a kumulativní relativní četnosti. Zpracování chybějících dat (ChD) je vhodné nezahrnovat do
analýzy.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 51
51
1.3.2 Třídění – číselné kategoriální znaky
Máme-li číselnou proměnnou, je nejprve nutné rozhodnout, zda provedeme prosté nebo
skupinové třídění. To záleží na počtu obměn statistického znaku a také na rozsahu souboru.
Je-li počet obměn statistického znaku "rozumný" (zpravidla do 10), provedeme prosté třídění.
Tabulku četnosti vytvoříme pomocí dialogu Statistiky – Základní statistiky/tabulky –
Tabulky četností. V zobrazeném dialogovém okně zadáme proměnnou (třída) a na kartě
Detaily vybereme volbu Všechny různé hodnoty nebo Celočíselné kategorie. Pomocí tlačítka
Výpočet potvrdíme volbu a systém vytvoří tabulku četností.
Obrázek 1-5: Vytvoření tabulky četností
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 52
52
Obrázek 1-6: Výběr proměnné
Obrázek 1-7: Možnosti tabulky četností
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 53
53
Obrázek 1-8: Příklad tabulky četností
Třídění – číselné spojité znaky
Pokud číselná proměnná nabývá velmi mnoha hodnot, je nutné použít intervalové třídění.
Nejprve určíme počet kategorií některým z běžně používaných pravidel – podle Sturgesova
pravidla je možné např. datový soubor rozsahu 800 roztřídit na 10 tříd.
Tabulku četnosti vytvoříme pomocí dialogu Statistiky – Základní statistiky/tabulky –
Tabulky četností. V zobrazeném dialogovém okně zadáme proměnnou (IQ_celkové) a na
kartě Detaily vybereme volbu Přesný počet intervalů (hodnotu nastavíme na 10) nebo Pěkné
intervaly (hodnotu nastavíme na 10, ale je pro počítač pouze orientační) nebo Velikost kroku
(nastavíme na předem zvolenou šířku intervalu – v našem případě 10, zrušíme volbu počátek
v minimu a nastavíme počátek na předem zvolenou nejmenší hodnotu – v našem případě 60)
– viz obrázek 1-9. Pomocí tlačítka Výpočet potvrdíme volbu a systém vytvoří tabulku četností.
Obrázek 1-9: Nastavení pro intervalové třídění
1.4 Výpočet charakteristik
Modus je možné vyčíst z tabulky četností pro všechny typy proměnných velmi snadno – pro
každou proměnnou určíme modální kategorii tak, že najdeme nejvyšší četnost.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 54
54
Pro ordinální proměnnou má smysl určit i další charakteristiky, jako je minimum, maximum,
medián a oba kvartily. Minimum je první kategorie, maximum je poslední kategorie. Medián
a oba kvartily najdeme pomocí sloupce Kumulativní relativní četnost. Mediánová kategorie je
ta, ve které Kumulativní relativní četnost poprvé přesáhne 50 %. Podobně najdeme i ob
kvadrilové kategorie – jedná se o ty kategorie, ve kterých Kumulativní relativní četnost
poprvé přesáhne 25 % (dolní kvartil) a 75 % (horní kvartil).
Analogicky i pro data tříděná do intervalů je možné z tabulky četností určit interval, ve které
se nachází minimum, maximum, modus, medián a oba kvartily. Je však nutné zdůraznit, že
v důsledku ztráty části informací, ke kterému při intervalovém třídění vždy dochází, neumíme
tyto charakteristiky z tabulky četností určit přesně. Proto si necháme všechny potřebné
charakteristiky vypočítat jiným způsobem. V dialogu Statistiky – Základní
statistiky/tabulky – Popisné statistiky zadáme proměnnou (IQ_celkové) a na kartě Detaily
zvolíme charakteristiky, které chceme pro zvolenou proměnnou vypočítat. Výpočet
provedeme pomocí tlačítka Souhrn. Tímto způsobem je možné počítat kromě výše popsaných
charakteristik polohy i např. aritmetický průměr, dále charakteristiky variability (např.
rozpětí, mezikvartilové rozpětí, rozptyl, směrodatnou odchylku) a také šikmost a špičatost.
2 Grafická prezentace dat
2.1 Grafická prezentace kategoriálních dat
2.1.1 Výsečový graf
Výsečový graf, který je vhodný zejména pro nominální proměnné, lze vytvořit pomocí
příkazu Grafy – 2D grafy – Výsečové grafy. Tím se zobrazí dialog, ve kterém je 6 různých
karet – pro nás budou důležité dvě: karta Detaily a karta Možnosti 1.
Na kartě Detaily je nutné vybrat ze seznamu ty kategoriální proměnné, pro které chceme
vytvořit graf. Dále je zde možné změnit legendu (nejčastěji budeme chtít zobrazit jak text, tak
i procenta) a typ a tvar grafu (nejlépe 2D, kruhový). Intervaly četnosti necháme pro
kvalitativní proměnnou nastavenou na Celočíselný mód, ale bylo by možné vybrat i variantu
Kódy nebo Všechny hodnoty.
Na kartě Možnosti 1 vypneme zobrazení výchozího názvu. Po potvrzení tlačítkem OK se
zobrazí výsečový graf.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 55
55
Všechny součásti grafu je možné upravovat tak, že na ně poklepeme myší. Např. ve spodní
části grafu je název proměnné, který bychom raději přenesli do horní části grafu. Poklepeme
na tento text a zobrazí se dialog, ve kterém je text možné upravit. Tlačítkem Více zobrazíme
další možnosti úprav. V položce Stav vybereme Nadpis (viz obrázek 2-11)1.
Velmi užitečná funkce programu Statistica spočívá v tom, že program umožňuje vrátit se do
jednotlivých analýz. Pokud chceme použít analýzu (např. vytvořit graf), která se od
předchozí liší nastavením parametrů jen nepatrně, je možné se do posledního nastavení vrátit.
V pravém dolním rohu se po provedení analýzy uloží ikona, která umožňuje návrat do
analýzy a provedení příslušné změnu v nastavení parametrů analýzy.
Obrázek 2-11: Úprava již vytvořeného grafu
2.1.2 Sloupcový graf
Nominální proměnnou je možné popsat také sloupcovým grafem. Tato možnost je však
v praxi využívána méně často než výsečový graf a využívá se zejména tehdy, když proměnná 1 V praxi však grafy vytváříme bez nadpisu a raději každý graf opatříme titulkem.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 56
56
má více obměn a výsečový graf by byl nepřehledný. Nejčastěji však tento typ grafu použijeme
pro ordinální proměnnou.
Sloupcový graf lze vytvořit pomocí příkazu Grafy – 2D grafy – Histogramy. Tím se zobrazí
dialog, ve kterém je 6 různých karet – pro nás budou důležité dvě: karta Detaily a karta
Možnosti 1.
Na kartě Detaily je nutné zadat proměnnou (rodinný stav). Dále je zde vhodné vypnout
proložení (Typ proložení – Vypn.) a zatrhnout volbu Mezery mezi sloupci. Intervaly četnosti
necháme pro kvalitativní proměnnou nastavenou na Celočíselný mód, ale bylo by možné
vybrat i variantu Kódy nebo Všechny hodnoty.
Na kartě Možnosti 1 vypneme zobrazení výchozího názvu. Po potvrzení tlačítkem OK se
zobrazí sloupcový graf. Všechny jeho součásti je opět možné upravovat tak, že na ně
poklepeme myší. Ukázka sloupcového grafu je na obrázku 2-12.
svobodný/á ženatý/vdaná vdovec/vdova rozvedený/á
rodinný stav
0
200
400
600
800
1000
1200
1400
1600
1800
2000
2200
Poče
t poz
orov
ání
Obrázek 2-12: Ukázka sloupcového grafu
2.2 Filtr, kategorizované grafy
Někdy budeme potřebovat vytvořit graf jen z vybraných záznamů. Např. ke každému
respondentu budu mít informaci o jeho ekonomickém postavení (např.: student, zaměstnanec,
podnikatel, důchodce, atd.). Nyní již nebudeme pracovat se všemi záznamy, ale jen s těmi
záznamy, které mají v proměnné Ekonomické postavení hodnotu podnikatel. Za tímto účelem
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 57
57
použijeme nástroj Filtr pro výběr případů, který nám umožní pracovat jen s některými
případy podle předem zadaných kritérií.
Na stavovém řádku (vpravo dole) je položka Filtr, která označuje, zda je Filtr zapnut (+) nebo
vypnut (–). Kliknutím na ni se objeví dialog Filtr – podmínky výběru případů, který
umožňuje filtr měnit, vypínat a zapínat (viz obrázek 2-13).
V tomto dialogu je nutné zaškrtnout políčko Povolit podmínky výběru, čímž se zpřístupní
pole pro definování podmínek. My chceme Zahrnout případy – vybrané výrazem: např.:
v10=“podnikatel“ (v10 označuje číslo proměnné; obměnu podnikatel je nutné uvést
v uvozovkách, neboť se jedná o kvalitativní proměnnou – nastavení je vidět na obrázku 2-13).
Pro větší přehlednost bychom chtěli, aby se vybrané případy nějak vyznačily v tabulce. Proto
ještě přepneme na kartu Zobrazit a zaškrtneme volbu Použít zadaný formát …. Pomocí
tlačítka Upravit formát je možné nastavit formát, jaký se nám líbí (např. červené písmo). Nyní
potvrdíme volbu tlačítkem OK. Tímto jsme zapnuli filtr, který se projeví ve všech nově
spuštěných analýzách!!! Pokud budeme chtít v budoucnu pracovat se všemi záznamy, bude
nutné filtr vypnout a opět spustit novou analýzu!!!
