Evropský sociální fond Praha & EU: Investujeme do vaší budoucnosti
Ing. Jiří Kašpar
prof. Ing. Pavel Tvrdík CSc.
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 2/24
High Availability Term Definitions
• High Availability (HA)
• Fault Tolerance (FT)
• Service Level Agreement (SLA)
• Disaster Recovery (DR)
• Disaster Tolerance (DT)
• Recovery Point Objective (RPO)
• Recovery Time Objective (RTO)
High Availability Term Definitions
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 3/24
PI-PSC Terminology
• Defect – fyzická porucha analogová
• Fault – číslicová porucha
• Error – informační nebo datová chyba
• Failure – selhání (typicky funkční)
• Disaster – zničení
High Availability Term Definitions
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 4/24
High Availability (HA)
• Typical computing technologies: o Redundant power supplies and fans o RAID for disks o Clusters of servers o Multiple NICs, redundant routers
o Data Center Facilities: o Dual power feeds, o n+1 Air Conditioning units, o Uninterruptable Power Supply (UPS), o Power generators.
High Availability Term Definitions High Availability (HA)
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 5/24
Single Point of Failure
• is a component whose fault causes fault of the whole system.
• Typically:
• active components in computer backplane,
• single clock module in old SMP systems,
• ...
High Availability Term Definitions Single Point of Failure
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 6/24
Fault Tolerance (FT)
• The ability for a computer system to continue operating despite hardware and/or software failures.
• Typically requires:
• Special hardware with full redundancy, built-in error-checking, and hot-swap support.
• Special software.
• Provides the highest availability possible within a single datacenter.
High Availability Term Definitions Fault Tolerance (FT)
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 7/24
Service Level Agreement (SLA)
• SLA is a part of a service contract where the level of service is formally defined. It usually defines delivery time (of the service) and/or performance.
• The SLA records a common understanding about services, priorities, responsibilities, guarantees, and warranties.
• Common SLA metrics for computer systems:
• Application availability (% per year).
• Application response time (percentage of requests to be processed in agreed time).
• Application throughput (# of transactions to be processed per minute/hour/day).
High Availability Term Definitions Service Level Agreement (SLA)
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 8/24
Disaster Recovery (DR)
• Disaster could be a destruction of the entire datacenter site and everything in it.
• Disaster Recovery is the ability to resume operations after a disaster.
• Implies off-site data storage of some sort.
High Availability Term Definitions Disaster Recovery (DR)
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 9/24
Disaster Recovery (DR)
• Typically:
• Disaster can cause some delay before operations can continue (hours or days), and
• some application data can be lost from IT systems and must be re-entered.
High Availability Term Definitions Disaster Recovery (DR)
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 10/24
Disaster Recovery (DR)
• Success depends on ability to restore, replace, or re-create:
o Data (and external data feeds)
o Facilities
o Computer Systems
o Networks
o User access
High Availability Term Definitions Disaster Recovery (DR)
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 11/24
Disaster Tolerance (DT)
Disaster Tolerance vs. Disaster Recovery:
• Disaster Recovery is the ability to resume operations after a disaster.
• Disaster Tolerance is the ability to continue operations uninterrupted despite a disaster.
• Ideally, Disaster Tolerance allows one to continue operations uninterrupted despite a disaster:
• Without any appreciable delays
• Without any lost transaction data
High Availability Term Definitions Disaster Tolerance (DT)
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 12/24
Disaster Tolerance
• Businesses vary in their requirements with respect to:
• Acceptable recovery time,
• Allowable data loss.
• Technologies also vary in their ability to achieve the ideals of no data loss and zero recovery time
High Availability Term Definitions Disaster Tolerance (DT)
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 13/24
Measuring of Disaster Tolerance and Disaster Recovery Needs
• Determine requirements based on business needs first
• Then find acceptable technologies to meet the needs of the business
High Availability Term Definitions Disaster Tolerance (DT)
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 14/24
Measuring Disaster Tolerance and Disaster Recovery Needs
• Commonly-used metrics:
• Recovery Point Objective (RPO): Amount of data loss that is acceptable, if any.
• Recovery Time Objective (RTO): Amount of downtime that is acceptable, if any.
High Availability Term Definitions Disaster Tolerance (DT)
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 15/24
Recovery Point Objective (RPO)
• Recovery Point Objective is measured in terms of time.
• RPO indicates the point in time to which one is able to recover the data after a failure, relative to the time of the failure itself.
• RPO effectively quantifies the amount of data loss permissible before the business is adversely affected.
High Availability Term Definitions Disaster Tolerance (DT)
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 16/24
Recovery Time Objective (RTO)
• Recovery Time Objective is also measured in terms of time.
• It measures downtime (application unavailability):
• from time of disaster until business can continue.
• Downtime costs vary with the nature of the business, and with outage length.
