73
Statistika (nejen) v bioinformatice Karel Berka KFC, PřF UP

Statistika (nejen) v bioinformatice
Karel Berka
KFC, PřF UP

Obsah• Základy teorie pravděpodobnosti
– Základní pojmy
– Bayesův vzorec
• Testy citlivosti a spolehlivosti– ROC křivka
• Popisy distribuce hodnot
• Regrese
• Standardizace pro porovnávání – Z-score

Základy teorie pravděpodobnosti

Náhodný pokus a náhodný jev
• deterministický pokus = pokus, jehož výsledek je dán jednoznačně podmínkami, za kterých probíhá (voda vře při 100 °C)
• náhodný pokus = výsledek není jednoznačně určen podmínkami, za kterých probíhá (např. hod mincí)
• elementární jev = výsledek náhodného pokusu (při hodu mincí padne „hlava“)
• prostor elementárních jevů = množina všech možných výsledků náhodného pokusu („hlava“, „orel“)
• náhodný jev = jakékoli tvrzení o výsledku, o kterém lze po uskutečnění pokusu či pozorování rozhodnout, zda je či není pravdivé (podmnožina prostoru elementárních jevů), např. „padne hlava“

Pravděpodobnost náhodného jevu
• míra častosti výskytu náhodného jevu
• nabývá hodnot v intervalu od 0 (jev nemožný) do 1 (jev jistý)
• klasická teorie pravděpodobnosti: p-st náhodného jevu odpovídá relativní četnosti
• axiomatická teorie pravděpodobnosti: nezáporná, sigma-aditivní míra s hodnotou 1 pro prostor elementárních jevů Ω

Pravidlo o sčítání pravděpodobností
• vztahy mezi náhodnými jevy:– náhodný jev C = (A,B) nastává v případě, že nastanou oba jevy A a B současně
(někdy se značí A ∩ B)– náhodný jev D = (A nebo B) nastává v případě, že nastane alespoň jeden z
jevů A a B (někdy se značí A U B)
• jevy A a B jsou neslučitelné, jestliže nemohou nastat oba současně (jev C = (A,B))
• pro neslučitelné jevy A a B je jev C = (A,B) nemožný a jeho pravděpodobnost je rovna nule →
• lze snadno rozšířit na libovolný počet vzájemně neslučitelných jevů A1, A2, …, Ak

Jev opačný
• nastává právě tehdy, když jev A nenastává
• platí
• na základě pravidla o sčítání pravděpodobností pak

Podmíněná pravděpodobnost
• výskyt jevu A jen v případě, že nastal určitý jev B, který má kladnou pravděpodobnost (tj. může opravdu nastat)
• víme-li že nastal jev B, může se tím změnit i pravděpodobnost výskytu jevu A
• všechny jevy neslučitelné s B se stanou nemožnými a jevy deterministicky určené B se stanou jistými (jev A nastává vždy, když nastane jev B)
• ostatní jevy se mohou vyskytnout s pravděpodobnostmi, které mohou být odlišné od původních
• podmíněná pravděpodobnost jevu A vzhledem k jevu B:

Nezávislé náhodné jevy
• pomocí podmíněné pravděpodobnosti lze vyjádřit pravděpodobnost současného výskytu dvou jevů (A,B)
• jevy A a B jsou nezávislé, jestliže výskyt jednoho jevu neovlivňuje výskyt druhého jevu, tj.:
• pro nezávislé jevy A, B platí pravidlo o násobení pravděpodobností:
nebo

Úplná pravděpodobnost
• pokud jsou náhodné jevy B1, B2, .., Bkvzájemně neslučitelné a v každém pokus nastává právě jeden z nich, platí
• známe-li podmíněné pravděpodobnosti jevu A za podmínky výskytu jevu Bi, 1,..,k, lze pravděpodobnost výskytu jevu A vyjádřit vztahem

Bayesův vzorec
• říká, jakým způsobem vypočítáme p-stiP(Bj|A) jevu Bj za podmínky, že nastal jev A, jestliže známe apriorní p-sti P(Bi) a podmíněné p-sti P(A|Bi) pro všechny jevy Bi, i = 1, 2, .., k

Bayesian Probability
•“Probability”: often used to refer to frequency
•… but
•Bayesian Probability: a measure of a state of knowledge.
•It quantifies uncertainty. Allows us to reason using uncertain statements.
•A Bayesian model is continually updated as more data is acquired.

Bayes' Theorem
•Bayes' Theorem shows the relationship between a conditional probability and its
inverse.
•i.e. it allows us to make an inference from
•the probability of a hypothesis given the evidence to
•the probability of that evidence given the hypothesis
•and vice versa

Bayes' Theorem
P(A|B) = P(B|A) P(A)
P(B)
•P(A) – the PRIOR PROBABILITY – represents your knowledge about A before you have gathered data.
•e.g. if 0.01 of a population has schizophrenia then the probability that a person drawn at random would have schizophrenia is 0.01

Bayes' Theorem
P(A|B) = P(B|A) P(A)
P(B)
•P(B|A) – the CONDITIONAL PROBABILITY – the probability of B, given A.
•e.g. you are trying to roll a total of 8 on two dice. What is the probability that you achieve this, given that the first die rolled a 6?

Bayes' Theorem
•P(A|B) = P(B|A) P(A)
• P(B)
•So the theorem says:
•The probability of A given B is equal to the probability of B given A, times the prior probability of A, divided by the prior probability of B.

A Simple Example
•Mode of transport: Probability he is late:
•Car 50%
•Bus 20%
•Train 1%
•Suppose that Bob is late one day.
•His boss wishes to estimate the probability that he traveled to work that day by car.
•He does not know which mode of transportation Bob usually uses, so he gives a prior probability of 1 in 3 to each of the three possibilities.

A Simple Example
•P(A|B) = P(B|A) P(A) / P(B)•P(car|late) = P(late|car) x P(car) / P(late)
•P(late|car) = 0.5 (he will be late half the time he drives)
•P(car) = 0.33 (this is the boss' assumption)
•P(late) = 0.5 x 0.33 + 0.2 x 0.33 + 0.01 x 0.33 • (all the probabilities that he will be late added together)
•P(car|late) = 0.5 x 0.33 / 0.5 x 0.33 + 0.2 x 0.33 + 0.01 x 0.33
• = 0.165 / 0.71 x 0.33• = 0.7042

More complex example
•Disease present in 0.5% population (i.e. 0.005)•Blood test is 99% accurate (i.e. 0.99)•False positive 5% (i.e. 0.05)• - If someone tests positive, what is the probability that they have the disease?
•P(A|B) = P(B|A) P(A) / P(B)
•P(disease|pos) = P(pos|disease) x P(disease) / P(pos)
• = 0.99 x 0.005 / (0.99x0.005)+(0.05x0.995)
• = 0.00495 / 0.00495 + 0.04975
• = 0.00495 / 0.0547
• = 0.0905

What does this mean?
•If someone tests positive for the disease, they have a 0.0905 chance of having the disease.
•i.e. there is just a 9% chance that they have it.
•Even though the test is very accurate, because the condition is so rare the test may not be useful.

So why is Bayesian probability useful?
•It allows us to put probability values on unknowns. We can make logical inferences even regarding uncertain statements.
•This can show counterintuitive results – e.g. that the disease test may not be useful.