Nyní vytvoříme sloupcový graf, ze kterého je zřejmé, že podnikatelé se na svých cestách
věnují převážně rekreaci a sportu – viz obrázek 2-14.
Dále nás zajímají důchodci. Ve filtru pouze zaměníme slovo „podnikatel“ za slovo
„důchodce“ a potvrdíme OK. Nyní musíme spustit novou analýzu, tedy opět jít do nabídky
Grafy – 2D grafy – Histogramy. V grafu vidíme, že důchodci nejčastěji navštěvují příbuzné
a známé, ale také se věnují rekreaci a sportu a jezdí na své chaty a chalupy (viz obrázek 2-14).
Na závěr práce s filtry je nutné opět filtr vypnout tím, že zrušíme zaškrtnutí v políčku Povolit
podmínky výběru.
Ve sloupcových grafech bude ještě vhodné upravit text v nadpisu a místo v10 napsat raději
jméno proměnné, tedy ekonomické postavení. Nebo raději hned při nastavování filtru do pole
výrazem: napsat ekonomické postavení = "podnikatel".
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 58
58
Obrázek 2-13: Ukázka nastavení filtru
Dva grafy na obrázku 2-14 mohou sloužit jako ukázka tzv. kategorizovaného grafu.
Kategorizované grafy slouží k porovnání odpovědí respondentů různých kategorií. Tedy
kromě zkoumané proměnné musíme zadat i tzv. grupovací proměnnou, která je kategoriální
a počet obměn této proměnné určuje počet jednotlivých grafů, které v rámci kategorizovaného
grafu vzniknou. Příklad kategorizovaného grafu je vidět na obrázku 2-15.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 59
59
Obrázek 2-14: Ukázka nastavení filtru
Výsečový kategorizovaný graf vytvoříme pomocí nabídky Grafy – 2D grafy – Výsečové
grafy. Tím se zobrazí dialog, ve kterém je 6 různých karet – pro nás budou tentokrát důležité
tři: karta Detaily, karta Kategorizovaný a karta Možnosti 1.
Na kartě Detaily je nutné zadat proměnnou, kterou chceme graficky prezentovat. Dále je zde
možné změnit legendu (zobrazíme jak text, tak i procenta) a typ a tvar grafu. Intervaly
četnosti necháme pro kvalitativní proměnnou nastavenou na Celočíselný mód, ale bylo by
možné vybrat i variantu Kódy nebo Všechny hodnoty.
Na kartě Kategorizovaný zaškrtneme v části Kategorie X políčko Zapnout a vybereme
proměnnou, podle které chceme vytvořit kategorie. Na kartě Možnosti 1 vypneme zobrazení
výchozího názvu. Po potvrzení tlačítkem OK se zobrazí několik výsečových grafů. Všechny
jejich součásti je možné upravovat tak, že na ně poklepeme myší.
doprava
rodinný stav: svobodný/á
autobus; 5%
železnice; 3%
ostatní; 1%
automobil; 13%
rodinný stav: ženatý/vdaná
autobus; 4%železnice; 4%
ostatní; 1%
automobil; 47%
rodinný stav: vdovec/vdova
autobus; 3%
železnice; 2%
ostatní; 0%
automobil; 6%
rodinný stav: rozvedený/á
autobus; 3%
železnice; 2%
automobil ; 5%
autobus; 5%
železnice; 3%
ostatní; 1%
automobil; 13%
autobus; 4%železnice; 4%
ostatní; 1%
automobil; 47%
autobus; 3%
železnice; 2%
ostatní; 0%
automobil; 6%
autobus; 3%
železnice; 2%
ostatní; 0%
automobil ; 5%
Obrázek 2-15: Ukázka kategorizovaného výsečového grafu
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 60
60
Všimněte si, že některé popisky se překrývají. To, bohužel, verze STATITICA 10 neumí
opravit.
2.3 Spojitá proměnná
Pro proměnnou, která nabývá mnoha hodnot, je nutné použít skupinové třídění a pro tento typ
proměnné je nejvhodnějším typem grafu histogram nebo krabicový graf. Oba grafy jsou běžné
a často používané, proto jsou přístupné i přímo z hlavní nabídky Grafy.
2.3.1 Histogram
Histogram je možné vytvořit pomocí nabídky Grafy – 2D grafy – Histogramy. Intervaly
četnosti nastavíme pro spojitou proměnnou nastavenou na Kategorie a zvolíme počet
intervalů. Program provede automaticky nastavení intervalů tak, aby byly stejně široké.
Ukázka vzhledu histogramu je na obrázku 2-16.
Vybereme-li pro zobrazení v grafu více proměnných, je možné udělat pro každou z nich
vlastní histogram nebo změnit typ grafu na Vícenásobný dát všechny proměnné do jednoho
grafu, ve kterém bude více různobarevných řad.
Obrázek 2-16: Ukázka histogramu s proložení normálním rozdělením
2.3.2 Krabicový graf
Krabicový graf je možné vytvořit pomocí příkazu Grafy – 2D grafy – Krabicový. Ukázka
nastavení dialogu pro tvorbu krabicového grafu je na obrázku 2-17. Zde je vidět, že je možné
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 61
61
v grafu prezentovat medián nebo průměr. Průměr volíme tehdy, má-li proměnná normální
rozdělení. Zpravidla používáme medián, který je "univerzální".
Obrázek 2-17: Ukázka nastavení pro krabicový graf
Vybereme-li pro zobrazení v grafu více proměnných, je možné udělat pro každou z nich
vlastní krabicový graf nebo změnit typ grafu na Vícenásobný a dát všechny proměnné do
jednoho grafu, ve kterém bude pro každou proměnnou vlastní krabice. Ukázka vícenásobného
krabicového grafu je na obrázku 2-18.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 62
62
Obrázek 2-18: Ukázka vícenásobného krabicového grafu
Histogramy i krabicové grafy je možné vytvořit i během intervalového třídění (Statistiky –
Základní statistiky/tabulky – Krabicové grafy nebo Statistiky – Základní
statistiky/tabulky – Tabulky četností).
Na listu Základ nebo na listu Detaily je tlačítko Histogram, na listu Popisné tlačítko
Krabicové diagramy …. Pokud vytvoříme histogram z tohoto nastavení, použijí se do grafu
intervaly, které byly použity při tvorbě tabulky četností.
2.4 Závislost proměnných – bodový graf
Pro grafické prezentování a posuzování vztahu dvou proměnných se používá bodový graf.
Je-li jedna proměnná závislá na druhé proměnné (např. váha může být závislá na výšce
člověka), je nutné tuto závislou proměnnou umístit na svislou osu y.
Obrázek 2-19: Ukázka bodového grafu – závislost mezi výsledky z testu v matematice a cizím jazyce
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 63
63
Na obrázku 2-19 je prezentován vztah mezi výsledky z testu v matematice a cizím jazyce. Zde
nedokážeme rozhodnout, která proměnná je závislá a která nezávislá, takže je jedno, kterou
z proměnných umístíme na osu x a kterou na osu y.
Bodový graf je možné vytvořit pomocí příkazu Grafy – 2D grafy – Bodový. I tento graf je
často používán, proto je přístupný i přímo z hlavní nabídky Grafy. V nastavení je na listu
Základní nutné správně zvolit proměnné a dále je zde možnost proložit body tzv. regresní
přímkou.
2.5 Spojnicový graf
Spojnicový graf nejčastěji používáme k prezentování časových řad. Jedná se o další z velmi
často používaných grafů, takže i jej najdeme v hlavní nabídce grafů Grafy – 2D grafy –
Spojnicový. Na listu Základní vybereme proměnné a dále je zde možnost, vybereme-li pro
zobrazení v grafu více proměnných, udělat pro každou z nich vlastní graf nebo změnit typ
grafu na Vícenásobný a dát všechny spojnice do jednoho grafu.
I časovou řadu má smysl prokládat tzv. trendovou přímkou. Tu do grafu přidáme tak, že na
kartě Detaily vybereme lineární proložení dat. Ukázka vícenásobného spojnicového grafu
včetně proložení trendovou přímkou je na obrázku 2-20.
Obrázek 2-20: Ukázka vícenásobného spojnicového grafu vývoj míry registrované nezaměstnanosti v ČR v %
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 64
64
3 Korelační analýza
3.1 Pearsonova korelační analýza
Úkol 1: Otevřete soubor absence.sta a zjistěte, zda existuje vztah mezi počtem dní absence za
rok (proměnná Y) a věkem pracovníka (proměnná X).
Řešení:
Z hlavní nabídky vybereme Statistiky – Základní statistiky/tabulky – Korelační matice a
volbu potvrdíme tlačítkem „OK“. Nyní pomocí tlačítka „1 seznam proměn.“ zadáme obě
proměnné (lze použít tlačítko „Vybrat vše“ a potvrdíme „OK“).
Předpoklad o dvourozměrné normalitě dat ověříme orientačně pomocí 2D bodového grafu.
Ten je možné vytvořit na kartě Detaily pomocí tlačítka „2D bodové grafy“ nebo „se jmény“
vpravo od něj. Bodový graf „se jmény“ je znázorněn na obrázku 3-1.