High Availability Term Definitions Disaster Tolerance (DT)
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 17/24
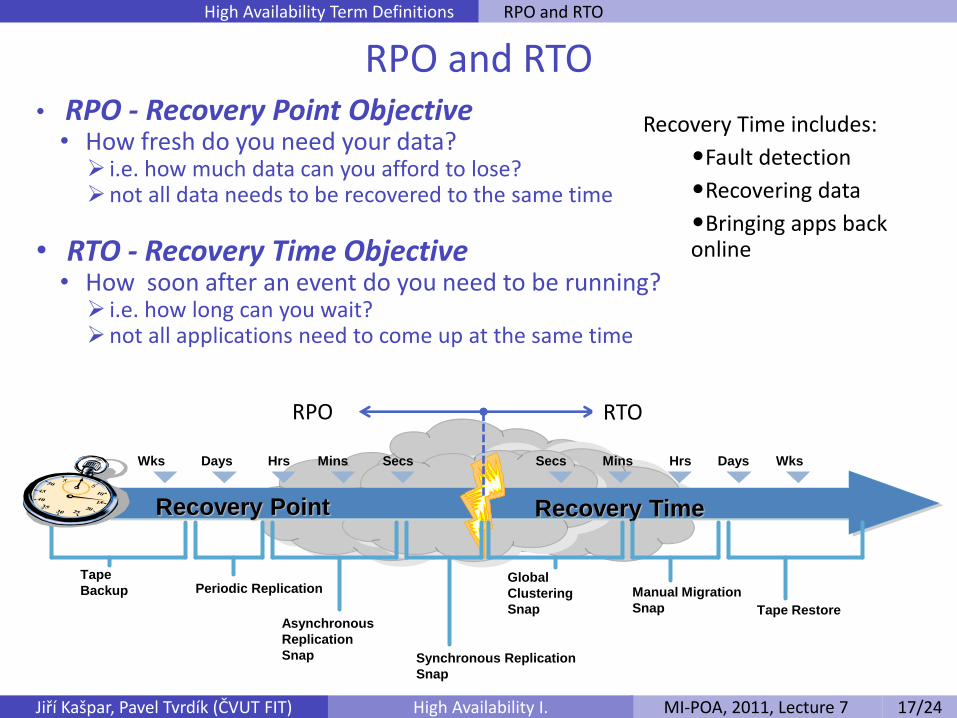
RPO and RTO • RPO - Recovery Point Objective • How fresh do you need your data? i.e. how much data can you afford to lose? not all data needs to be recovered to the same time
• RTO - Recovery Time Objective • How soon after an event do you need to be running? i.e. how long can you wait? not all applications need to come up at the same time
High Availability Term Definitions RPO and RTO
Recovery Time includes:
•Fault detection
•Recovering data
•Bringing apps back online
Tape
Backup
Secs Mins Hrs Days Wks Secs Mins Hrs Days Wks
Recovery Point Recovery Time
Synchronous Replication
Snap
Periodic Replication
Asynchronous
Replication
Snap
Tape Restore
Global
Clustering
Snap
Manual Migration
Snap
RPO RTO
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 18/24
Data Consistency Methods
• Traditional data manipulating techniques update data on the place where they are located (in-place-update).
• Consistency of data and metadata depends on atomicity of update operations.
• Data consistency brings issues at various levels:
o inconsistency of file system metadata,
o inconsistency of file data (i.e., records within a file),
o inconsistency of database indexes and data.
Data Consistency Methods
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 19/24
Sources of Inconsistency
• Even more, disk cache and file system are independent components in traditional Unix.
• Data blocks are write-back cached and written to a disk asynchronously and not in order of write operations.
• Write-back cache does not make difference between data and metadata blocks.
Data Consistency Methods
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 20/24
Log-Structured File System
• Places all new copies of data and metadata to a sequential log. No file or a directory has stable place on a disk, there is the only log.
• Invented in 1990, Sprite LFS
• Very fast write operations, they can achieve write disk performance.
• But, there are two major issues:
• How to find directories, files and data in the log ?
• How to manage free space ?
Data Consistency Methods Log-Structured File System
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 21/24
Database High Available Solutions
• Modern Database Engines can produce transaction logs (After Image of Before Image) to be able to improve high availability parameters.
• These techniques are useful for single or multiple server node databases.
• A database engine usually works with two kinds of database logs (journals):
o on-line redo logs contain both committed and uncommitted transactions (Before Image).
o archive redo logs contain committed transactions only (usually After Image).
Database High Available Solutions
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 22/24
Single Server Node High Availability
• On-line redo logs are used for fast recovery from a failure by reprocessing data changes to ensure data consistency:
• committed transactions are reapplied to data blocks,
• uncommitted transactions are rolled back.
• As on-line redo logs also contain old data (Before Image), they can be used to repair application or database errors using roll back.
• Archive logs are de-facto incremental backups of a database, they can be applied to the restored full copy of database files.
Database High Available Solutions Single Server Node High Availability
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 23/24
Multiple Server Node High Availability
Several levels of High Availability:
• Cold Standby: transfer of closed archive log files to a standby system, and replay of these logs to a restored full backup of the database when necessary.
• Warm Standby: automated transfer of log files and their replay to a standby database.
• Hot Standby: automated asynchronous on-line replication of committed transactions to a standby database. Hot and Warm Standby databases can be in some solutions used for read-only processing.
• Database Mirror: synchronous replication of committed transactions to a standby database.
Database High Available Solutions Multiple Server Node High Availability
Jiří Kašpar, Pavel Tvrdík (ČVUT FIT) MI-POA, 2011, Lecture 7 High Availability I. 24/24
Sources Keith Parris: Long-Distance Disaster Tolerance: Technology, Challenges, State of the Art, and Directions. HP Technology Forum 2005, Orlando.
Mendel Rosenblum and John K. Ousterhout: The Design and Implementation of a Log-Structured File System. http://www.cs.berkeley.edu/~brewer/cs262/LFS.pdf