SKRÍNINGOVÝ TEST

Skríningový test
• předpoklad - včasná detekce nemoci povede k příznivější prognóze nemoci (bude včas zahájena léčba)
• onemocnění musí být závažné a léčba zahájená před rozvinutím příznaků musí být příznivější vzhledem ke snížení mortality či morbidity než v případě, že onemocnění zachytíme již v pokročilém stadiu
• prevalence nemoci (podíl počtu jedinců trpících danou nemocí ve sledované populaci) v preklinickém stadiu musí být dostatečně vysoká v populaci, na které je skríning prováděn

Příklad
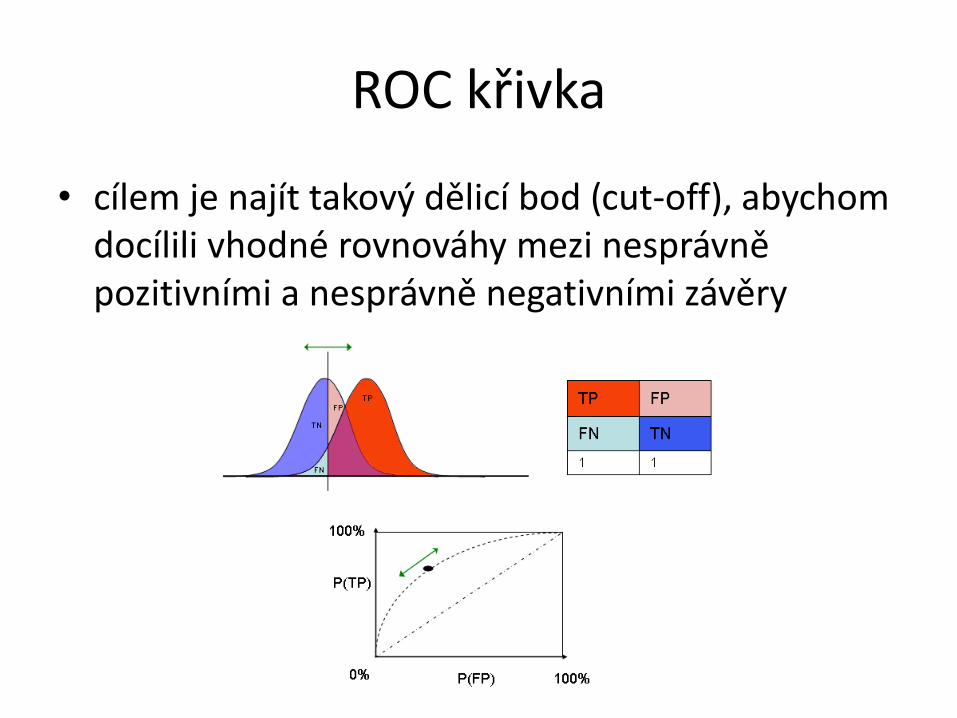
ROC křivka
• cílem je najít takový dělicí bod (cut-off), abychom docílili vhodné rovnováhy mezi nesprávně pozitivními a nesprávně negativními závěry

Výběr a popisné statistiky
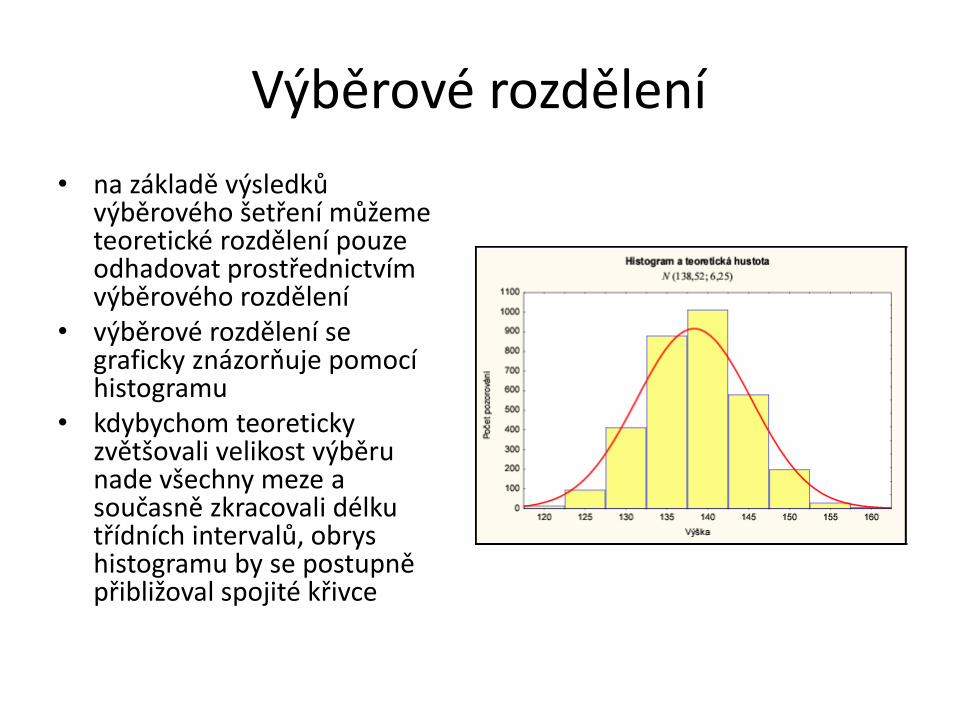
Výběrové rozdělení
• na základě výsledků výběrového šetření můžeme teoretické rozdělení pouze odhadovat prostřednictvím výběrového rozdělení
• výběrové rozdělení se graficky znázorňuje pomocí histogramu
• kdybychom teoreticky zvětšovali velikost výběru nade všechny meze a současně zkracovali délku třídních intervalů, obrys histogramu by se postupně přibližoval spojité křivce

Charakteristiky výběru
• míry polohy: míry určující hodnotu, kolem které se data soustřeďují, tj. jakýsi „střed“
• míry variability: míry určující, jak hodnoty kolem kolem „středu“ kolísají
• míry tvaru mající souvislost s tvarem rozdělení pravděpodobnosti (šikmost, špičatost)
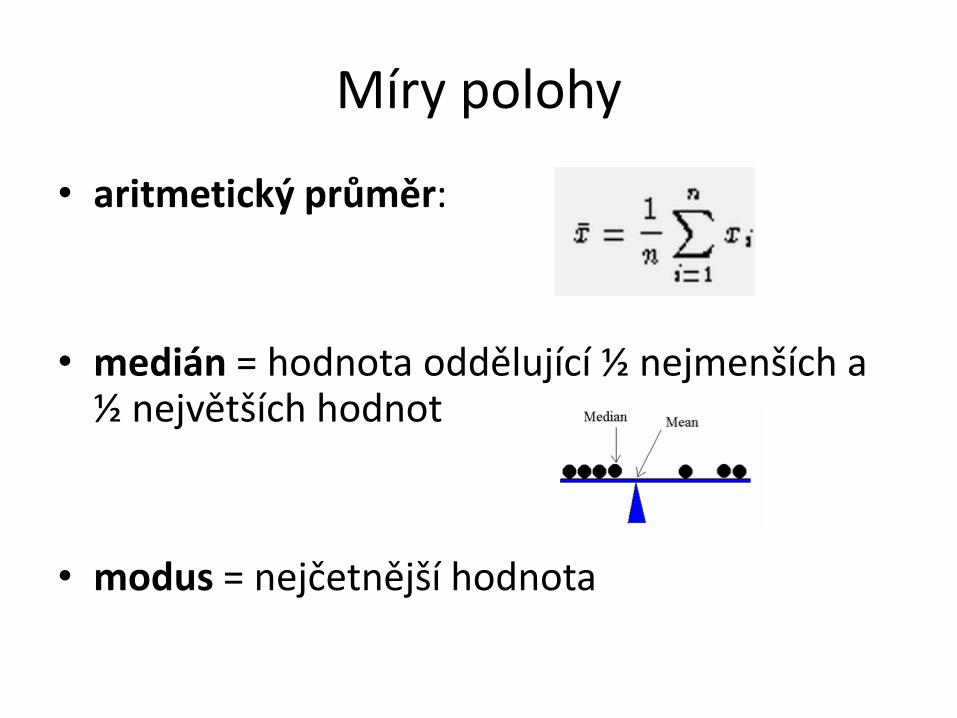
Míry polohy
• aritmetický průměr:
• medián = hodnota oddělující ½ nejmenších a ½ největších hodnot
• modus = nejčetnější hodnota