Obrázek 3-1
Při splnění předpokladu o dvourozměrné normalitě dat by body měly ležet uvnitř pomyslné
elipsy. Vzhled grafu svědčí o tom, že předpoklad je oprávněný.
Nyní se vrátíme do dialogu Korelace a parciální korelace. Pomocí tlačítka „Výpočet:
Korelační matice“ zobrazíme korelační matici (viz obrázek 3-2).
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 65
65
Obrázek 3-2
Korelační koeficient pro proměnné věk a pohlaví nabývá hodnoty –0,93, což ukazuje na
silnou nepřímou lineární závislost mezi těmito proměnnými. Koeficient je navíc zvýrazněn
červenou barvou, takže je i statisticky významný (tedy různý od 0).
Úkol 2: V tabulce Test.sta jsou výsledky osmi náhodně vybraných studentů ze dvou
předmětů. Určete parametry obou sdružených regresních přímek, odhadněte počet bodů z
druhého testu, jestliže z prvního testu dostal student 90 bodů a počet bodů z prvního testu,
jestliže student z druhého testu získal 10 bodů. Dále vypočítejte korelační koeficient a na
hladině významnosti = 0,05 otestujte hypotézu, že neexistuje lineární závislost mezi
výsledky obou testů.
Řešení:
Na položené otázky je možné odpovědět pomocí 2D grafu, který vytvoříme z nabídky Grafy
– Bodové grafy. Na kartě Detaily zatrhneme volby „R kvadrát“, „Korelace a p“ a „Regresní
rovnice“. Jako proměnnou X označíme 1. test a do proměnné Y vložíme 2. test. Výsledný graf
je zobrazen na obrázku 3-3.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 66
66
Obrázek 3-3
Koeficient determinace nabývá hodnoty 0,39, tedy příslušná regresní přímka (y = 19,9 + 0,5x)
vysvětluje 39 % variability závisle proměnné. Pokud do rovnice této regresní přímky
dosadíme za x = 90, získáme příslušný odhad počtu bodů z 2. testu: 64,9. U studentů, kteří
v prvním testu dosáhli 90 bodů, tedy můžeme ve druhém testu očekávat průměrně 65 bodů.
Korelační koeficient nabývá hodnoty 0,63, ale p-hodnota 0,097 nedovoluje zamítnout nulovou
hypotézu, takže o těsnosti závislosti nemůžeme dělat žádné závěry. Je to důsledek malého
rozsahu souboru. Na základě pozorování daného výběru se nepodařilo prokázat, že existuje
závislost mezi výsledky obou testů.
Nyní se vrátíme do dialogu 2D bodové grafy a zaměníme proměnné – 2. test do proměnné X
a 1. test do proměnné Y a potvrdíme klávesou „OK“. Výsledný graf je na obrázku 3-4.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 67
67
Obrázek 3-4
Koeficient determinace, korelační koeficient a p-hodnota vyšly shodně s předchozími
výpočty. Rovnice druhé regresní přímky vyšla poněkud odlišně. Pokud do ní za x dosadíme
10, dostáváme y = 28,7. U studentů, kteří dosáhli ve druhém testu 10 bodů, lze očekávat, že
v prvním testu získali průměrně 29 bodů.
Úloha 3: Při zkoumání hodinové výkonnosti dělníka (proměnná Y) na jeho věku (proměnná
X1) a době zapracování (proměnná X2) byly zjištěny údaje, které jsou uvedeny v souboru
vykon.sta. Určete párové koeficienty korelace a jejich statistické významnosti a také parciální
koeficienty korelace a jejich statistické významnosti.
Řešení:
Z hlavní nabídky vybereme Statistiky – Základní statistiky/tabulky – Korelační matice a
volbu potvrdíme tlačítkem „OK“. Nyní pomocí tlačítka „1 seznam proměn.“ zadáme všechny
tři proměnné (lze použít tlačítko „Vybrat vše“ a potvrdíme „OK“).
Předpoklad o vícerozměrné normalitě dat lze orientačně ověřit pomocí 3D bodového grafu.
Ten je možné vytvořit na kartě Detaily pomocí tlačítka „3D bodové grafy“ nebo „se jmény“
vpravo od něj.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 68
68
Pomocí tlačítka „Výpočet: Korelační matice“ vytvoříme symetrickou matici, která obsahuje
všechny párové koeficienty korelace. Červeně jsou navíc vyznačeny ty koeficienty, které jsou
statisticky významné. Výsledná korelační matice je zachycena na obrázku 3-5.
Obrázek 3-5
Z korelační matice vyplývá, že mezi hodinovou výkonností dělníka a jeho věkem (resp. dobou
zapracování) existuje slabá (0,23), resp. nepříliš těsná (0,45) závislost. Tyto výsledky však
nejsou statisticky významné, což je způsobeno především malým rozsahem souboru. Hodnoty
těchto korelačních koeficientů jsou ovlivněny dosti silnou závislostí mezi věkem a dobou
zapracování dělníka (0,85), který je statisticky významný. Kladná hodnota koeficientu
korelace znamená, že se jedná o přímou závislost – vyššímu věku dělníka odpovídá větší doba
zapracovanosti.
3.2 Pořadová korelace
Úkol 1: Na základě údajů v souboru Domacnosti.sta, který obsahuje pořadí 15 náhodně
vybraných domácností podle vybavenosti a podle podílu výdajům služby, máme ověřit
hypotézu, že podíl výdajů domácnosti na služby nezávisí na vybavenosti domácnosti
předměty dlouhodobé spotřeby.
Řešení:
Z hlavní nabídky vybereme Statistiky – Neparametrická statistika – Korelace (Spearman,
Kendallovo tau, gama). Pomocí tlačítka „Proměnné“ vybereme obě proměnné a tlačítkem
„Spermanovo R“ vypočítáme Spearmanovy korelační koeficienty mezi proměnnými.
Výslednou korelační matici vidíme na obrázku 3-6.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 69
69
Obrázek 3-6
Spearmanův korelační koeficient vyšel –0,16, ale není statisticky významný. Nemůžeme tedy
potvrdit, že podíl výdajů na služby s rostoucí vybaveností klesá.
Úkol 2: V souboru Obrat.sta je uveden obrat zahraničního obchodu (proměnná Y) a počet
obyvatel (proměnná X) několika vybraných států. Zjistěte, zda existuje závislost mezi obratem
a počtem obyvatel.
Řešení:
Nejprve si data prohlédneme pomocí bodového grafu. V nabídce Grafy – Bodové grafy
zadáme proměnné a potvrdíme tlačítkem „OK“. Z bodového grafu, který je uveden na
obrázku 3-7, je zřejmé, že proměnná X obsahuje odlehlá pozorování, a proto použijeme jako
míru závislosti Spermanův korelační koeficient.
Z hlavní nabídky vybereme Statistiky – Neparametrická statistika – Korelace (Spearman,
Kendallovo tau, gama). Pomocí tlačítka „Proměnné“ vybereme obě proměnné a tlačítkem
„Spermanovo R“ vypočítáme Spearmanovy korelační koeficienty mezi proměnnými.
Výslednou korelační matici vidíme na obrázku 3-8.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 70
70
Obrázek 3-7
Obrázek 3-8
Spermanův korelační koeficient vyšel 0,66 a je statisticky významný. To ukazuje na středně
silnou závislost mezi pořadím podle počtu obyvatel a pořadím podle velikosti obratu
zahraničního obchodu.
4 Lineární regrese
4.1 Jedna nezávislá proměnná
Úkol 1: V souboru Poptavka.sta jsou uvedeny údaje od šesti obchodníků, kteří uvedli
poptávku po jistém druhu zboží v loňském a letošním roce.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 71
71
Odhadněte parametry regresní přímky, která vystihuje závislost letošní poptávky (proměnná
Y) na loňské poptávce (proměnná X) a tyto koeficienty interpretujte. Určete, kolik procent
variability závisle proměnné model vysvětluje.
Dále odhadněte střední hodnotu letošní poptávky při loňské poptávce 110 ks.
Zhodnoťte rezidua a rozhodněte, zda je použití lineárního modelu pro tento případ vhodné.
Řešení:
Nejprve si prohlédneme data a prověříme, zda neobsahují nějaké odlehlé hodnoty (chyby
nebo netypické případy), které by mohly výsledky regrese zkreslit. Vytvoříme bodový graf,
ve kterém na ose x bude nezávislá proměnná (loňská poptávka) a na ose y závislá proměnná
(letošní poptávka). V nabídce Grafy – Bodové grafy zadáme proměnné a potvrdíme
tlačítkem „OK“. Z bodového grafu, který je uveden na obrázku 4-1, je zřejmé, že data
neobsahují odlehlé hodnoty.
Obrázek 4-1
Pro odhad regresního modelu vybereme z nabídky Statistiky – Vícerozměrná regrese
a zadáme proměnné: závislá proměnná – letos, nezávislá proměnná – loni. Klikneme dvakrát
na „OK“, načež STATISTICA vypočítá odhad modelu a zobrazí základní výsledky. Tytéž
výsledky ve formě přehledné tabulky získáme přes tlačítko „Výpočet: výsledky regrese“ na
záložce Základní výsledky. Tato tabulka je na obrázku 4-2.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 72
72
Obrázek 4-2
Z této tabulky lze vyčíst celou řadu důležitých informací. Regresní model lze popsat vztahem
Y = 0,69 + 1,27X. Zatímco koeficient 1,27 je statisticky významný (nenulový), má tedy
v modelu své opodstatnění, statistická významnost absolutního členu se nepodařilo prokázat.
Koeficient determinace R2 = 0,945 říká, že tento regresní model vysvětluje 94,5 % variability
závisle proměnné (letošní poptávka).
Pro předpovězení hodnoty závisle proměnné ze znalosti nezávisle proměnné přepneme na
záložku Rezidua/předpoklady/předpovědi. Pomocí tlačítka „Předpověď závisle proměnné“
zadáme hodnotu 110 pro nezávisle proměnnou. Potvrdíme „OK“ a ve výsledné tabulce (viz
obrázek 4-3) zjistíme jednak předpověď průměrné hodnoty závisle proměnné (140) a také
konfidenční interval pro tuto předpověď.
Obrázek 4-3
Závěrem je ještě nutné prohlédnout rezidua a jejich náhodnost. Na záložce
Rezidua/předpoklady/předpovědi použijeme tlačítko „Reziduální analýza“ a dále na záložce
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 73
73
Rezidua tlačítko „Rezidua vs. nezávislé prom.“ a zadáme nezávisle proměnnou (loni). Na
výsledném grafu vidíme (viz obrázek 4-4), že rezidua jsou v tomto grafu rozmístěna náhodně.
Obrázek 4-4
Úkol 2: V souboru Spotreba.sta jsou uvedeny informace o průměrně spotřebě auta při
různých rychlostech. Ověřte, zda je vhodný pro popis závislosti spotřeby na rychlosti lineární
model.
Řešení:
Vytvoříme 2D bodový graf (viz obrázek 4-5), ze kterého je již vidět, že závislost spotřeby na
rychlosti není lineární (spotřeba nejprve klesá a pro vyšší rychlosti opět stoupá) a lineární
model tedy není vhodný. Podívejme se však, jaké koeficienty by tento lineární model
obsahoval a jak by se nevhodnost modelu projevila na reziduích.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 74
74
Obrázek 4-5
Z tabulky na obrázku 4-6 je vidět, že oba koeficienty jsou statisticky významné a model
vysvětluje 65,6 % variability závisle proměnné. Přesto použití tohoto lineárního modelu není
vhodné. Je to zřejmé z grafu rezidua vs. nezávislá proměnná, který je na obrázku 4-7. Body
nejsou rozmístěny náhodně, tvoří přibližně parabolu.
Obrázek 4-6
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 75
75
Obrázek 4-7
4.2 Více nezávislých proměnných
Úkol 3: V souboru Vydaje.sta jsou údaje o měsíčních výdajích na potraviny a nápoje
(proměnná Y), počtu členů domácnosti (proměnná X1), počtu dětí (proměnná X2), průměrném
věku vydělávajících členů domácnosti (proměnná X3) a měsíčním příjmu domácnosti
(proměnná X4), které byly zjištěné u 20 náhodně vybraných domácností. Rozhodněte, které
proměnné významně přispívají k vysvětlení variability výdajů, a zkonstruujte lineární regresní
model s nejlepší podmnožinou vysvětlujících proměnných.
Řešení:
Pro odhad regresního modelu vybereme z nabídky Statistiky – Vícerozměrná regrese a
zadáme proměnné: závislá proměnná – výdaje, nezávislé proměnné – všechny ostatní. Volbu
potvrdíme „OK“ a na kartě „Detailní nastavení“ zatrhneme volbu „Další možnosti (kroková
nebo hřebenová regrese)“. Potvrdíme „OK“ a na záložce „Základ“ nebo „Detaily“ zvolíme
metodu.
Metodu můžeme zvolit „Vš. efekty“, „Kroková dopředná“ nebo „Kroková zpětná“. Volbu
metody potvrdíme „OK“ a zobrazíme pomocí tlačítka „Výpočet: výsledky regrese“ na záložce
Základní výsledky výsledný model ve formě přehledné tabulky.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 76
76
Analýza poskytuje výsledek v podobě tabulky vždy pro zvolenou metodu. Chceme-li provést
výpočet jinou metodou, je nutné v analýze učinit jeden krok zpět (tlačítko "Storno") a změnit
zvolenou metodu. Takto postupně jsme schopni získat výsledky analýzy s použitím všech
třech metod.
Tyto výsledky jsou v podobě tabulek uvedeny na následujících obrázcích. Na obrázku 4-8 je
model získaný metodou Všechny efekty, na obrázku 4-9 je model získaný Krokovou
dopřednou metodou a na obrázku 4-10 je model získaný Krokovou zpětnou metodou.
Obrázek 4-8
Obrázek 4-9
Obrázek 4-10
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 77
77
Model, získaný metodou Všechny efekty, není vhodný, protože žádný z koeficientů B není
statisticky významný. Model získaný Krokovou dopřednou metodou je vhodnější než model
získaný Krokovou zpětnou metodou, protože jak koeficient determinace (R2), tak i jeho
nezkreslený odhad (Upravené R2) jsou vyšší. Posuzujeme-li modely s různým počtem
vstupujících nezávislých proměnných, kvality modelů je potřeba posuzovat podle Upraveného
R2.
Nejlepší lineární regresní model má tvar Y = –3063,80 + 2648,92X1 + 105,65X3. Vysvětluje
více než 65 % variability závisle proměnné. Tento model zařazuje proměnné X1 (počet členů
domácnosti) a X3 (průměrný věk vydělávajících členů domácnosti), další proměnné již model
nezahrnuje.
5 Testování hypotéz
5.1 Kontingenční tabulky
Úkol 1: Otevřete soubor CR2.sta a vytvořte kontingenční tabulku pro proměnné doprava
a rodinný stav. Zobrazte hodnoty z tabulky graficky.
Řešení:
Z hlavní nabídky vybereme nabídky Statistika – Základní statistiky/tabulky –
Kontingenční tabulky. V dialogu Kontingenční tabulky vybereme proměnné pomocí tlačítka
„Specif. tabulky (vyberte proměnné)“. Do 1. seznamu proměnných zadáme proměnnou
Doprava a do 2. seznamu proměnných proměnnou Rodinný stav. Volbu potvrdíme dvakrát
tlačítkem „OK“. Kontingenční tabulku (viz obrázek 5-1) vytvoříme tlačítkem „Výpočet“.
Obrázek 5-1
Pro vytvoření grafů je nutné se vrátit do dialogu Výsledky; Kontingenční tabulky a zde použít
tlačítko „Kategoriz. histogramy“, resp. „Grafy interakcí mezi četnostmi“ (viz obrázek 5-2).
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 78
78
V obou grafech je nápadný nárůst dopravy osobním autem u ženatých/vdaných respondentů.
G r af int er akcí : dopr ava x r odinný st av
sv
ob
od
ný
/á
že
na
tý
/v
da
ná
vd
ov
ec
/v
do
va
ro
zv
ed
en
ý/
á
r odinný st av
- 100
0
100
200
300
400
500
600
Če
tn
os
ti
Obrázek 5-2
Úkol 2: Doplňte kontingenční tabulku o procenta z počtu ve sloupci. Zároveň změňte
nastavení tak, aby se červeně zvýraznily četnosti větší než 5.
Řešení:
Opět je nutné se vrátit do dialogu Výsledky; Kontingenční tabulkya přepnout na záložku
Možnosti. Zde nastavíme jak zvýraznění četností > 5, tak také zatrhneme volbu „Procenta
z počtu ve sloupci“. Novou tabulku (viz obrázek 5-3) vytvoříme tlačítkem „Výpočet“.
Obrázek 5-3
Úkol 3: Otevřete soubor CR2.sta a prozkoumejte závislost nominálních proměnných doprava
a ekonomické postavení.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 79
79
Řešení:
Z hlavní nabídky vybereme nabídky Statistika – Základní statistiky/tabulky –
Kontingenční tabulky. V dialogu Kontingenční tabulky vybereme proměnné pomocí tlačítka
„Specif. tabulky (vyberte proměnné)“. Do 1. seznamu proměnných zadáme proměnnou
Doprava a do 2. seznamu proměnných proměnnou ekonomické postavení. Volbu potvrdíme
dvakrát tlačítkem „OK“.
Nyní přepneme na záložku Možnosti. Zde zatrhneme dvě volby: Pearsonův& M–V chí-
kvadrát a Fí &Cramérovo V & C. Přepneme zpět na záložku Detailní výsledky a výpočet
provedeme pomocí tlačítka „Detailní 2-rozměrné tab.“. Výstupem jsou dvě tabulky –
kontingenční tabulka a tabulka statistik, která je znázorněna na obrázku 5-4.
Obrázek 5-4
Nejdříve se podíváme na p-hodnotu chí-kvadrát tesu o nezávislosti. Ta je menší než 0,05,
zamítáme tedy nulovou hypotézu a přijímáme hypotézu: proměnné jsou závislé. Sílu
závislosti popisují další tři koeficienty. Pro naše účely vybereme Cramérovo V, protože
nabývá pouze hodnoty z intervalu 0, 1. Hodnota 0,217 ukazuje na slabší závislost.
Úkol 4: V souboru IQ.sta prozkoumejte závislost ordinálních proměnných vzdělání matky
a vzdělání otce.