Míry variability
• rozpětí:
• rozptyl:
• směrodatná odchylka = druhá odmocnina z rozptylu
• variační koeficient:
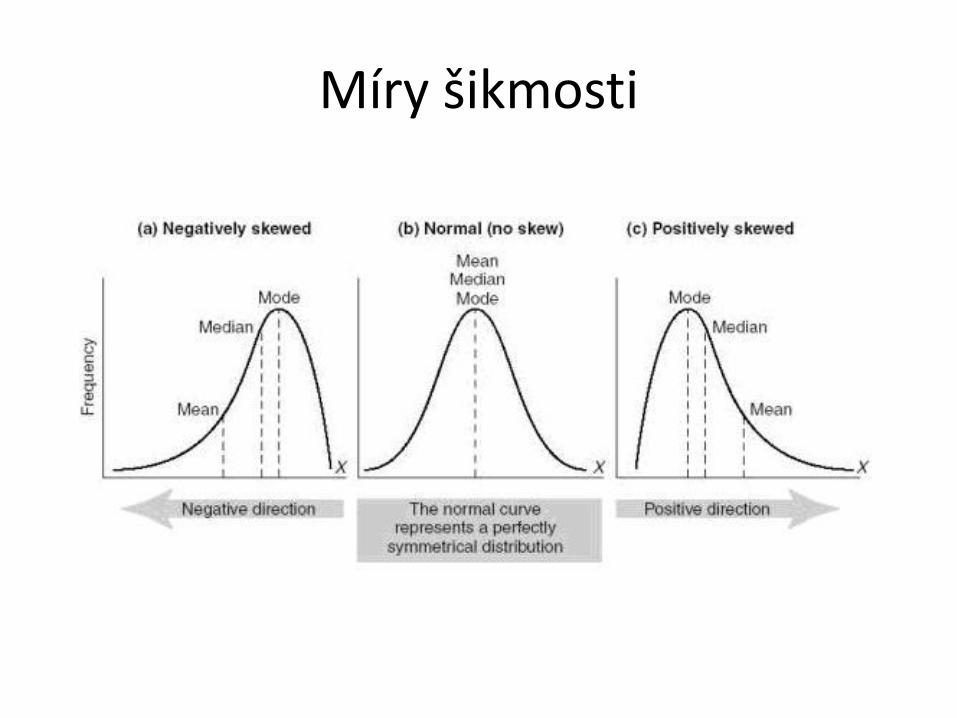
Míry šikmosti

Kvantily
• 100P% kvantil je taková hodnota, kdy 100P % hodnot ve výběru má hodnotu menší nebo rovnou tomuto kvantilu:– kvartily: 1. kvartil je roven 25% kvantilu, 2. kvartil 50% kvantilu (neboli
mediánu) a 3. kvartil 75% kvantilu,– decily: oddělujeme-li hodnoty postupně po deseti procentech, např. 1. decil =
10% kvantil apod.,– percentily: oddělujeme-li hodnoty po jednom procentu, např. 1. percentil =
1% kvantil
• jsou užívané:– pro srovnání individuálních hodnot se stanovenými normami,– jako rozmezí normálních hodnot pro laboratorní nálezy (např. mezi 2,5% a
97,5% percentilem = 95 % hodnot uvažované populace),– jako míra polohy: 50% kvantil = 2. kvartil = 5. decil = 50% percentil = medián– jako míra variability: mezikvartilové rozpětí IQR = rozdíl mezi 3. kvartilem (75%
kvantilem) a 1. kvartilem (25% kvantilem),– jako podklad pro grafické zobrazení analyzovaných dat: boxplot, normální graf,
resp. kvantilový graf atd.

Měření závislosti

Závislost a kauzalita
• v biomedicínském výzkumu zjišťujeme současně řadu znaků, které mohou být vzájemně závislé
• sílu závislosti (korelaci) vyjadřujeme prostřednictvím různých měr statistické závislosti, ke kterým patří i korelační koeficienty (s hodnotami od -1 do 1, přičemž hodnoty blízké -1 označují negativní korelaci, blízké +1 pozitivní korelaci)
• statistická závislost zdaleka nemusí znamenat kauzalitu – příčinné souvislosti čistě empirickými prostředky neodhalíme (je třeba přidat odborné znalosti a praktické zkušenosti)

Lineární regrese a korelace
• vztah mezi dvěma kvantitativními znaky neboli veličinami• jedna z veličin, tzv. nezávisle proměnná X, má řídit druhou,
tzv. závisle proměnnou Y• 1. krok = zakreslení dat do X-Y bodového grafu• lineární regrese = proložení přímky daty a analýza jejích
statistických vlastností• nejčastěji používaná metoda – metoda nejmenších čtverců
(MNČ):– minimalizace reziduálního součtu čtverců:
absolutní člen (intercept)
směrnice přímky (slope)
reziduální rozptyl
reziduum

Regresní koeficienty přímky
• vypočtené (odhadnuté) MNČ:
výběrové průměry
odhady rozptylů
odhad kovariance náhodných veličin X a Y

Regresní analýza
• předpoklady:– závisle proměnná Y má normální rozdělení pro každou hodnotu
nezávisle proměnné X = x– rozptyl závisle proměnné Y je stejný pro každou hodnotu nezávisle
proměnné X = x– závislost veličiny Y na X je lineární
• interval spolehlivosti pro směrnici přímky (df=n-2):
kde
• test významnosti regresního koeficientu β:
• testová statistika má Studentovo t-rozdělení s n-2 stupni volnosti
nutno odhadnout 2 parametry

Pearsonův korelační koeficient
• slouží k měření síly lineární závislosti mezi dvěma spojitými náhodnými veličinami
• jeho hodnota se pohybuje od -1 do 1, přičemž hodnoty ±1 nabývá jen pokud všechny body [xi,yi] leží na přímce
• jsou-li veličiny X a Y nezávislé je roven 0• korelační koeficient může být 0 i v případě, že veličiny jsou funkčně závislé,
ale závislost není lineární!!!• znaménko korelačního koeficientu je:
– kladné, když obě veličiny X a Y zároveň rostou nebo obě zároveň klesají– záporné, když jedna z veličin roste, zatímco druhá klesá
• znaménko korelačního koeficientu udává směr• velikost korelačního koeficientu udává, jak blízko jsou body
nashromážděny kolem přímky• korelace je často uváděna s dosaženou hladinou významnosti p, která se
obvykle vztahuje k testu nulové hypotézy, že korelační koeficient (dvourozměrné) populace je nula, tedy že mezi veličinami X a Y neexistuje žádný lineární vztah
korelace neznamená příčinnost

Koeficient determinace
• pokud nás zajímá pouze síla lineární závislosti, používáme místo korelačního koeficientu r spíše jeho druhou mocninu r2, často značenou R2
• koeficient determinace měří jen velikost lineárního vztahu mezi X a Y bez ohledu na to, která veličina je nezávislá a která závislá
• je i mírou vhodnosti modelu – udává tu část variability Y, kterou lze pomocí modelu vysvětlit, tj. pouze (1-r2)100% variability Y nelze vysvětlit variabilitou X
kde
celkový součet čtverců
regresní součet čtverců

Předpoklady modelu a jejich ověření
• pokud nejsou splněny předpoklady, na nichž je model založen, mohou být získané závěry značně chybné
• celá systematická variabilita Y je zahrnuta v odhadu přímky a žádný další systematický rozptyl (přesněji řečeno, systematický trend) by data neměla obsahovat
• obvyklým postupem při ověřování předpokladů modelu je nejprve z dat eliminovat efekt regresní přímky (tedy lineární funkce) a potom hledat systematické chování reziduí
• porovnání reziduí s čímkoli dalším (pozorovanými hodnotami, odhadnutými hodnotami, hodnotami X) by nemělo ukázat žádné systematické závislosti
• předpokládáme, že kolísání hodnot závisle proměnné kolem regresní přímky je dáno normálním rozdělením, rezidua by se měla chovat alespoň přibližně jako výběr z normálního rozdělení s nulovou střední hodnotou – použijeme normální graf reziduí
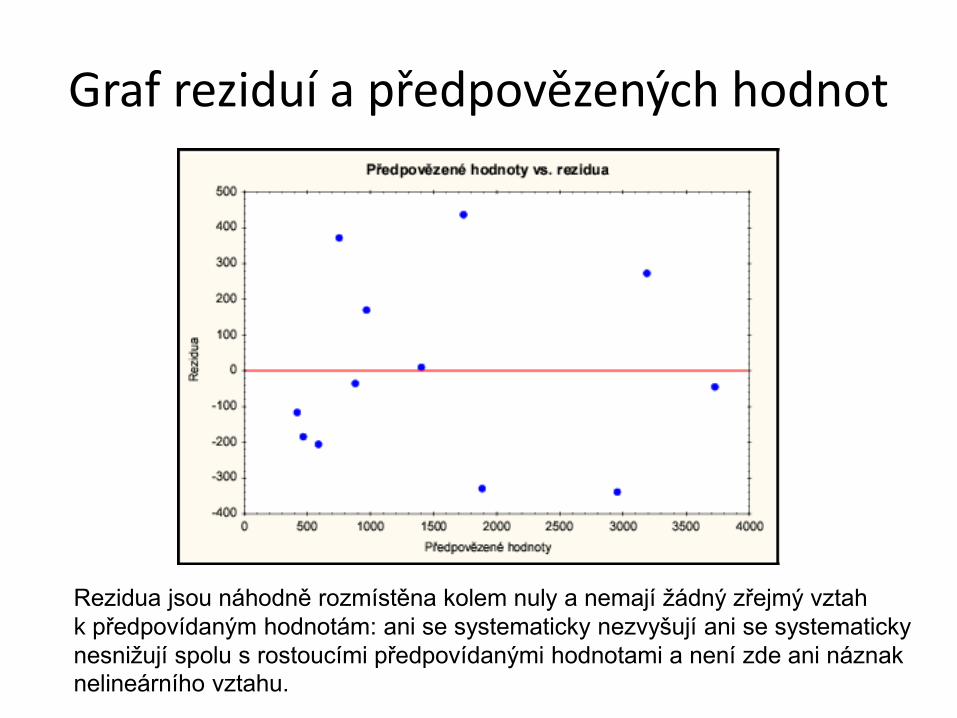
Graf reziduí a předpovězených hodnot
Rezidua jsou náhodně rozmístěna kolem nuly a nemají žádný zřejmý vztah
k předpovídaným hodnotám: ani se systematicky nezvyšují ani se systematicky
nesnižují spolu s rostoucími předpovídanými hodnotami a není zde ani náznak
nelineárního vztahu.
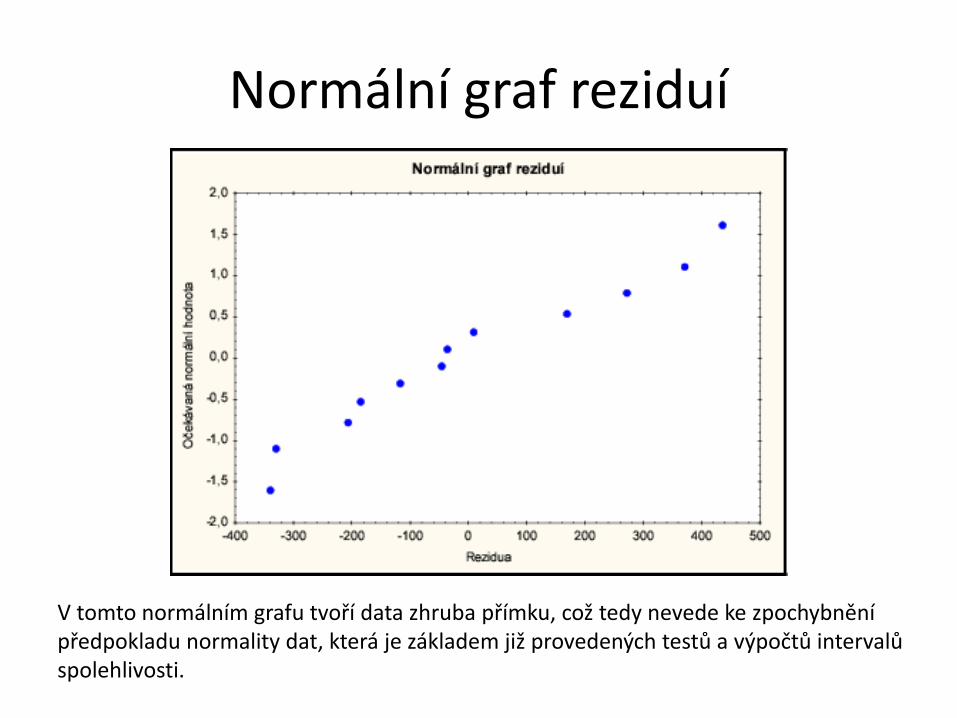
Normální graf reziduí
V tomto normálním grafu tvoří data zhruba přímku, což tedy nevede ke zpochybnění předpokladu normality dat, která je základem již provedených testů a výpočtů intervalů spolehlivosti.