Řešení:
Z hlavní nabídky vybereme nabídky Statistika – Základní statistiky/tabulky –
Kontingenční tabulky. V dialogu Kontingenční tabulky vybereme proměnné pomocí tlačítka
„Specif. tabulky (vyberte proměnné)“. Do 1. seznamu proměnných zadáme proměnnou
vzdělání matky a do 2. seznamu proměnných proměnnou vzdělání otce. Volbu potvrdíme
dvakrát tlačítkem „OK“.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 80
80
Nyní přepneme na záložku Možnosti. Zde zatrhneme volbu Spearmanovakorelace. Přepneme
zpět na záložku Detailní výsledky a výpočet provedeme pomocí tlačítka „Detailní 2-rozměrné
tab.“. Výstupem jsou dvě tabulky – kontingenční tabulka a tabulka statistik, která je
znázorněna na obrázku 5-5.
Obrázek 5-5
Nejdříve se podíváme na p-hodnotu. Ta je menší než 0,05, zamítáme tedy nulovou hypotézu
o nezávislosti proměnných a přijímáme hypotézu: proměnné jsou závislé. Hodnota
Spearmanova pořadového R = 0,612 signalizuje středně silnou pozitivní závislost mezi
proměnnými.
5.2 Neparametrické testy
Úkol 1: Otevřete soubor IQ1.sta. Rozhodněte, zda je IQ chlapců stejné jako IQ dívek nebo
zda se navzájem liší.
Řešení:
Stanovíme nulovou hypotézu H0: IQ chlapců je stejné jako IQ dívek a alternativní hypotézu
H1: IQ chlapců a IQ dívek se liší.
Neparametrické testy najdeme v dialogu Statistiky – Neparametrické testy – Porovnání
dvou nezávislých vzorků (skupin). Závislá proměnná je v tomto případě IQ, protože její
střední hodnoty chceme porovnávat. Grupovací proměnnou je Pohlaví. Z nabídky testů
vybereme Mann-Whitneyův U test. Výstupem je tabulka uvedená na obrázku 5-6
Obrázek 5-6
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 81
81
p-hodnota Mann-Whitneyova U testu je větší než 0,05, takže nulovou hypotézu nezamítáme a
považujeme IQ chlapců a dívek za stejná.
Pokud bychom chtěli tuto zjištěnou skutečnost ještě graficky znázornit, vrátíme se do dialogu
Porovnání dvou skupin a v něm vybereme Krabicový graf dle skupin. Výsledný graf je na
obrázku 5-7.
Obrázek 5-7
Úkol 2: Otevřete soubor Animal Weights.sta. Rozhodněte, zda je hmotnost kontrolní skupiny
stejná jako hmotnost léčené skupiny nebo zda se navzájem liší.
Řešení:
Stanovíme nulovou hypotézu H0: Hmotnost kontrolní skupiny je stejná jako hmotnost léčené
skupiny a alternativní hypotézu H1: Hmotnost kontrolní skupiny a hmotnost léčené skupiny se
liší.
Jelikož se jedná o dvě nezávislé skupiny, vybereme z hlavní nabídky Statistiky –
Neparametrické statistiky – Porovnání dvou nezávislých vzorků (skupiny). V dialogu,
který se otevře, zadáme proměnné (závislá proměnná: WEIGHT, grupovací proměnná:
GROUP) a vybereme Mann-Whitneyův U test, který neprokazuje rozdíl mezi testovanými
skupinami (p-hodnota je 0,1939). Na obrázku 5-8 je však jistý rozdíl mezi hodnotami zřejmý.
Použijeme-li test Wald–Wolfowitzův, je vypočítaná p-hodnota testu 0,0369. Tento test tedy
rozdíl mezi testovanými skupinami prokázal.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 82
82
Obrázek 5-8
Úkol 3: Otevřete soubor nehody.sta. Rozhodněte, zda je počet nehod v roce 2003 stejný jako
počet nehod v roce 2005 nebo zda se tyto počty navzájem liší.
Řešení:
Stanovíme nulovou hypotézu H0: Počty nehod jsou v obou letech stejné a alternativní
hypotézu H1: Počty nehod v obou letech se liší.
Protože se jedná o dvě závislé proměnné, vybereme z nabídky Statistiky – Neparametrické
testy – Porovnání dvou závislých vzorků (proměnné). Zadáme proměnné tak, že do
1. seznamu proměnných zadáme rok 2003 a do 2. seznamu proměnných rok 2005. Nyní
pomocí tlačítka „Wilkoksonův párový test“ zobrazíme výsledek testu. 푝-hodnota je 0,0376,
což znamená, že nulovou hypotézu zamítáme. Počty nehod v obou letech se liší.
Vraťme se nyní do dialogu „Porovnání dvou závislých vzorků“ a vytvořme pro obě proměnné
krabicové grafy – pomocí tlačítka „Krabicový graf“. Z nabídky čtyř typů vybereme
„Průměr/SmOdch/1,96*SmOdch“ (tato volba je odůvodněna normálním rozdělením u obou
proměnných). Výsledný graf vidíme na obrázku 5-9.
Krabicový graf dle skupinProměnná: WEIGHT (lbs)
Medián 25%-75% Min-Max
Control TreatmentGROUP
9
10
11
12
13
14
15
16
17
18
WEI
GH
T (lb
s)
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 83
83
Obrázek 5-9
Úkol 4: Otevřete soubor CR1.sta. Rozhodněte, zda je střední hodnota počtu strávených nocí
na cestě stejná v červenci a v prosinci nebo zda se tyto hodnoty navzájem liší. (Všimněte si,
že tato data obsahují pouze odpovědi respondentů, kteří cestovali v červenci a v prosinci
Proměnnou měsíc lze považovat za grupovací.)
Řešení:
Stanovíme nulovou hypotézu H0: střední hodnota počtu strávených nocí na cestě je stejná
v červenci a v prosinci a alternativní hypotézu H1: střední hodnota počtu strávených nocí na
cestě v červenci a v prosinci se liší.
Použijeme neparametrický test, který najdeme v dialogu Statistika – Neparametrické
statistiky – Porovnání dvou nezávislých vzorků (skupiny). V dialogu, který se otevře,
zadáme proměnné (závislá proměnná: počet nocí, grupovací proměnná: měsíc) a vybereme
test.
Všechny tři testy (Wald–Wolfowitzův, Kolmogorov–Smirnovův i Mann–Whiteyův U test)
prokázaly rozdíly mezi počtem nocí strávených na cestě v červenci a v prosinci (ve všech
třech případech je p-hodnota menší než 0,05).
Pro úplnou představu lze ještě data znázornit graficky pomocí krabicového grafu. Z tohoto
grafu je vidět, že počet nocí strávených na cestě v červenci je vyšší než počet nocí strávených
na cestě v prosinci.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 84
84
5.3 T-testy
Úkol 1: Otevřete soubor IQ1.sta. Rozhodněte, zda je IQ chlapců stejné jako IQ dívek nebo
zda se navzájem liší.
Řešení:
Nejprve je nutné otestovat předpoklady pro použití dvouvýběrového t-testu. Pomocí popisné
statistiky zjistíme, kolik se výzkumu zúčastnilo chlapců a kolik dívek. Chlapců bylo 426
a dívek 430. To znamená, že oba předpoklady (četnost v obou skupinách > 30 a v obou
skupinách přibližně stejná: 430/426 = 1,009 < 1,500) jsou splněné.
Stanovíme nulovou hypotézu H0: IQ chlapců je stejné jako IQ dívek a alternativní hypotézu
H1: IQ chlapců a IQ dívek se liší.
Jelikož se jedná o dvě nezávislé skupiny, vybereme z hlavní nabídky Statistika – Základní
statistiky/tabulky – t-test, nezávislé, dle skupin. Závislá proměnná je v tomto případě IQ,
protože její střední hodnoty chceme porovnávat. Grupovací proměnnou je Pohlaví.
Pro zajímavost ověříme platnost předpokladu, že rozptyly závisle proměnné jsou v obou
skupinách stejné (homogenní). Proto na záložce Možnosti ještě zaškrtneme možnosti
Leveneův a Brown &Forsythův test shody rozptylů (nulová hypotéza říká, že rozptyly jsou
v obou skupinách stejné, alternativní, že se liší).
Na záložce Základ klikneme na tlačítko „Výpočet: t-testy“ a dostaneme tabulku s výsledky
testů. V první části tabulky (viz obrázek 5-10) je výsledek t-testu. Pro zamítnutí nebo
nezamítnutí nulové hypotézy je rozhodující p-hodnota, neboli minimální hladina
významnosti, na které lze zamítnout nulovou hypotézu. V našem případě je p > 0,05, proto
nulovou hypotézu nezamítáme a můžeme tvrdit, že IQ chlapců a IQ dívek se neliší.
Obrázek 5-10
V další části tabulky (viz obrázek 5-11) jsou výsledky tří testů homogenity rozptylů obou
skupin. Vidíme, že p-hodnoty pro všechny tři testy (vzájemně jsou odděleny dvojitou čárou)
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 85
85
jsou větší než 0,05, takže nulovou hypotézu nezamítáme a usuzujeme, že data neukázala
rozdílné rozptyly.
Obrázek 5-11
Dalším předpokladem použití t-testu na souborech dat malého rozsahu je normální rozdělení
dat v obou skupinách. K posouzení normality nám slouží Kategorizované histogramy
a Kategorizované pravděpodobnostní normální grafy, které rovněž najdeme na záložce
Detailní výsledky. Tento druhý předpoklad t-testu však u souborů velkého rozsahu (jako je
tomu v tomto případě) není při praktickém výpočtu nutno ověřovat.