Závislost kvalitativních znaků Spearmanův korelační koeficient
• Spearmanův korelační koeficient je (podobně jako jiné neparametrické metody) založený na pořadích jedinců
• každému bodu z dvourozměrného výběru se přiřadí dvojice pořadí Q (pořadí podle první veličiny X) a R (pořadí podle druhé veličiny Y)
kde
• shodném pořadí → rS=1, opačné pořadí rS=-1, v ostatních případech: -1<rS<1• hodnoty korelačního koeficientu blízké nule naznačují, že pořadí jsou náhodně
zpřeházená, a mezi sledovanými veličinami není závislost• při platnosti nulové hypotézy o nezávislosti obou veličin jsou odchylky
Spearmanova korelačního koeficientu od nuly jen náhodné:– když |rS| překročí 5% nebo 1% kritickou hodnotu, zamítá se nulová hypotéza o nezávislosti na
příslušné hladině významnosti (kritické hodnoty Spearmanova korelačního koeficientu jsou tabelovány)
– pro větší rozsah výběru (větší než 30) můžeme použít testové statistiky s N(0,1) rozdělením:

Analýza rozptylu

Z-SCORES (STANDARD SCORES)
• We can use the SD (s) to classify people on any measured variable.
• Why might you ever use this in real life?
– Diagnosis of a mental disorder
– Selecting the best person for the job
– Figuring out which children may need special assistance in school
Xz

HARDER EXAMPLE:
• Two people applying to graduate school
– Bob, GPA = 3.2 at Northwestern Michigan
– Mary, GPA = 3.2 at Southern Michigan
• Whom do we accept?
• What else do we need to know to determine who gets in?

SCHOOL PARAMETERS
• NWMU mean GPA = 3.0; SD = .1
• SMU mean GPA = 3.6; SD = .2
• THE MORAL OF THE STORY: We can compare people across ANY two tests just by saying how many SD’s they are from the mean.

z-SCORES
• The sign tells whether the score is located above (+) or below (-) the mean
• The number (magnitude) tells the distance between the score and the mean in terms of number of standard deviations

WHAT ELSE CAN WE DO WITH z-SCORES?
• Converting z-scores to X values
• Go backwards. Aaron says he had a z-score of 2.2 on the Math SAT.
– Math SAT has a m = 500 and s = 100
– What was his SAT score?

USING Z-SCORES TO STANDARDIZE A DISTRIBUTION
• Shape doesn’t change (Think of it as re-labeling)– Mean is always 0
– SD is always 1
– Why is the fact that the mean is 0 and the SD is 1 useful?
• standardized distribution is composed of scores that have been transformed to create predetermined values for m and s
• Standardized distributions are used to make dissimilar distributions comparable
• After the transformation to z-scores, the mean of the distribution becomes 0· After the transformation, the SD becomes 1· For a z-score distribution, Sz = 0
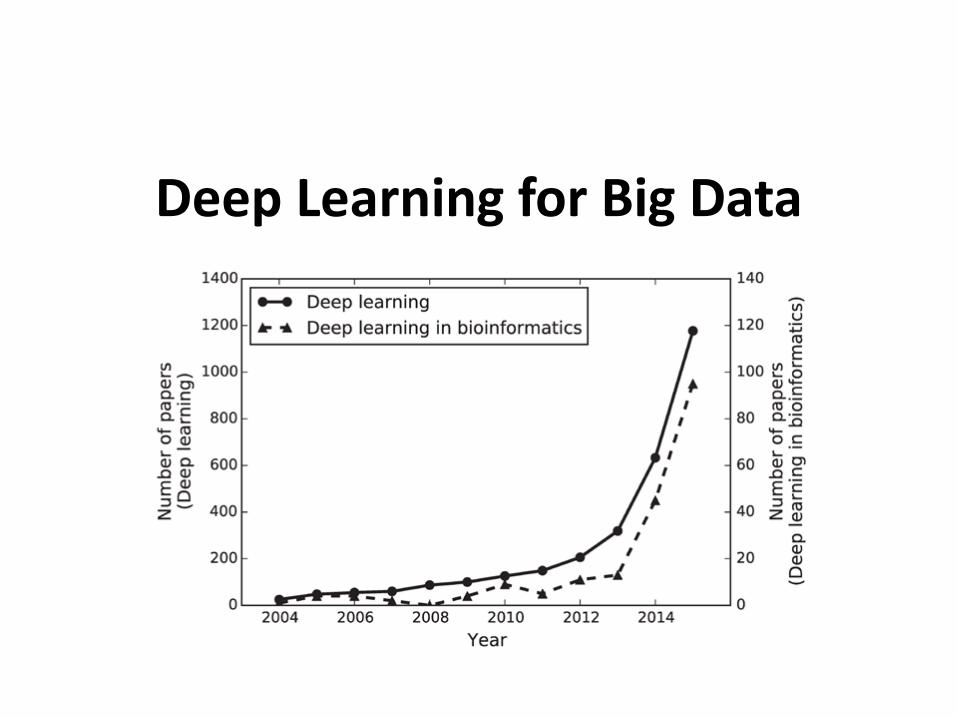
Deep Learning for Big Data

So, 1. what exactly is deep learning ?
And, 2. why is it generally better than other methods on image, speech and certain other types of data?
The short answers
1. ‘Deep Learning’ means using a neural network
with several layers of nodes between input and output
2. the series of layers between input & output do
feature identification and processing in a series of stages,
just as our brains seem to.

hmmm… OK, but: 3. multilayer neural networks have been around for
25 years. What’s actually new?
we have always had good algorithms for learning theweights in networks with 1 hidden layer
but these algorithms are not good at learning the weights fornetworks with more hidden layers
what’s new is: algorithms for training many-later networks
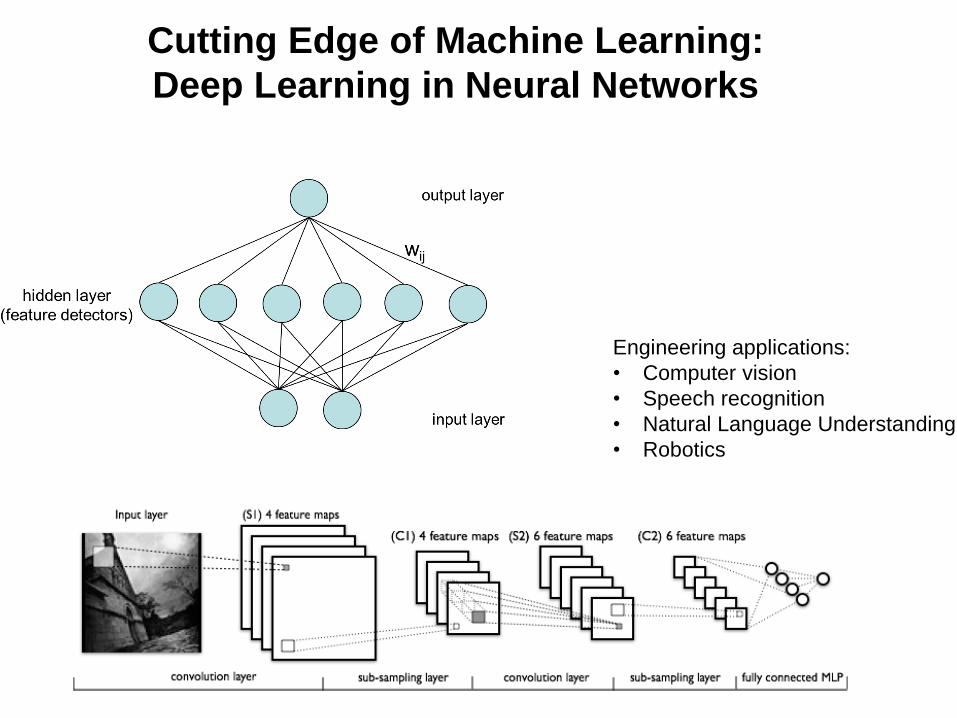
Cutting Edge of Machine Learning:
Deep Learning in Neural Networks
Engineering applications:
• Computer vision
• Speech recognition
• Natural Language Understanding
• Robotics
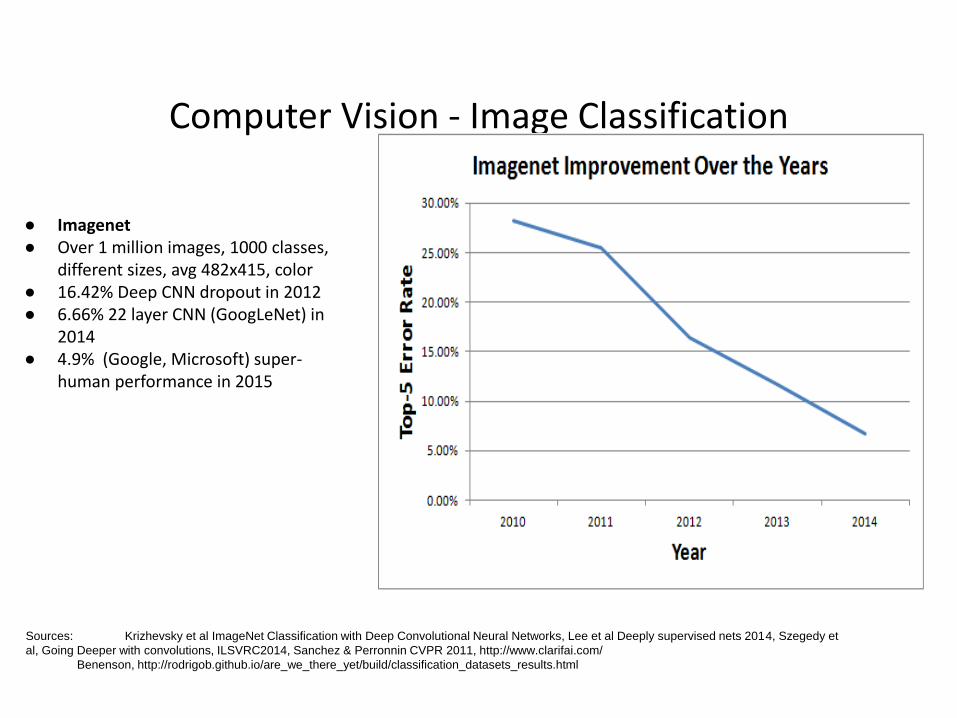
Computer Vision - Image Classification
● Imagenet● Over 1 million images, 1000 classes,
different sizes, avg 482x415, color● 16.42% Deep CNN dropout in 2012● 6.66% 22 layer CNN (GoogLeNet) in
2014● 4.9% (Google, Microsoft) super-
human performance in 2015
Sources: Krizhevsky et al ImageNet Classification with Deep Convolutional Neural Networks, Lee et al Deeply supervised nets 2014, Szegedy et
al, Going Deeper with convolutions, ILSVRC2014, Sanchez & Perronnin CVPR 2011, http://www.clarifai.com/
Benenson, http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html