Úkol 2: Otevřete soubor Animal Weights.sta. Rozhodněte, zda je hmotnost kontrolní skupiny
stejná jako hmotnost léčené skupiny nebo zda se navzájem liší.
Řešení:
Stanovíme nulovou hypotézu H0: Hmotnost kontrolní skupiny je stejná jako hmotnost léčené
skupiny a alternativní hypotézu H1: Hmotnost kontrolní skupiny a hmotnost léčené skupiny se
liší.
Jelikož se jedná o dvě nezávislé skupiny, vybereme z hlavní nabídky Statistika – Základní
statistiky/tabulky – t-test, nezávislé, dle skupin. Závislá proměnná je v tomto případě
WEIGHT, protože její střední hodnoty chceme porovnávat. Grupovací proměnnou je GROUP.
Kromě t-testu ověříme platnost předpokladu, že rozptyly závisle proměnné jsou v obou
skupinách stejné (homogenní), a proto na záložce Možnosti ještě zaškrtneme možnosti
Leveneův a Brown &Forsythův test shody rozptylů. Ani jeden z testů neprokázal homogenitu
rozptylu (p-hodnoty jsou ve všech třech případech menší než 0,05, nulovou hypotézu
o rovnosti rozptylů zmítáme). Výsledek t-testu (rozdíly mezi skupinami nebyly prokázány)
nemůžeme považovat za hodnověrný a musíme vycházet pouze z výsledků poskytnutých
neparametrickými testy.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 86
86
Úkol 3: Otevřete soubor nehody.sta. Rozhodněte, zda je počet nehod v roce 2003 stejný jako
počet nehod v roce 2005 nebo zda se tyto počty navzájem liší.
Řešení:
Nejprve je nutné otestovat předpoklady pro použití dvouvýběrového t-testu. Počet hodnot je
nízký (pro každou z proměnných máme jen 12 naměřených hodnot), proto pomocí popisné
statistiky musíme otestovat předpoklad normálního rozdělení obou proměnných. Testování
normality obou proměnných provádíme v dialogu Statistiky – Základní statistiky/tabulky –
Tabulky četností. Na kartě Normalita zvolíme Shapiro–Wilksův W test a přes tlačítko „Test
normality“ vypočítáme příslušné hodnoty statistiky W a p-hodnotu. p-hodnota pro proměnnou
„rok 2003“ nabývá hodnoty 0,155 a pro proměnnou „rok 2005“ hodnoty 0,375. V obou
případech tedy nezamítáme nulovou hypotézu a považujeme rozdělení obou proměnných za
normální.
Stanovíme nulovou hypotézu H0: Počty nehod jsou v obou letech stejné a alternativní
hypotézu H1: Počty nehod v obou letech se liší.
Protože se jedná o dvě závislé proměnné, vybereme z nabídky Statistika – Základní
statistiky/tabulky – t-test, závislé vzorky. Zadáme proměnné tak, že do 1. seznamu
proměnných zadáme rok 2003 a do 2. seznamu proměnných rok 2005. Nyní pomocí tlačítka
„Výpočet: t-testy“ zobrazíme výsledek testu. p-hodnota je 0,0156, což znamená, že nulovou
hypotézu zamítáme. Počty nehod v obou letech se liší.
Vraťme se nyní do dialogu „t-test pro závislé vzorky“ a vytvořme pro obě proměnné
krabicové grafy – pomocí tlačítka „Krabicový graf“. Z nabídky čtyř typů vybereme
„Průměr/SmOdch/1,96*SmOdch“ (tato volba je odůvodněna normálním rozdělením u obou
proměnných). Výsledný graf je stejný jako na obr. 5-9.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 87
87
Příklady k procvičení
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 88
88
1 Popisná statistika
1.1 Otázky k datovému souboru Spánek.xlsx
V dotazníkovém šetření bylo cíleně osloveno několik respondentů za účelem výzkumu poruch
spánku.
1. Určete všechny kategoriální proměnné v souboru.
2. Určete všechny spojité proměnné v souboru.
3. Určete všechny ordinální proměnné v souboru.
4. Jaké třídění použijete na proměnnou rodinný stav?
5. Jaké třídění použijete na proměnnou kvalita spánku?
6. Jaké třídění použijete na proměnnou výška?
7. Jaké obměny statistické znaku nalezneme u proměnné pohlaví?
8. Jaké obměny statistické znaku nalezneme u proměnné nejvyšší dosažené vzdělání?
9. Jaké obměny statistické znaku nalezneme u proměnné kondice?
10. Proveďte bodové třídění proměnné kvalita spánku?
11. Proveďte bodové třídění proměnné zdravotní stav?
12. Proveďte intervalové třídění proměnné váha?
13. Pro proměnnou váha určete a slovně interpretujte:
a. průměr,
b. medián,
c. extrémy,
d. dolní a horní kvartil,
e. modus.
14. Pro proměnnou výška určete a slovně interpretujte:
a. variační rozpětí,
b. mezikvartilové rozpětí,
c. rozptyl,
d. směrodatnou odchylku,
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 89
89
e. variační koeficient.
15. Pro proměnnou kuřák určete a slovně interpretujte charakteristiky, které dávají smysl:
a. průměr,
b. variační rozpětí,
c. modus.
16. Kolik respondentů v datovém souboru jsou nekuřáci?
17. Kolik mužů se účastnilo dotazování?
18. Jaký je průměrný počet alkoholových nápojů vypitých za den na respondenta?
19. Určete nejčastější odpověď na otázku kondice? Jak nazvete tuto charakteristiku?
1.2 Otázky k datovému souboru Zaměstnanec.xlsx
V dotazníkovém šetření byli osloveni zaměstnanci jedné nejmenované firmy. Cílem šetření
bylo zjistit, jak vnímají svoji pozici v této firmě a jak je pro ně jejich zaměstnání důležité.
Vysvětlivky k souboru Zaměstnanec:
Položené otázky č. 1 až 10
1. Je zřejmé, co se očekává od Vaší práce?
2. Byl jste seznámen s vybavením a materiály potřebnými k Vaší práci dostatečně?
3. Jste informován a o vývoji a změnách týkající se Vaší práce?
4. Dostává se Vám uznání od zaměstnavatele za dobře odvedenou práci?
5. Podporuje Vás Váš nadřízený v dalším rozvoji?
6. Máte pocit, že zaměstnavatel bere na Vaše názory zřetel?
7. Dává Vám zaměstnavatel najevo, že je vaše práce důležitá?
8. Máte pocit, že jsou Vaši spolupracovníci oddáni své práci?
9. Byl Váš výkon v posledních 6 měsících vyhodnocen nebo nějak diskutován?
10. Měl jste možnost v průběhu posledního roku zlepšovat své dovednosti?
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 90
90
Respondenti odpovídali na každou otázku pomocí dvou pětistupňových škál:
Otázky značené A = míra souhlasu respondenta s položenou otázkou
1 = vůbec
5 = naprosto
Otázky značené I = míra důležitosti daného aspektu pro respondenta
1 = žádná
5 = velká
Otázky k datovému souboru Zaměstnanec
1. Jaký typ proměnných nalezneme v tomto datovém souboru?
2. Jaké třídění použijete na proměnnou Pracovní poměr?
3. Jaké třídění použijete na proměnnou Věk?
4. Jaké třídění použijete na otázky 1 až 10?
5. Jaké obměny statistické znaku nalezneme u proměnné Pracovní poměr?
6. Jaké obměny statistické znaku nalezneme u proměnné Věk?
7. Jaké obměny statistické znaku nalezneme u otázek 1 až 10?
8. Proveďte bodové třídění proměnné otázka 1A?
9. Proveďte bodové třídění proměnné Pracovní poměr?
10. Proveďte intervalové třídění proměnné Počet let v nynějším zaměstnání?
11. Pro proměnnou Počet let v nynějším zaměstnání určete a slovně interpretujte:
a. průměr,
b. medián,
c. extrémy,
d. dolní a horní kvartil,
e. modus.
12. K otázce 3I určete a slovně interpretujte:
a. variační rozpětí,
b. mezikvartilové rozpětí,
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 91
91
c. rozptyl,
d. směrodatnou odchylku,
e. variační koeficient.
13. Pro proměnnou Pracovní poměr určete a slovně interpretujte charakteristiky, které dávají
smysl:
a. průměr,
b. rozptyl,
c. variační rozpětí,
d. dolní a horní kvartil,
e. modus.
14. Kolik zaměstnanců by firmu doporučilo ostatním?
15. Určete takovou hodnotu věku, aby pouze desetina zaměstnanců byla starší? Jak nazvete
tuto charakteristiku?
16. Určete nejčastější odpověď na otázku 8A? Jak nazvete tuto charakteristiku?
1.3 Otázky k datovému souboru Náročnost povolání zdravotní sestry.xlsx
1. Jaký typ proměnných nalezneme v tomto datovém souboru?
2. Jaké třídění použijete na proměnnou Pohlaví?
3. Jaké třídění použijete na proměnnou Pracovní zařazení?
4. Jaké třídění použijete na proměnnou Počet let na nynějším pracovišti?
5. Jaké třídění použijete na proměnnou Vaše výše platu?
6. Jaké třídění použijete na proměnnou Cítíte se za svoji práci ohodnocena?
7. Jaké obměny statistické znaku nalezneme u proměnné Pracoviště?
8. Jaké obměny statistické znaku nalezneme u proměnné Délka praxe?
9. Jaké obměny statistické znaku nalezneme u proměnné Těší Vás vaše práce?
10. Proveďte bodové třídění proměnné Nejvyšší dosažené vzdělání.
11. Proveďte bodové třídění proměnné Co Vás v práci nejvíce zatěžuje.
12. Proveďte intervalové třídění proměnné Věk.
13. Proveďte intervalové třídění proměnné Vaše výše platu.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 92
92
14. Pro proměnnou Věk určete a slovně interpretujte:
a. průměr,
b. medián,
c. extrémy,
d. dolní a horní kvartil,
e. modus.