Deep Learning Applications
• Engineering:– Computer Vision (e.g. image classification, segmentation)
– Speech Recognition
– Natural Language Processing (e.g. sentiment analysis, translation)
• Science:– Biology (e.g. protein structure prediction, analysis of genomic data)
– Chemistry (e.g. predicting chemical reactions)
– Physics (e.g. detecting exotic particles)
and many more
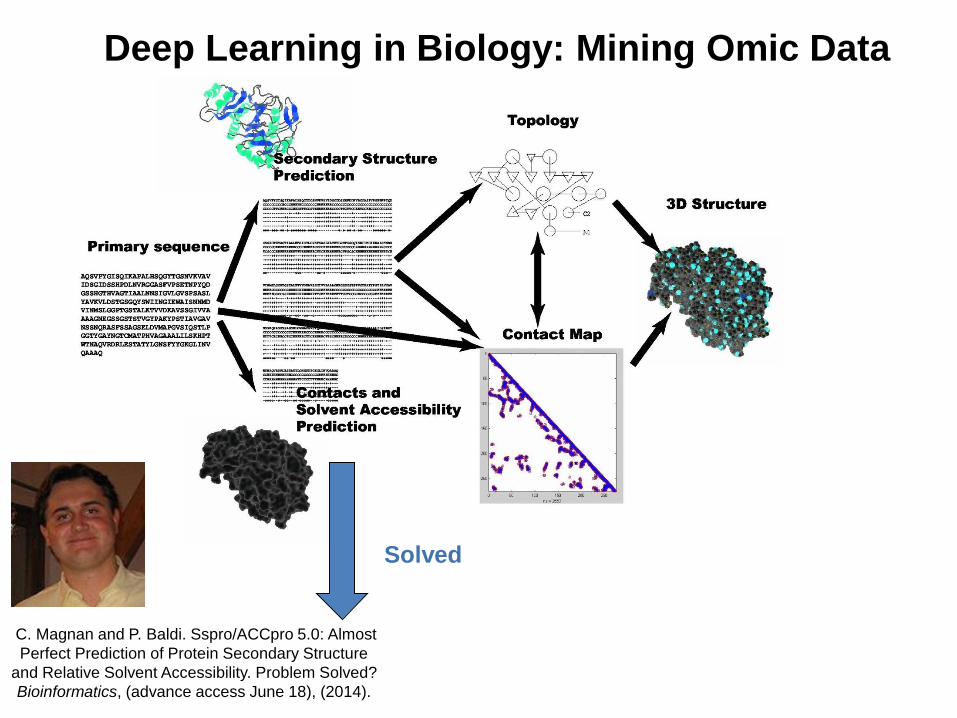
Deep Learning in Biology: Mining Omic Data
C. Magnan and P. Baldi. Sspro/ACCpro 5.0: Almost
Perfect Prediction of Protein Secondary Structure
and Relative Solvent Accessibility. Problem Solved?
Bioinformatics, (advance access June 18), (2014).
Solved
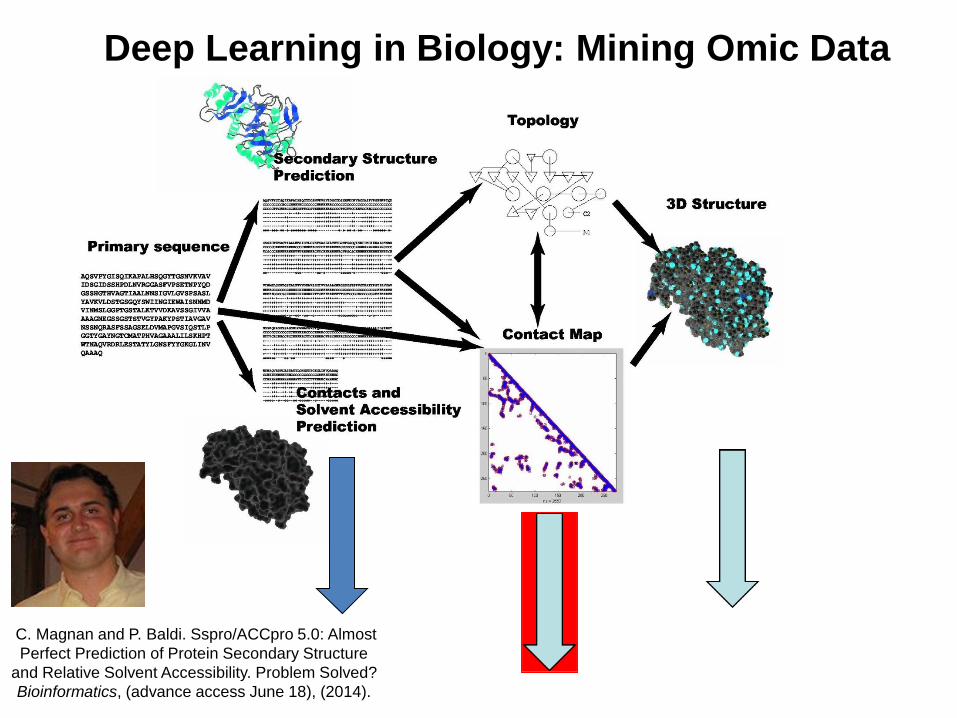
Deep Learning in Biology: Mining Omic Data
C. Magnan and P. Baldi. Sspro/ACCpro 5.0: Almost
Perfect Prediction of Protein Secondary Structure
and Relative Solvent Accessibility. Problem Solved?
Bioinformatics, (advance access June 18), (2014).
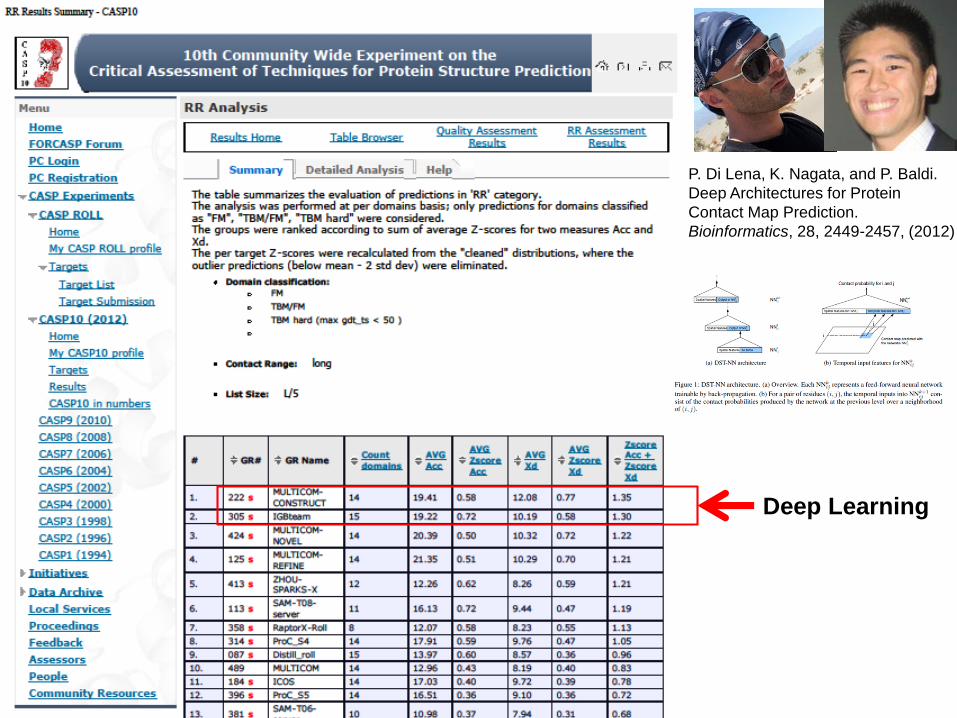
Deep Learning
P. Di Lena, K. Nagata, and P. Baldi.
Deep Architectures for Protein
Contact Map Prediction.
Bioinformatics, 28, 2449-2457, (2012)
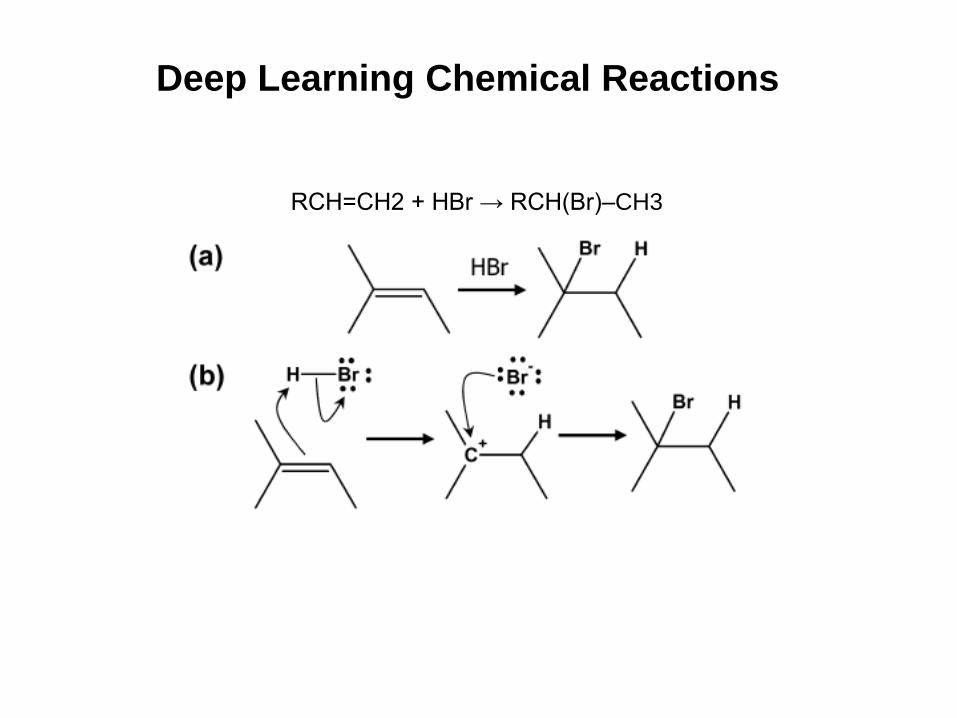
Deep Learning Chemical Reactions
RCH=CH2 + HBr → RCH(Br)–CH3

M. Kayala and P. Baldi. ReactionPredictor: Prediction of Complex Chemical
Reactions at the Mechanistic Level Using Machine Learning. Journal of
Chemical Information and Modeling, 52, 10, 2526–2540, (2012).
M. Kayala, C. Azencott, J. Chen, and P. Baldi. Learning to Predict Chemical
Reactions. Journal of Chemical Information and Modeling, 51, 9, 2209–2222,
(2011).
Deep Learning Chemical Reaction: ReactionPredictor

Deep Learning in Chemistry:
Predicting Chemical Reactions
RCH=CH2 + HBr → RCH(Br)–CH3
• Many important applications (e.g.
synthesis, retrosynthesis, reaction
discovery)
• Two different approaches:
1. Write a system of rules
2. Learn the rules from big data

Writing a System of Rules: Reaction Explorer
• ReactionExplorer System has about
1800 rules
• Covers undergraduate organic
chemistry curriculum
• Interactive educational system
• Licensed by Wiley from
ReactionExplorer and distributed world-
wide
J. Chen and P. Baldi. No Electron Left-
Behind: a Rule-Based Expert System
to Predict Chemical Reactions and
Reaction Mechanisms. Journal of
Chemical Information and Modeling,
49, 9, 2034-2043, (2009).
Jonathan Chen

Problems
• Very tedious
• Non-scalable
• Limited coverage (undergraduate)

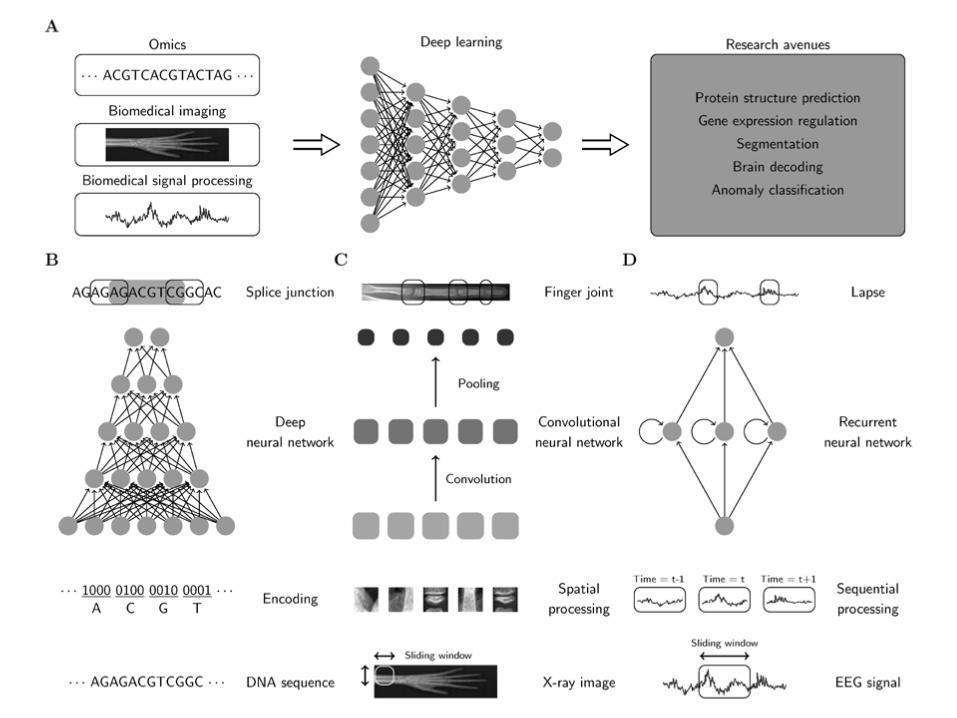
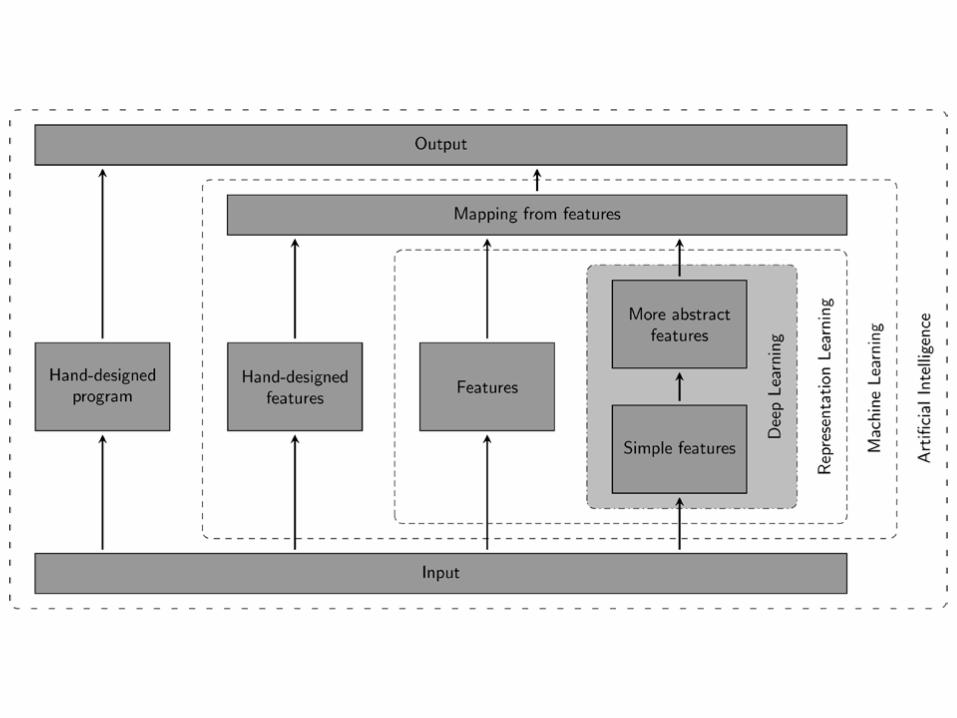
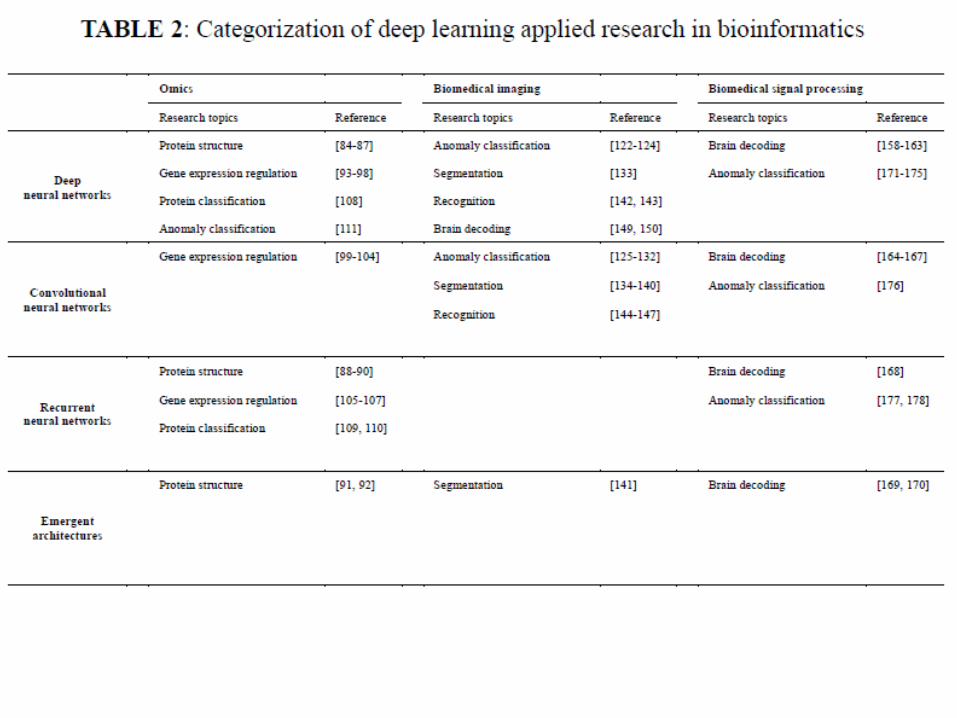
Min 2016 Brief in Bioinformatics



THANK YOU

Zdroje:
• Úvod do statistické metodologieod Mgr. Jana Vrbková, Ph.D., ÚMTM LF UP, [email protected]
http://alfresco.imtm.cz/share/s/e2asWYOaRTWw7ZAPuoNamQ

Acknowledgements and Recommended Resources
• Úvod do statistické metodologieod Mgr. Jana Vrbková, Ph.D., ÚMTM LF UP,
• Jean Daunizeau and his SPM course slides
• http://faculty.vassar.edu/lowry/bayes.html
• P. Baldi University of California, Irvine Deep Learning for Big Data

