15. Pro proměnnou Plat určete a slovně interpretujte:
a. variační rozpětí,
b. mezikvartilové rozpětí,
c. rozptyl,
d. směrodatnou odchylku,
e. variační koeficient.
16. Pro proměnnou Pracoviště určete a slovně interpretujte charakteristiky, které dávají
smysl:
a. průměr,
b. rozptyl,
c. variační rozpětí,
d. dolní a horní kvartil,
e. modus.
17. Kolik zdravotních sester pracuje na jednotce intenzivní péče? Udejte jak absolutní četnost,
tak i četnost relativní.
18. Kolik mužů se účastnilo dotazování?
19. Jaké vzdělání má nejvyšší četnost mezi dotazovanými zdravotními sestrami?
20. Kolik dotazovaných zdravotních sester zvládá svoji práci bez problémů?
21. Určete počet let délky praxe tak, aby polovina dotazovaných sester měla praxi delší
a polovina kratší. Jak nazvete tuto charakteristiku?
22. Určete takovou hodnotu platu, aby pouze desetina dotazovaných sester měla plat vyšší?
Jak nazvete tuto charakteristiku?
23. Určete nejčastější odpověď na otázku Na konci směny se cítíte? Jak nazvete tuto
charakteristiku?
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 93
93
24. Je průměrný plat dotazovaných mužů vyšší než plat dotazovaných žen?
2 Grafické zpracování dat
2.1 Otázky k datovému souboru Spánek.xlsx
V dotazníkovém šetření bylo cíleně osloveno několik respondentů za účelem výzkumu poruch
spánku.
1. Pomocí krabicových grafů zobrazte odpověď na otázku hladina stresu. Kategorie pro
zobrazení zvolte rodinný stav.
2. S využitím filtru zobrazte do sloupcového grafu odpověď na otázku nejvyšší dosažené
vzdělání a to pouze svobodné respondenty.
3. Pomocí kategorizovaných grafů zobrazte odpověď na otázku kvalita spánku. Jako
kategorie pro zobrazení zvolte pohlaví dotazovaných.
2.2 Otázky k datovému souboru Zaměstnanec.xlsx
V dotazníkovém šetření byli osloveni zaměstnanci jedné nejmenované firmy. Cílem šetření
bylo zjistit, jak vnímají svoji pozici v této firmě a jak je pro ně jejich zaměstnání důležité.
Vysvětlivky k souboru Zaměstnanec:
Položené otázky č. 1 až 10
1. Je zřejmé, co se očekává od Vaší práce?
2. Byl jste seznámen s vybavením a materiály potřebnými k Vaší práci dostatečně?
3. Jste informován a o vývoji a změnách týkající se Vaší práce?
4. Dostává se Vám uznání od zaměstnavatele za dobře odvedenou práci?
5. Podporuje Vás Váš nadřízený v dalším rozvoji?
6. Máte pocit, že zaměstnavatel bere na Vaše názory zřetel?
7. Dává Vám zaměstnavatel najevo, že je vaše práce důležitá?
8. Máte pocit, že jsou Vaši spolupracovníci oddáni své práci?
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 94
94
9. Byl Váš výkon v posledních 6 měsících vyhodnocen nebo nějak diskutován?
10. Měl jste možnost v průběhu posledního roku zlepšovat své dovednosti?
Respondenti odpovídali na každou otázku pomocí dvou pětistupňových škál:
Otázky značené A = míra souhlasu respondenta s položenou otázkou
1 = vůbec
5 = naprosto
Otázky značené I = míra důležitosti daného aspektu pro respondenta
1 = žádná
5 = velká
Otázky k datovému souboru Zaměstnanec
1. Pomocí vhodného grafu zpracujte odpovědi proměnné 1A?
2. Pomocí vhodného grafu zpracujte odpovědi proměnné Pracovní poměr?
3. Pomocí vhodného grafu zpracujte odpovědi proměnné Počet let v nynějším zaměstnání?
4. Porovnejte pomocí krabicových grafů odpověď na otázky 7A a 7I. Pokuste se popsat, co
dané grafy ukazují.
5. S využitím filtru zobrazte do sloupcového grafu odpověď na otázku 3I a to pouze pro
zaměstnance na částečný úvazek.
6. Pomocí kategorizovaných grafů zobrazte odpověď na otázku č. 10A. Jako kategorie pro
zobrazení zvolte věk dotazovaných.
2.3 Otázky k datovému souboru Náročnost povolání zdravotní sestry.xlsx
1. Pomocí vhodného grafu zpracujte odpovědi proměnné Nejvyšší dosažené vzdělání.
2. Pomocí vhodného grafu zpracujte odpovědi proměnné Co Vás v práci nejvíce zatěžuje.
3. Pomocí vhodného grafu zpracujte odpovědi proměnné Věk.
4. Pomocí vhodného grafu zpracujte odpovědi proměnné Vaše výše platu.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 95
95
3 Korelační analýza
U každého příkladu promyslete, zda je vhodné pro zjišťování vztahu mezi proměnnými použít
korelační koeficient (pouze lineární závislosti). Pokud ano, určete jaký typ korelačního
koeficientu je vhodný (Spearmanův, Pearsonův).
K řešení příkladů použijte jednak korelační koeficient, jehož hodnotu se pokuste vhodně
okomentovat. Pro názornost doplňte grafické zpracování.
3.1 Otázky k souboru Korelace a regrese.xlxs
1. Zjistěte, zda existuje vztah mezi výškou a váhou 1.
2. Zjistěte, zda existuje vztah mezi výškou a váhou 1, váhou 2 a váhou 3. Určete párové
koeficienty korelace a jejich statistické významnosti.
3. Zjistěte, zda existuje vztah mezi platem a výdaji na domácnost 1.
4. Zjistěte, zda existuje vztah mezi platem a váhou 1.
3.2 Otázky k souboru Spánek.xlsx
1. Zjistěte, zda existuje vztah mezi délkou spánku o víkendu a délkou spánku v pracovní
den.
2. Zjistěte, zda existuje vztah mezi věkem (proměnná X) a délkou spánku (proměnná Y).
3. Zjistěte, zda existuje vztah mezi váhou (proměnná Y) a výškou respondenta (proměnná
X).
4. Zjistěte, zda existuje vztah mezi problémy s usínáním a lehkým spánkem.
5. Zjistěte, zda existuje vztah mezi počtem vypitých kofeinových nápojů a alkoholových
drinků.
3.3 Otázky k souboru Zaměstnanec.xlsx
1. Zjistěte, zda existuje vztah mezi odpovědí na otázku 1A a 1I.
2. Zjistěte, zda existuje vztah mezi odpovědí na otázku 1A a 2A.
3. Zjistěte, zda existuje vztah mezi odpovědí na otázku 7I a 9I.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 96
96
4. Zjistěte, zda existuje vztah mezi odpovědí na otázku 4A a 7A. Jako kategorie zvolte
pracovní poměr a porovnejte obě skupiny.
5. Zjistěte, zda existuje vztah mezi počtem let v zaměstnání a odpovědí na otázku 6A.
3.4 Otázky k souboru Náročnost povolání.xlsx
1. Zjistěte, zda existuje vztah u respondenta mezi věkem a počtem let v nynějším
zaměstnání.
2. Zjistěte, zda existuje vztah u respondenta mezi věkem a počtem let v nynějším
zaměstnání. Jako kategorie zvolte pracovní zařazení a skupiny porovnejte.
3. Zjistěte, zda existuje vztah u respondenta mezi věkem, délkou praxe a výší platu. Určete
párové koeficienty korelace a jejich statistické významnosti.
4 Regresní analýza
4.1 Otázky k souboru Korelace a regrese.xlsx
1. Proveďte regresní analýzu pro proměnné výška a postupně váha1, váha2, váha3.
a. Určete parametry regresní přímky, která popisuje závislost délky praxe na počtu let
respondenta.
b. Odhadněte intenzitu této závislosti (koeficient korelace).
c. Udejte, kolik procent variability délky praxe je vysvětleno počtem let respondenta.
d. Odhadněte, jakou váhu bude mít respondent, který měří 180 cm.
e. Zdůvodněte, zda odhad z předchozího příkladu má smysl a že užití lineární regrese je
vhodné.
2. Proveďte regresní analýzu pro proměnné hodnoty krevního tlaku 1 a hodnoty krevního
tlaku po požití léku.
a. Určete parametry regresní přímky, která popisuje závislost hodnot tlaku po požití léku
na hodnotách před požitím léku.
b. Odhadněte intenzitu této závislosti (koeficient korelace).
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 97
97
c. Udejte, kolik procent variability hodnoty tlaku po požití léku je vysvětleno původní
hodnotou tlaku.
d. Odhadněte, jak vysoký tlak po požití léku bude mít respondent, jehož tlak před
požitím byl 140.
e. Zdůvodněte, zda odhad z předchozího příkladu má smysl a že užití lineární regrese je
vhodné.
3. Proveďte regresní analýzu pro proměnné výška a plat.
a. Určete parametry regresní přímky, která popisuje závislost platu na výšce respondenta.
b. Odhadněte intenzitu této závislosti (koeficient korelace).
c. Udejte, kolik procent variability platu je vysvětleno výškou respondenta.
d. Odhadněte, jaký plat bude mít respondent, kterému je 20 let.
e. Zdůvodněte, zda odhad z předchozího příkladu má smysl a že užití lineární regrese je
vhodné.
4.2 Otázky k souboru Náročnost povolání.xlsx
1. Proveďte regresní analýzu pro proměnné věk a délka praxe.
a. Určete parametry regresní přímky, která popisuje závislost délky praxe na počtu let
respondenta.
b. Odhadněte intenzitu této závislosti (koeficient korelace).
c. Udejte, kolik procent variability délky praxe je vysvětleno počtem let respondenta.
d. Odhadněte, jakou délku praxe bude mít respondent, kterému je 25 let.
e. Zdůvodněte, zda odhad z předchozího příkladu má smysl a že užití lineární regrese je
vhodné.
2. Proveďte regresní analýzu pro proměnné věk a počet let v nynější práci.
a. Určete parametry regresní přímky, která popisuje závislost délky počtu let v práci na
věku respondenta.
b. Odhadněte intenzitu této závislosti (koeficient korelace).
c. Udejte, kolik procent variability délky praxe je vysvětleno věkem respondenta.
d. Odhadněte, kolik let bude v nynější práci respondent, kterému je 30 let.
e. Zdůvodněte, zda odhad z předchozího příkladu má smysl a že užití lineární regrese je
vhodné.
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 98
98
4.3 Otázky k souboru Spánek.xlsx
1. Proveďte regresní analýzu pro proměnné váha a výška.
a. Určete parametry regresní přímky, která popisuje závislost váhy na výšce respondenta.
b. Odhadněte intenzitu této závislosti (koeficient korelace).
c. Udejte, kolik procent variability váhy je vysvětleno výškou respondenta.
d. Odhadněte, jakou váhu bude mít respondent, který měří 180 cm.
e. Zdůvodněte, zda odhad z předchozího příkladu má smysl a že užití lineární regrese je
vhodné.
2. Proveďte regresní analýzu pro proměnné počet kofeinových nápojů na den a délka
spánku v pracovní den.
a. Určete parametry regresní přímky, která popisuje závislost spánku na počtu nápojů.
b. Odhadněte intenzitu této závislosti (koeficient korelace).
c. Udejte, kolik procent variability délky spánku je vysvětleno počtem vypitých nápojů.
d. Odhadněte, jak dlouho bude respondent spát, pokud pije průměrně 3 kofeinové nápoje
denně.
e. Zdůvodněte, zda odhad z předchozího příkladu má smysl a že užití lineární regrese je
vhodné.
5 Neparametrické testy
Před každým testem se vždy zamyslete, zda má vůbec smysl test provádět.
Pokud není řečeno jinak, testy provádějte na hladině významnosti 0,05.
5.1 Otázky k souboru Testování hypotéz.xlsx
1. Zjistěte, zda existuje závislost mezi pohlavím a tím, zda je respondent kuřák (odpověď 1
a 2 samostatně). Otestujte na hladině významnosti 0,05 a 0,01. Pro daná data vytvořte
kontingenční tabulku, včetně vhodných relativních četností. (chí-kvadrát)
2. Na hladině významnosti 0,01 otestujte závislost mezi pohlavím a dosaženým vzděláním.
(chí-kvadrát)
3. Na hladině významnosti 0,01 otestujte závislost mezi dosaženým vzděláním otce
a dosaženým vzděláním matky. (Spearmanova korelace)
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 99
99
4. Rozhodněte, zda se váha 1 liší u mužů a žen. Graficky znázorněte. (Mann-Whitneyův
U test)
5. Rozhodněte, zda se váha 2 liší u mužů a žen. Graficky znázorněte. (Mann-Whitneyův
U test)
6. Rozhodněte, zde je počet návštěv u lékaře v lednu stejný, jako v únoru. Graficky
znázorněte. (Wilkoksonův párový test)
7. Rozhodněte, zda je počet návštěv u lékaře v lednu stejný, jako v březnu. Graficky
znázorněte. (Wilkoksonův párový test)
5.2 Otázky k souboru Spánek.xlsx
1. Zjistěte, zda existuje závislost mezi pohlavím a rodinným stavem. Otestujte na hladině
významnosti 0,05 a 0,01. Pro daná data vytvořte kontingenční tabulku, včetně vhodných
relativních četností. (chí-kvadrát)
2. Zjistěte, zda existuje závislost mezi pohlavím a tím, zda je respondent kuřák. Pro daná
data vytvořte kontingenční tabulku, včetně vhodných relativních četností. (chí-kvadrát)
3. Zjistěte, zda existuje závislost mezi pohlavím a nejvyšším dosaženým vzděláním. Pro
daná data vytvořte kontingenční tabulku, včetně vhodných relativních četností. (chí-
kvadrát)
4. Zjistěte, zda existuje závislost mezi nejvyšším dosaženým vzděláním a tím, zda je
respondent kuřák. Pro daná data vytvořte kontingenční tabulku, včetně vhodných
relativních četností. (chí-kvadrát)
5. Zjistěte, zda existuje závislost mezi pohlavím a odpovědí na otázku kvalita spánku. Pro
daná data vytvořte kontingenční tabulku, včetně vhodných relativních četností. (chí-
kvadrát)
6. Na hladině významnosti 0,01 otestujte závislost mezi vnímáním zdravotního stavu
a kondice. (Spearmanova korelace)
7. Otestujte závislost mezi pocitem vyčerpání a pocitem ospalosti v minulém měsíci.
(Spearmanova korelace)
8. Rozhodněte, zda se váha u mužů a žen liší. Graficky znázorněte. (Mann-Whitneyův
U test)
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 100
100
9. Rozhodněte, zda se u mužů a žen liší délka spánku v pracovní den. Graficky znázorněte.
(Mann-Whitneyův U test)
10. Rozhodněte, zde je u respondenta délka spánku v pracovní den stejná, jako o víkendu.
Graficky znázorněte. (Wilkoksonův párový test)
5.3 Otázky k souboru Zaměstnanec.xlsx
1. Zjistěte, zda existuje závislost mezi pracovním poměrem a doporučením firmy ostatním.
Otestujte na hladině významnosti 0,05 a 0,01. Pro daná data vytvořte kontingenční
tabulku, včetně vhodných relativních četností. (chí-kvadrát)
2. Na hladině významnosti 0,01 otestujte závislost odpovědí na otázku 1A a 1I.
3. Na hladině významnosti 0,01 otestujte závislost odpovědí na otázku 10A a 10I.
4. Otestujte závislost odpovědí na otázku 1A a 6A.
5. Rozhodněte, zda se liší odpověď na otázku 5A u zaměstnanců, kteří by firmu doporučili
a kteří ne?
6. Rozhodněte, zda se liší odpověď na otázku 6I u zaměstnanců, kteří by firmu doporučili
a kteří ne?
6 Parametrické testy
Před každým testem se vždy zamyslete, zda má vůbec smysl test provádět.
Pokud není řečeno jinak, testy provádějte na hladině významnosti 0,05.
6.1 Otázky k souboru Testování hypotéz.xlsx
1. Rozhodněte, zda se u mužů a žen liší jejich průměrná výška. Graficky znázorněte. (t-test,
nezávislé, dle skupin)
2. Rozhodněte, zda se u mužů a žen liší jejich průměrná váha 1. Graficky znázorněte. (t-test,
nezávislé, dle skupin)
3. Rozhodněte, zda se u mužů a žen liší jejich průměrný plat. Graficky znázorněte. (t-test,
nezávislé, dle skupin)
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)
Page 101
101
4. Rozhodněte, zda se liší průměrný plat u skupin utvořených na základě spokojenosti.
Graficky znázorněte. (t-test, nezávislé, dle skupin)
5. Rozhodněte, zda se liší průměrný věk u skupin utvořených na základě spokojenosti.
Graficky znázorněte. (t-test, nezávislé, dle skupin)
6. Rozhodněte, zda se liší průměrná hodnota krevního tlaku 1 u kuřáků 1 a nekuřáků 1.
Graficky znázorněte. (t-test, nezávislé, dle skupin)
7. Rozhodněte, zda se liší hodnota krevního tlaku 1 a hodnota krevního tlaku po požití léku.
Graficky znázorněte. (t-test, závislé)
8. Rozhodněte, zda se liší hodnota krevního tlaku 2 a hodnota krevního tlaku po požití léku.
Graficky znázorněte. (t-test, závislé)
6.2 Otázky k souboru Spánek.xlsx
1. Rozhodněte, zda se u mužů a žen liší jejich průměrná výška. Graficky znázorněte. (t-test,
nezávislé, dle skupin)
2. Rozhodněte, zda se u mužů a žen liší jejich průměrná váha. Graficky znázorněte. (t-test,
nezávislé, dle skupin)
6.3 Otázky k souboru Náročnost povolání.xlsx
1. Rozhodněte, zda se u mužů a žen liší jejich průměrný plat. Graficky znázorněte. (t-test,
nezávislé, dle skupin)
You created this PDF from an application that is not licensed to print to novaPDF printer (http://www.novapdf.com)